Co to jest znacznik kanoniczny i jak go używać
Opublikowany: 2022-04-17- Definicja i znaczenie
- Nazewnictwo, rozważania i błędy, których należy unikać
- Procedury wdrożeniowe
- Znacznik HTML
- Nagłówek HTTP
- Inne sygnały: mapa witryny i linki wewnętrzne
- Sprawy dotyczące efektów i SEO
- Jak analizować lub audytować tagi kanoniczne
- Poznaj kod źródłowy
- Narzędzia dla programistów Chrome
- W Google Search Console
- Jak analizować znaczniki kanoniczne za pomocą SISTRIX Toolbox Optimizer
- Indeksowanie i wykrywanie ostrzeżeń
- Eksplorator adresów URL: analizuj poszczególne adresy URL
- Tryb ekspercki
Definicja i znaczenie
Tag kanoniczny to element HTML, którego używamy, aby poinformować Google, że co najmniej 2 adresy URL w naszej witrynie są zduplikowane, podobne lub identyczne.
Ten tag pozwala nam „wybrać”, który z wielu adresów URL powinien być wyświetlany w SERP, aby pomóc Google zdecydować, która strona powinna ostatecznie wyświetlić się w wynikach. Innymi słowy, przekazujemy Google sygnał wskazujący preferowaną wersję do zindeksowania .
Oprócz wzmocnienia tego sygnału indeksowania, konsoliduje również nasze wewnętrzne linki prowadzące od adresu URL pochodzenia do docelowego kanonicznego adresu URL.
Jeśli chodzi o powielanie treści i różne mity krążące w branży, nie ma lepszego sposobu na wyjaśnienie tego, niż cytowanie oficjalnych źródeł i odniesień pochodzących z samego Google:
„Połóżmy to do łóżka raz na zawsze, ludzie: nie ma czegoś takiego jak „kara za powielenie treści”. Przynajmniej nie w sposób, w jaki większość ludzi ma na myśli, kiedy to mówią. Możesz pomóc innym webmasterom, nie utrwalając mitu powielania kar za treści!”
Susan Moska
https://webmasters.googleblog.com/2008/09/demystifying-duplicate-content-penalty.html
„Zduplikowane treści zazwyczaj odnoszą się do znaczących bloków treści w obrębie domen lub między domenami, które albo całkowicie pasują do innych treści, albo są znacznie podobne. Przeważnie nie jest to zwodnicze pochodzenie”.
https://developers.google.com/search/docs/advanced/guidelines/duplicate-content
Nazewnictwo, rozważania i błędy, których należy unikać
Oto główne rozważania dotyczące dyrektywy kanonicznej i sposoby jej określenia:
- Kanoniczny może odnosić się do siebie, zwłaszcza na stronie głównej, ponieważ może mieć kilka punktów dostępu generowanych przez CMS lub sam serwer (index.html, żeby wymienić tylko jeden).
- Kanoniczny musi być używany, gdy istnieją dwa fragmenty treści, które są podobne, zduplikowane lub, innymi słowy, całkowicie lub częściowo identyczne. W przeciwnym razie ten tag można zignorować.
- Kanoniczny musi wskazywać na indeksowalny adres URL, zwracający 200 OK i nie zawierający znacznika noindex . Kolejną rzeczą, o której warto wspomnieć, jest to, że nie powinniśmy wysyłać pliku kanonicznego do nieistotnego adresu URL, ponieważ zostanie on zinterpretowany jako Soft 404.
- Dla każdego adresu URL powinien istnieć tylko jeden unikalny kanoniczny. Jeśli istnieją dwa różne znaczniki kanoniczne, mogą kolidować i oba zostaną zignorowane.
- Kanoniczny może używać bezwzględnych i względnych adresów URL. Należy jednak zaznaczyć, że względne adresy URL są podatne na błędy i niedopatrzenia.
- Znacznik kanoniczny można zignorować, jeśli występują oczywiste błędy w pisowni lub inne niezamierzone błędy. Mogą istnieć inne sygnały, które zostaną przeanalizowane w celu określenia, czy znacznik kanoniczny powinien być respektowany, czy ignorowany.
- Znacznik kanoniczny można również zignorować, jeśli wysyłamy mylące sygnały, takie jak odwoływanie się do kanonicznego z url1 do url2, a następnie z url2 do url1. Wpadnięcie w tego rodzaju „pętle” może skutkować nieoczekiwanym zachowaniem.
- Kanoniczny może być cross-domain, tj. wskazywać od domeny 1 do domeny2. Powinna być stosowana – najlepiej – gdy mamy kontrolę nad obiema domenami i chcemy preferować indeksowanie jednej domeny względem drugiej, aby zapobiec duplikacjom. Bądź z tym ostrożny.
- Innym przykładem może być syndykacja treści.
Pod warunkiem, że rozwiązuje problemy z powielaniem treści między stronami, niektóre z najbardziej typowych przypadków, w których będziemy musieli sobie z tym poradzić, to:
- Adresy URL z www a adresy URL bez www
- Adresy URL z http kontra adresy URL z https
- Adresy URL kończące się na / vs adresy URL nie kończące się na / (nie licząc strony głównej)
- Adresy URL z parametrami a adresy URL bez parametrów (np. adresy URL z identyfikatorami sesji).
- Adresy URL z paginacją a adresy bez paginacji
- Adresy URL z AMP vs adresy bez AMP (jako wymagane znaczniki).
- Mobilne adresy URL (m-witryny) a adresy stacjonarne
- Adresy URL wstępne (wstępne) a adresy URL produkcyjne (produkcyjne) (w każdym razie lepiej jest trzymać Google z dala od etapów w przypadku logowania HTTP)
- Itp.
Chociaż wszystkie te sytuacje można rozwiązać za pomocą tagów kanonicznych, istnieje inna, bardziej bezpośrednia metoda dla Google: przekierowanie 301 .
