什么是规范标签以及如何使用它
已发表: 2022-04-17- 定义和含义
- 术语、注意事项和应避免的错误
- 实施程序
- HTML 标记
- HTTP 标头
- 其他信号:站点地图和内部链接
- 效果及SEO案例
- 如何分析或审核规范标签
- 探索源代码
- Chrome 开发者工具
- 在 Google 搜索控制台上
- 如何使用 SISTRIX Toolbox Optimizer 分析规范标签
- 爬取和检测警告
- URL 浏览器:分析单个 URL
- 专家模式
定义和含义
规范标签是我们用来让 Google 知道我们网站上的 2 个或多个 URL 重复、相似或相同的 HTML 元素。
这个标签允许我们“选择”多个 URL 中的哪一个应该显示在 SERP 中,以帮助 Google 决定最终应该在结果中显示哪个页面。 换句话说,我们正在向 Google 提供一个信号,指示要编入索引的首选版本。
除了加强这个索引信号之外,它还整合了我们从原始 URL 指向目标规范 URL 的内部链接。
关于重复的内容和业内流传的各种神话,没有比引用来自谷歌本身的官方资料和参考资料更好的方式来澄清它:
“伙计们,让我们一劳永逸地解决这个问题:没有所谓的“重复内容惩罚”。 至少,不像大多数人说的那样。 您可以通过避免重复内容处罚的神话来帮助您的网站管理员!”
苏珊·莫斯卡
https://webmasters.googleblog.com/2008/09/demystifying-duplicate-content-penalty.html
