Ce este eticheta canonică și cum se utilizează
Publicat: 2022-04-17- Definiție și semnificație
- Nomenclatură, considerații și erori de evitat
- Proceduri de implementare
- Etichetă HTML
- Antet HTTP
- Alte semnale: sitemap și link-uri interne
- Cazuri de efect și SEO
- Cum să analizați sau să auditați etichetele canonice
- Explorați codul sursă
- Instrumente pentru dezvoltatori Chrome
- Pe Google Search Console
- Cum să analizați etichetele canonice folosind SISTRIX Toolbox Optimizer
- Crawling și detectarea avertismentelor
- URL explorer: analizați adrese URL individuale
- Modul expert
Definiție și semnificație
Eticheta canonică este elementul HTML pe care îl folosim pentru a anunța Google că 2 sau mai multe adrese URL de pe site-ul nostru sunt duplicate, similare sau identice.
Această etichetă ne permite să „selectăm” care dintre multiplele adrese URL ar trebui să fie afișate în SERP-uri, pentru a ajuta Google să decidă ce pagină ar trebui să afișeze în cele din urmă în rezultate. Cu alte cuvinte, oferim Google un semnal care indică versiunea preferată de indexat .
Pe lângă întărirea acestui semnal de indexare, consolidează și legăturile noastre interne care indică de la adresa URL de origine la adresa URL canonică țintă.
În ceea ce privește conținutul duplicat și diversele mituri care plutesc în industrie, nu există o modalitate mai bună de a-l clarifica decât prin citarea surselor oficiale și a referințelor care vin de la Google însuși:
„Să punem asta la culcare odată pentru totdeauna, oameni buni: nu există așa ceva ca o „penalizare pentru conținut duplicat”. Cel puțin, nu așa cum spun majoritatea oamenilor când spun asta. Îți poți ajuta colegii webmasteri, nu perpetuând mitul penalităților pentru conținut duplicat!”
Susan Moska
https://webmasters.googleblog.com/2008/09/demystifying-duplicate-content-penalty.html
„Conținutul duplicat se referă, în general, la blocuri substanțiale de conținut în sau între domenii, care fie se potrivesc complet cu alt conținut, fie sunt semnificativ similare. În mare parte, acest lucru nu este înșelător la origine.”
https://developers.google.com/search/docs/advanced/guidelines/duplicate-content
Nomenclatură, considerații și erori de evitat
Iată principalele considerații referitoare la directiva canonică și modalitățile de a o specifica:
- O canonică poate fi autoreferențială, mai ales pe pagina de start, deoarece poate avea mai multe puncte de acces generate de CMS sau de serverul însuși (index.html, ca să numim unul).
- Un canonical trebuie folosit ori de câte ori există două părți de conținut care sunt similare, duplicate sau, cu alte cuvinte, total sau parțial identice. În caz contrar, această etichetă poate fi ignorată.
- Un canonic trebuie să trimită către o adresă URL indexabilă, returnând 200 OK și fără etichetă noindex . Un alt lucru demn de menționat este că nu ar trebui să trimitem un canonic la o adresă URL irelevantă, deoarece va fi interpretat ca un Soft 404.
- Ar trebui să existe un singur canonic unic pentru fiecare adresă URL. Dacă există două etichete canonice diferite, acestea pot intra în conflict și ambele ajung să fie ignorate.
- Un canonical poate folosi URL-uri absolute și relative. Cu toate acestea, este important să subliniem faptul că adresele URL relative sunt predispuse la erori și supraveghere.
- O etichetă canonică poate fi ignorată dacă există erori evidente, în ceea ce privește ortografia lor sau alte greșeli neintenționate. Pot exista și alte semnale, care vor fi analizate pentru a determina dacă o etichetă canonică trebuie respectată sau ignorată.
- O etichetă canonică poate fi, de asemenea, ignorată dacă trimitem semnale confuze, cum ar fi trimiterea unei etichete canonice de la url1 la url2 și apoi de la url2 la url1. Apariția în acest tip de „bucle” poate duce la un comportament neașteptat.
- Un canonic poate fi cross-domain, adică punct de la domeniul 1 la domeniul 2. Ar trebui folosit – de preferință – atunci când avem control asupra ambelor domenii și dorim să favorizăm indexarea unui domeniu față de celălalt pentru a preveni duplicitățile. Fii precaut cu asta.
- Un alt exemplu poate fi sindicarea de conținut.
Cu condiția să rezolve situațiile de conținut duplicat între pagini, unele dintre cele mai tipice cazuri în care va trebui să ne ocupăm de asta sunt:
- URL-uri cu www vs. URL-uri fără www
- Adresele URL cu http vs. URL-urile cu https
- Adresele URL care se termină cu / vs. Adresele URL care nu se termină cu / (fără a lua în calcul pagina de pornire)
- Adrese URL cu parametri versus adrese URL fără parametri (cum ar fi adresele URL cu ID-uri de sesiune).
- Adrese URL cu paginare vs URL-uri fără paginare
- Adrese URL cu AMP versus adrese URL fără AMP (ca markup obligatoriu).
- Adrese URL pentru dispozitive mobile (site-uri m) versus adrese URL pentru desktop
- Adrese URL de pre (proiectare) versus URL-uri de producție (de producție) (oricum, este mai bine să țineți Google departe de organizare prin HTTP-Login)
- etc.
Deși toate aceste situații ar putea fi rezolvate folosind etichete canonice, există o altă metodă, mai directă pentru Google: 301 redirect .
