
Ein Appell für mehr Wissenschaft im SEO
Veröffentlicht: 2022-04-17- Eine böse Überraschung: Es war nur ein Fehler!
- Also, wo ist das Problem bei all dem?
- Was hat der/die Mitarbeiter über die Panne herausgefunden?
- Warum nicht solche Analysen durchführen?
- Was ist eine Hypothese und wie formuliert man sie richtig?
Sie haben wahrscheinlich schon davon gehört, aber für diejenigen unter Ihnen, die Google nicht auf Schritt und Tritt folgen, hier eine Zusammenfassung:
Anfang August stieg die Fluktuation der Suchergebnisse bei Google massiv an – weltweit und in allen Sprachen. In den Webmaster-Foren und den üblichen Black-Hat-Foren wurde sofort über die Einführung eines massiven unangekündigten Updates spekuliert. Die Schwankungen und Veränderungen innerhalb der Suchergebnislisten waren so groß, dass mehrere große SEO-Portale in den USA das größte Update aller Zeiten meldeten.
Tatsächlich wurden alle SEO-Tools und Ranking-Checker plötzlich von massiven Verschiebungen in den Suchergebnissen von Google getroffen. Die Suchergebnisse haben sich nicht nur geändert; Sie wurden auf den Kopf gestellt, manchmal mit absurden Ergebnissen, die die Spitzenpositionen füllten.
Die Auswirkungen des Bugs sieht man sehr deutlich im täglichen Sichtbarkeitsindex:
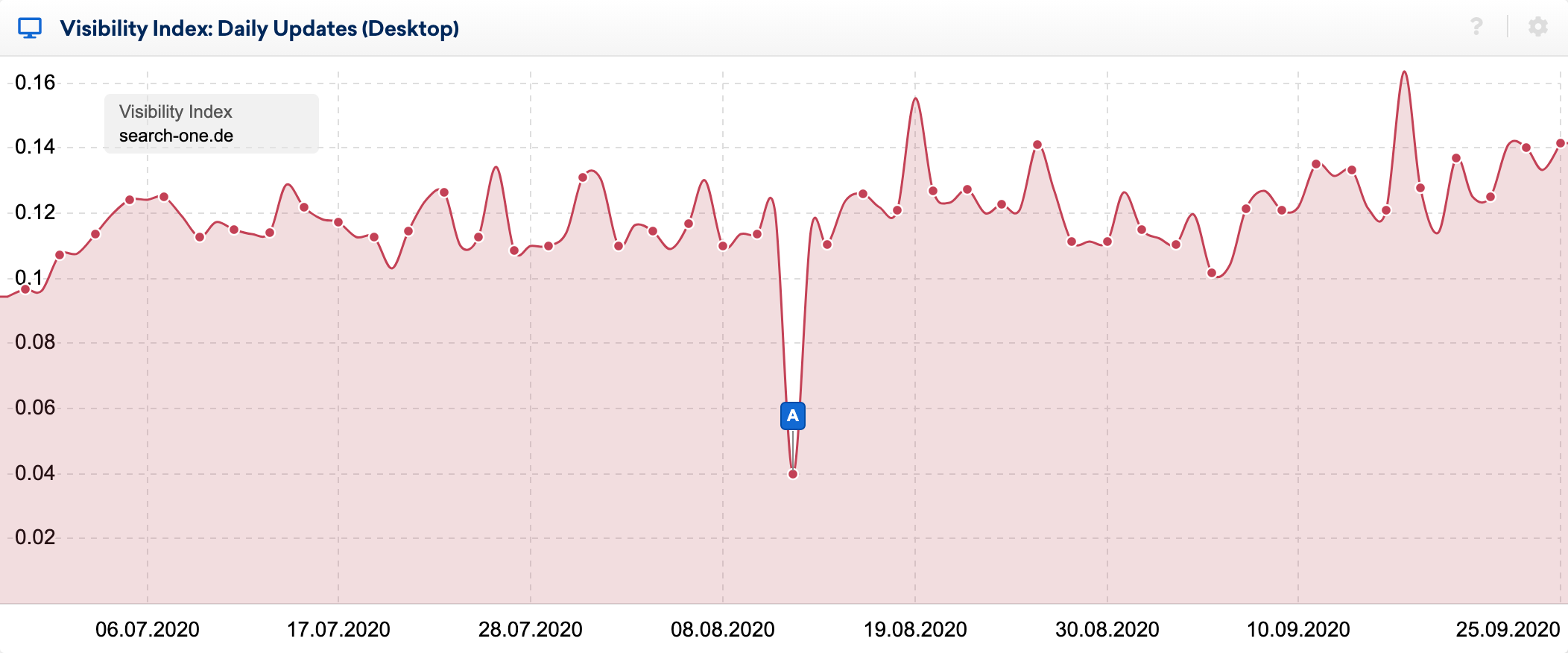
Anhand der großartigen SERP-Vergleichsfunktion in der SISTRIX-Toolbox habe ich mir die Veränderungen innerhalb der Top 20 einiger Keywords, deren Rankings ich seit vielen Jahren beobachte, genauer angeschaut. Ich habe Dutzende von Analysen der gerankten Websites für diese Schlüsselwörter durchgeführt und weiß normalerweise relativ gut, warum eine URL dort rankt, wo sie es tut.
