
Contenuto duplicato, cura e – Cos'è un Rel=Canonical?
Pubblicato: 2014-05-19 È un mondo freddo e duro per un motore di ricerca. Le persone ti chiedono una guida; scannerizzi milioni di pagine per loro, dai loro i migliori risultati che riesci a trovare e loro non dicono mai grazie. Sei trattato come un funzionario, ignorato finché non hanno di nuovo bisogno di te. (Annusare.)
È un mondo freddo e duro per un motore di ricerca. Le persone ti chiedono una guida; scannerizzi milioni di pagine per loro, dai loro i migliori risultati che riesci a trovare e loro non dicono mai grazie. Sei trattato come un funzionario, ignorato finché non hanno di nuovo bisogno di te. (Annusare.)
Tuttavia, è un mondo in cui il motore mangia motore. Hai un lavoro da fare e lo farai nel miglior modo possibile. Significa molto quando le persone si rivolgono a te piuttosto che agli altri e, per mantenere la loro fiducia, devi continuare a migliorare continuamente, superare gli altri motori di ricerca e fornire i risultati più gustosi.
Alcuni marketer di contenuti sono bravi nell'ottimizzazione, aiutandoti con testo alternativo su foto, contenuti significativi e metadati che rendono completamente chiaro di cosa tratta la pagina. Quando riesci a fornire esattamente ciò che un ricercatore ha chiesto, è una sorta di eleganza, come la perfetta piroetta eseguita da un ballerino o la cattura dell'onda migliore di sempre al momento giusto. Un piacere quasi fisico. Se tu avessi un corpo, cammineresti un po' più in alto.
Sei un maestro nel rilevare le sfumature tra le pagine. Come un segugio, annusi i viticci di significato che ti aiutano a ordinare una pagina A da una pagina A +. E attraverso l'allenamento e il tempo, hai sviluppato la capacità di capire spesso quando qualcuno sta cercando di manipolarti. Quando scopri qualcuno che gioca con il tuo sistema, hai una carta vincente da giocare: puoi scegliere di non visualizzare quel sito nei risultati di ricerca, in modo che non possa ingannare o deludere di nuovo un ricercatore desideroso.
C'è un intoppo che i marketer di contenuti potrebbero svelare per te e per se stessi, un problema spesso creato da persone oneste che desiderano condividere buoni contenuti che ironicamente ti causa un problema inutile: contenuti duplicati . Ok, lo diremo al mondo per te.
Perché i contenuti duplicati sono un problema
(Avvertenza: ciò che segue è una semplificazione di alto livello dei contenuti duplicati, intesi come informazioni di base per il marketer che crea contenuti. Se sei un professionista SEO attivo, ci sono molti problemi di contenuti duplicati (come parametri URL e ID di sessione, ecc.) che questo articolo non affronta affatto . Per i più avanzati , suggeriamo la guida alle migliori pratiche di Moz , " Che cos'è il contenuto duplicato ?"
Il "contenuto duplicato" è un problema che si crea quando un sito Web ospita due pagine di contenuto uguali o quasi, o due (o più) siti Web ospitano una pagina di contenuto praticamente identico. Ecco un'illustrazione del tipo di problemi che provoca:
 Il sito A ha pubblicato una bella biografia di 600 parole della terza moglie di Charles Dickens. Site B ha voluto condividere la biografia con i suoi lettori e ha chiesto il permesso di pubblicarla sul blog di Site B. Permesso accordato. Il sito B ha pubblicato l'articolo sul proprio sito. La copia era la stessa, ma il post sul blog aveva un titolo leggermente diverso e il suo URL era diverso.
Il sito A ha pubblicato una bella biografia di 600 parole della terza moglie di Charles Dickens. Site B ha voluto condividere la biografia con i suoi lettori e ha chiesto il permesso di pubblicarla sul blog di Site B. Permesso accordato. Il sito B ha pubblicato l'articolo sul proprio sito. La copia era la stessa, ma il post sul blog aveva un titolo leggermente diverso e il suo URL era diverso.
