
SEOにおけるより多くの科学へのアピール
公開: 2022-04-17- 厄介な驚き:それはただの間違いでした!
- それで、これのすべての問題はどこにありますか?
- 従業員はグリッチについて何を知りましたか?
- そのような分析をしてみませんか?
- 仮説とは何ですか。また、どのようにして正しく仮説を立てますか。
あなたはおそらくすでに聞いたことがあるでしょう、しかしグーグルのすべてのステップに従わないあなたのそれらのために、ここに要約があります:
8月の初めに、世界中およびすべての言語でのGoogleの検索結果の変動が大幅に増加しました。 Webmasterフォーラムと通常のBlackHatフォーラムでは、大規模な未発表の更新の公開について即座に憶測が飛び交いました。 検索結果リスト内の変動と変化は非常に大きかったため、米国のいくつかの主要なSEOポータルはこれまでで最大の更新を報告しました。
実際、すべてのSEOツールとランキングチェッカーは、Googleの検索結果内で突然大きな変化に見舞われました。 検索結果が変わっただけではありません。 彼らは逆さまになり、時にはばかげた結果がトップの位置を埋めました。
バグの影響は、毎日の可視性インデックスで非常に明確に確認できます。
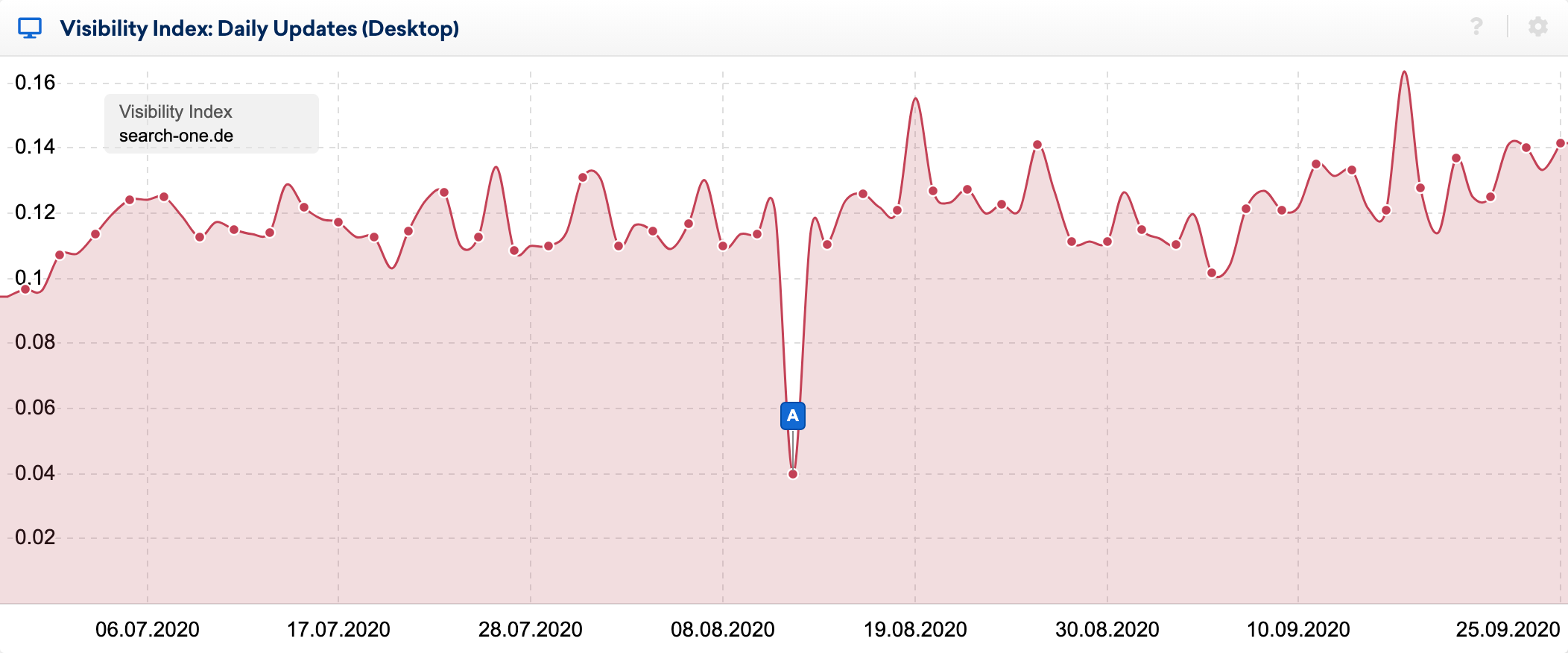
SISTRIXツールボックスの優れたSERP比較機能を使用して、私が長年観察してきたランキングの上位20のキーワードの変化を詳しく調べました。 私はこれらのキーワードについてランク付けされたWebサイトを何十回も分析しましたが、通常、URLがランク付けされる理由を比較的よく知っています。
