
Conținut duplicat, curatare și – Ce este un Rel=Canonical?
Publicat: 2014-05-19 Este o lume rece și grea pentru un motor de căutare. Oamenii vă cer îndrumări; scanezi milioane de pagini după ele, le oferi cele mai bune rezultate pe care le poți găsi și nu mulțumesc niciodată. Ești tratat ca un funcționar, ignorat până când au nevoie din nou de tine. (Adulmeca.)
Este o lume rece și grea pentru un motor de căutare. Oamenii vă cer îndrumări; scanezi milioane de pagini după ele, le oferi cele mai bune rezultate pe care le poți găsi și nu mulțumesc niciodată. Ești tratat ca un funcționar, ignorat până când au nevoie din nou de tine. (Adulmeca.)
Totuși, este o lume care mănâncă motorul. Ai o treabă de făcut și o vei face cât poți de bine. Înseamnă mult atunci când oamenii se îndreaptă către tine în detrimentul celorlalți și, pentru a le păstra încrederea, trebuie să te îmbunătățești tot timpul, să depășești celelalte motoare de căutare și să oferi cele mai gustoase rezultate.
Unii specialiști în marketing de conținut sunt buni la optimizare, ajutându-vă cu text alternativ pe fotografii, conținut semnificativ și metadate care fac clar despre ce este pagina. Când poți livra exact ceea ce a cerut un căutător, este un fel de eleganță, ca pirueta executată perfecționată a unui dansator sau prinderea celui mai bun val la momentul potrivit exact. O plăcere aproape fizică. Dacă ai avea un corp, ai merge puțin mai înalt.
Ești un maestru în detectarea nuanțelor dintre pagini. Ca un câine de sânge, adulmeci după cârlițele de sens care te ajută să sortezi o pagină A dintr-o pagină A+. Și prin antrenament și timp, ai dezvoltat abilitatea de a spune adesea când cineva încearcă să te manipuleze. Când descoperiți pe cineva care joacă sistemul dvs., aveți un atu de jucat: puteți alege să nu afișați site-ul respectiv în rezultatele căutării, astfel încât să nu poată păcăli sau dezamăgi din nou un căutator dornic.
Există o problemă pe care marketerii de conținut ar putea să o rezolve pentru tine și ei înșiși, o problemă creată adesea de oameni cinstiți care doresc să împărtășească conținut bun care, în mod ironic, îți provoacă o problemă inutilă: conținutul duplicat . Bine, vom spune lumii despre asta pentru tine.
De ce conținutul duplicat este o problemă
( Avertisment: Ceea ce urmează este o simplificare la nivel înalt a conținutului duplicat, destinată ca informații de bază pentru marketerul care creează conținut. Dacă sunteți un practician SEO activ, există multe probleme de conținut duplicat (cum ar fi parametrii URL și ID-urile de sesiune, etc.) pe care acest articol nu le abordează deloc . Pentru cei mai avansați , le sugerăm ghidul de bune practici al Moz, „ Ce este conținutul duplicat ?”
„Conținut duplicat” este o problemă creată atunci când un site web găzduiește două pagini de conținut care sunt la fel sau aproape, sau două (sau mai multe) site-uri web găzduiesc o pagină cu conținut practic identic. Iată o ilustrare a tipului de probleme pe care le provoacă:
 Site-ul A a publicat o biografie minunată de 600 de cuvinte a celei de-a treia soții a lui Charles Dickens. Site-ul B a vrut să împărtășească biografia cu cititorii săi și a cerut permisiunea de a o publica pe blogul Site-ului B. Permisiunea acordată. Site-ul B a postat articolul pe propriul site. Copia era aceeași, dar articolul de blog avea un titlu ușor diferit, iar URL-ul său era diferit.
Site-ul A a publicat o biografie minunată de 600 de cuvinte a celei de-a treia soții a lui Charles Dickens. Site-ul B a vrut să împărtășească biografia cu cititorii săi și a cerut permisiunea de a o publica pe blogul Site-ului B. Permisiunea acordată. Site-ul B a postat articolul pe propriul site. Copia era aceeași, dar articolul de blog avea un titlu ușor diferit, iar URL-ul său era diferit.