“重复内容通常是指域内或跨域的实质性内容块,它们要么完全匹配其他内容,要么明显相似。 大多数情况下,这在起源上并不具有欺骗性。”
谷歌
https://developers.google.com/search/docs/advanced/guidelines/duplicate-content
术语、注意事项和应避免的错误
以下是有关规范指令的主要注意事项以及指定它的方法:
- 规范可以是自引用的,尤其是在主页上,因为它可以具有由 CMS 或服务器本身生成的多个访问点(例如 index.html)。
- 只要有两条内容相似、重复,或者换句话说,完全或部分相同,就必须使用规范。 否则,可以忽略此标记。
- 规范必须指向可索引的 URL,返回 200 OK 并且不带有noindex标记。 值得一提的另一件事是,我们不应该将规范发送到不相关的 URL,因为它将被解释为软 404。
- 每个 URL 应该只有一个唯一的规范。 如果有两个不同的规范标签,它们可能会发生冲突,最终都会被忽略。
- 规范可以使用绝对和相对 URL。 但是,重要的是要指出相对 URL 容易出错和疏忽。
- 如果在拼写或其他无意错误方面存在明显错误,则可以忽略规范标签。 可能还有其他信号,将对其进行分析以确定是否应该尊重或忽略规范标签。
- 如果我们发送令人困惑的信号,也可以忽略规范标记,例如从 url1 引用规范到 url2,然后从 url2 到 url1。 发生这种“循环”可能会导致意外行为。
