
Un appel à plus de science dans le SEO
Publié: 2022-04-17- Une mauvaise surprise : c'était juste une erreur !
- Alors, où est le problème dans tout ça ?
- Qu'est-ce que le ou les employés ont découvert sur le problème ?
- Pourquoi ne pas effectuer de telles analyses ?
- Qu'est-ce qu'une hypothèse et comment la formuler correctement ?
Vous en avez probablement déjà entendu parler, mais pour ceux d'entre vous qui ne suivent pas toutes les étapes de Google, voici un résumé :
Début août, il y a eu une augmentation massive de la fluctuation des résultats de recherche sur Google - dans le monde entier et dans toutes les langues. Dans les forums Webmaster et les forums Black Hat habituels, il y a eu des spéculations immédiates sur le déploiement d'une mise à jour massive non annoncée. Les fluctuations et les changements dans les listes de résultats de recherche étaient si énormes que plusieurs grands portails SEO aux États-Unis ont signalé la plus grande mise à jour jamais réalisée.
En fait, tous les outils de référencement et les vérificateurs de classement ont été soudainement touchés par des changements massifs dans les résultats de recherche de Google. Les résultats de la recherche ont non seulement changé ; ils se sont retournés, parfois avec des résultats absurdes remplissant les premières positions.
Vous pouvez voir très clairement les effets du bug dans l'indice de visibilité quotidien :
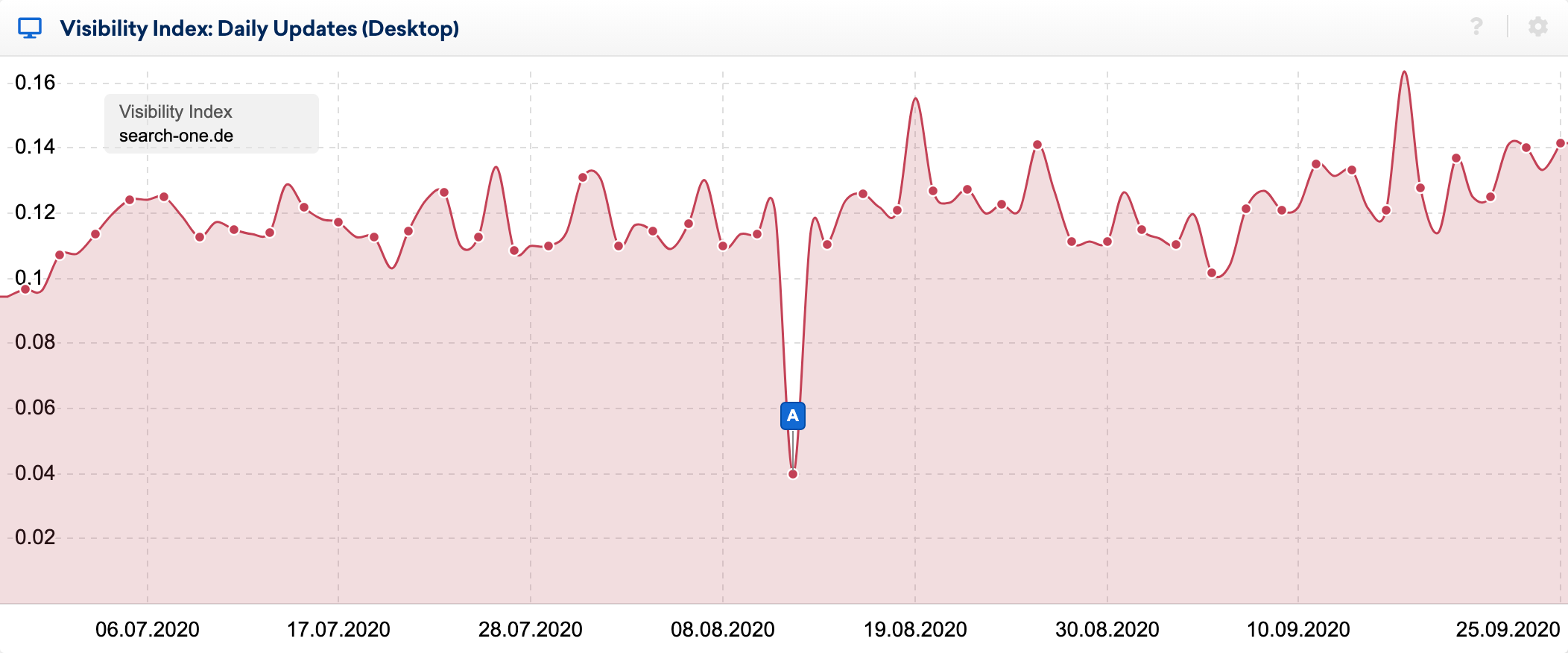
En utilisant l'excellente fonction de comparaison SERP de la boîte à outils SISTRIX, j'ai examiné de plus près les changements dans le top 20 de certains mots-clés, dont j'observe le classement depuis de nombreuses années. J'ai effectué des dizaines d'analyses des sites Web classés pour ces mots clés et je sais généralement relativement bien pourquoi une URL se classe là où elle se classe.
