
Zduplikowana treść, kuracja i – co to jest Rel=Canonical?
Opublikowany: 2014-05-19 To zimny, trudny świat dla wyszukiwarki. Ludzie proszą cię o przewodnictwo; skanujesz dla nich miliony stron, dajesz im najlepsze wyniki, jakie możesz znaleźć, a oni nigdy nie dziękują. Jesteś traktowany jak funkcjonariusz, ignorowany, dopóki nie będą cię znowu potrzebować. (Powąchać.)
To zimny, trudny świat dla wyszukiwarki. Ludzie proszą cię o przewodnictwo; skanujesz dla nich miliony stron, dajesz im najlepsze wyniki, jakie możesz znaleźć, a oni nigdy nie dziękują. Jesteś traktowany jak funkcjonariusz, ignorowany, dopóki nie będą cię znowu potrzebować. (Powąchać.)
Mimo to jest to świat, w którym silnik zjada silnik. Masz zadanie do wykonania i masz zamiar wykonać je najlepiej jak potrafisz. To wiele znaczy, gdy ludzie zwracają się do Ciebie zamiast innych i aby zachować ich zaufanie, musisz cały czas stawać się lepszy, wyprzedzać inne wyszukiwarki i dostarczać najsmaczniejsze wyniki.
Niektórzy marketerzy treści są dobrzy w optymalizacji, pomagając w tekście alternatywnym na zdjęciach, sensownej treści i metadanych, które sprawiają, że całkowicie jasne jest, o czym jest strona. Kiedy możesz dostarczyć dokładnie to, o co prosi poszukiwacz, jest to rodzaj elegancji, jak perfekcyjny wykonany piruet tancerza lub złapanie najlepszej fali we właściwym czasie. Niemal fizyczna przyjemność. Gdybyś miał ciało, chodziłbyś trochę wyższy.
Jesteś mistrzem w wykrywaniu niuansów między stronami. Niczym pies gończy węszysz w poszukiwaniu wąsów znaczeń, które pomogą ci oddzielić stronę A od strony A+. A dzięki treningowi i czasowi rozwinąłeś umiejętność częstego rozpoznawania, kiedy ktoś próbuje tobą manipulować. Kiedy odkryjesz, że ktoś oszukuje Twój system, masz kartę atutową do zagrania: możesz zrezygnować z wyświetlania tej witryny w wynikach wyszukiwania, aby nie mogła ponownie oszukać ani rozczarować gorliwego poszukiwacza.
Jest jeden problem, który marketerzy treści mogą rozwikłać dla ciebie i dla siebie, jeden problem często tworzony przez uczciwych ludzi, którzy chcą udostępniać dobre treści, co jak na ironię powoduje niepotrzebny problem: duplikaty treści . Dobra, powiemy o tym światu za Ciebie.
Dlaczego powielanie treści jest problemem
(Uwaga: Poniżej znajduje się duże uproszczenie duplikatów treści, pomyślane jako bardzo podstawowe informacje dla marketera, który tworzy treści. Jeśli jesteś aktywnym praktykiem SEO, istnieje wiele problemów z duplikatami treści (takich jak parametry adresów URL i identyfikatory sesji, itp.), których ten artykuł w ogóle nie dotyczy . Dla bardziej zaawansowanych polecamy przewodnik po najlepszych praktykach firmy Moz, „ Co to jest zduplikowana zawartość ?”
„Zduplikowana treść” to problem, który powstaje, gdy w jednej witrynie znajdują się dwie strony o takiej samej lub zbliżonej treści albo dwie (lub więcej) witryny zawierają stronę o praktycznie identycznej treści. Oto ilustracja tego rodzaju problemów, jakie powoduje:
 Witryna A opublikowała cudowną, liczącą 600 słów biografię trzeciej żony Karola Dickensa. Witryna B chciała udostępnić biografię swoim czytelnikom i poprosiła o pozwolenie na opublikowanie jej na blogu Witryny B. Pozwolenie udzielone. Witryna B opublikowała artykuł na swojej własnej stronie. Kopia była taka sama, ale post na blogu miał nieco inny tytuł, a jego adres URL był inny.
Witryna A opublikowała cudowną, liczącą 600 słów biografię trzeciej żony Karola Dickensa. Witryna B chciała udostępnić biografię swoim czytelnikom i poprosiła o pozwolenie na opublikowanie jej na blogu Witryny B. Pozwolenie udzielone. Witryna B opublikowała artykuł na swojej własnej stronie. Kopia była taka sama, ale post na blogu miał nieco inny tytuł, a jego adres URL był inny.