- 规范可以是跨域的,即从域1 指向域2。 当我们可以控制两个域并且我们希望对一个域进行索引而不是另一个域以防止重复时,应该使用它——最好是。 对此要谨慎。
- 另一个示例可以是内容联合。
如果它解决了页面之间重复内容的情况,我们必须处理的一些最典型的情况是:
- 带 www 的 URL 与不带 www 的 URL
- 带有 http 的 URL 与带有 https 的 URL
- 以 / 结尾的 URL vs 不以 / 结尾的 URL(不包括主页)
- 带参数的网址与不带参数的网址(如带有会话 ID 的网址)。
- 有分页的网址与没有分页的网址
- 带 AMP 的 URL 与不带 AMP 的 URL(作为必需的标记)。
- 移动 URL(m 站点)与桌面 URL
- Pre (staging) URLs vs prod (production) URLs
- 等等。
尽管所有这些情况都可以使用规范标签来解决,但谷歌还有另一种更直接的方法: 301 重定向。
您将阅读大量 301 和规范标签比较。 我们不会深入研究它,但我们将在下图中强调有关此问题的最重要的几点:
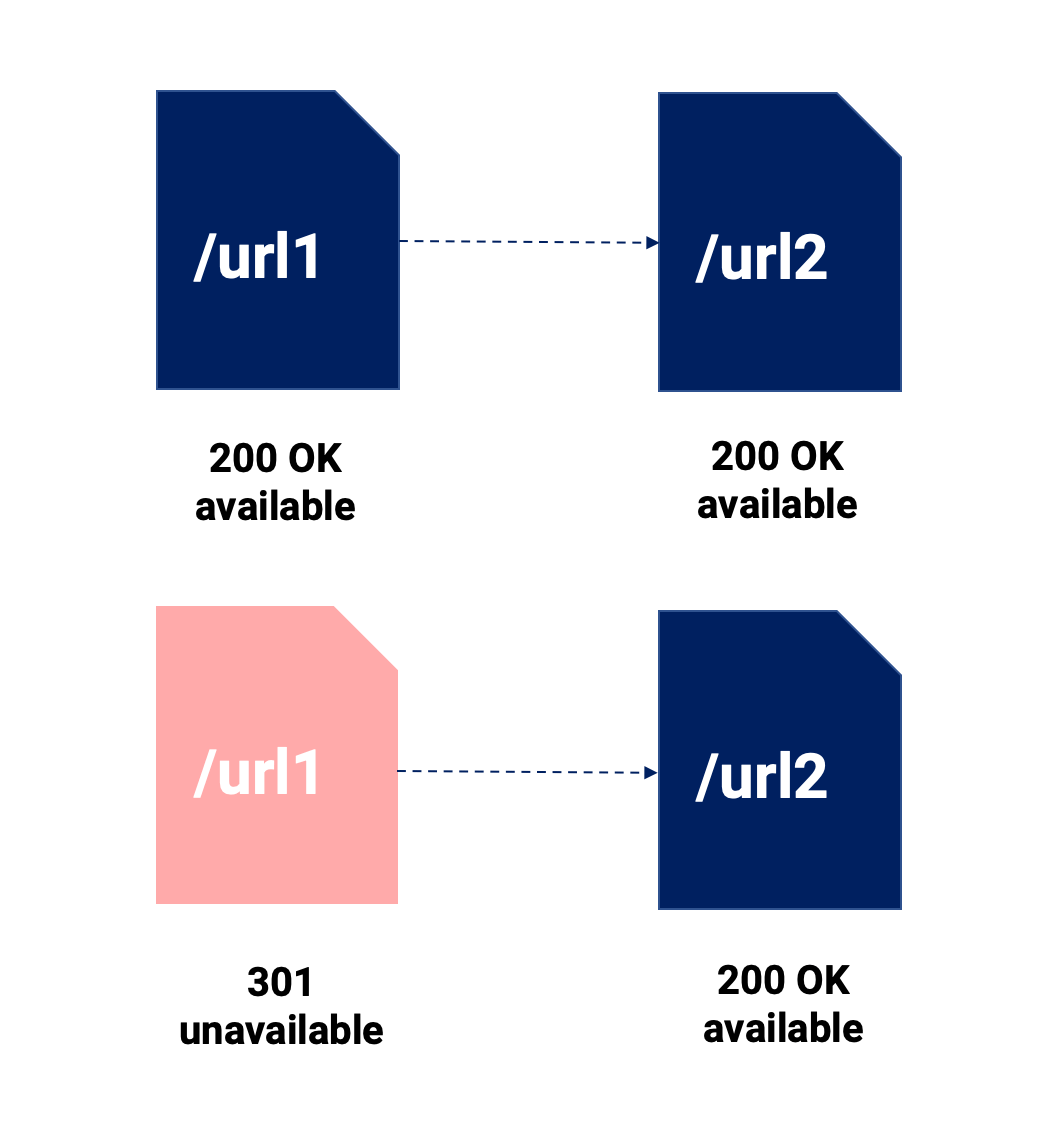
使用这个视觉摘要,我们想要突出显示以下内容:
- 301重定向合并了两条内容,这意味着原始内容不复存在。 它是直接的,100% 紧随其后的是谷歌(和用户)。
- 规范,它的作用是允许我们为任何渠道保留各种可用的 URL,如果 Google 尊重该指令,则只有规范化的 URL 将被编入 SEO 频道的索引。
