O que é a tag canônica e como usá-la
Publicados: 2022-04-17- Definição e significado
- Nomenclatura, considerações e erros a evitar
- Procedimentos de implementação
- Tag HTML
- Cabeçalho HTTP
- Outros sinais: mapa do site e links internos
- Casos de efeito e SEO
- Como analisar ou auditar tags canônicas
- Explorar o código-fonte
- Ferramentas para desenvolvedores do Chrome
- No Google Search Console
- Como analisar tags canônicas usando o SISTRIX Toolbox Optimizer
- Rastreamento e detecção de avisos
- Explorador de URL: analise URLs individuais
- Modo especialista
Definição e significado
A tag canônica é o elemento HTML que usamos para informar ao Google que 2 ou mais URLs em nosso site são duplicados, semelhantes ou idênticos.
Essa tag nos permite 'selecionar' quais dos vários URLs devem ser exibidos nas SERPs, para ajudar o Google a decidir qual página deve ser exibida nos resultados. Em outras palavras, estamos fornecendo ao Google um sinal indicando a versão preferencial a ser indexada .
Além de fortalecer esse sinal de indexação, também consolida nossos links internos apontando da URL de origem para a URL canônica de destino.
Com relação ao conteúdo duplicado e vários mitos que circulam na indústria, não há melhor maneira de esclarecer isso do que citando fontes oficiais e referências vindas do próprio Google:
“Vamos acabar com isso de uma vez por todas, pessoal: não existe uma “penalidade de conteúdo duplicado”. Pelo menos, não da maneira que a maioria das pessoas quer dizer quando dizem isso. Você pode ajudar seus colegas webmasters não perpetuando o mito de penalidades por conteúdo duplicado!”
Susan Moska
https://webmasters.googleblog.com/2008/09/demystifying-duplicate-content-penalty.html
“Conteúdo duplicado geralmente se refere a blocos substantivos de conteúdo dentro ou entre domínios que correspondem completamente a outro conteúdo ou são sensivelmente semelhantes. Principalmente, isso não é de origem enganosa.”
https://developers.google.com/search/docs/advanced/guidelines/duplicate-content
Nomenclatura, considerações e erros a evitar
Aqui estão as principais considerações sobre a diretiva canônica e as formas de especificá-la:
- Um canônico pode ser auto-referencial, principalmente na página inicial, pois pode ter vários pontos de acesso gerados pelo CMS ou pelo próprio servidor (index.html, para citar um).
- Um canônico deve ser usado sempre que houver dois conteúdos semelhantes, duplicados, ou seja, total ou parcialmente idênticos. Caso contrário, esta tag pode ser ignorada.
- Um canônico deve apontar para um URL indexável, retornando 200 OK e não carregando uma tag noindex . Outra coisa que vale a pena mencionar é que não devemos enviar um canônico para uma URL irrelevante, pois será interpretado como um Soft 404.
- Deve haver apenas um canônico exclusivo para cada URL. Se houver duas tags canônicas diferentes, elas podem entrar em conflito e ambas acabam sendo ignoradas.
- Um canônico pode usar URLs absolutos e relativos. No entanto, é importante salientar que os URLs relativos são propensos a erros e descuidos.
- Uma tag canônica pode ser ignorada se houver erros óbvios, em termos de ortografia ou outros erros não intencionais. Pode haver outros sinais, que serão analisados para determinar se uma tag canônica deve ser respeitada ou ignorada.
- Uma tag canônica também pode ser ignorada se estivermos enviando sinais confusos, como fazer referência a um canônico de url1 para url2 e depois de url2 para url1. Incorrer neste tipo de “loops” pode resultar em comportamentos inesperados.
- Um canônico pode ser de domínio cruzado, ou seja, apontar do domínio1 para o domínio2. Deve ser usado –de preferência– quando temos controle sobre ambos os domínios e queremos favorecer a indexação de um domínio sobre o outro para evitar duplicidades. Seja cauteloso com isso.
- Outro exemplo pode ser a distribuição de conteúdo.
Desde que resolva situações de conteúdo duplicado entre páginas, alguns dos casos mais típicos em que teremos que lidar com isso são:
- URLs com www vs URLs sem www
- URLs com http vs URLs com https
- URLs que terminam com / vs URLs que não terminam com / (sem contar a página inicial)
- URLs com parâmetros versus URLs sem parâmetros (como URLs com IDs de sessão).
- URLs com paginação vs URLs sem paginação
- URLs com AMP x URLs sem AMP (como marcação obrigatória).
- URLs para celular (sites m) x URLs para desktop
- URLs pré (preparação) vs URLs de produção (produção) (de qualquer forma, é melhor manter o Google fora do teste é por HTTP-Login)
- etc.
Embora todas essas situações possam ser resolvidas usando tags canônicas, existe outro método mais direto para o Google: redirecionamento 301 .
