Was ist das Canonical Tag und wie wird es verwendet?
Veröffentlicht: 2022-04-17- Definition und Bedeutung
- Nomenklatur, Überlegungen und zu vermeidende Fehler
- Durchführungsverfahren
- HTML-Tag
- HTTP-Header
- Andere Signale: Sitemap und interne Links
- Wirkungs- und SEO-Fälle
- Wie man kanonische Tags analysiert oder auditiert
- Untersuchen Sie den Quellcode
- Chrome-Entwicklertools
- In der Google Search Console
- So analysieren Sie Canonical Tags mit dem SISTRIX Toolbox Optimizer
- Crawling und Erkennung von Warnungen
- URL-Explorer: Analysieren Sie einzelne URLs
- Expertenmodus
Definition und Bedeutung
Das kanonische Tag ist das HTML-Element, das wir verwenden, um Google mitzuteilen, dass zwei oder mehr URLs auf unserer Website doppelt, ähnlich oder identisch sind.
Mit diesem Tag können wir „auswählen“, welche der mehreren URLs in den SERPs angezeigt werden sollen, um Google bei der Entscheidung zu helfen, welche Seite letztendlich in den Ergebnissen angezeigt werden soll. Mit anderen Worten, wir geben Google ein Signal, das anzeigt, welche Version bevorzugt indexiert werden soll .
Neben der Stärkung dieses Indizierungssignals konsolidiert es auch unsere internen Links , die von der Ursprungs-URL zur kanonischen Ziel-URL verweisen.
In Bezug auf doppelte Inhalte und diverse Mythen, die in der Branche herumschwirren, gibt es keinen besseren Weg, dies aufzuklären, als offizielle Quellen und Verweise von Google selbst zu zitieren:
„Lassen Sie uns das ein für alle Mal zu Bett bringen, Leute: Es gibt keine „Strafe für doppelte Inhalte“. Zumindest nicht so, wie die meisten Leute das meinen. Sie können Ihren Webmaster-Kollegen helfen, indem Sie den Mythos der Duplicate-Content-Strafen nicht aufrechterhalten!“
Susan Moska
https://webmasters.googleblog.com/2008/09/demystifying-duplicate-content-penalty.html
„Duplicate Content bezieht sich im Allgemeinen auf wesentliche Inhaltsblöcke innerhalb oder zwischen Domains, die entweder vollständig mit anderen Inhalten übereinstimmen oder merklich ähnlich sind. Meistens ist dies nicht trügerisch.“
https://developers.google.com/search/docs/advanced/guidelines/duplicate-content
Nomenklatur, Überlegungen und zu vermeidende Fehler
Hier sind die wichtigsten Überlegungen zur kanonischen Richtlinie und Möglichkeiten, sie zu spezifizieren:
- Ein Canonical kann selbstreferenziell sein, insbesondere auf der Startseite, da es mehrere Zugriffspunkte haben kann, die vom CMS oder dem Server selbst generiert werden (index.html, um nur einen zu nennen).
- Ein Canonical muss immer dann verwendet werden, wenn zwei Inhalte ähnlich, doppelt oder mit anderen Worten ganz oder teilweise identisch sind. Andernfalls kann dieses Tag ignoriert werden.
- Ein Canonical muss auf eine indexierbare URL verweisen, 200 OK zurückgeben und kein noindex -Tag tragen. Erwähnenswert ist auch, dass wir einen Canonical nicht an eine irrelevante URL senden sollten, da dies als Soft 404 interpretiert wird.
- Für jede URL sollte es nur einen eindeutigen Canonical geben. Wenn es zwei verschiedene kanonische Tags gibt, können sie kollidieren und beide werden ignoriert.
- Ein Canonical kann absolute und relative URLs verwenden. Es ist jedoch wichtig darauf hinzuweisen, dass relative URLs anfällig für Fehler und Versehen sind.
- Ein Canonical-Tag kann ignoriert werden, wenn es offensichtliche Fehler in Bezug auf ihre Rechtschreibung oder andere unbeabsichtigte Fehler gibt. Es kann andere Signale geben, die analysiert werden, um zu bestimmen, ob ein kanonisches Tag respektiert oder ignoriert werden sollte.
- Ein kanonisches Tag kann auch ignoriert werden, wenn wir verwirrende Signale senden, wie z. B. das Verweisen auf ein kanonisches Tag von url1 zu url2 und dann von url2 zu url1. Diese Art von „Schleifen“ kann zu unerwartetem Verhalten führen.
- Ein Canonical kann domänenübergreifend sein, dh von Domäne1 auf Domäne2 zeigen. Es sollte –vorzugsweise– verwendet werden, wenn wir die Kontrolle über beide Domains haben und die Indizierung einer Domain gegenüber der anderen bevorzugen möchten, um Duplikate zu vermeiden. Seien Sie dabei vorsichtig.
- Ein weiteres Beispiel kann die Syndizierung von Inhalten sein.
Unter der Voraussetzung, dass Duplicate-Content-Situationen zwischen Seiten gelöst werden, sind einige der typischsten Fälle, in denen wir uns damit befassen müssen, folgende:
- URLs mit www vs. URLs ohne www
- URLs mit http vs. URLs mit https
- URLs, die mit / enden, im Vergleich zu URLs, die nicht mit / enden (die Homepage wird nicht mitgezählt)
- URLs mit Parametern im Vergleich zu URLs ohne Parameter (wie URLs mit Sitzungs-IDs).
- URLs mit Paginierung vs. URLs ohne Paginierung
- URLs mit AMP vs. URLs ohne AMP (als erforderliches Markup).
- Mobile URLs (M-Sites) vs. Desktop-URLs
- Pre-(Staging-)URLs vs. Prod-(Produktions-)URLs (auf jeden Fall ist es besser, Google aus dem Staging per HTTP-Login herauszuhalten)
- Etc.
Obwohl all diese Situationen mit Canonical Tags gelöst werden könnten, gibt es eine andere, direktere Methode für Google: 301-Weiterleitung .