Przeczytasz mnóstwo porównań tagów 301 i kanonicznych. Nie będziemy się w to zbytnio zagłębiać, ale najważniejsze punkty w tej sprawie podkreślimy na poniższym obrazku:
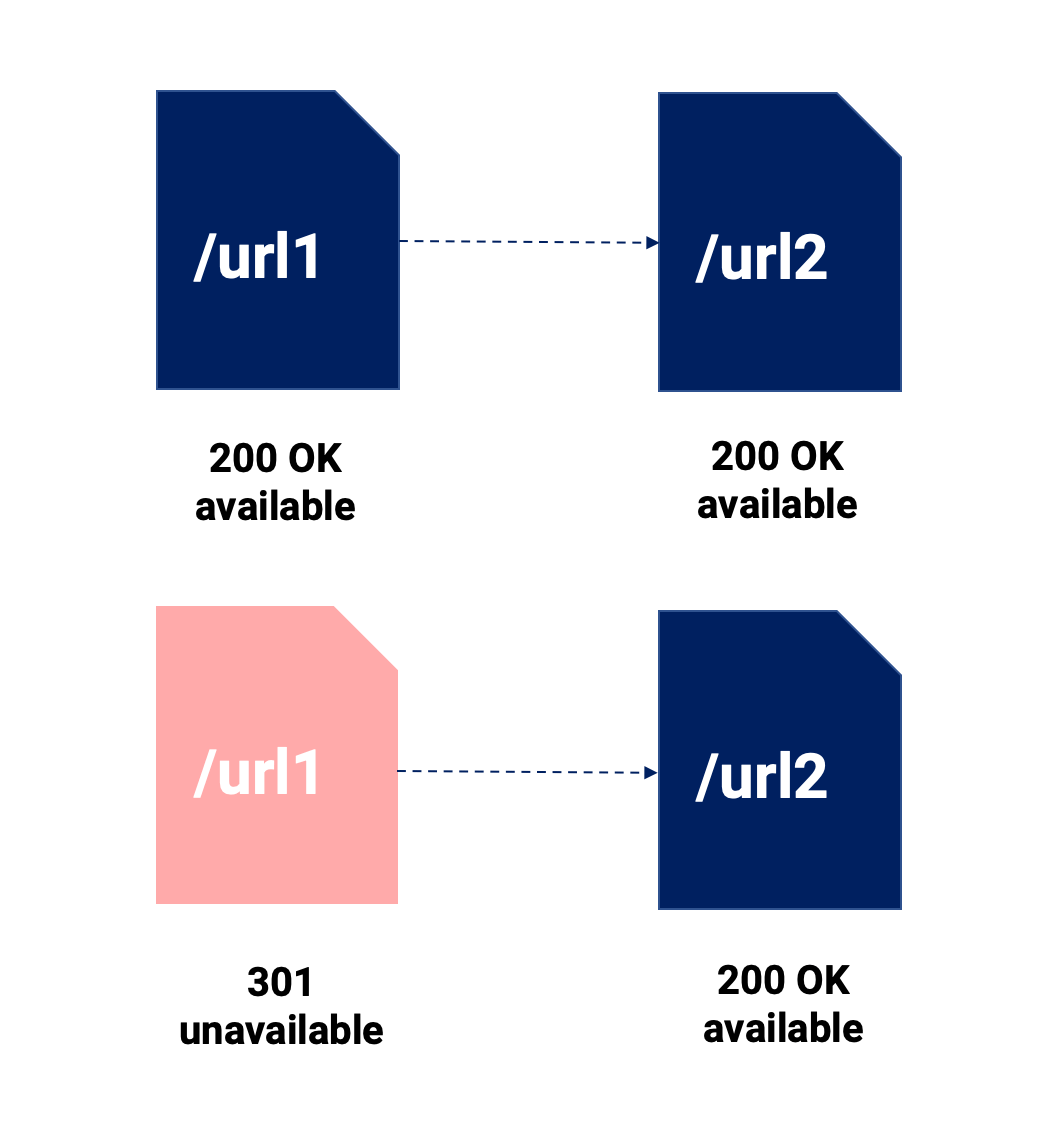
Korzystając z tego wizualnego podsumowania, chcemy podkreślić następujące rzeczy:
- Przekierowanie 301 łączy dwa fragmenty treści, co oznacza, że oryginalna treść przestaje istnieć. Jest bezpośredni i w 100% śledzony przez Google (i użytkowników).
- Kanoniczny, co pozwala nam zachować dostępne różne adresy URL dla dowolnego kanału, a jeśli Google przestrzega dyrektywy, tylko kanoniczny adres URL zostanie zindeksowany dla kanału SEO.
- Oba mogą prawdopodobnie wiązać się z osłabieniem sygnału i może mieć bardziej znaczący efekt, gdy nie użyjemy przekierowania 301, ponieważ kanoniczne adresy URL mogą zawierać wewnętrzne i zewnętrzne linki prowadzące do nich, zmuszając nas do podzielenia naszych wysiłków między kilka adresów URL.
Procedury wdrożeniowe
Istnieje kilka sposobów implementacji tagów kanonicznych:
Znacznik HTML
Najczęstszym sposobem zaimplementowania wersji kanonicznej jest umieszczenie elementu link z atrybutem rel="canonical" i bezwzględną ścieżką do wersji kanonicznej w obrębie <head> każdego adresu URL. Oto poprawna składnia:
<link rel="canonical" href="https://www.sistrix.com/ask-sistrix/what-is-the-canonical-tag-and-how-to-use-it/" />Nagłówek HTTP
Ta metoda jest zwykle używana na stronach innych niż HMTL. Na przykład: pliki PDF, XML lub TXT.
Jest to typowa metoda używana, gdy mamy zarówno plik PDF, jak i pasującą stronę HTML. Poprzez kanoniczny możemy pokazać Google, że chcemy, aby strona HTML była pozycjonowana.
Niemniej jednak, biorąc pod uwagę różnorodność różnych przypadków, zalecamy ten post, obejmujący bardziej techniczną implementację za pośrednictwem pliku .htaccess.
<Files "seo-guide.pdf"> Header add Link "< http://www.sistrix.com/seo-guide/ >; rel=\"canonical\"" </Files>Inne sygnały: mapa witryny i linki wewnętrzne
W tym przypadku nie zamierzamy implementować dyrektywy kanonicznej, ale domyślnie stwierdzamy, że ten adres URL (w przeciwieństwie do innych jego wersji) jest oryginalny i ma większą wagę i wartość.
