
Призыв к большей науке в SEO
Опубликовано: 2022-04-17- Неприятный сюрприз: это была просто ошибка!
- Итак, в чем проблема во всем этом?
- Что сотрудники узнали о сбое?
- Почему бы не сделать такие анализы?
- Что такое гипотеза и как ее правильно сформулировать?
Вы, наверное, уже слышали, но для тех из вас, кто не следит за каждым шагом Google, вот краткое изложение:
В начале августа резко увеличились колебания результатов поиска в Google — по всему миру и на всех языках. На форумах веб-мастеров и обычных форумах Black Hat сразу же появились слухи о выпуске масштабного необъявленного обновления. Колебания и изменения в списках результатов поиска были настолько велики, что несколько крупных порталов SEO в США сообщили о самом большом обновлении за всю историю.
На самом деле, все инструменты SEO и средства проверки ранжирования внезапно подверглись массовым изменениям в результатах поиска Google. Результаты поиска не только изменились; они переворачивались с ног на голову, иногда с абсурдными результатами, занимая верхние позиции.
Вы можете очень четко увидеть последствия ошибки в ежедневном индексе видимости:
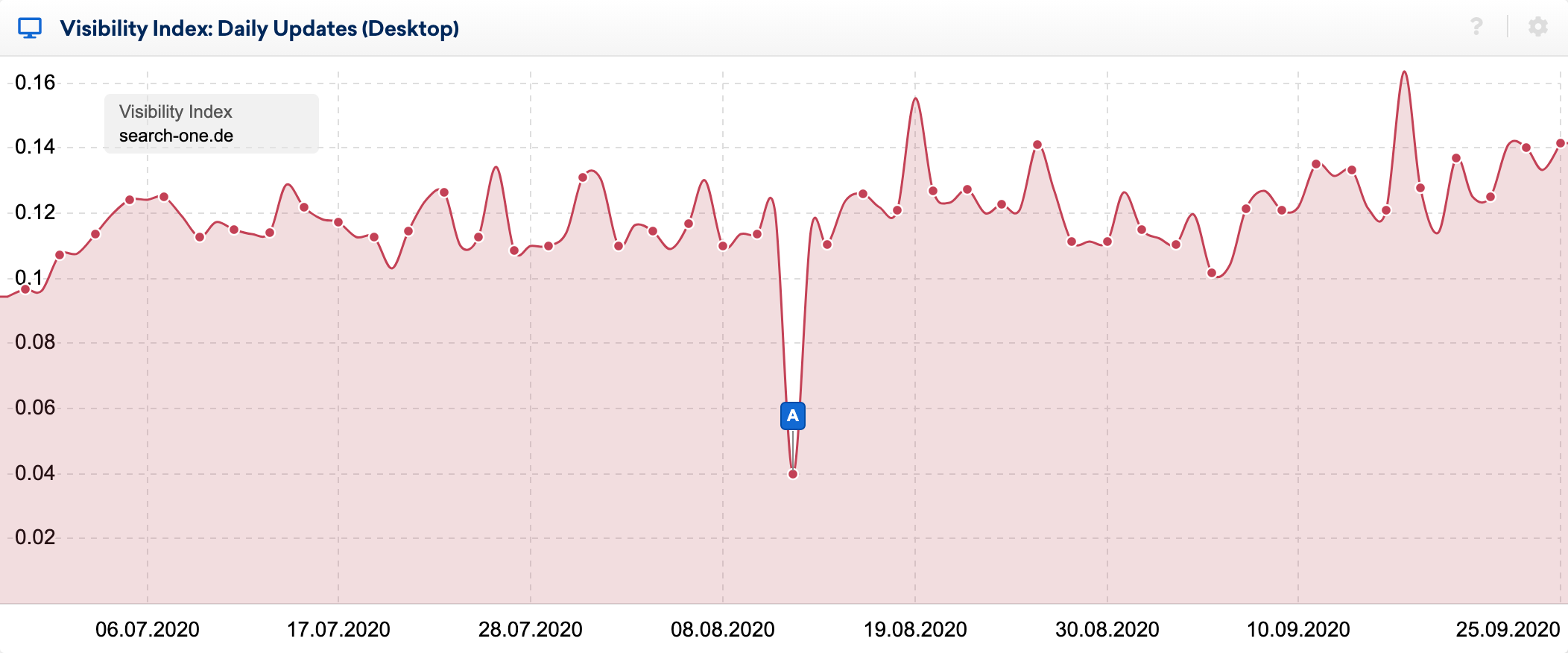
Используя отличную функцию сравнения SERP в наборе инструментов SISTRIX, я внимательно изучил изменения в топ-20 некоторых ключевых слов, за рейтингом которых я наблюдал в течение многих лет. Я провел десятки анализов ранжируемых веб-сайтов по этим ключевым словам и обычно относительно хорошо знаю, почему URL ранжируется там, где он есть.