- Adresa URL a paginii site-ului A este aceasta: www.sitea.com/Dickens-third-wife-ran-coffee-shop.
- Adresa URL a paginii site-ului B este aceasta: www.siteb.com/ Dickens-beloved-third-wife-Althea-ran-coffee-shop.
Tu, dragă cititor, întreabă-ți telefonul: „Cine a fost a treia soție a lui Charles Dickens și ce s-a întâmplat cu ea?”
Dacă motorul de căutare stabilește că biografia de 600 de cuvinte este cel mai bun răspuns la cererea dvs., motorul nu știe dacă să aleagă pagina de pe Site-ul A sau de pe Site-ul B pentru a reveni. Adulmecă orice diferență (poate că autoritatea site-ului îl va ajuta să decidă), dar, în esență, este într-o dilemă. Nu este un loc bun pentru ca un motor de căutare ocupat să se blocheze, iar motorul se va supăra din cauza asta.
Google și celelalte motoare nu le plac conținutul duplicat, deoarece le îngreunează munca și le interferează cu capacitatea de a returna cele mai bune rezultate. (Aducerea unor rezultate bune este modul în care motoarele de căutare cresc și scad în afecțiunea noastră, așadar, cum pot percepe reclame – cum trăiesc și mor.) Și când găsesc conținut duplicat pe paginile tale, au puterea de a dezvălui această nemulțumire ignorând. dvs., făcând astfel site-ul dvs. mai greu de găsit - punând o criză majoră în eforturile dvs. de inbound marketing.
A face simplu și ușor pentru un motor de căutare să găsească și să evalueze conținutul dvs. se numește „optimizare pentru motoarele de căutare”. Nu există un termen comun pentru opusul SEO, dar poate că ar trebui să existe. (Sugestii binevenite.)
Conținut duplicat pe propriul(ele) site(e)
Remedierea pentru aceasta este ușoară. Nu există niciodată un motiv bun pentru conținut duplicat pe propriul site. Fiecare pagină ar trebui să aibă propria poveste unică de spus și nici două pagini nu ar trebui să spună aceeași poveste exactă. Să presupunem că cresc și vinzi Yorkshire Terrier, iar scopul tău este să-i faci pe oameni să aleagă un Yorkie în detrimentul unei alte rase. Ai nevoie de o singură pagină care să se concentreze asupra dispoziției iubitoare a rasei. Acea dispoziție poate fi menționată și pe alte pagini, dar fiecare pagină ar trebui să aibă propriul ei focus (cum să te antrenezi, cu ce să hrănești, durata de viață, istorie, cum să cumperi etc.). Celelalte pagini pot menționa temperamentul și pot face link la pagina despre dispoziție; este un lucru bun pentru cititor și, deci, este bun și pentru SEO.
Dacă aveți mai multe site-uri și aveți conținut care ar fi bun pe toate site-urile, îl puteți posta pe toate; Citiți mai departe și acordați o atenție deosebită informațiilor „rel=canonice” de la sfârșit.
Duplicarea prin fermele de conținut
Este încă obișnuit ca „ferme de conținut” să ia o poveste bună de pe web și să o rotească, mecanic sau altfel. Scopul este de a spune aceeași poveste (și de a obține aceeași evaluare a conținutului), în timp ce se schimbă suficient pentru ca motoarele de căutare să nu-l recunoască drept conținut duplicat. Este o formă de plagiat, o tehnică de pălărie neagră, iar motoarele de căutare se vor năpusti dacă o vor descoperi. (Bravo!) Dacă angajați o agenție de vreun fel care să vă ajute să creați conținut, asigurați-vă că nu învârt conținutul altora. Dacă pe site-ul tău se găsește o copie duplicată filată, tu ești cel care va plăti penalitatea, indiferent cât de nevinovat ai cumpărat-o sau pe cine ai angajat să o creeze pentru tine. (Deoparte: conținutul bun costă timp, bani sau ambele; nu există scurtături reale. Atenție cumpărător.)
