Что такое канонический тег и как его использовать
Опубликовано: 2022-04-17- Определение и значение
- Номенклатура, соображения и ошибки, которых следует избегать
- Процедуры реализации
- HTML-тег
- HTTP-заголовок
- Другие сигналы: карта сайта и внутренние ссылки
- Эффект и SEO-кейсы
- Как анализировать или проверять канонические теги
- Исследуйте исходный код
- Инструменты разработчика Chrome
- В консоли поиска Google
- Как анализировать канонические теги с помощью SISTRIX Toolbox Optimizer
- Сканирование и обнаружение предупреждений
- Проводник URL: анализ отдельных URL-адресов
- Экспертный режим
Определение и значение
Канонический тег — это элемент HTML, который мы используем, чтобы сообщить Google, что 2 или более URL-адреса на нашем веб-сайте дублируются, похожи или идентичны.
Этот тег позволяет нам «выбрать», какой из нескольких URL-адресов должен отображаться в поисковой выдаче, чтобы помочь Google решить, какую страницу он должен в конечном итоге показать в результатах. Другими словами, мы предоставляем Google сигнал, указывающий предпочтительную версию для индексации .
Помимо усиления этого сигнала индексации, он также объединяет наши внутренние ссылки , указывающие с URL-адреса источника на целевой канонический URL-адрес.
Что касается дублированного контента и различных мифов, циркулирующих в отрасли, то нет лучшего способа прояснить ситуацию, чем процитировать официальные источники и ссылки, исходящие от самого Google:
«Давайте покончим с этим раз и навсегда, ребята: не существует такого понятия, как «штраф за дублирование контента». По крайней мере, не в том смысле, в каком большинство людей имеют в виду, когда говорят это. Вы можете помочь своим коллегам-веб-мастерам, не поддерживая миф о штрафах за дублированный контент!»
Сьюзан Моска
https://webmasters.googleblog.com/2008/09/demystifying-duplicate-content-penalty.html
«Повторяющийся контент обычно относится к существенным блокам контента внутри или между доменами, которые либо полностью соответствуют другому контенту, либо заметно похожи. В основном это не обманчивое происхождение».
https://developers.google.com/search/docs/advanced/guidelines/duplicate-content
Номенклатура, соображения и ошибки, которых следует избегать
Вот основные соображения относительно канонической директивы и способов ее определения:
- Канонический может быть самореференциальным, особенно на домашней странице, поскольку он может иметь несколько точек доступа, созданных CMS или самим сервером (например, index.html).
- Канонический должен использоваться всякий раз, когда есть две части контента, которые похожи, дублируют или, другими словами, полностью или частично идентичны. В противном случае этот тег можно игнорировать.
- Канонический должен указывать на индексируемый URL, возвращать 200 OK и не иметь тега noindex . Еще одна вещь, о которой стоит упомянуть, это то, что мы не должны отправлять канонический URL на нерелевантный URL, потому что он будет интерпретирован как Soft 404.
- Для каждого URL должен быть только один уникальный канонический. Если есть два разных канонических тега, они могут столкнуться, и оба в конечном итоге будут проигнорированы.
- Канонический может использовать абсолютные и относительные URL-адреса. Однако важно отметить, что относительные URL-адреса подвержены ошибкам и недосмотру.
- Канонический тег может быть проигнорирован, если есть явные ошибки, с точки зрения их правописания или другие непреднамеренные ошибки. Могут быть и другие сигналы, которые будут проанализированы, чтобы определить, следует ли соблюдать или игнорировать канонический тег.
- Канонический тег также можно игнорировать, если мы посылаем запутанные сигналы, например, ссылаемся на канонический с url1 на url2, а затем с url2 на url1. Попадание в такие «петли» может привести к неожиданному поведению.
- Канонический может быть междоменным, т.е. указывать от домена1 к домену2. Его следует использовать — предпочтительно — когда у нас есть контроль над обоими доменами, и мы хотим предпочесть индексацию одного домена другому, чтобы предотвратить дублирование. Будьте осторожны с этим.
- Другим примером может быть синдикация контента.
При условии, что он решает ситуации дублирования контента между страницами, некоторые из наиболее типичных случаев, когда нам придется иметь дело с этим, следующие:
- URL-адреса с www и URL-адреса без www
- URL-адреса с http против URL-адресов с https
- URL-адреса, заканчивающиеся на /, и URL-адреса, не заканчивающиеся на / (не считая домашней страницы)
- URL-адреса с параметрами и URL-адреса без параметров (например, URL-адреса с идентификаторами сеанса).
- URL-адреса с нумерацией страниц и URL-адреса без нумерации страниц
- URL-адреса с AMP и URL-адреса без AMP (в качестве обязательной разметки).
- Мобильные URL-адреса (мобильные сайты) и URL-адреса настольных компьютеров
- Предварительные (постановочные) URL-адреса по сравнению с рабочими (производственными) URL-адресами (в любом случае, лучше не допускать Google к подготовке для HTTP-логина)
- И т. д.
Хотя все эти ситуации можно было бы решить с помощью канонических тегов, для Google есть другой, более прямой метод: 301 редирект .
