正規タグとは何ですか?その使用方法
公開: 2022-04-17- 定義と意味
- 避けるべき命名法、考慮事項、およびエラー
- 実施手順
- HTMLタグ
- HTTPヘッダー
- その他のシグナル:サイトマップと内部リンク
- 効果とSEOのケース
- 正規タグを分析または監査する方法
- ソースコードを調べる
- Chromeデベロッパーツール
- Google検索コンソールで
- SISTRIXToolboxOptimizerを使用して正規タグを分析する方法
- クロールと警告の検出
- URLエクスプローラー:個々のURLを分析します
- エキスパートモード
定義と意味
正規タグは、ウェブサイト上の2つ以上のURLが重複、類似、または同一であることをGoogleに通知するために使用するHTML要素です。
このタグを使用すると、複数のURLのどれをSERPに表示するかを「選択」して、最終的に結果に表示するページをGoogleが決定できるようになります。 つまり、インデックスに登録する優先バージョンを示すシグナルをGoogleに提供しています。
このインデックス信号を強化するだけでなく、発信元のURLからターゲットの正規URLを指す内部リンクも統合します。
重複コンテンツや業界に浮かぶさまざまな神話に関しては、Google自体からの公式の情報源や参考文献を引用する以外に、それを明確にするためのより良い方法はありません。
「これを一度だけ寝かせましょう。皆さん、「重複コンテンツのペナルティ」のようなものはありません。 少なくとも、ほとんどの人がそう言うときの意味ではありません。 重複コンテンツのペナルティの神話を永続させないことで、仲間のウェブマスターを助けることができます!」
スーザンモスカ
https://webmasters.googleblog.com/2008/09/demystifying-duplicate-content-penalty.html