Veți citi o mulțime de comparații de etichete 301 și canonice. Nu vom aprofunda prea mult în ea, dar vom sublinia cele mai importante puncte cu privire la această chestiune în imaginea de mai jos:
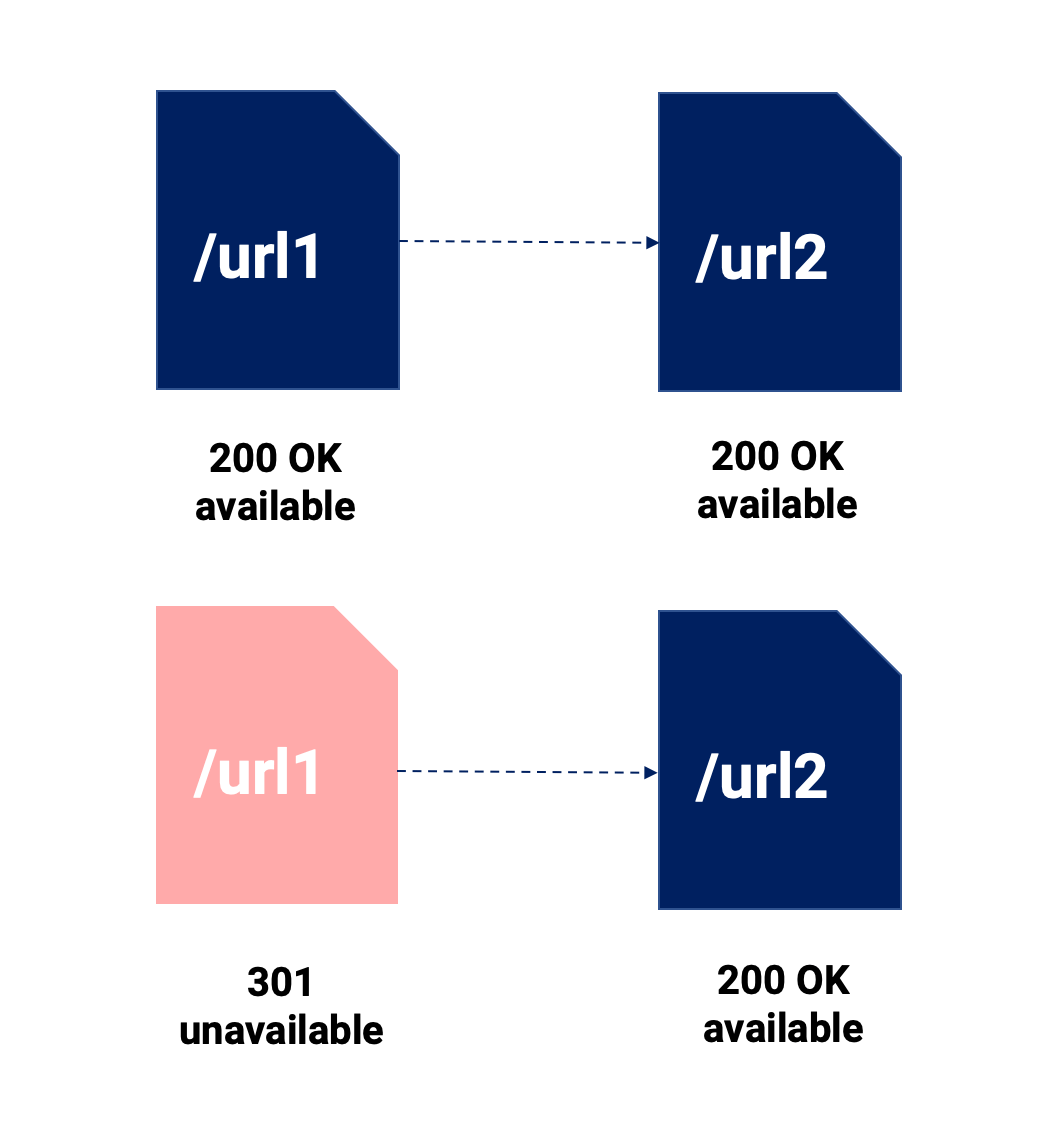
Folosind acest rezumat vizual, dorim să evidențiem următoarele lucruri:
- Redirecționarea 301 îmbină două părți de conținut, ceea ce înseamnă că conținutul original încetează să mai existe. Este direct și urmărit 100% de Google (și utilizatori).
- Canonicul, ceea ce face este să ne permită să menținem diferite URL-uri disponibile pentru orice canal, iar dacă Google respectă directiva, doar URL-ul canonizat va fi indexat pentru canalul SEO.
- Ambele pot implica eventual diluarea semnalului și ar putea avea un efect mai semnificativ atunci când nu folosim o redirecționare 301, deoarece URL-urile canonizate pot avea legături interne și externe care să trimită către ele, forțându-ne să ne împărțim eforturile între mai multe adrese URL.
Proceduri de implementare
Există mai multe moduri de implementare a etichetelor canonice:
Etichetă HTML
Cea mai comună modalitate de a implementa un canonic este plasarea unui element de legătură cu atributul rel="canonical" și calea absolută către versiunea canonică în <head> al fiecărei adrese URL. Iată sintaxa corectă:
<link rel="canonical" href="https://www.sistrix.com/ask-sistrix/what-is-the-canonical-tag-and-how-to-use-it/" />Antet HTTP
Această metodă este utilizată în mod normal pe pagini non-HMTL. De exemplu: fișiere PDF, XML sau TXT.
Aceasta este metoda tipică folosită atunci când avem atât un PDF, cât și o pagină HTML care se potrivește. Prin canonic îi putem arăta lui Google că vrem ca pagina HTML să se claseze.
Cu toate acestea, având în vedere varietatea de cazuri diferite, vă recomandăm această postare, acoperind implementarea mai tehnică prin fișierul .htaccess.
<Files "seo-guide.pdf"> Header add Link "< http://www.sistrix.com/seo-guide/ >; rel=\"canonical\"" </Files>Alte semnale: sitemap și link-uri interne
În acest caz, nu vom implementa directiva canonică, dar afirmăm, implicit, că această adresă URL (spre deosebire de celelalte versiuni ale sale) este cea originală și are mai multă greutate și valoare.
Ceva la fel de simplu ca adăugarea de adrese URL la un sitemap sau conectarea unei adrese URL din navigarea site-ului are deja o importanță tacită și implicită , așa că trimitem aproape un semnal SEO cu privire la importanța acestei versiuni URL pentru noi. Dacă ne contrazicem sau există alte semnale ambigue sau neconcludente, vom încălca legea simplității în SEO : nu faceți totul mai complicat pentru Google decât este deja.