Você lerá muitas comparações de tags 301 e canônicas. Não vamos nos aprofundar muito nisso, mas vamos destacar os pontos mais importantes sobre esse assunto na imagem abaixo:
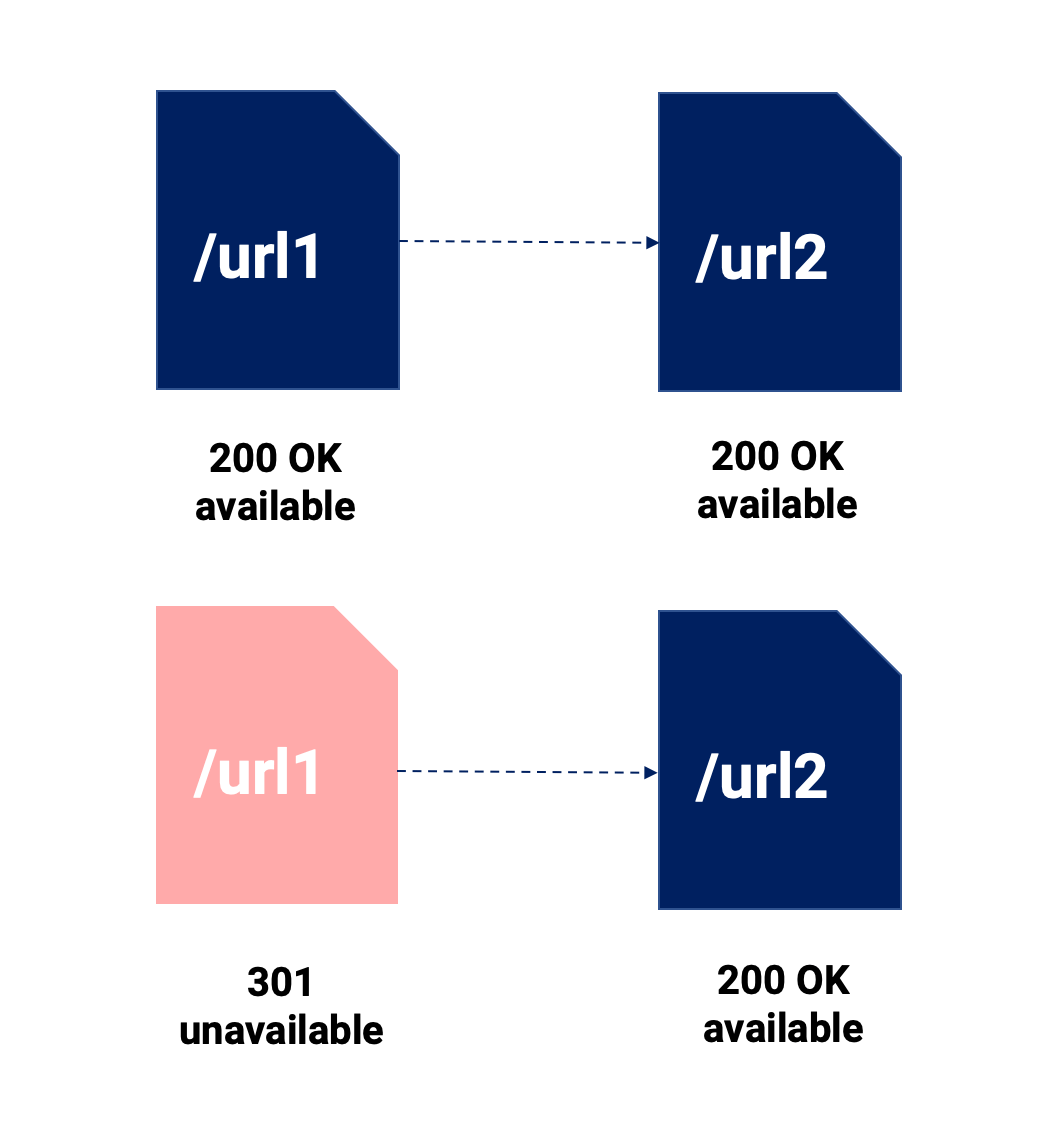
Usando este resumo visual, queremos destacar as seguintes coisas:
- O redirecionamento 301 mescla duas partes do conteúdo, o que significa que o conteúdo original deixa de existir. É direto e 100% seguido pelo Google (e usuários).
- O canônico, o que ele faz é nos permitir manter disponíveis vários URLs para qualquer canal, e se o Google respeitar a diretiva, apenas o URL canônico será indexado para o canal SEO.
- Ambos podem envolver diluição de sinal, e pode ter um efeito mais significativo quando não usamos um redirecionamento 301, pois URLs canonizadas podem ter links internos e externos apontando para eles, forçando-nos a dividir nossos esforços entre vários URLs.
Procedimentos de implementação
Existem várias maneiras de implementar tags canônicas:
Tag HTML
A maneira mais comum de implementar um canônico é colocando um elemento de link com o atributo rel=”canonical” e o caminho absoluto para a versão canônica dentro do <head> de cada URL. Aqui está a sintaxe correta:
<link rel="canonical" href="https://www.sistrix.com/ask-sistrix/what-is-the-canonical-tag-and-how-to-use-it/" />Cabeçalho HTTP
Este método é normalmente usado em páginas não-HMTL. Por exemplo: arquivos PDF, XML ou TXT.
Este é o método típico usado, quando temos um PDF e uma página HTML correspondente. Através do canônico, podemos mostrar ao Google que queremos que a página HTML seja classificada.
No entanto, dada a variedade de casos que podem existir, recomendamos este post, abordando a implementação mais técnica através do arquivo .htaccess.
<Files "seo-guide.pdf"> Header add Link "< http://www.sistrix.com/seo-guide/ >; rel=\"canonical\"" </Files>Outros sinais: mapa do site e links internos
Neste caso não vamos implementar a diretiva canônica, mas estamos afirmando, implicitamente, que esta URL (ao contrário de suas outras versões) é a original, e tem mais peso e valor.
Algo tão simples como adicionar URLs a um mapa do site ou vincular um URL a partir da navegação do site já tem uma importância tácita e implícita , então estamos enviando um sinal de SEO sobre a importância dessa versão de URL para nós. Se nos contradizermos ou houver outros sinais ambíguos ou inconclusivos, estaremos violando a lei da simplicidade em SEO : não complique mais para o Google do que já é.
- Com 2 URLs duplicados, usando canônicos, o URL original será incluído no mapa do site, o canônico não será.
- Com 2 URLs duplicados, usando canônicos, o URL original será vinculado de forma proeminente, o canonizado não será (embora isso nem sempre seja possível, e o URL canônico pode ter algum link apontando para ele).