- 两者都可能涉及信号稀释,并且当我们不使用 301 重定向时,它可能会产生更显着的影响,因为规范化的 URL 可以具有指向它们的内部和外部链接,迫使我们在多个 URL 之间分配工作。
实施程序
有几种方法可以实现规范标签:
HTML 标记
实现规范的最常见方法是在每个 URL 的 <head> 中放置一个带有属性 rel=”canonical” 和规范版本的绝对路径的链接元素。 这是正确的语法:
<link rel="canonical" href="https://www.sistrix.com/ask-sistrix/what-is-the-canonical-tag-and-how-to-use-it/" />HTTP 标头
此方法通常用于非 HMTL 页面。 例如:PDF、XML 或 TXT 文件。
当我们同时拥有 PDF 和匹配的 HTML 页面时,这是使用的典型方法。 通过规范,我们可以向 Google 展示我们希望 HTML 页面进行排名。
尽管如此,考虑到可能存在的各种不同情况,我们推荐这篇文章,通过 .htaccess 文件介绍更多技术实现。
<Files "seo-guide.pdf"> Header add Link "< http://www.sistrix.com/seo-guide/ >; rel=\"canonical\"" </Files>其他信号:站点地图和内部链接
在这种情况下,我们不打算实现规范指令,但我们暗示,这个 URL(与其其他版本相反)是原始 URL,并且它具有更多的权重和价值。