問題の時点でのキーワード「googleoptimisation」のSERP比較を見ると、1つのURLを除いて、上位20全体が完全に変更されていることがわかります。 以前は1位だったものが8位に下がり、残りのURLはどこからともなく、つまりトップ20の外側からトップの場所に移動しました。
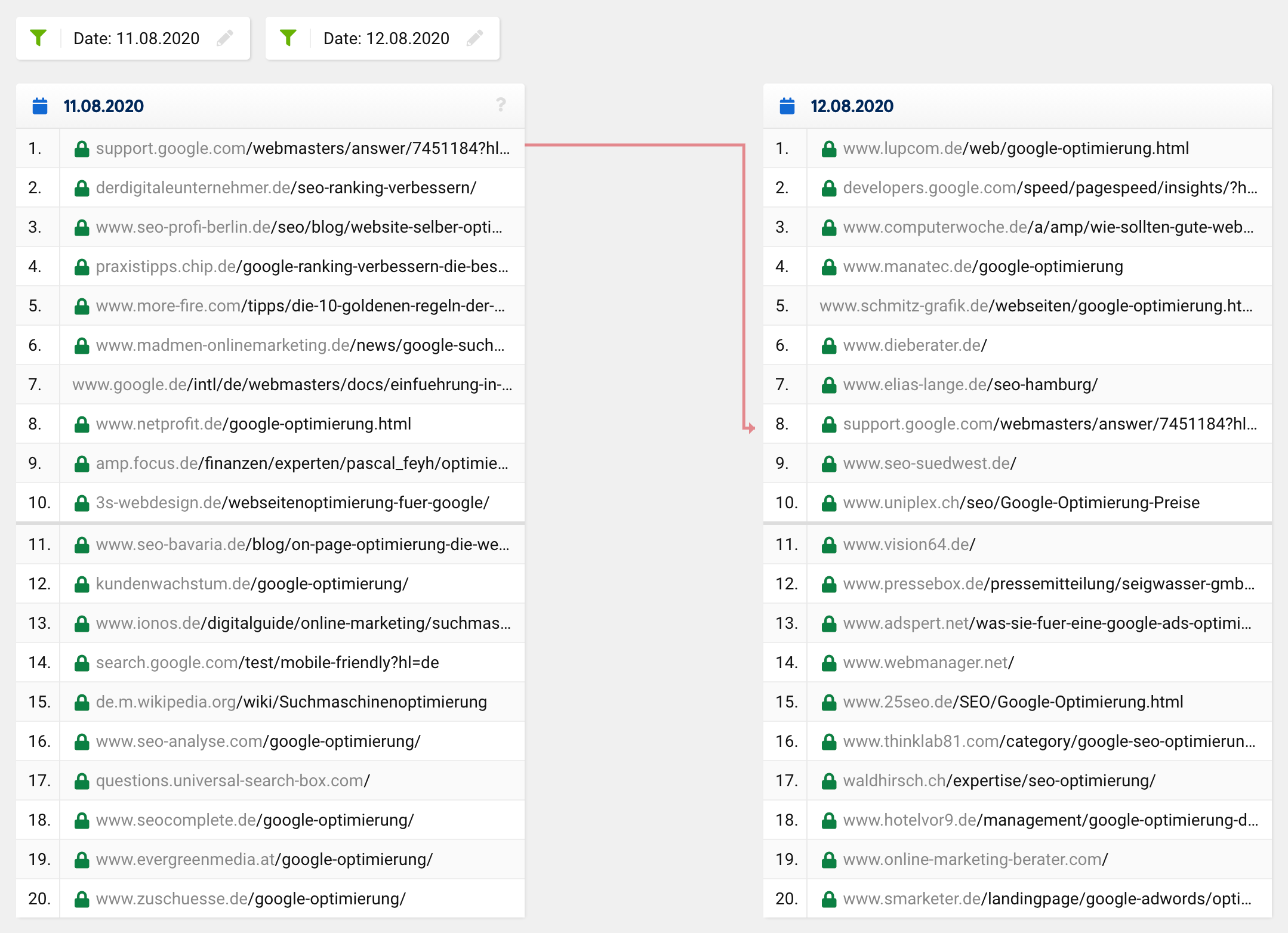
通常の更新または定期的なランキングの変更は、通常、次のようになります。

多くのURLは同じままですが、特定のURLは上に移動し、他のURLは下に移動します。 もちろん、URLがトップ20から消えたり、上位20に移動したりすることもあります。 ただし、20ヒットのうち、「新しい」トップ20に1つだけが残ることは非常にまれです。これは、特定の1つのキーワードだけでなく、全体的に当てはまります。
悪名高いファントムの更新と同様の広範囲にわたる変更を考えると、検索クエリの想定されるユーザーの意図が調整され、一部のキーワードの上位20の構成が根本的に変更されることが予想されます。 ただし、このような場合、検索結果は改善されます。つまり、より関連性が高く、意味のあるものになります。これは、このグリッチで発生したことではないことは明らかです。
SEOの大多数は、明らかにばかげた検索結果に驚いて、比較的すぐにエラーがあると思い込んでいました。少なくとも、それが一時的な問題であると期待していました。 私のウェブサイトのいくつかは数時間の間に彼らの最も重要なランキングを完全に失ったので、私は同じように感じました!
