
Дублированный контент, курирование и что такое Rel=Canonical?
Опубликовано: 2014-05-19 Это холодный, жесткий мир для поисковой системы. Люди просят у вас руководства; вы просматриваете для них миллионы страниц, даете им наилучшие результаты, которые только можете найти, и они никогда не говорят спасибо. С тобой обращаются как с чиновником, игнорируют до тех пор, пока ты им снова не понадобишься. (Нюхать.)
Это холодный, жесткий мир для поисковой системы. Люди просят у вас руководства; вы просматриваете для них миллионы страниц, даете им наилучшие результаты, которые только можете найти, и они никогда не говорят спасибо. С тобой обращаются как с чиновником, игнорируют до тех пор, пока ты им снова не понадобишься. (Нюхать.)
Тем не менее, это мир двигателя, который ест двигатель. У тебя есть работа, и ты будешь делать ее как можно лучше. Это много значит, когда люди обращаются к вам, а не к другим, и чтобы сохранить их доверие, вы должны постоянно совершенствоваться, опережать другие поисковые системы и выдавать самые вкусные результаты.
Некоторые контент-маркетологи хороши в оптимизации, помогая вам с замещающим текстом на фотографиях, осмысленным контентом и метаданными, которые делают совершенно ясным, о чем страница. Когда вы можете дать именно то, о чем просит искатель, это своего рода элегантность, как совершенный пируэт танцора или ловля лучшей волны в нужное время. Почти физическое удовольствие. Если бы у тебя было тело, ты бы ходил немного выше.
Вы мастер в обнаружении нюансов между страницами. Как ищейка, вы вынюхиваете щупальца смысла, которые помогут вам отделить страницу A от страницы A+. И благодаря тренировкам и времени вы развили способность часто определять, когда кто-то пытается вами манипулировать. Когда вы обнаруживаете, что кто-то играет с вашей системой, у вас есть козырная карта: вы можете не отображать этот сайт в результатах поиска, чтобы он не мог снова обмануть или разочаровать нетерпеливого пользователя.
Есть одна загвоздка, которую контент-маркетологи могут разгадать для вас и самих себя, одна проблема, которую часто создают честные люди, желающие поделиться хорошим контентом, которая по иронии судьбы вызывает у вас ненужную проблему: дублирование контента . Хорошо, мы расскажем об этом всему миру для вас.
Почему дублированный контент — это проблема
( Предостережение: то, что следует ниже, представляет собой упрощение дублированного контента высокого уровня, предназначенное как основная информация для маркетолога, создающего контент. Если вы активно практикуете SEO, существует много проблем с дублированием контента (таких как параметры URL и идентификаторы сеансов, и т. д.), которые в этой статье вообще не рассматриваются . Для более продвинутых пользователей мы предлагаем руководство Moz с рекомендациями « Что такое дублированный контент ?»
«Дублированный контент» — это проблема, возникающая, когда на одном веб-сайте размещены две страницы с одинаковым или почти одинаковым контентом, или на двух (или более) веб-сайтах размещена страница с практически идентичным контентом. Вот иллюстрация того, какие проблемы это вызывает:
 Сайт А опубликовал прекрасную биографию третьей жены Чарльза Диккенса из 600 слов. Сайт Б хотел поделиться биографией со своими читателями и попросил разрешения опубликовать ее в блоге Сайта Б. Разрешение получено. Сайт B разместил статью на своем сайте. Копия была такой же, но пост в блоге имел немного другое название и URL-адрес.
Сайт А опубликовал прекрасную биографию третьей жены Чарльза Диккенса из 600 слов. Сайт Б хотел поделиться биографией со своими читателями и попросил разрешения опубликовать ее в блоге Сайта Б. Разрешение получено. Сайт B разместил статью на своем сайте. Копия была такой же, но пост в блоге имел немного другое название и URL-адрес.
- URL-адрес страницы Сайта А выглядит следующим образом: www.sitea.com/Dickens- Third-wife-ran-coffee-shop.
- URL-адрес страницы Сайта Б выглядит следующим образом: www.siteb.com/Dickens-beloved- Third-wife-Althea-ran-coffee-shop.
Вы, дорогой читатель, спросите у своего телефона: «Кем была третья жена Чарльза Диккенса и что с ней случилось?»
Если поисковая система определяет, что лучшим ответом на ваш запрос является биография из 600 слов, она не знает, какую страницу выбрать для возврата: на сайте А или на сайте Б. Он вынюхивает любые различия (возможно, авторитет сайта поможет ему определиться), но, по сути, он в затруднительном положении. Не самое лучшее место для занятой поисковой системы, чтобы зацикливаться на ней, и система будет раздражена этим.
Google и другие движки не любят дублированный контент, потому что это усложняет их работу и мешает им выдавать наилучшие результаты. (Возвращение хороших результатов — это то, как поисковые системы прибавляют и ослабевают в нашей привязанности, следовательно, как они могут взимать плату за рекламу — как они живут и умирают.) И когда они находят дублированный контент на ваших страницах, у них есть возможность выразить это неудовольствие, игнорируя вас, тем самым затрудняя поиск вашего веб-сайта, что серьезно ограничивает ваши усилия по входящему маркетингу.
