
Duplicate Content, Curation und – Was ist ein Rel=Canonical?
Veröffentlicht: 2014-05-19 Es ist eine kalte, harte Welt für eine Suchmaschine. Die Leute bitten dich um Führung; Sie scannen Millionen von Seiten für sie, geben ihnen die besten Ergebnisse, die Sie finden können, und sie sagen nie Danke. Du wirst wie ein Funktionär behandelt, ignoriert, bis sie dich wieder brauchen. (Schnüffeln.)
Es ist eine kalte, harte Welt für eine Suchmaschine. Die Leute bitten dich um Führung; Sie scannen Millionen von Seiten für sie, geben ihnen die besten Ergebnisse, die Sie finden können, und sie sagen nie Danke. Du wirst wie ein Funktionär behandelt, ignoriert, bis sie dich wieder brauchen. (Schnüffeln.)
Trotzdem ist es eine Motor-Eat-Engine-Welt. Sie haben einen Job zu erledigen, und Sie werden ihn so gut wie möglich erledigen. Es bedeutet viel, wenn sich die Leute an Sie wenden, anstatt an andere, und um ihr Vertrauen zu behalten, müssen Sie immer besser werden, die anderen Suchmaschinen überholen und die leckersten Ergebnisse liefern.
Einige Content-Vermarkter sind gut in der Optimierung und helfen Ihnen mit Alt-Text auf Fotos, aussagekräftigen Inhalten und Metadaten, die völlig klar machen, worum es auf der Seite geht. Wenn Sie genau das liefern können, was ein Suchender verlangt, ist es eine Art Eleganz, wie die perfekt ausgeführte Pirouette eines Tänzers oder das Fangen der besten Welle aller Zeiten genau zum richtigen Zeitpunkt. Ein fast körperliches Vergnügen. Wenn du einen Körper hättest, würdest du ein bisschen größer gehen.
Sie sind ein Meister darin, die Nuancen zwischen den Seiten zu erkennen. Wie ein Bluthund schnüffeln Sie nach den Ranken der Bedeutung, die Ihnen helfen, eine A-Seite von einer A+-Seite zu trennen. Und durch Training und Zeit haben Sie die Fähigkeit entwickelt, oft zu erkennen, wenn jemand versucht, Sie zu manipulieren. Wenn Sie jemanden entdecken, der auf Ihrem System spielt, haben Sie einen Trumpf zum Ausspielen: Sie können sich dafür entscheiden, diese Seite nicht in den Suchergebnissen anzuzeigen, damit sie einen eifrigen Suchenden nicht erneut täuschen oder enttäuschen kann.
Es gibt einen Haken, den Content-Vermarkter für Sie und sich selbst lösen könnten, ein Problem, das oft von ehrlichen Menschen verursacht wird, die gute Inhalte teilen möchten, das Ihnen ironischerweise ein unnötiges Problem verursacht: Duplicate Content . Okay, wir werden der Welt für dich davon erzählen.
Warum Duplicate Content ein Problem ist
(Einschränkung: Was folgt, ist eine grobe Vereinfachung von doppelten Inhalten, die als sehr grundlegende Informationen für den Vermarkter gedacht ist, der Inhalte erstellt. Wenn Sie ein aktiver SEO-Praktiker sind, gibt es viele Probleme mit doppelten Inhalten (wie URL-Parameter und Sitzungs-IDs, usw.), auf die dieser Artikel überhaupt nicht eingeht . Für die Fortgeschrittenen empfehlen wir den Best Practices-Leitfaden von Moz, „ What is Duplicate Content ?“
„Duplicate Content“ ist ein Problem, das entsteht, wenn eine Website zwei Seiten mit Inhalten hostet, die gleich oder fast gleich sind, oder zwei (oder mehr) Websites eine Seite mit praktisch identischem Inhalt hosten. Hier ist eine Illustration der Art von Problemen, die es verursacht:
 Site A veröffentlichte eine schöne 600-Wörter-Biographie von Charles Dickens' dritter Frau. Seite B wollte die Biografie mit ihren Lesern teilen und bat um Erlaubnis, sie auf dem Blog von Seite B veröffentlichen zu dürfen. Erlaubnis erteilt. Seite B veröffentlichte den Artikel auf ihrer eigenen Seite. Der Text war derselbe, aber der Blogbeitrag hatte einen etwas anderen Titel und seine URL war anders.