「重複コンテンツとは、一般に、ドメイン内またはドメイン間で、他のコンテンツと完全に一致するか、かなり類似しているコンテンツの実質的なブロックを指します。 ほとんどの場合、これは元々欺瞞的ではありません。」
グーグル
https://developers.google.com/search/docs/advanced/guidelines/duplicate-content
避けるべき命名法、考慮事項、およびエラー
正規ディレクティブに関する主な考慮事項と、それを指定する方法は次のとおりです。
- カノニカルは、CMSまたはサーバー自体(たとえば、index.html)によって生成された複数のアクセスポイントを持つことができるため、特にホームページで自己参照することができます。
- 似ている、重複している、または完全にまたは部分的に同一である2つのコンテンツがある場合は常に、正規を使用する必要があります。 それ以外の場合、このタグは無視できます。
- カノニカルはインデックス可能なURLを指し、200 OKを返し、 noindexタグを持たない必要があります。 言及する価値のあるもう1つのことは、無関係なURLに正規のURLを送信するべきではないということです。これは、Soft404として解釈されるためです。
- URLごとに一意の正規情報が1つだけ存在する必要があります。 2つの異なる正規タグがある場合、それらは衝突する可能性があり、両方とも無視されることになります。
- カノニカルは絶対URLと相対URLを使用できます。 ただし、相対URLはエラーや見落としが発生しやすいことを指摘することが重要です。
- スペルやその他の意図しない間違いに関して明らかなエラーがある場合は、正規タグを無視できます。 正規タグを尊重するか無視するかを決定するために分析される他のシグナルが存在する可能性があります。
- 正規タグを無視することもできます。たとえば、正規リンクをurl1からurl2に参照し、次にurl2からurl1に参照するなど、紛らわしいシグナルを送信する場合です。 この種の「ループ」が発生すると、予期しない動作が発生する可能性があります。