Coś tak prostego, jak dodanie adresów URL do mapy witryny lub połączenie adresu URL z nawigacji witryny, ma już ukryte i niejawne znaczenie , więc wysyłamy sygnał SEO dotyczący znaczenia tej wersji adresu URL dla nas. Jeśli sobie zaprzeczymy lub pojawią się inne niejednoznaczne lub niejednoznaczne sygnały, naruszymy prawo prostoty w SEO : nie komplikuj Google bardziej niż jest.
- W przypadku dwóch zduplikowanych adresów URL, używających znaków kanonicznych, oryginalny adres URL zostanie uwzględniony w mapie witryny, a kanoniczny nie.
- W przypadku dwóch zduplikowanych adresów URL z użyciem kanonicznych adresów URL oryginalny adres URL zostanie wyraźnie połączony, a kanonizowany nie będzie (chociaż nie zawsze jest to możliwe, a kanoniczny adres URL może mieć odsyłacz do niego).
Sprawy dotyczące efektów i SEO
Największy wpływ, jaki może wywrzeć użycie znaku kanonicznego, polega na tym, że po uznaniu go przez Google adres URL, na który wskazuje tag kanoniczny, staje się indeksowalny , a podmiot wystawiający kanoniczny zrezygnuje i poświęci się, aby bardziej oryginalna treść mogła zostać zindeksowane.

Z drugiej strony, jeśli adres URL wystawiający plik kanoniczny otrzyma linki wewnętrzne gdzieś w strukturze nawigacji, Google będzie w stanie zaindeksować tę stronę i zainwestować w nią czas . Powinno to poważnie skłonić nas do zastanowienia się nad naszym łącznym wykorzystaniem Robots.txt (nawet „noindex”) i kanonicznym. Jeśli chcemy zaoszczędzić budżet na indeksowanie, możliwe, że uniemożliwimy Google zrozumienie, gdzie znajduje się duplikat i jego kanon.
Mówiąc o bardziej szczegółowych przypadkach, możemy określić nieco więcej:
- Parametry pasywne : są używane jako środek ostrożności w połączeniu z zarządzaniem parametrami w Google Search Console. Te parametry są jednak używane do tagowania kampanii (płatnych, e-mailowych, społecznościowych…).
- Aktywne parametry : język, filtry. Kluczem jest tutaj zidentyfikowanie, które z nich zawierają minimalnie oryginalną treść, którą możemy pozycjonować, oprócz pewności, czy odpowiadają one intencji wyszukiwania. Dodatkowymi problemami mogą być wewnętrzne linki i marnowanie autorytetu przez wewnętrzne linki tych filtrów.
- Paginacja : obecny scenariusz dotyczący paginacji wciąż jest kontrowersyjny sam w sobie. Google usunęło wytyczne rel prev rel next, a teraz świat SEO debatuje, czy powinniśmy używać noindex, kanonicznego do pierwszej strony, nieskończonego przewijania lub dynamicznych technologii, takich jak AJAX, aby zachować funkcjonalność dla użytkownika bez generowania nowych stron/linków, w zależności od przypadku. To wcale nie jest trywialna decyzja.
- Strony produktów o podobnych atrybutach (kolor, rozmiar) : podobnie do tego, co powiedzieliśmy o filtrach, musimy określić, kiedy ich treść nie jest minimalnie oryginalna pod względem rankingu i musimy wiedzieć, czy odpowiadają na intencje wyszukiwania. Należy pamiętać o zasadzie „to, czego nie szukamy, nie powinno być indeksowane” .
Jak analizować lub audytować tagi kanoniczne
Teraz przechodzimy do sprawy, jak identyfikować lub kontrolować znaczniki kanoniczne. Mamy metody, które zaspokoją wszystkie preferencje:
Poznaj kod źródłowy
Odwiedź stronę i kliknij prawym przyciskiem myszy w dowolnym miejscu na stronie, aby wyświetlić menu z opcją „Wyświetl źródło strony” (Control + U, jeśli używasz Windows; CMD + Alt + U, jeśli używasz Mac).
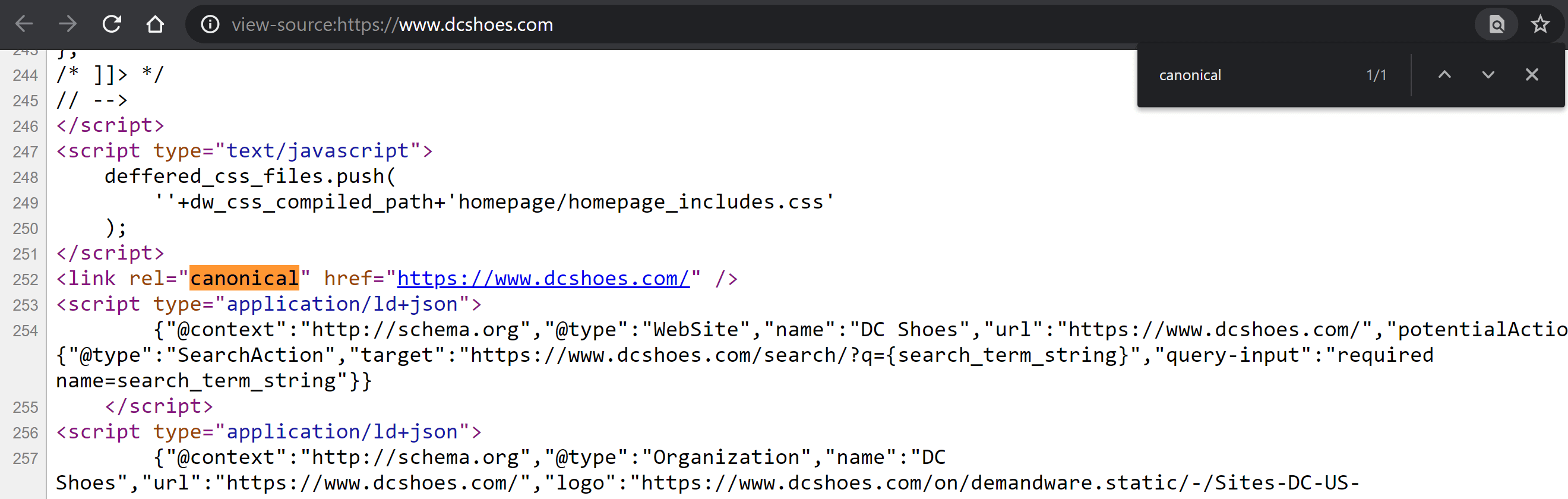
W środku naciśnij Control + F w systemie Windows lub CMD + F na komputerze Mac, aby przeszukać kod. Wpisz „canonical”, aby tag został podświetlony innym kolorem, jeśli istnieje. Porównaj jej zawartość i ustal, czy ta wartość została poprawnie zdefiniowana, czy nie.