- Cu 2 adrese URL duplicat, folosind coduri canonice, adresa URL inițială va fi inclusă în harta site-ului, iar cea canonică nu va fi inclusă.
- Cu 2 adrese URL duplicat, folosind coduri canonice, adresa URL inițială va fi legată în mod vizibil, cea canonizată nu va fi (deși acest lucru nu este întotdeauna posibil, iar URL-ul canonizat poate avea un link care să indice către acesta).
Cazuri de efect și SEO
Cel mai mare impact pe care îl poate avea utilizarea canonical este că, odată ce este respectat de Google, adresa URL către care indică eticheta canonical devine indexabilă , iar cel care emite canonical se va retrage și se va sacrifica, astfel încât conținutul mai original poate fi indexat.

Pe de altă parte, dacă adresa URL care emite canonicul primește link-uri interne undeva în structura de navigare, Google va putea să acceseze cu crawlere această pagină și să investească timp în ea . Acest lucru ar trebui să ne facă să ne gândim serios la utilizarea combinată a Robots.txt (chiar „noindex”) și canonic. Dacă vrem să ne economisim bugetul de accesare cu crawlere, este posibil să împiedicăm Google să înțeleagă unde se află duplicatul și canonic.
Apropo de cazuri mai particulare, putem preciza ceva mai multe:
- Parametri pasivi : sunt utilizați ca măsură de precauție, în combinație cu gestionarea parametrilor Google Search Console. Cu toate acestea, acești parametri sunt utilizați pentru a eticheta campanii (plătite, e-mail, social...).
- Parametri activi : limba, filtre. Cheia aici este să identificăm care dintre ele au conținut minim original pe care le putem poziționa, în afară de a ști cu certitudine dacă răspund sau nu la o intenție de căutare. Probleme suplimentare pot fi legaturile interne și risipa de autoritate prin linkurile interne ale acestor filtre.
- Paginare : scenariul actual în ceea ce privește paginarea este încă o controversă în sine. Google a eliminat ghidul rel prev rel next, iar acum lumea SEO dezbate dacă ar trebui să folosim noindex, un canonic la prima pagină, un scroll infinit sau tehnologii dinamice precum AJAX pentru a menține funcționalitatea pentru utilizator fără a genera noi pagini/linkuri, in functie de caz. Nu este deloc o decizie banala.
- Pagini de produse cu atribute similare (culoare, dimensiune) : Similar cu ceea ce am spus despre filtre, trebuie să identificăm când conținutul lor nu este minim original pentru a fi clasat și trebuie să știm dacă răspund la o intenție de căutare. Ar trebui să ținem cont de regula „ceea ce nu este căutat, nu trebuie indexat” .
Cum să analizați sau să auditați etichetele canonice
Acum, trecem la treaba cum să identificăm sau să audităm etichetele canonice. Avem metode care să se potrivească preferințelor fiecăruia:
Explorați codul sursă
Vizitați pagina și faceți clic dreapta oriunde pe pagină pentru a dezvălui meniul cu opțiunea „Vedeți sursa paginii” (Control + U dacă utilizați Windows; CMD + Alt + U dacă utilizați Mac).
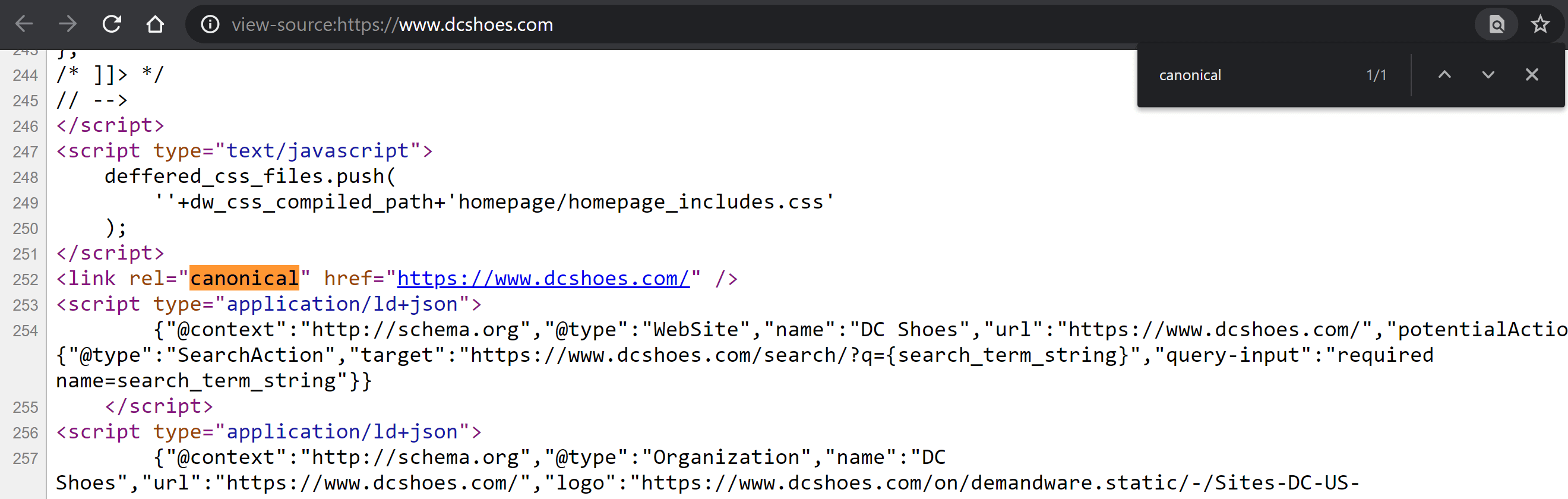
Odată înăuntru, apăsați Control + F pe Windows sau CMD + F pe Mac pentru a căuta în cod. Tastați „canonic”, astfel încât eticheta să fie evidențiată într-o culoare diferită, dacă este acolo. Comparați conținutul său și stabiliți dacă această valoare a fost definită corect sau nu.