- Adres URL strony Witryny A to: www.sitea.com/Dickens-third-wife-ran-coffee-shop.
- Adres URL strony Witryny B to: www.siteb.com/ Dickens-beloved-third-wife-Althea-ran-coffee-shop.
Ty, drogi czytelniku, zapytaj swój telefon: „Kim była trzecia żona Karola Dickensa i co się z nią stało?”
Jeśli wyszukiwarka stwierdzi, że biografia składająca się z 600 słów jest najlepszą odpowiedzią na Twoje zapytanie, nie wie, czy wybrać stronę w witrynie A, czy w witrynie B do powrotu. Wyszukuje wszelkie różnice (być może autorytet witryny pomoże mu w podjęciu decyzji), ale zasadniczo jest w rozterce. Nie jest to dobre miejsce dla zapracowanej wyszukiwarki, aby się rozłączyła, a silnik będzie tym zirytowany.
Google i inne wyszukiwarki nie lubią duplikatów treści, ponieważ utrudnia to ich pracę i przeszkadza w uzyskiwaniu najlepszych wyników. (Zwracanie dobrych wyników to sposób, w jaki wyszukiwarki rosną i słabną w naszym upodobaniu, a więc w jaki sposób mogą pobierać opłaty za reklamy – jak żyją i umierają.) A kiedy znajdą zduplikowane treści na Twoich stronach, mają możliwość wyładowania tego niezadowolenia, ignorując Ciebie, przez co trudniej jest znaleźć Twoją witrynę internetową – poważnie utrudniając działania marketingu przychodzącego.
Ułatwienie wyszukiwarce znalezienia i oceny Twoich treści nazywa się „optymalizacją wyszukiwarek”. Nie ma wspólnego terminu na przeciwieństwo SEO, ale być może powinno być. (Sugestie mile widziane.)
Powielanie treści we własnych witrynach
Naprawa tego jest łatwa. Nigdy nie ma dobrego powodu do powielania treści we własnej witrynie. Każda strona powinna mieć swoją własną, niepowtarzalną historię do opowiedzenia, a dwie strony nie powinny opowiadać dokładnie tej samej historii. Załóżmy, że hodujesz i sprzedajesz yorkshire terriery, a Twoim celem jest skłonienie ludzi do wybrania yorka zamiast innej rasy. Potrzebujesz tylko jednej strony, która skupia się na sympatycznym usposobieniu rasy. O tym usposobieniu można wspomnieć na innych stronach, ale każda strona powinna mieć swój własny cel (jak trenować, czym karmić, długość życia, historia, jak kupować itp.). Te inne strony mogą wspominać o temperamencie i linkować do strony o usposobieniu; to dobra rzecz dla czytelnika, więc jest też dobra dla SEO.
Jeśli masz wiele witryn i masz zawartość, która byłaby dobra na wszystkich witrynach, możesz opublikować ją na nich wszystkich; czytaj dalej i zwróć szczególną uwagę na informację „rel=canonical” na końcu.
Powielanie przez farmy treści
Nadal często zdarza się, że „farmy treści” chwytają dobrą historię z sieci i obracają ją mechanicznie lub w inny sposób. Celem jest opowiedzenie tej samej historii (i uzyskanie takiej samej oceny treści), zmieniając się na tyle, aby wyszukiwarki nie rozpoznały jej jako zduplikowanej treści. Jest to forma plagiatu, technika czarnego kapelusza, a wyszukiwarki rzucą się, jeśli ją odkryją. (Brawo!) Jeśli zatrudniasz jakąś agencję do pomocy w tworzeniu treści, upewnij się, że nie przetwarza ona treści innych osób. Jeśli na Twojej stronie zostanie znaleziona wykręcona kopia, to Ty zapłacisz karę, bez względu na to, jak niewinnie ją kupiłeś lub kogo zatrudniłeś do jej stworzenia. (Poza tym: dobra treść kosztuje czas, pieniądze lub jedno i drugie; nie ma prawdziwych skrótów. Kupujący, uważaj.)