Если вы посмотрите на сравнение поисковой выдачи по ключевому слову «оптимизация Google» в рассматриваемое время, вы увидите, что все топ-20, за исключением одного URL, полностью изменились. То, что раньше было на 1 -м месте, опустилось на 8 -е место, а остальные URL-адреса появились из ниоткуда, то есть из-за пределов топ-20 на верхние места.
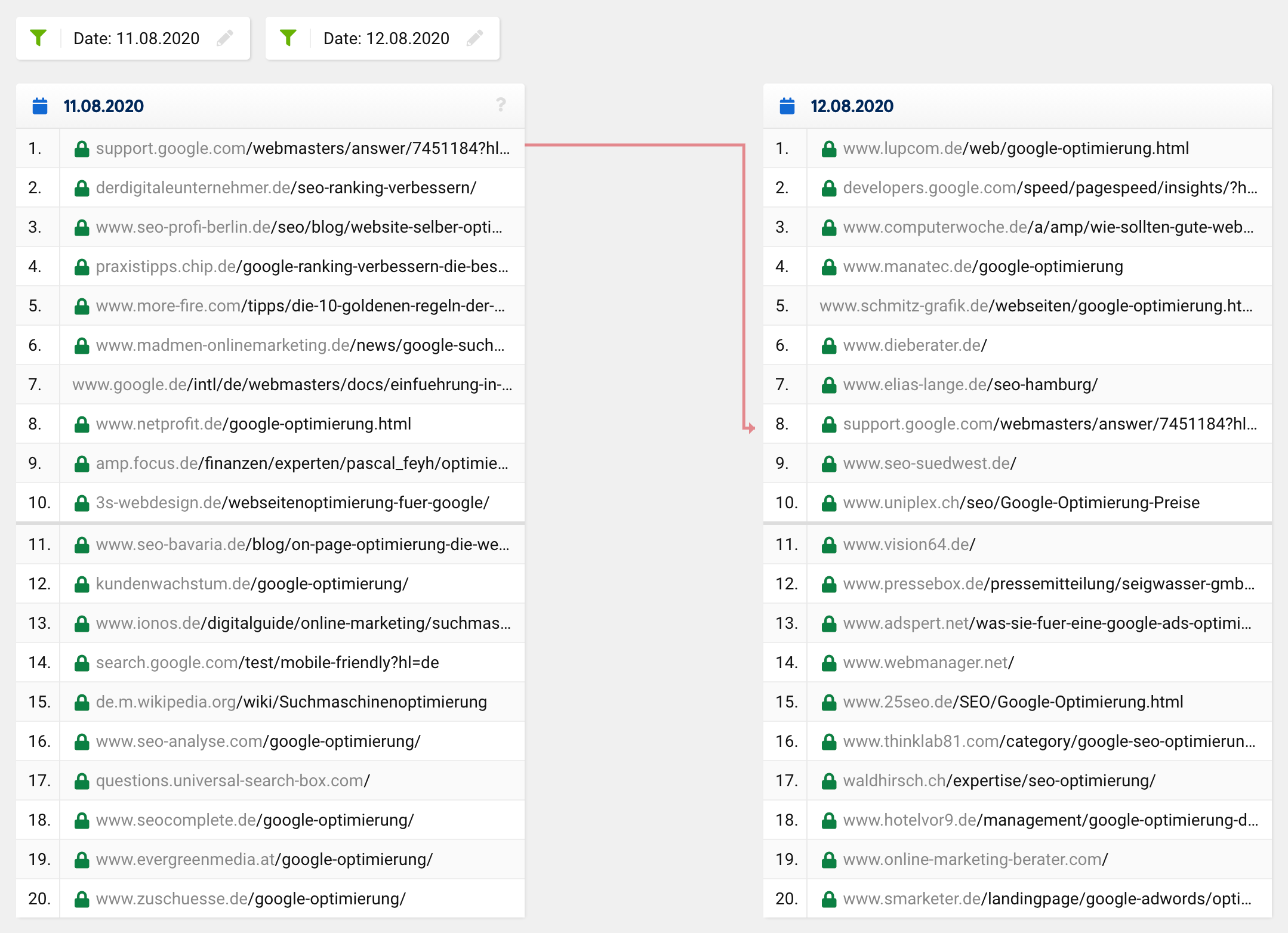
Обычное обновление или регулярное изменение рейтинга обычно выглядит примерно так:

Многие URL-адреса остаются прежними, в то время как некоторые URL-адреса перемещаются вверх, а другие - вниз. Конечно, иногда URL-адрес исчезает из топ-20 или перемещается в него. Однако невероятно редко из 20 попаданий в «новых» топ-20 остается только одно — так было по всем направлениям, а не только по одному конкретному ключевому слову.