Вы прочтете множество сравнений 301 и канонических тегов. Мы не собираемся слишком углубляться в это, но мы собираемся подчеркнуть наиболее важные моменты, касающиеся этого вопроса, на изображении ниже:
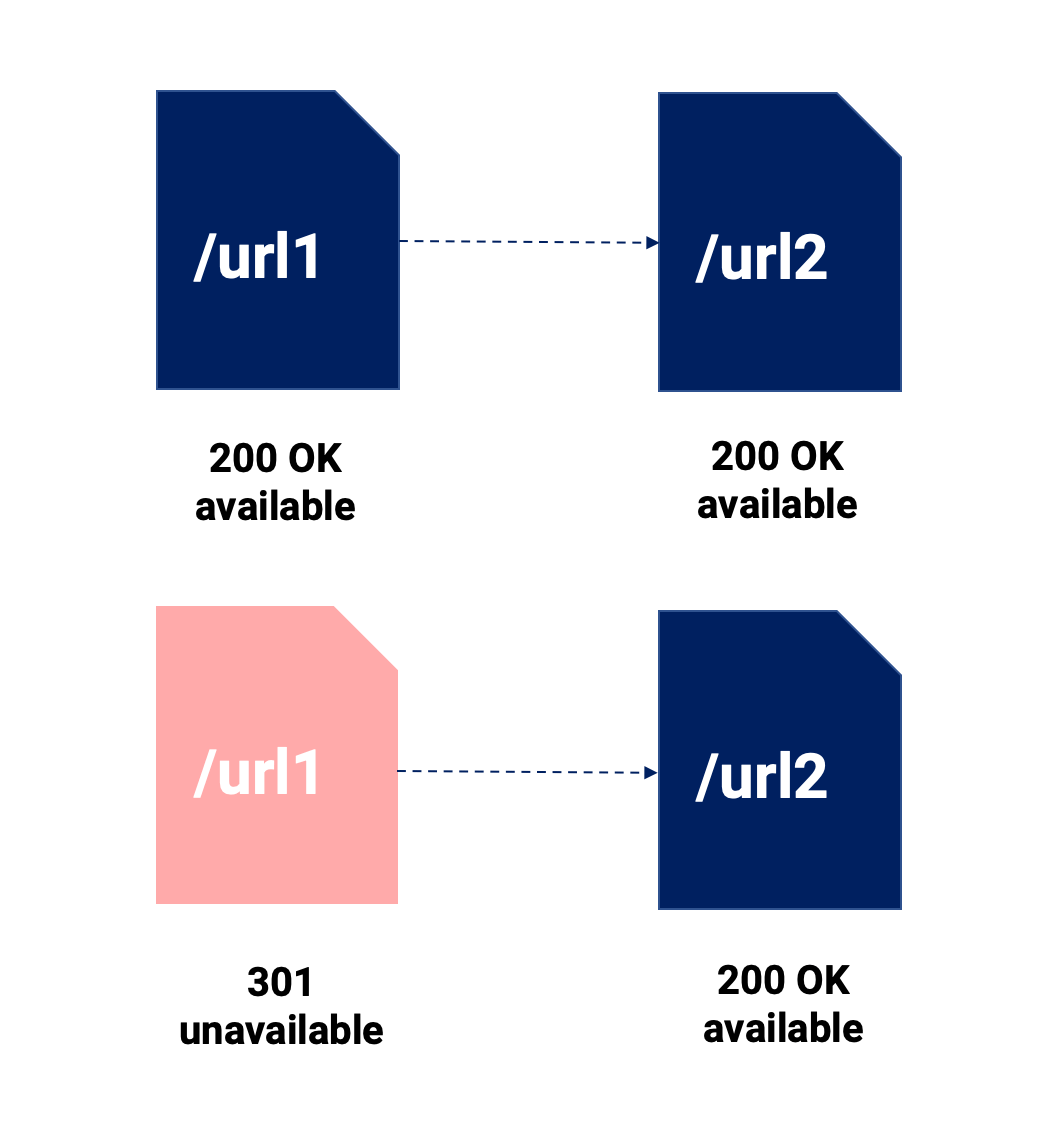
Используя это визуальное резюме, мы хотим выделить следующие вещи:
- 301 редирект объединяет две части контента, что означает, что исходный контент перестает существовать. Это прямое и на 100% сопровождаемое Google (и пользователями).
- Канонический, он позволяет нам сохранять доступными различные URL-адреса для любого канала, и если Google соблюдает директиву, только канонизированный URL-адрес будет проиндексирован для SEO-канала.
- И то, и другое может привести к разбавлению сигнала, и это может иметь более значительный эффект, если мы не используем перенаправление 301, поскольку канонизированные URL-адреса могут иметь внутренние и внешние ссылки, указывающие на них, что вынуждает нас разделять наши усилия между несколькими URL-адресами.
Процедуры реализации
Существует несколько способов реализации канонических тегов:
HTML-тег
Самый распространенный способ реализовать каноническую версию – разместить элемент ссылки с атрибутом rel="canonical" и абсолютным путем к канонической версии в <head> каждого URL-адреса. Вот правильный синтаксис:
<link rel="canonical" href="https://www.sistrix.com/ask-sistrix/what-is-the-canonical-tag-and-how-to-use-it/" />HTTP-заголовок
Этот метод обычно используется на страницах, отличных от HMTL. Например: файлы PDF, XML или TXT.
Это типичный метод, используемый, когда у нас есть и PDF-файл, и соответствующая HTML-страница. С помощью канонического мы можем показать Google, что мы хотим, чтобы HTML-страница ранжировалась.
Тем не менее, учитывая разнообразие возможных случаев, мы рекомендуем этот пост, описывающий более техническую реализацию через файл .htaccess.
<Files "seo-guide.pdf"> Header add Link "< http://www.sistrix.com/seo-guide/ >; rel=\"canonical\"" </Files>Другие сигналы: карта сайта и внутренние ссылки
В этом случае мы не собираемся реализовывать каноническую директиву, но мы неявно заявляем, что этот URL (в отличие от других его версий) является исходным и имеет больший вес и ценность.
Такие простые вещи, как добавление URL-адресов в карту сайта или ссылка на URL -адрес из навигации по веб-сайту, уже имеют неявную и неявную важность , поэтому мы в значительной степени посылаем SEO-сигнал о важности этой версии URL для нас. Если мы противоречим сами себе или есть другие двусмысленные или неубедительные сигналы, мы нарушаем закон простоты в SEO : не усложняйте для Google больше, чем он уже есть.