- カノニカルはクロスドメイン、つまりドメイン1からドメイン2へのポイントにすることができます。 両方のドメインを制御でき、重複を防ぐために一方のドメインのインデックスをもう一方のドメインよりも優先したい場合に使用する必要があります。 これには注意してください。
- 別の例として、コンテンツシンジケーションがあります。
ページ間の重複コンテンツの状況を解決する場合、これに対処する必要がある最も一般的なケースのいくつかは次のとおりです。
- wwwのあるURLとwwwのないURL
- httpを使用したURLとhttpsを使用したURL
- /で終わるURLと/で終わらないURL(ホームページは数えません)
- パラメータのあるURLとパラメータのないURL(セッションIDのあるURLなど)。
- ページ付けのあるURLとページ付けのないURL
- AMPを含むURLとAMPを含まないURL(必須のマークアップとして)。
- モバイルURL(mサイト)とデスクトップURL
- 事前(ステージング)URLと本番(本番)URL(とにかく、Googleをステージングから除外することをお勧めします)
- 等。
これらの状況はすべて正規タグを使用して解決できますが、Googleには別のより直接的な方法があります。301リダイレクトです。
あなたはたくさんの301と標準的なタグの比較を読むでしょう。 あまり深く掘り下げるつもりはありませんが、下の画像でこの問題に関する最も重要な点を強調します。
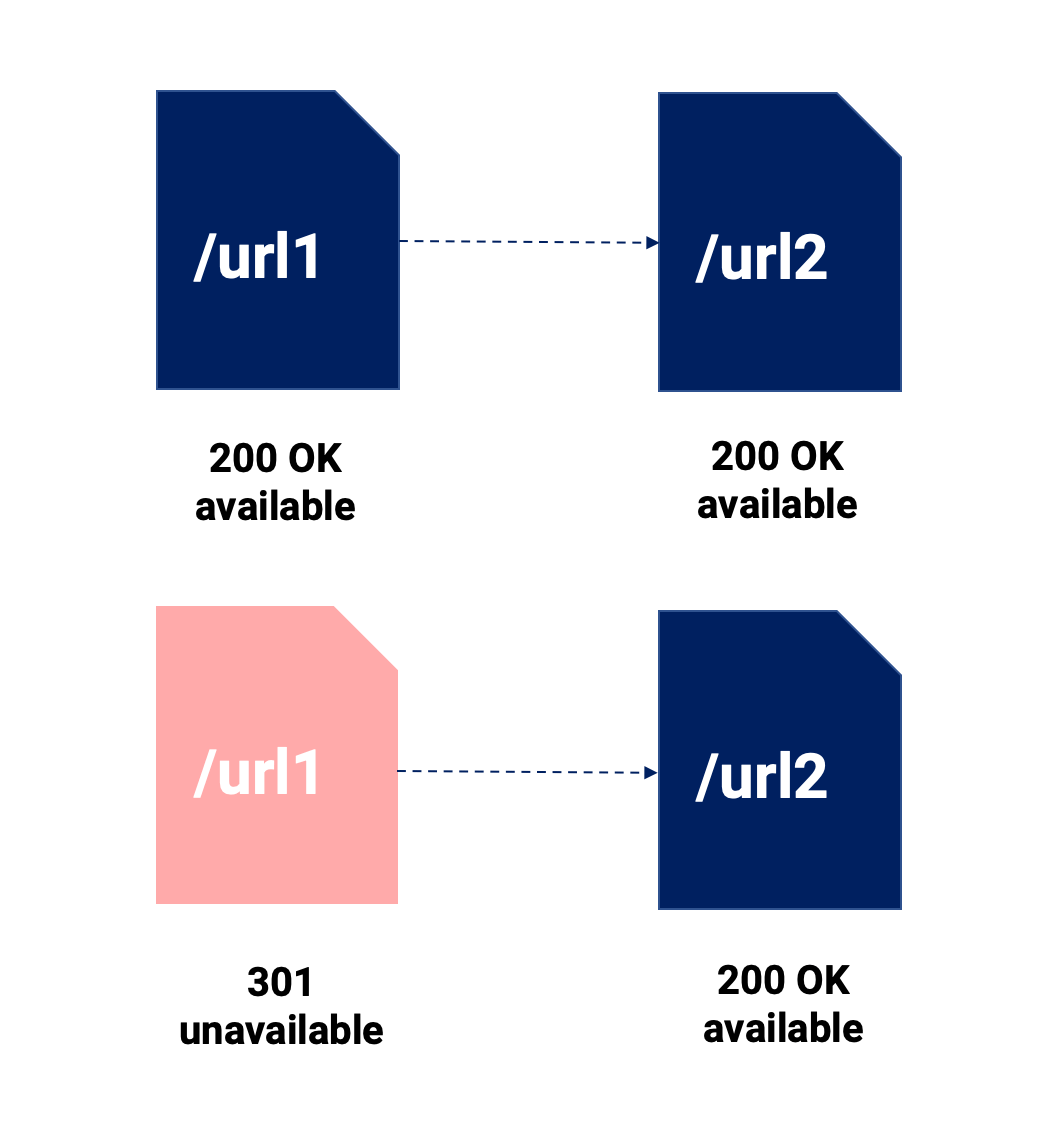
この視覚的な要約を使用して、次のことを強調したいと思います。
- 301リダイレクトは、2つのコンテンツをマージします。これは、元のコンテンツが存在しなくなることを意味します。 それは直接であり、100%グーグル(そしてユーザー)が続く。