厄介な驚き:それはただの間違いでした!
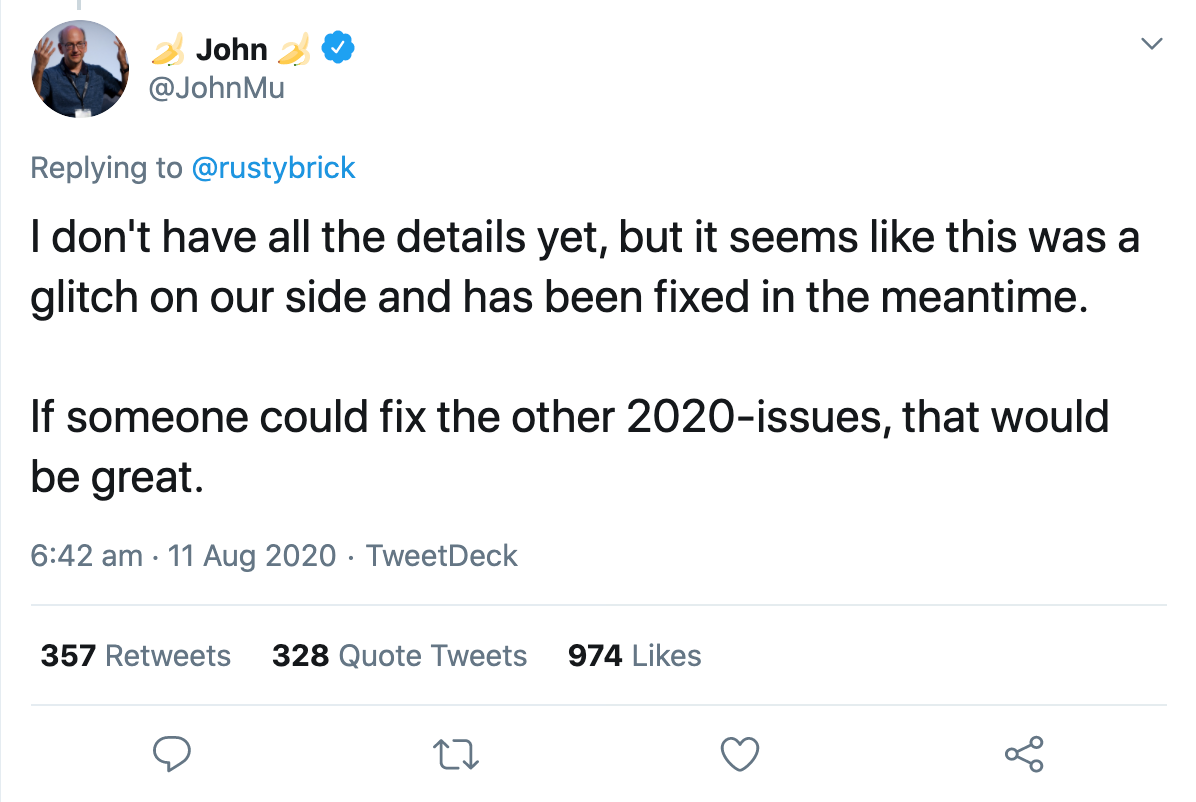
その同じ夜、Googleのスポークスパーソンは、それが修正中のバグであることを確認しました。 数時間以内に、すべてが正常に戻りました。 John MullerはTwitterでバグが修正されたことを確認しましたが、詳細はまだわかっていません。
ちょうど1日後、公式のGoogleウェブマスターアカウントは、検索結果がインデックスシステムの明らかな問題の影響を受けていることを確認しました。
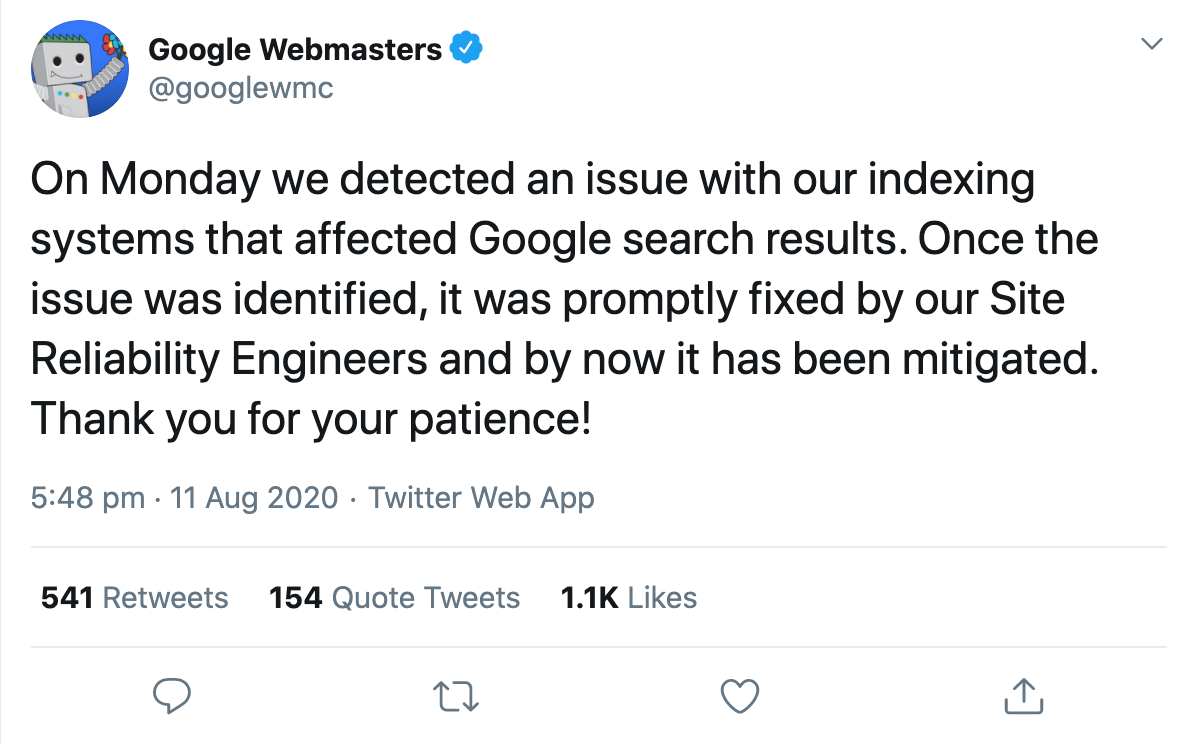
そして、これは人々が正確に何が起こったのかについて推測し始めた場所です。
Gary Illyesは、インデックスシステムであるCaffeineが実際に何をするかを説明することで、物事をもう少し具体的にしようとしました。 彼のツイートによると、フェッチログを取り込み、フェッチされたデータをレンダリングおよび変換し、リンク、メタおよび構造化データを抽出し、名前のないシグナルを抽出して計算し、新しいクロールをスケジュールし、配信にプッシュされるインデックスを構築します。 これを理解しやすくするために、彼は何がうまくいかない可能性があるかについていくつかの例を示しました。これは、変更された検索結果に反映されます。