- С 2 повторяющимися URL-адресами с использованием канонических ссылок исходный URL-адрес будет включен в карту сайта, а канонизированный — нет.
- С двумя повторяющимися URL-адресами, использующими канонические ссылки, исходный URL-адрес будет заметно связан, а канонизированный не будет (хотя это не всегда возможно, и канонизированный URL-адрес может иметь ссылку, указывающую на него).
Эффект и SEO-кейсы
Самое большое влияние, которое может иметь использование канонического, заключается в том, что после того, как Google будет его уважать, URL-адрес, на который указывает канонический тег, станет индексируемым , и тот, кто выдает канонический тег, уйдет в отставку и пожертвует собой, чтобы более оригинальный контент мог получить индексацию.

С другой стороны, если URL-адрес, выдающий канонический, получает внутренние ссылки где-то в структуре навигации, Google сможет просканировать эту страницу и потратить на нее время . Это должно серьезно заставить нас задуматься о совместном использовании Robots.txt (даже «noindex») и канонического. Если мы хотим сэкономить наш краулинговый бюджет, возможно, мы можем помешать Google понять, где находится дубликат и его канонический код.
Говоря о более частных случаях, можно указать немного больше:
- Пассивные параметры : используются в качестве меры предосторожности в сочетании с управлением параметрами Google Search Console. Однако эти параметры используются для маркировки кампаний (платных, электронных, социальных…).
- Активные параметры : язык, фильтры. Ключевым моментом здесь является определение того, какие из них имеют минимально оригинальный контент, который мы можем позиционировать, кроме того, чтобы точно знать, реагируют ли они на намерение поиска. Дополнительными проблемами могут быть внутренние ссылки и растрата полномочий через внутренние ссылки этих фильтров.
- Пагинация : текущий сценарий в отношении нумерации страниц сам по себе является спорным. Google удалил руководство rel prev rel next, и теперь мир SEO обсуждает, следует ли нам использовать noindex, канонический переход на первую страницу, бесконечную прокрутку или динамические технологии, такие как AJAX, чтобы поддерживать функциональность для пользователя без создания новых страниц/ссылок. в зависимости от случая. Это совсем не тривиальное решение.
- Страницы продуктов с похожими атрибутами (цвет, размер) . Как и в случае с фильтрами, нам нужно определить, когда их контент не является минимально оригинальным для ранжирования, и нам нужно знать, реагируют ли они на намерение поиска. Следует помнить о правиле «то, что не ищут, не индексировать» .
Как анализировать или проверять канонические теги
Теперь мы приступим к тому, как идентифицировать или проверять канонические теги. У нас есть методы на любой вкус:
Исследуйте исходный код
Посетите страницу и щелкните правой кнопкой мыши в любом месте страницы, чтобы открыть меню с параметром «Просмотр исходного кода страницы» (Control + U, если вы используете Windows; CMD + Alt + U, если вы используете Mac).
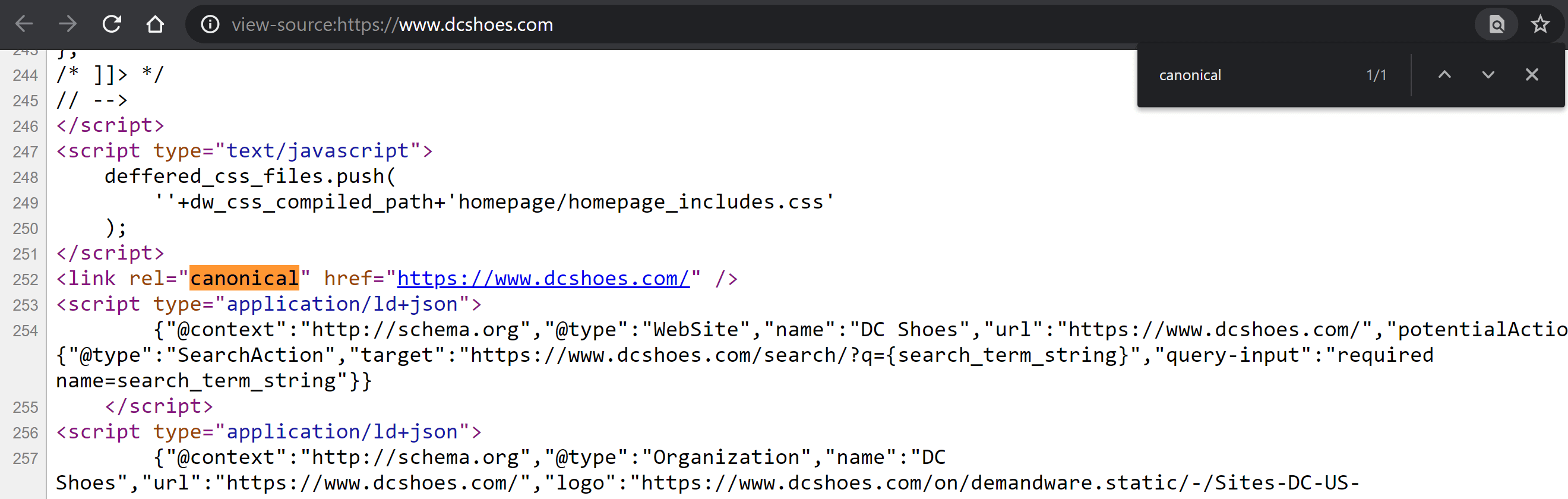
Оказавшись внутри, нажмите Control + F в Windows или CMD + F на Mac, чтобы выполнить поиск по коду. Введите «canonical», чтобы тег стал выделен другим цветом, если он есть. Сравните его содержимое и определите, правильно ли определено это значение.
Инструменты разработчика Chrome
Используя Chrome, мы можем открыть веб-сайт, который хотим проанализировать, щелкнуть правой кнопкой мыши по экрану и нажать «Проверить». Это откроет инструменты разработчика, где мы можем искать тег с помощью Control + F или Cmd + F, как мы делали в предыдущем пункте.