Narzędzia dla programistów Chrome
Za pomocą przeglądarki Chrome możemy otworzyć witrynę, którą chcemy przeanalizować, kliknąć prawym przyciskiem myszy na ekranie i nacisnąć „Sprawdź”. Spowoduje to otwarcie narzędzi programistycznych, w których możemy wyszukać tag za pomocą Control + F lub Cmd + F, tak jak zrobiliśmy to w poprzednim punkcie.
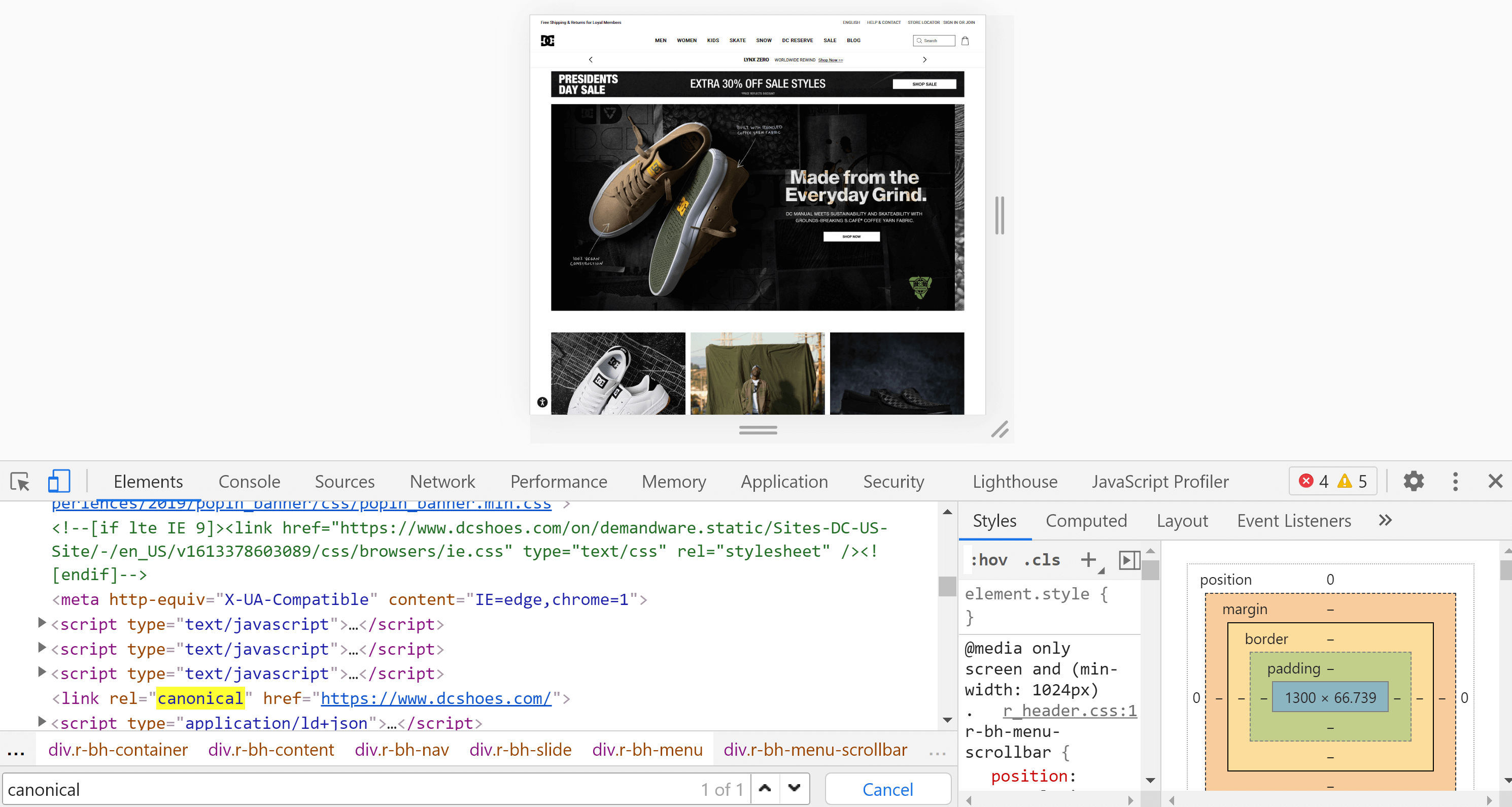
Główna różnica między kodem źródłowym strony a inspektorem polega na tym, że drugi już wyrenderował stronę i widzimy zawartość po zakończeniu tego procesu (włącznie z wykonaniem JavaScript).
