
Um apelo por mais ciência em SEO
Publicados: 2022-04-17- Uma surpresa desagradável: foi apenas um erro!
- Então, onde está o problema nisso tudo?
- O que os funcionários descobriram sobre a falha?
- Por que não realizar tais análises?
- O que é uma hipótese e como você formula uma corretamente?
Você provavelmente já ouviu falar, mas para aqueles que não seguem todos os passos do Google, aqui está um resumo:
No início de agosto, houve um aumento maciço na flutuação dos resultados de pesquisa no Google – em todo o mundo e em todos os idiomas. Nos fóruns de webmasters e nos fóruns habituais da Black Hat, houve especulação imediata sobre o lançamento de uma atualização massiva não anunciada. As flutuações e mudanças nas listas de resultados de pesquisa foram tão grandes que vários grandes portais de SEO nos EUA relataram a maior atualização de todos os tempos.
Na verdade, todas as ferramentas de SEO e verificadores de classificação foram subitamente atingidos por grandes mudanças nos resultados de pesquisa do Google. Os resultados da pesquisa não apenas mudaram; eles viraram de cabeça para baixo, às vezes com resultados absurdos preenchendo as primeiras posições.
Você pode ver os efeitos do bug muito claramente no índice de visibilidade diária:
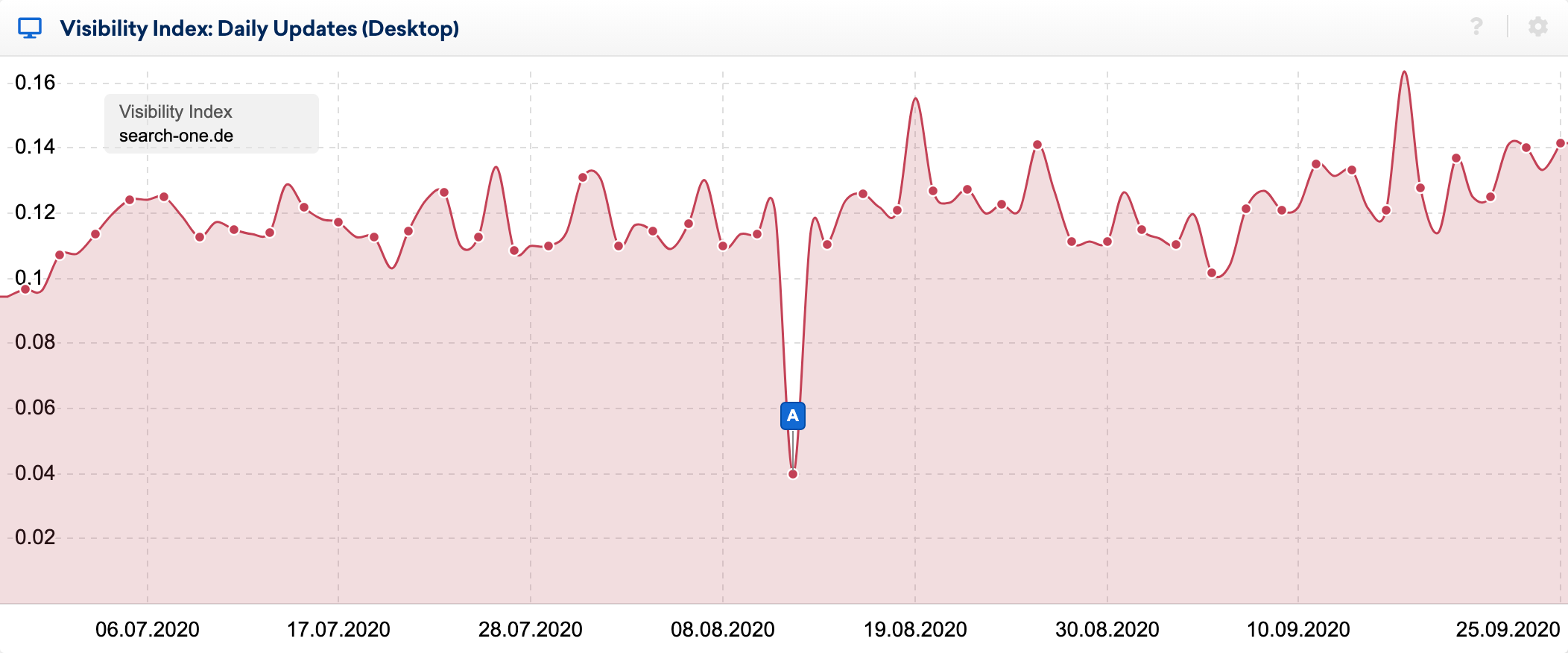
Usando o ótimo recurso de comparação de SERP na caixa de ferramentas do SISTRIX, observei mais de perto as mudanças no top 20 de algumas palavras-chave, cujos rankings venho observando há muitos anos. Eu fiz dezenas de análises dos sites classificados para essas palavras-chave e geralmente sei relativamente bem por que um URL classifica onde está.
