¿Qué es la etiqueta canónica y cómo usarla?
Publicado: 2022-04-17- Definición y significado
- Nomenclatura, consideraciones y errores a evitar
- Procedimientos de implementación
- etiqueta HTML
- Encabezado HTTP
- Otras señales: mapa del sitio y enlaces internos
- Casos de efecto y SEO
- Cómo analizar o auditar etiquetas canónicas
- Explora el código fuente
- Herramientas para desarrolladores de Chrome
- En la consola de búsqueda de Google
- Cómo analizar etiquetas canónicas utilizando SISTRIX Toolbox Optimizer
- Rastreo y detección de advertencias
- Explorador de URL: analiza URL individuales
- Modo experto
Definición y significado
La etiqueta canónica es el elemento HTML que usamos para que Google sepa que 2 o más URL en nuestro sitio web son duplicadas, similares o idénticas.
Esta etiqueta nos permite 'seleccionar' cuál de las múltiples URL debe mostrarse en las SERP, para ayudar a Google a decidir qué página debe mostrar finalmente en los resultados. En otras palabras, estamos proporcionando a Google una señal que indica la versión preferida para indexar .
Además de fortalecer esta señal de indexación, también consolida nuestros enlaces internos que apuntan desde la URL de origen a la URL canónica de destino.
Con respecto al contenido duplicado y varios mitos que flotan en la industria, no hay mejor manera de aclararlo que citando fuentes oficiales y referencias provenientes del propio Google:
“Acabemos con esto de una vez por todas, amigos: no existe tal cosa como una “penalización por contenido duplicado”. Al menos, no en la forma en que la mayoría de la gente quiere decir cuando dice eso. ¡Puedes ayudar a tus compañeros webmasters al no perpetuar el mito de las penalizaciones por contenido duplicado!”
Susan Moska
https://webmasters.googleblog.com/2008/09/demystifying-duplicate-content-penalty.html
“El contenido duplicado generalmente se refiere a bloques sustanciales de contenido dentro o entre dominios que coinciden completamente con otro contenido o son apreciablemente similares. Principalmente, esto no es engañoso en su origen”.
https://developers.google.com/search/docs/advanced/guidelines/duplicate-content
Nomenclatura, consideraciones y errores a evitar
Estas son las principales consideraciones con respecto a la directiva canónica y las formas de especificarla:
- Un canónico puede ser autorreferencial, especialmente en la página de inicio, ya que puede tener varios puntos de acceso generados por el CMS o por el propio servidor (index.html, por citar uno).
- Se debe utilizar una canónica siempre que existan dos contenidos similares, duplicados o, en otras palabras, total o parcialmente idénticos. De lo contrario, esta etiqueta se puede ignorar.
- Un canonical debe apuntar a una URL indexable, devolver 200 OK y no llevar una etiqueta noindex . Otra cosa que vale la pena mencionar es que no debemos enviar un canonical a una URL irrelevante, porque se interpretará como un Soft 404.
- Solo debe haber un canónico único para cada URL. Si hay dos etiquetas canónicas diferentes, pueden chocar y ambas terminarán siendo ignoradas.
- Un canónico puede usar URL absolutas y relativas. Sin embargo, es importante señalar que las URL relativas son propensas a errores y descuidos.
- Una etiqueta canónica se puede ignorar si hay errores obvios, en términos de ortografía u otros errores no intencionales. Puede haber otras señales, que se analizarán para determinar si se debe respetar o ignorar una etiqueta canónica.
- Una etiqueta canónica también se puede ignorar si enviamos señales confusas, como hacer referencia a una etiqueta canónica de url1 a url2 y luego de url2 a url1. Incurrir en este tipo de “bucles” puede resultar en un comportamiento inesperado.
- Un canónico puede ser multidominio, es decir, apuntar desde el dominio1 al dominio2. Debe utilizarse –preferiblemente– cuando tengamos control sobre ambos dominios y queramos favorecer la indexación de un dominio sobre otro para evitar duplicidades. Tenga cuidado con esto.
- Otro ejemplo puede ser la sindicación de contenidos.
Siempre que solucione situaciones de contenido duplicado entre páginas, algunos de los casos más típicos en los que tendremos que lidiar con esto son:
- URL con www vs URL sin www
- URL con http vs URL con https
- URL que terminan en / frente a URL que no terminan en / (sin contar la página de inicio)
- URL con parámetros frente a URL sin parámetros (como URL con ID de sesión).
- URLs con paginación vs URLs sin paginación
- URL con AMP frente a URL sin AMP (como marcado obligatorio).
- URL móviles (m-sites) frente a URL de escritorio
- URL previas (de puesta en escena) frente a URL de producción (de producción) (de todos modos, es mejor mantener a Google fuera de la puesta en escena según el inicio de sesión HTTP)
- Etc.
Si bien todas estas situaciones podrían resolverse utilizando etiquetas canónicas, existe otro método más directo para Google: la redirección 301 .