- 正規の、それが行うことは、どのチャネルでも利用可能なさまざまなURLを維持できるようにすることであり、Googleがディレクティブを尊重する場合、正規化されたURLのみがSEOチャネルのインデックスに登録されます。
- どちらも信号の希薄化を伴う可能性があり、正規化されたURLにはそれらを指す内部リンクと外部リンクが含まれる可能性があるため、301リダイレクトを使用しない場合は、より大きな影響が生じる可能性があります。
実施手順
正規タグを実装する方法はいくつかあります。
HTMLタグ
正規を実装する最も一般的な方法は、属性rel =” canonical”と各URLの<head>内の正規バージョンへの絶対パスを持つリンク要素を配置することです。 正しい構文は次のとおりです。
<link rel="canonical" href="https://www.sistrix.com/ask-sistrix/what-is-the-canonical-tag-and-how-to-use-it/" />HTTPヘッダー
この方法は通常、HMTL以外のページで使用されます。 例:PDF、XML、またはTXTファイル。
これは、PDFページと一致するHTMLページの両方がある場合に使用される一般的な方法です。 カノニカルを通じて、HTMLページをランク付けすることをGoogleに示すことができます。
それでも、さまざまなケースが存在する可能性があるため、この投稿をお勧めします。.htaccessファイルを使用したより技術的な実装について説明します。
<Files "seo-guide.pdf"> Header add Link "< http://www.sistrix.com/seo-guide/ >; rel=\"canonical\"" </Files>その他のシグナル:サイトマップと内部リンク
この場合、正規のディレクティブを実装するつもりはありませんが、暗黙的に、このURLは(他のバージョンとは対照的に)元のURLであり、より重要で価値があることを示しています。