Se você der uma olhada na comparação SERP para a palavra-chave “otimização do google” no momento em questão, verá que todo o top 20, com exceção de um URL, mudou completamente. O que estava anteriormente em 1º lugar desceu para o 8º lugar, com as restantes URLs a surgirem do nada, ou seja, de fora do top 20 para os primeiros lugares.
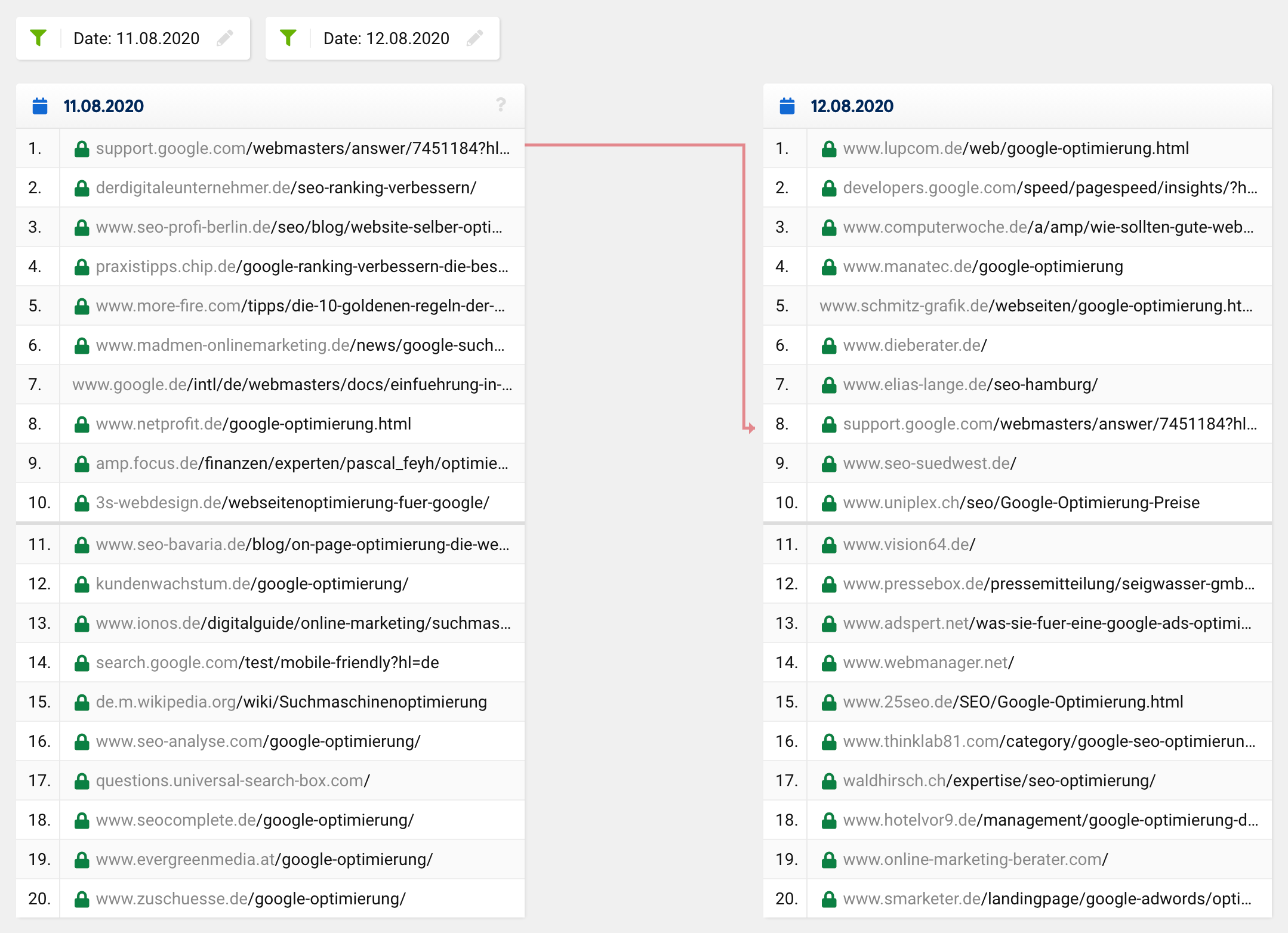
Uma atualização normal ou uma mudança regular de classificação normalmente se pareceria mais com isso:

Muitos URLs permanecem os mesmos, enquanto certos URLs sobem e outros descem. Claro, às vezes um URL desaparece do top 20 ou sobe para ele. No entanto, é incrivelmente raro que de 20 hits, apenas um seja deixado no “novo” top 20 – esse foi o caso em geral, não apenas para uma palavra-chave específica.
Dadas essas mudanças de longo alcance semelhantes às notórias atualizações fantasmas, você esperaria ver um ajuste na intenção do usuário assumida de uma consulta de pesquisa, o que levaria a mudanças fundamentais na composição das 20 principais para algumas palavras-chave. Nesse caso, porém, os resultados da busca melhorariam, ou seja, se tornariam mais relevantes e significativos, o que obviamente não foi o que ocorreu com essa falha.
A grande maioria dos SEOs ficou surpresa com os resultados de pesquisa obviamente absurdos e assumiu relativamente rápido que havia um erro – ou pelo menos esperava que fosse apenas um problema temporário. Eu me senti da mesma forma, pois alguns dos meus sites perderam completamente seus rankings mais importantes no espaço de algumas horas!
Uma surpresa desagradável: foi apenas um erro!