Leerá muchas comparaciones de etiquetas 301 y canónicas. No vamos a ahondar mucho en ello, pero vamos a recalcar los puntos más importantes al respecto en la siguiente imagen:
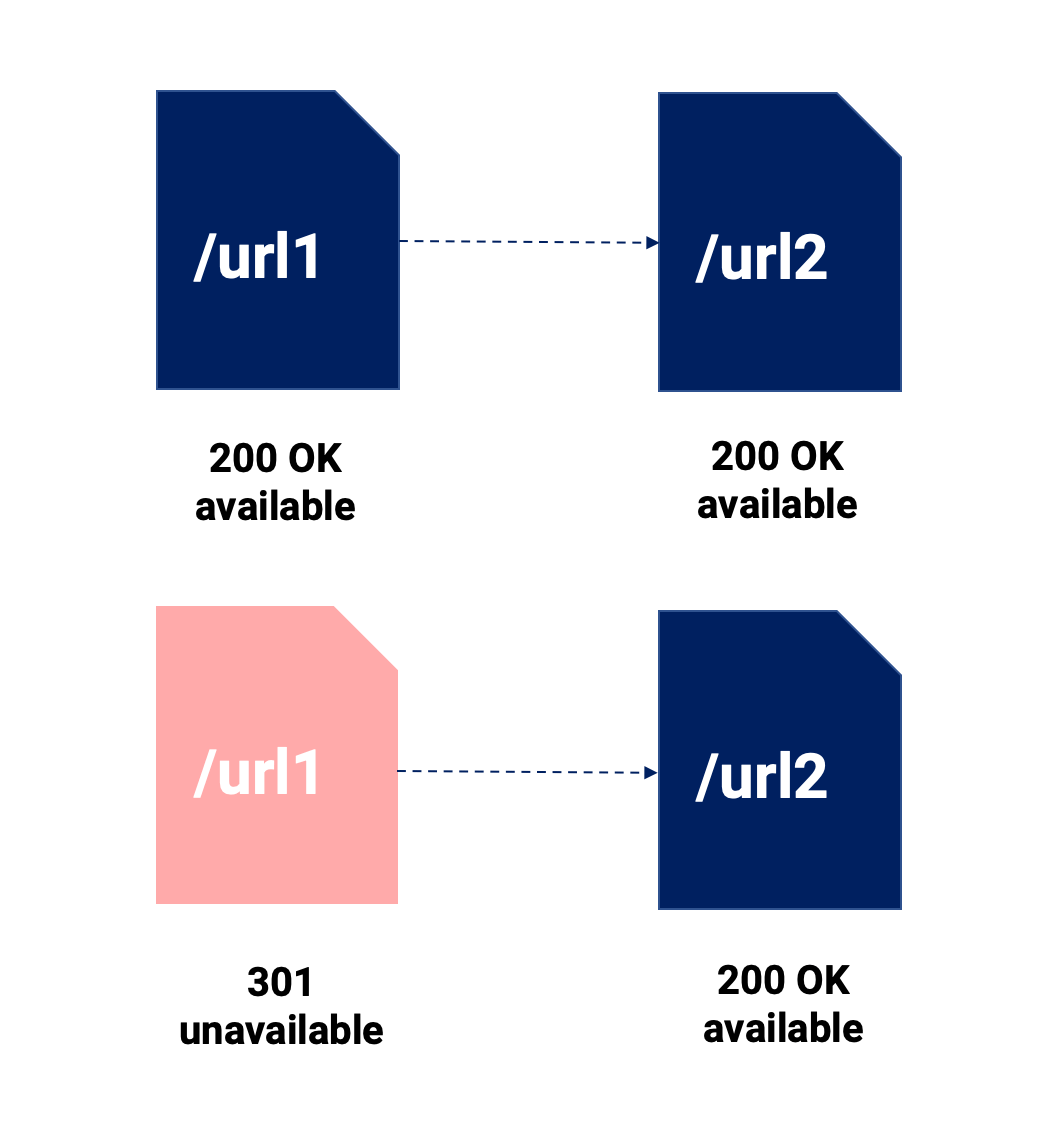
Usando este resumen visual, queremos resaltar las siguientes cosas:
- La redirección 301 fusiona dos piezas de contenido, lo que significa que el contenido original deja de existir. Es directo y 100% seguido por Google (y usuarios).
- La canonical, lo que hace es permitirnos tener disponibles varias URL para cualquier canal, y si Google respeta la directiva, solo la URL canonicalizada será indexada para el canal SEO.
- Ambos pueden implicar posiblemente la dilución de la señal, y podría tener un efecto más significativo cuando no usamos una redirección 301, ya que las URL canonicalizadas pueden tener enlaces internos y externos que apuntan a ellas, lo que nos obliga a dividir nuestros esfuerzos entre varias URL.
Procedimientos de implementación
Hay varias formas de implementar etiquetas canónicas:
etiqueta HTML
La forma más común de implementar un canonical es colocando un elemento de enlace con el atributo rel=”canonical” y la ruta absoluta a la versión canónica dentro del <head> de cada URL. Aquí está la sintaxis correcta:
<link rel="canonical" href="https://www.sistrix.com/ask-sistrix/what-is-the-canonical-tag-and-how-to-use-it/" />Encabezado HTTP
Este método se usa normalmente en páginas que no son HTML. Por ejemplo: archivos PDF, XML o TXT.
Este es el método típico que se utiliza cuando tenemos un PDF y una página HTML coincidente. A través del canonical podemos mostrarle a Google que queremos que la página HTML se posicione.
No obstante, dada la variedad de casos diferentes que puede haber, recomendamos este post, cubriendo la implementación más técnica a través del archivo .htaccess.
<Files "seo-guide.pdf"> Header add Link "< http://www.sistrix.com/seo-guide/ >; rel=\"canonical\"" </Files>Otras señales: mapa del sitio y enlaces internos
En este caso no vamos a implementar la directiva canónica, pero afirmamos implícitamente que esta URL (a diferencia de sus otras versiones) es la original y tiene más peso y valor.
Algo tan simple como agregar URL a un mapa del sitio o vincular una URL desde la navegación del sitio web ya tiene una importancia tácita e implícita , por lo que estamos enviando una señal de SEO sobre la importancia de esta versión de URL para nosotros. Si nos contradecimos o hay otras señales ambiguas o inconclusas, estaremos incumpliendo la ley de la sencillez en el SEO : no se lo pongas más complicado a Google de lo que ya es.
- Con 2 URL duplicadas, utilizando canonicals, la URL original se incluirá en el mapa del sitio, la canonicalizada no.