サイトマップにURLを追加したり、WebサイトのナビゲーションからURLをリンクしたりするのと同じくらい簡単なことは、すでに暗黙的かつ暗黙的な重要性を持っているため、このURLバージョンの重要性に関するSEOシグナルを送信しています。 私たちが自分自身と矛盾する場合、または他のあいまいなまたは決定的なシグナルがない場合、SEOの単純さの法則に違反することになります。Googleにとってこれまで以上に複雑にしないでください。
- 2つの重複するURLを使用して、正規化を使用すると、元のURLがサイトマップに含まれますが、正規化されたものは含まれません。
- 2つの重複するURLを使用すると、canonicalsを使用して、元のURLが目立つようにリンクされ、正規化されません(ただし、これが常に可能であるとは限りません。正規化されたURLには、それを指すリンクが含まれる場合があります)。
効果とSEOのケース
カノニカルの使用がもたらす最大の影響は、Googleによって尊重されると、カノニカルタグが指しているURLがインデックスに登録可能になり、カノニカルを発行するURLがステップダウンして自分自身を犠牲にすることです。これにより、よりオリジナルなコンテンツが可能になります。インデックスを取得します。
一方、カノニカルを発行するURLがナビゲーション構造内のどこかで内部リンクを受信した場合、 Googleはこのページをクロールしてそれに時間を費やすことができます。 これにより、Robots.txt(「noindex」でさえ)とcanonicalの併用について真剣に考える必要があります。 クロールの予算を節約したい場合は、重複とその正規の場所をGoogleが理解できない可能性があります。

より具体的なケースについて言えば、もう少し指定することができます。
- パッシブパラメータ:予防策として、Google検索コンソールのパラメータ管理と組み合わせて使用されます。 ただし、これらのパラメータは、キャンペーン(有料、電子メール、ソーシャルなど)にタグを付けるために使用されます。