Instrumente pentru dezvoltatori Chrome
Folosind Chrome, putem deschide site-ul web pe care vrem să-l analizăm, faceți clic dreapta pe ecran și apăsați „Inspectați”. Acest lucru va deschide instrumentele pentru dezvoltatori, unde putem căuta eticheta cu Control + F sau Cmd + F, așa cum am făcut în punctul anterior.
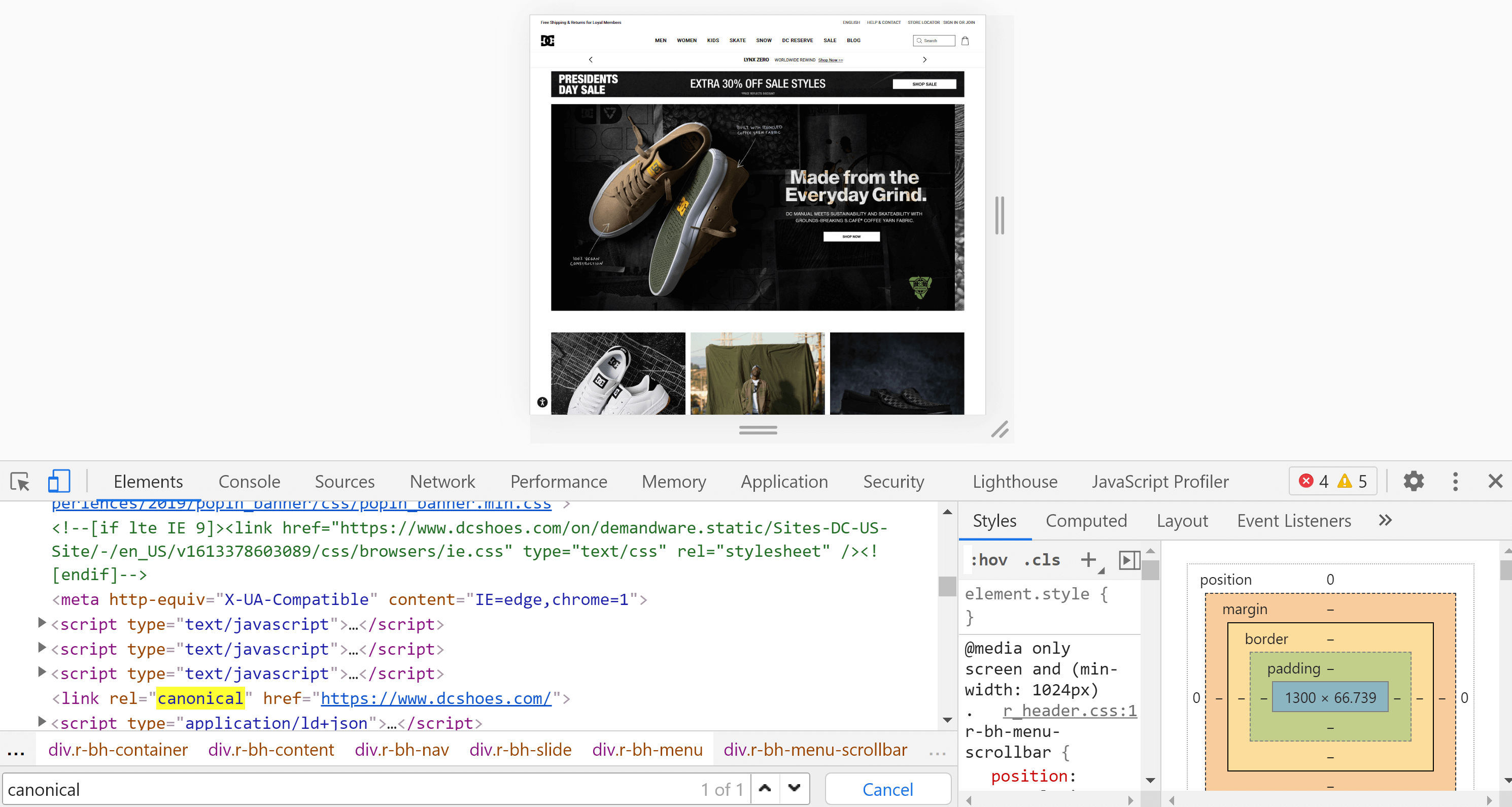
Principala diferență între codul sursă a paginii și inspector, este că al doilea a redat deja pagina și vedem conținutul după ce acest proces (inclusiv execuția JavaScript) este terminat.