С учетом таких далеко идущих изменений, подобных пресловутым фантомным обновлениям, можно было бы ожидать корректировку предполагаемого пользовательского намерения поискового запроса, что затем привело бы к кардинальным изменениям в составе топ-20 по некоторым ключевым словам. Однако в таком случае результаты поиска улучшались, т. е. становились более релевантными и значимыми, чего явно не произошло с этим глюком.
Подавляющее большинство SEO-специалистов были удивлены явно абсурдными результатами поиска и относительно быстро предположили, что произошла ошибка — или, по крайней мере, надеялись, что это временная проблема. Я чувствовал то же самое, когда некоторые из моих веб-сайтов полностью потеряли свои самые важные позиции в рейтинге всего за несколько часов!
Неприятный сюрприз: это была просто ошибка!
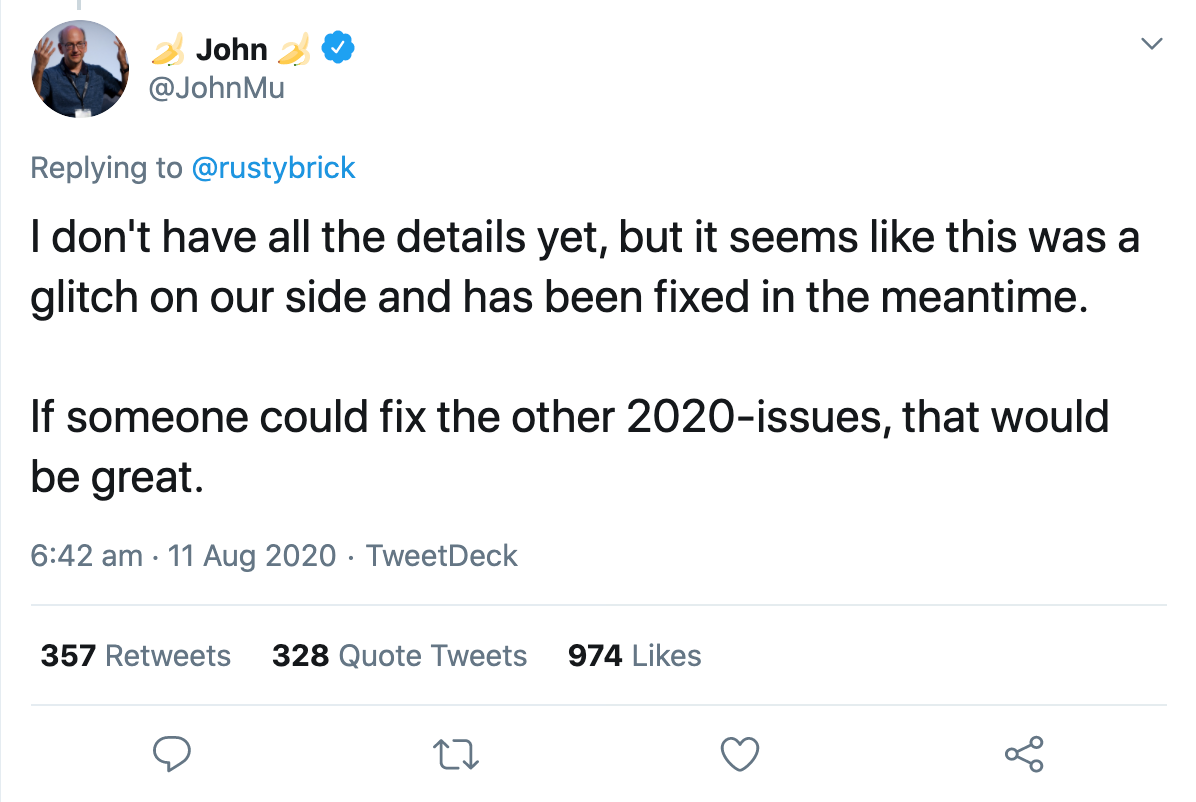
Той же ночью представитель Google подтвердил, что они исправили ошибку. Через несколько часов все нормализовалось. Джон Мюллер подтвердил в Твиттере, что ошибка была исправлена, но пока не знает всех подробностей:
Всего через день официальная учетная запись Google для веб-мастеров подтвердила, что на результаты поиска повлияла очевидная проблема с системой индексации.