Si vous jetez un coup d'œil à la comparaison SERP pour le mot-clé "google optimisation" à l'époque en question, vous verrez que l'ensemble du top 20, à l'exception d'une URL, a complètement changé. Ce qui était auparavant à la 1 ère place est passé à la 8 ème place, les URL restantes sortant de nulle part, c'est-à-dire de l'extérieur du top 20 vers les premières places.
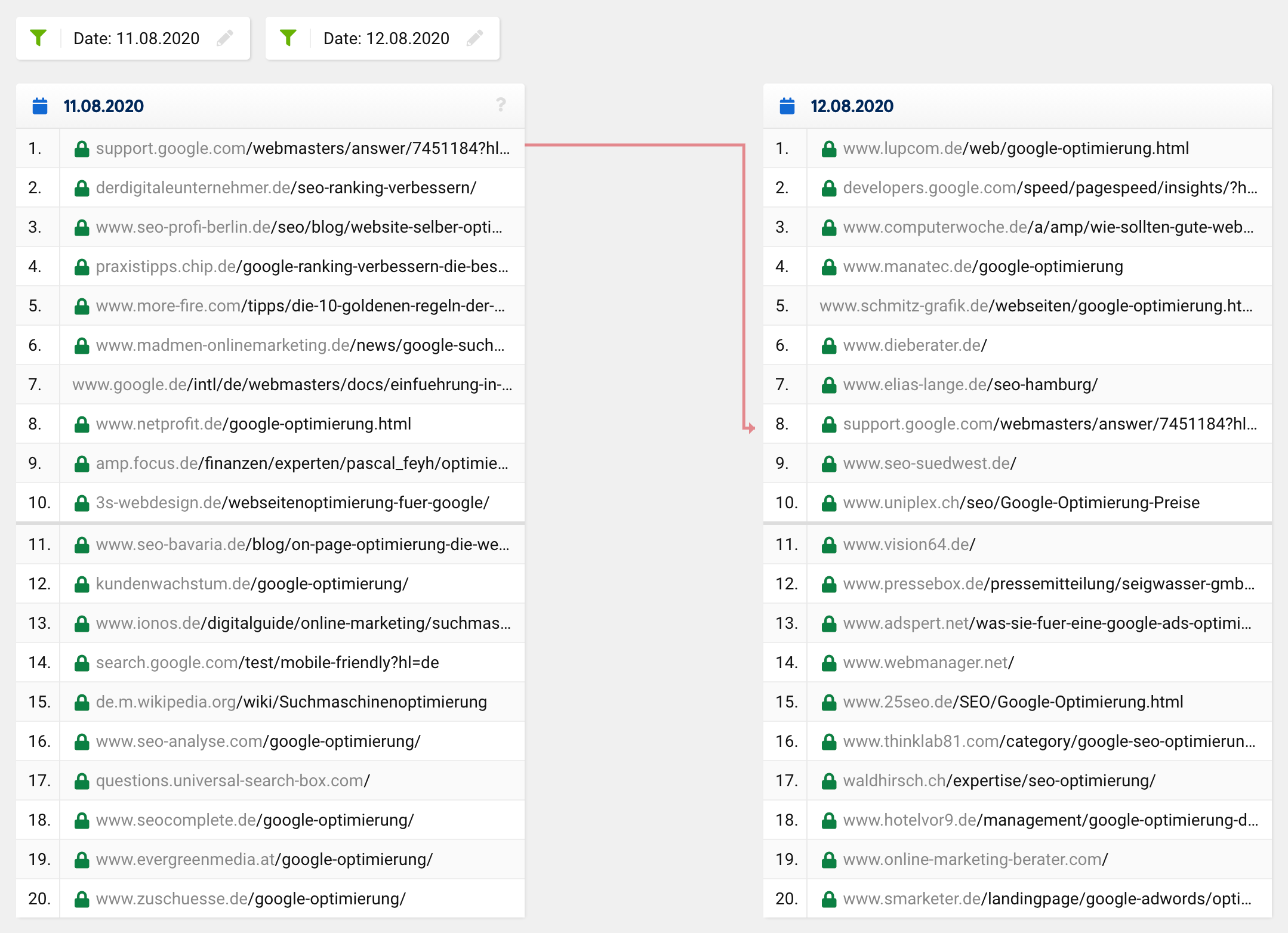
Une mise à jour normale ou un changement de classement régulier ressemblerait normalement plus à ceci :

De nombreuses URL restent les mêmes, tandis que certaines URL montent et d'autres descendent. Bien sûr, il arrive parfois qu'une URL disparaisse du top 20 ou y monte. Cependant, il est extrêmement rare que sur 20 résultats, il n'en reste qu'un seul dans le "nouveau" top 20 - c'était le cas dans tous les domaines, pas seulement pour un mot-clé spécifique.
Compte tenu de changements aussi profonds similaires aux mises à jour fantômes notoires, vous vous attendriez à voir un ajustement dans l'intention supposée de l'utilisateur d'une requête de recherche, ce qui entraînerait alors des changements fondamentaux dans la composition du top 20 pour certains mots-clés. Dans un tel cas, cependant, les résultats de la recherche s'amélioreraient, c'est-à-dire deviendraient plus pertinents et significatifs, ce qui n'était évidemment pas ce qui s'est produit avec ce bug.
La grande majorité des référenceurs ont été surpris par les résultats de recherche manifestement absurdes et ont assez rapidement supposé qu'il y avait une erreur - ou du moins espéraient qu'il ne s'agissait que d'un problème temporaire. J'ai ressenti la même chose, car certains de mes sites Web ont complètement perdu leur classement le plus important en l'espace de quelques heures !
Une mauvaise surprise : c'était juste une erreur !