「クロールのスケジュールがうまくいかない場合、クロールが遅くなる可能性があります。 レンダリングがうまくいかない場合、Googleはページを誤解する可能性があります。 インデックスの作成がうまくいかない場合、ランキングとサービスに影響が出る可能性があります。」

次に、検索がいかに複雑であるか、そして何千もの相互接続されたシステムが完璧に連携して、関連する結果をユーザーに提供する必要があることを強調しました。 砂粒が機械に投げ込まれると、昨日と同じように停電になります。
Twitterユーザーから尋ねられたとき、彼はインデックス自体の構築に明らかにエラーがあったことを指定しました。
それで、これのすべての問題はどこにありますか?
グーグルが問題を修正するのはほんの数時間だったので、バグ自体は私を悩ませませんでした。 しかし、その後のコメントや出版物によって、私はかなり腹を立てました。
Googleは問題を比較的透過的に開示していましたが、一部のSEOはフックまたは詐欺師によってバグを理解しようとし、パターンを探すために変更を調べ始めました。 現時点では公開したくない有名なアメリカのSEOエージェンシーの従業員が、現在および以前のすべてのクライアントのGoogle Analyticsデータの分析を開始し、ランキングの変更の理由について結論を導き出そうとしました。
これはいくつかの理由で一線を越えていると思いますが、それについては後で詳しく説明します。
従業員はグリッチについて何を知りましたか?