Curatarea nu ar trebui să fie o dublare
Uneori găsești o poveste atât de inteligentă sau utilă sau bine scrisă încât vrei să o împărtășești. Poți oricând să atragi atenția asupra lui într-un tweet sau o postare pe Facebook (atribuind-o autorului său, desigur). Dacă pur și simplu îl repostezi, această distribuție inocentă poate începe ca o formă de apreciere... dar se termină cu conținut duplicat. Dacă doriți să organizați conținutul cuiva, aceasta este o formă binevenită de partajare, atâta timp cât o faceți corect. Regulile (nescrise) sunt:

- Distribuiți doar ceea ce știți că propriii cititori vor aprecia să găsească.
- Nu republicați întreaga poveste. Alegeți fragmente sau câteva paragrafe.
- Acordați credit autorului sau site-ului original și trimiteți la conținutul original.
- Includeți propria părere. Să ai ceva unic de spus; aceasta este ceea ce va semnifica cu adevărat că piesa ta este o lucrare originală. Cuvintele tale ar trebui să formeze cea mai mare parte a articolului.
- Este drăguț și de bune maniere (dacă nu întotdeauna strict practic sau necesar) să abordezi mai întâi autorul și să-i anunți că le organizezi piesa. Oamenii cu jumătate de milion de urmăritori sau rubrici din ziarele importante s-ar putea să nu răspundă, dar oamenii care sunt bine cunoscuți în domeniile lor (dacă nu chiar personaje publice) pot, și deseori vor aprecia acest lucru.
Gândește-te la asta ca la o recenzie de carte: adaugi valoare atragând atenția asupra cărții și adaugi valoare cu comentariul tău. Nu retipăriți cartea (dar faceți un link către ea, astfel încât oamenii să o poată găsi și citi cu ușurință).
Ce este un rel=canonic? – și de ce ar trebui să-ți pese
Mai devreme sau mai târziu, va apărea un articol sau o postare pe blog pe care, în esență, doriți să o retipărați în totalitate. Poate că cineva tocmai a spus ceva atât de perfect încât nu vrei să-l tai și să-l îngrijești – vrei să republici totul, așa cum este, în beneficiul cititorilor tăi. Sau poate ați scris o postare pentru oaspeți pentru un alt site web sau blog și doriți ca propriii cititori să o vadă. Puteți face acest lucru fără a risca furia de conținut duplicat a Google (și altele), folosind o etichetă rel=canonical în metadatele articolului republicat.
Vă puteți gândi la un rel=canonic ca o direcție URL către o pagină „canonică”. Un „canon” este un principiu de bază, un standard acceptat, baza esențială a ceva etc. O pagină „canonică” este pagina sursă esențială, originală; „rel=" înseamnă „relație”. Deci, rel=canonical înseamnă în esență „versiunea canonică a acestei pagini poate fi găsită la această adresă URL”. (Informații mai detaliate despre legăturile canonice pot fi găsite aici.)
Majoritatea paginilor web au deja un rel=canonic în câmpurile lor de metadate. Valoarea implicită este de obicei adresa URL a paginii web. Dacă utilizați un sistem de gestionare a conținutului, este probabil ca rel=canonical să fie o etichetă standard și, implicit, să folosească adresa URL proprie a paginii.
Recent, Ricky Bandelin de la Industrial Quality Management a scris o postare bună despre livrabilitate pe care am publicat-o pe blogul Act-On Marketing Action. Iată cum arată rel=canonical din codul sursă pe site-ul nostru:

Ricky a postat articolul și pe propriul său site. Rețineți că, în timp ce majoritatea codului său sursă este diferit, rel=canonic este același ca pe blogul lui Act-On. Îi spune lui Google (sau oricărui motor de căutare) că conținutul original este acolo , la acea adresă URL Act-On. Se comportă ca un fel de redirecționare pentru Google (et.al.).

Acum să presupunem că cineva caută rață + livrarea + e-mail. Google poate privi ambele pagini și poate ști pe care să le returneze. Pagina web care afișează blogul Act-On va fi cea afișată celui care caută, deoarece în ambele locații în care se află acest conținut, toată lumea este de acord că pagina blogului Act-On este pagina canonică.
