
Conteúdo duplicado, curadoria e – O que é um Rel=Canonical?
Publicados: 2014-05-19 É um mundo frio e difícil para um mecanismo de busca. As pessoas pedem orientação; você escaneia milhões de páginas para eles, dá a eles os melhores resultados que pode encontrar e eles nunca agradecem. Você é tratado como um funcionário, ignorado até que precisem de você novamente. (Farejar.)
É um mundo frio e difícil para um mecanismo de busca. As pessoas pedem orientação; você escaneia milhões de páginas para eles, dá a eles os melhores resultados que pode encontrar e eles nunca agradecem. Você é tratado como um funcionário, ignorado até que precisem de você novamente. (Farejar.)
Ainda assim, é um mundo de motores comendo motores. Você tem um trabalho a fazer e vai fazê-lo da melhor maneira possível. Significa muito quando as pessoas recorrem a você em detrimento de outras pessoas e, para manter a confiança delas, você precisa melhorar o tempo todo, ultrapassar os outros mecanismos de pesquisa e fornecer os resultados mais saborosos.
Alguns profissionais de marketing de conteúdo são bons em otimização, ajudando você com texto alternativo em fotos, conteúdo significativo e metadados que deixam totalmente claro sobre o que é a página. Quando você pode entregar exatamente o que um pesquisador pediu, é uma espécie de elegância, como uma pirueta executada com perfeição por um dançarino ou pegar a melhor onda de todos os tempos precisamente no momento certo. Um prazer quase físico. Se você tivesse um corpo, andaria um pouco mais alto.
Você é um mestre em detectar as nuances entre as páginas. Como um cão de caça, você fareja as gavinhas de significado que o ajudam a separar uma página A de uma página A+. E por meio de treinamento e tempo, você desenvolveu a capacidade de perceber quando alguém está tentando manipulá-lo. Quando você descobre alguém jogando contra o seu sistema, você tem um trunfo para jogar: você pode optar por não exibir esse site nos resultados da pesquisa, para que ele não engane ou desaponte um pesquisador ansioso novamente.
Há um problema que os profissionais de marketing de conteúdo podem resolver para você e para eles mesmos, um problema geralmente criado por pessoas honestas que desejam compartilhar um bom conteúdo que, ironicamente, causa um problema desnecessário: conteúdo duplicado . Ok, vamos contar ao mundo sobre isso para você.
Por que o conteúdo duplicado é um problema
( Advertência: o que se segue é uma simplificação de alto nível de conteúdo duplicado, com o objetivo de fornecer informações básicas para o profissional de marketing que cria conteúdo. Se você for um profissional de SEO ativo, há muitos problemas de conteúdo duplicado (como parâmetros de URL e IDs de sessão, etc.) que este artigo não aborda de forma alguma . Para os mais avançados , sugerimos o guia Moz' Best Practices, “ What is Duplicate Content ?”
“Conteúdo duplicado” é um problema criado quando um site hospeda duas páginas de conteúdo iguais ou quase iguais, ou dois (ou mais) sites hospedam uma página de conteúdo praticamente idêntico. Aqui está uma ilustração do tipo de problemas que causa:
 O site A publicou uma adorável biografia de 600 palavras da terceira esposa de Charles Dickens. O Site B queria compartilhar a biografia com seus leitores e pediu permissão para publicá-la no blog do Site B. Permissão garantida. O Site B postou o artigo em seu próprio site. A cópia era a mesma, mas a postagem do blog tinha um título ligeiramente diferente e sua URL era diferente.
O site A publicou uma adorável biografia de 600 palavras da terceira esposa de Charles Dickens. O Site B queria compartilhar a biografia com seus leitores e pediu permissão para publicá-la no blog do Site B. Permissão garantida. O Site B postou o artigo em seu próprio site. A cópia era a mesma, mas a postagem do blog tinha um título ligeiramente diferente e sua URL era diferente.