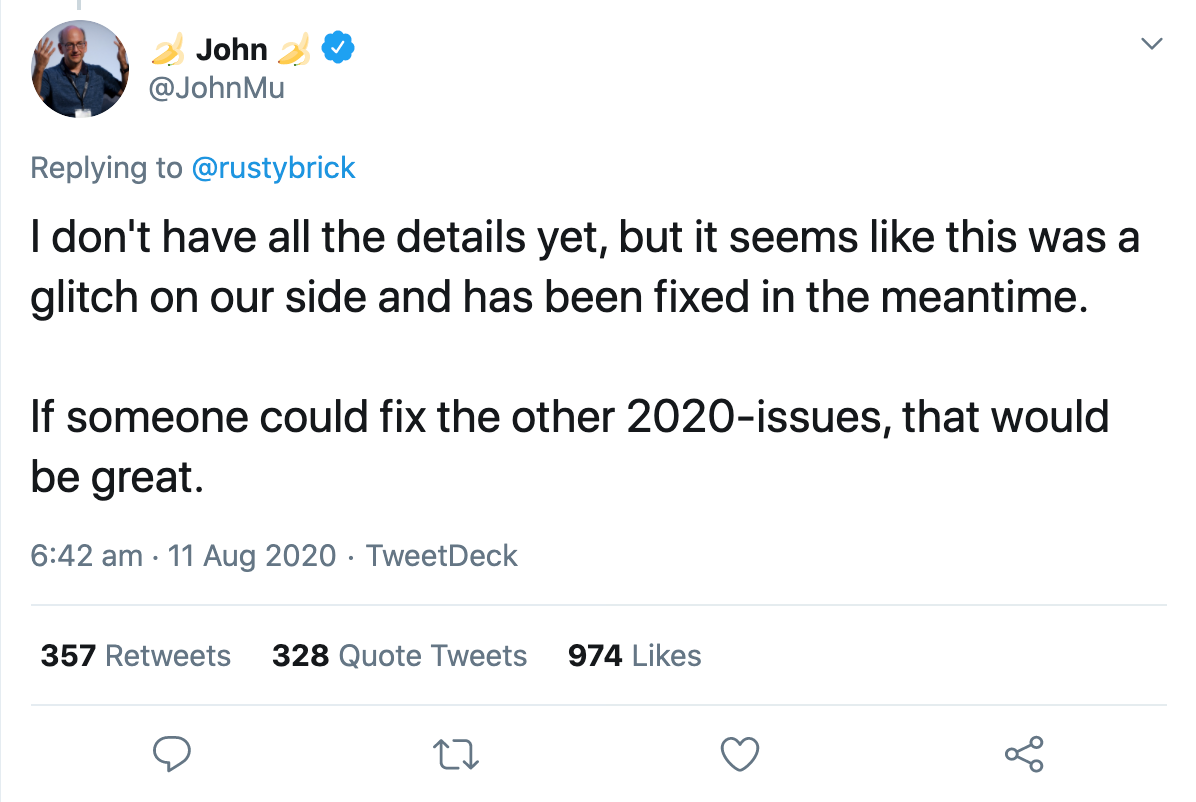
Naquela mesma noite, um porta-voz do Google confirmou que era um bug que eles estavam corrigindo. Em poucas horas, tudo voltou ao normal. John Muller confirmou via Twitter que o bug foi corrigido, mas que ainda não tinha todos os detalhes:
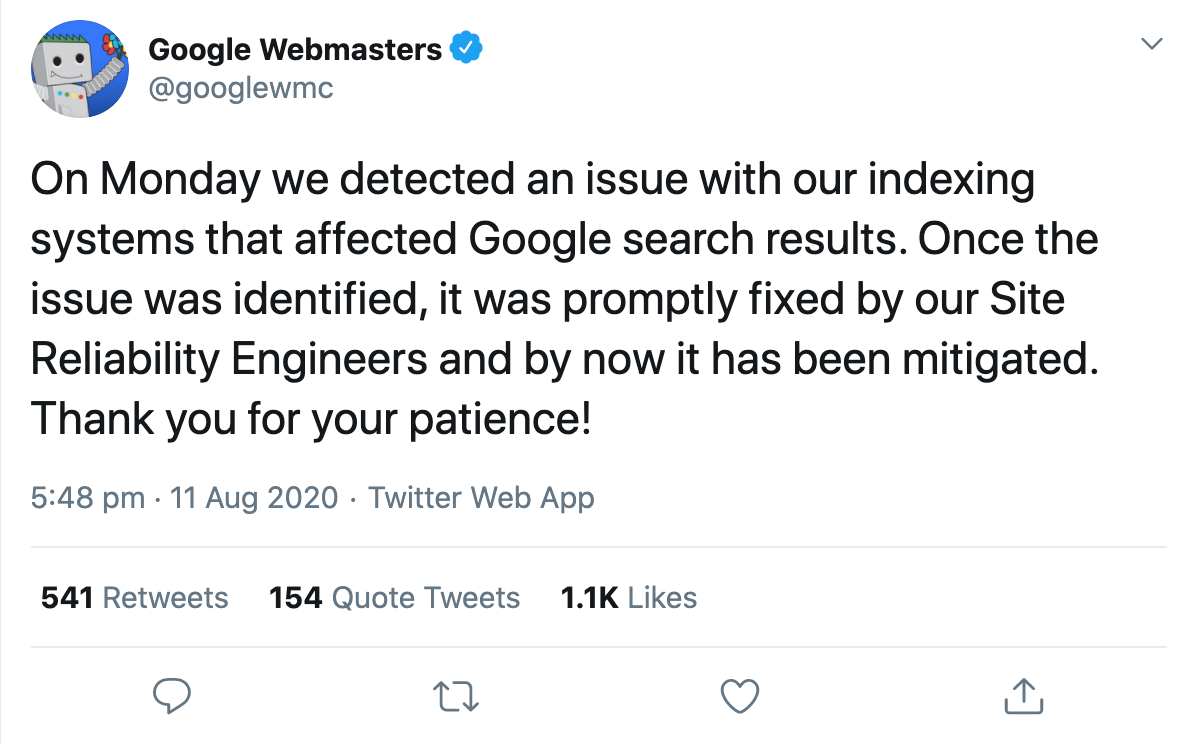
Apenas um dia depois, a conta oficial do Google Webmaster confirmou que os resultados da pesquisa foram afetados por um aparente problema com o sistema de indexação.
E foi aí que as pessoas começaram a especular sobre o que exatamente poderia ter acontecido.
Gary Illyes tentou tornar as coisas um pouco mais concretas descrevendo o que o sistema de indexação, Cafeína, realmente faz. De acordo com seu tweet, ele ingere fetchlogs, renderiza e converte dados buscados, extrai links, meta e dados estruturados, extrai e computa alguns sinais sem nome, agenda novos rastreamentos e cria o índice que é enviado para veiculação. Para tornar isso mais fácil de entender, ele deu alguns exemplos do que poderia dar errado, o que seria refletido nos resultados de pesquisa alterados:
“Se o agendamento dos rastreamentos der errado, o rastreamento pode desacelerar. Se a renderização der errado, o Google pode interpretar mal as páginas. Se a construção do índice for ruim, a classificação e a veiculação podem ser afetadas.”
Ele então enfatizou o quão complexa é a busca e que milhares de sistemas interconectados devem trabalhar juntos sem falhas para entregar resultados relevantes aos usuários. Se um grão de areia fosse jogado no maquinário, o resultado seria uma interrupção como ontem.
Quando perguntado por um usuário do Twitter, ele especificou que aparentemente houve um erro na construção do próprio índice:

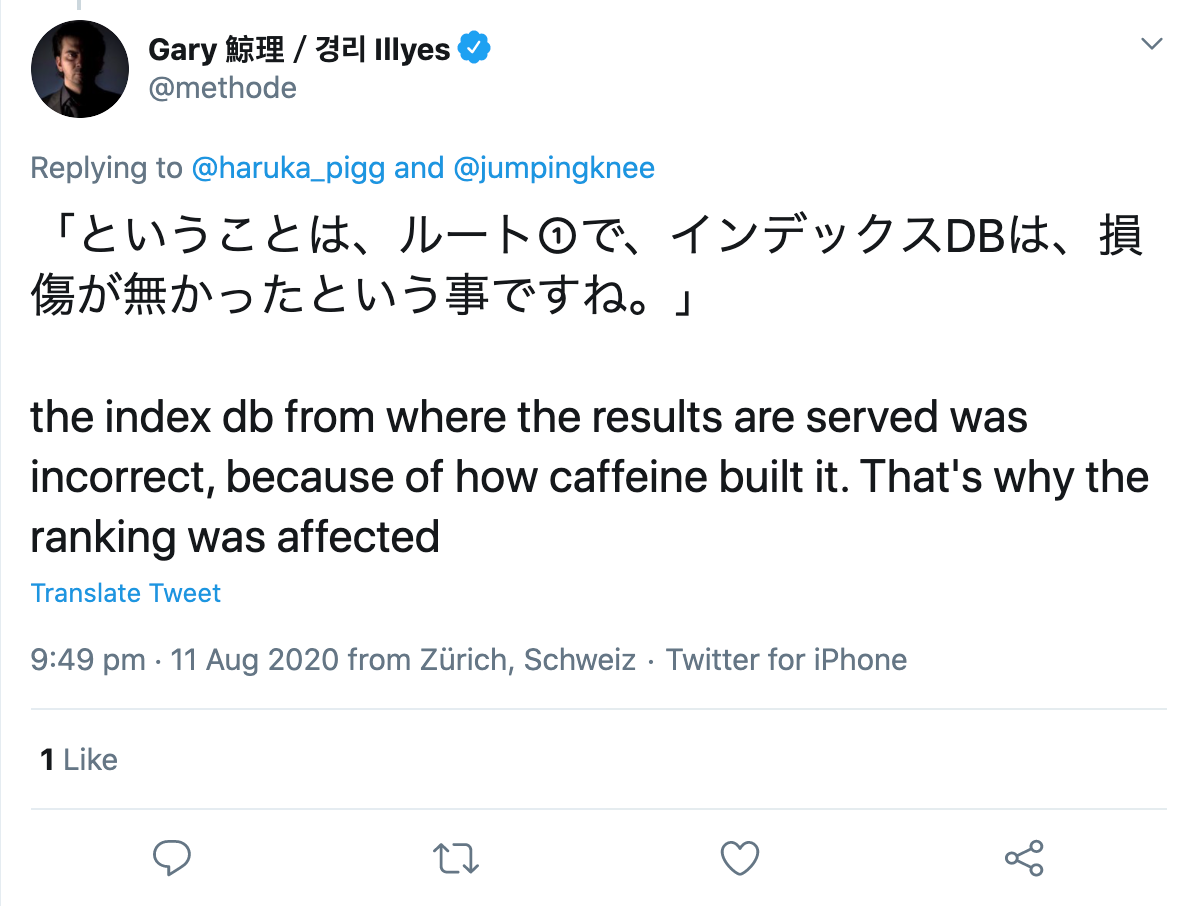
Então, onde está o problema nisso tudo?
O bug em si não me incomodou, pois foi apenas uma questão de horas até que o Google corrigisse o problema. No entanto, alguns comentários e publicações sobre isso depois me deixaram bastante irritado.
Embora o Google tenha divulgado o problema de forma relativamente transparente, alguns SEOs tentaram entender o bug por bem ou por mal e começaram a examinar as mudanças para procurar padrões. Um funcionário de uma conhecida agência americana de SEO, que não quero expor neste momento, começou a analisar os dados do Google Analytics de todos os clientes atuais e antigos e tentou tirar conclusões sobre o motivo das mudanças no ranking.
Eu considero que isso está passando dos limites por várias razões, mas mais sobre isso mais tarde.
O que os funcionários descobriram sobre a falha?
No caso de atualizações regulares do Google, todas as subpáginas de um domínio normalmente seriam afetadas pela alteração, seja ela positiva ou negativa. Este não foi o caso com a falha atual, porque enquanto algumas subpáginas de um mesmo domínio sofreram grandes perdas, outras lucraram e algumas quase não mudaram, se é que mudaram.
Seu primeiro insight foi, portanto, que não parecia uma atualização típica do Google. Até agora tudo bem.
Agora torna-se um pouco aventureiro:
“Muitas páginas que subiram no ranking continham informações médicas que contradiziam o consenso científico. Para esclarecimento, é feita referência aqui às Diretrizes do Avaliador de Qualidade do Google, que afirmam que, ao determinar o EAT de uma página sobre tópicos científicos, ele deve ser criado por pessoas ou organizações com experiência no respectivo campo e deve refletir o consenso estabelecido da ciência, onde existe”.