Casos de efeito e SEO
O maior impacto que o uso de canonical pode ter é que, uma vez respeitado pelo Google, o URL para o qual a tag canonical está apontando se torna indexável , e quem emite o canonical renuncia e se sacrifica, para que o conteúdo mais original possa ser indexado.

Por outro lado, se o URL que emite o canônico receber links internos em algum lugar da estrutura de navegação, o Google poderá rastrear essa página e investir tempo nela . Isso deve nos fazer pensar seriamente em nosso uso combinado de Robots.txt (mesmo “noindex”) e canônico. Se quisermos economizar nosso orçamento de rastreamento, é possível que estejamos impedindo o Google de entender onde está a duplicata e sua canônica.
Falando de casos mais particulares, podemos especificar um pouco mais:
- Parâmetros passivos : são usados como precaução, em combinação com o gerenciamento de parâmetros do Google Search Console. No entanto, esses parâmetros são usados para marcar campanhas (pagas, e-mail, social…).
- Parâmetros ativos : idioma, filtros. A chave aqui é identificar quais têm conteúdo minimamente original que podemos posicionar, além de saber com certeza se respondem ou não a uma intenção de busca. Problemas adicionais podem ser links internos e desperdício de autoridade por meio dos links internos desses filtros.
- Paginação : o cenário atual no que diz respeito à paginação ainda é uma controvérsia por si só. O Google removeu a diretriz rel prev rel next, e agora o mundo do SEO está debatendo se devemos usar noindex, um canônico para a primeira página, rolagem infinita ou tecnologias dinâmicas como AJAX para manter a funcionalidade do usuário sem gerar novas páginas/links, dependendo do caso. Não é uma decisão trivial.
- Páginas de produtos com atributos semelhantes (cor, tamanho) : semelhante ao que dissemos sobre os filtros, precisamos identificar quando o conteúdo deles não é minimamente original para classificar e precisamos saber se eles respondem a uma intenção de pesquisa. Devemos ter em mente a regra de que “aquilo que não é procurado, não deve ser indexado” .
Como analisar ou auditar tags canônicas
Agora, vamos direto ao assunto de como identificar ou auditar tags canônicas. Temos métodos para atender às preferências de todos:
Explorar o código-fonte
Visite a página e clique com o botão direito do mouse em qualquer lugar da página para revelar o menu com a opção “View Page Source” (Control + U se estiver usando Windows; CMD + Alt + U se estiver usando Mac).
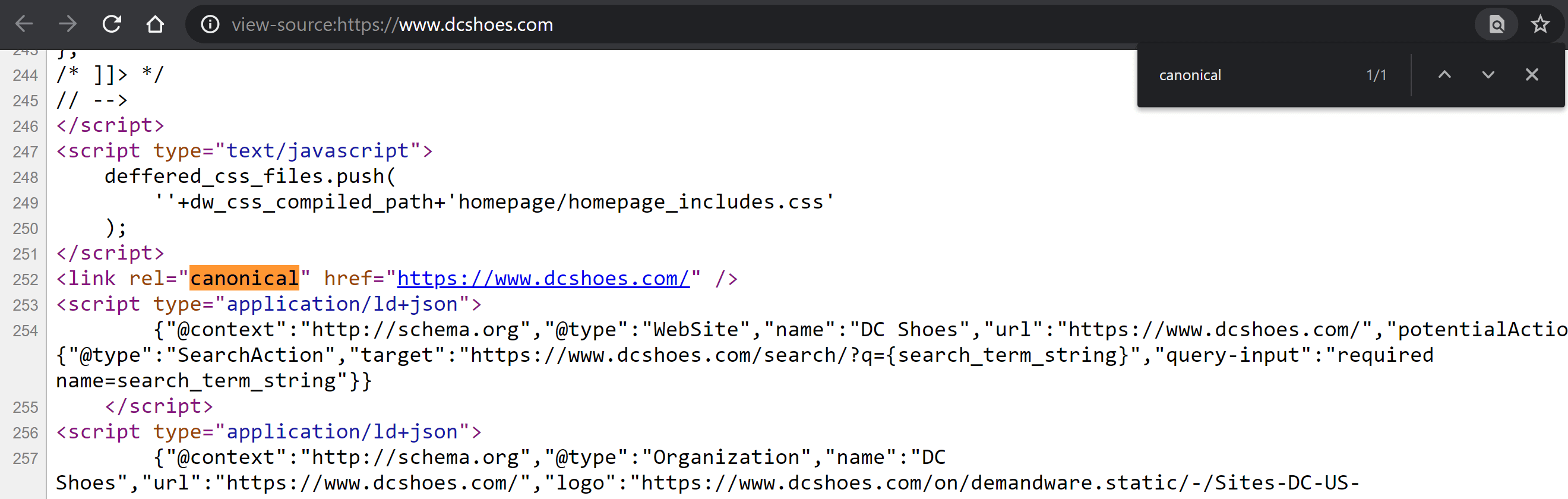
Uma vez dentro, pressione Control + F no Windows ou CMD + F no Mac para pesquisar dentro do código. Digite “canonical”, para que a tag fique destacada em uma cor diferente, se estiver lá. Compare seu conteúdo e determine se este valor foi definido corretamente ou não.
Ferramentas para desenvolvedores do Chrome
Usando o Chrome, podemos abrir o site que queremos analisar, clicar com o botão direito do mouse na tela e clicar em “Inspecionar”. Isso abrirá as ferramentas do desenvolvedor, onde podemos procurar a tag com Control + F ou Cmd + F, assim como fizemos no ponto anterior.