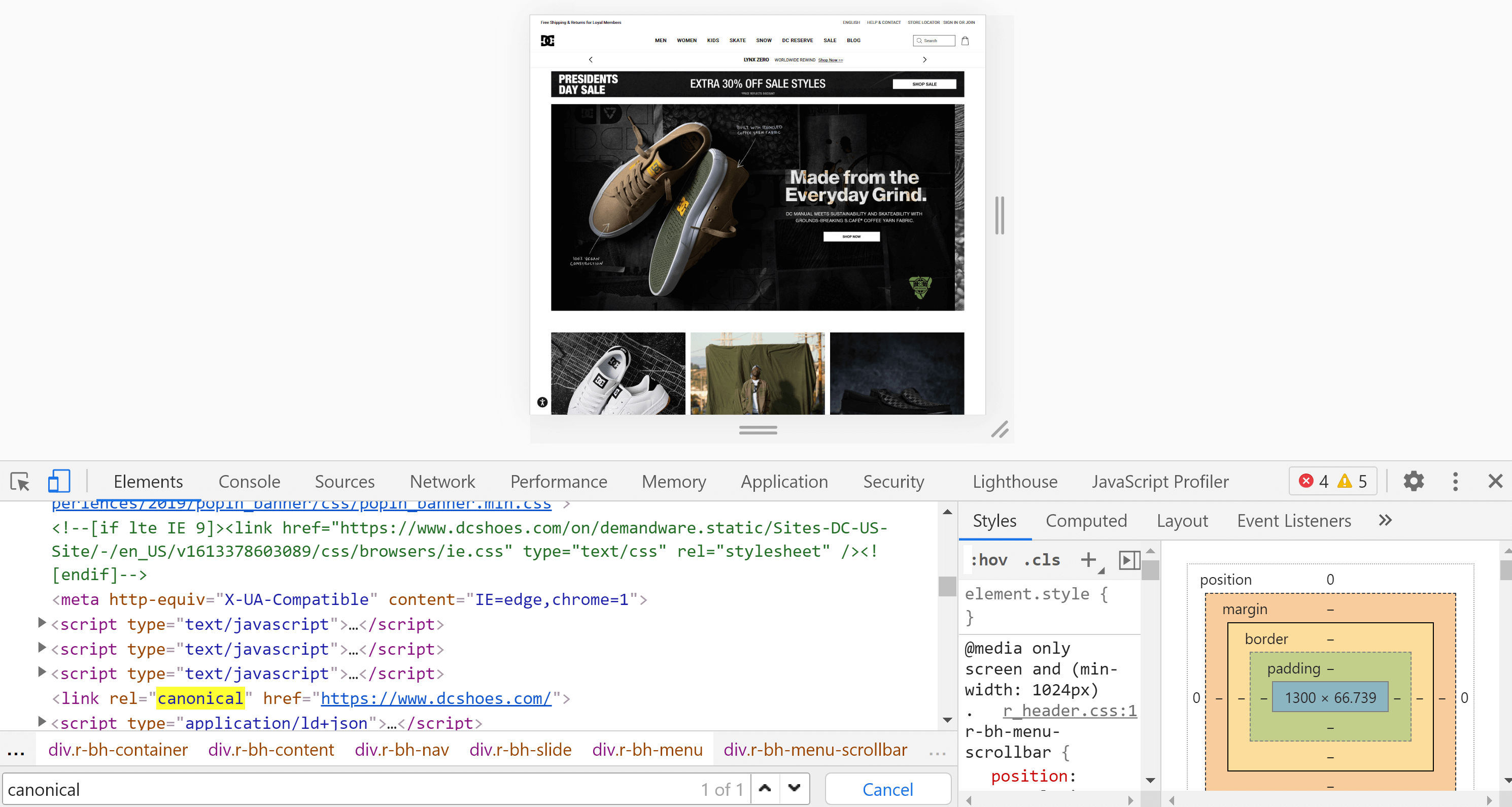
Основное различие между исходным кодом страницы и инспектором заключается в том, что второй уже отрисовал страницу, и мы видим содержимое после завершения этого процесса (включая выполнение JavaScript).
