
Apel o więcej nauki w SEO
Opublikowany: 2022-04-17- Przykra niespodzianka: to był tylko błąd!
- Więc gdzie w tym wszystkim problem?
- Czego pracownicy dowiedzieli się o usterce?
- Dlaczego nie przeprowadzić takich analiz?
- Czym jest hipoteza i jak ją poprawnie sformułować?
Prawdopodobnie już słyszeliście, ale dla tych z Was, którzy nie śledzą każdego kroku Google, oto podsumowanie:
Na początku sierpnia nastąpił ogromny wzrost fluktuacji wyników wyszukiwania w Google – na całym świecie i we wszystkich językach. Na forach webmasterów i zwykłych forach Black Hat pojawiły się natychmiastowe spekulacje na temat wprowadzenia ogromnej, niezapowiedzianej aktualizacji. Wahania i zmiany na listach wyników wyszukiwania były tak ogromne, że kilka głównych portali SEO w USA zgłosiło największą aktualizację w historii.
W rzeczywistości wszystkie narzędzia SEO i kontrolery rankingu zostały nagle dotknięte ogromnymi zmianami w wynikach wyszukiwania Google. Wyniki wyszukiwania nie tylko się zmieniły; odwracali się do góry nogami, czasami z absurdalnymi wynikami wypełniającymi najwyższe pozycje.
Skutki błędu widać bardzo wyraźnie w indeksie dziennej widoczności:
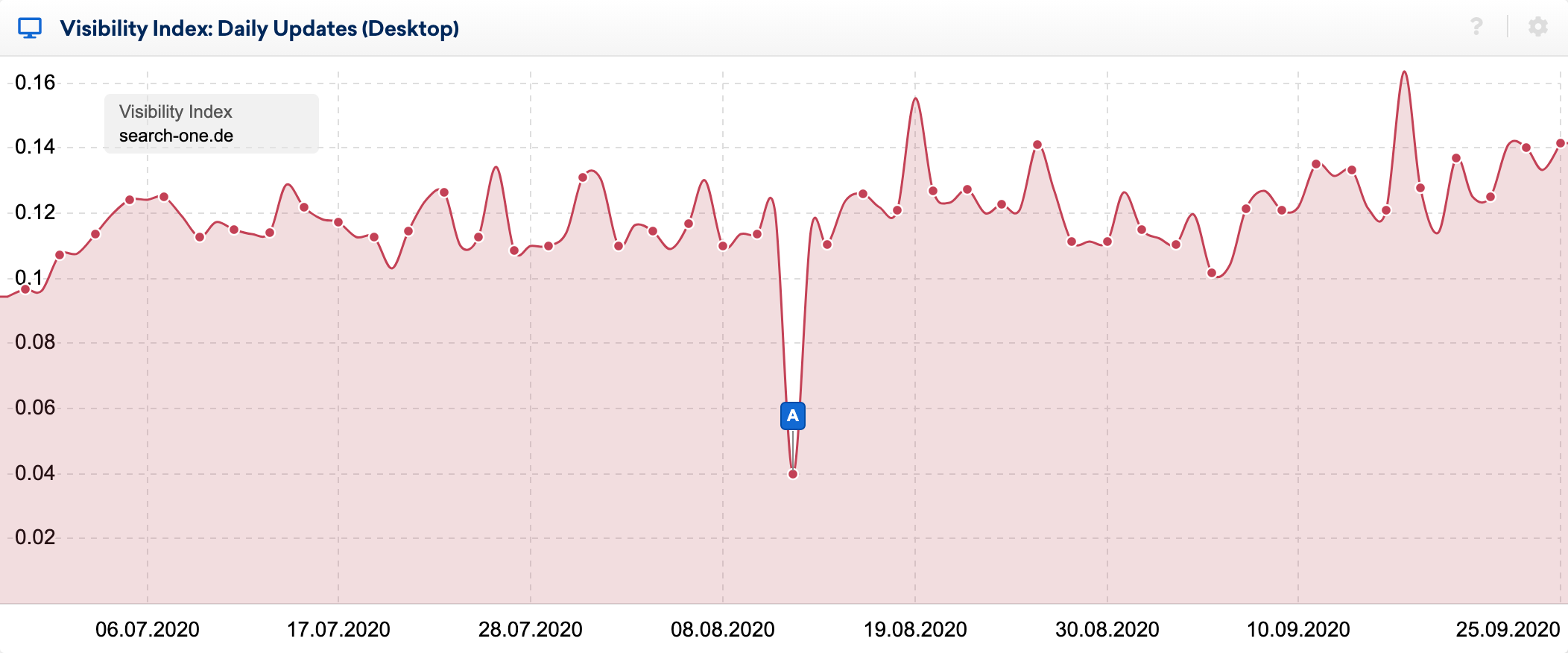
Korzystając ze świetnej funkcji porównywania SERP w zestawie narzędzi SISTRIX, przyjrzałem się bliżej zmianom w top 20 niektórych słów kluczowych, których rankingi obserwuję od wielu lat. Przeprowadziłem dziesiątki analiz rankingowych witryn pod kątem tych słów kluczowych i zwykle stosunkowo dobrze wiem, dlaczego adres URL znajduje się tam, gdzie się znajduje.