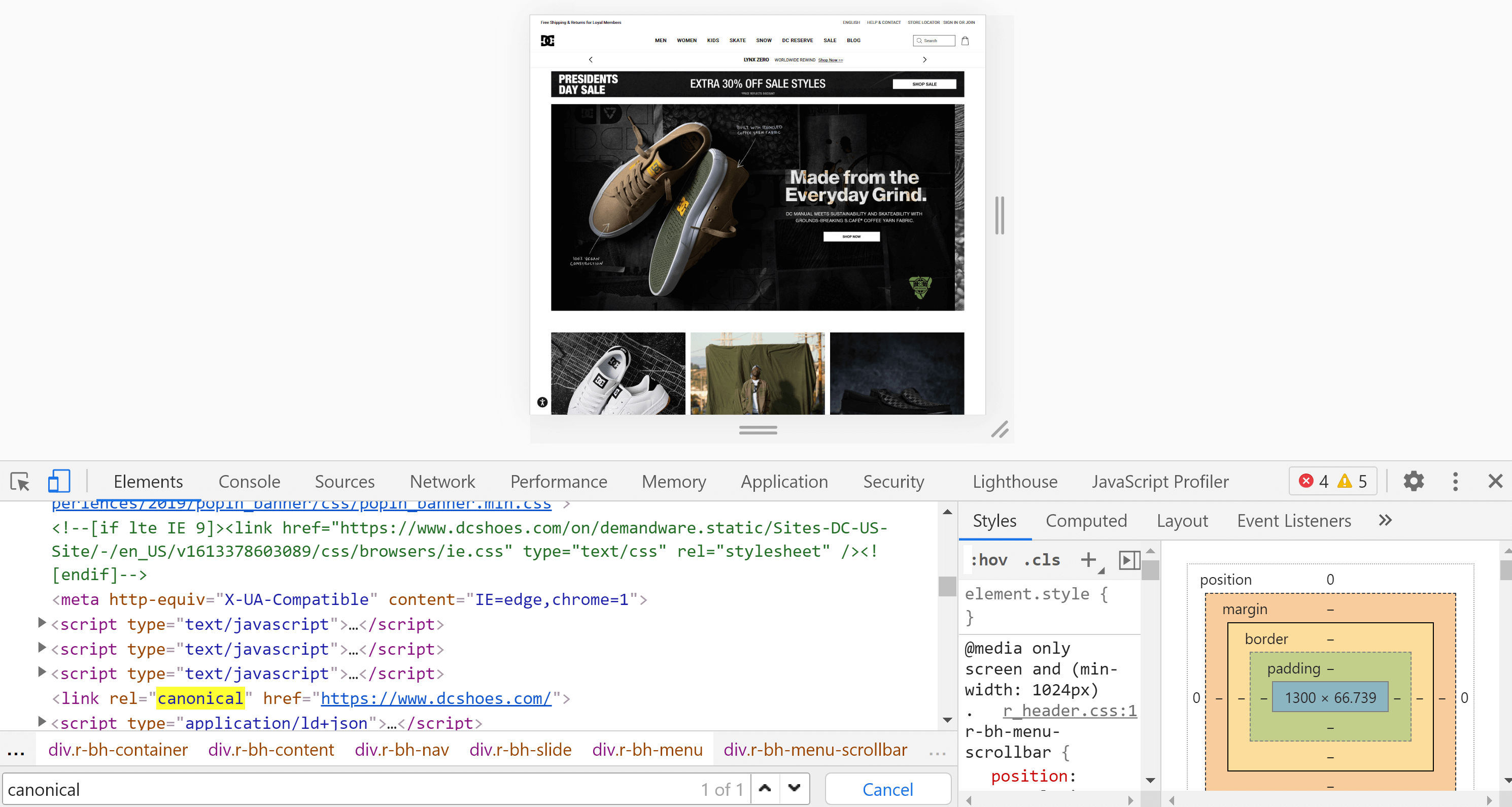
A principal diferença entre o código fonte da página e o inspetor, é que o segundo já renderizou a página e vemos o conteúdo depois que esse processo (incluindo a execução do JavaScript) é finalizado.
Alternativamente, podemos usar o console , indo até a aba “Console” e digitando o seguinte comando:
$$('link[rel="canonical"]')[0] 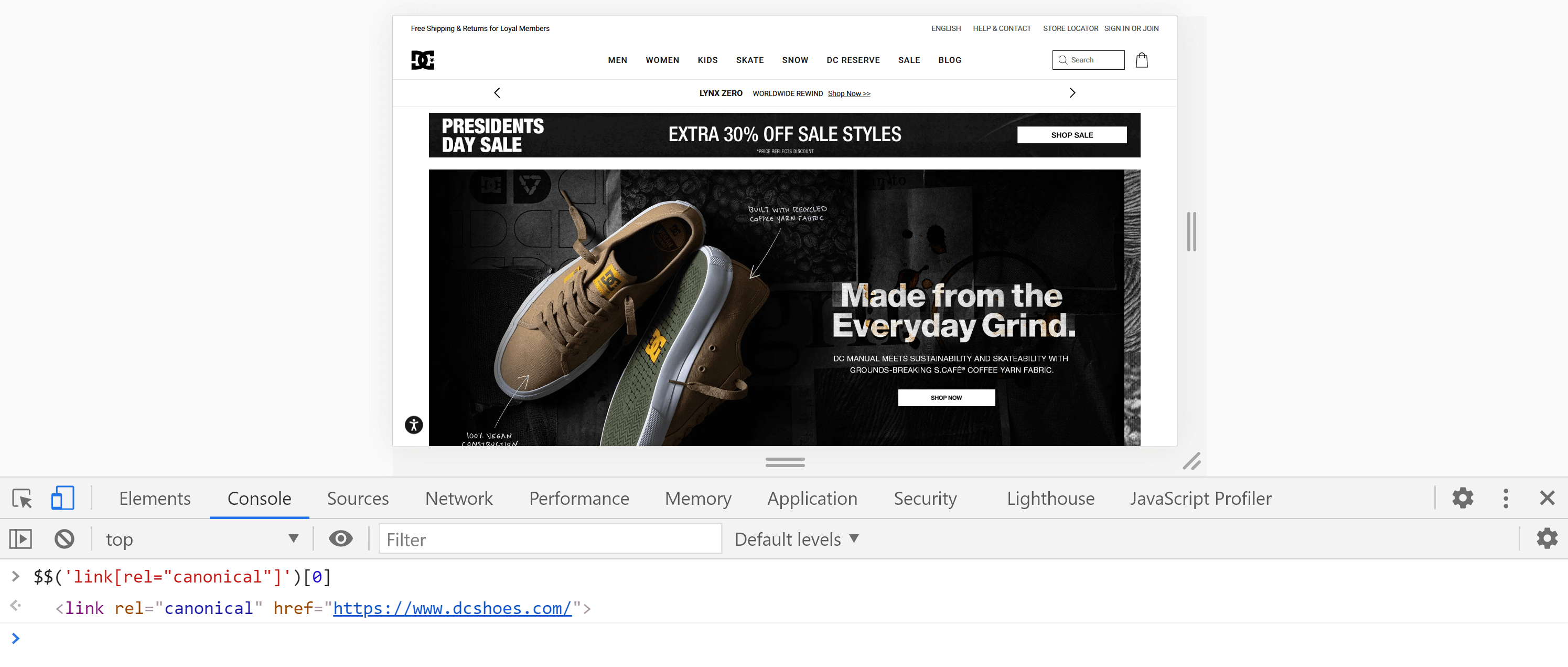
No Google Search Console
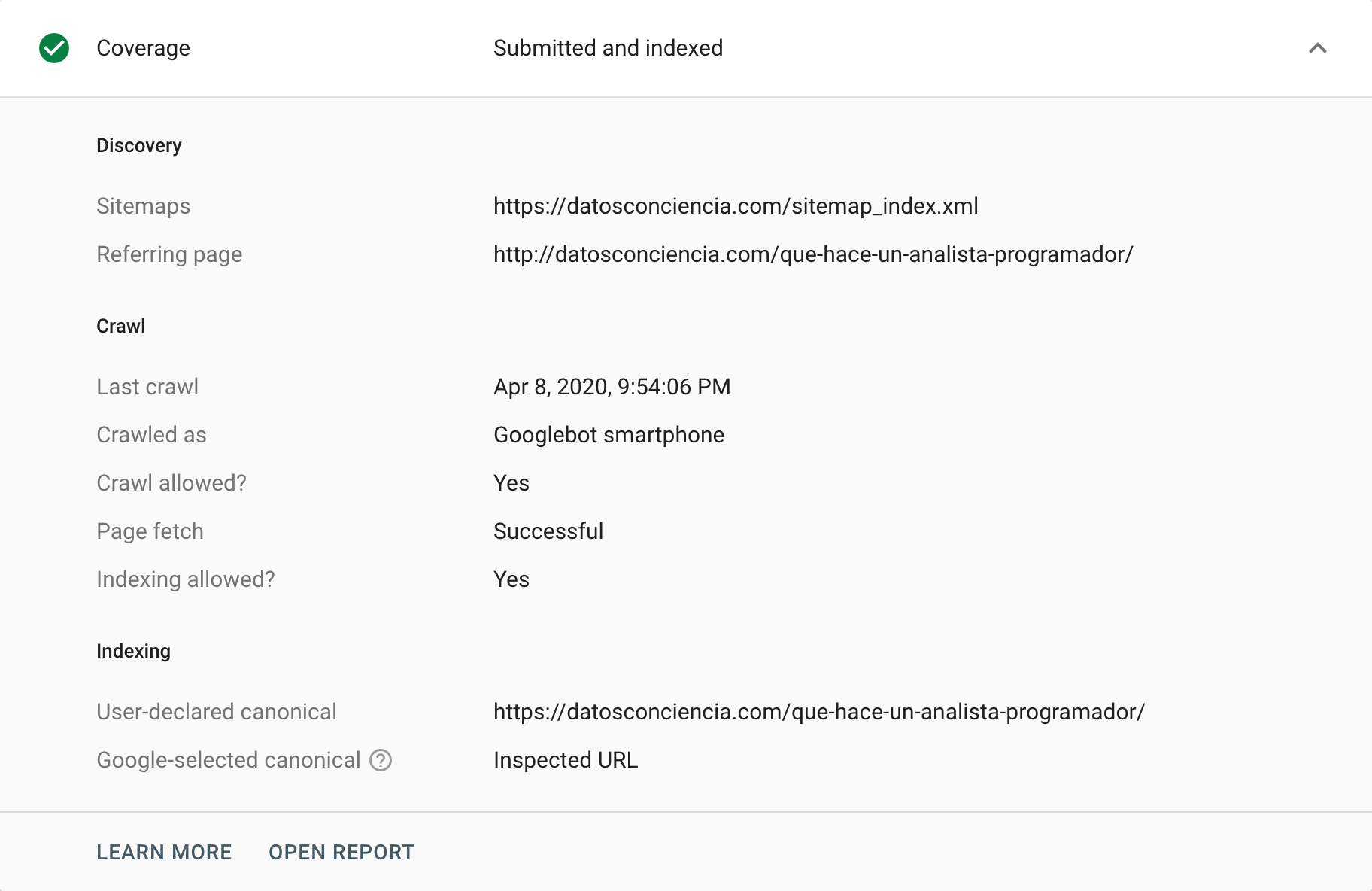
O Google Search Console oferece diferentes maneiras de analisar ou auditar tags canônicas. Uma maneira de fazer isso é acessar o relatório “Cobertura” , onde podemos analisar qualquer evento responsável pela exclusão de determinados URLs de seu índice. Nesta seção “Excluídos” , às vezes podemos encontrar situações relacionadas a tags canônicas, tanto casos corretos quanto incorretos (interpretados correta e incorretamente). Sem dúvida, é a maneira perfeita de começar a puxar o fio que nos ajudará a identificar problemas.