Alternatywnie możemy skorzystać z konsoli , przechodząc do zakładki „Konsola” i wpisując następujące polecenie:
$$('link[rel="canonical"]')[0] 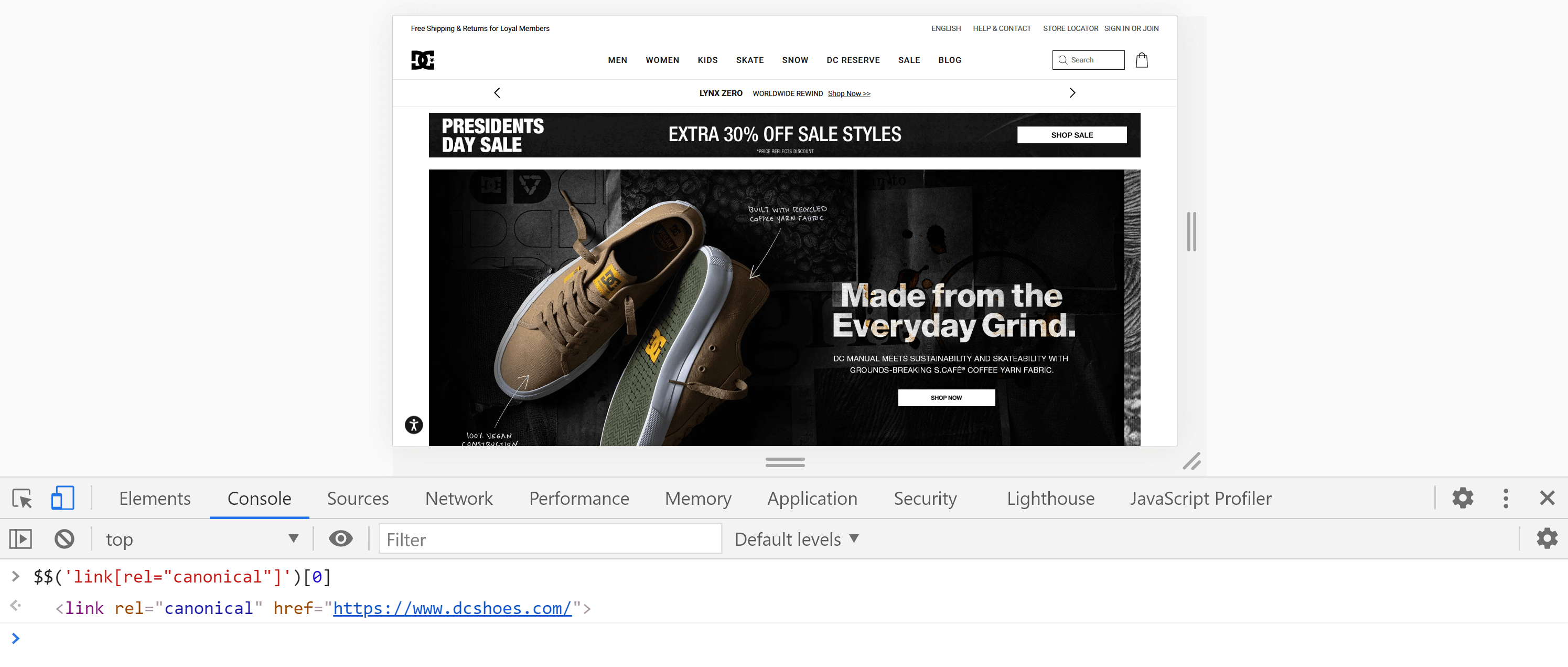
W Google Search Console
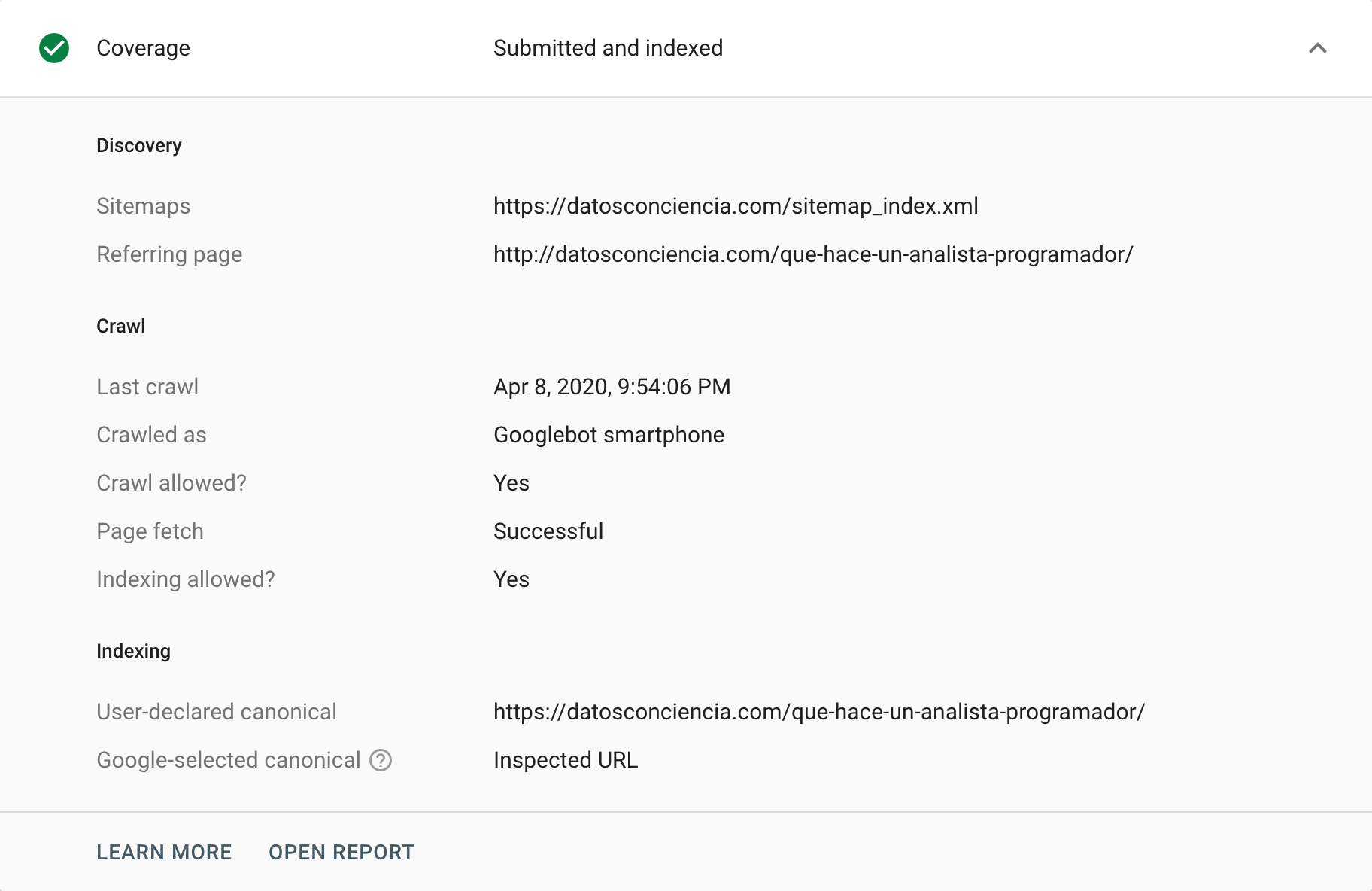
Konsola Google Search Console zapewnia różne sposoby analizowania i kontrolowania tagów kanonicznych. Jednym ze sposobów, aby to zrobić, jest przejście do raportu „Pokrycie” , w którym możemy przeanalizować każde zdarzenie odpowiedzialne za wykluczenie określonych adresów URL ze swojego indeksu. W tej sekcji „Wykluczone” czasami możemy znaleźć sytuacje związane z tagami kanonicznymi, zarówno poprawne, jak i niepoprawne przypadki (poprawnie i niepoprawnie zinterpretowane). Niewątpliwie jest to doskonały sposób na rozpoczęcie ciągnięcia wątku, który pomoże nam zidentyfikować problemy.