Jeśli spojrzysz na porównanie SERP dla słowa kluczowego „optymalizacja google” w danym momencie, zobaczysz, że cała pierwsza 20, z wyjątkiem jednego adresu URL, uległa całkowitej zmianie. To, co wcześniej znajdowało się na 1. miejscu, spadło na 8. miejsce , a pozostałe adresy URL pojawiły się znikąd, tj. spoza pierwszej dwudziestki na najwyższe miejsca.
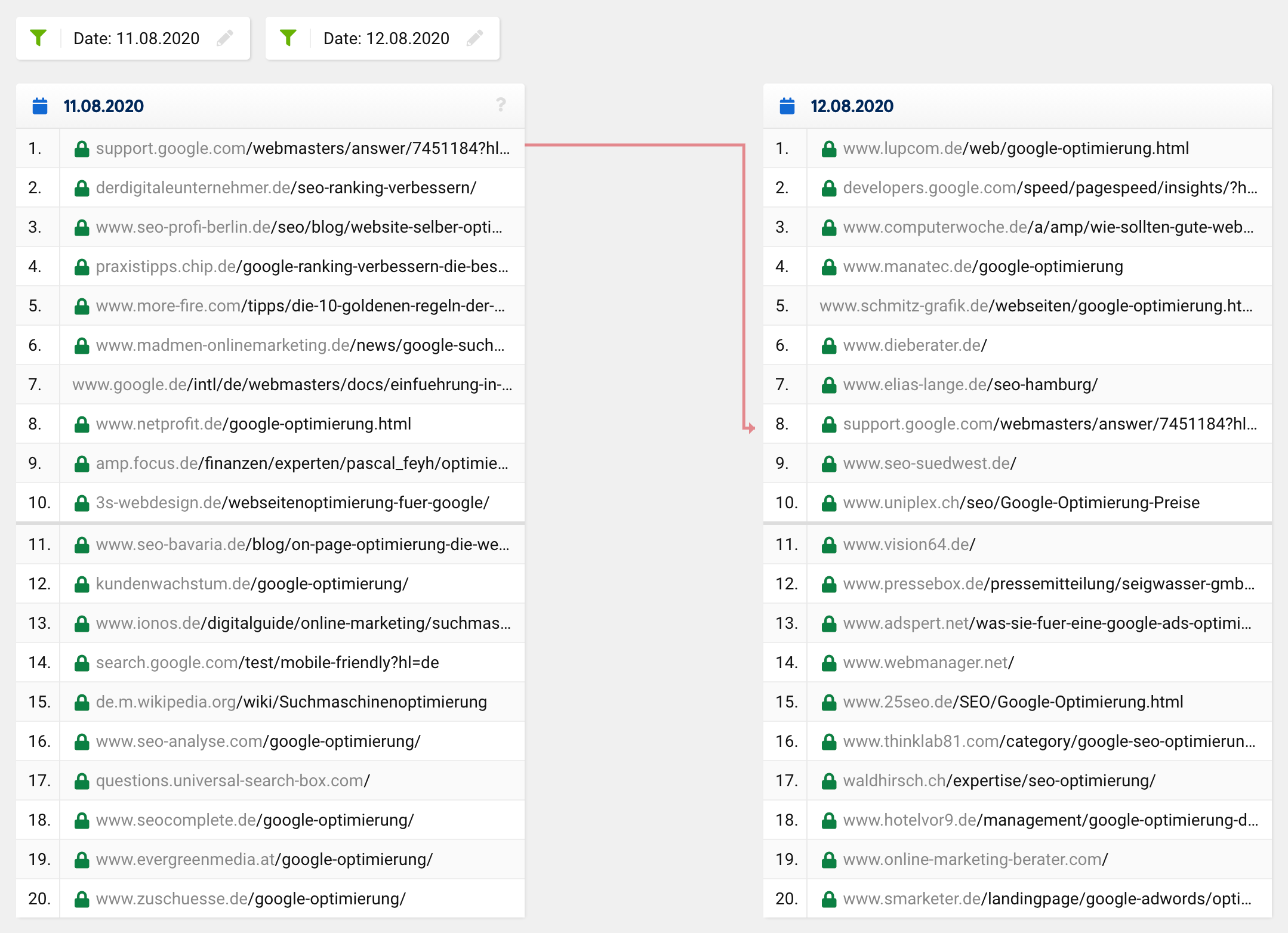
Normalna aktualizacja lub zwykła zmiana rankingu zwykle wyglądałaby mniej więcej tak:

Wiele adresów URL pozostaje takich samych, podczas gdy niektóre adresy URL przesuwają się w górę, a inne w dół. Oczywiście czasami adres URL znika z pierwszej dwudziestki lub przesuwa się do niej. Jednak niezwykle rzadko zdarza się, że z 20 trafień tylko jeden pozostaje w „nowej” pierwszej dwudziestce – tak było we wszystkich przypadkach, nie tylko w przypadku jednego konkretnego słowa kluczowego.
Biorąc pod uwagę tak daleko idące zmiany, podobne do głośnych aktualizacji fantomowych, można by się spodziewać korekty w założonych zamiarach użytkownika w zapytaniu, co z kolei doprowadziłoby do fundamentalnych zmian w składzie top 20 dla niektórych słów kluczowych. W takim przypadku jednak wyniki wyszukiwania poprawiłyby się, tj. stałyby się bardziej trafne i znaczące, co oczywiście nie miało miejsca w przypadku tej usterki.
Zdecydowana większość SEO była zaskoczona absurdalnymi wynikami wyszukiwania i stosunkowo szybko założyła, że wystąpił błąd – a przynajmniej miała nadzieję, że to tylko przejściowy problem. Czułem się tak samo, ponieważ niektóre z moich witryn całkowicie straciły swoje najważniejsze rankingi w ciągu kilku godzin!
Przykra niespodzianka: to był tylko błąd!