Por outro lado, temos a ferramenta de inspeção de URL , que pode fornecer insights sobre tags canônicas de URLs individuais. Podemos solicitá-lo para rastreá-los e retornar seu status, especialmente se houver uma diferença entre nossa instrução e o que o Google decide interpretar.
Como analisar tags canônicas usando o SISTRIX Toolbox Optimizer
Existem várias maneiras de analisar canônicos usando o SISTIX Toolbox Optimizer.
Rastreamento e detecção de avisos
Sendo um rastreador, o Optimizer visitará seu site para identificar oportunidades de melhoria, erros e outros aspectos sobre os quais você será informado de maneira fácil e visual, para que você não perca seu tempo processando dados. Aqui está um exemplo relacionado a tags canônicas, sobre as quais o Optimizer o notificará (se você cometer um erro):

Explorador de URL: analise URLs individuais
Esse recurso é semelhante à ferramenta de inspeção de URL do Google Search Console, o que significa que você poderá avaliar URLs individuais que foram rastreados em seu projeto do Optimizer e ver as informações desse URL específico.
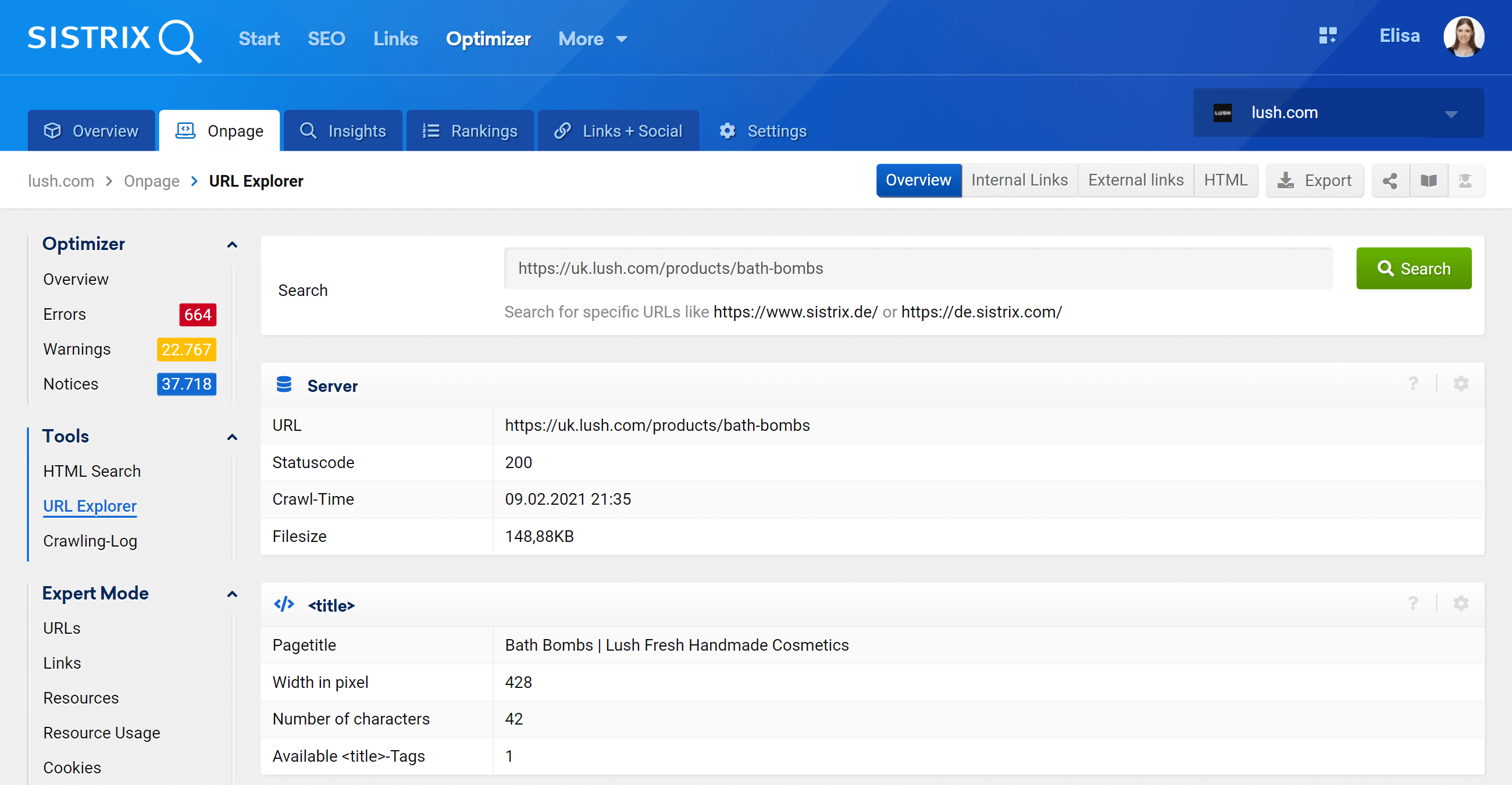
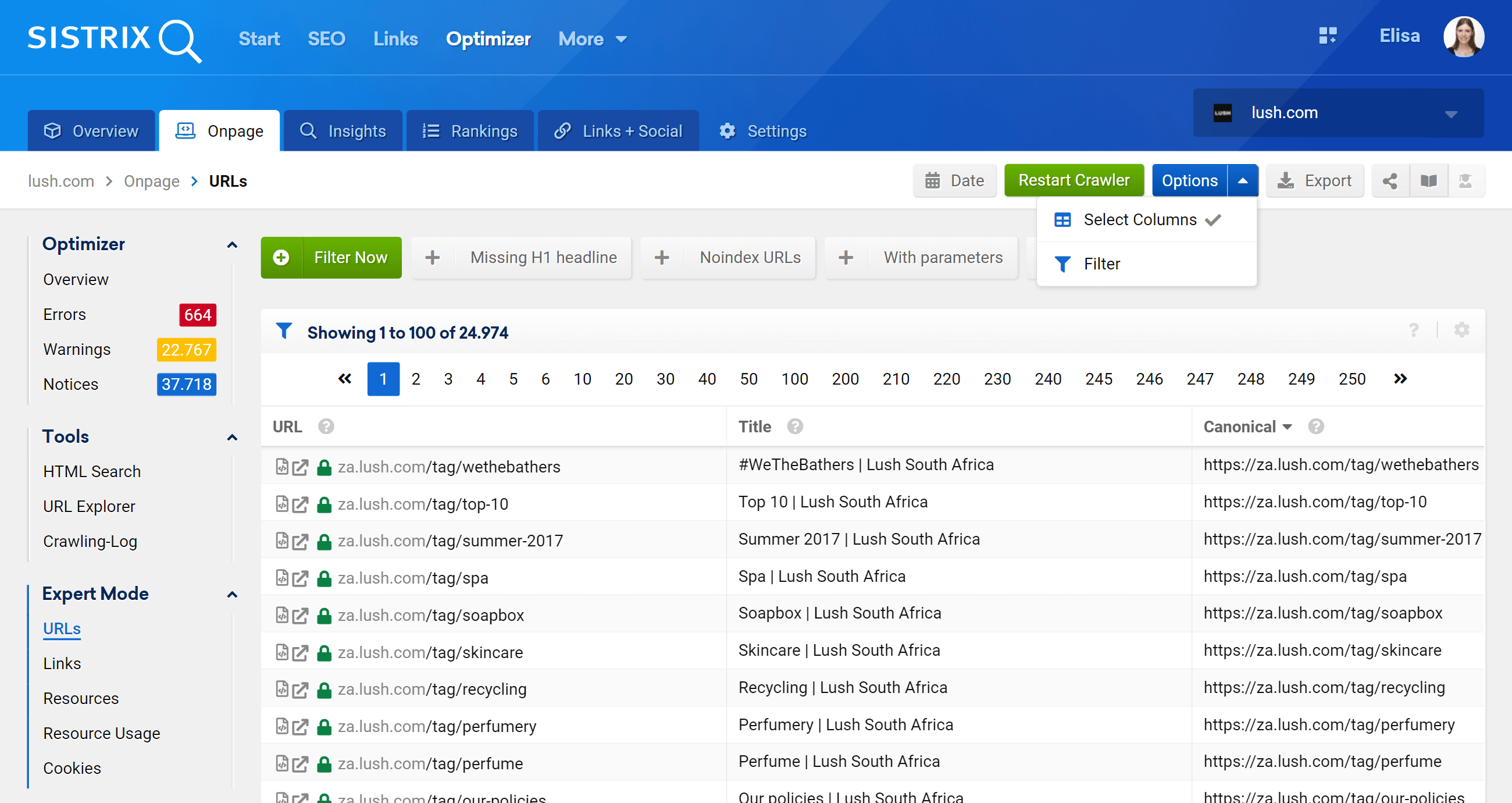
Como você pode ver, podemos analisar todos os aspectos on-page relacionados a essa URL, links internos de entrada e saída, informações do servidor, tags de SEO, e aqui é onde você também encontrará a implementação canônica, que é o assunto em questão .
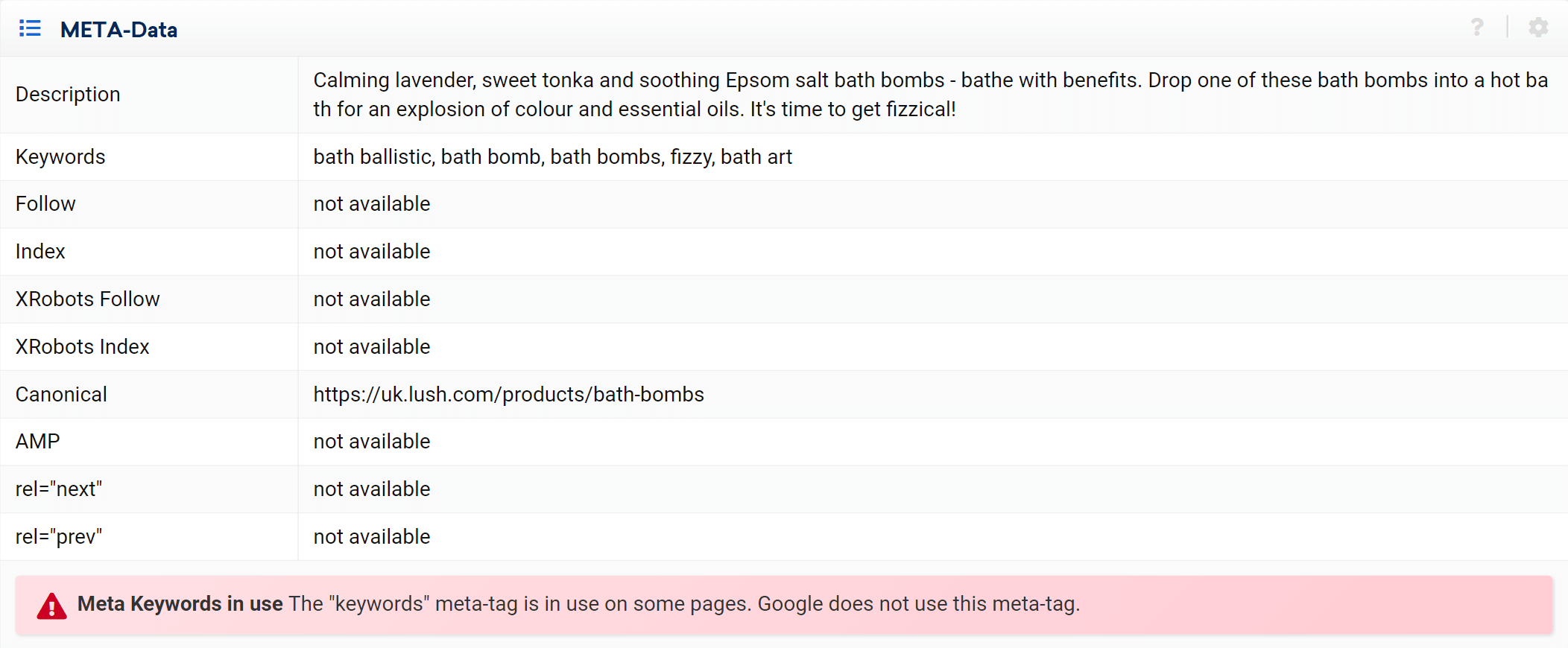
Modo especialista
Ao acessar a seção Expert Mode, podemos acessar todos os URLs rastreados do nosso projeto e usar vários filtros para refinar nossa pesquisa. No exemplo abaixo, incluí os URLs que contêm /products/ em seus URLs, mas não pertencem ao mercado /en_gb/.