像向站点地图添加 URL 或从网站导航链接 URL 这样简单的事情已经具有默认和隐含的重要性,因此我们几乎发送了一个关于此 URL 版本对我们的重要性的 SEO 信号。 如果我们自相矛盾或有其他模棱两可或不确定的信号,我们将违反SEO 的简单法则:不要让谷歌变得比现在更复杂。
- 使用规范的 2 个重复 URL,原始 URL 将包含在站点地图中,规范化的 URL 不会。
- 对于 2 个重复的 URL,使用规范,原始 URL 将被突出链接,规范化的 URL 不会(尽管这并不总是可能的,并且规范化的 URL 可能有一些指向它的链接)。
效果及SEO案例
使用 canonical 最大的影响是,一旦被 Google 尊重,canonical 标签所指向的 URL 就可以被索引,并且发布 canonical 的人会下台牺牲自己,让更多的原创内容获得索引。
另一方面,如果发布规范的 URL 在导航结构中的某处接收到内部链接, Google 将能够抓取该页面并在其上投入时间。 这应该让我们认真考虑我们结合使用 Robots.txt(甚至是“noindex”)和规范。 如果我们想节省抓取预算,我们可能会阻止 Google 了解重复项及其规范所在的位置。
说到更特殊的情况,我们可以指定更多:
- 被动参数:作为预防措施,与 Google Search Console 的参数管理结合使用。 但是,这些参数用于标记活动(付费、电子邮件、社交……)。