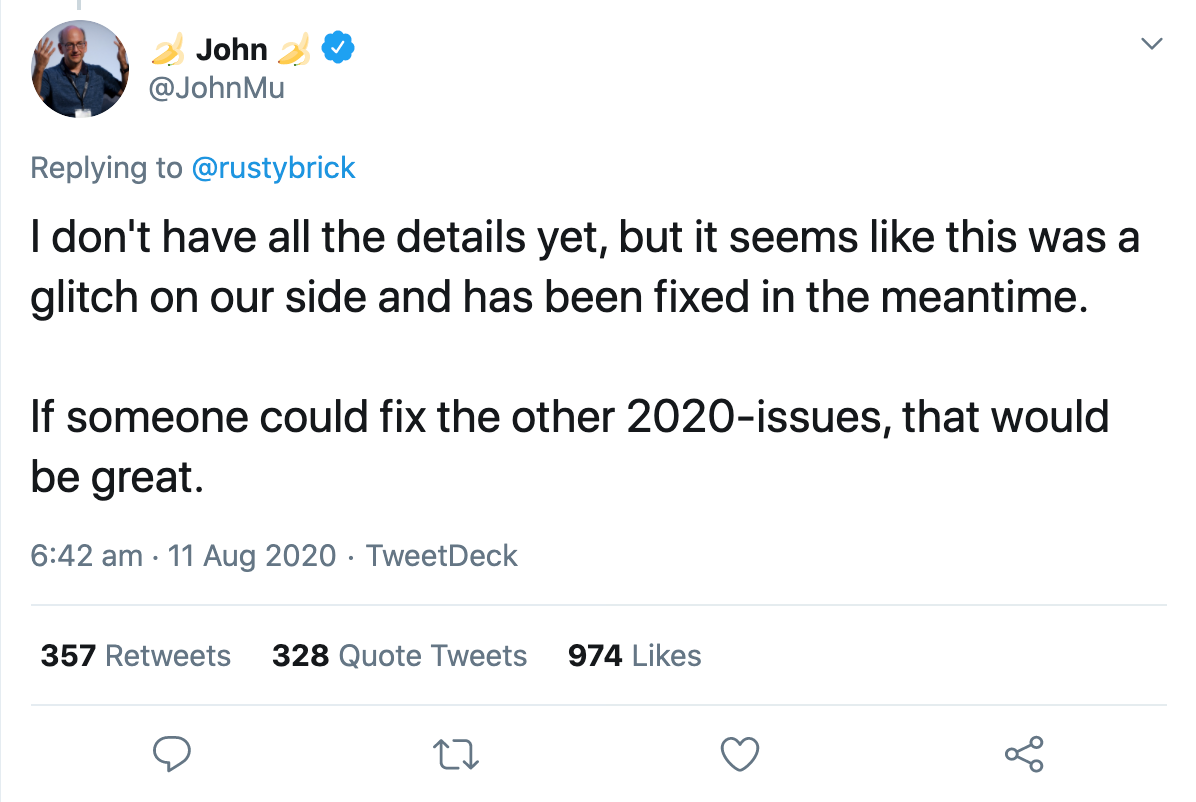
Tej samej nocy rzecznik Google potwierdził, że był to błąd, który naprawiali. W ciągu kilku godzin wszystko wróciło do normy. John Muller potwierdził na Twitterze, że błąd został naprawiony, ale