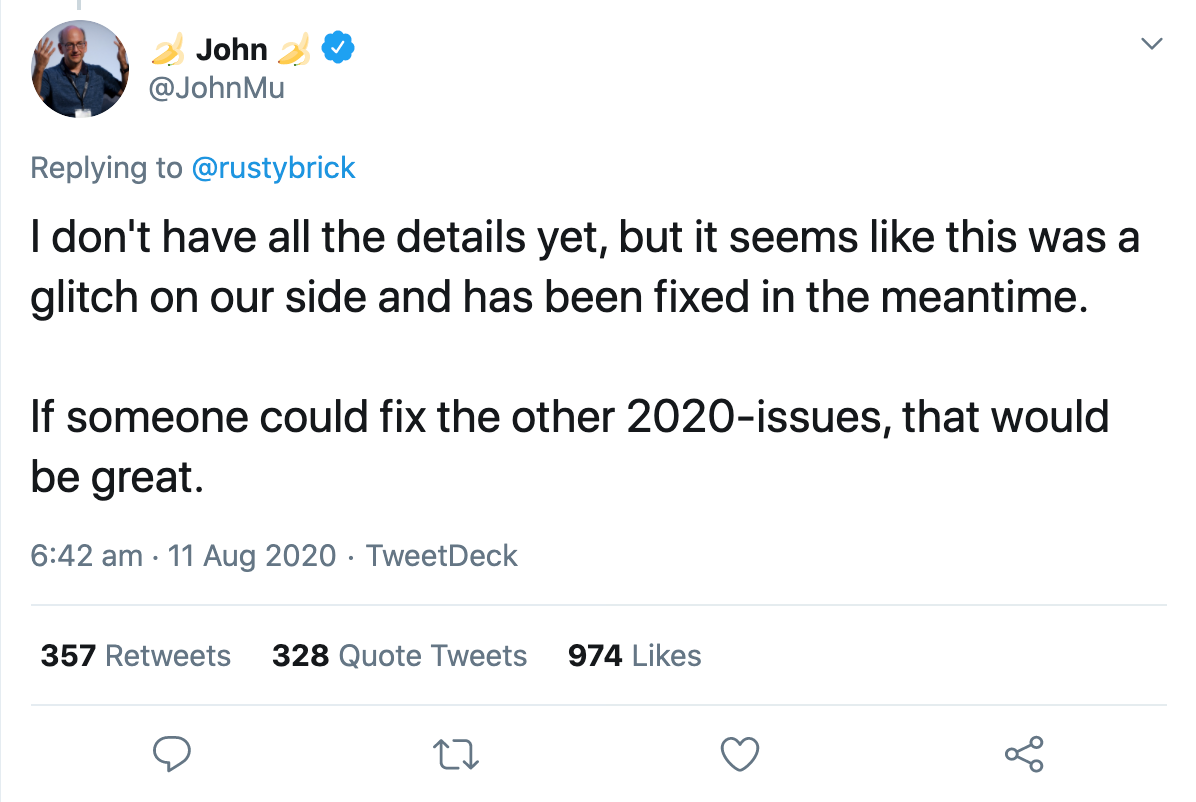
Le même soir, un porte-parole de Google a confirmé qu'il s'agissait d'un bogue qu'ils corrigeaient. En quelques heures, tout était revenu à la normale. John Muller a confirmé via Twitter que le bug avait été corrigé, mais qu'il n'avait pas encore tous les détails :
Juste un jour plus tard, le compte officiel Google Webmaster a confirmé que les résultats de recherche avaient été affectés par un problème apparent avec le système d'indexation.
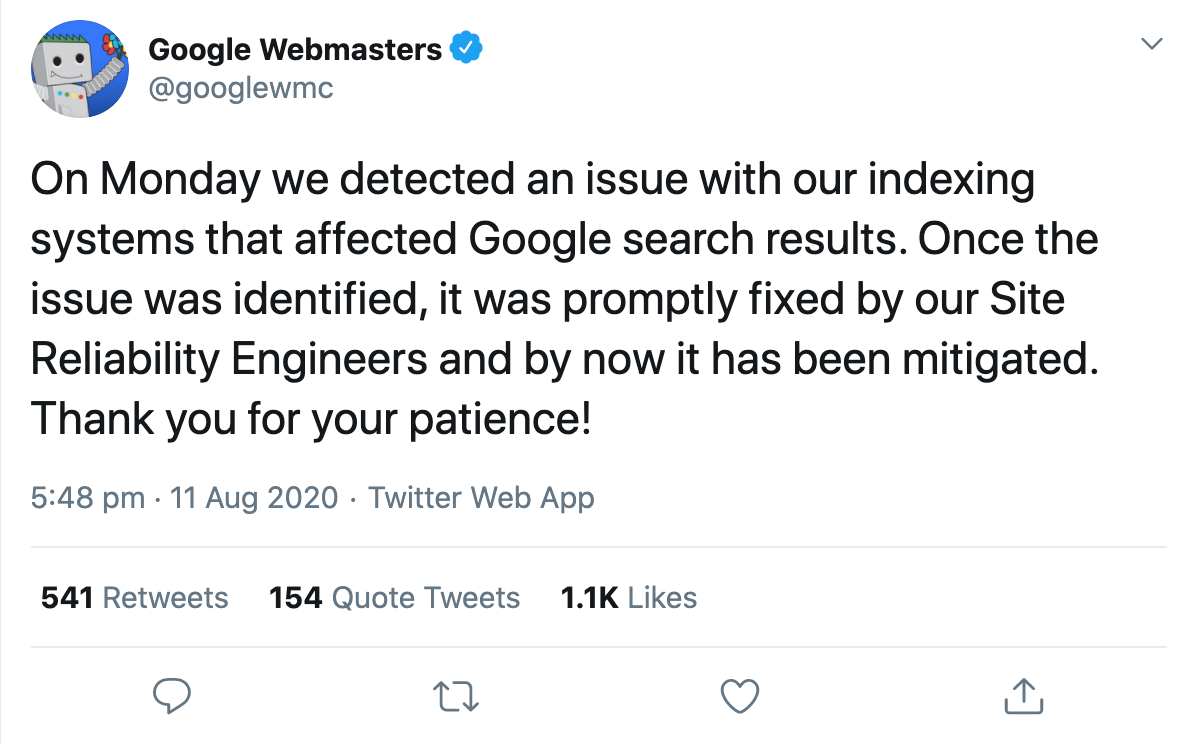
Et c'est là que les gens ont commencé à spéculer sur ce qui aurait pu se passer exactement.
Gary Illyes a essayé de rendre les choses un peu plus concrètes en décrivant ce que fait réellement le système d'indexation, Caffeine. Selon son tweet, il ingère des journaux de récupération, restitue et convertit les données récupérées, extrait des liens, des métadonnées et des données structurées, extrait et calcule des signaux sans nom, planifie de nouveaux crawls et construit l'index qui est mis en service. Pour faciliter la compréhension, il a donné quelques exemples de ce qui pourrait mal tourner, ce qui se refléterait ensuite dans les résultats de recherche modifiés :
"Si la planification des crawls tourne mal, le crawl peut ralentir. Si le rendu se passe mal, Google peut mal comprendre les pages. Si la construction de l'index tourne mal, le classement et la diffusion peuvent être affectés. »