- A URL da página do Site A é esta: www.sitea.com/Dickens-third-wife-ran-coffee-shop.
- A URL da página do Site B é esta: www.siteb.com/ Dickens-beloved-third-wife-Althea-ran-coffee-shop.
Você, caro leitor, pergunte ao seu telefone: “Quem foi a terceira esposa de Charles Dickens e o que aconteceu com ela?”
Se o mecanismo de busca determinar que a biografia de 600 palavras é a melhor resposta para sua solicitação, o mecanismo não saberá se deve escolher a página do Site A ou do Site B para retornar. Ele fareja quaisquer diferenças (talvez a autoridade do site o ajude a decidir), mas, essencialmente, está em um dilema. Não é um bom lugar para um mecanismo de busca ocupado ficar travado, e o mecanismo ficará irritado com isso.
O Google e os outros mecanismos não gostam de conteúdo duplicado porque isso dificulta o trabalho e interfere na capacidade de retornar os melhores resultados. (Retornar bons resultados é como os mecanismos de busca aumentam e diminuem em nossa afeição, portanto, como eles podem cobrar por publicidade – como eles vivem e morrem.) E quando encontram conteúdo duplicado em suas páginas, eles têm o poder de desabafar esse descontentamento ignorando você, tornando seu site mais difícil de encontrar – colocando um grande obstáculo em seus esforços de marketing de entrada.
Tornar simples e fácil para um mecanismo de pesquisa encontrar e avaliar seu conteúdo é chamado de “otimização de mecanismo de pesquisa”. Não há um termo comum para o oposto de SEO, mas talvez devesse haver. (Sugestões são bem-vindas.)
Duplicar conteúdo em seu(s) próprio(s) site(s)
A solução para isso é fácil. Nunca há um bom motivo para conteúdo duplicado em seu próprio site. Cada página deve ter sua própria história única para contar, e duas páginas não devem contar exatamente a mesma história. Suponha que você crie e venda Yorkshire terriers, e seu objetivo é fazer com que as pessoas escolham um Yorkie em vez de outra raça. Você precisa de apenas uma página que se concentre na disposição adorável da raça. Essa disposição pode ser mencionada em outras páginas, mas cada página deve ter seu foco (como treinar, o que alimentar, tempo de vida, história, como comprar, etc.). Essas outras páginas podem mencionar temperamento e vincular à página de disposição; isso é bom para o leitor e também para o SEO.
Se você tiver vários sites e tiver conteúdo que seria bom em todos os sites, poderá publicá-lo em todos eles; continue lendo e preste atenção especial às informações “rel=canonical” no final.
Duplicação por fazendas de conteúdo
Ainda é comum que “fazendas de conteúdo” peguem uma boa história da web e a divulguem, mecanicamente ou não. O objetivo é contar a mesma história (e obter a mesma avaliação de conteúdo) enquanto muda apenas o suficiente para que os mecanismos de pesquisa não o reconheçam como conteúdo duplicado. É uma forma de plágio, uma técnica de chapéu preto, e os mecanismos de busca atacarão se descobrirem. (Bravo!) Se você está contratando algum tipo de agência para ajudá-lo a criar conteúdo, certifique-se de que eles não estão divulgando o conteúdo de outras pessoas. Se uma cópia duplicada fiada for encontrada em seu site, você é quem pagará a penalidade, não importa o quão inocentemente você a comprou ou quem você contratou para criá-la para você. (À parte: um bom conteúdo custa tempo, ou dinheiro, ou ambos; não há atalhos reais. O comprador deve ficar atento.)
Curadoria não deve ser duplicação
Às vezes, você encontra uma história tão inteligente, útil ou bem escrita que deseja compartilhá-la. Você sempre pode chamar a atenção para isso em um tweet ou postagem no Facebook (atribuindo-o ao autor, é claro). Se você simplesmente republicá-lo, esse compartilhamento inocente pode começar como uma forma de agradecimento... mas terminar em conteúdo duplicado. Se você deseja selecionar o conteúdo de alguém, essa é uma forma de compartilhamento bem-vinda, desde que você o faça corretamente. As regras (não escritas) são:

- Compartilhe apenas o que você sabe que seus próprios leitores apreciarão encontrar.