Kuracja nie powinna być powielaniem
Czasami znajdziesz historię, która jest tak mądra, użyteczna lub dobrze napisana, że chcesz się nią podzielić. Zawsze możesz zwrócić na to uwagę w tweecie lub poście na Facebooku (oczywiście przypisując go autorowi). Jeśli po prostu opublikujesz go ponownie, to niewinne udostępnienie może zacząć się jako forma uznania… ale zakończy się powieleniem treści. Jeśli chcesz nadzorować czyjeś treści, jest to mile widziana forma udostępniania, o ile robisz to poprawnie. (Niepisane) zasady to:

- Dziel się tylko tym, o czym wiesz, że Twoi czytelnicy docenią znalezienie.
- Nie publikuj ponownie całej historii. Wybierz fragmenty lub kilka akapitów.
- Podaj źródło oryginalnego autora lub witryny i umieść link do oryginalnej treści.
- Dołącz własną opinię. Mieć coś wyjątkowego do powiedzenia; to naprawdę będzie oznaczać, że twój utwór jest dziełem oryginalnym. Twoje własne słowa powinny stanowić większą część artykułu.
- To miłe i dobre maniery (jeśli nie zawsze jest to ściśle praktyczne lub konieczne), aby najpierw skontaktować się z autorem i dać mu znać, że opiekujesz się jego dziełem. Ludzie z pół miliona obserwujących lub felietoniści w głównych gazetach mogą nie odpowiadać, ale ludzie, którzy są dobrze znani w swoich dziedzinach (jeśli nie są osobami publicznymi) mogą, i często to docenią.
Pomyśl o tym jak o recenzji książki: zwiększasz wartość, zwracając uwagę na książkę, a także dodając wartość swoim komentarzem. Nie przedrukowujesz książki (ale umieszczasz link do niej, aby ludzie mogli ją łatwo znaleźć i przeczytać).
Co to jest rel=canonical? – i dlaczego powinno Cię to obchodzić
Prędzej czy później pojawi się artykuł lub post na blogu, który zasadniczo chcesz przedrukować w całości. Może ktoś właśnie powiedział coś tak doskonale, że nie chcesz tego wycinać i redagować – chcesz ponownie opublikować całość, tak jak jest, z korzyścią dla czytelników. A może napisałeś post gościnny dla innej witryny lub bloga i chcesz, aby Twoi czytelnicy go zobaczyli. Możesz to zrobić bez ryzyka gniewu Google (i innych) z powodu duplikatów treści , używając tagu rel=canonical w metadanych ponownie opublikowanego artykułu.
Możesz myśleć o rel=canonical jako o adresie URL do „kanonicznej” strony. „Kanon” to podstawowa zasada, przyjęty standard, podstawowa podstawa czegoś itp. Strona „kanoniczna” to podstawowa, oryginalna strona źródłowa; „rel=” oznacza „związek”. Tak więc rel=canonical zasadniczo oznacza „kanoniczną wersję tej strony można znaleźć pod tym adresem URL”. (Bardziej szczegółowe, ukryte informacje o linkach kanonicznych można znaleźć tutaj.)
Większość stron internetowych ma już rel=canonical w swoich polach metadanych. Wartością domyślną jest zwykle adres URL strony internetowej. Jeśli korzystasz z systemu zarządzania treścią, prawdopodobnie tag rel=canonical jest tagiem standardowym i domyślnie używa własnego adresu URL strony.
Niedawno Ricky Bandelin z Industrial Quality Management napisał dobry gościnny post na temat dostarczalności, który opublikowaliśmy na blogu Act-On's Marketing Action. Oto jak wygląda rel=canonical w kodzie źródłowym na naszej stronie:

Ricky opublikował artykuł również na swojej stronie. Zauważ, że chociaż większość jego kodu źródłowego jest inna, rel=canonical jest taki sam jak na blogu Act-On. Informuje Google (lub dowolną wyszukiwarkę), że oryginalna treść znajduje się pod tym adresem URL usługi Act-On. Zachowuje się jak rodzaj przekierowania dla Google (et.al.).

Załóżmy teraz, że ktoś wyszukuje frazę kaczka + dostarczalność + e-mail. Google może spojrzeć na obie strony i wiedzieć, którą zwrócić. Strona internetowa, na której jest wyświetlany blog Act-On, zostanie wyświetlona osobie wyszukującej, ponieważ w obu lokalizacjach, w których znajdują się te treści, wszyscy zgadzają się, że strona blogu Act-On jest stroną kanoniczną.