- L'URL della pagina del sito A è questo: www.sitea.com/Dickens-hird-wife-ran-coffee-shop.
- L'URL della pagina del sito B è questo: www.siteb.com/Dickens-beloved-hird-wife-Althea-ran-coffee-shop.
Tu, caro lettore, chiedi al tuo telefono: "Chi era la terza moglie di Charles Dickens e cosa le è successo?"
Se il motore di ricerca determina che la biografia di 600 parole è la migliore risposta alla tua richiesta, il motore non sa se scegliere la pagina sul sito A o sul sito B per tornare. Annusa eventuali differenze (forse l'autorità del sito lo aiuterà a decidere), ma essenzialmente è in imbarazzo. Non è un buon posto per un motore di ricerca occupato per rimanere bloccato, e il motore si arrabbierà per questo.
A Google e agli altri motori non piacciono i contenuti duplicati perché rendono più difficile il loro lavoro e interferiscono con la loro capacità di restituire i migliori risultati. (Restituire buoni risultati è il modo in cui i motori di ricerca aumentano e diminuiscono nel nostro affetto, ergo come possono addebitare la pubblicità - come vivono e muoiono.) E quando trovano contenuti duplicati sulle tue pagine, hanno il potere di sfogare questo dispiacere ignorando te, rendendo così il tuo sito web più difficile da trovare, mettendo a dura prova i tuoi sforzi di marketing in entrata.
Rendere semplice e facile per un motore di ricerca trovare e valutare i tuoi contenuti si chiama "ottimizzazione per i motori di ricerca". Non esiste un termine comune per l'opposto di SEO, ma forse dovrebbe esserci. (Suggerimenti ben accetti.)
Contenuti duplicati sui tuoi siti
La soluzione per questo è facile. Non c'è mai una buona ragione per duplicare i contenuti sul tuo sito. Ogni pagina dovrebbe avere la sua storia unica da raccontare, e due pagine non dovrebbero raccontare la stessa identica storia. Supponi di allevare e vendere Yorkshire terrier e il tuo obiettivo è convincere le persone a scegliere uno Yorkie rispetto a un'altra razza. Hai bisogno solo di una pagina che si concentri sulla disposizione amabile della razza. Tale disposizione può essere menzionata in altre pagine, ma ogni pagina dovrebbe avere il proprio focus (come allenarsi, cosa nutrire, durata della vita, storia, come acquistare, ecc.). Quelle altre pagine possono menzionare il temperamento e collegarsi alla pagina sulla disposizione; questa è una buona cosa per il lettore, e quindi anche per la SEO.
Se hai più siti e hai contenuti che andrebbero bene su tutti i siti, puoi pubblicarli su tutti; continua a leggere e presta particolare attenzione alle informazioni "rel=canonical" alla fine.
Duplicazione per content farm
È ancora comune per le "content farm" prendere una buona storia dal web e farla girare, meccanicamente o in altro modo. L'obiettivo è raccontare la stessa storia (e ottenere la stessa valutazione del contenuto) cambiando quel tanto che basta in modo che i motori di ricerca non lo riconoscano come contenuto duplicato. È una forma di plagio, una tecnica black-hat, e i motori di ricerca si avventeranno se la scoprono. (Bravo!) Se stai assumendo un'agenzia di qualche tipo per aiutarti a creare contenuti, assicurati che non stiano girando il contenuto di altri. Se sul tuo sito viene trovata una copia duplicata, sarai tu a pagare la penalità, non importa quanto innocentemente l'hai acquistata o chi hai assunto per crearla per te. (A parte: un buon contenuto costa tempo, o denaro, o entrambi; non ci sono vere scorciatoie. Attenzione dell'acquirente.)
La cura non dovrebbe essere una duplicazione
A volte trovi una storia così intelligente o utile o ben scritta che vuoi condividerla. Puoi sempre richiamare l'attenzione su di esso in un tweet o in un post su Facebook (attribuendolo al suo autore, ovviamente). Se lo ripubblichi semplicemente, questa condivisione innocente può iniziare come una forma di apprezzamento... ma finire con un contenuto duplicato. Se vuoi curare i contenuti di qualcuno, questa è una gradita forma di condivisione purché tu lo faccia correttamente. Le regole (non scritte) sono:

- Condividi solo ciò che sai che i tuoi lettori apprezzeranno trovare.