В качестве альтернативы мы можем использовать консоль , перейдя на вкладку «Консоль» и введя следующую команду:
$$('ссылка[rel="canonical"]')[0] 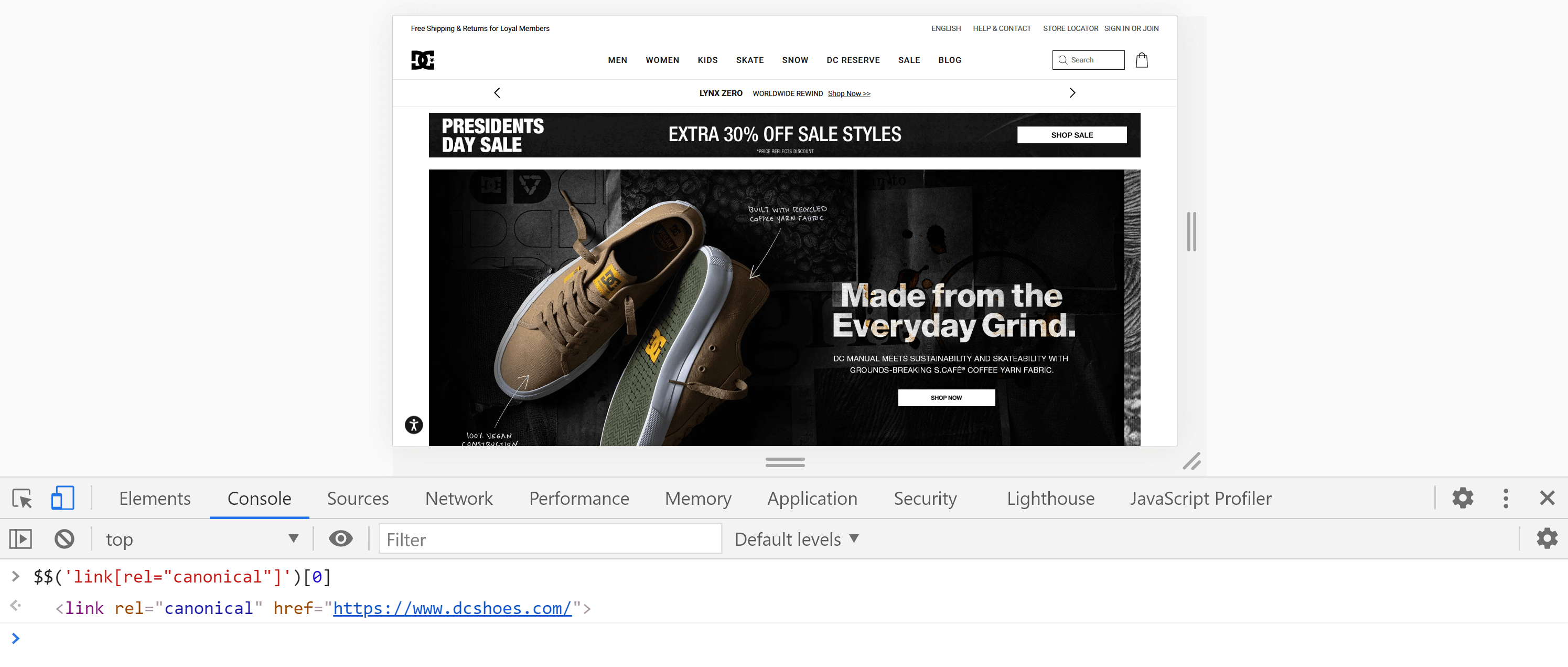
В консоли поиска Google
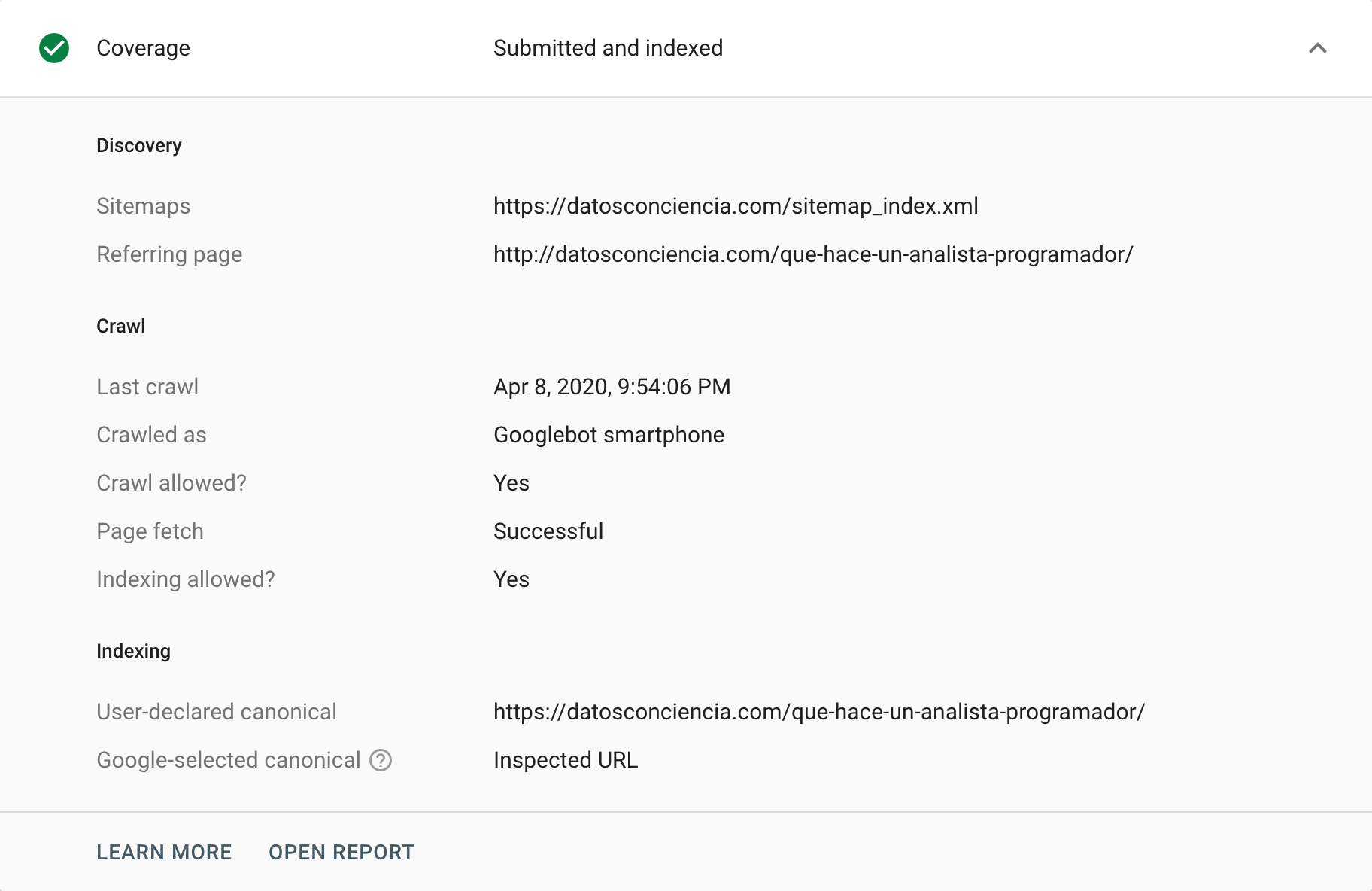
Google Search Console предоставляет различные способы анализа или аудита канонических тегов. Один из способов сделать это — перейти к отчету «Покрытие» , где мы можем проанализировать любое событие, ответственное за исключение определенных URL-адресов из его индекса. В этом разделе «Исключено» мы иногда можем найти ситуации, связанные с каноническими тегами, как в правильных, так и в неправильных случаях (правильно и неправильно интерпретированных). Несомненно, это идеальный способ начать тянуть за ниточку, которая поможет нам выявить проблемы.