Sie werden viele 301- und kanonische Tag-Vergleiche lesen. Wir werden nicht zu sehr darauf eingehen, aber wir werden die wichtigsten Punkte zu diesem Thema im Bild unten hervorheben:
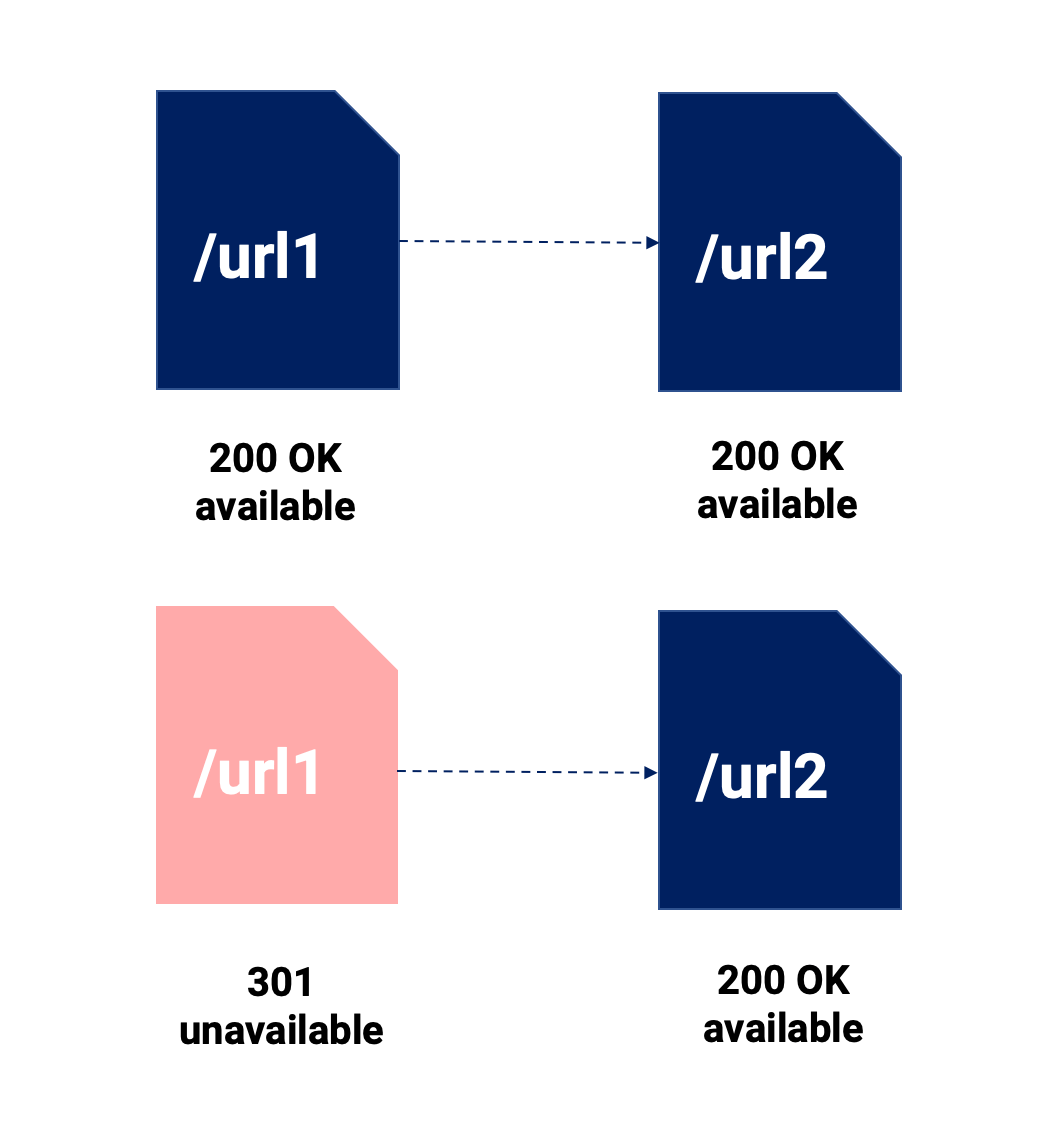
Anhand dieser visuellen Zusammenfassung möchten wir die folgenden Dinge hervorheben:
- Bei der 301-Weiterleitung werden zwei Inhalte zusammengeführt, was bedeutet, dass der ursprüngliche Inhalt nicht mehr existiert. Es ist direkt und wird zu 100 % von Google (und den Nutzern) verfolgt.
- Die kanonische URL ermöglicht es uns, verschiedene URLs für jeden Kanal verfügbar zu halten, und wenn Google die Richtlinie respektiert, wird nur die kanonisierte URL für den SEO-Kanal indexiert.
- Beides kann möglicherweise eine Signalverwässerung beinhalten, und es könnte einen bedeutenderen Effekt haben, wenn wir keine 301-Weiterleitung verwenden, da kanonisierte URLs interne und externe Links haben können, die auf sie verweisen, was uns zwingt, unsere Bemühungen auf mehrere URLs aufzuteilen.
Durchführungsverfahren
Es gibt mehrere Möglichkeiten, Canonical Tags zu implementieren:
HTML-Tag
Die gebräuchlichste Art, eine kanonische Version zu implementieren, besteht darin, ein Link-Element mit dem Attribut rel=”canonical” und dem absoluten Pfad zur kanonischen Version innerhalb des <head> jeder URL zu platzieren. Hier ist die korrekte Syntax:
<link rel="canonical" href="https://www.sistrix.com/ask-sistrix/what-is-the-canonical-tag-and-how-to-use-it/" />HTTP-Header
Diese Methode wird normalerweise auf Nicht-HTML-Seiten verwendet. Zum Beispiel: PDF-, XML- oder TXT-Dateien.
Dies ist die typische Methode, die verwendet wird, wenn wir sowohl eine PDF- als auch eine passende HTML-Seite haben. Durch das Canonical können wir Google zeigen, dass wir möchten, dass die HTML-Seite rankt.
Angesichts der Vielzahl unterschiedlicher Fälle empfehlen wir jedoch diesen Beitrag, der die eher technische Implementierung durch die .htaccess-Datei behandelt.
<Files "seo-guide.pdf"> Header add Link "< http://www.sistrix.com/seo-guide/ >; rel=\"canonical\"" </Files>Andere Signale: Sitemap und interne Links
In diesem Fall werden wir die kanonische Direktive nicht implementieren, aber wir sagen implizit, dass diese URL (im Gegensatz zu ihren anderen Versionen) die ursprüngliche URL ist und mehr Gewicht und Wert hat.