Site A veröffentlichte eine schöne 600-Wörter-Biographie von Charles Dickens' dritter Frau. Seite B wollte die Biografie mit ihren Lesern teilen und bat um Erlaubnis, sie auf dem Blog von Seite B veröffentlichen zu dürfen. Erlaubnis erteilt. Seite B veröffentlichte den Artikel auf ihrer eigenen Seite. Der Text war derselbe, aber der Blogbeitrag hatte einen etwas anderen Titel und seine URL war anders.
- Die URL der Seite von Site A lautet: www.sitea.com/Dickens-third-wife-ran-coffee-shop.
- Die URL der Seite von Site B lautet: www.siteb.com/Dickens-beloved-third-wife-Althea-ran-coffee-shop.
Sie, lieber Leser, fragen Ihr Telefon: „Wer war die dritte Frau von Charles Dickens, und was ist mit ihr passiert?“
Wenn die Suchmaschine feststellt, dass die 600-Wörter-Biographie die beste Antwort auf Ihre Anfrage ist, weiß die Suchmaschine nicht, ob sie die Seite auf Site A oder Site B auswählen soll, um zurückzukehren. Es schnüffelt nach Unterschieden (vielleicht hilft ihm die Site-Autorität bei der Entscheidung), aber im Grunde ist es in einem Dilemma. Kein guter Ort für eine geschäftige Suchmaschine, um aufzulegen, und die Suchmaschine wird darüber verärgert sein.
Google und die anderen Suchmaschinen mögen doppelte Inhalte nicht, weil sie ihre Arbeit erschweren und ihre Fähigkeit beeinträchtigen, die besten Ergebnisse zu liefern. (Das Zurückgeben guter Ergebnisse ist, wie Suchmaschinen in unserer Zuneigung wachsen und schwinden, ergo, wie sie Werbung berechnen können – wie sie leben und sterben.) Und wenn sie doppelte Inhalte auf Ihren Seiten finden, haben sie die Macht, diesem Unmut Luft zu machen, indem sie sie ignorieren Sie, wodurch Ihre Website schwerer zu finden ist – was Ihre Inbound-Marketing-Bemühungen erheblich beeinträchtigt.
Es für eine Suchmaschine unkompliziert und einfach zu machen, Ihre Inhalte zu finden und zu bewerten, nennt man „Suchmaschinenoptimierung“. Es gibt keinen gebräuchlichen Begriff für das Gegenteil von SEO, aber vielleicht sollte es einen geben. (Vorschläge willkommen.)
Duplicate Content auf Ihrer/Ihren eigenen Website(s)
Die Lösung dafür ist einfach. Es gibt nie einen triftigen Grund für Duplicate Content auf der eigenen Seite. Jede Seite sollte ihre eigene einzigartige Geschichte zu erzählen haben, und keine zwei Seiten sollten genau dieselbe Geschichte erzählen. Angenommen, Sie züchten und verkaufen Yorkshire Terrier und Ihr Ziel ist es, die Leute dazu zu bringen, einen Yorkie einer anderen Rasse vorzuziehen. Sie brauchen nur eine Seite, die sich auf die liebenswerte Veranlagung der Rasse konzentriert. Diese Einstellung kann auf anderen Seiten erwähnt werden, aber jede Seite sollte ihren eigenen Schwerpunkt haben (wie man trainiert, was man füttert, Lebensdauer, Geschichte, wie man kauft usw.). Diese anderen Seiten können das Temperament erwähnen und auf die Seite über die Disposition verlinken; Das ist gut für den Leser und damit auch gut für SEO.