- Con 2 URL duplicadas, utilizando canonicals, la URL original se vinculará de manera destacada, la canonicalizada no lo estará (aunque esto no siempre es posible, y la URL canonicalizada puede tener algún enlace que la apunte).
Casos de efecto y SEO
El mayor impacto que puede tener el uso de canonical es que, una vez que Google lo respeta, la URL a la que apunta la etiqueta canonical se vuelve indexable , y el que emite el canonical se retirará y se sacrificará, de modo que el contenido más original pueda ser indexado.

Por otro lado, si la URL que emite el canonical recibe enlaces internos en algún lugar dentro de la estructura de navegación, Google podrá rastrear esta página e invertir tiempo en ella . Esto debería hacernos pensar seriamente en nuestro uso combinado de Robots.txt (incluso "noindex") y canonical. Si queremos ahorrar nuestro presupuesto de rastreo, es posible que impidamos que Google entienda dónde se encuentran el duplicado y su canónico.
Hablando de casos más particulares, podemos especificar un poco más:
- Parámetros pasivos : se utilizan por precaución, en combinación con la gestión de parámetros de Google Search Console. Sin embargo, estos parámetros se utilizan para etiquetar campañas (de pago, de correo electrónico, sociales…).
- Parámetros activos : idioma, filtros. La clave aquí es identificar cuáles tienen contenido mínimamente original que podamos posicionar, además de saber con certeza si responden o no a un intento de búsqueda. Otros problemas pueden ser los enlaces internos y el desperdicio de autoridad a través de los enlaces internos de estos filtros.
- Paginación : el escenario actual con respecto a la paginación sigue siendo una controversia en sí misma. Google eliminó la directriz rel prev rel next, y ahora el mundo del SEO está debatiendo si debemos usar noindex, un canónico en la primera página, desplazamiento infinito o tecnologías dinámicas como AJAX para mantener la funcionalidad para el usuario sin generar nuevas páginas/enlaces. dependiendo del caso. No es una decisión trivial en absoluto.
- Páginas de productos con atributos similares (color, tamaño) : similar a lo que dijimos sobre los filtros, necesitamos identificar cuándo su contenido no es mínimamente original para clasificar, y necesitamos saber si responden a una intención de búsqueda. Debemos tener presente la regla de “lo que no se busca, no se indexa” .
Cómo analizar o auditar etiquetas canónicas
Ahora, nos ponemos manos a la obra de cómo identificar o auditar etiquetas canónicas. Tenemos métodos que se adaptan a las preferencias de cada uno:
Explora el código fuente
Visite la página y haga clic derecho en cualquier parte de la página para revelar el menú con la opción "Ver código fuente de la página" (Control + U si está usando Windows; CMD + Alt + U si está usando Mac).
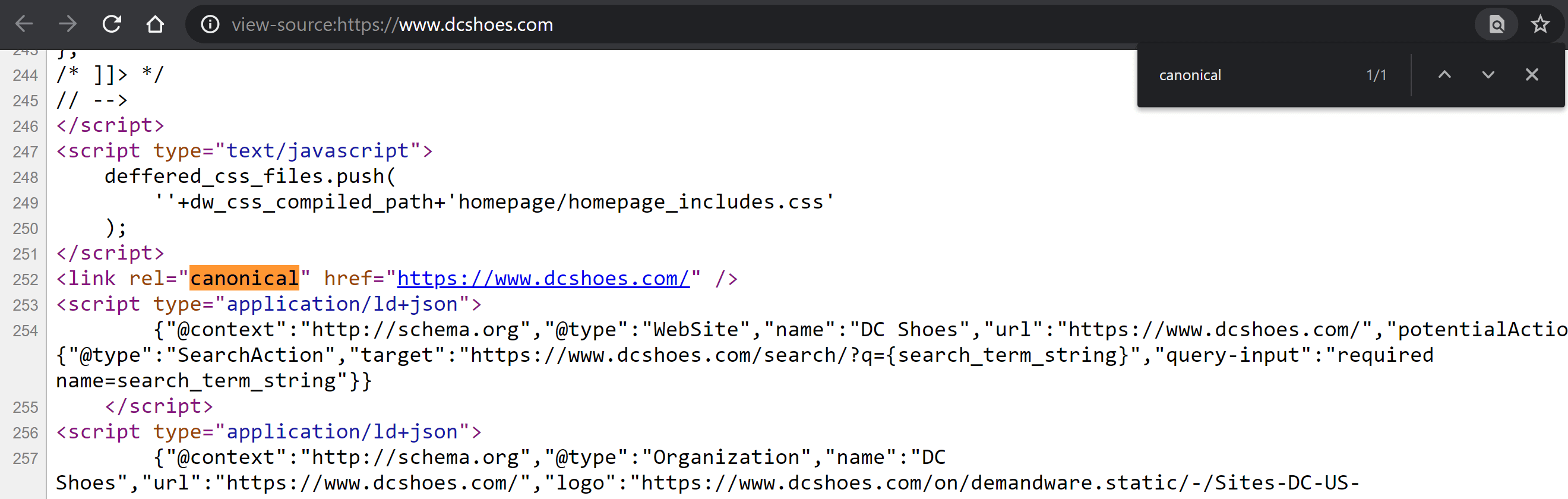
Una vez dentro, presiona Control + F en Windows o CMD + F en Mac para buscar dentro del código. Escriba "canonical", para que la etiqueta se resalte en un color diferente, si está allí. Compara su contenido y determina si este valor se ha definido correctamente o no.
Herramientas para desarrolladores de Chrome
Usando Chrome podemos abrir el sitio web que queremos analizar, hacer clic derecho en la pantalla y presionar "Inspeccionar". Esto abrirá las herramientas de desarrollador, donde podremos buscar la etiqueta con Control + F o Cmd + F, tal y como hicimos en el punto anterior.