Alternativ, putem folosi consola , mergând la fila „Consola” și introducând următoarea comandă:
$$('link[rel="canonical"]')[0] 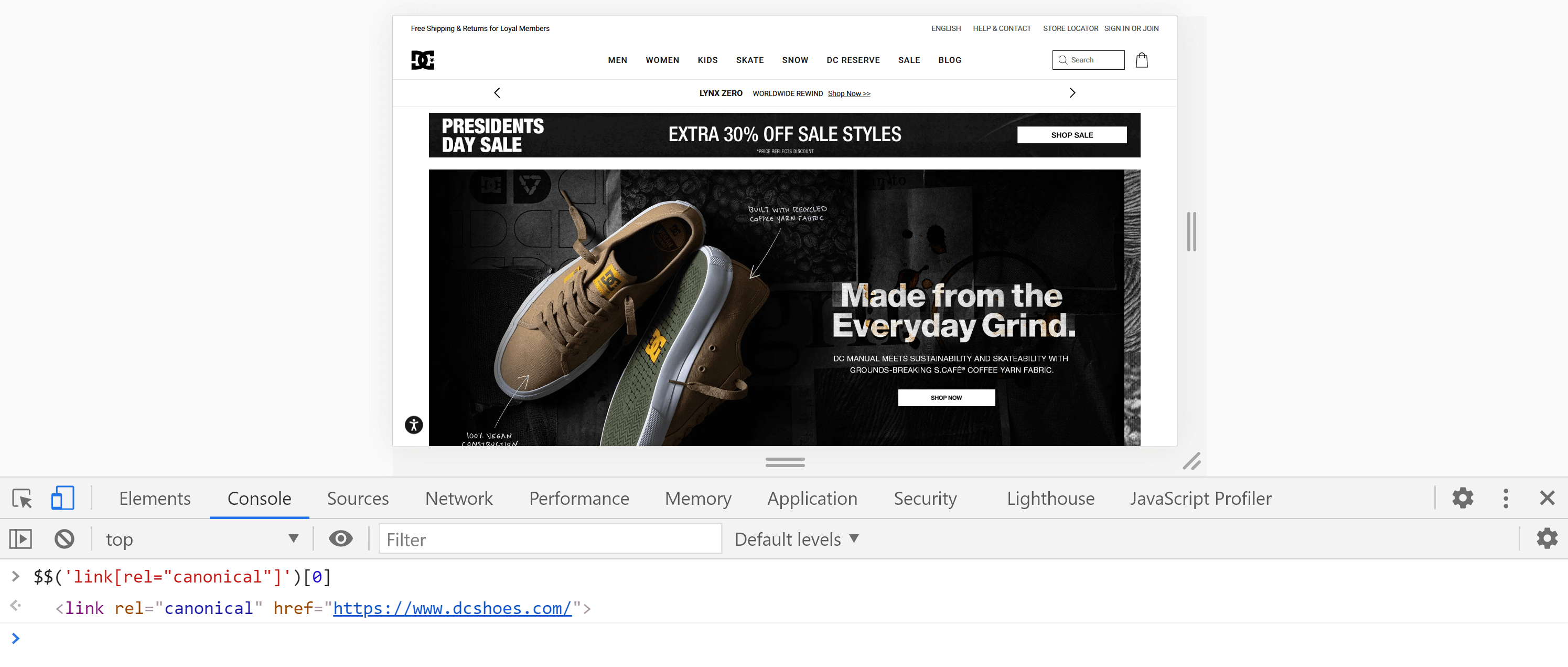
Pe Google Search Console
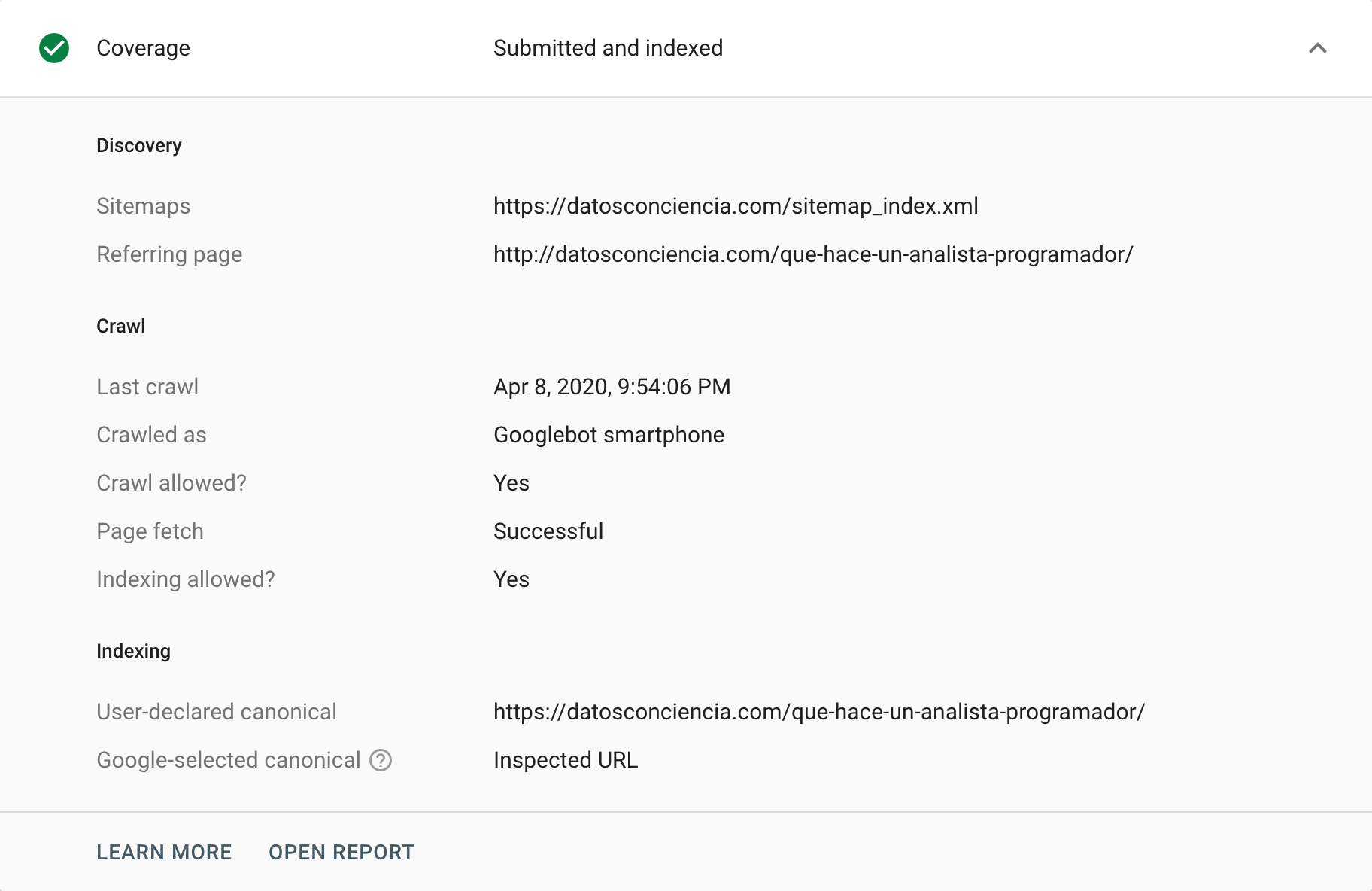
Google Search Console oferă diferite moduri de a analiza sau de a audita etichetele canonice. O modalitate de a face acest lucru este să accesăm raportul „Acoperire” , unde putem analiza orice eveniment responsabil de excluderea anumitor URL-uri din indexul său. În această secțiune „Exclus” , putem găsi uneori situații legate de etichetele canonice, atât cazuri corecte, cât și incorecte (interpretate corect și incorect). Fără îndoială, este modalitatea perfectă de a începe să tragem de fir care ne va ajuta să identificăm problemele.