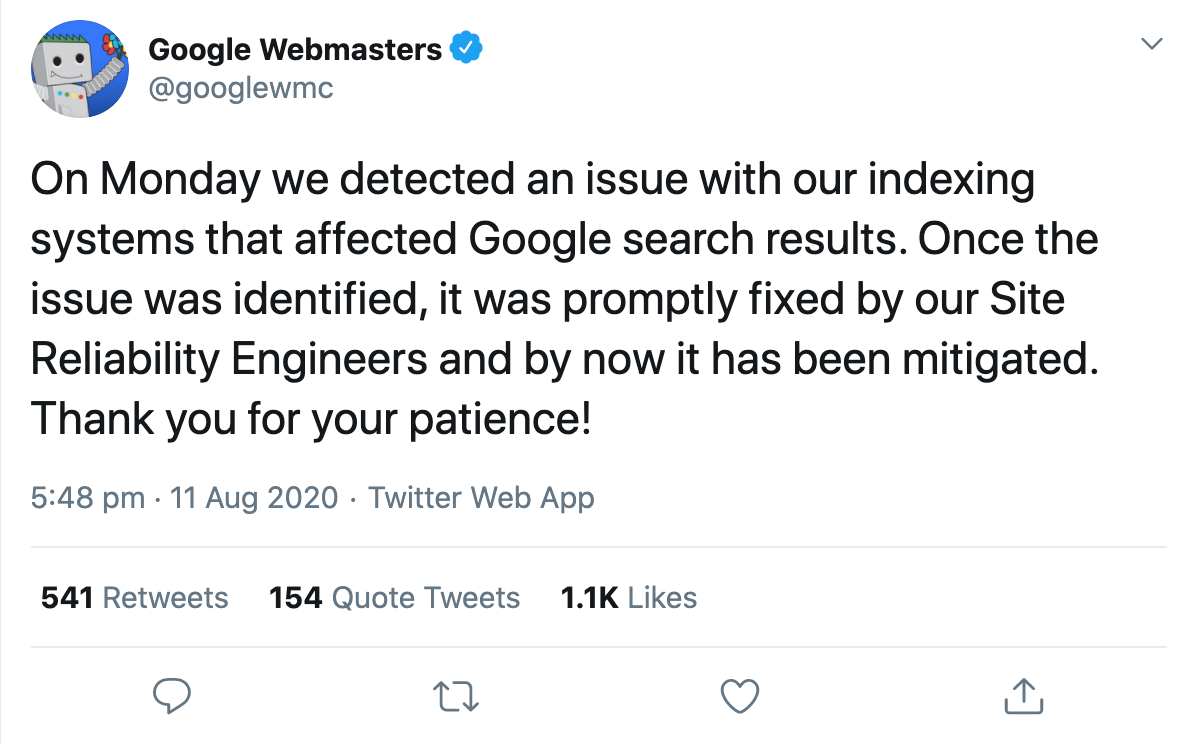
И тут люди начали строить догадки о том, что именно могло произойти.
Гэри Иллиес попытался сделать вещи немного более конкретными, описав, что на самом деле делает система индексации Caffeine. Согласно его сообщению, он принимает журналы выборки, обрабатывает и преобразует извлеченные данные, извлекает ссылки, метаданные и структурированные данные, извлекает и вычисляет некоторые неназванные сигналы, планирует новые обходы и строит индекс, который передается для обслуживания. Чтобы это было легче понять, он привел несколько примеров того, что может пойти не так, что затем будет отражено в измененных результатах поиска:
«Если планирование сканирования пойдет не так, сканирование может замедлиться. Если рендеринг пойдет не так, Google может неправильно понять страницы. Если построение индекса пойдет плохо, это может повлиять на ранжирование и обслуживание».
Затем он подчеркнул, насколько сложен поиск и что тысячи взаимосвязанных систем должны безупречно работать вместе, чтобы предоставлять релевантные результаты пользователям. Если в механизм брошена песчинка, результатом будет такой же сбой, как и вчера.