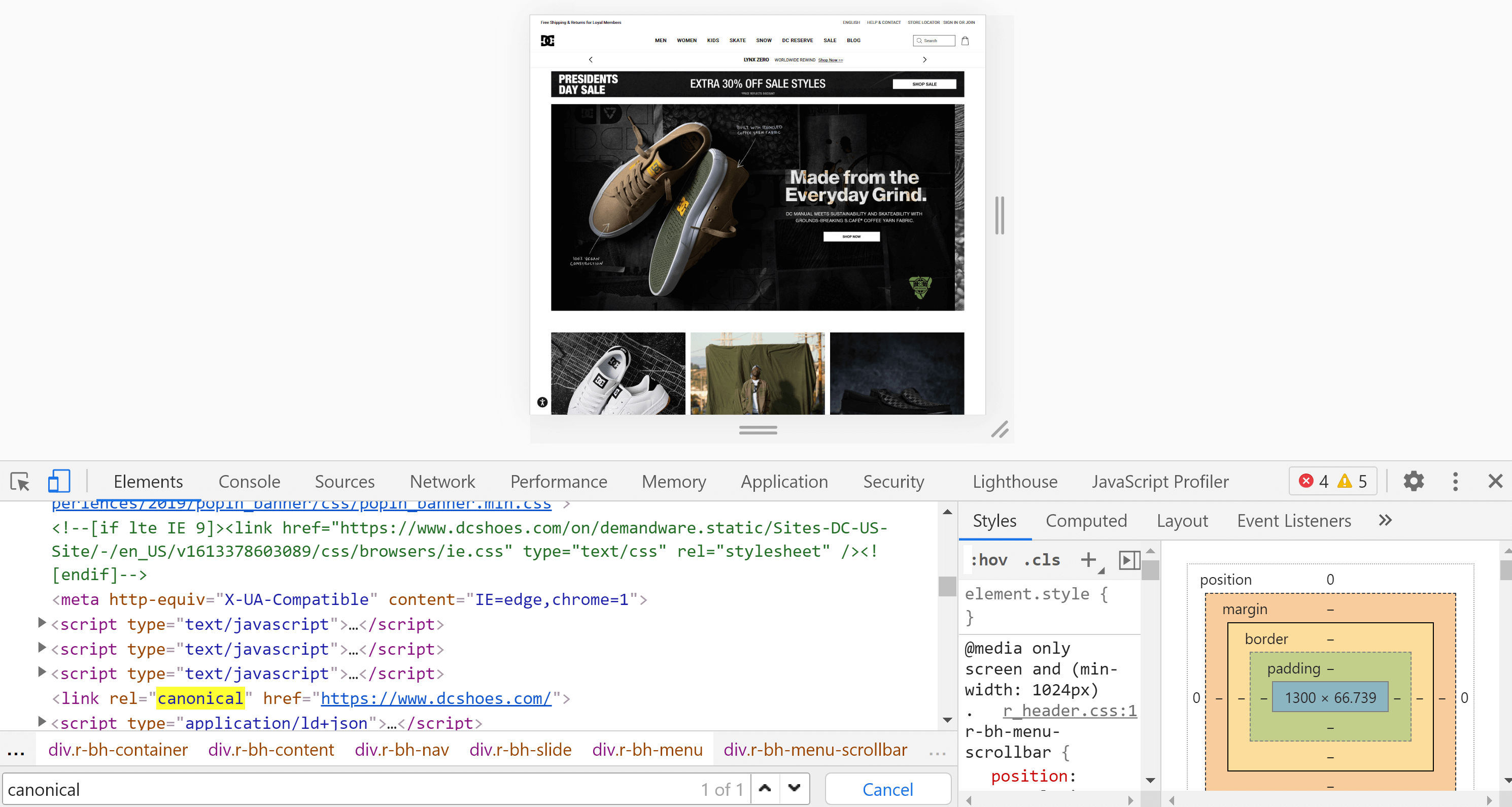
La principal diferencia entre el código fuente de la página y el inspector es que el segundo ya ha renderizado la página y vemos el contenido después de que finaliza este proceso (incluida la ejecución de JavaScript).
Alternativamente, podemos usar la consola , yendo a la pestaña “Consola” e ingresando el siguiente comando:
$$('enlace[rel="canonical"]')[0] 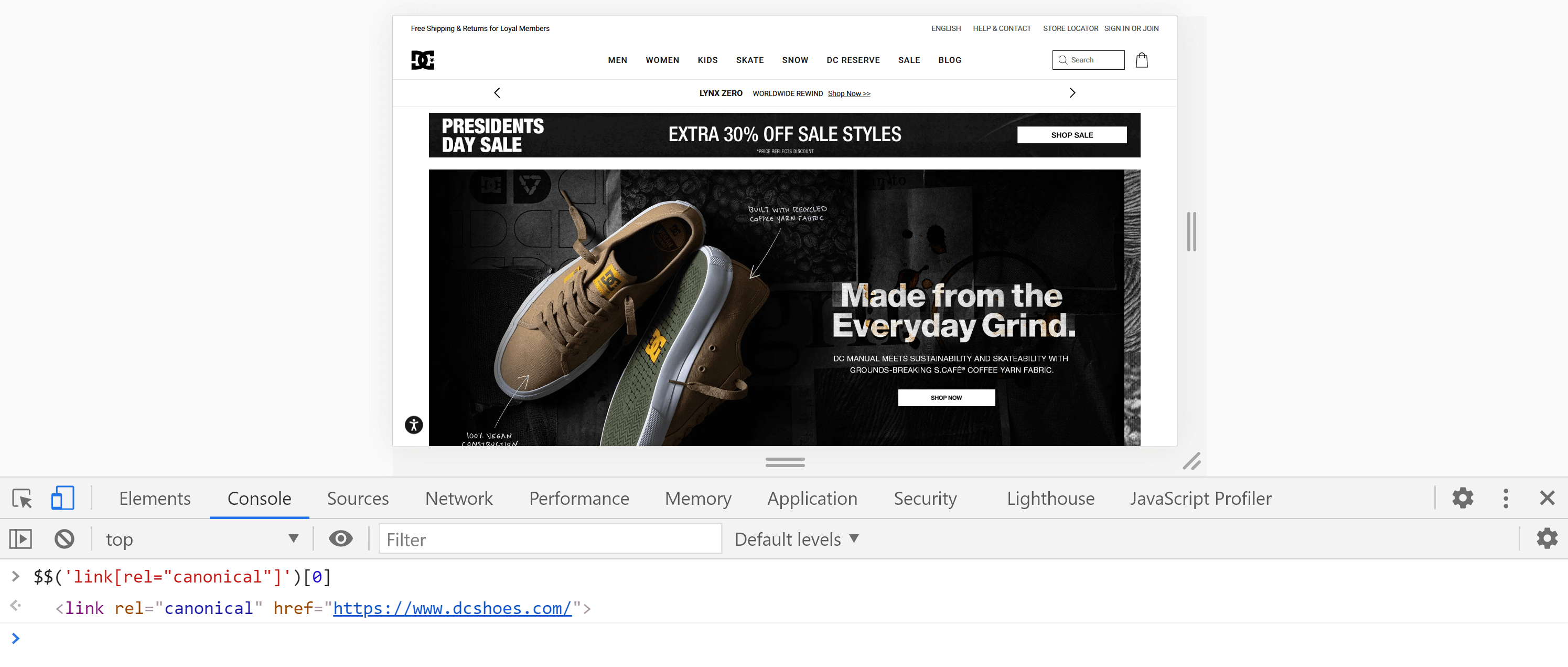
En la consola de búsqueda de Google
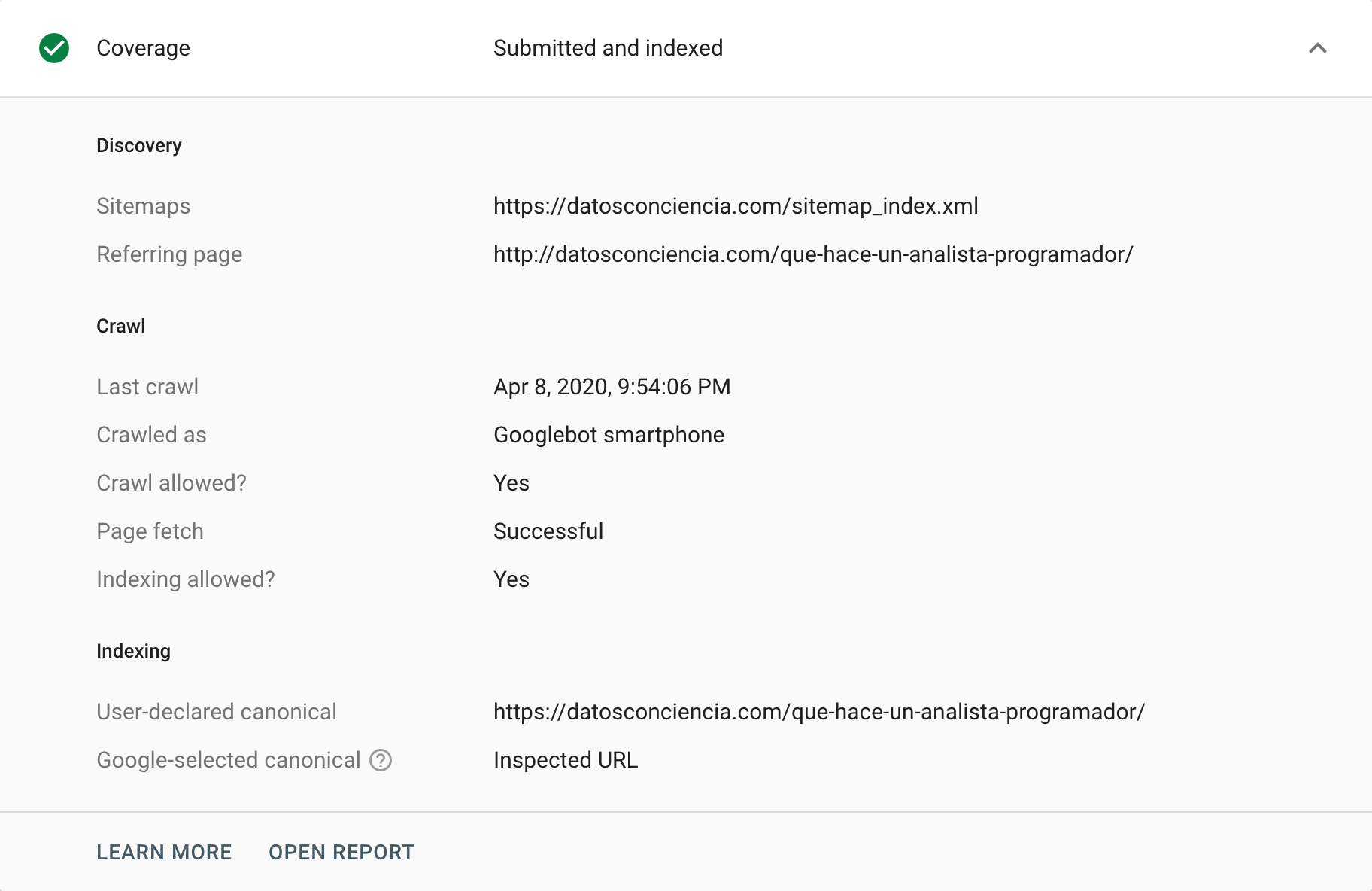
Google Search Console proporciona diferentes formas de analizar o auditar etiquetas canónicas. Una forma de hacerlo es acudir al informe de “Cobertura” , donde podemos analizar cualquier evento responsable de la exclusión de determinadas URL de su índice. En esta sección de “Excluidos” , en ocasiones podemos encontrar situaciones relacionadas con etiquetas canónicas, tanto casos correctos como incorrectos (interpretados correctamente o incorrectamente). Sin duda, es la forma perfecta de empezar a tirar del hilo que nos ayudará a identificar problemas.