- Non ripubblicare l'intera storia. Scegli frammenti o alcuni paragrafi.
- Dai credito all'autore o al sito originale e collega al contenuto originale.
- Includi la tua opinione. Avere qualcosa di unico da dire; questo è ciò che significherà davvero che il tuo pezzo è un'opera originale. Le tue stesse parole dovrebbero costituire la maggior parte dell'articolo.
- È carino e buone maniere (se non sempre strettamente pratico o necessario) toccare prima la base con l'autore e fargli sapere che stai curando il suo pezzo. Le persone con mezzo milione di follower o colonne sui principali giornali potrebbero non rispondere, ma le persone che sono ben note nei loro campi (se non esattamente personaggi pubblici) possono, e spesso lo apprezzeranno.
Pensala come una recensione di un libro: stai aggiungendo valore attirando l'attenzione sul libro e stai aggiungendo valore con il tuo commento. Non stai ristampando il libro (ma ti colleghi ad esso in modo che le persone possano trovarlo e leggerlo facilmente).
Cos'è un rel=canonical? – e perché dovrebbe interessarti
Prima o poi ci sarà un articolo o un post sul blog che vorrai sostanzialmente ristampare in toto. Forse qualcuno ha appena detto qualcosa in modo così perfetto che non vuoi tagliarlo e curarlo - vuoi ripubblicare tutto, così com'è, a beneficio dei tuoi lettori. O forse hai scritto un guest post per un altro sito web o blog e vuoi che i tuoi lettori lo vedano. Puoi farlo senza rischiare l'ira del contenuto duplicato di Google (et alia) utilizzando un tag rel=canonical nei metadati dell'articolo ripubblicato.
Puoi pensare a rel=canonical come a una direzione URL verso una pagina "canonica". Un “canone” è un principio fondamentale, uno standard accettato, la base essenziale di qualcosa, ecc. Una pagina “canonica” è la pagina sorgente essenziale, originale; "rel=" significa "relazione". Quindi, rel=canonical significa essenzialmente "la versione canonica di questa pagina si trova a questo indirizzo URL". (Informazioni più dettagliate sui collegamenti canonici possono essere trovate qui.)
La maggior parte delle pagine Web ha già un rel=canonical nei campi dei metadati. L'impostazione predefinita è in genere l'URL della pagina web. Se utilizzi un sistema di gestione dei contenuti, è probabile che rel=canonical sia un tag standard e per impostazione predefinita utilizzi l'URL della pagina.
Recentemente Ricky Bandelin di Industrial Quality Management ha scritto un buon guest post sulla deliverability che abbiamo pubblicato nel blog Marketing Action di Act-On. Ecco come appare rel=canonical nel codice sorgente sul nostro sito:

Anche Ricky ha pubblicato l'articolo sul suo sito. Nota che mentre la maggior parte del suo codice sorgente è diverso, rel=canonical è lo stesso del blog di Act-On. Sta dicendo a Google (o qualsiasi motore di ricerca) che il contenuto originale è laggiù , in quell'URL di azione. Si comporta come una sorta di reindirizzamento per Google (et.al.).

Supponiamo ora che qualcuno cerchi duck + deliverability + email. Google può esaminare entrambe le pagine e sapere quale restituire. La pagina web che mostra il blog di Act-On sarà quella mostrata al ricercatore perché in entrambi i luoghi in cui si trova questo contenuto, tutti concordano sul fatto che la pagina del blog di Act-On sia la pagina canonica.