Pe de altă parte, avem instrumentul de inspecție URL , care poate oferi informații despre etichetele canonice ale adreselor URL individuale. Îi putem solicita să le acceseze cu crawlere și să le returneze starea, mai ales dacă există o diferență între instrucțiunile noastre și ceea ce Google alege să interpreteze.
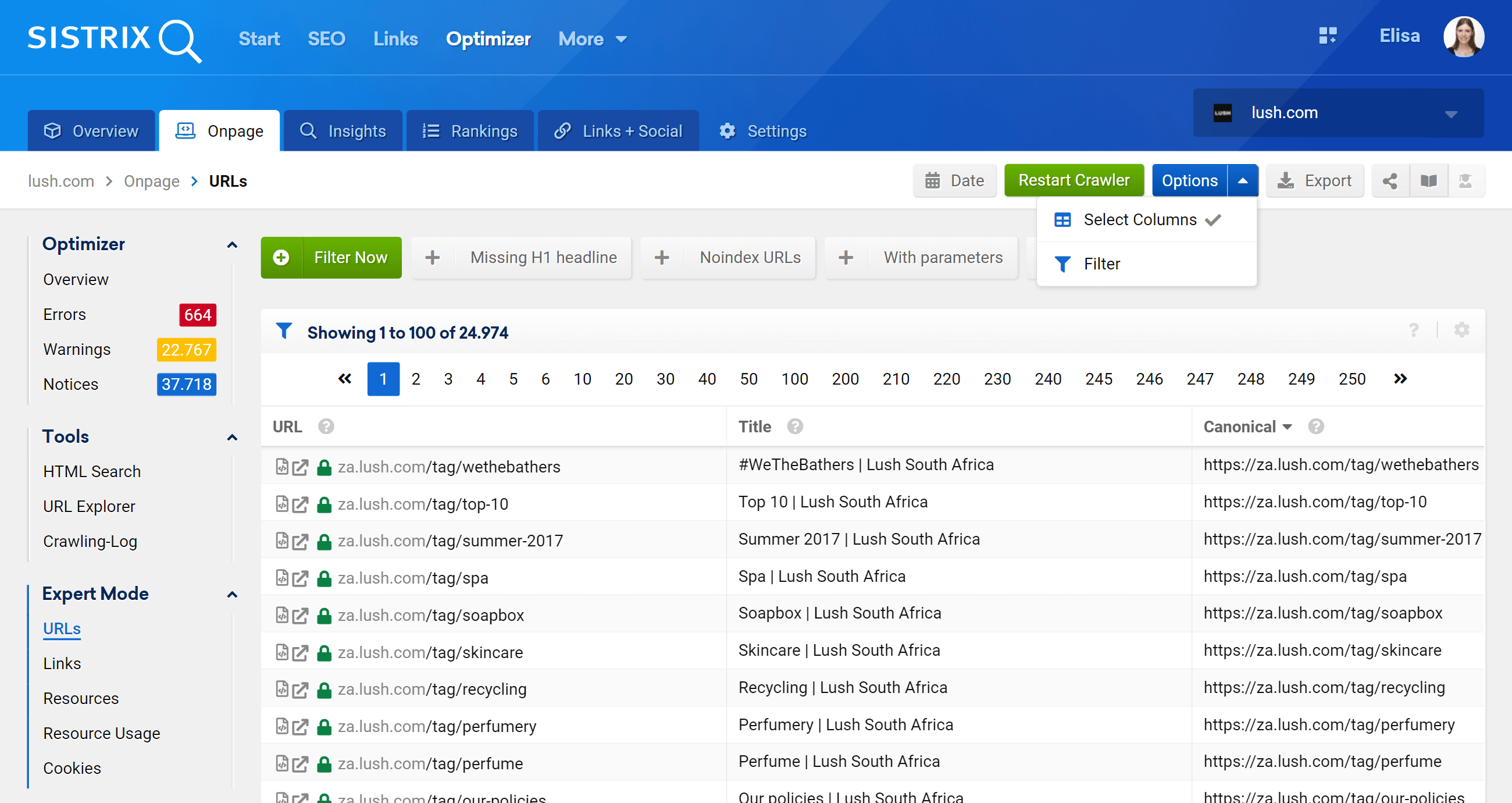
Cum să analizați etichetele canonice folosind SISTRIX Toolbox Optimizer
Există mai multe moduri de a analiza canonicalele folosind SISTIX Toolbox Optimizer.
Crawling și detectarea avertismentelor
Fiind un crawler, Optimizer vă va vizita site-ul web pentru a identifica oportunități de îmbunătățire, erori și alte aspecte despre care veți fi informat într-un mod ușor și vizual, astfel încât să nu vă pierdeți timpul procesând datele. Iată un exemplu legat de etichetele canonice, despre care Optimizer vă va anunța (dacă faceți o greșeală):

URL explorer: analizați adrese URL individuale
Această funcție este similară cu instrumentul de inspecție URL al Google Search Console, ceea ce înseamnă că veți putea evalua adresele URL individuale care au fost accesate cu crawlere în proiectul dvs. Optimizer și veți vedea informațiile pentru acea adresă URL specifică.