- アクティブなパラメータ:言語、フィルター。 ここで重要なのは、検索意図に応答するかどうかを確実に知ることに加えて、位置付けることができる最小限のオリジナルコンテンツを持っているものを特定することです。 追加の問題は、これらのフィルターの内部リンクを介した内部リンクおよび権限の浪費である可能性があります。
- ページ付け:ページ付けに関する現在のシナリオは、それ自体でまだ論争の的です。 Googleはrelprevrel nextガイドラインを削除しました。現在、SEOの世界では、新しいページやリンクを生成せずにユーザーの機能を維持するために、noindex、最初のページの標準、無限スクロール、またはAJAXなどの動的テクノロジーを使用する必要があるかどうかが議論されています。場合によっては。 それは決して些細な決断ではありません。
- 類似の属性(色、サイズ)を持つ製品ページ:フィルターについて述べたのと同様に、コンテンツがランク付けするために最低限オリジナルではない場合を特定する必要があり、検索意図に応答するかどうかを知る必要があります。 「検索されないものは索引付けされるべきではない」という規則に留意する必要があります。
正規タグを分析または監査する方法
ここで、正規タグを識別または監査する方法のビジネスに取り掛かります。 皆の好みに合う方法があります:
ソースコードを調べる
ページにアクセスし、ページの任意の場所を右クリックして、[ページソースの表示]オプション(Windowsを使用している場合はControl + U、Macを使用している場合はCMD + Alt + U)のメニューを表示します。
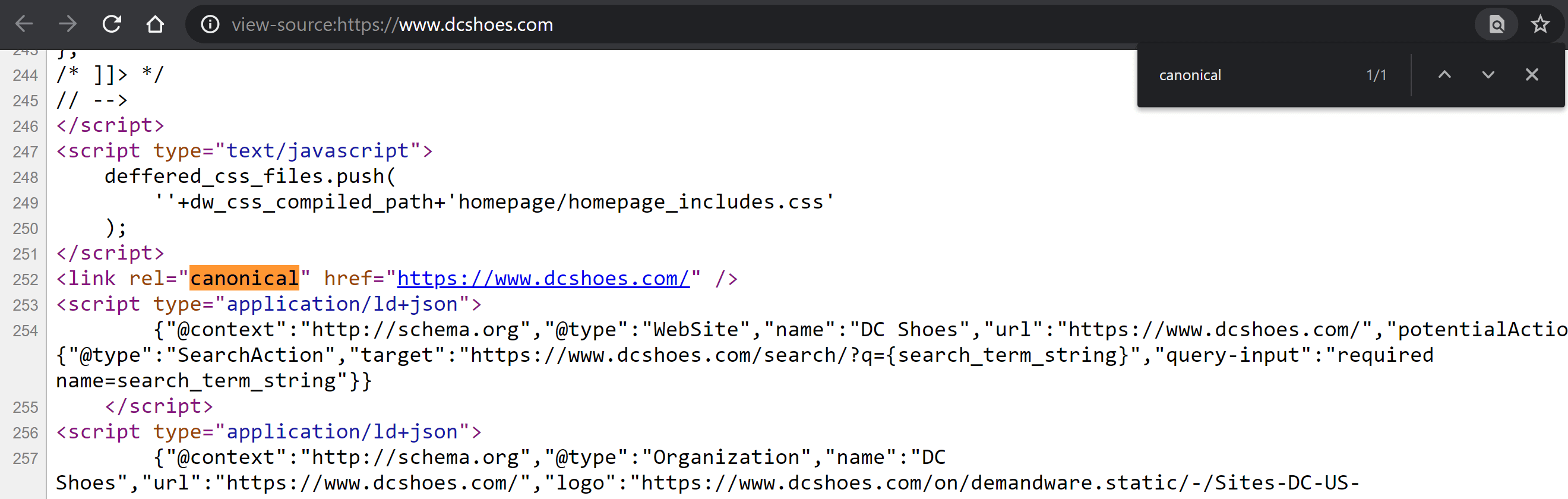
内部に入ったら、Windowsの場合はControl + F、Macの場合はCMD + Fを押して、コード内を検索します。 「canonical」と入力すると、タグがある場合は別の色で強調表示されます。 その内容を比較し、この値が正しく定義されているかどうかを判断します。