Googleの定期的な更新の場合、ドメインのすべてのサブページは通常、ポジティブかネガティブかにかかわらず、変更の影響を受けます。 これは現在のグリッチには当てはまりませんでした。同じドメインの一部のサブページが大規模な損失を被った一方で、他のサブページは利益を上げ、一部はほとんど変更されなかったためです。
したがって、彼らの最初の洞察は、それが典型的なグーグルのアップデートのようには見えなかったということでした。 ここまでは順調ですね。
今ではやや冒険的になります:
「ランキングを上げた多くのページには、科学的コンセンサスと矛盾する医療情報が含まれていました。 明確にするために、ここでは、科学的トピックに関するページのEATを決定する際に、それぞれの分野の専門知識を持つ人々または組織によって作成され、確立された科学のコンセンサスを反映する必要があると述べているGoogle品質評価者ガイドラインを参照します。存在する場所。」
この主張は、明らかに科学の状態と矛盾し、悪いまたは不自然なバックリンクを持っているいくつかの医療記事が、バグの前後よりも突然はるかに良くランク付けされたという観察によって「証明」されています。
彼らの理論は、品質の問題のために切り下げられるべきページは実際にはうまくランク付けされているというものです。 たとえば、ハッキングされたページ、不自然なリンクのあるページ、または一般的な科学的コンセンサスから逸脱した主張のあるページは、トップの位置に追いやられたでしょう。
これから、著者は次のことを推測します。
ページのランキングが向上した場合、これは喜ぶ理由である可能性があります。
失敗した将来のアップデートのテスト。 または、ページのランキングを制限したWebサイトの品質の問題を示している可能性がありますが、バグの時点では役割を果たしていなかった可能性があります。
一方、ページがランキングを下げた場合、これは、現在Googleのアルゴリズムによって再びダウングレードされている劣ったページまたはスパムページに追い抜かれたことを意味する可能性があります。
伍長! 本当に? 私の毎日のSEO作業にとって、この洞察は何が良いのでしょうか。
そのような分析をしてみませんか?
彼らが以前のクライアントのGoogleAnalyticsデータにアクセスして使用しているという事実とは別に、ここでは従業員のアプローチにはるかに大きな問題があります。
問題は、仮説のないパターンを探すと、常に何かが見つかるということです。 その後、さらにテストせずにその結果を正しいものとしてとると、それは科学とは何の関係もありません。
常にパターンがあり、場合によってはランダムであり、場合によっては1つ以上の要因によって引き起こされます。 最初にパターンを検索してから、観察したことを説明する理論を考案し、その後、それを現実として捉えることはできません。 それは知識がどのように機能するかではありません。
たとえば、仮説を立ててテストする場合など、SEOでより科学的な方法が使用されていることを本当に望んでいます。
仮説とは何ですか。また、どのようにして正しく仮説を立てますか。
仮説は、実証的研究の開始時に行われる合理的な仮定です。 この仮定は、定性的または定量的な方法を使用して分析され、確認または反証されます。
仮説を立てるときは、2つの変数間に相関があるか相関がないと仮定します。 独立変数が原因であり、従属変数が考えられる影響です。
仮説には、基本的に2つのタイプがあります。有向と無向です。
無向仮説では、2つの変数間に何らかの相関関係があると仮定するだけです。 たとえば、リンクされたWebサイトの数は、ドメインの可視性に影響を与えます。
一方、有向仮説では、推定された相関が評価されます。 例:記事の被リンクが多いほど、ランクが高くなります。
ただし、仮説を立てるには、次の基準を考慮する必要があります。
- 使用される変数は両方とも測定可能でなければなりません。
- 仮説は客観的かつ簡潔に定式化する必要があります。
- いくつかの仮説が立てられる場合、それらは互いに矛盾してはなりません。
- そして:科学的な仮定は反駁できなければなりません。
SEOの分野での仮定のほとんどは実験によって反証することができないので、科学的な観点から話す証拠はありません。 同様に、使用されたランキング要素について結論を出すために、検索クエリの結果を分析しないでください。
相関関係が因果関係と等しくないという認識は、幸いなことに近年受け入れられるようになりました。 ツールプロバイダーのランキング要因に関する研究は、今日、経験豊富なSEOによって真剣に受け止められていません。つまり、実行および公開されるSEOはますます少なくなっています。