На вопрос пользователя Twitter он уточнил, что, по-видимому, произошла ошибка при построении самого индекса:
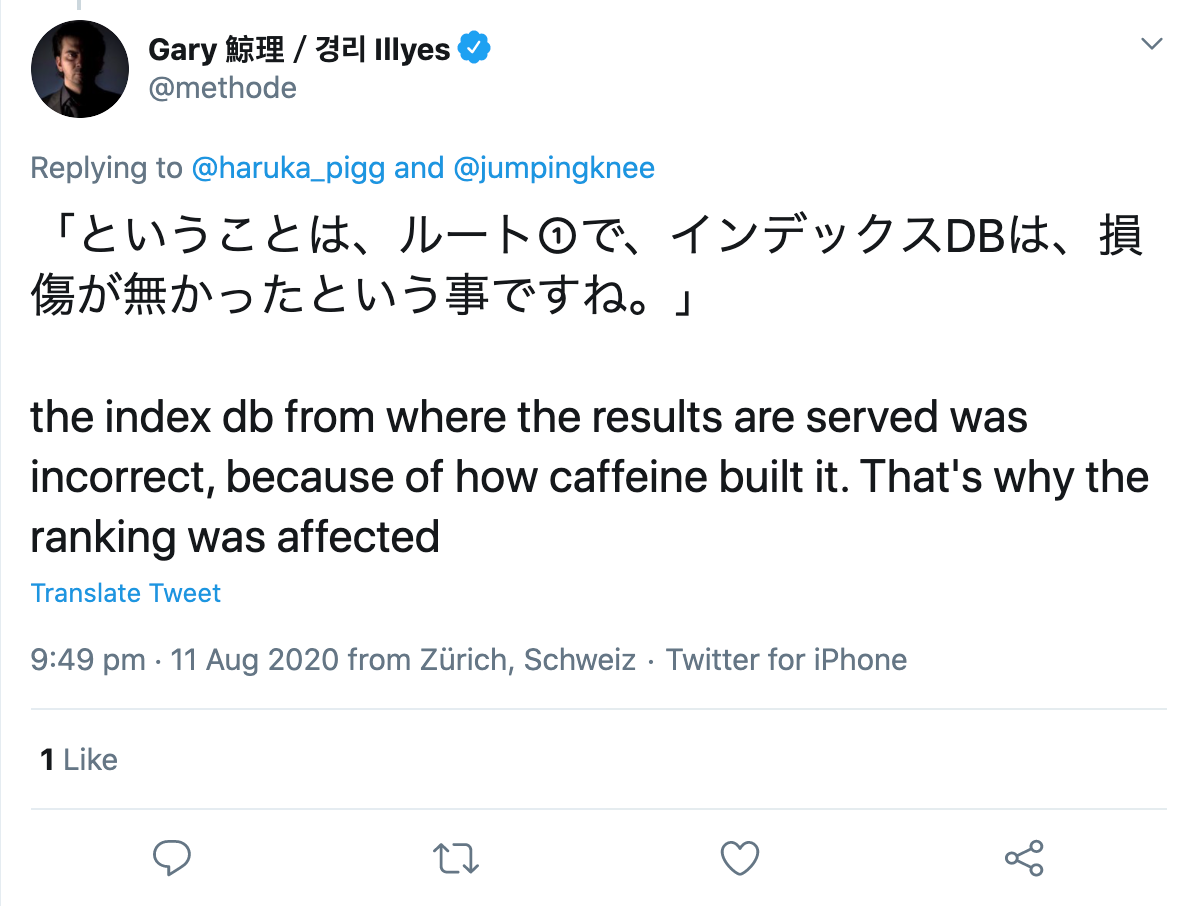
Итак, в чем проблема во всем этом?
Сама ошибка меня не раздражала, так как Google исправила ее всего за несколько часов. Однако некоторые комментарии и публикации по этому поводу впоследствии меня сильно разозлили.

Хотя Google раскрыл проблему относительно прозрачно, некоторые SEO-специалисты пытались всеми правдами и неправдами разобраться в баге и начали изучать изменения в поисках закономерностей. Сотрудник известного американского SEO-агентства, которого я не хочу сейчас раскрывать, начал анализировать данные Google Analytics по каждому текущему и бывшему клиенту и попытался сделать выводы о причине изменения рейтинга.
Я считаю это переходом черты по нескольким причинам, но об этом позже.
Что сотрудники узнали о сбое?