Il a ensuite souligné à quel point la recherche est complexe et que des milliers de systèmes interconnectés doivent fonctionner ensemble sans faille pour fournir des résultats pertinents aux utilisateurs. Si un grain de sable était jeté dans la machinerie, le résultat serait une panne comme hier.
Interrogé par un utilisateur de Twitter, il a précisé qu'il y avait apparemment eu une erreur dans la construction de l'index lui-même :

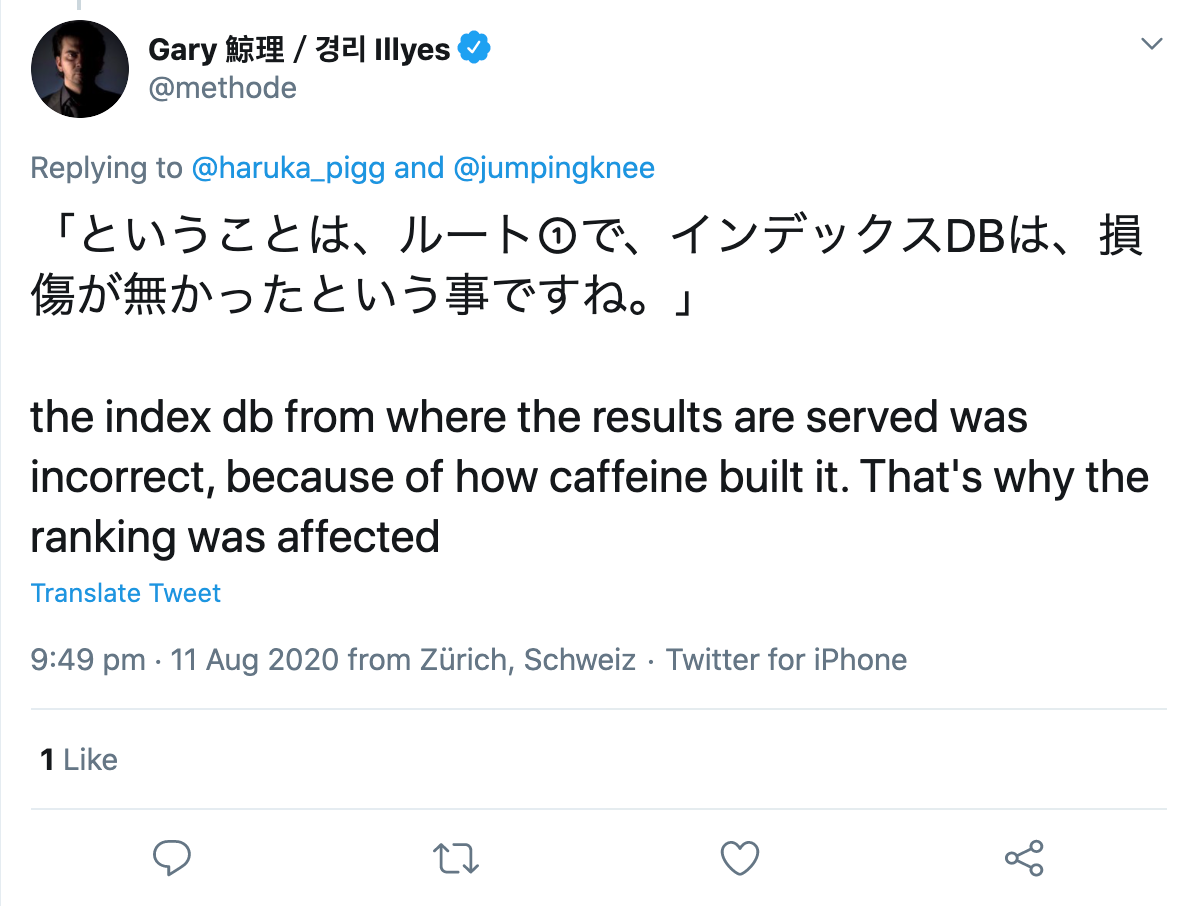
Alors, où est le problème dans tout ça ?
Le bogue lui-même ne m'a pas ennuyé, car ce n'était qu'une question d'heures avant que Google ne corrige le problème. Cependant, quelques commentaires et publications à ce sujet par la suite m'ont plutôt mis en colère.
Bien que Google ait divulgué le problème de manière relativement transparente, certains référenceurs ont essayé de donner un sens au bogue par crochet ou par escroc et ont commencé à examiner les changements pour rechercher des modèles. Un employé d'une agence de référencement américaine bien connue, que je ne veux pas exposer à ce stade, a commencé à analyser les données Google Analytics de chaque client actuel et ancien et a tenté de tirer des conclusions sur la raison des changements de classement.
Je considère que cela franchit la ligne pour plusieurs raisons, mais j'en reparlerai plus tard.
Qu'est-ce que le ou les employés ont découvert sur le problème ?
Dans le cas des mises à jour régulières de Google, toutes les sous-pages d'un domaine seraient généralement affectées par le changement, qu'il soit positif ou négatif. Ce n'était pas le cas avec le glitch actuel, car si certaines sous-pages d'un même domaine ont subi des pertes massives, d'autres en ont profité et certaines n'ont pratiquement pas changé, voire pas du tout.
Leur première idée était donc que cela ne ressemblait pas à une mise à jour typique de Google. Jusqu'ici tout va bien.
Maintenant, cela devient un peu aventureux :
« De nombreuses pages qui sont montées plus haut dans le classement contenaient des informations médicales qui contredisaient le consensus scientifique. Pour plus de clarté, il est fait référence ici aux directives Google Quality Rater qui stipulent que lors de la détermination de l'EAT d'une page sur des sujets scientifiques, elle doit être créée par des personnes ou des organisations ayant une expertise dans le domaine respectif et doit refléter le consensus établi de la science, là où il y en a. »
Cette affirmation est « prouvée » par l'observation que quelques articles médicaux, qui contredisent évidemment l'état de la science et ont aussi des backlinks mauvais ou non naturels, se classent soudainement bien mieux qu'avant et après le bug.