Por otro lado, tenemos la herramienta de inspección de URL , que puede proporcionar información sobre etiquetas canónicas de URL individuales. Podemos solicitar que los rastree y devuelva su estado, especialmente si hay una diferencia entre nuestra instrucción y lo que Google elige interpretar.
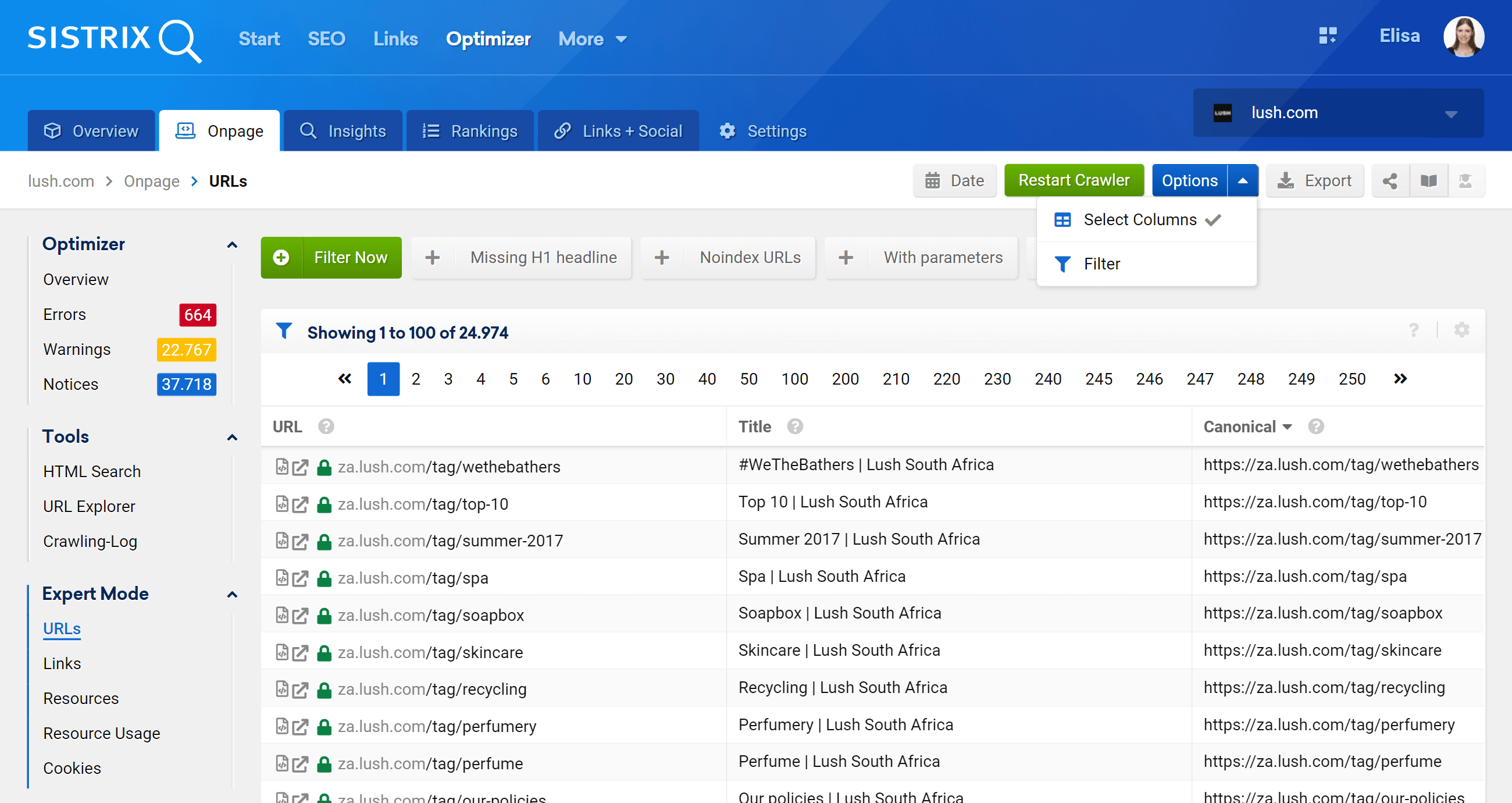
Cómo analizar etiquetas canónicas utilizando SISTRIX Toolbox Optimizer
Hay varias formas de analizar canonicals utilizando SISTIX Toolbox Optimizer.
Rastreo y detección de advertencias
Al ser un crawler, Optimizer visitará tu sitio web para identificar oportunidades de mejora, errores y otros aspectos de los que estarás informado de forma fácil y visual, para que no pierdas tu tiempo procesando datos. Aquí hay un ejemplo relacionado con las etiquetas canónicas, sobre las cuales el Optimizador le notificará (si comete un error):

Explorador de URL: analiza URL individuales
Esta función es similar a la herramienta de inspección de URL de Google Search Console, lo que significa que podrá evaluar las URL individuales que se rastrearon en su proyecto de Optimizer y ver la información de esa URL específica.