nie zna jeszcze wszystkich szczegółów:
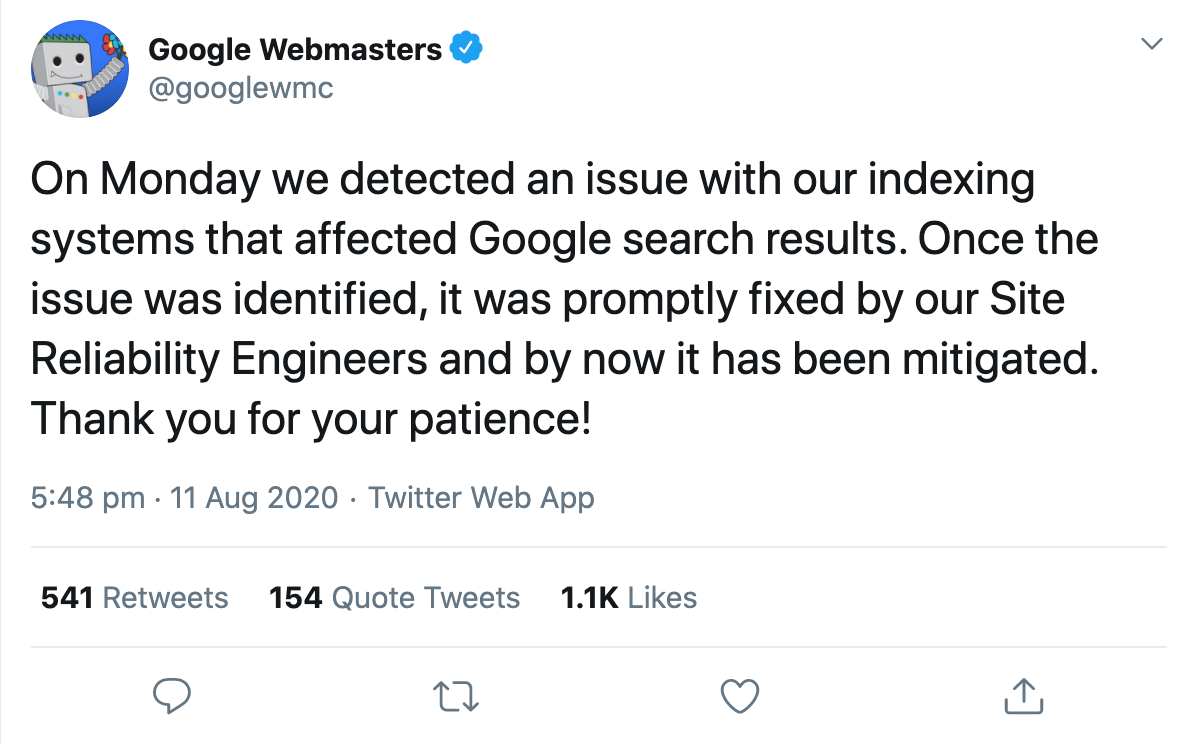
Zaledwie dzień później oficjalne konto Google dla webmasterów potwierdziło, że w wynikach wyszukiwania wystąpił widoczny problem z systemem indeksowania.