Leur théorie est que les pages qui devraient être dévaluées en raison de problèmes de qualité sont en fait bien classées. Par exemple, des pages piratées, des pages avec des liens non naturels ou des pages avec des revendications qui s'écartent du consensus scientifique général auraient été catapultées aux premières places.
L'auteur en déduit ce qui suit :
Si le classement d'une page s'améliore, cela pourrait être une raison de se réjouir, ou peut-être était-ce simplement
un test pour une future mise à jour qui a mal tourné. Ou cela pourrait être une indication d'un problème de qualité avec le site Web, qui a limité le classement de la page, mais qui n'a peut-être pas joué de rôle au moment du bogue.
En revanche, si une page avait dégringolé dans le classement, cela pourrait signifier que vous étiez dépassé par des pages inférieures ou spammées, qui sont à nouveau déclassées actuellement par les algorithmes de Google.
Uffz ! Vraiment? À quoi bon cet aperçu pour mon travail SEO quotidien ? !
Pourquoi ne pas effectuer de telles analyses ?
Outre le fait qu'ils ont toujours accès et utilisent les données Google Analytics d'anciens clients, je vois ici un problème beaucoup plus important avec l'approche de l'employé :
Le problème est que si vous recherchez des modèles sans hypothèse, vous trouverez toujours quelque chose. Si vous considérez ensuite ce résultat, sans autre test, comme étant correct, cela n'a rien à voir avec la science.
Il y a toujours des modèles, parfois aléatoires, parfois causés par un ou plusieurs facteurs. Vous ne pouvez pas d'abord rechercher des modèles, puis concevoir une théorie pour expliquer ce que vous observez et, par la suite, le considérer comme une réalité. Ce n'est pas ainsi que fonctionne la connaissance.
J'aimerais vraiment voir davantage de méthodes scientifiques utilisées dans le référencement, par exemple lorsqu'il s'agit de faire des hypothèses et de les tester ensuite !
Qu'est-ce qu'une hypothèse et comment la formuler correctement ?
Une hypothèse est une hypothèse raisonnable qui est faite au début d'une étude empirique. Cette hypothèse est analysée à l'aide de méthodes qualitatives ou quantitatives et est ensuite confirmée ou infirmée.
Lorsque vous formulez une hypothèse, vous supposez soit une corrélation, soit aucune corrélation entre deux variables . Une variable indépendante est la cause, la variable dépendante est l'effet possible.
Il existe essentiellement deux types d'hypothèses : dirigées et non dirigées.
Avec une hypothèse non dirigée, vous supposez simplement qu'il existe une corrélation entre deux variables. Par exemple, le nombre de sites Web liés influence la visibilité d'un domaine.
Avec une hypothèse dirigée, en revanche, la corrélation présumée est évaluée. Par exemple : plus un article a de backlinks, meilleur est son classement.
Cependant, pour faire une hypothèse, vous devez considérer les critères suivants :
- Les deux variables utilisées doivent être mesurables.
- Les hypothèses doivent être formulées de manière objective et concise.
- Si plusieurs hypothèses sont formulées, elles ne doivent pas se contredire.
- Et : Les hypothèses scientifiques doivent pouvoir être réfutées.
Étant donné que la plupart des hypothèses dans le domaine du référencement ne peuvent être réfutées par une expérience, il n'y a aucune preuve à proprement parler d'un point de vue scientifique. De même, vous ne devez pas analyser les résultats des requêtes de recherche afin de tirer des conclusions sur les facteurs de classement utilisés.
La prise de conscience que corrélation n'est pas synonyme de causalité a heureusement été acceptée ces dernières années. Les études sur les facteurs de classement de tout fournisseur d'outils ne sont plus prises au sérieux par aucun référenceur expérimenté aujourd'hui, ce qui signifie que de moins en moins d'entre elles sont réalisées et publiées.