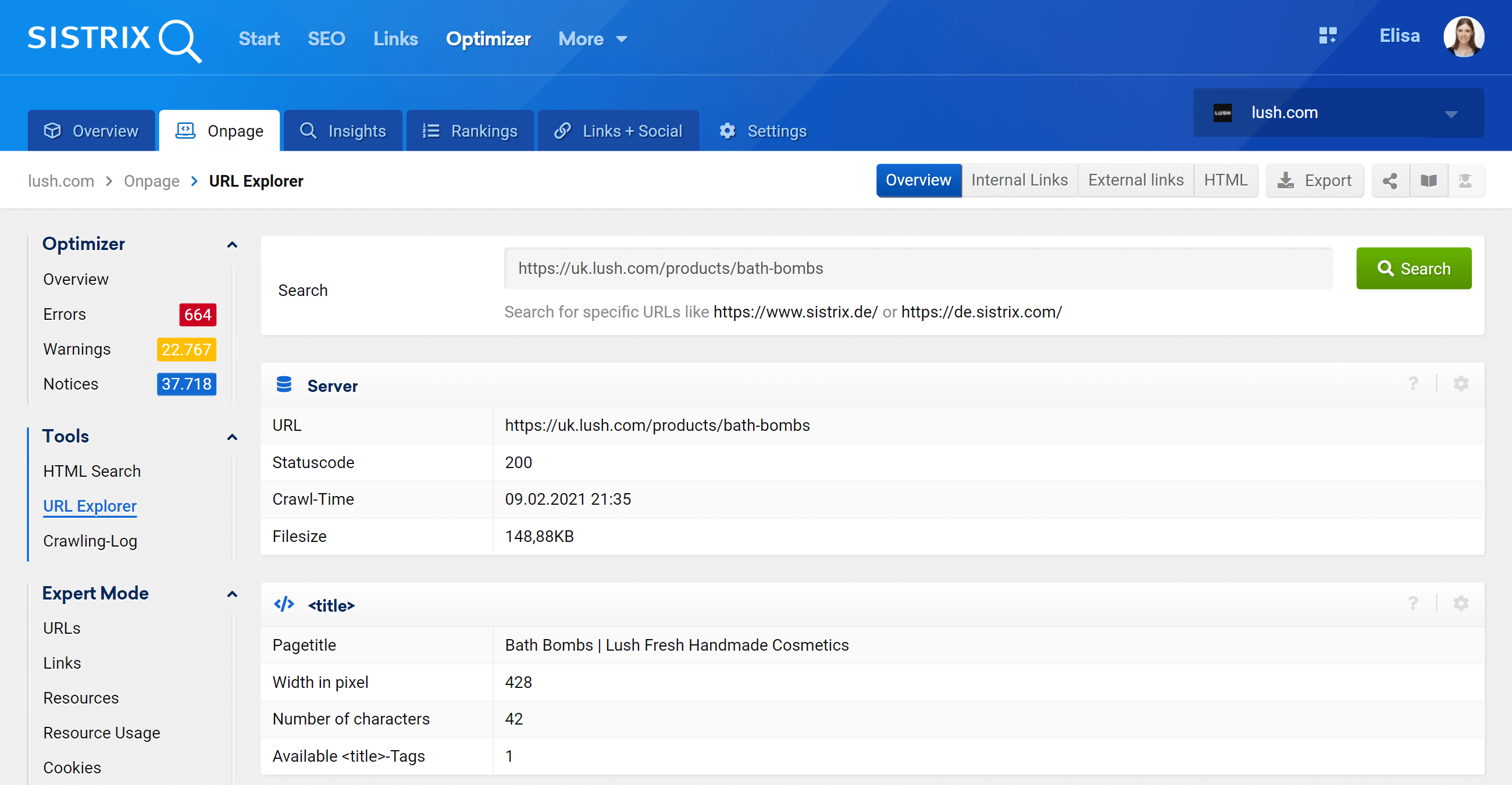
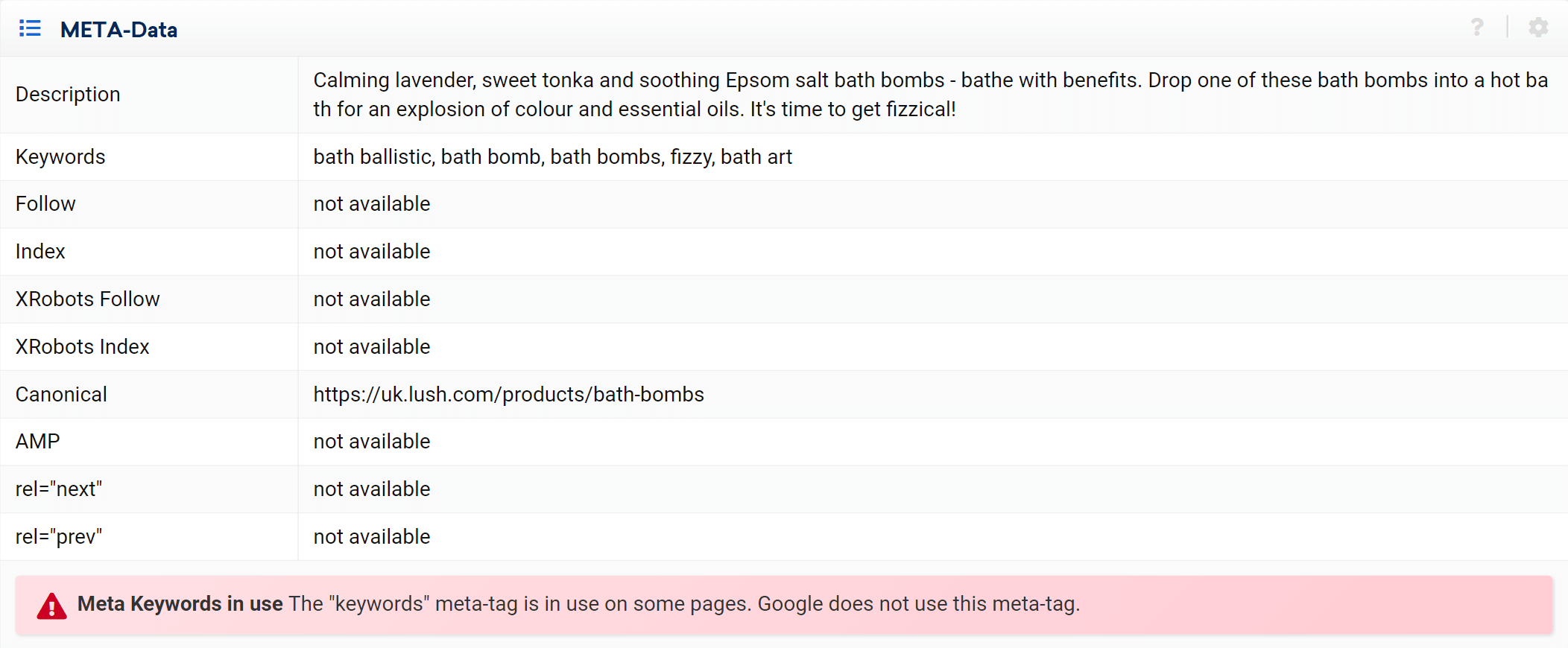
Como puede ver, podemos analizar todos los aspectos en la página relacionados con esta URL, tanto los enlaces internos entrantes como salientes, la información del servidor, las etiquetas SEO, y aquí es donde también encontrará la implementación canónica, que es el tema que nos ocupa. .