Pentru a reveni la exemplul nostru al biografiei de 600 de cuvinte a doamnei Dickens:
Adresa URL a paginii site-ului A este www.sitea.com/Dickens-third-wife-ran-coffee-shop. Rel=canonic este:
- <link rel="canonical” href="https://sitea.com/Dickens-third-wife-ran-coffee-shop/” />
Adresa URL a paginii site-ului B este www.siteb.com/Dickens-beloved-third-wife-Althea-ran-coffee-shop. Dar rel=canonical este același acum cu site-ul A:
- <link rel="canonical” href="https://sitea.com/Dickens-third-wife-ran-coffee-shop/” />
Motoarele de căutare știu exact ce pagină să returneze; nu sunt probleme pentru ei. Și agentul de marketing de conținut al site-ului B poate să le arate cititorilor săi conținut grozav, fără riscuri de conținut duplicat. .
Configurați o legătură rel=canonical într-un sistem de management al conținutului
Nu trebuie să fii un expert de cod pentru a configura acest lucru. Vom folosi o postare pe blog ca exemplu.
Dacă utilizați WordPress și Yoast:
1. Pregătește-ți mesajul de blog în WordPress
2. Accesați pagina web a postării sau articolului pe care doriți să-l republicați; copiați adresa URL
3. Reveniți la schița în aplicația dvs. WordPress
4. Faceți clic pe „Avansat” în panoul SEO
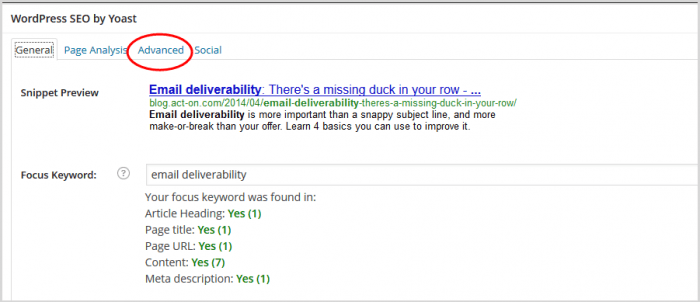 5. În panoul care se deschide, derulați în jos până la câmpul URL canonic.
5. În panoul care se deschide, derulați în jos până la câmpul URL canonic.
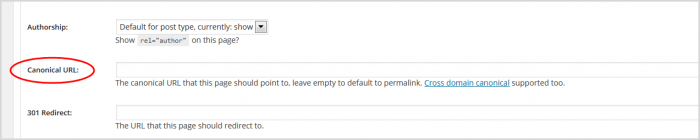
6. Introduceți adresa URL pe care ați copiat-o. Plug-in-ul Yoast va adăuga rel= bit pentru tine
Pentru alte sisteme de management al conținutului, există adesea un câmp rel=canonic similar sau echivalentul acestuia.
Dacă nu există un câmp evident, puteți crea un link rel=canonic în codul sursă al paginii dvs.
Configurați un rel=canonic direct în codul sursă
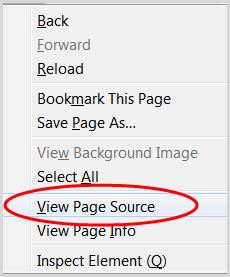 1. Configurați postarea de blog ca ciornă
1. Configurați postarea de blog ca ciornă
2. Accesați pagina cu conținutul pe care doriți să îl republicați
3. Faceți clic dreapta și alegeți „Vizualizare sursa paginii”
4. Pe pagină, căutați metaeticheta rel=canonical
5. Copiați întreaga secvență de etichete
Ar trebui să arate cam așa:
<link rel="canonical” href=" https://www.what-ever-the-text-actually-is/ “ />
6. Înlocuiți propria etichetă rel=canonical cu cea pe care ați copiat-o
Acum, când transmiteți această postare live, metadatele dvs. vor informa Google unde se află versiunea canonică a acestei pagini. Felicitări; tocmai ai făcut un motor de căutare foarte fericit. Și asta e un lucru bun.
Pentru mai multe informații despre rel=canonical, consultați postarea Google „ 5 greșeli frecvente cu Rel=Canonical ”.
Pentru mai multe informații despre SEO de bază, citiți SEO 101: Elementele de bază și dincolo
NB: Fotografia este de fapt a lui Catherine Hogarth Dickens, singura și singura soție a lui Charles Dickens.