- 活动参数:语言、过滤器。 这里的关键是要确定哪些具有我们可以定位的最少原始内容,此外还要确定它们是否响应搜索意图。 其他问题可能是内部链接和通过这些过滤器的内部链接浪费权限。
- 分页:关于分页的当前场景本身仍然是一个争议。 谷歌删除了 rel prev rel next 指南,现在 SEO 界正在争论我们是否应该使用 noindex、第一页的规范、无限滚动或 AJAX 等动态技术来维护用户的功能而不生成新的页面/链接,视情况而定。 这根本不是一个微不足道的决定。
- 具有相似属性(颜色、尺寸)的产品页面:与我们所说的过滤器类似,我们需要确定它们的内容何时不是最低限度的原始内容,并且我们需要知道它们是否响应搜索意图。 我们应该牢记“不被搜索的不应该被索引”的规则。
如何分析或审核规范标签
现在,我们开始讨论如何识别或审核规范标签。 我们有适合每个人喜好的方法:

探索源代码
访问该页面并右键单击页面上的任意位置以显示带有“查看页面源”选项的菜单(如果您使用的是 Windows,则为 Control + U;如果您使用的是 Mac,则为 CMD + Alt + U)。
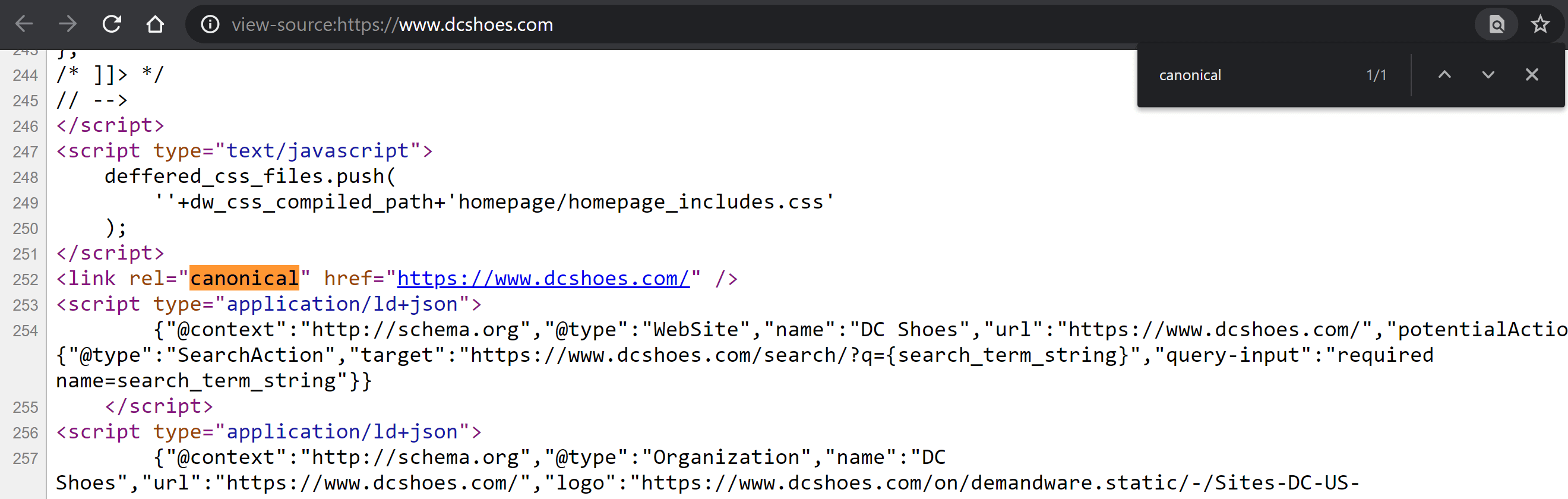
进入后,在 Windows 上按 Control + F 或在 Mac 上按 CMD + F 以在代码中搜索。 键入“canonical”,以便标签以不同的颜色突出显示(如果存在)。 比较其内容并确定该值是否已正确定义。
Chrome 开发者工具