Per tornare al nostro esempio della biografia di 600 parole della signora Dickens:
L'URL della pagina del sito A è www.sitea.com/Dickens-hird-wife-ran-coffee-shop. Il rel=canonico è:
- <link rel=”canonical” href=”https://sitea.com/Dickens-third-wife-ran-coffee-shop/” />
L'URL della pagina del sito B è www.siteb.com/Dickens-beloved-hird-wife-Althea-ran-coffee-shop. Ma il rel=canonical ora è lo stesso del sito A:
- <link rel=”canonical” href=”https://sitea.com/Dickens-third-wife-ran-coffee-shop/” />
I motori di ricerca sanno esattamente quale pagina restituire; non ci sono problemi per loro. E il content marketer del sito B può mostrare ai propri lettori ottimi contenuti senza il rischio di contenuti duplicati. .
Imposta un collegamento rel=canonical in un sistema di gestione dei contenuti
Non devi essere un mago del codice per configurarlo. Useremo un post sul blog come esempio.
Se usi WordPress e Yoast:
1. Prepara la tua bozza di post sul blog in WordPress
2. Vai alla pagina web del post o dell'articolo che desideri ripubblicare; copia l'URL
3. Torna alla bozza nella tua app WordPress
4. Fai clic su "Avanzate" nel pannello SEO
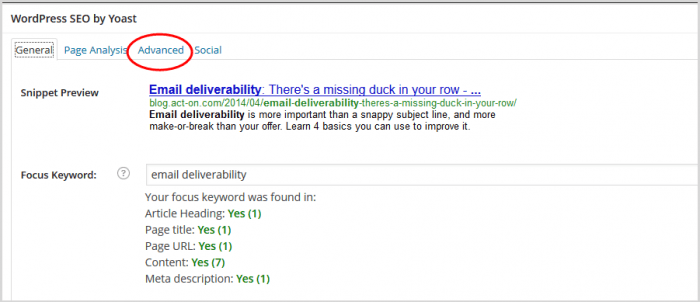 5. Nel pannello che si apre, scorri verso il basso fino al campo URL canonico.
5. Nel pannello che si apre, scorri verso il basso fino al campo URL canonico.
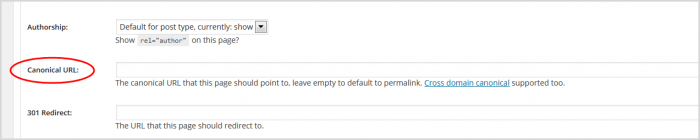
6. Inserisci l'URL che hai copiato. Il plug-in Yoast aggiungerà il bit rel= per te
Per altri sistemi di gestione dei contenuti, esiste spesso un campo rel=canonical simile o un suo equivalente.
Se non c'è un campo ovvio, puoi creare un link rel=canonical nel codice sorgente della tua pagina.
Imposta un rel=canonical direttamente nel codice sorgente
 1. Imposta il tuo post sul blog come bozza
1. Imposta il tuo post sul blog come bozza
2. Vai alla pagina con il contenuto che desideri ripubblicare
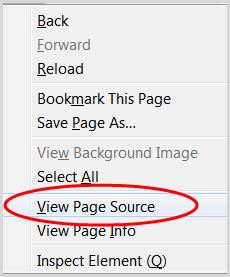
3. Fai clic con il pulsante destro del mouse e scegli "Visualizza sorgente pagina"
4. Nella pagina, cerca il meta tag rel=canonical
5. Copiare l'intera sequenza di tag
Dovrebbe assomigliare molto a questo:
<link rel=”canonical” href=” https://www.what-ever-the-text-actually-is/ “ />
6. Sostituisci il tuo tag rel=canonical con quello che hai copiato
Ora, quando pubblichi questo post, i tuoi metadati faranno sapere a Google dove si trova la versione canonica di questa pagina. Congratulazioni; hai appena reso molto felice un motore di ricerca. E questa è una buona cosa.
Per ulteriori informazioni su rel=canonical, vedere il post di Google " 5 errori comuni con Rel=Canonical ".
Per ulteriori informazioni sulla SEO di base, leggi SEO 101: The Basics and Beyond
NB: La fotografia è in realtà di Catherine Hogarth Dickens, l'unica moglie di Charles Dickens.