С другой стороны, у нас есть инструмент проверки URL -адресов, который может предоставить информацию о канонических тегах отдельных URL-адресов. Мы можем попросить его просканировать их и вернуть их статус, особенно если есть разница между нашей инструкцией и тем, что Google решит интерпретировать.
Как анализировать канонические теги с помощью SISTRIX Toolbox Optimizer
Существует несколько способов анализа канонических значений с помощью оптимизатора SISTIX Toolbox Optimizer.
Сканирование и обнаружение предупреждений
Будучи сканером, Optimizer посещает ваш веб-сайт, чтобы определить возможности для улучшения, ошибки и другие аспекты, о которых вы будете проинформированы в простой и наглядной форме, поэтому вам не придется тратить время на обработку данных. Вот пример, связанный с каноническими тегами, о которых оптимизатор уведомит вас (если вы ошибетесь):

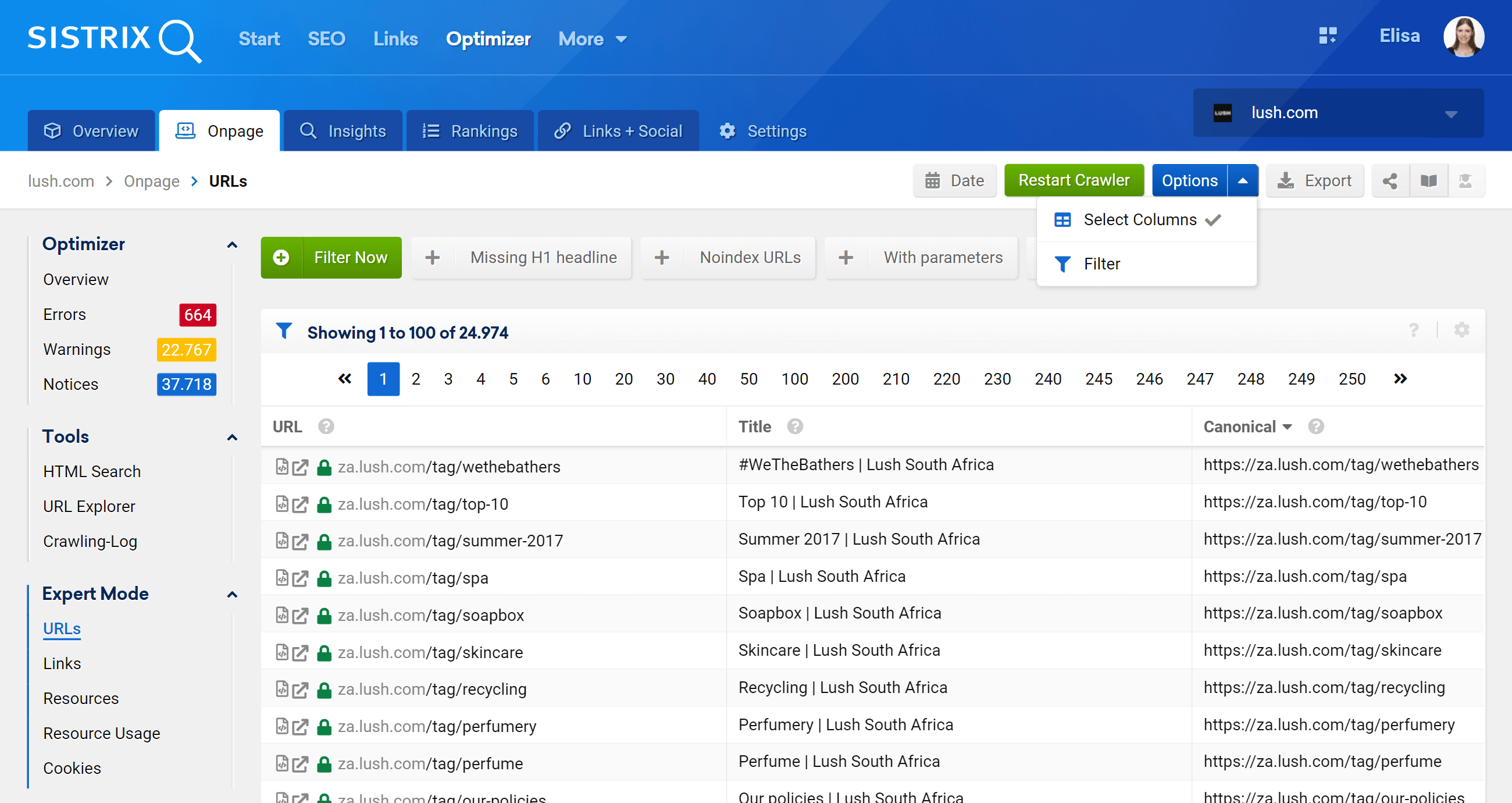
Проводник URL: анализ отдельных URL-адресов
Эта функция аналогична инструменту проверки URL-адресов Google Search Console, что означает, что вы сможете оценивать отдельные URL-адреса, которые были просканированы в вашем проекте оптимизатора, и просматривать информацию для этого конкретного URL-адреса.