Z drugiej strony mamy narzędzie do sprawdzania adresów URL , które może zapewnić wgląd w tagi kanoniczne poszczególnych adresów URL. Możemy poprosić o ich zindeksowanie i zwrócenie ich stanu, zwłaszcza jeśli istnieje różnica między naszą instrukcją a tym, co Google zdecyduje się zinterpretować.
Jak analizować znaczniki kanoniczne za pomocą SISTRIX Toolbox Optimizer
Istnieje kilka sposobów analizy kanonicznych za pomocą narzędzia SISTIX Toolbox Optimizer.
Indeksowanie i wykrywanie ostrzeżeń
Będąc robotem indeksującym, Optimizer odwiedzi Twoją witrynę, aby zidentyfikować możliwości ulepszeń, błędy i inne aspekty, o których zostaniesz poinformowany w prosty i wizualny sposób, dzięki czemu nie będziesz musiał tracić czasu na przetwarzanie danych. Oto przykład związany z tagami kanonicznymi, o których powiadomi Cię Optymalizator (jeśli się pomylisz):

Eksplorator adresów URL: analizuj poszczególne adresy URL
Ta funkcja jest podobna do narzędzia do sprawdzania adresów URL w Google Search Console, co oznacza, że możesz oceniać poszczególne adresy URL, które zostały zaindeksowane w projekcie Optymalizatora, i wyświetlać informacje dla tego konkretnego adresu URL.
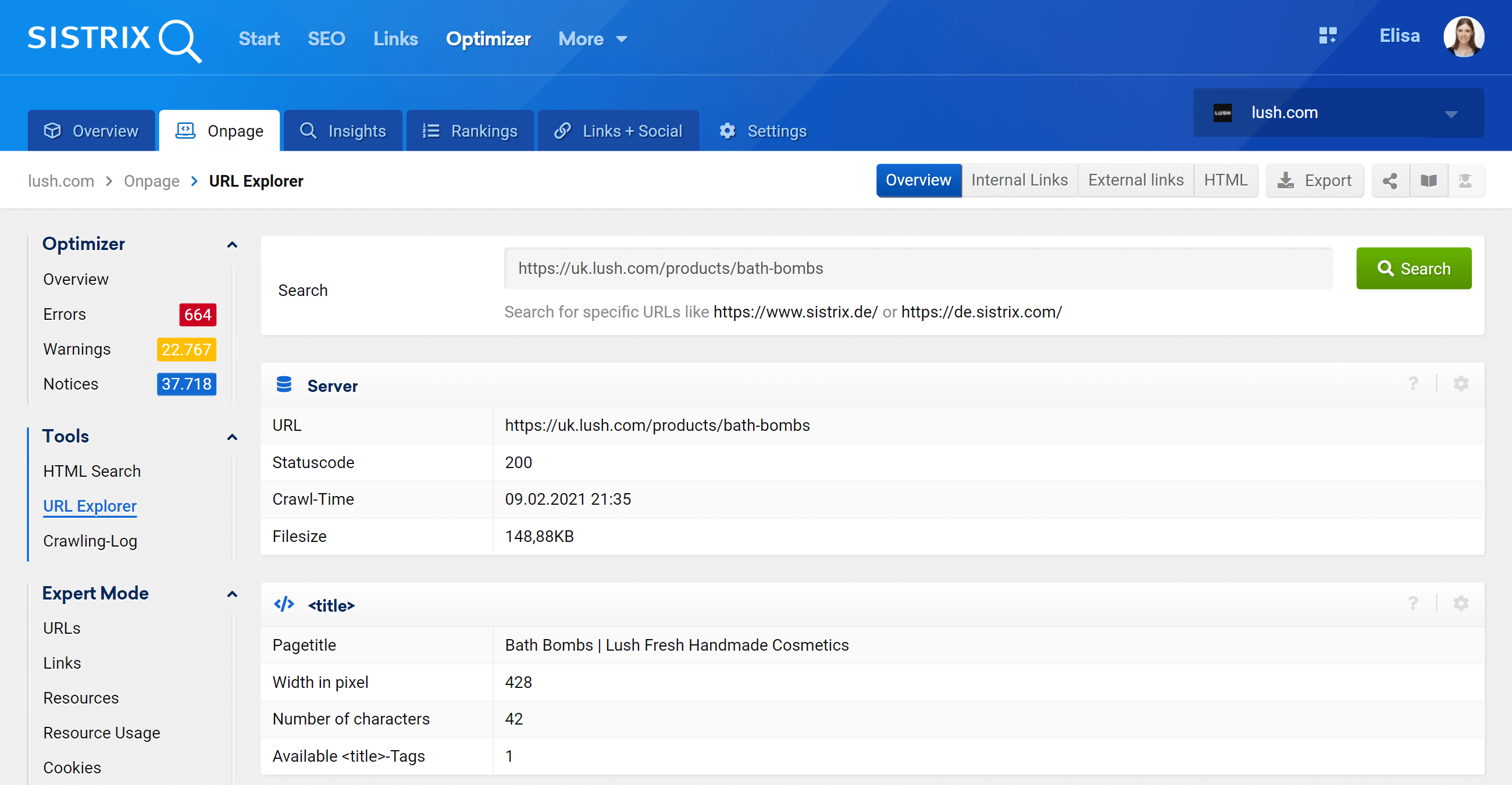
Jak widać, możemy przeanalizować wszystkie aspekty strony dotyczące tego adresu URL, zarówno wewnętrzne linki przychodzące, jak i wychodzące, informacje o serwerze, tagi SEO, i tutaj znajdziesz również implementację kanoniczną, która jest przedmiotem naszego zainteresowania .