В случае регулярных обновлений Google все подстраницы домена обычно затрагиваются изменением, как положительным, так и отрицательным. Этого не произошло с текущим сбоем, потому что в то время как некоторые подстраницы одного и того же домена понесли огромные убытки, другие выиграли, а некоторые почти не изменились, если вообще изменились.
Таким образом, их первое понимание заключалось в том, что это не было похоже на типичное обновление Google. Все идет нормально.
Теперь это становится несколько авантюрным:
«Многие страницы, которые поднялись выше в рейтинге, содержали медицинскую информацию, которая противоречила научному консенсусу. Для уточнения здесь делается ссылка на Руководство Google Quality Rater, в котором говорится, что при определении EAT страницы на научную тематику он должен создаваться людьми или организациями, обладающими опытом в соответствующей области, и должен отражать установленный научный консенсус. где он существует».
Это утверждение «доказывается» наблюдением, что несколько медицинских статей, которые явно противоречат состоянию науки, а также имеют плохие или неестественные обратные ссылки, внезапно стали ранжироваться намного лучше, чем до и после ошибки.
Их теория состоит в том, что страницы, которые должны быть обесценены из-за проблем с качеством, на самом деле ранжируются хорошо. Например, взломанные страницы, страницы с неестественными ссылками или страницы с утверждениями, отклоняющимися от общепринятого научного консенсуса, были бы выброшены на первые позиции.
Отсюда автор делает следующий вывод:
Если рейтинг страницы улучшается, это может быть поводом для радости, а может быть, это просто
тест для будущего обновления, которое пошло не так. Или это может быть признаком проблемы с качеством веб-сайта, которая ограничивала ранжирование страницы, но, возможно, не играла роли во время ошибки.
С другой стороны, если страница опустилась в рейтинге, это может означать, что вас обогнали низкокачественные страницы или страницы со спамом, которые в настоящее время снова понижены алгоритмами Google.
Уффз! Действительно? Какая польза от этого понимания для моей повседневной работы по SEO?!
Почему бы не сделать такие анализы?
Помимо того, что они все еще имеют доступ и используют данные Google Analytics бывших клиентов, я вижу здесь гораздо большую проблему с подходом сотрудника:
Проблема в том, что если вы ищете закономерности без гипотезы, вы всегда что-то найдете. Если вы затем примете этот результат без дальнейшего тестирования за верный, он не имеет ничего общего с наукой.
Всегда есть закономерности, иногда случайные, иногда вызванные одним или несколькими факторами. Вы не можете сначала искать закономерности, а затем разрабатывать теорию, объясняющую то, что вы наблюдаете, и после этого принимать это как реальность. Это просто не то, как работает знание.
Мне бы очень хотелось, чтобы в SEO использовалось больше научных методов, например, когда дело доходит до выдвижения гипотез и их последующей проверки!
Что такое гипотеза и как ее правильно сформулировать?
Гипотеза – это разумное предположение, которое делается в начале эмпирического исследования. Это предположение анализируется с использованием качественных или количественных методов, а затем подтверждается или опровергается.
Выдвигая гипотезу, вы либо предполагаете корреляцию, либо отсутствие корреляции между двумя переменными . Независимая переменная — причина, зависимая переменная — возможное следствие.
Существует два основных типа гипотез: направленные и ненаправленные.
В случае ненаправленной гипотезы вы просто предполагаете наличие некоторой корреляции между двумя переменными. Например, количество связанных веб-сайтов влияет на видимость домена.
С другой стороны, при направленной гипотезе оценивается предполагаемая корреляция. Например: чем больше обратных ссылок у статьи, тем лучше она ранжируется.
Однако для того, чтобы выдвинуть гипотезу, следует учитывать следующие критерии:
- Обе используемые переменные должны быть измеримыми.
- Гипотезы должны быть сформулированы объективно и лаконично.
- Если сформулировано несколько гипотез, они не должны противоречить друг другу.
- И: Научные предположения должны быть опровергнуты.
Поскольку большинство предположений в области SEO не могут быть опровергнуты экспериментом, нет никаких доказательств, о которых можно было бы говорить с научной точки зрения. Точно так же не следует анализировать результаты каких-либо поисковых запросов, чтобы делать выводы об используемых факторах ранжирования.
Осознание того, что корреляция не равна причинности, к счастью, стало общепринятым в последние годы. Сегодня опытные оптимизаторы больше не воспринимают всерьез исследования факторов ранжирования любого поставщика инструментов, а это означает, что все меньше и меньше таких исследований проводится и публикуется.