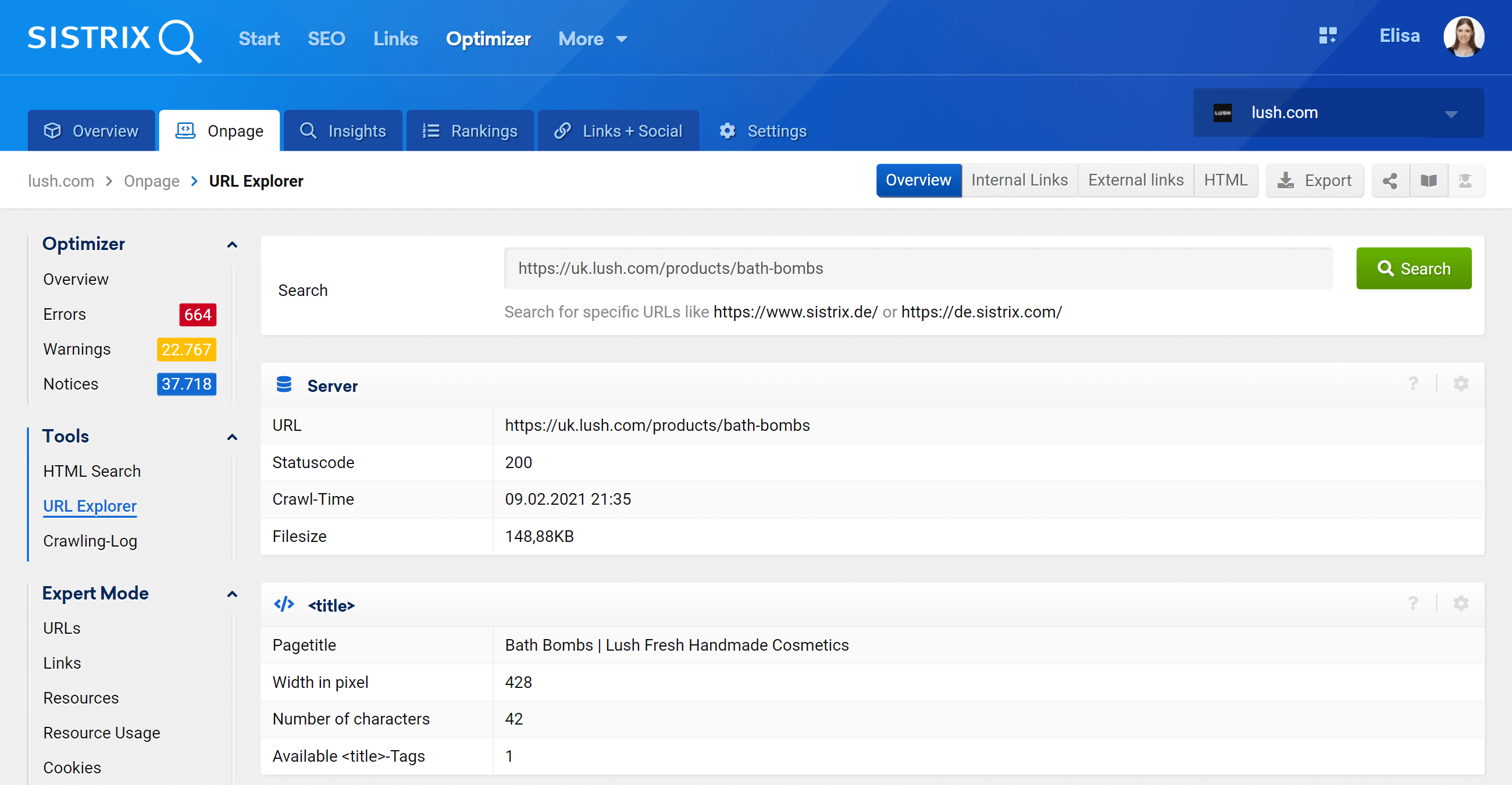
Как видите, мы можем проанализировать все аспекты на странице, касающиеся этого URL-адреса, как входящие, так и исходящие внутренние ссылки, информацию о сервере, теги SEO, и здесь вы также найдете каноническую реализацию, о которой идет речь. .
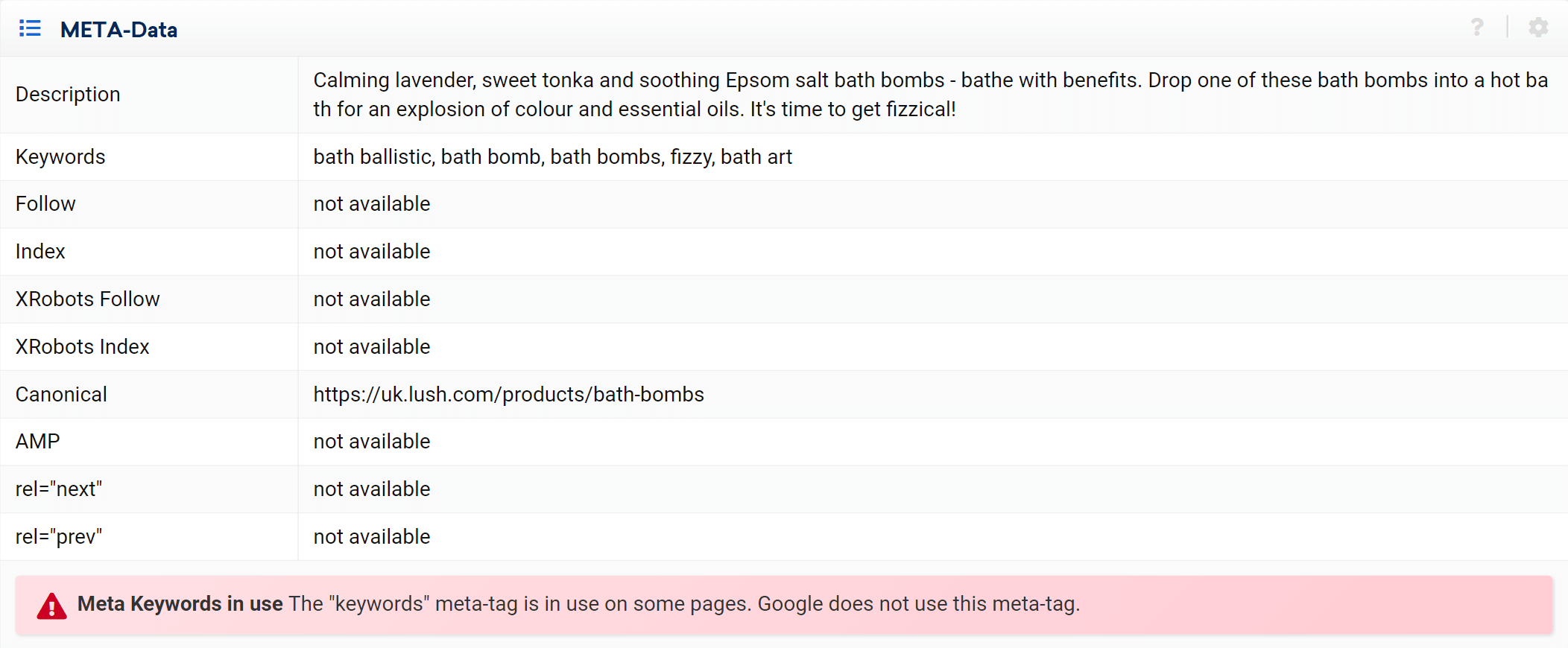
Экспертный режим
Перейдя в раздел «Экспертный режим», мы можем получить доступ ко всем просканированным URL-адресам нашего проекта и использовать несколько фильтров для уточнения нашего поиска. В приведенном ниже примере я включил URL-адреса, которые содержат /products/ в своих URL-адресах, но не относятся к рынку /en_gb/.