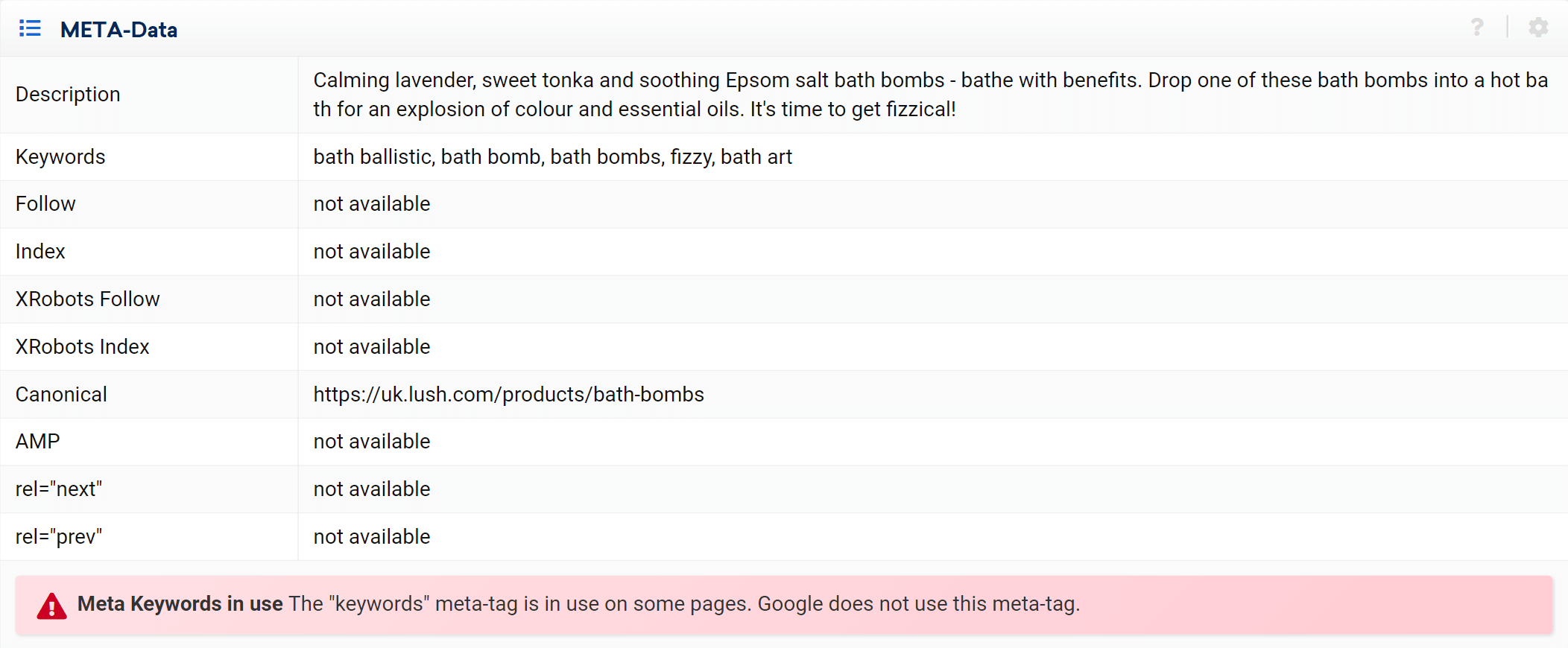
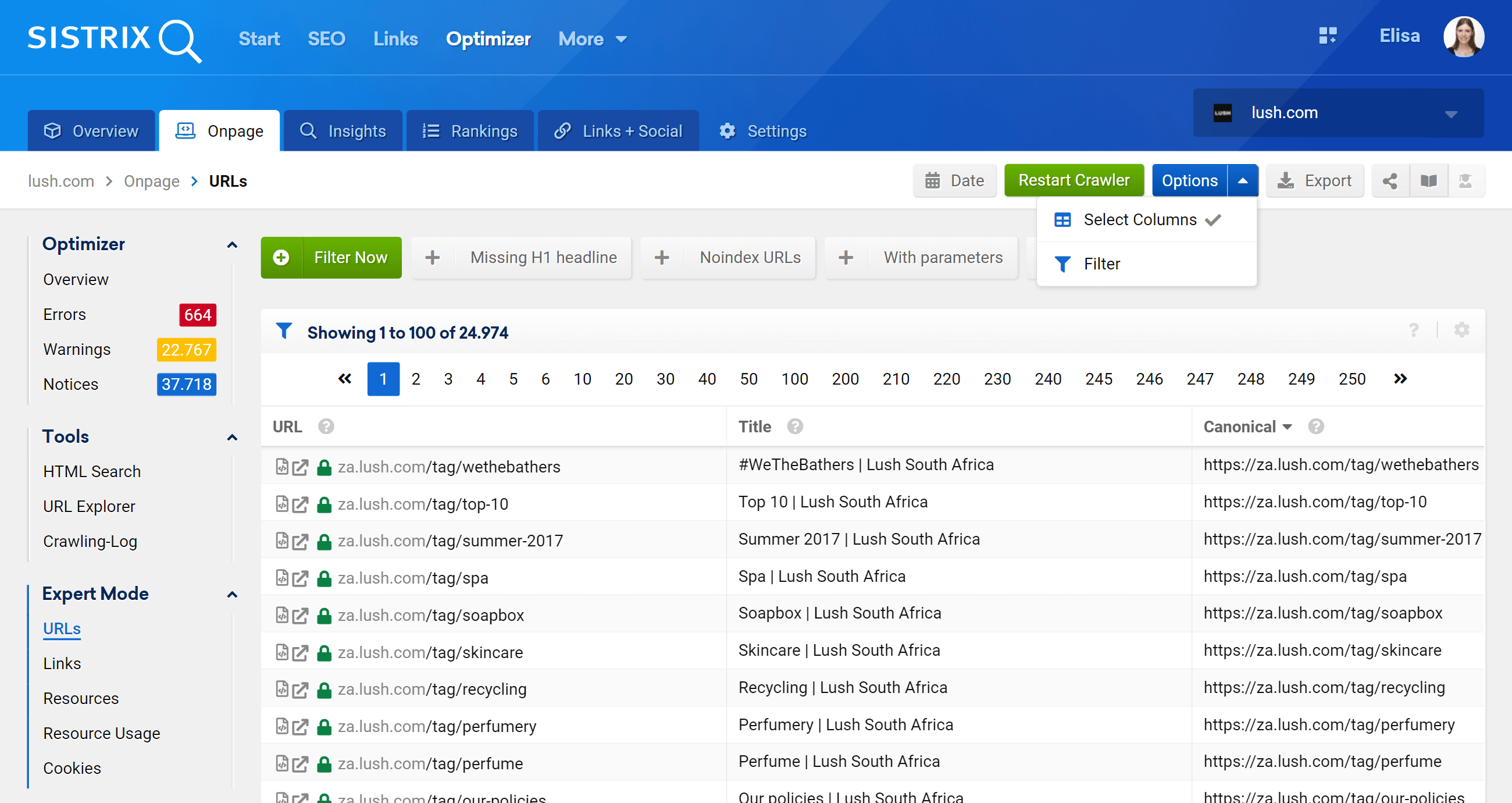
Tryb ekspercki
Przechodząc do sekcji Tryb eksperta, możemy uzyskać dostęp do wszystkich zaindeksowanych adresów URL naszego projektu i użyć wielu filtrów, aby uściślić nasze wyszukiwanie. W poniższym przykładzie umieściłem adresy URL, które zawierają /products/ w swoich adresach URL, ale nie należą do rynku /en_gb/.