Essa afirmação é “comprovada” pela observação de que alguns artigos médicos, que obviamente contradizem o estado da ciência e também têm backlinks ruins ou não naturais, de repente foram classificados muito melhor do que antes e depois do bug.
A teoria deles é que as páginas que deveriam ser desvalorizadas por causa de problemas de qualidade realmente se classificaram bem. Por exemplo, páginas invadidas, páginas com links não naturais ou páginas com alegações que se desviam do consenso científico geral teriam sido catapultadas para as primeiras posições.
A partir disso, o autor deduz o seguinte:
Se a classificação de uma página melhorar, isso pode ser motivo de regozijo, ou talvez tenha sido apenas
um teste para uma atualização futura que deu errado. Ou pode ser uma indicação de um problema de qualidade com o site, que limitou a classificação da página, mas pode não ter desempenhado um papel no momento do bug.
Por outro lado, se uma página desceu no ranking, isso pode significar que você foi ultrapassado por páginas inferiores ou com spam, que mais uma vez são rebaixadas pelos algoritmos do Google.
Uffz! Sério? De que adianta esse insight para o meu trabalho diário de SEO?!
Por que não realizar tais análises?
Além do fato de que eles ainda têm acesso e usam os dados do Google Analytics de antigos clientes, vejo um problema muito maior aqui com a abordagem do funcionário:
O problema é que se você procurar padrões sem uma hipótese, sempre encontrará algo. Se você considerar esse resultado, sem mais testes, como correto, não tem nada a ver com ciência.
Há sempre padrões, às vezes aleatórios, às vezes causados por um ou mais fatores. Você não pode procurar padrões primeiro e depois inventar uma teoria para explicar o que você observa e, depois disso, tomá-lo como realidade. Não é assim que o conhecimento funciona.
Eu realmente gostaria de ver mais métodos científicos sendo usados em SEO, por exemplo, quando se trata de fazer hipóteses e testá-las!
O que é uma hipótese e como você formula uma corretamente?
Uma hipótese é uma suposição razoável que é feita no início de um estudo empírico. Esta suposição é analisada usando métodos qualitativos ou quantitativos e, em seguida, é confirmada ou refutada.
Ao fazer uma hipótese, você assume uma correlação ou nenhuma correlação entre duas variáveis . Uma variável independente é a causa, a variável dependente é o possível efeito.
Existem essencialmente dois tipos de hipóteses: direcionadas e não direcionadas.
Com uma hipótese não direcionada, você simplesmente assume que há alguma correlação entre duas variáveis. Por exemplo, o número de sites vinculados influencia a visibilidade de um domínio.
Com uma hipótese direcionada, por outro lado, avalia-se a correlação presumida. Por exemplo: quanto mais backlinks um artigo tiver, melhor ele será classificado.
No entanto, para fazer uma hipótese, você deve considerar os seguintes critérios:
- Ambas as variáveis utilizadas devem ser mensuráveis.
- As hipóteses devem ser formuladas de forma objetiva e concisa.
- Se várias hipóteses forem formuladas, elas não devem se contradizer.
- E: As suposições científicas devem poder ser refutadas.
Como a maioria das suposições no campo de SEO não pode ser refutada por um experimento, não há evidências para falar de uma perspectiva científica. Da mesma forma, você não deve analisar os resultados de nenhuma consulta de pesquisa para tirar conclusões sobre os fatores de classificação usados.
A percepção de que a correlação não é igual à causalidade felizmente foi aceita nos últimos anos. Estudos sobre os fatores de classificação de qualquer provedor de ferramentas não são mais levados a sério por qualquer SEO experiente hoje, o que significa que cada vez menos deles são realizados e publicados.