Chromeデベロッパーツール
Chromeを使用して、分析するWebサイトを開き、画面を右クリックして、[検査]をクリックします。 これにより、開発者ツールが開き、前のポイントで行ったように、Control+FまたはCmd+Fでタグを検索できます。
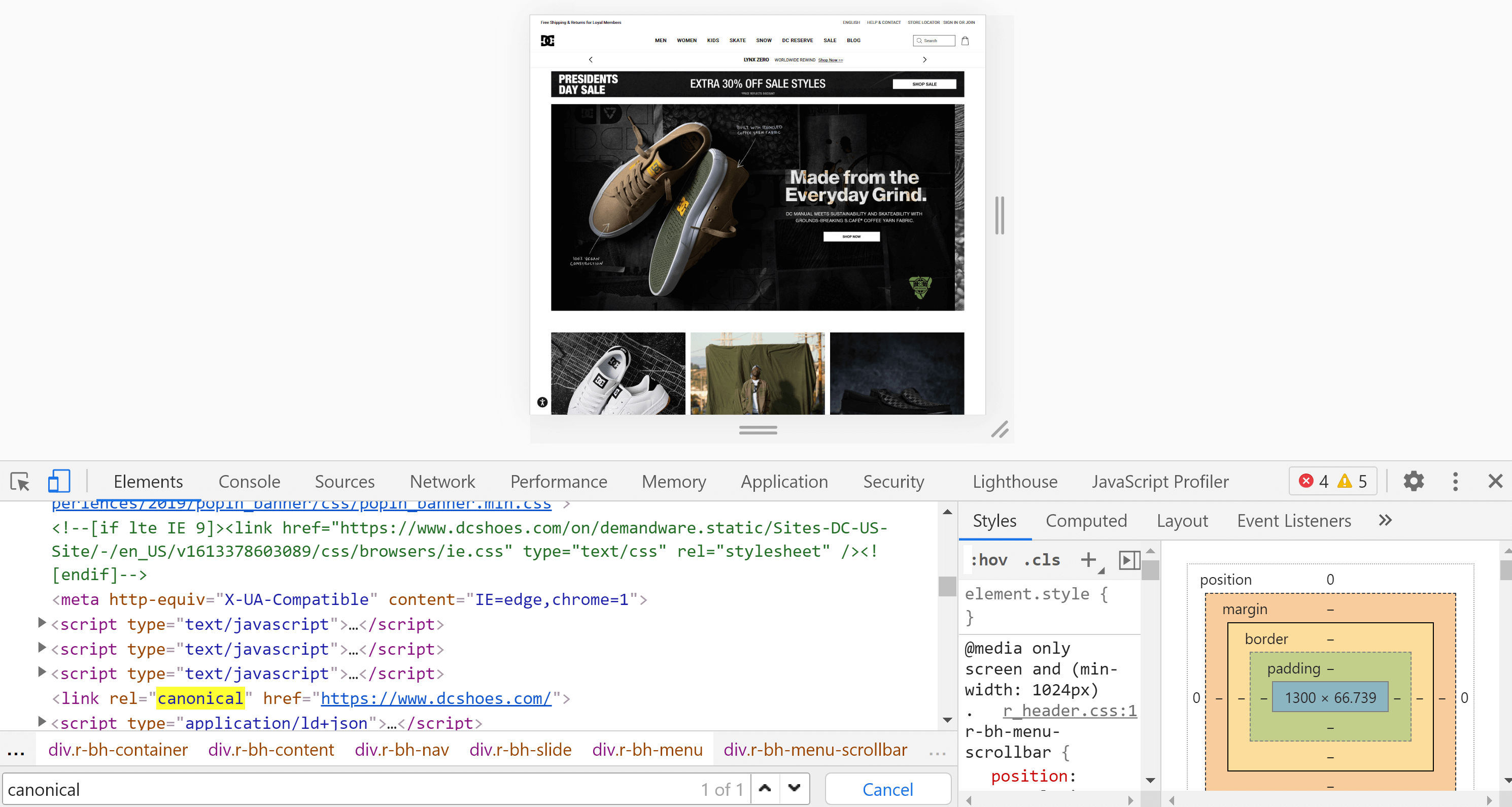
ページのソースコードとインスペクターの主な違いは、2番目のコードはすでにページをレンダリングしており、このプロセス(JavaScriptの実行を含む)が終了した後にコンテンツが表示されることです。
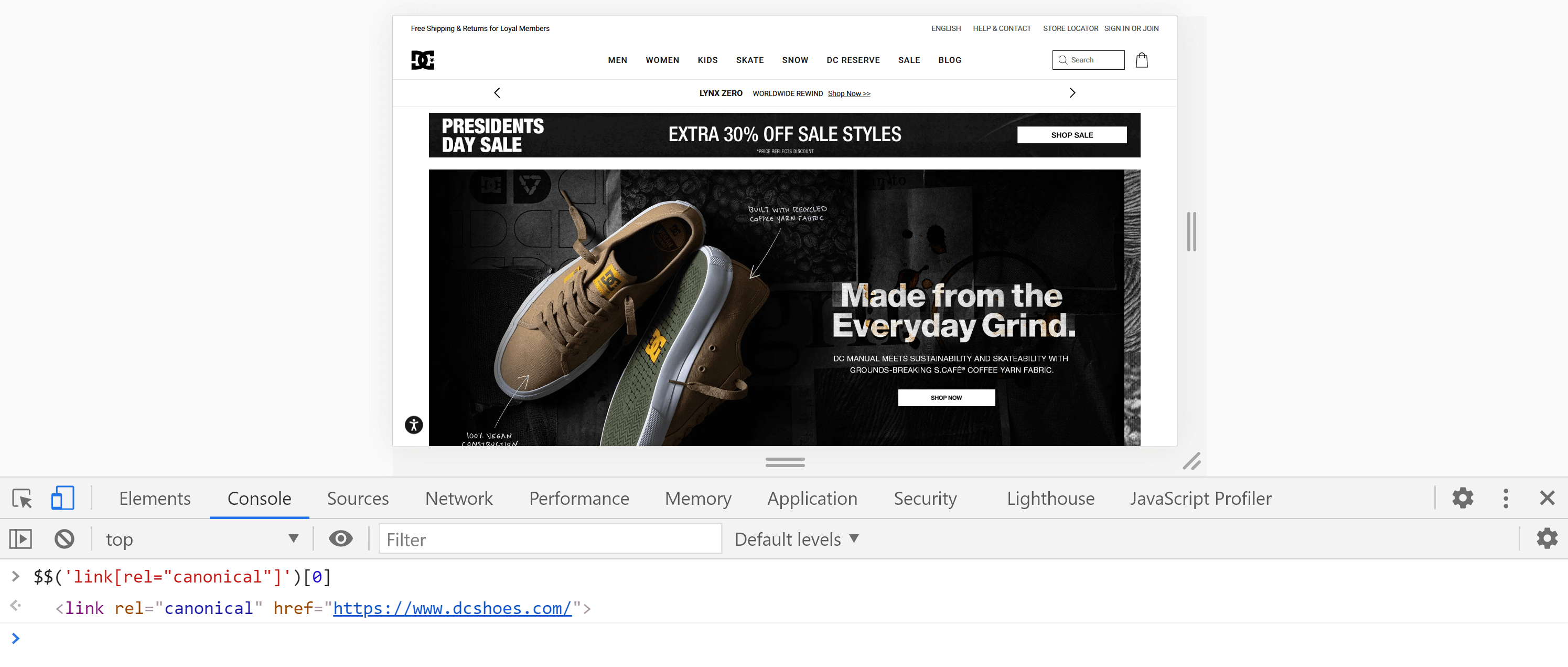
または、[コンソール]タブに移動し、次のコマンドを入力して、コンソールを使用することもできます。
$$('link [rel = "canonical"]')[0]
Google検索コンソールで
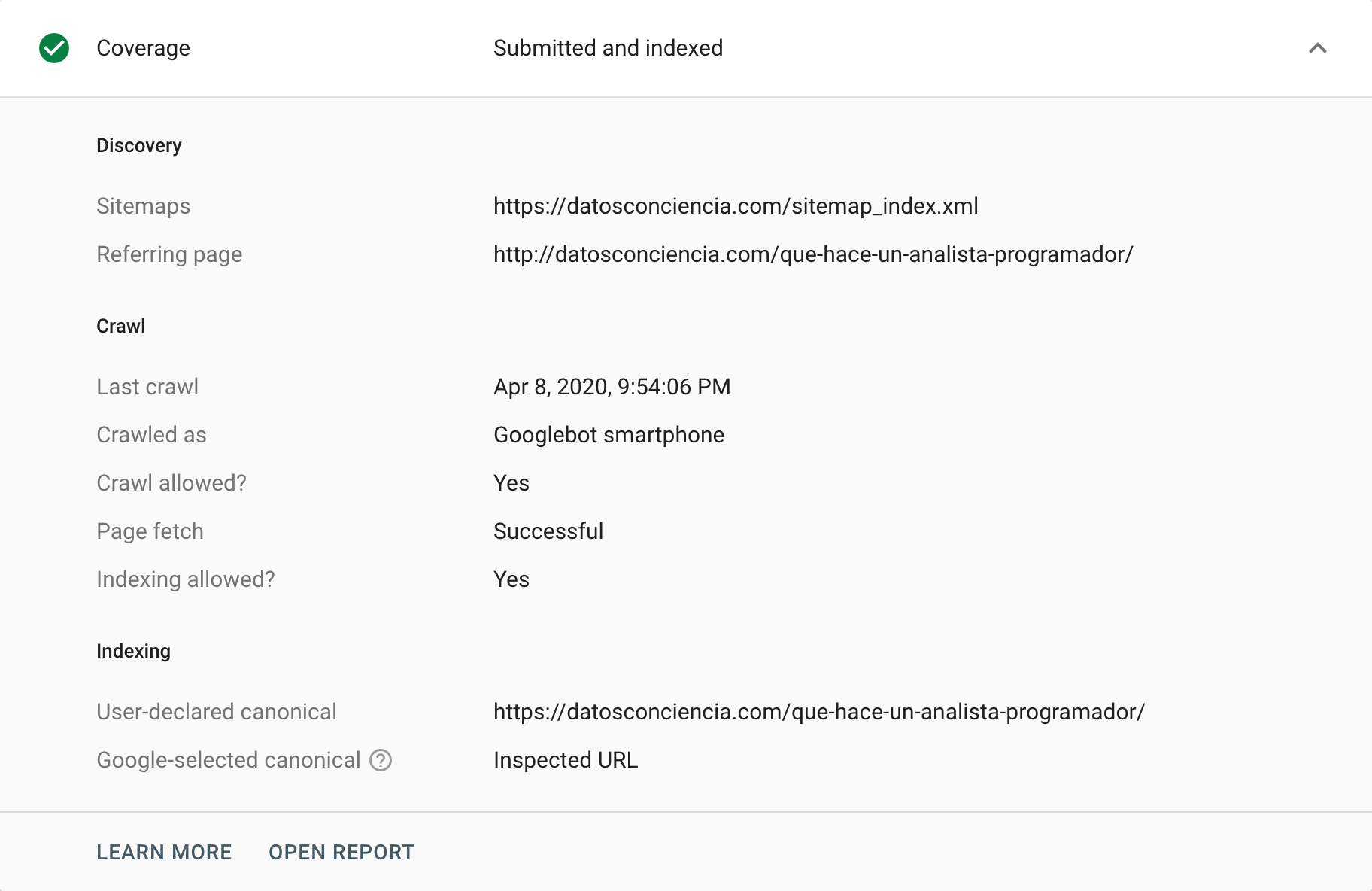
Google Search Consoleは、正規タグを分析または監査するためのさまざまな方法を提供します。 そのための1つの方法は、「カバレッジ」レポートに移動することです。このレポートでは、特定のURLをインデックスから除外する原因となったイベントを分析できます。 この「除外」セクションでは、正規タグに関連する状況を、正しい場合と正しくない場合(正しく解釈された場合と誤って解釈された場合)の両方で見つけることがあります。 間違いなく、問題を特定するのに役立つスレッドを引っ張るのに最適な方法です。

一方、個々のURLの正規タグに関する洞察を提供できるURL検査ツールがあります。 特に、Googleの指示と、Googleが解釈することを選択したものとの間に違いがある場合は、それらをクロールしてステータスを返すようにリクエストできます。