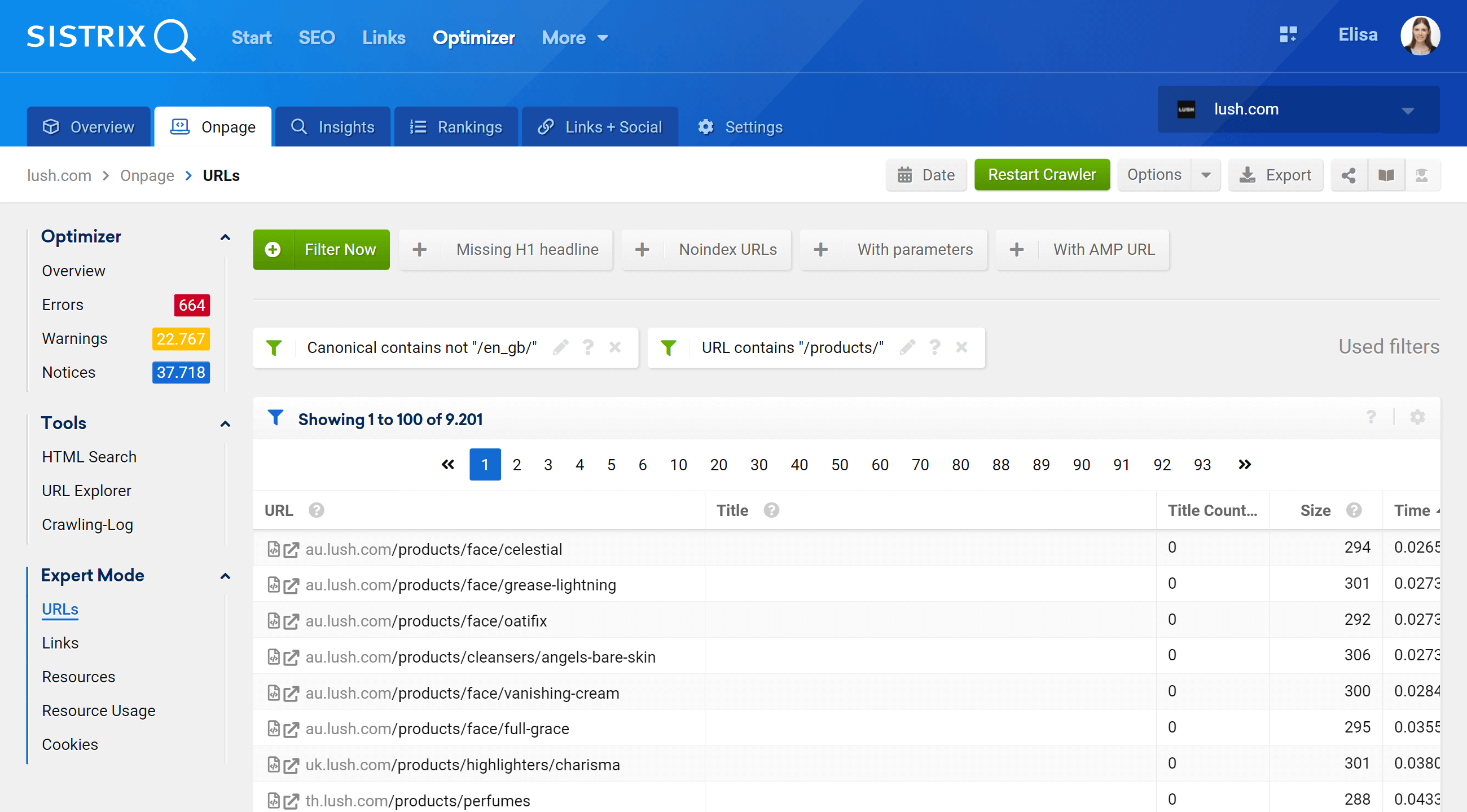
Além disso, também podemos configurar as colunas da tabela para exibir os campos nos quais estamos mais interessados. No meu exemplo, optei por mostrar códigos de status, nível de profundidade, links internos, meta robôs e canônicos, mas também poderíamos adicionar – simplesmente marcando sua caixa – o título, descrição, H1, tamanho, tipo de conteúdo, etc.