Etwas so Einfaches wie das Hinzufügen von URLs zu einer Sitemap oder das Verlinken einer URL aus der Website-Navigation hat bereits eine stillschweigende und implizite Bedeutung , sodass wir so ziemlich ein SEO-Signal bezüglich der Bedeutung dieser URL-Version für uns senden. Wenn wir uns widersprechen oder andere mehrdeutige oder nicht schlüssige Signale kommen, verstoßen wir gegen das Gesetz der Einfachheit im SEO : Machen Sie es Google nicht komplizierter, als es ohnehin schon ist.
- Bei 2 doppelten URLs, die Canonicals verwenden, wird die ursprüngliche URL in die Sitemap aufgenommen, die kanonisierte nicht.
- Bei 2 doppelten URLs, die kanonische URLs verwenden, wird die Original-URL prominent verlinkt, die kanonisierte nicht (obwohl dies nicht immer möglich ist und die kanonisierte URL möglicherweise einen Link enthält, der darauf verweist).
Wirkungs- und SEO-Fälle
Die größte Wirkung, die die Verwendung von Canonical haben kann, besteht darin, dass die URL, auf die das Canonical-Tag verweist, indexierbar wird, sobald es von Google respektiert wird, und derjenige, der das Canonical herausgibt, zurücktreten und sich selbst opfern wird, damit der originellere Inhalt kann indiziert werden.

Wenn andererseits die URL, die das Canonical ausgibt, irgendwo innerhalb der Navigationsstruktur interne Links erhält, kann Google diese Seite crawlen und Zeit dafür investieren . Dies sollte uns ernsthaft dazu bringen, über unsere kombinierte Verwendung von Robots.txt (sogar „noindex“) und Canonical nachzudenken. Wenn wir unser Crawl-Budget sparen wollen, könnten wir Google möglicherweise daran hindern, zu verstehen, wo das Duplikat und sein kanonischer Code liegen.
Apropos speziellere Fälle, wir können ein bisschen mehr spezifizieren:
- Passive Parameter : werden vorsichtshalber in Kombination mit der Parameterverwaltung der Google Search Console verwendet. Diese Parameter werden jedoch verwendet, um Kampagnen (bezahlt, E-Mail, Social…) zu markieren.
- Aktive Parameter : Sprache, Filter. Der Schlüssel hier ist, zu identifizieren, welche einen minimal originellen Inhalt haben, den wir positionieren können, und außerdem mit Sicherheit zu wissen, ob sie auf eine Suchabsicht reagieren oder nicht. Weitere Probleme können interne Links und Autoritätsverschwendung durch die internen Links dieser Filter sein.
- Paginierung : Das aktuelle Szenario in Bezug auf die Paginierung ist immer noch eine Kontroverse an und für sich. Google hat die Richtlinie rel prev rel next entfernt, und jetzt debattiert die SEO-Welt, ob wir noindex, ein Canonical zur ersten Seite, unendliches Scrollen oder dynamische Technologien wie AJAX verwenden sollten, um die Funktionalität für den Benutzer aufrechtzuerhalten, ohne neue Seiten/Links zu generieren. je nach Fall. Es ist überhaupt keine triviale Entscheidung.
- Produktseiten mit ähnlichen Attributen (Farbe, Größe) : Ähnlich wie bei Filtern müssen wir identifizieren, wenn ihr Inhalt nicht minimal originell ist, um ein Ranking zu erzielen, und wir müssen wissen, ob sie auf eine Suchabsicht reagieren. Wir sollten die Regel „was nicht gesucht wird, sollte nicht indiziert werden“ beachten .
Wie man kanonische Tags analysiert oder auditiert
Jetzt kommen wir zur Sache, wie man kanonische Tags identifiziert oder prüft. Wir haben Methoden für jeden Geschmack:
Untersuchen Sie den Quellcode
Besuchen Sie die Seite und klicken Sie mit der rechten Maustaste auf eine beliebige Stelle auf der Seite, um das Menü mit der Option „Seitenquelltext anzeigen“ anzuzeigen (Strg + U, wenn Sie Windows verwenden; CMD + Alt + U, wenn Sie einen Mac verwenden).
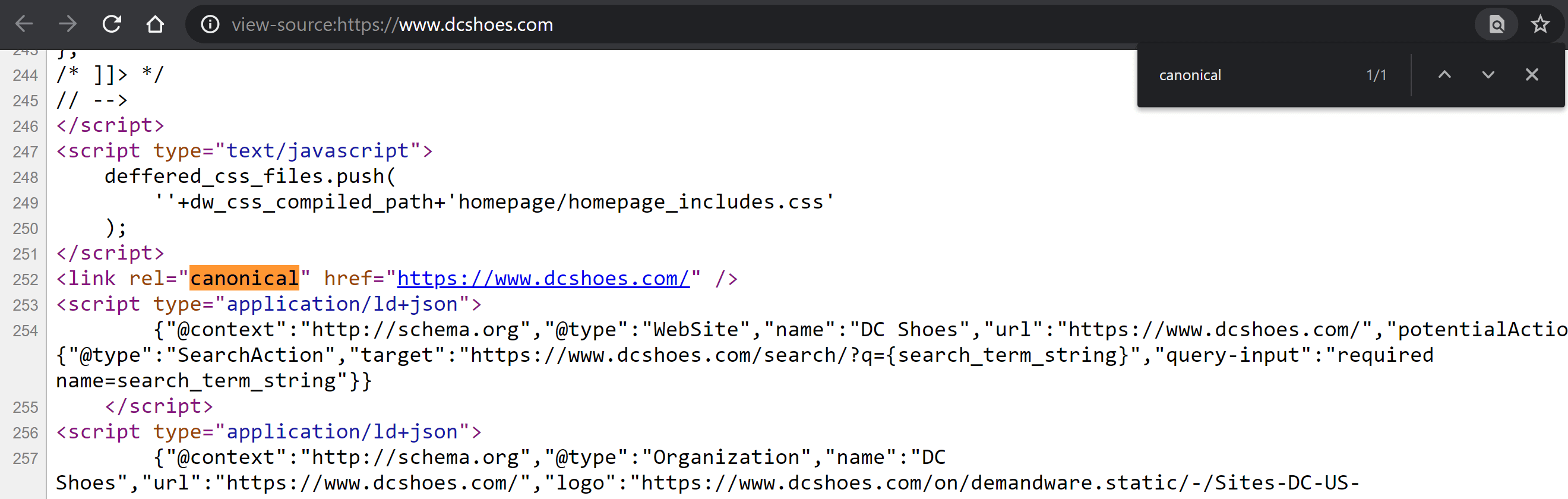
Sobald Sie drinnen sind, drücken Sie Strg + F auf Windows oder CMD + F auf Mac, um im Code zu suchen. Geben Sie „canonical“ ein, damit das Tag, falls vorhanden, in einer anderen Farbe hervorgehoben wird. Vergleichen Sie seinen Inhalt und stellen Sie fest, ob dieser Wert richtig definiert wurde oder nicht.