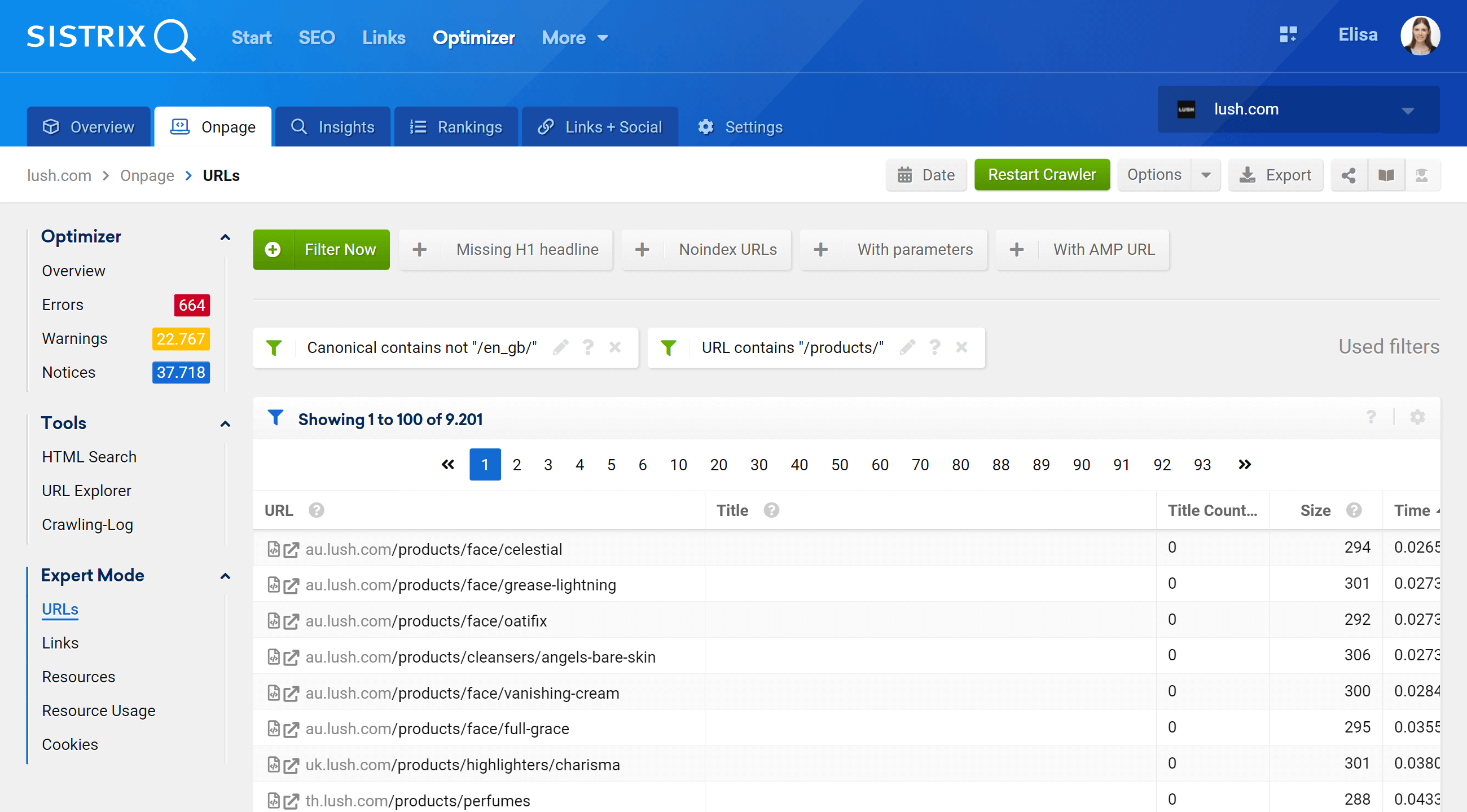
Кроме того, мы также можем настроить столбцы таблицы для отображения полей, которые нас больше интересуют. В моем примере я выбрал отображение кодов состояния, уровня глубины, внутренних ссылок, мета-роботов и канонических, но мы также можем добавить – просто отметьте их поле — заголовок, описание, H1, размер, тип контента и т. д.