I tutaj ludzie zaczęli spekulować, co dokładnie mogło się wydarzyć.
Gary Illyes spróbował uczynić rzeczy bardziej konkretnymi, opisując, co tak naprawdę robi system indeksowania, Kofeina. Według jego tweeta, pozyskuje on logi pobierania, renderuje i konwertuje pobrane dane, wyodrębnia linki, meta i dane strukturalne, wyodrębnia i oblicza niektóre nienazwane sygnały, planuje nowe indeksowanie i buduje indeks, który jest wysyłany do udostępniania. Aby to ułatwić, podał kilka przykładów tego, co może pójść nie tak, co następnie znalazło odzwierciedlenie w zmienionych wynikach wyszukiwania:
„Jeśli planowanie indeksowania się nie powiedzie, indeksowanie może spowolnić. Jeśli renderowanie się nie powiedzie, Google może źle zrozumieć strony. Jeśli budowanie indeksu pójdzie źle, może to wpłynąć na ranking i serwowanie”.
Następnie podkreślił, jak złożone jest wyszukiwanie i że tysiące połączonych systemów musi bezbłędnie współpracować, aby dostarczać użytkownikom trafne wyniki. Jeśli do maszyny wrzuci się ziarnko piasku, rezultatem będzie awaria, tak jak wczoraj.

Zapytany przez użytkownika Twittera stwierdził, że najwyraźniej wystąpił błąd w budowie samego indeksu:
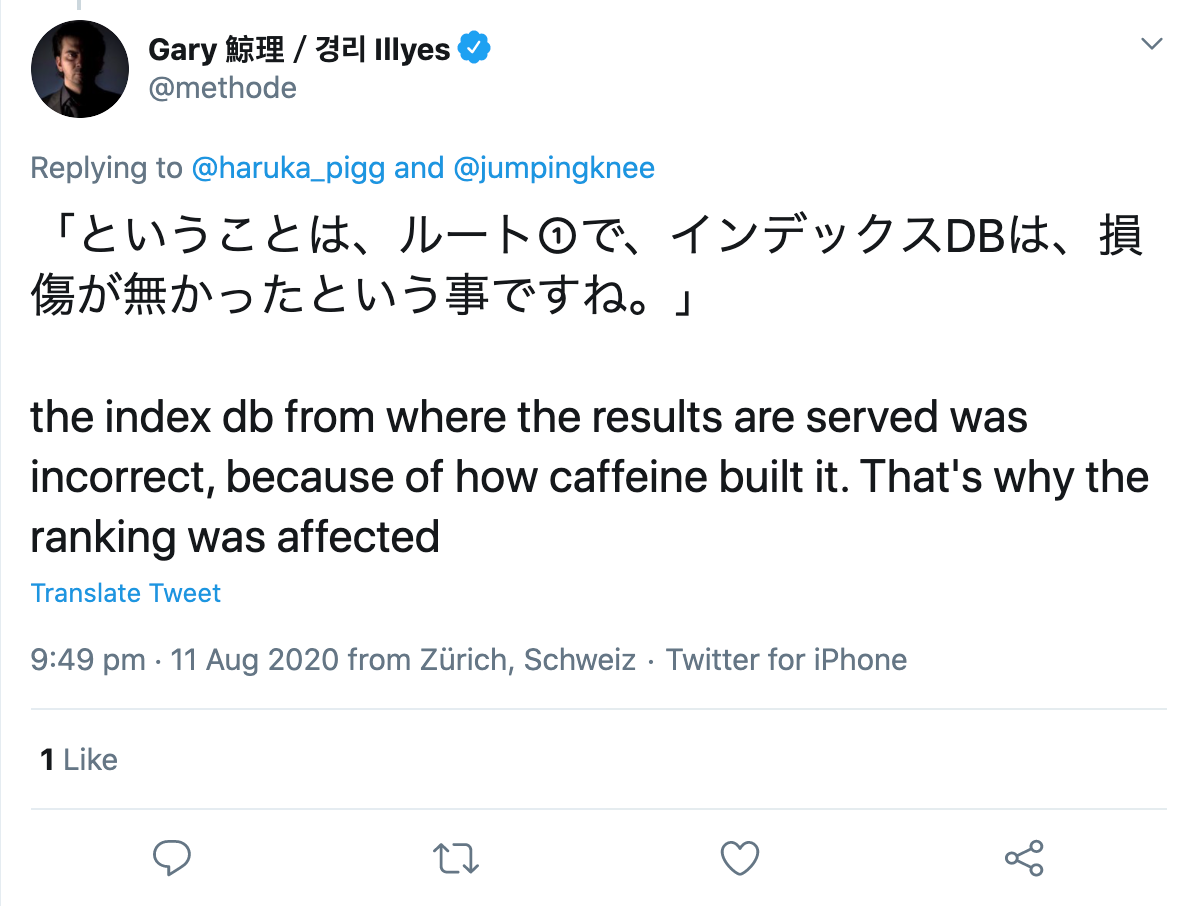
Więc gdzie w tym wszystkim problem?
Sam błąd mnie nie denerwował, ponieważ to kwestia godzin, zanim Google naprawi problem. Jednak niektóre komentarze i publikacje na ten temat później mnie rozzłościły.