Chrome-Entwicklertools
Mit Chrome können wir die Website öffnen, die wir analysieren möchten, mit der rechten Maustaste auf den Bildschirm klicken und auf „Inspizieren“ klicken. Dadurch werden die Entwicklertools geöffnet, in denen wir wie im vorherigen Punkt mit Strg + F oder Cmd + F nach dem Tag suchen können.
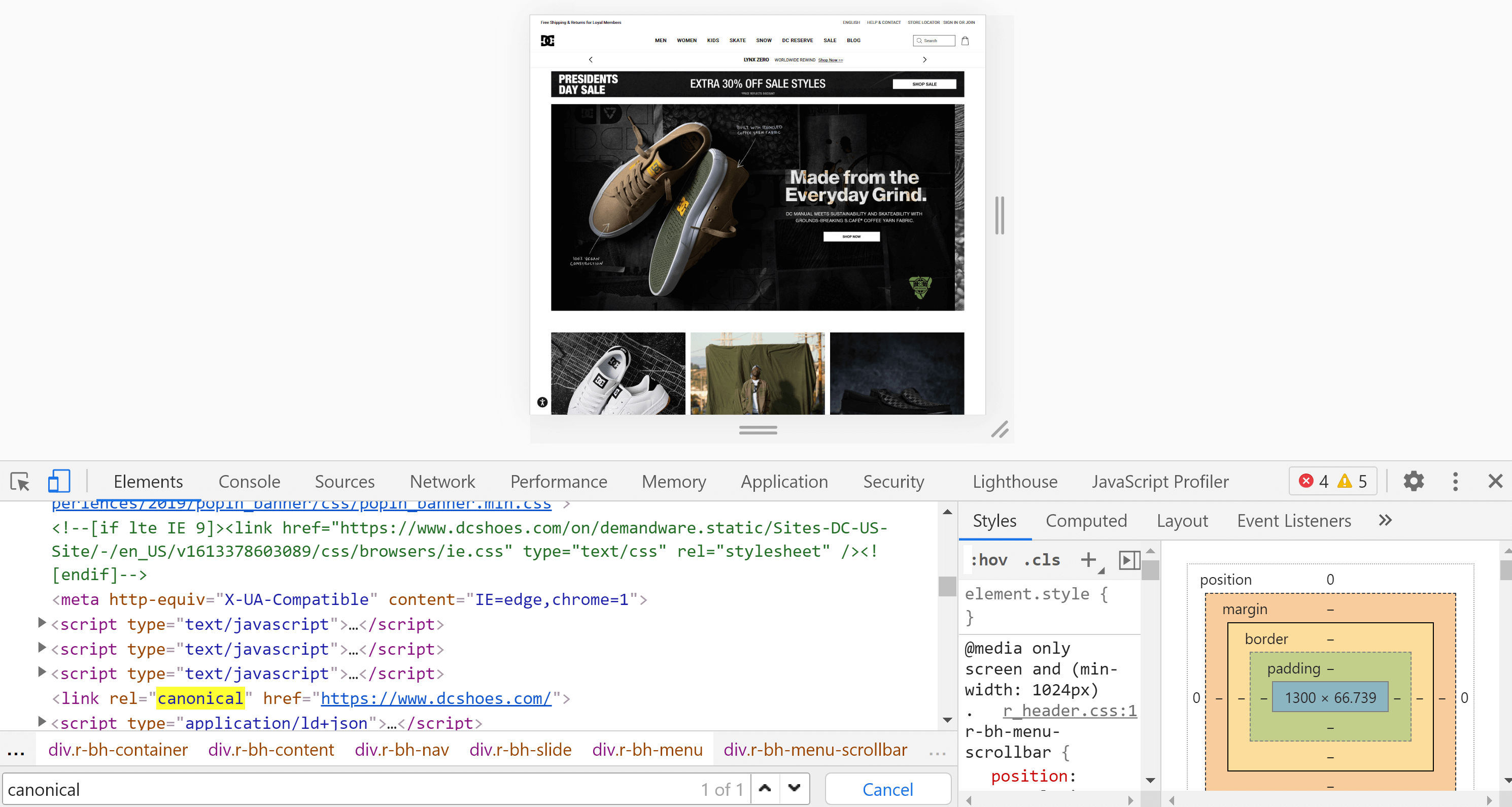
Der Hauptunterschied zwischen dem Seitenquellcode und dem Inspektor besteht darin, dass der zweite die Seite bereits gerendert hat und wir den Inhalt sehen, nachdem dieser Prozess (einschließlich der Ausführung von JavaScript) abgeschlossen ist.