Сделать так, чтобы поисковая система могла легко и просто находить и оценивать ваш контент, называется «поисковая оптимизация». Общепринятого термина, противоположного SEO, не существует, но, возможно, он должен быть. (Предложения приветствуются.)
Дублирование контента на вашем собственном сайте (сайтах)
Исправить это легко. Никогда не бывает веской причины для дублирования контента на вашем собственном сайте. У каждой страницы должна быть своя уникальная история, и никакие две страницы не должны рассказывать одну и ту же историю. Предположим, вы разводите и продаете йоркширских терьеров, и ваша цель — убедить людей предпочесть йоркширского терьера другой породе. Вам нужна только одна страница, посвященная привлекательному характеру породы. Это расположение может быть упомянуто на других страницах, но каждая страница должна иметь свою направленность (как тренировать, чем кормить, продолжительность жизни, историю, как покупать и т. д.). Эти другие страницы могут упоминать темперамент и ссылаться на страницу о характере; это хорошо для читателя, а значит, и для SEO.
Если у вас есть несколько сайтов и у вас есть контент, который будет хорошо смотреться на всех сайтах, вы можете разместить его на них всех; читайте дальше и обратите особое внимание на информацию «rel=canonical» в конце.
Дублирование контент-фермами
«Контент-фермы» по-прежнему часто берут хорошую историю из Интернета и раскручивают ее, механически или каким-либо другим образом. Цель состоит в том, чтобы рассказать одну и ту же историю (и получить одинаковую оценку контента), изменив при этом ровно столько, чтобы поисковые системы не распознали его как дублированный контент. Это форма плагиата, метод черной шляпы, и поисковые системы набросятся на него, если обнаружат. (Браво!) Если вы нанимаете какое-либо агентство для помощи в создании контента, убедитесь, что они не распространяют чужой контент. Если на вашем сайте будет найден дубликат, вы будете тем, кто заплатит штраф, независимо от того, насколько невинно вы его приобрели или кого вы наняли, чтобы создать его для вас. (Кроме того, хороший контент стоит времени, или денег, или и того, и другого; настоящих коротких путей не существует. Покупатель, будьте осторожны.)
Курирование не должно быть дублированием
Иногда вы находите настолько умную, полезную или хорошо написанную историю, что вам хочется ею поделиться. Вы всегда можете привлечь к ней внимание в твите или публикации в Facebook (конечно, со ссылкой на ее автора). Если вы просто повторно опубликуете это, эта невинная публикация может начаться как форма признательности… но закончиться дублирующимся контентом. Если вы хотите курировать чей-то контент, это желанная форма обмена, если вы делаете это правильно. (Неписаные) правила:

- Делитесь только тем, что, как вы знаете, ваши собственные читатели оценят.
- Не переиздавайте всю историю. Выберите фрагменты или несколько абзацев.
- Отдайте должное оригинальному автору или сайту и дайте ссылку на исходный контент.
- Включите собственное мнение. Есть что сказать уникальное; это то, что действительно будет означать, что ваша работа является оригинальной работой. Ваши собственные слова должны составлять основную часть статьи.
- Это мило и считается хорошим тоном (хотя и не всегда строго практичным или необходимым) сначала связаться с автором и сообщить ему, что вы курируете его произведение. Люди, у которых полмиллиона подписчиков или колонки в крупных газетах, могут не ответить, но люди, хорошо известные в своей области (если не совсем публичные лица), могут, и они часто это оценят.
Думайте об этом как о обзоре книги: вы добавляете ценность, привлекая внимание к книге, и вы добавляете ценность своим комментарием. Вы не перепечатываете книгу (но даете ссылку на нее, чтобы люди могли легко найти и прочитать ее).
Что такое rel=canonical? - и почему вы должны заботиться
Рано или поздно появится статья или запись в блоге, которую вы захотите полностью перепечатать. Может быть, кто-то только что сказал что-то настолько прекрасное, что вы не хотите его сокращать и редактировать — вы хотите переиздать все это, как есть, на благо ваших читателей. Или, может быть, вы написали гостевой пост для другого веб-сайта или блога и хотите, чтобы его увидели ваши собственные читатели. Вы можете сделать это, не рискуя вызвать гнев Google (и др.) за дублированный контент, используя тег rel=canonical в метаданных переизданной статьи.
Вы можете думать о rel=canonical как о направлении URL на «каноническую» страницу. «Канон» — это основополагающий принцип, общепринятый стандарт, существенная основа чего-либо и т. д. «Каноническая» страница — это основная, исходная, исходная страница; «rel=» означает «отношения». Таким образом, rel=canonical, по сути, означает, что «каноническая версия этой страницы находится по этому URL-адресу». (Более подробную информацию о канонических ссылках можно найти здесь.)
Большинство веб-страниц уже имеют rel=canonical в своих полях метаданных. По умолчанию обычно используется URL-адрес веб-страницы. Если вы используете систему управления контентом, вполне вероятно, что rel=canonical является стандартным тегом и по умолчанию использует собственный URL-адрес страницы.