使用 Chrome,我们可以打开我们要分析的网站,右键单击屏幕,然后点击“检查”。 这将打开开发人员工具,我们可以在其中使用 Control + F 或 Cmd + F 搜索标签,就像我们在前一点中所做的那样。
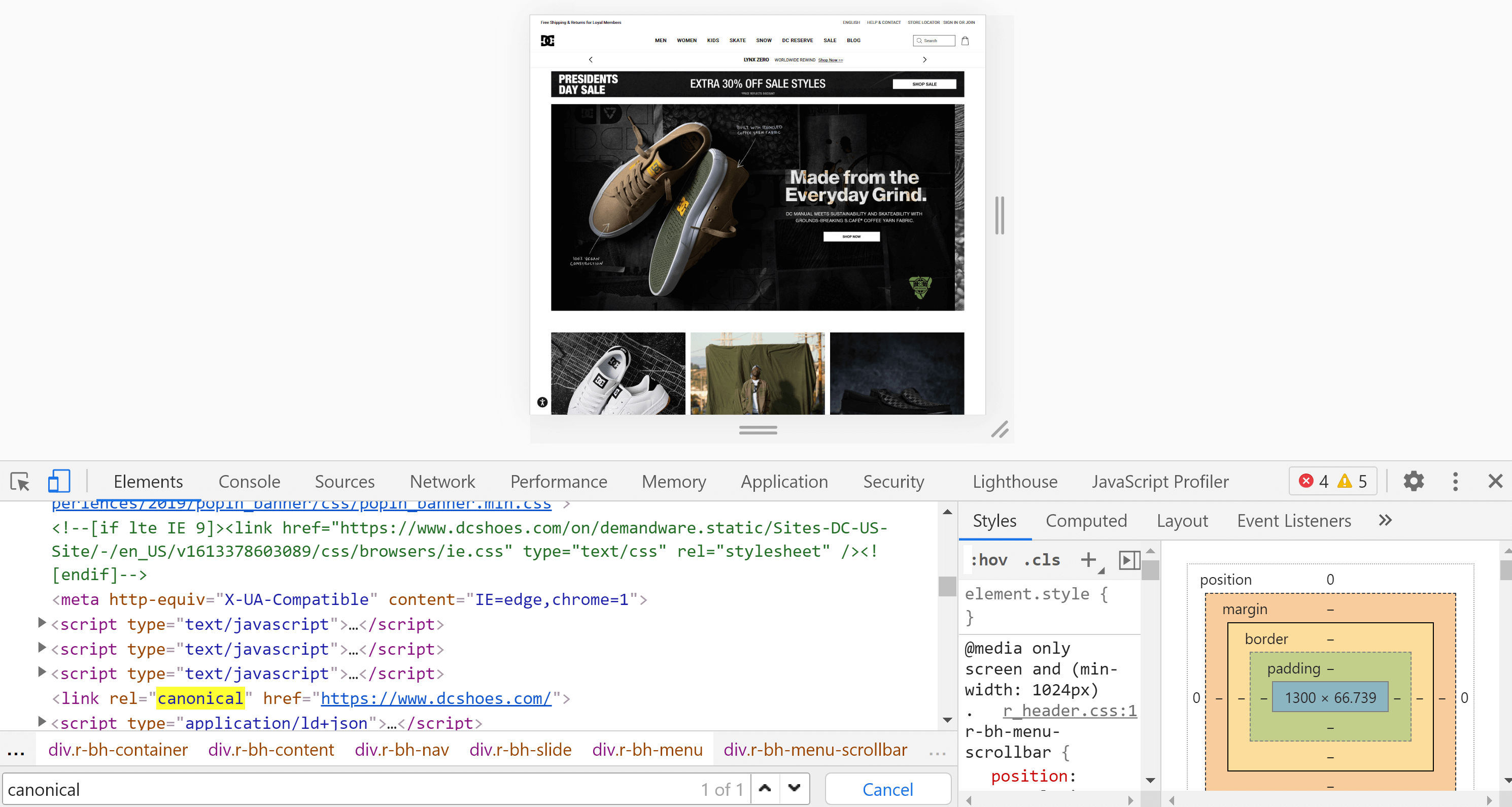
页面源代码和检查器的主要区别在于,第二个已经渲染了页面,我们在这个过程(包括 JavaScript 的执行)完成后看到了内容。
或者,我们可以使用控制台,方法是转到“控制台”选项卡并输入以下命令:
$$('link[rel="canonical"]')[0] 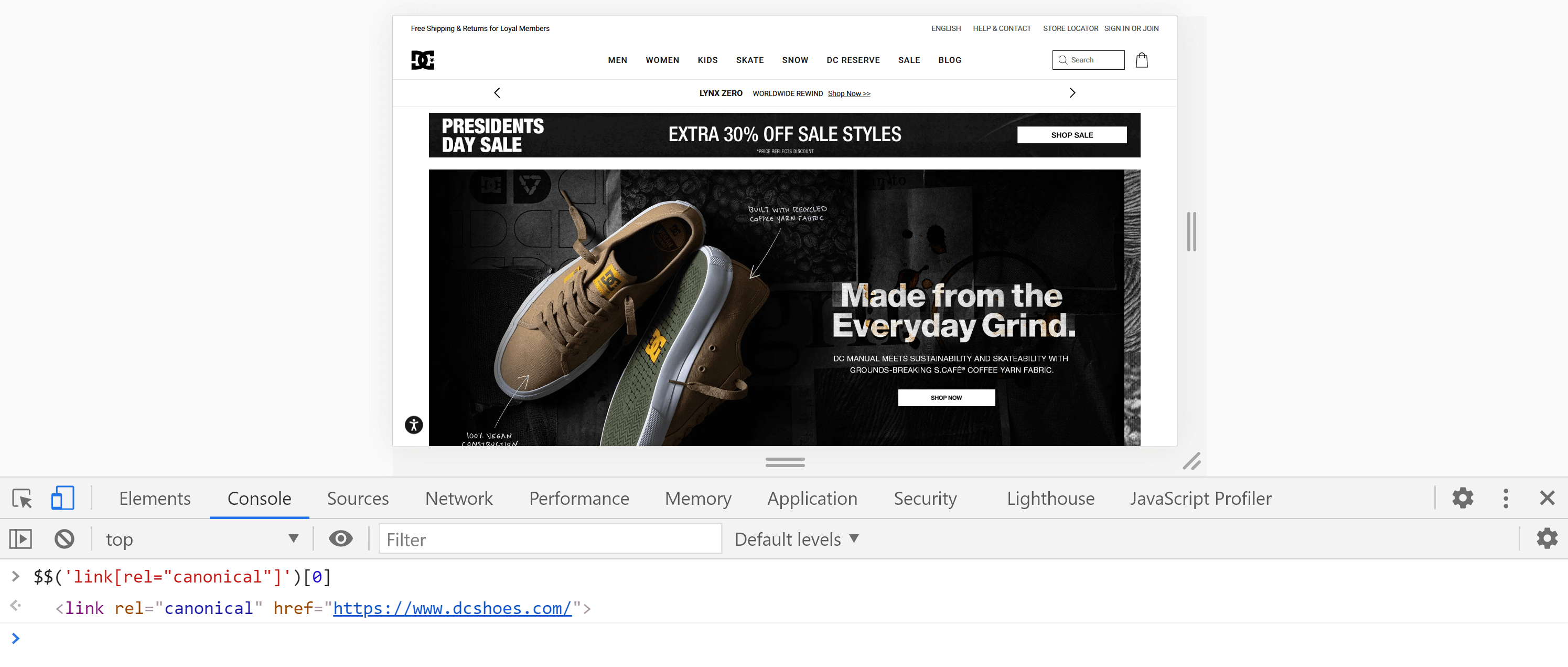
在 Google 搜索控制台上
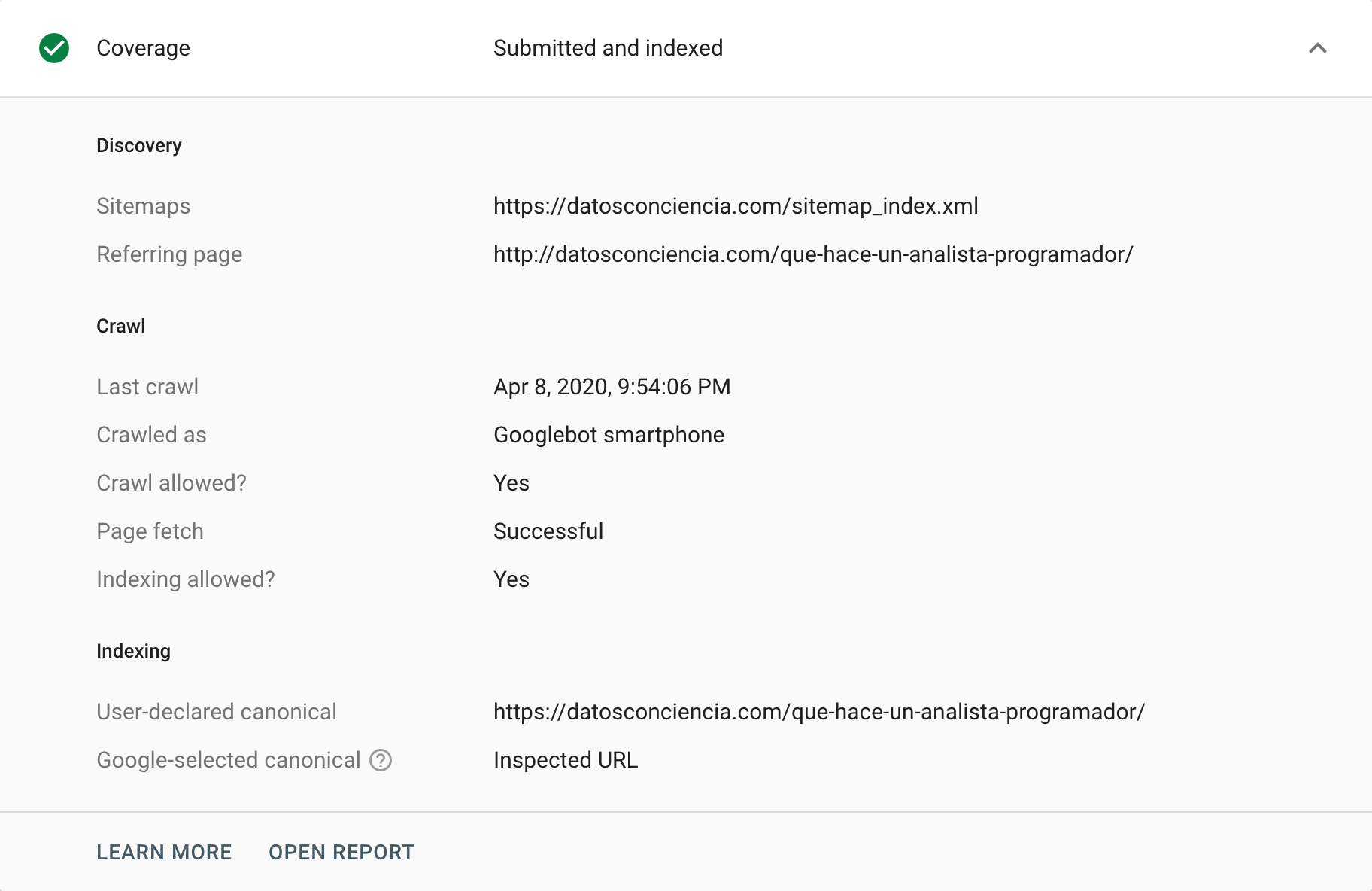
Google Search Console 提供了不同的方法来分析或审核规范标签。 一种方法是转到“覆盖率”报告,我们可以在其中分析导致将某些 URL 从其索引中排除的任何事件。 在这个“排除”部分,我们有时可以找到与规范标签相关的情况,包括正确和不正确的情况(正确和错误解释)。 毫无疑问,这是开始拉扯线索的完美方式,有助于我们发现问题。

另一方面,我们有URL 检查工具,它可以提供有关单个 URL 的规范标签的见解。 我们可以请求它抓取它们并返回它们的状态,尤其是当我们的指令与 Google 选择解释的内容之间存在差异时。
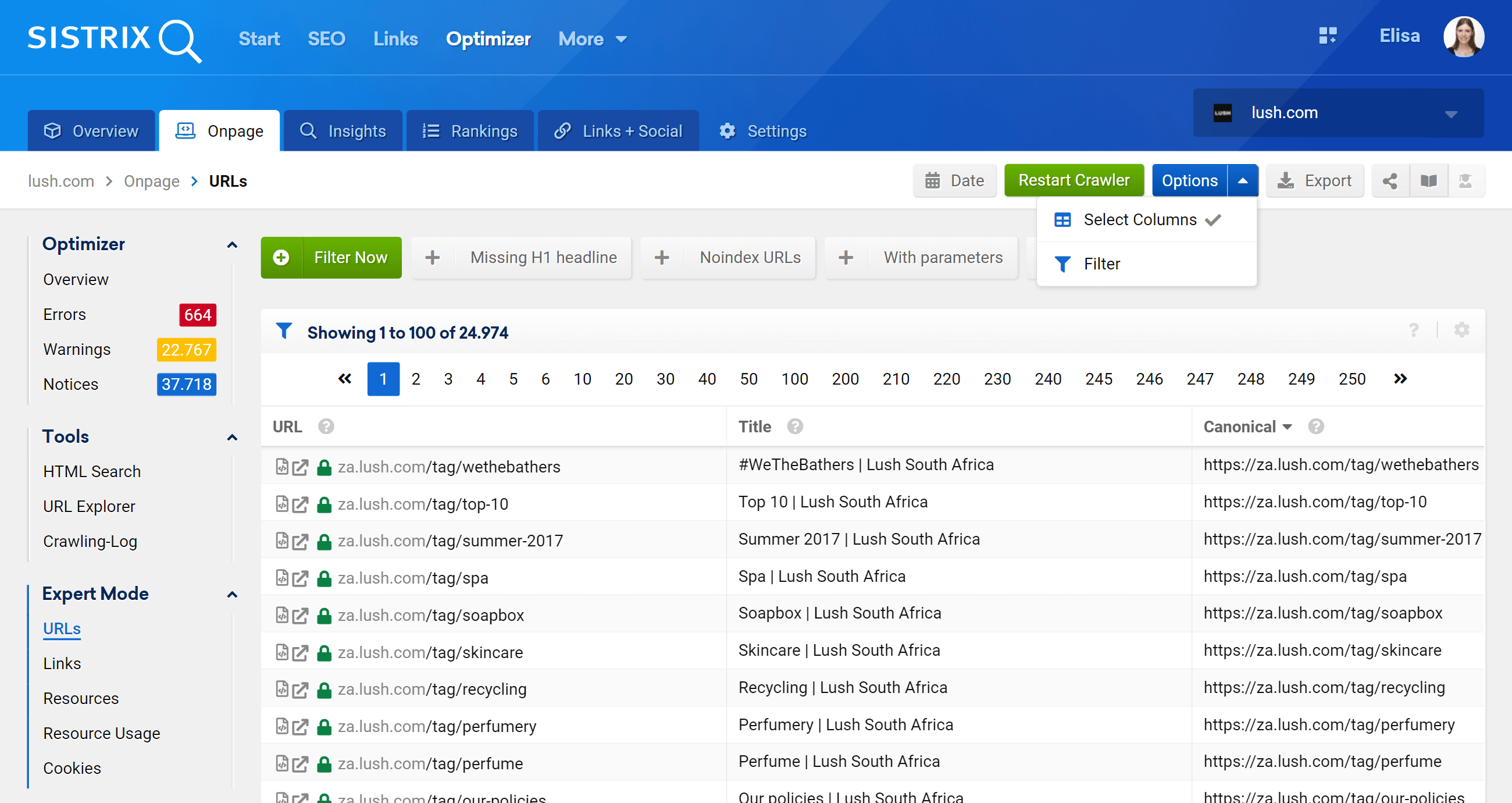
如何使用 SISTRIX Toolbox Optimizer 分析规范标签