Chociaż Google ujawnił problem stosunkowo przejrzyście, niektórzy SEO próbowali zrozumieć błąd za pomocą haka lub oszusta i zaczęli badać zmiany w poszukiwaniu wzorców. Pracownik znanej amerykańskiej agencji SEO, którego nie chcę w tym miejscu ujawniać, zaczął analizować dane Google Analytics każdego obecnego i byłego klienta i próbował wyciągnąć wnioski na temat przyczyn zmian w rankingu.
Uważam to za przekroczenie linii z kilku powodów, ale o tym później.
Czego pracownicy dowiedzieli się o usterce?
W przypadku regularnych aktualizacji Google zmiana dotyczyłaby zwykle wszystkich podstron w domenie, zarówno pozytywnych, jak i negatywnych. Nie było tak w przypadku obecnej usterki, ponieważ podczas gdy niektóre podstrony tej samej domeny poniosły ogromne straty, inne zyskiwały, a niektóre prawie się nie zmieniły, jeśli w ogóle.
Ich pierwszym spostrzeżeniem było zatem to, że nie wyglądało to na typową aktualizację Google. Jak na razie dobrze.
Teraz staje się nieco ryzykowne:
„Wiele stron, które znalazły się wyżej w rankingach, zawierało informacje medyczne sprzeczne z konsensusem naukowym. W celu wyjaśnienia odsyłamy do wytycznych Google Quality Rater, które stanowią, że przy określaniu EAT strony o tematyce naukowej powinna ona być tworzona przez osoby lub organizacje posiadające wiedzę specjalistyczną w danej dziedzinie i powinna odzwierciedlać ustalony konsensus naukowy, tam, gdzie istnieje”.
To twierdzenie jest „udowodnione” przez obserwację, że kilka artykułów medycznych, które oczywiście są sprzeczne ze stanem nauki, a także mają złe lub nienaturalne linki zwrotne, nagle uplasowały się znacznie lepiej niż przed i po błędzie.