Schaut man sich zum fraglichen Zeitpunkt den SERP-Vergleich für das Keyword „Google-Optimierung“ an, so stellt man fest, dass sich die gesamten Top 20 bis auf eine URL komplett verändert haben. Was zuvor auf Platz 1 lag , rückte auf Platz 8 ab, die restlichen URLs kamen aus dem Nichts, also von außerhalb der Top 20 in die Top-Plätze.
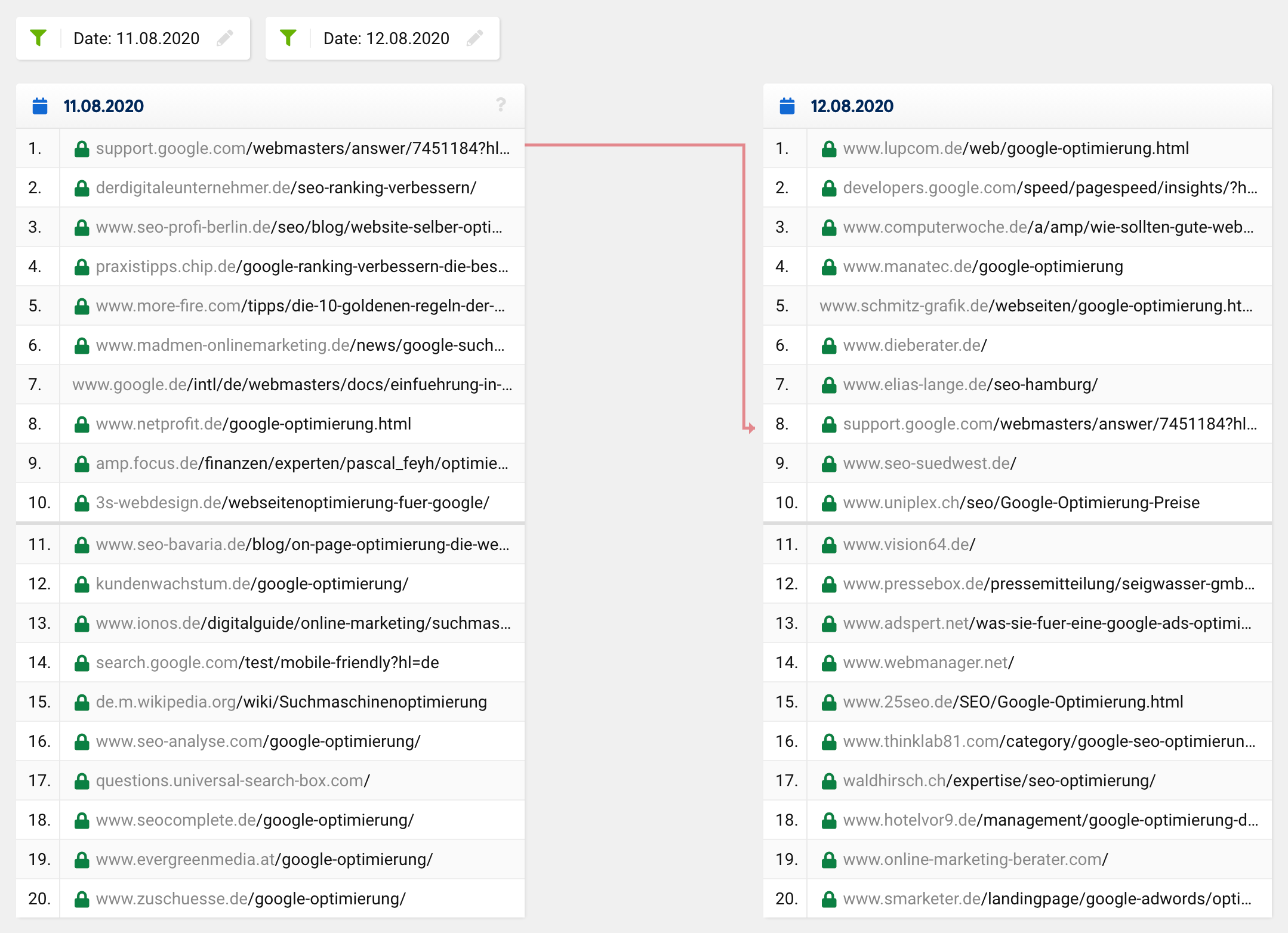
Ein normales Update bzw. ein regelmäßiger Ranking-Wechsel würde normalerweise eher so aussehen:

Viele URLs bleiben gleich, während bestimmte URLs nach oben und andere nach unten verschoben werden. Natürlich verschwindet manchmal eine URL aus den Top 20 oder rückt nach oben. Allerdings kommt es unglaublich selten vor, dass von 20 Treffern nur noch einer in den „neuen“ Top 20 bleibt – das war flächendeckend der Fall, nicht nur bei einem bestimmten Keyword.