Alternativ können wir die Konsole verwenden , indem wir auf die Registerkarte „Konsole“ gehen und den folgenden Befehl eingeben:
$$('link[rel="canonical"]')[0] 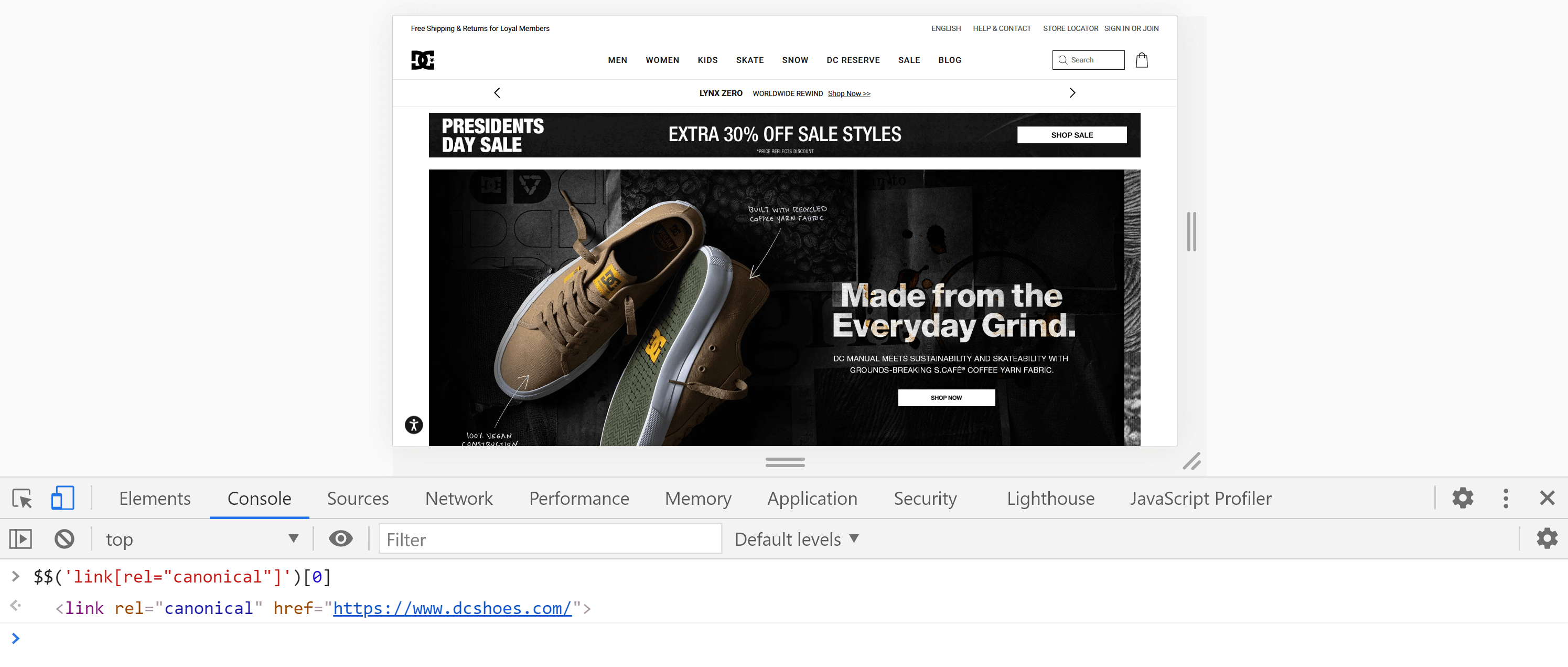
In der Google Search Console
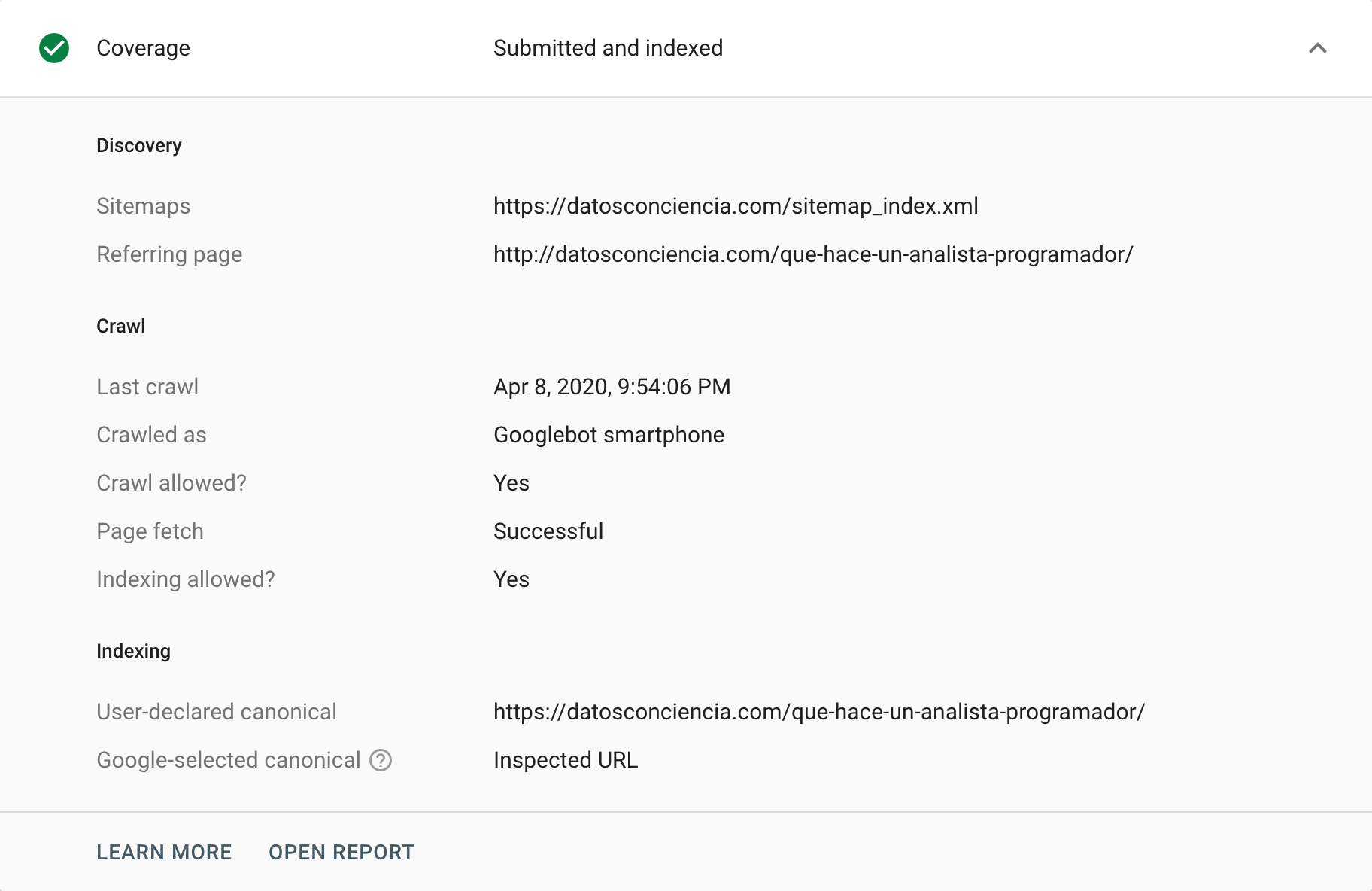
Die Google Search Console bietet verschiedene Möglichkeiten, kanonische Tags zu analysieren oder zu prüfen. Eine Möglichkeit, dies zu tun, besteht darin, zum Bericht „Abdeckung“ zu gehen, in dem wir jedes Ereignis analysieren können, das für den Ausschluss bestimmter URLs aus seinem Index verantwortlich ist. In diesem Abschnitt „Ausgeschlossen“ finden wir manchmal Situationen im Zusammenhang mit kanonischen Tags, sowohl korrekte als auch falsche Fälle (korrekt und falsch interpretiert). Zweifellos ist dies der perfekte Weg, um an dem Faden zu ziehen, der uns hilft, Probleme zu erkennen.