Ich teoria głosi, że strony, które powinny zostać zdewaluowane z powodu problemów z jakością, faktycznie mają dobrą pozycję w rankingu. Na przykład zhakowane strony, strony z nienaturalnymi linkami lub strony z twierdzeniami odbiegającymi od ogólnego konsensusu naukowego zostałyby wyrzucone na najwyższe pozycje.
Z tego autor wyprowadza następujące wnioski:
Jeśli ranking strony poprawi się, może to być powód do radości, a może po prostu
test na przyszłą aktualizację, która poszła nie tak. Lub może to wskazywać na problem z jakością strony internetowej, który ograniczył pozycję strony w rankingu, ale mógł nie odgrywać żadnej roli w momencie wystąpienia błędu.
Z drugiej strony, jeśli strona spadła w rankingu, może to oznaczać, że wyprzedziły Cię gorsze lub spamerskie strony, które ponownie są obecnie obniżane przez algorytmy Google.
Uffz! Naprawdę? Jaki dobry jest ten wgląd w moją codzienną pracę SEO?!
Dlaczego nie przeprowadzić takich analiz?
Poza tym, że nadal mają dostęp i korzystają z danych Google Analytics byłych klientów, widzę tu znacznie większy problem z podejściem pracownika:
Problem w tym, że jeśli szukasz wzorców bez hipotezy, zawsze coś znajdziesz. Jeśli następnie uznasz ten wynik bez dalszych badań za poprawny, nie ma on nic wspólnego z nauką.
Zawsze istnieją wzorce, czasem przypadkowe, czasem spowodowane jednym lub kilkoma czynnikami. Nie możesz najpierw szukać wzorców, a następnie wymyślić teorię wyjaśniającą to, co obserwujesz, a następnie przyjąć to jako rzeczywistość. Po prostu tak nie działa wiedza.
Naprawdę chciałbym zobaczyć więcej naukowych metod stosowanych w SEO, na przykład jeśli chodzi o stawianie hipotez, a następnie ich testowanie!
Czym jest hipoteza i jak ją poprawnie sformułować?
Hipoteza jest rozsądnym założeniem stawianym na początku badania empirycznego. Założenie to jest analizowane metodami jakościowymi lub ilościowymi, a następnie potwierdzane lub obalane.
Stawiając hipotezę, zakładasz korelację lub brak korelacji między dwiema zmiennymi . Zmienna niezależna jest przyczyną, zmienna zależna jest możliwym skutkiem.
Zasadniczo istnieją dwa rodzaje hipotez: skierowana i nieukierunkowana.
W przypadku hipotezy nieskierowanej zakładasz jedynie, że istnieje pewna korelacja między dwiema zmiennymi. Na przykład liczba stron, do których prowadzą linki, wpływa na widoczność domeny.
Natomiast przy hipotezie ukierunkowanej oceniana jest zakładana korelacja. Na przykład: im więcej linków zwrotnych ma artykuł, tym lepsza jest jego pozycja.
Aby jednak postawić hipotezę, należy wziąć pod uwagę następujące kryteria:
- Obie użyte zmienne muszą być mierzalne.
- Hipotezy muszą być formułowane obiektywnie i zwięźle.
- Jeśli sformułowanych jest kilka hipotez, nie mogą one być ze sobą sprzeczne.
- Oraz: Założenia naukowe muszą być możliwe do obalenia.
Ponieważ większości założeń z zakresu SEO nie da się obalić eksperymentem, nie ma dowodów, o których można by mówić z naukowego punktu widzenia. Podobnie nie powinieneś analizować wyników jakichkolwiek zapytań w celu wyciągnięcia wniosków na temat użytych czynników rankingowych.
Świadomość, że korelacja nie równa się przyczynowości, została na szczęście zaakceptowana w ostatnich latach. Badania nad czynnikami rankingowymi dowolnego dostawcy narzędzi nie są już dziś traktowane poważnie przez żadnego doświadczonego SEO, co oznacza, że coraz mniej z nich jest przeprowadzanych i publikowanych.