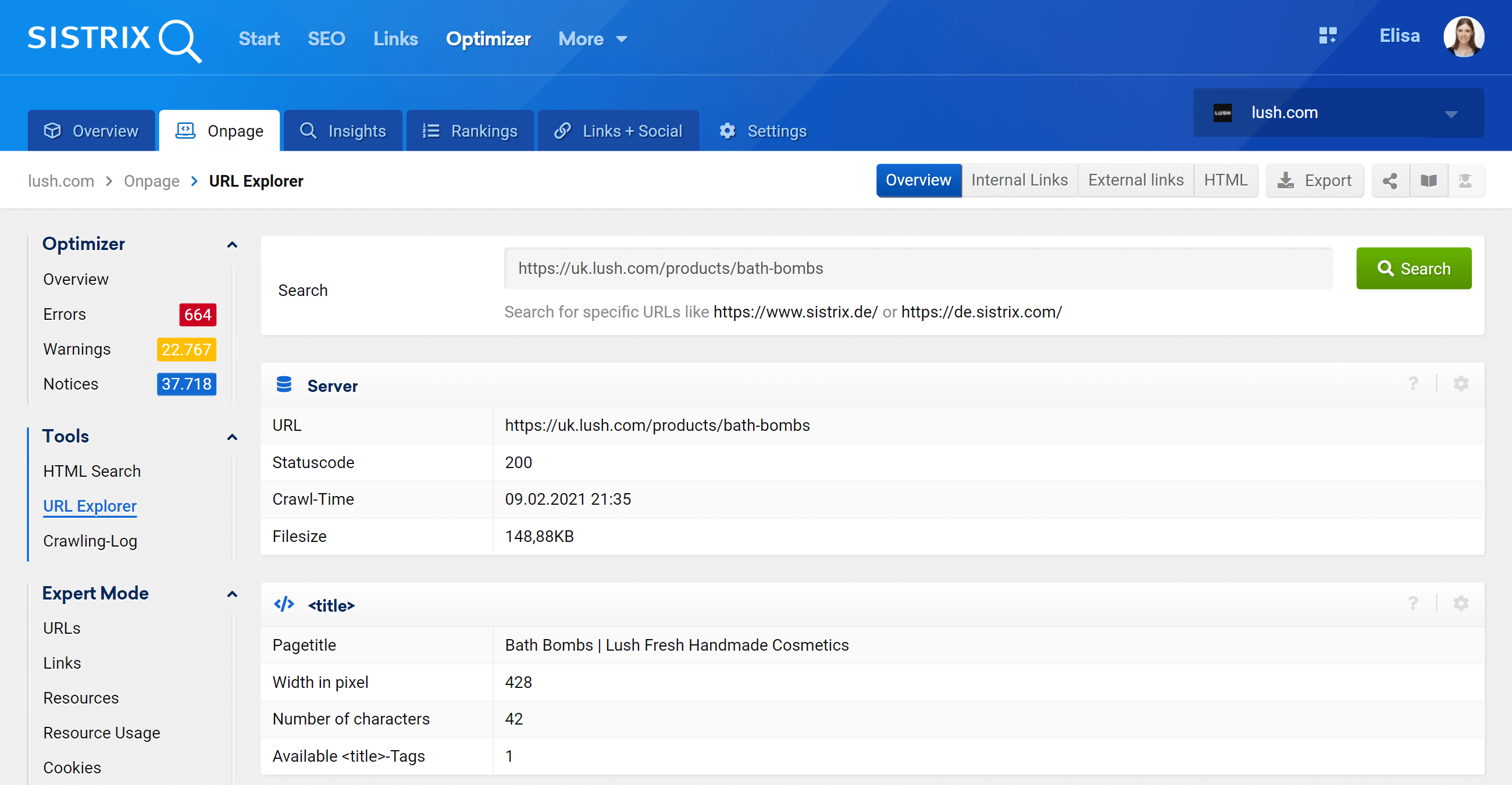
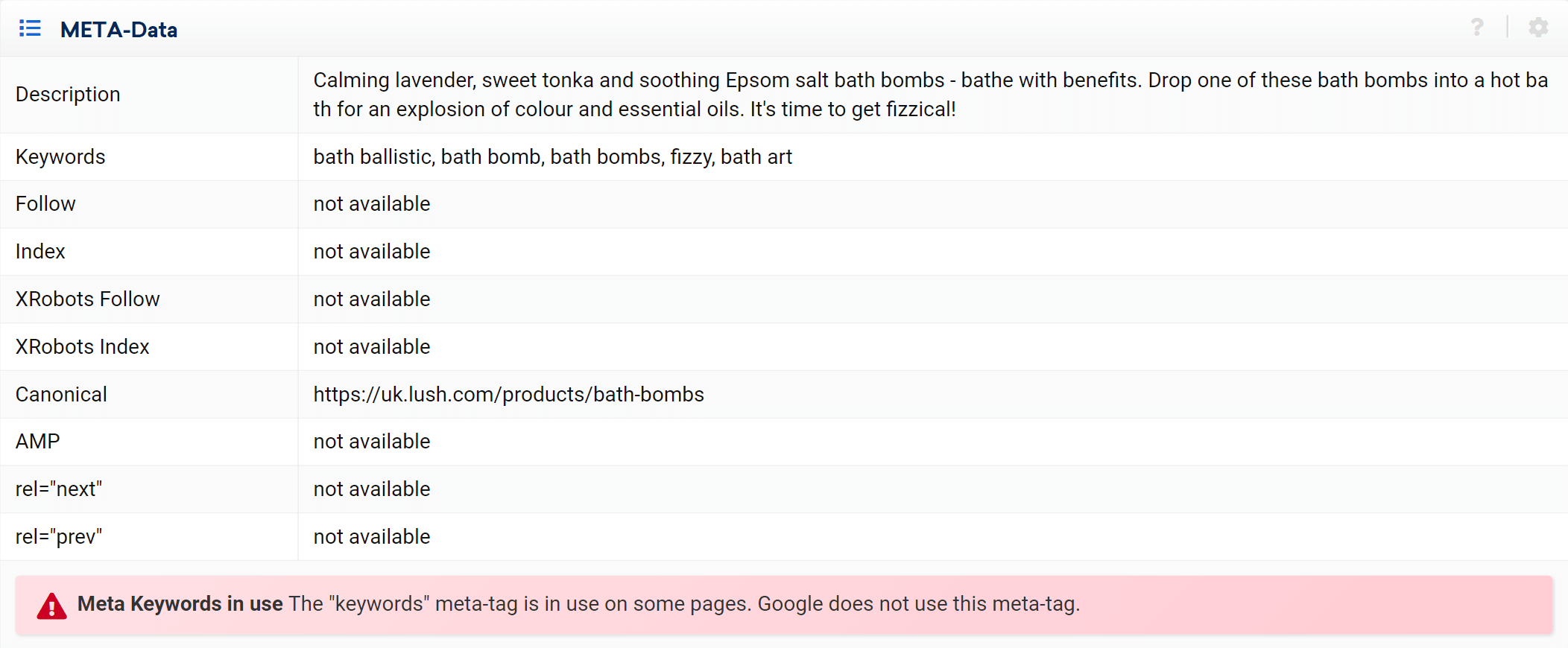
După cum puteți vedea, putem analiza toate aspectele de pe pagină referitoare la această adresă URL, atât linkuri interne de intrare cât și de ieșire, informații de server, etichete SEO și aici veți găsi și implementarea canonică, care este subiectul la îndemână. .