Wracając do naszego przykładu biografii pani Dickens na 600 słów:
Adres URL strony Witryny A to www.sitea.com/Dickens-trzecia-żona-ran-coffee-shop. Rel = kanoniczny to:
- <link rel=”canonical” href=”https://sitea.com/Dickens-third-wife-ran-coffee-shop/” />
Adres URL strony Witryny B to www.siteb.com/Dickens-beloved-third-wife-Althea-ran-coffee-shop. Ale rel=canonical jest teraz taki sam jak w witrynie A:
- <link rel=”canonical” href=”https://sitea.com/Dickens-third-wife-ran-coffee-shop/” />
Wyszukiwarki dokładnie wiedzą, którą stronę zwrócić; nie ma dla nich problemów. A sprzedawca treści w Witrynie B może pokazywać swoim czytelnikom świetne treści bez ryzyka powielania treści. .
Skonfiguruj łącze rel=canonical w systemie zarządzania treścią
Nie musisz być kreatorem kodu, aby to skonfigurować. Jako przykład użyjemy wpisu na blogu.
Jeśli korzystasz z WordPress i Yoast:
1. Przygotuj wersję roboczą posta na blogu w WordPress
2. Przejdź do strony internetowej wpisu lub artykułu, który chcesz ponownie opublikować; skopiuj adres URL
3. Wróć do wersji roboczej w aplikacji WordPress
4. Kliknij „Zaawansowane” w panelu SEO
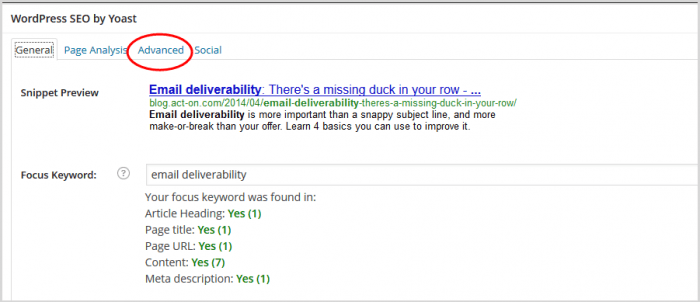 5. W panelu, który zostanie otwarty, przewiń w dół do pola kanonicznego adresu URL.
5. W panelu, który zostanie otwarty, przewiń w dół do pola kanonicznego adresu URL.
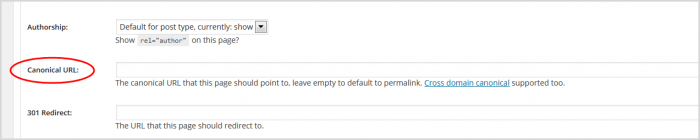
6. Wprowadź skopiowany adres URL. Wtyczka Yoast doda za Ciebie bit rel=
W przypadku innych systemów zarządzania treścią często występuje podobne pole rel=canonical lub jego odpowiednik.
Jeśli nie ma oczywistego pola, możesz utworzyć link rel=canonical w kodzie źródłowym swojej strony.
Skonfiguruj rel=canonical bezpośrednio w kodzie źródłowym
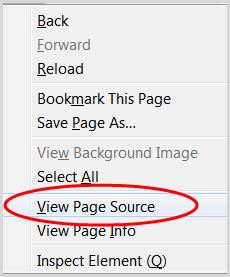 1. Skonfiguruj post na blogu jako wersję roboczą
1. Skonfiguruj post na blogu jako wersję roboczą
2. Przejdź do strony z treścią, którą chcesz ponownie opublikować
3. Kliknij prawym przyciskiem myszy i wybierz „Wyświetl źródło strony”
4. Poszukaj na stronie metatagu rel=canonical
5. Skopiuj całą sekwencję znaczników
Powinno to wyglądać mniej więcej tak:
<link rel=”canonical” href=” https://www.what-ever-the-text-actually-is/ “ />
6. Zastąp swój własny znacznik rel=canonical tym, który skopiowałeś
Teraz, gdy opublikujesz ten post, Twoje metadane poinformują Google, gdzie znajduje się kanoniczna wersja tej strony. Gratulacje; właśnie uszczęśliwiłeś wyszukiwarkę. I to jest dobra rzecz.
Aby uzyskać więcej informacji na temat rel=canonical, zobacz post Google „ 5 typowych błędów związanych z Rel=Canonical ”.
Aby uzyskać więcej informacji na temat podstawowego SEO, przeczytaj SEO 101: podstawy i nie tylko
Uwaga: Fotografia przedstawia w rzeczywistości Catherine Hogarth Dickens, jedyną żonę Charlesa Dickensa.