Auf der anderen Seite haben wir das URL-Inspektionstool , das Einblicke in kanonische Tags einzelner URLs geben kann. Wir können es anfordern, sie zu crawlen und ihren Status zurückzugeben, insbesondere wenn ein Unterschied zwischen unserer Anweisung und der von Google gewählten Interpretation besteht.
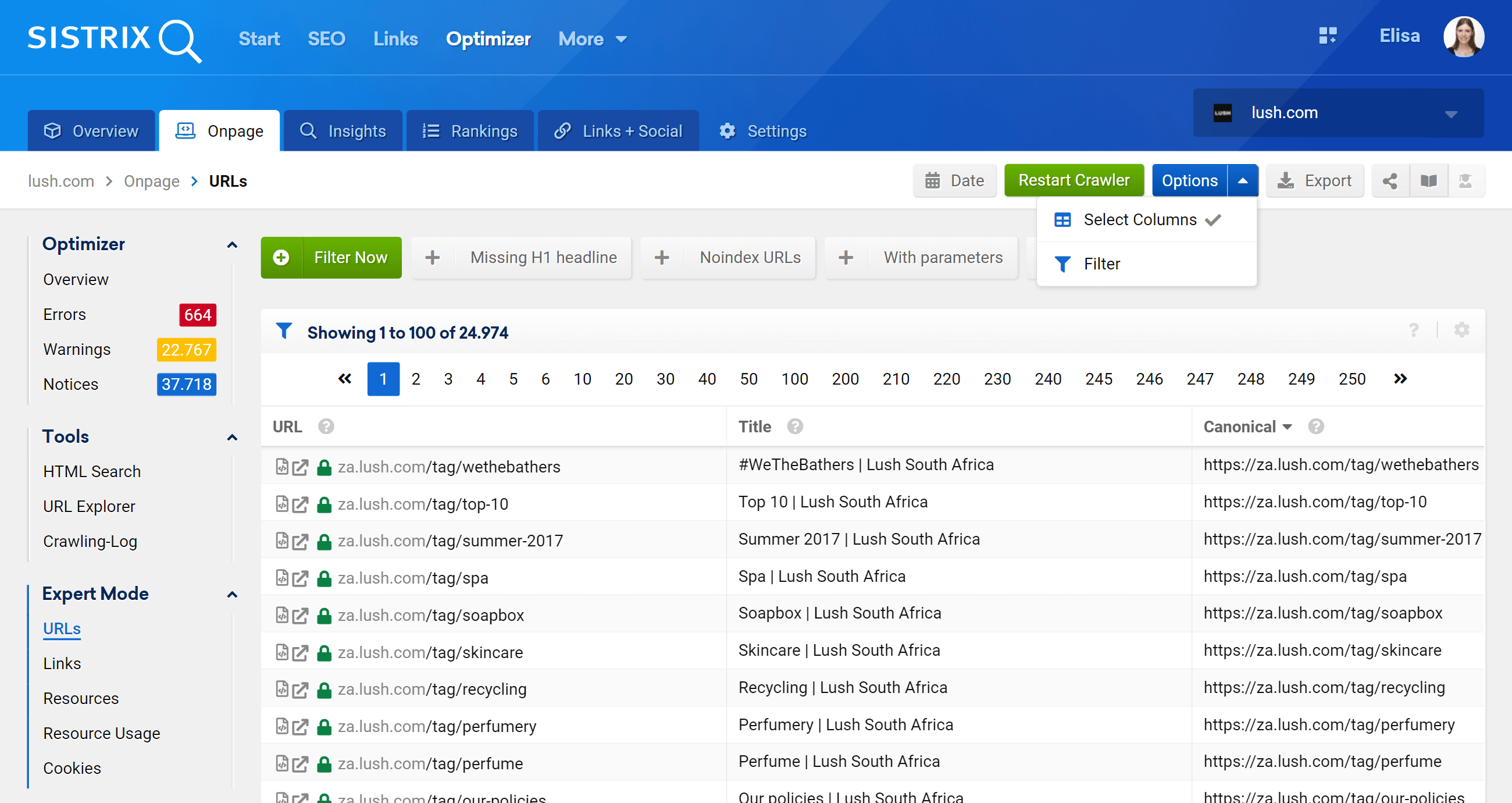
So analysieren Sie Canonical Tags mit dem SISTRIX Toolbox Optimizer
Es gibt mehrere Möglichkeiten, Canonicals mit dem SISTIX Toolbox Optimizer zu analysieren.
Crawling und Erkennung von Warnungen
Als Crawler besucht Optimizer Ihre Website, um Verbesserungsmöglichkeiten, Fehler und andere Aspekte zu identifizieren, über die Sie auf einfache und visuelle Weise informiert werden, sodass Sie Ihre Zeit nicht mit der Verarbeitung von Daten verschwenden müssen. Hier ist ein Beispiel für kanonische Tags, über die Sie der Optimizer benachrichtigt (wenn Sie einen Fehler machen):

URL-Explorer: Analysieren Sie einzelne URLs
Diese Funktion ähnelt dem URL-Inspektionstool der Google Search Console, was bedeutet, dass Sie einzelne URLs auswerten können, die in Ihrem Optimizer-Projekt gecrawlt wurden, und die Informationen für diese eine bestimmte URL anzeigen können.