有几种方法可以使用 SISTIX Toolbox Optimizer 分析规范。
爬取和检测警告
作为一个爬虫,Optimizer 将访问您的网站以识别改进机会、错误和其他方面,您将以简单和直观的方式获悉,因此您不必浪费时间处理数据。 这是一个与规范标签相关的示例,优化器会通知您(如果您犯了错误):

URL 浏览器:分析单个 URL
此功能类似于 Google Search Console 的 URL 检查工具,这意味着您将能够评估在优化器项目中抓取的各个 URL 并查看该特定 URL 的信息。
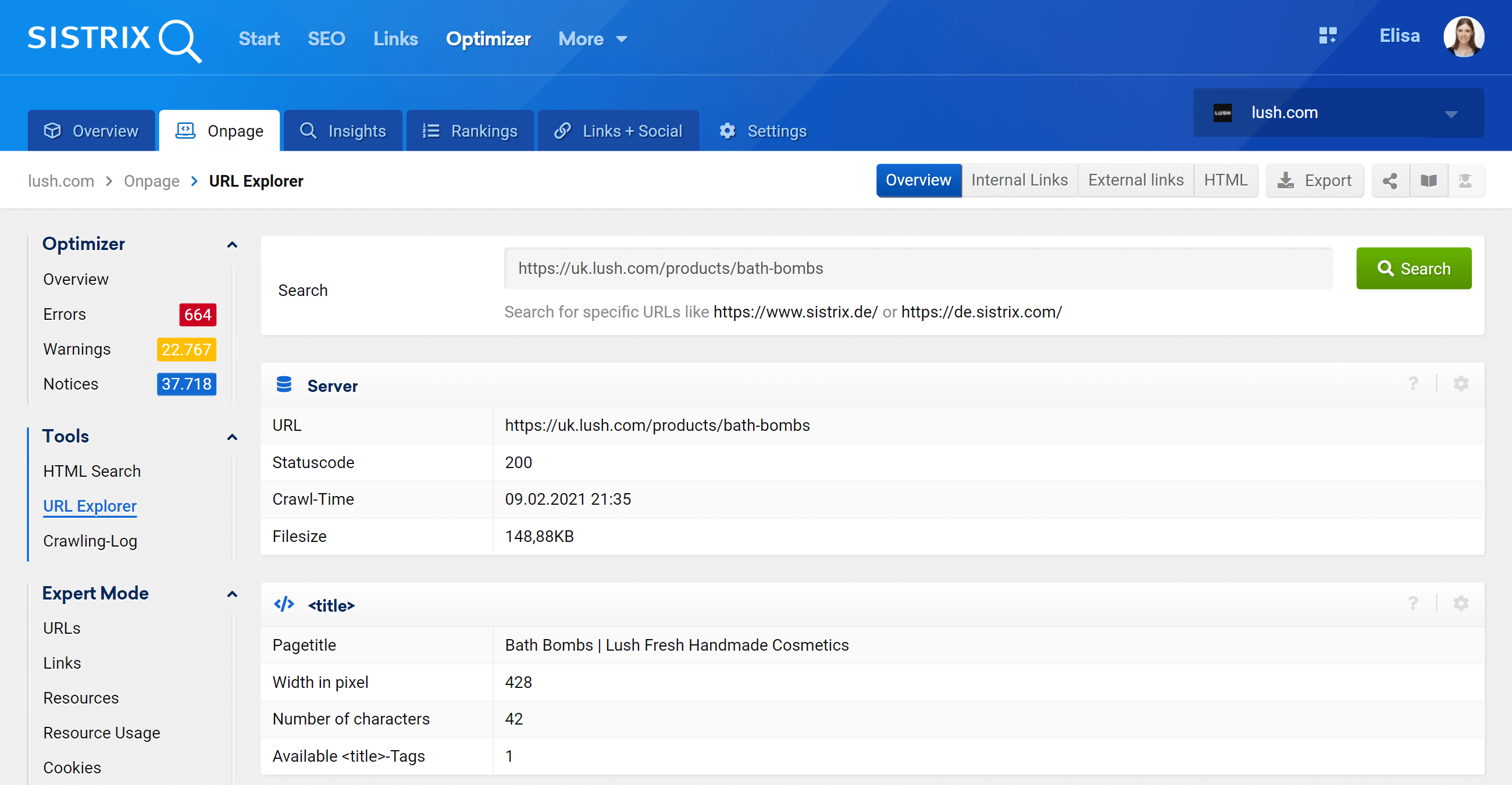
如您所见,我们可以分析与此 URL 相关的所有页面方面,包括入站和出站内部链接、服务器信息、SEO 标签,您还可以在这里找到规范的实现,这是手头的主题.
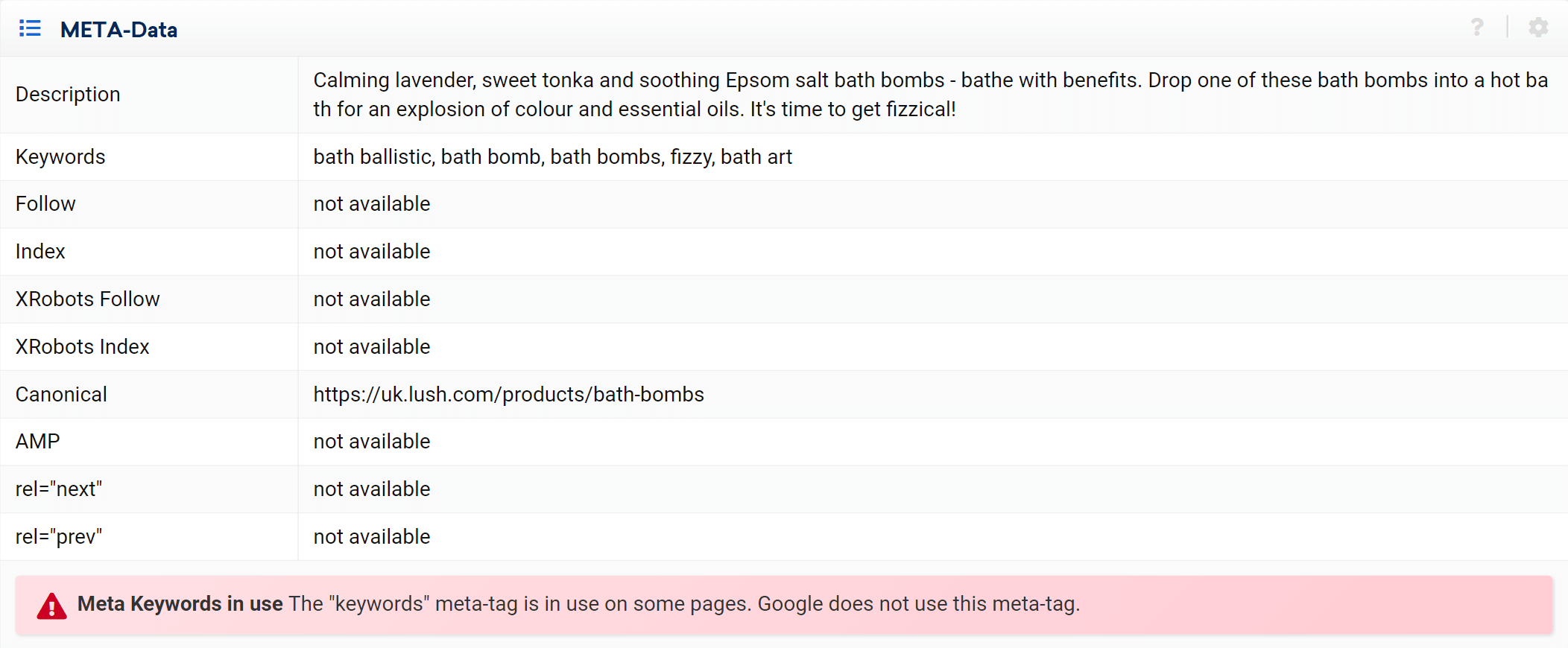
专家模式
通过进入专家模式部分,我们可以访问我们所有项目的抓取 URL,并使用多个过滤器来优化我们的搜索。 在下面的示例中,我在其 URL 中包含了包含 /products/ 但不属于 /en_gb/ 市场的 URL。
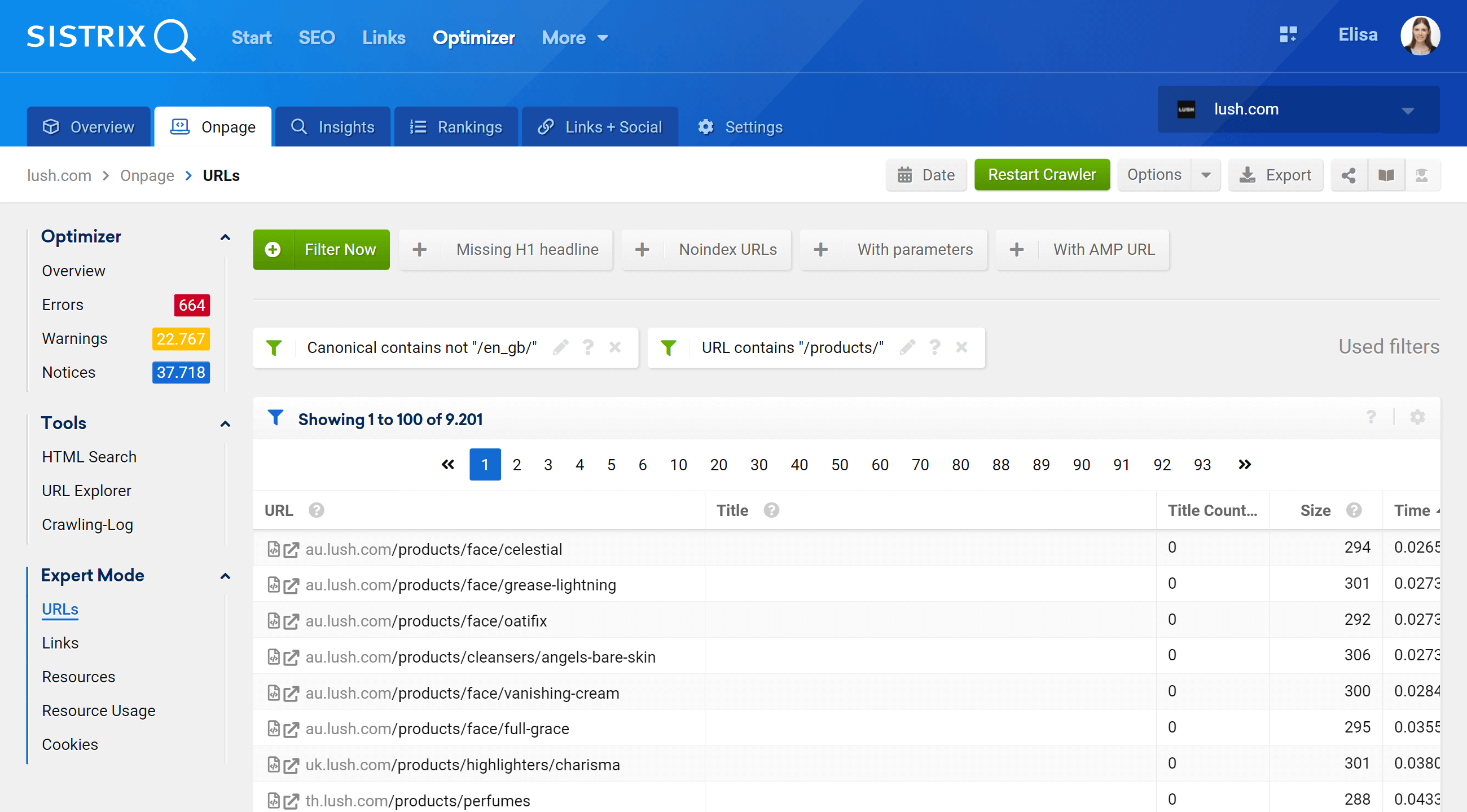
此外,我们还可以配置表格列以显示我们更感兴趣的字段。在我的示例中,我选择显示状态代码、深度级别、内部链接、元机器人和规范,但我们也可以添加 -by 简单检查他们的框——标题、描述、H1、大小、内容类型等。