- Não republique a história inteira. Escolha trechos ou alguns parágrafos.
- Dê crédito ao autor ou site original e coloque um link para o conteúdo original.
- Inclua sua própria opinião. Tenha algo único a dizer; isso é o que realmente significará que sua peça é um trabalho original. Suas próprias palavras devem formar a maior parte do artigo.
- É bom e educado (mesmo que nem sempre seja estritamente prático ou necessário) entrar em contato com o autor primeiro e informá-lo de que você está selecionando a peça dele. Pessoas com meio milhão de seguidores ou colunas em grandes jornais podem não responder, mas pessoas que são bem conhecidas em suas áreas (se não exatamente personagens públicos) podem, e muitas vezes vão gostar disso.
Pense nisso como uma resenha de livro: você está agregando valor ao chamar a atenção para o livro e está agregando valor com seu comentário. Você não está reimprimindo o livro (mas coloca um link para ele para que as pessoas possam encontrá-lo e lê-lo facilmente).
O que é um rel=canônico? – e por que você deveria se importar
Mais cedo ou mais tarde, haverá um artigo ou postagem de blog que você deseja reimprimir in toto. Talvez alguém tenha dito algo tão perfeitamente que você não quer cortá-lo e fazer a curadoria – você quer republicar a coisa toda, assim como está, para o benefício de seus leitores. Ou talvez você tenha escrito uma postagem de convidado para outro site ou blog e deseja que seus próprios leitores a vejam. Você pode fazer isso sem arriscar a ira de conteúdo duplicado do Google (e outros) usando uma tag rel=canonical nos metadados do artigo republicado.
Você pode pensar em um rel=canonical como uma direção de URL para uma página “canônica”. Um “cânone” é um princípio fundamental, um padrão aceito, a base essencial de algo, etc. Uma página “canônica” é a página de origem essencial e original; “rel=” significa “relação”. Portanto, rel=canonical significa essencialmente “a versão canônica desta página pode ser encontrada neste endereço de URL”. (Informações mais detalhadas sobre as ervas daninhas sobre links canônicos podem ser encontradas aqui.)
A maioria das páginas da Web já possui um rel=canonical em seus campos de metadados. O padrão geralmente é o URL da página da web. Se você usa um sistema de gerenciamento de conteúdo, é provável que rel=canonical seja uma tag padrão e, por padrão, use o próprio URL da página.
Recentemente, Ricky Bandelin, da Industrial Quality Management, escreveu um bom post sobre entregabilidade que publicamos no blog Marketing Action da Act-On. Aqui está a aparência do rel=canonical no código-fonte em nosso site:

Ricky postou o artigo em seu próprio site também. Observe que, embora a maior parte de seu código-fonte seja diferente, o rel=canonical é o mesmo do blog do Act-On. Ele está informando ao Google (ou a qualquer mecanismo de pesquisa) que o conteúdo original está ali , naquele URL do Act-On. Ele se comporta como uma espécie de redirecionamento para o Google (etc.).

Agora suponha que alguém pesquise pato + capacidade de entrega + e-mail. O Google pode olhar para ambas as páginas e saber qual delas retornar. A página da web que exibe o blog Act-On será aquela mostrada ao pesquisador porque em ambos os locais onde esse conteúdo reside, todos concordam que a página do blog Act-On é a página canônica.