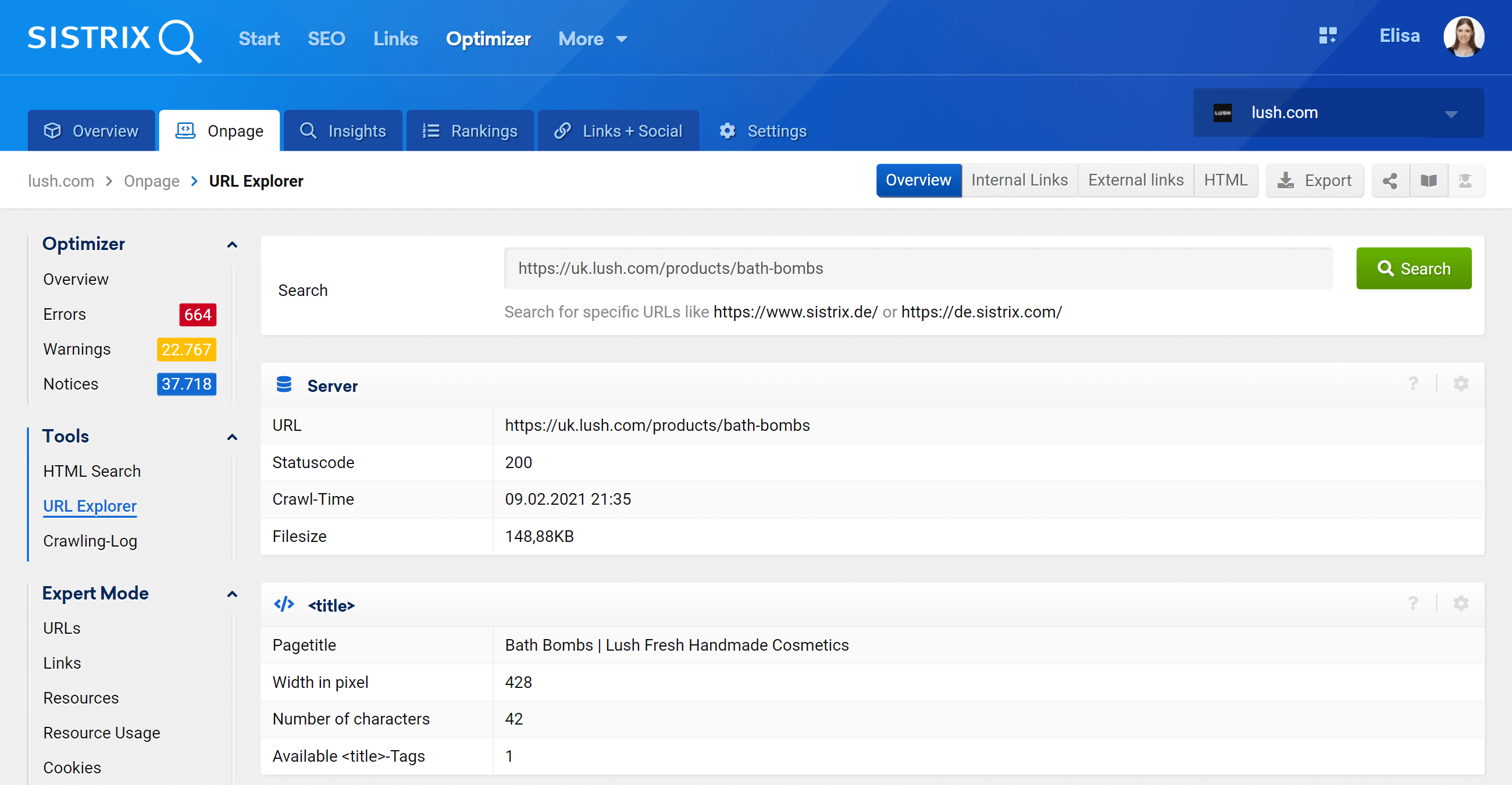
Wie Sie sehen, können wir alle Onpage-Aspekte dieser URL analysieren, sowohl eingehende als auch ausgehende interne Links, Serverinformationen, SEO-Tags, und hier finden Sie auch die kanonische Implementierung, um die es hier geht .