Modul expert
Accesând secțiunea Modul Expert, putem accesa toate adresele URL accesate cu crawlere ale proiectului nostru și putem folosi mai multe filtre pentru a ne rafina căutarea. În exemplul de mai jos, am inclus adresele URL care conțin /produse/ în adresele lor URL, dar care nu aparțin pieței /en_gb/.
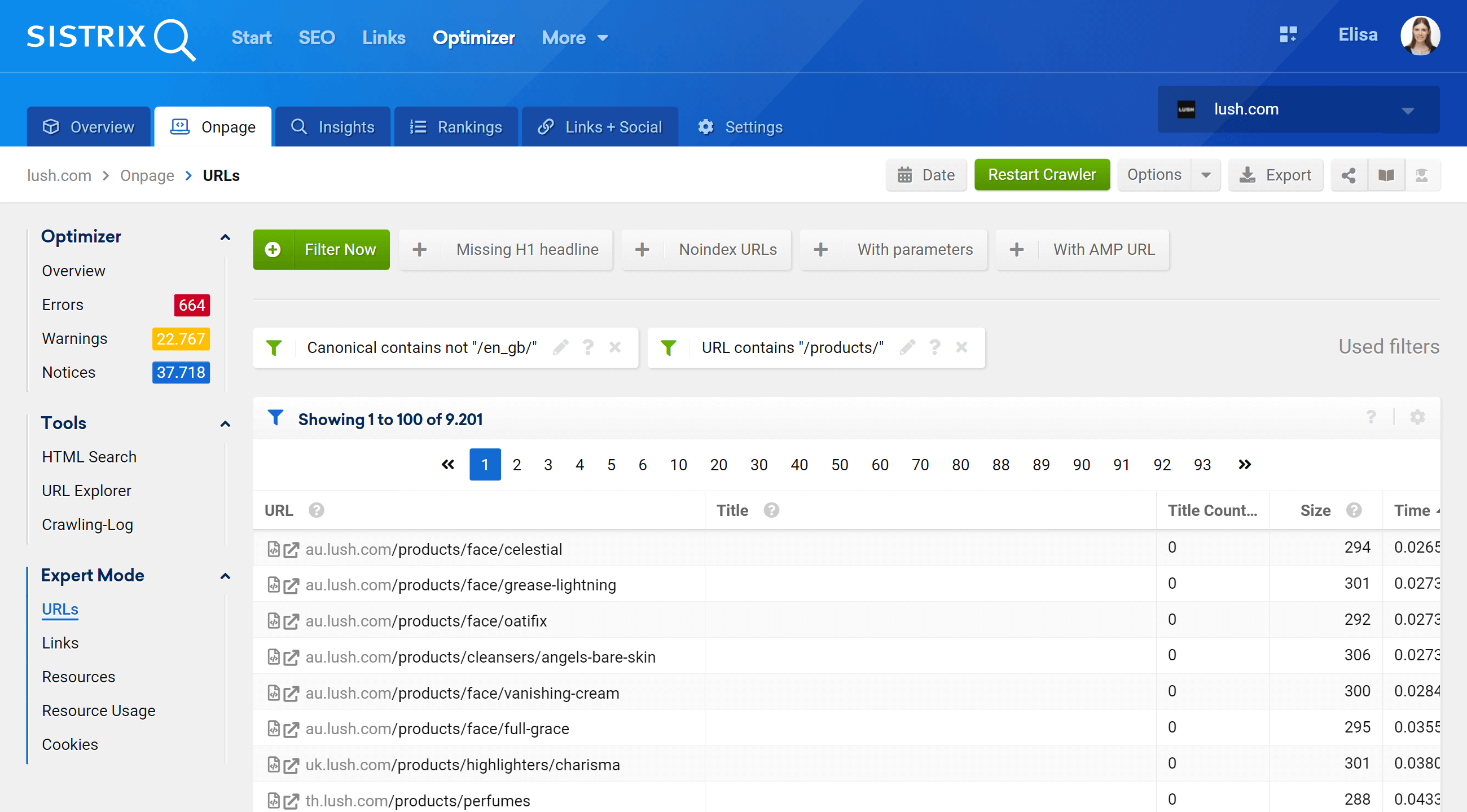
Mai mult decât atât, putem configura și coloanele tabelului pentru a afișa câmpurile care ne interesează mai mult. În exemplul meu, am ales să afișez coduri de stare, nivel de adâncime, legături interne, meta-roboți și canonice, dar am putea adăuga, pur și simplu, bifând caseta lor – titlul, descrierea, H1, dimensiunea, tipul de conținut etc.