Bei solch weitreichenden Änderungen ähnlich den berüchtigten Phantom-Updates würde man eine Anpassung der vermuteten User-Intent einer Suchanfrage erwarten, was dann zu grundlegenden Änderungen in der Zusammensetzung der Top 20 für einige Keywords führen würde. In einem solchen Fall würden sich die Suchergebnisse jedoch verbessern, dh relevanter und aussagekräftiger werden, was bei diesem Glitch offensichtlich nicht der Fall war.
Die große Mehrheit der SEOs war von den offensichtlich absurden Suchergebnissen überrascht und ging relativ schnell von einem Fehler aus – oder hoffte zumindest, dass es sich nur um ein vorübergehendes Problem handelte. Mir ging es genauso, da einige meiner Websites innerhalb weniger Stunden ihre wichtigsten Rankings komplett verloren haben!
Eine böse Überraschung: Es war nur ein Fehler!
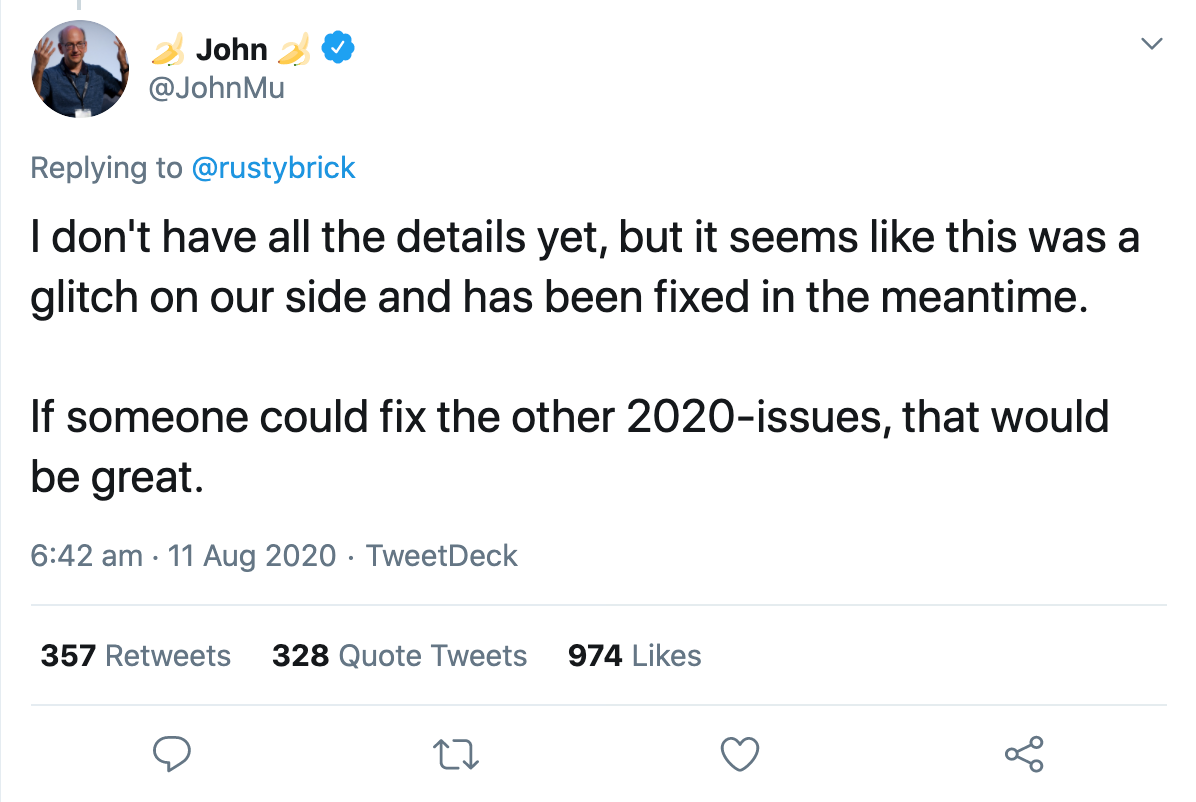
In derselben Nacht bestätigte ein Google-Sprecher, dass es sich um einen Fehler handelte, den sie beheben wollten. Innerhalb weniger Stunden war alles wieder normal. John Muller bestätigte via Twitter, dass der Fehler behoben sei, ihm aber noch nicht alle Details bekannt seien:
Nur einen Tag später bestätigte der offizielle Google-Webmaster-Account, dass die Suchergebnisse von einem offensichtlichen Problem mit dem Indexierungssystem betroffen waren.
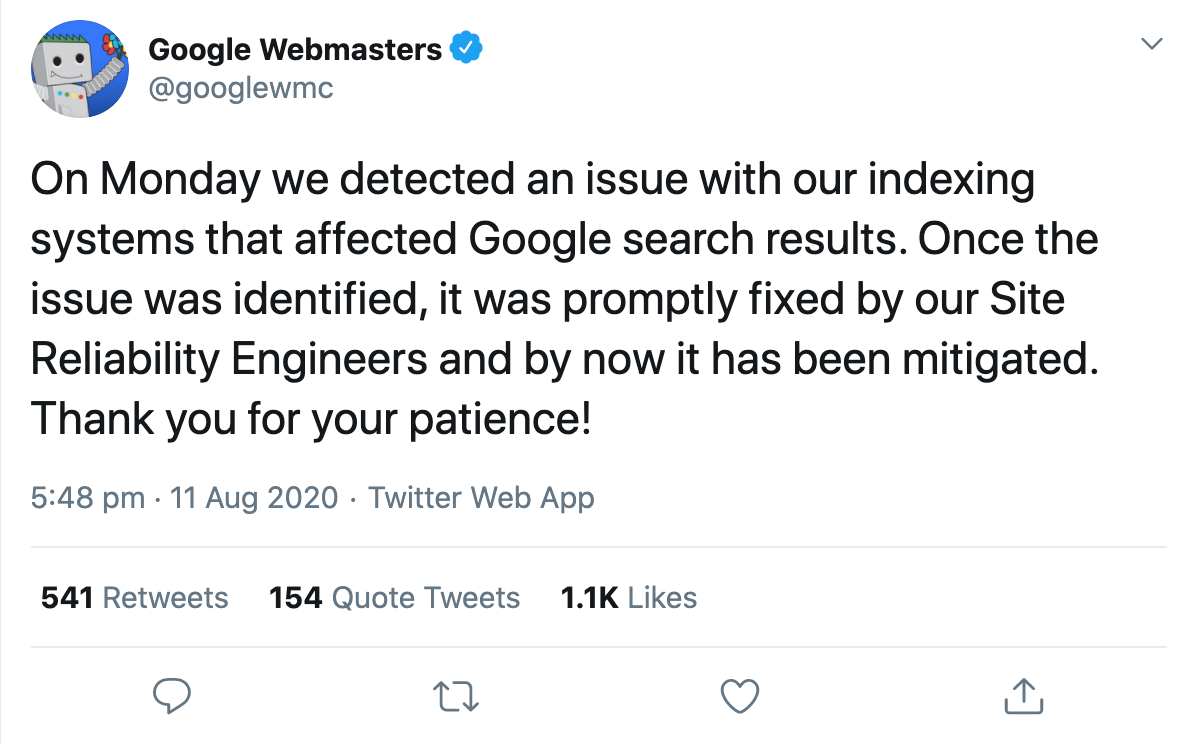
Und hier begannen die Leute darüber zu spekulieren, was genau passiert sein könnte.