Wenn Sie mehrere Websites haben und Inhalte haben, die auf allen Websites gut wären, können Sie sie auf allen veröffentlichen. Lesen Sie weiter und achten Sie besonders auf die „rel=canonical“-Informationen am Ende.
Vervielfältigung durch Inhaltsfarmen
Es ist immer noch üblich, dass „Content-Farmen“ eine gute Geschichte aus dem Internet holen und sie mechanisch oder auf andere Weise drehen. Das Ziel ist es, die gleiche Geschichte zu erzählen (und die gleiche Bewertung des Inhalts zu erhalten), während sich gerade genug ändert, damit die Suchmaschinen ihn nicht als doppelten Inhalt erkennen. Es ist eine Form des Plagiats, eine Black-Hat-Technik, und die Suchmaschinen werden sich stürzen, wenn sie es entdecken. (Bravo!) Wenn Sie irgendeine Agentur beauftragen, Ihnen bei der Erstellung von Inhalten zu helfen, stellen Sie sicher, dass sie nicht die Inhalte anderer drehen. Wenn auf Ihrer Website eine gesponnene Duplikatkopie gefunden wird, sind Sie derjenige, der die Strafe zahlen muss, egal wie unschuldig Sie sie gekauft haben oder wen Sie mit der Erstellung für Sie beauftragt haben. (Nebenbei: Gute Inhalte kosten Zeit oder Geld oder beides; es gibt keine wirklichen Abkürzungen. Käufer aufgepasst.)
Kuration sollte keine Duplizierung sein
Manchmal finden Sie eine Geschichte, die so klug oder nützlich oder gut geschrieben ist, dass Sie sie teilen möchten. Sie können jederzeit in einem Tweet oder Facebook-Posting darauf aufmerksam machen (natürlich mit Angabe des Autors). Wenn Sie es einfach erneut posten, kann dieses unschuldige Teilen als eine Form der Wertschätzung beginnen … aber in doppeltem Inhalt enden. Wenn Sie Inhalte von jemandem kuratieren möchten, ist dies eine willkommene Form des Teilens, solange Sie es richtig machen. Die (ungeschriebenen) Regeln lauten:

- Teilen Sie nur das mit, von dem Sie wissen, dass Ihre eigenen Leser es schätzen werden, es zu finden.
- Veröffentliche nicht die ganze Geschichte. Wählen Sie Snippets oder ein paar Absätze aus.
- Nennen Sie den ursprünglichen Autor oder die Website und verlinken Sie auf den ursprünglichen Inhalt.
- Fügen Sie Ihre eigene Meinung hinzu. Haben Sie etwas Einzigartiges zu sagen; Dies wird wirklich bedeuten, dass Ihr Stück ein Originalwerk ist. Ihre eigenen Worte sollten den Großteil des Artikels ausmachen.
- Es gehört zu den netten und guten Manieren (wenn auch nicht immer streng praktisch oder notwendig), zuerst mit dem Autor in Kontakt zu treten und ihn wissen zu lassen, dass Sie sein Stück kuratieren. Leute mit einer halben Million Follower oder Kolumnen in großen Zeitungen antworten vielleicht nicht, aber Leute, die auf ihrem Gebiet bekannt sind (wenn nicht gerade Persönlichkeiten des öffentlichen Lebens), können das, und sie werden es oft zu schätzen wissen.
Stellen Sie es sich wie eine Buchbesprechung vor: Sie schaffen Mehrwert, indem Sie die Aufmerksamkeit auf das Buch lenken, und Sie schaffen Mehrwert mit Ihrem Kommentar. Sie drucken das Buch nicht nach (aber Sie verlinken darauf, damit die Leute es leicht finden und lesen können).