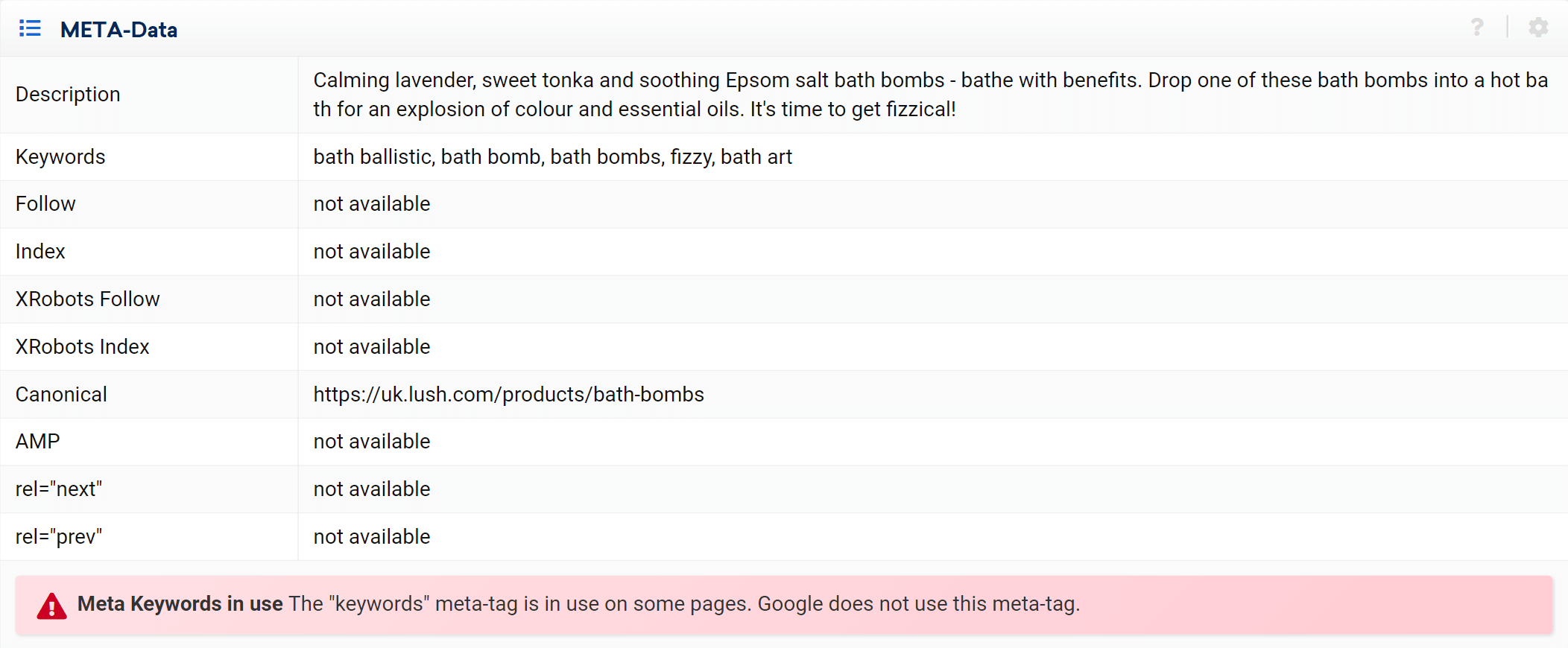
Expertenmodus
Indem wir zum Abschnitt „Expertenmodus“ gehen, können wir auf alle gecrawlten URLs unseres Projekts zugreifen und mehrere Filter verwenden, um unsere Suche zu verfeinern. Im folgenden Beispiel habe ich die URLs eingefügt, die /products/ in ihren URLs enthalten, aber nicht zum Markt /en_gb/ gehören.
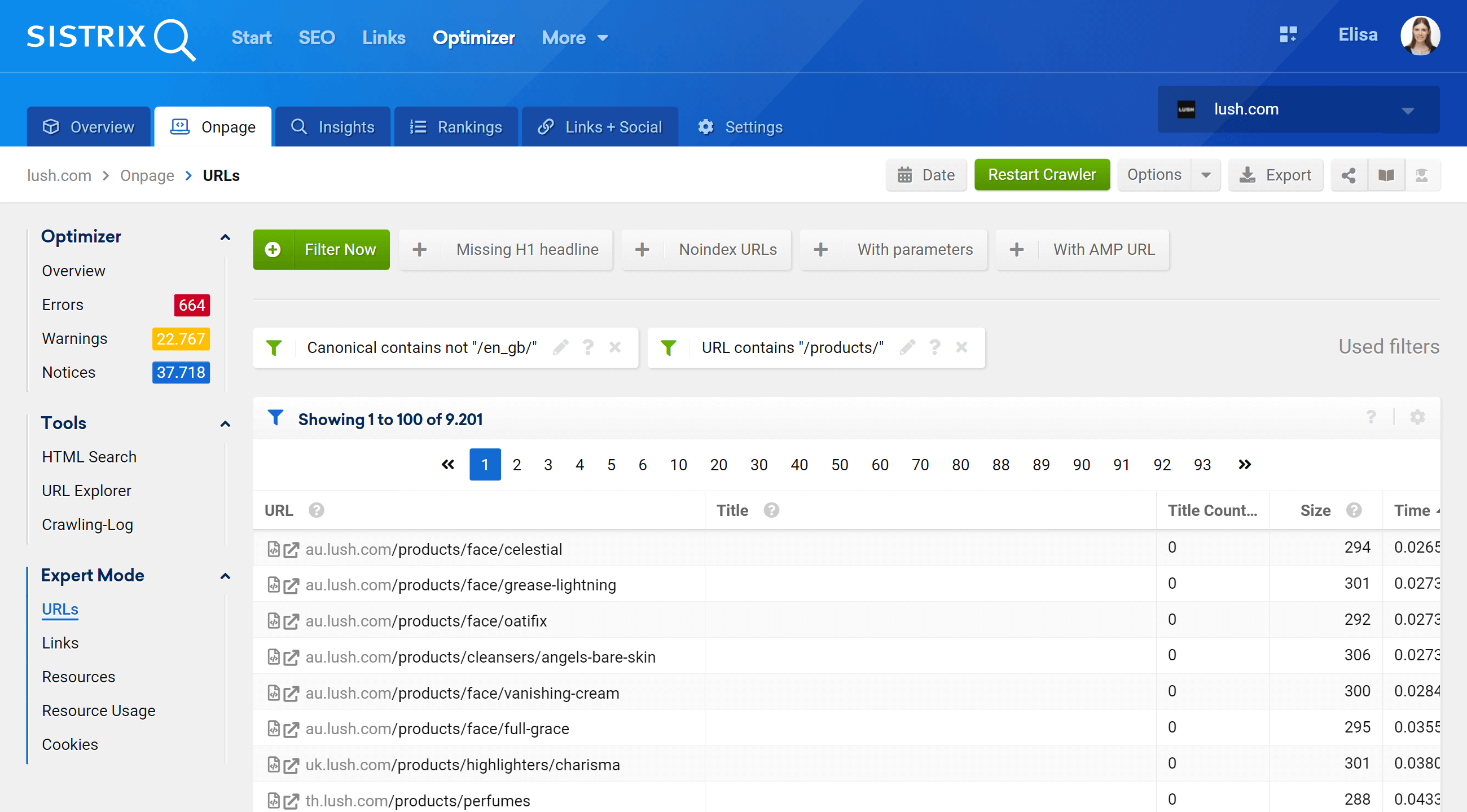
Darüber hinaus können wir auch die Tabellenspalten so konfigurieren, dass sie Felder anzeigen, die uns mehr interessieren. In meinem Beispiel habe ich mich dafür entschieden, Statuscodes, Tiefenlevel, interne Links, Meta-Robots und kanonisch anzuzeigen, aber wir könnten auch einfach „by“ hinzufügen Ankreuzen des Kästchens – Titel, Beschreibung, H1, Größe, Art des Inhalts usw.