Gary Illyes versuchte, die Dinge ein wenig konkreter zu machen, indem er beschrieb, was das Indizierungssystem Caffeine tatsächlich tut. Laut seinem Tweet nimmt es Fetchlogs auf, rendert und konvertiert abgerufene Daten, extrahiert Links, Meta- und strukturierte Daten, extrahiert und berechnet einige unbenannte Signale, plant neue Crawls und erstellt den Index, der zum Bereitstellen gepusht wird. Um dies verständlicher zu machen, gab er einige Beispiele dafür, was schief gehen könnte, was sich dann in veränderten Suchergebnissen widerspiegeln würde:
„Wenn die Planung der Crawls schief geht, kann sich das Crawlen verlangsamen. Wenn das Rendering schief geht, missversteht Google die Seiten möglicherweise. Wenn die Indexerstellung fehlschlägt, können Ranking und Bereitstellung beeinträchtigt werden.“
Anschließend betonte er, wie komplex die Suche sei und dass tausende miteinander verbundener Systeme reibungslos zusammenarbeiten müssten, um den Nutzern relevante Ergebnisse zu liefern. Wenn ein Sandkorn in die Maschinen geworfen würde, wäre die Folge ein Ausfall wie gestern.
Auf Nachfrage eines Twitter-Nutzers präzisierte er, dass offenbar beim Aufbau des Indexes selbst ein Fehler aufgetreten sei:
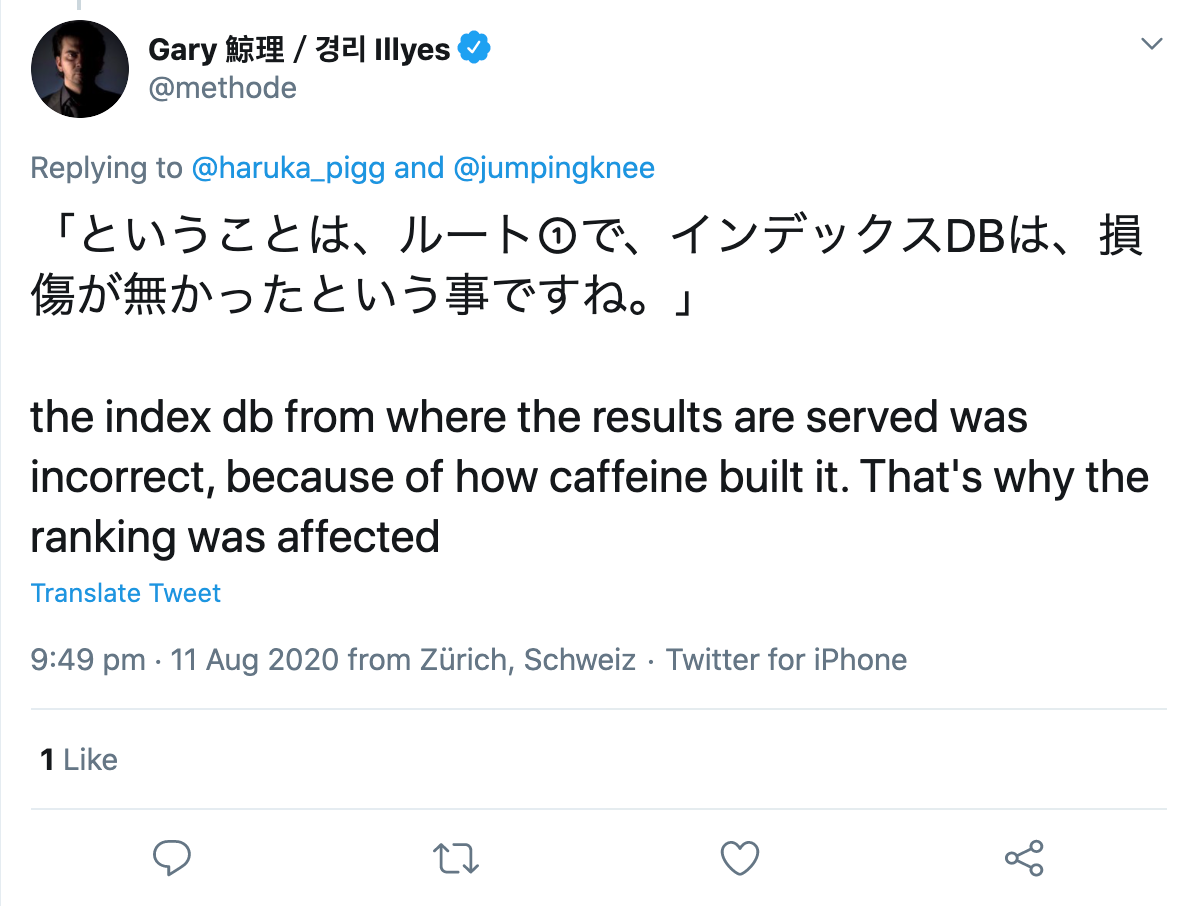
Also, wo ist das Problem bei all dem?
Der Fehler selbst hat mich nicht gestört, da es nur eine Frage von Stunden war, bis Google das Problem behoben hatte. Allerdings haben mich einige Kommentare und Veröffentlichungen darüber im Nachhinein ziemlich wütend gemacht.

Obwohl Google das Problem relativ transparent offengelegt hatte, versuchten einige SEOs, den Fehler auf Biegen und Brechen zu verstehen und begannen, die Änderungen zu untersuchen, um nach Mustern zu suchen. Ein Mitarbeiter einer bekannten amerikanischen SEO-Agentur, den ich an dieser Stelle nicht preisgeben möchte, hat begonnen, die Google-Analytics-Daten jedes aktuellen und ehemaligen Kunden zu analysieren und versucht, Rückschlüsse auf den Grund für die Ranking-Veränderungen zu ziehen.