SISTRIXToolboxOptimizerを使用して正規タグを分析する方法
SISTIXToolboxOptimizerを使用してカノニカルを分析する方法はいくつかあります。
クロールと警告の検出
クローラーであるオプティマイザーは、Webサイトにアクセスして、改善の機会、エラー、および通知されるその他の側面を簡単かつ視覚的に特定するため、データの処理に時間を浪費する必要はありません。 これは、オプティマイザーが(間違えた場合に)通知する正規タグに関連する例です。

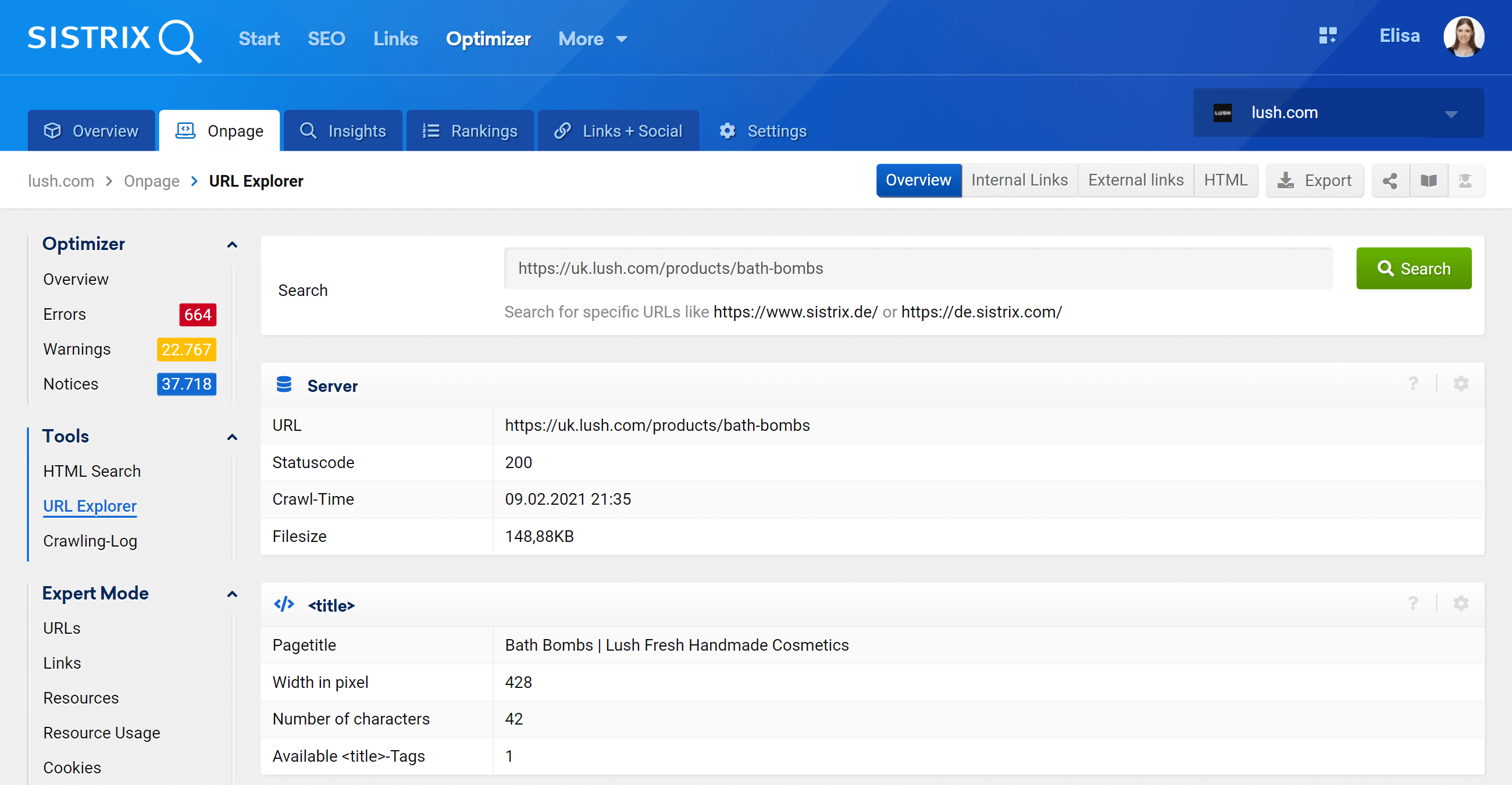
URLエクスプローラー:個々のURLを分析します
この機能は、Google検索コンソールのURL検査ツールに似ています。つまり、オプティマイザープロジェクトでクロールされた個々のURLを評価し、その1つの特定のURLの情報を確認できます。
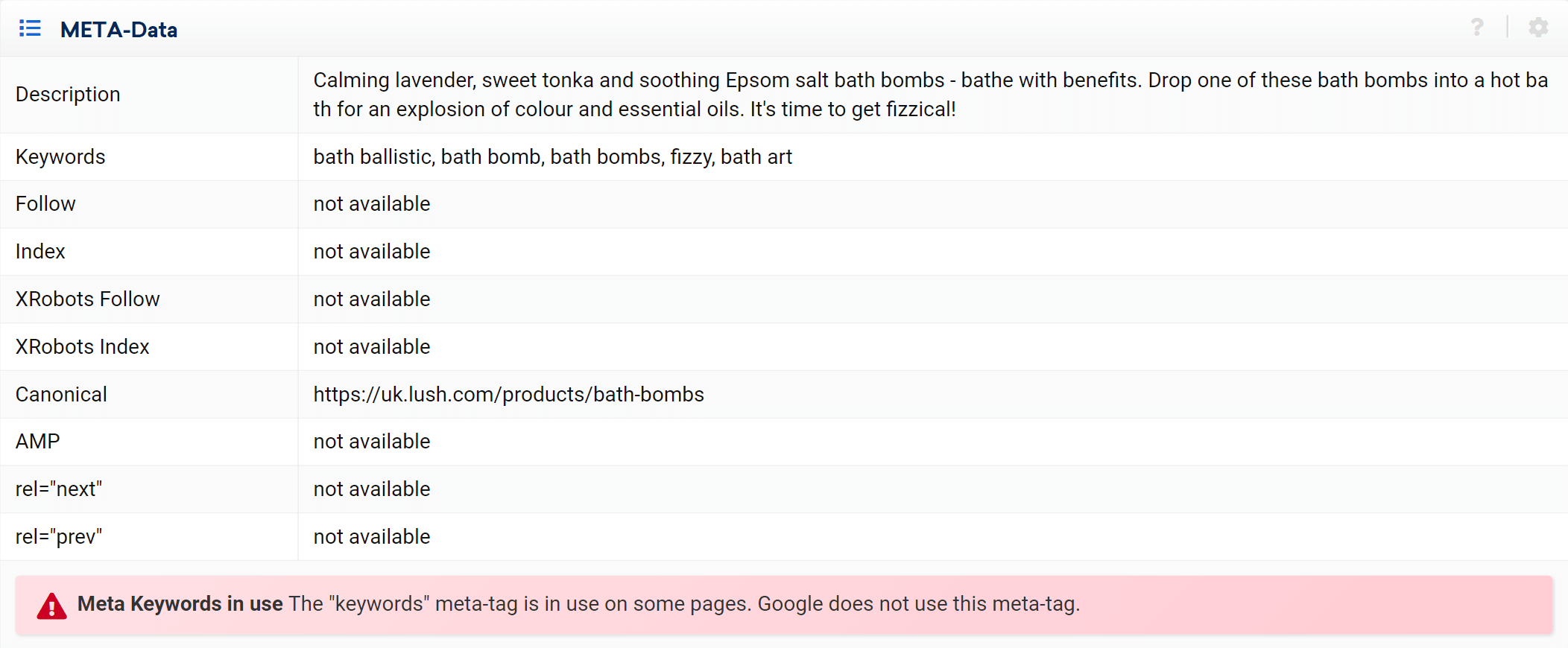
ご覧のとおり、このURLに関するすべてのページ上の側面、インバウンドとアウトバウンドの両方の内部リンク、サーバー情報、SEOタグを分析できます。ここには、目前の主題である正規の実装もあります。 。
エキスパートモード
エキスパートモードセクションに移動すると、プロジェクトのクロールされたすべてのURLにアクセスし、複数のフィルターを使用して検索を絞り込むことができます。 以下の例では、URLに/ products /を含むURLを含めましたが、/en_gb/マーケットには属していません。
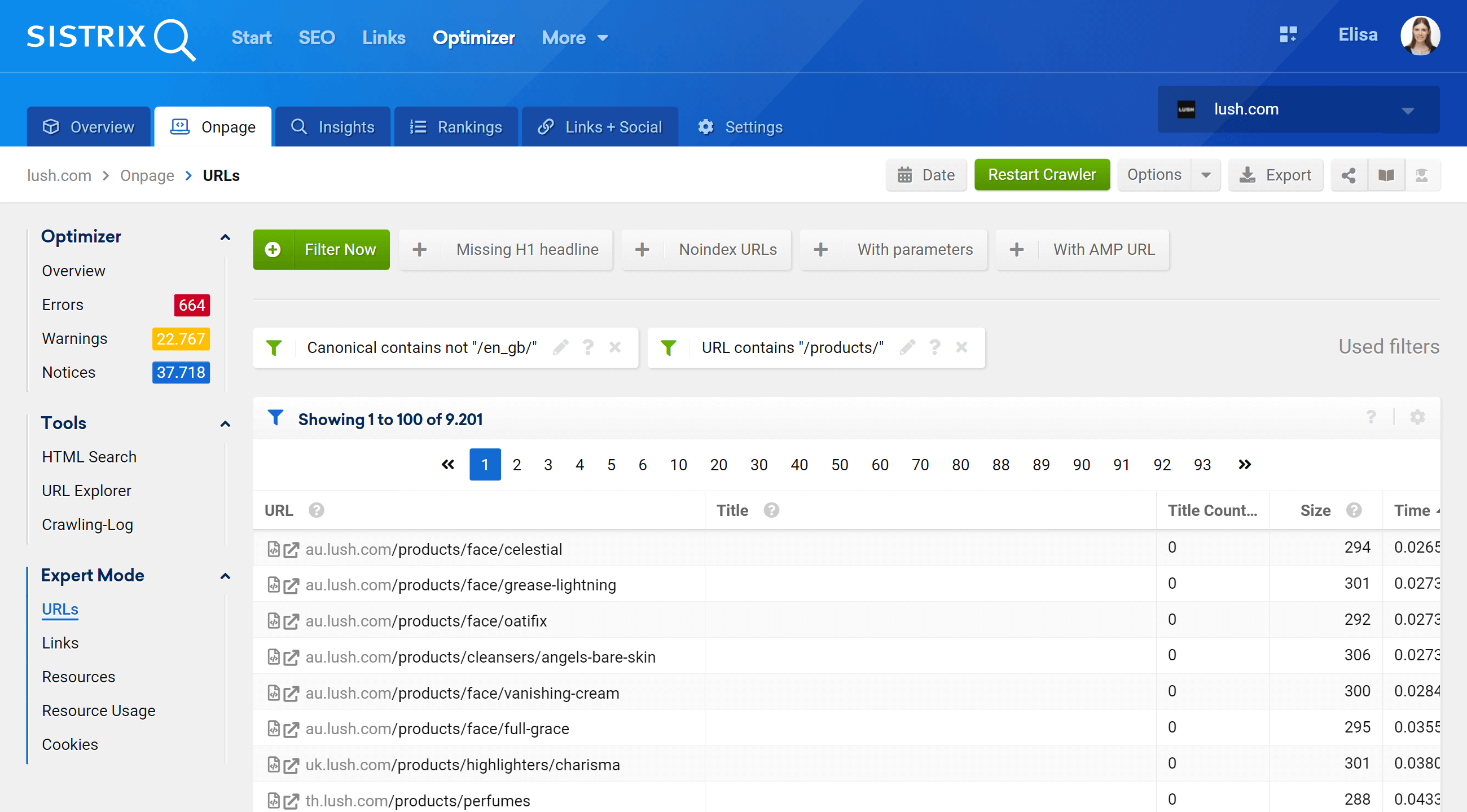
さらに、より関心のあるフィールドを表示するようにテーブル列を構成することもできます。私の例では、ステータスコード、深度レベル、内部リンク、メタロボット、および正規を表示することを選択しましたが、単純に追加することもできます。チェックボックスをオンにします–タイトル、説明、H1、サイズ、コンテンツの種類など。