Modo experto
Al ir a la sección Modo experto, podemos acceder a todas las URL rastreadas de nuestro proyecto y usar múltiples filtros para refinar nuestra búsqueda. En el siguiente ejemplo, he incluido las URL que contienen /products/ en sus URL, pero que no pertenecen al mercado /en_gb/.
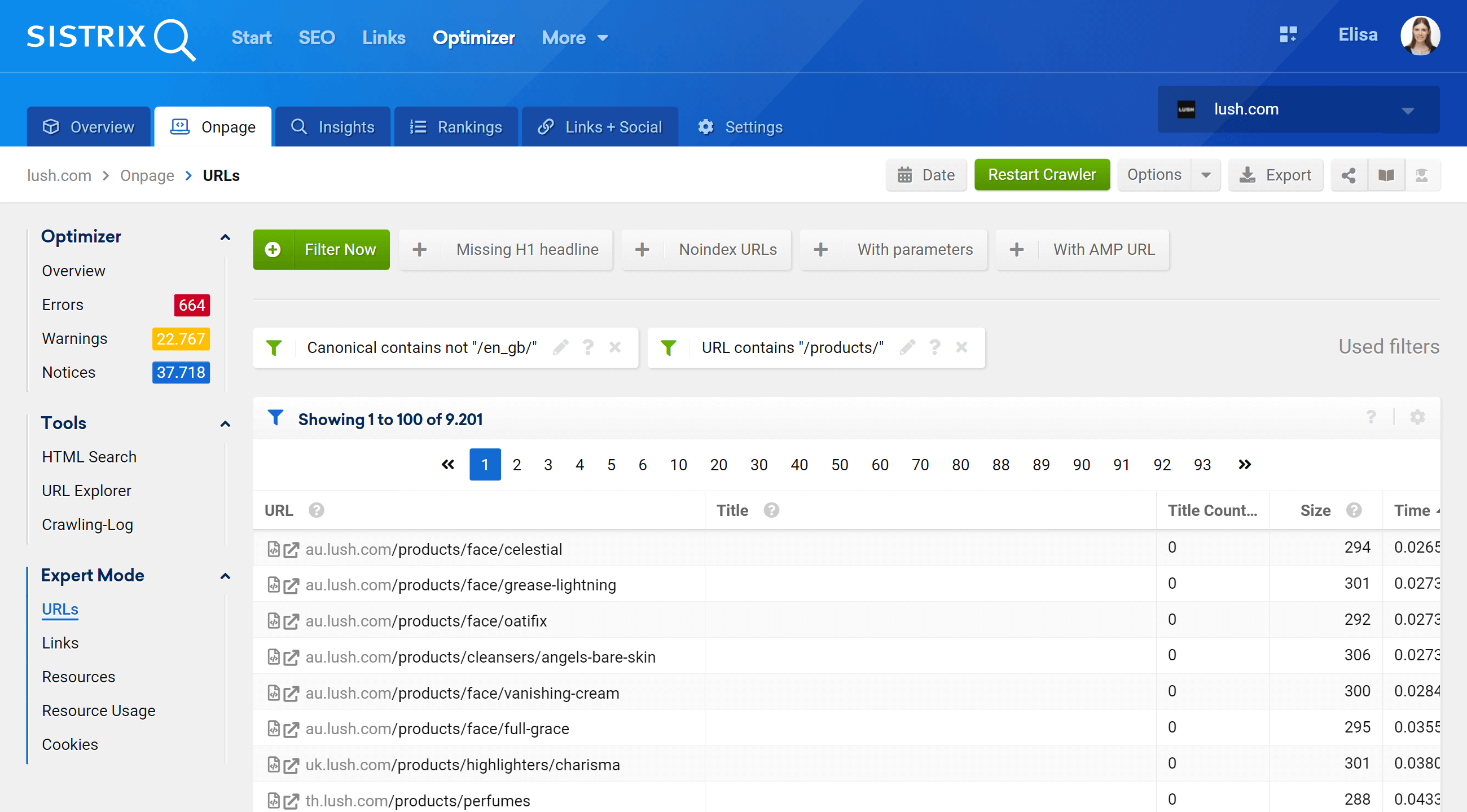
Además, también podemos configurar las columnas de la tabla para mostrar los campos que más nos interesen. En mi ejemplo, he elegido mostrar códigos de estado, nivel de profundidad, enlaces internos, meta robots y canónicos, pero también podríamos agregar, simplemente marcando su casilla: el título, descripción, H1, tamaño, tipo de contenido, etc.