Was ist ein rel=canonical? – und warum es Sie interessieren sollte
Früher oder später wird es einen Artikel oder Blog-Beitrag geben, den Sie im Wesentlichen vollständig nachdrucken möchten. Vielleicht hat jemand gerade etwas so perfekt gesagt, dass Sie es nicht schneiden und kuratieren möchten – Sie möchten das Ganze so, wie es ist, zum Nutzen Ihrer Leser neu veröffentlichen. Oder vielleicht haben Sie einen Gastbeitrag für eine andere Website oder einen anderen Blog geschrieben und möchten, dass Ihre eigenen Leser ihn sehen. Sie können dies tun, ohne den Duplicate-Content-Zorn von Google (u. a.) zu riskieren, indem Sie in den Metadaten des erneut veröffentlichten Artikels ein rel=canonical-Tag verwenden.
Sie können sich ein rel=canonical als eine URL-Richtung zu einer „kanonischen“ Seite vorstellen. Ein „Kanon“ ist ein grundlegendes Prinzip, ein akzeptierter Standard, die wesentliche Basis von etwas usw. Eine „kanonische“ Seite ist die wesentliche, ursprüngliche Quellseite; „rel=“ bedeutet „Beziehung“. rel=canonical bedeutet also im Wesentlichen „die kanonische Version dieser Seite ist unter dieser URL-Adresse zu finden“. (Detailliertere Informationen zu kanonischen Links finden Sie hier.)
Die meisten Webseiten haben bereits ein rel=canonical in ihren Metadatenfeldern. Der Standardwert ist normalerweise die URL der Webseite. Wenn Sie ein Content-Management-System verwenden, ist rel=canonical wahrscheinlich ein Standard-Tag und verwendet standardmäßig die eigene URL der Seite.
Kürzlich hat Ricky Bandelin von Industrial Quality Management einen guten Gastbeitrag zur Zustellbarkeit geschrieben, den wir im Marketing Action-Blog von Act-On veröffentlicht haben. So sieht das rel=canonical im Quellcode auf unserer Seite aus:

Ricky hat den Artikel auch auf seiner eigenen Seite veröffentlicht. Beachten Sie, dass, obwohl der größte Teil seines Quellcodes anders ist, rel=canonical dasselbe ist wie im Blog von Act-On. Es teilt Google (oder irgendeiner Suchmaschine) mit, dass sich der ursprüngliche Inhalt dort drüben unter dieser Act-On-URL befindet. Es verhält sich wie eine Art Weiterleitung für Google (et.al.).

Angenommen, jemand sucht nach Ente + Zustellbarkeit + E-Mail. Google kann sich beide Seiten ansehen und weiß, welche zurückgegeben werden soll. Die Webseite, die den Act-On-Blog anzeigt, wird dem Suchenden angezeigt, da sich an beiden Orten, an denen dieser Inhalt vorhanden ist, alle einig sind, dass die Act-On-Blog-Seite die kanonische Seite ist.
Um auf unser Beispiel der 600-Wörter-Biografie von Frau Dickens zurückzukommen:
Die URL der Seite von Site A lautet www.sitea.com/Dickens-third-wife-ran-coffee-shop. Das rel=canonical ist:
- <link rel=“canonical“ href=“https://sitea.com/Dickens-dritte-frau-ran-kaffeeladen/“ />
Die URL der Seite von Site B lautet www.siteb.com/Dickens-beloved-third-wife-Althea-ran-coffee-shop. Aber das rel=canonical ist jetzt dasselbe wie das von Site A:
- <link rel=“canonical“ href=“https://sitea.com/Dickens-dritte-frau-ran-kaffeeladen/“ />
Die Suchmaschinen wissen genau, welche Seite sie zurückgeben müssen; es gibt keine Probleme für sie. Und der Content-Vermarkter von Site B kann seinen Lesern großartige Inhalte ohne das Risiko von doppelten Inhalten zeigen. .