Ich halte dies aus mehreren Gründen für eine Grenzüberschreitung, aber dazu später mehr.
Was hat der/die Mitarbeiter über die Panne herausgefunden?
Bei regelmäßigen Google-Updates wären in der Regel alle Unterseiten einer Domain von der Änderung betroffen, egal ob positiv oder negativ. Bei der aktuellen Panne war dies nicht der Fall, denn während einige Unterseiten ein und derselben Domain massive Einbußen erlitten, profitierten andere davon und einige änderten sich kaum oder gar nicht.
Ihre erste Erkenntnis war daher, dass es nicht wie ein typisches Google-Update aussah. So weit, ist es gut.
Jetzt wird es etwas abenteuerlich:
„Viele Seiten, die in den Rankings weiter nach oben gingen, enthielten medizinische Informationen, die dem wissenschaftlichen Konsens widersprachen. Zur Klarstellung wird hier auf die Google Quality Rater Guidelines verwiesen, die besagen, dass bei der Bestimmung des EAT einer Seite zu wissenschaftlichen Themen diese von Personen oder Organisationen mit Expertise auf dem jeweiligen Gebiet erstellt werden und den etablierten Konsens der Wissenschaft widerspiegeln soll, wo man existiert.“
„Bewiesen“ wird diese Behauptung durch die Beobachtung, dass einige medizinische Artikel, die offensichtlich dem Stand der Wissenschaft widersprechen und zudem schlechte oder unnatürliche Backlinks haben, plötzlich viel besser rankten als vor und nach dem Bug.
Ihre Theorie ist, dass Seiten, die aufgrund von Qualitätsproblemen abgewertet werden sollten, tatsächlich gut ranken. So wären beispielsweise gehackte Seiten, Seiten mit unnatürlichen Links oder Seiten mit Behauptungen, die vom allgemeinen wissenschaftlichen Konsens abweichen, auf Spitzenplätze katapultiert worden.