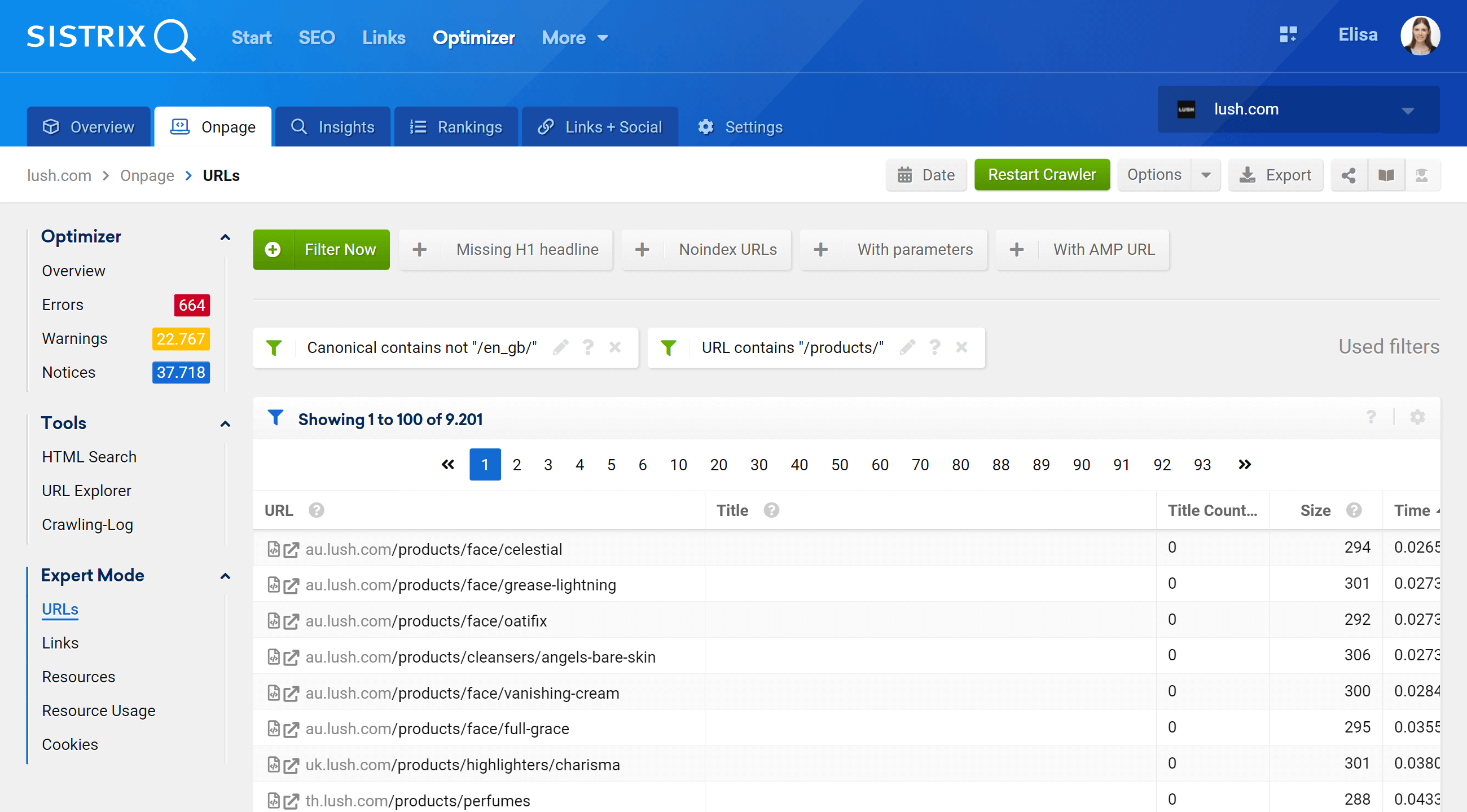
Co więcej, możemy również skonfigurować kolumny tabeli tak, aby wyświetlały pola, które nas bardziej interesują. W moim przykładzie wybrałem wyświetlanie kodów statusu, poziomu głębokości, linków wewnętrznych, meta robotów i kanonicznych, ale moglibyśmy również dodać – po prostu zaznaczenie ich pola – tytuł, opis, H1, rozmiar, rodzaj treści itp.