Richten Sie in einem Content-Management-System einen rel=canonical-Link ein
Sie müssen kein Code-Experte sein, um dies einzurichten. Wir verwenden einen Blogbeitrag als unser Beispiel.
Wenn Sie WordPress und Yoast verwenden:
1. Bereiten Sie Ihren Blogbeitragsentwurf in WordPress vor
2. Rufen Sie die Webseite des Beitrags oder Artikels auf, den Sie erneut veröffentlichen möchten. Kopieren Sie die URL
3. Gehen Sie zurück zu Ihrem Entwurf in Ihrer WordPress-App
4. Klicken Sie im SEO-Panel auf „Erweitert“.
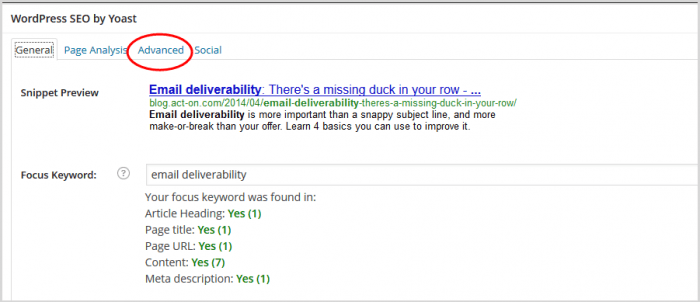 5. Scrollen Sie im sich öffnenden Fenster nach unten zum Feld für die kanonische URL.
5. Scrollen Sie im sich öffnenden Fenster nach unten zum Feld für die kanonische URL.
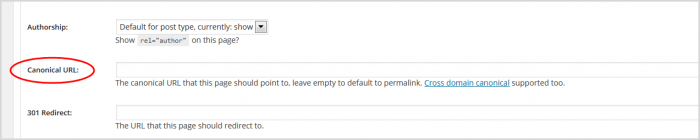
6. Geben Sie die kopierte URL ein. Das Yoast-Plug-in fügt das rel=-Bit für Sie hinzu
Für andere Content-Management-Systeme gibt es oft ein ähnliches rel=canonical-Feld oder ein Äquivalent.
Wenn es kein offensichtliches Feld gibt, können Sie im Quellcode Ihrer Seite einen rel=canonical-Link erstellen.
Richten Sie direkt im Quellcode ein rel=canonical ein
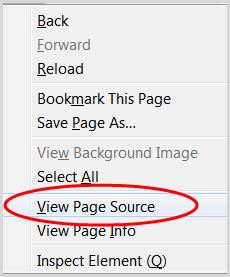 1. Richten Sie Ihren Blogbeitrag als Entwurf ein
1. Richten Sie Ihren Blogbeitrag als Entwurf ein
2. Gehen Sie zu der Seite mit den Inhalten, die Sie erneut veröffentlichen möchten
3. Klicken Sie mit der rechten Maustaste und wählen Sie „Seitenquelltext anzeigen“
4. Suchen Sie auf der Seite nach dem Meta-Tag rel=canonical
5. Kopieren Sie die gesamte Tag-Sequenz
Es sollte etwa so aussehen:
<link rel=“canonical“ href=“ https://www.was-immer-der-text-eigentlich-ist/ “ />
6. Ersetzen Sie Ihr eigenes rel=canonical-Tag durch das von Ihnen kopierte
Wenn Sie diesen Beitrag jetzt live schalten, teilen Ihre Metadaten Google mit, wo sich die kanonische Version dieser Seite befindet. Glückwunsch; Sie haben gerade eine Suchmaschine sehr glücklich gemacht. Und das ist gut so.
Weitere Informationen zu rel=canonical finden Sie in Googles Post „ 5 Common Mistakes with Rel=Canonical .“
Weitere Informationen zu grundlegendem SEO finden Sie unter SEO 101: The Basics and Beyond
NB: Das Foto zeigt eigentlich Catherine Hogarth Dickens, die einzige Frau von Charles Dickens.