Voltando ao nosso exemplo da biografia de 600 palavras da Sra. Dickens:
O URL da página do Site A é www.sitea.com/Dickens-third-wife-ran-coffee-shop. O rel=canônico é:
- <link rel=”canonical” href=”https://sitea.com/Dickens-third-wife-ran-coffee-shop/” />
A URL da página do Site B é www.siteb.com/Dickens-beloved-third-wife-Althea-ran-coffee-shop. Mas o rel=canonical é o mesmo agora do Site A:
- <link rel=”canonical” href=”https://sitea.com/Dickens-third-wife-ran-coffee-shop/” />
Os mecanismos de busca sabem exatamente qual página retornar; não há problemas para eles. E o profissional de marketing de conteúdo do Site B consegue mostrar a seus leitores um ótimo conteúdo sem risco de conteúdo duplicado. .
Configurar um link rel=canonical em um sistema de gerenciamento de conteúdo
Você não precisa ser um assistente de código para configurar isso. Usaremos uma postagem de blog como nosso exemplo.
Se você usa WordPress e Yoast:
1. Prepare seu rascunho de postagem de blog no WordPress
2. Acesse a página da postagem ou artigo que deseja republicar; copie o URL
3. Volte ao seu rascunho em seu aplicativo WordPress
4. Clique em “Avançado” no painel SEO
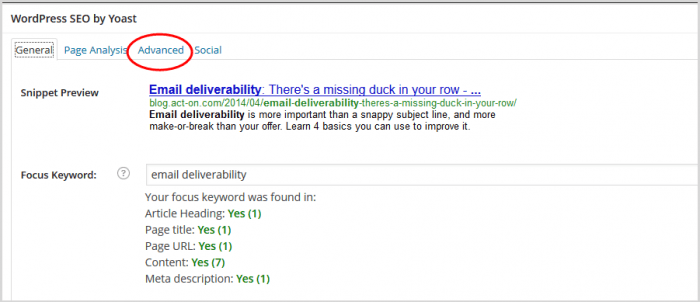 5. No painel que se abre, role para baixo até o campo URL canônico.
5. No painel que se abre, role para baixo até o campo URL canônico.
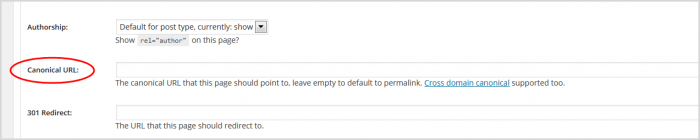
6. Insira o URL que você copiou. O plug-in Yoast adicionará o bit rel= para você
Para outros sistemas de gerenciamento de conteúdo, geralmente há um campo rel=canonical semelhante ou equivalente.
Se não houver um campo óbvio, você pode criar um link rel=canonical no código-fonte da sua página.
Configure um rel=canonical diretamente no código-fonte
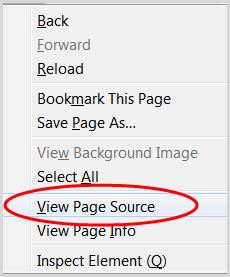 1. Configure sua postagem de blog como um rascunho
1. Configure sua postagem de blog como um rascunho
2. Acesse a página com o conteúdo que deseja republicar
3. Clique com o botão direito do mouse e escolha “Exibir fonte da página”
4. Na página, procure a meta tag rel=canonical
5. Copie toda a sequência de tags
Deve se parecer muito com isto:
<link rel=”canonical” href=” https://www.what-ever-the-text-actually-is/ “ />
6. Substitua sua própria tag rel=canonical pela que você copiou
Agora, quando você publicar esta postagem, seus metadados permitirão que o Google saiba onde está a versão canônica desta página. Parabéns; você acabou de deixar um mecanismo de pesquisa muito feliz. E isso é bom.
Para obter mais informações sobre rel=canonical, consulte a postagem do Google “ 5 erros comuns com Rel=Canonical .”
Para obter mais informações sobre SEO básico, leia SEO 101: The Basics and Beyond
NB: A fotografia é na verdade de Catherine Hogarth Dickens, a única esposa de Charles Dickens.