Daraus leitet der Autor Folgendes ab:
Wenn sich die Rankings einer Seite verbessern, könnte das ein Grund zur Freude sein, oder vielleicht war es auch nur so
ein Test für ein zukünftiges Update, das schief gelaufen ist. Oder es könnte ein Hinweis auf ein Qualitätsproblem der Website sein, das das Ranking der Seite einschränkte, zum Zeitpunkt des Fehlers aber möglicherweise keine Rolle gespielt hat.
Hatte sich eine Seite hingegen im Ranking nach unten bewegt, könnte dies bedeuten, dass Sie von minderwertigen oder spammigen Seiten überholt wurden, die derzeit von den Algorithmen von Google erneut herabgestuft werden.
Uffz! Wirklich? Was nützt mir diese Erkenntnis für meine tägliche SEO-Arbeit?!
Warum nicht solche Analysen durchführen?
Abgesehen davon, dass sie immer noch Zugriff auf und Nutzung der Google-Analytics-Daten ehemaliger Kunden haben, sehe ich hier ein viel größeres Problem bei der Vorgehensweise des Mitarbeiters:
Das Problem ist, dass man, wenn man ohne Hypothese nach Mustern sucht, immer etwas findet. Wenn Sie dieses Ergebnis dann ohne weitere Prüfung für richtig halten, hat das nichts mit Wissenschaft zu tun.
Es gibt immer Muster, manchmal zufällig, manchmal verursacht durch einen oder mehrere Faktoren. Sie können nicht zuerst nach Mustern suchen und dann eine Theorie entwickeln, um zu erklären, was Sie beobachten, und es anschließend als Realität annehmen. So funktioniert Wissen einfach nicht.
Ich würde mir sehr wünschen, dass im SEO mehr wissenschaftliche Methoden zum Einsatz kommen, zum Beispiel wenn es darum geht, Hypothesen aufzustellen und diese dann zu testen!
Was ist eine Hypothese und wie formuliert man sie richtig?
Eine Hypothese ist eine vernünftige Annahme, die zu Beginn einer empirischen Studie aufgestellt wird. Diese Annahme wird mit qualitativen oder quantitativen Methoden analysiert und anschließend bestätigt oder widerlegt.
Wenn Sie eine Hypothese aufstellen, gehen Sie entweder von einer Korrelation oder von keiner Korrelation zwischen zwei Variablen aus . Eine unabhängige Variable ist die Ursache, die abhängige Variable ist die mögliche Wirkung.
Es gibt im Wesentlichen zwei Arten von Hypothesen: gerichtete und ungerichtete.
Bei einer ungerichteten Hypothese gehen Sie lediglich davon aus, dass es eine gewisse Korrelation zwischen zwei Variablen gibt. So beeinflusst beispielsweise die Anzahl der verlinkten Webseiten die Sichtbarkeit einer Domain.
Bei einer gerichteten Hypothese hingegen wird die vermutete Korrelation bewertet. Zum Beispiel: Je mehr Backlinks ein Artikel hat, desto besser rankt er.
Um eine Hypothese aufzustellen, sollten Sie jedoch die folgenden Kriterien berücksichtigen:
- Beide verwendeten Variablen müssen messbar sein.
- Hypothesen müssen sachlich und prägnant formuliert werden.
- Werden mehrere Hypothesen formuliert, dürfen diese sich nicht widersprechen.
- Und: Wissenschaftliche Annahmen müssen widerlegbar sein.
Da die meisten Annahmen im Bereich SEO nicht durch ein Experiment widerlegt werden können, gibt es aus wissenschaftlicher Sicht keine nennenswerten Beweise. Ebenso sollten Sie die Ergebnisse etwaiger Suchanfragen nicht analysieren, um Rückschlüsse auf die verwendeten Ranking-Faktoren zu ziehen.
Die Erkenntnis, dass Korrelation nicht gleich Kausalität ist, hat sich in den letzten Jahren glücklicherweise durchgesetzt. Studien zu den Ranking-Faktoren beliebiger Tool-Anbieter werden heute von keinem erfahrenen SEO mehr ernst genommen, wodurch immer weniger davon durchgeführt und veröffentlicht werden.