Недавно Рикки Банделин из Industrial Quality Management написал хороший гостевой пост о доставляемости, который мы опубликовали в блоге Act-On Marketing Action. Вот как выглядит rel=canonical в исходном коде на нашем сайте:

Рики также разместил статью на своем сайте. Обратите внимание, что хотя большая часть его исходного кода отличается, rel=canonical такой же, как и в блоге Act-On. Он сообщает Google (или любой поисковой системе), что исходный контент находится там , по этому URL-адресу действия. Он ведет себя как своего рода перенаправление для Google (и др.).

Теперь предположим, что кто-то ищет утку + доставляемость + электронная почта. Google может просматривать обе страницы и знать, какую из них вернуть. Веб-страница, отображающая блог Act-On, будет показана искателю, потому что в обоих местах, где находится этот контент, все согласны с тем, что страница блога Act-On является канонической страницей.
Вернемся к нашему примеру с биографией миссис Диккенс из 600 слов:
URL-адрес страницы Сайта А: www.sitea.com/Dickens- Third-wife-ran-coffee-shop. Относительное = каноническое:
- <ссылка rel="canonical" href="https://sitea.com/Dickens- Third-wife-ran-coffee-shop/" />
URL-адрес страницы Сайта Б: www.siteb.com/Dickens-beloved- Third-wife-Althea-ran-coffee-shop. Но rel=canonical теперь такой же, как на сайте A:
- <ссылка rel="canonical" href="https://sitea.com/Dickens- Third-wife-ran-coffee-shop/" />
Поисковые системы точно знают, на какую страницу возвращаться; к ним вопросов нет. А контент-маркетолог Сайта Б может показывать своим читателям отличный контент без риска дублирования контента. .
Настройте ссылку rel=canonical в системе управления контентом.
Вам не нужно быть мастером кода, чтобы настроить это. В качестве примера мы будем использовать сообщение в блоге.
Если вы используете WordPress и Yoast:
1. Подготовьте черновик сообщения в блоге в WordPress
2. Перейдите на веб-страницу поста или статьи, которую вы хотите опубликовать; скопируйте URL-адрес
3. Вернитесь к черновику в приложении WordPress.
4. Нажмите «Дополнительно» на панели SEO.
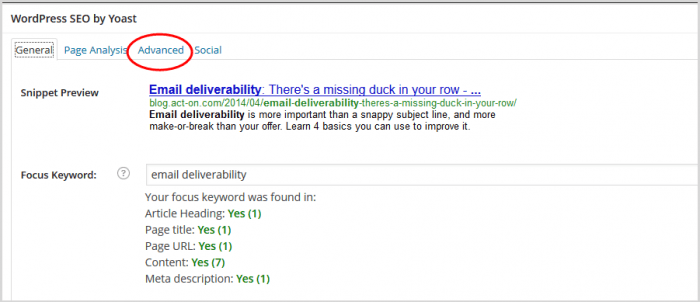 5. В открывшейся панели прокрутите вниз до поля канонического URL.
5. В открывшейся панели прокрутите вниз до поля канонического URL.
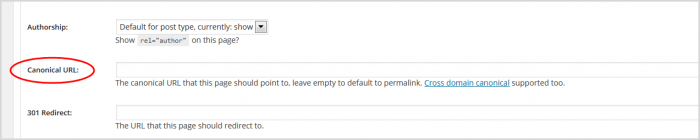
6. Введите скопированный URL-адрес. Плагин Yoast добавит для вас бит rel=
Для других систем управления контентом часто используется аналогичное поле rel=canonical или его эквивалент.
Если нет очевидного поля, вы можете создать ссылку rel=canonical в исходном коде своей страницы.
Настройте rel=canonical прямо в исходном коде.
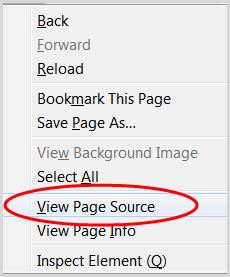 1. Настройте свой пост в блоге как черновик
1. Настройте свой пост в блоге как черновик
2. Перейдите на страницу с контентом, который вы хотите опубликовать повторно.
3. Щелкните правой кнопкой мыши и выберите «Просмотреть исходный код страницы».
4. Найдите на странице метатег rel=canonical.
5. Скопируйте всю последовательность тегов
Это должно выглядеть примерно так:
<link rel="canonical" href=" https://www.what-ever-the-text-actually-is/ " />
6. Замените собственный тег rel=canonical на скопированный.
Теперь, когда вы опубликуете этот пост, ваши метаданные сообщат Google, где находится каноническая версия этой страницы. Поздравления; Вы только что сделали поисковую систему очень счастливой. И это хорошо.
Для получения дополнительной информации о rel=canonical см. пост Google « 5 распространенных ошибок с Rel=Canonical ».
Для получения дополнительной информации об основах SEO прочитайте SEO 101: основы и не только.
NB: На самом деле на фотографии Кэтрин Хогарт Диккенс, единственная жена Чарльза Диккенса.