Qu'est-ce que la balise canonique et comment l'utiliser
Publié: 2022-04-17- Définition et signification
- Nomenclature, considérations et erreurs à éviter
- Procédures de mise en œuvre
- Balise HTML
- En-tête HTTP
- Autres signaux : sitemap et liens internes
- Cas d'effet et de référencement
- Comment analyser ou auditer les balises canoniques
- Explorer le code source
- Outils de développement Chrome
- Sur la console de recherche Google
- Comment analyser les balises canoniques à l'aide de SISTRIX Toolbox Optimizer
- Crawling et détection des avertissements
- Explorateur d'URL : analysez des URL individuelles
- Mode expert
Définition et signification
La balise canonique est l'élément HTML que nous utilisons pour informer Google que 2 URL ou plus sur notre site Web sont en double, similaires ou identiques.
Cette balise nous permet de "sélectionner" laquelle des multiples URL doit être affichée dans les SERP, pour aider Google à décider quelle page elle doit finalement afficher dans les résultats. En d'autres termes, nous fournissons à Google un signal indiquant la version préférée à indexer .
Outre le renforcement de ce signal d'indexation, il consolide également nos liens internes pointant de l'URL d'origine vers l'URL canonique cible.
En ce qui concerne le contenu dupliqué et les divers mythes qui circulent dans l'industrie, il n'y a pas de meilleur moyen de le clarifier qu'en citant des sources officielles et des références provenant de Google lui-même :
« Mettons cela au lit une fois pour toutes, les amis : il n'y a pas de « pénalité de contenu dupliqué ». Du moins, pas de la manière dont la plupart des gens pensent quand ils disent cela. Vous pouvez aider vos collègues webmasters en ne perpétuant pas le mythe des pénalités de contenu dupliqué ! »
Susan Mosca
https://webmasters.googleblog.com/2008/09/demystifying-duplicate-content-penalty.html
"Le contenu dupliqué fait généralement référence à des blocs de contenu substantiels dans ou entre des domaines qui correspondent complètement à un autre contenu ou qui sont sensiblement similaires. Surtout, ce n'est pas trompeur à l'origine.
https://developers.google.com/search/docs/advanced/guidelines/duplicate-content
Nomenclature, considérations et erreurs à éviter
Voici les principales considérations concernant la directive canonique et les moyens de la spécifier :
- Un canonique peut être auto-référentiel, notamment sur la page d'accueil, car il peut avoir plusieurs points d'accès générés par le CMS ou le serveur lui-même (index.html, pour n'en citer qu'un).
- Un canonique doit être utilisé chaque fois qu'il y a deux éléments de contenu similaires, en double ou, en d'autres termes, totalement ou partiellement identiques. Sinon, cette balise peut être ignorée.
- Un canonique doit pointer vers une URL indexable, renvoyant 200 OK et ne portant pas de balise noindex . Une autre chose à mentionner est que nous ne devrions pas envoyer un canonique à une URL non pertinente, car elle sera interprétée comme un Soft 404.
- Il ne devrait y avoir qu'un seul canonique unique pour chaque URL. S'il existe deux balises canoniques différentes, elles peuvent entrer en conflit et les deux finissent par être ignorées.
- Un canonique peut utiliser des URL absolues et relatives. Cependant, il est important de souligner que les URL relatives sont sujettes aux erreurs et aux oublis.
- Une balise canonique peut être ignorée s'il y a des erreurs évidentes, en termes d'orthographe ou d'autres erreurs involontaires. Il peut y avoir d'autres signaux, qui seront analysés pour déterminer si une balise canonique doit être respectée ou ignorée.
- Une balise canonique peut également être ignorée si nous envoyons des signaux déroutants, comme référencer une balise canonique de url1 à url2, puis de url2 à url1. S'engager dans ce genre de « boucles » peut entraîner des comportements inattendus.
- Un canonique peut être interdomaine, c'est-à-dire pointer du domaine1 au domaine2. Il doit être utilisé – de préférence – lorsque nous avons le contrôle sur les deux domaines et que nous voulons favoriser l'indexation d'un domaine par rapport à l'autre pour éviter les duplicités. Soyez prudent avec cela.
- Un autre exemple peut être la syndication de contenu.
À condition qu'il résolve les situations de contenu en double entre les pages, certains des cas les plus typiques où nous devrons faire face à cela sont :
- URL avec www vs URL sans www
- URL avec http vs URL avec https
- URL se terminant par / vs URL ne se terminant pas par / (sans compter la page d'accueil)
- URL avec paramètres vs URL sans paramètres (comme les URL avec ID de session).
- URL avec pagination vs URL sans pagination
- URL avec AMP vs URL sans AMP (en tant que balisage requis).
- URL mobiles (m-sites) vs URL de bureau
- URL de pré (mise en scène) vs URL de production (de toute façon, il est préférable de garder Google hors de la mise en scène par HTTP-Login)
- Etc.
Bien que toutes ces situations puissent être résolues à l'aide de balises canoniques, il existe une autre méthode plus directe pour Google : la redirection 301 .
Vous lirez de nombreuses comparaisons de balises 301 et canoniques. Nous n'allons pas trop nous étendre là-dessus, mais nous allons insister sur les points les plus importants à ce sujet dans l'image ci-dessous :
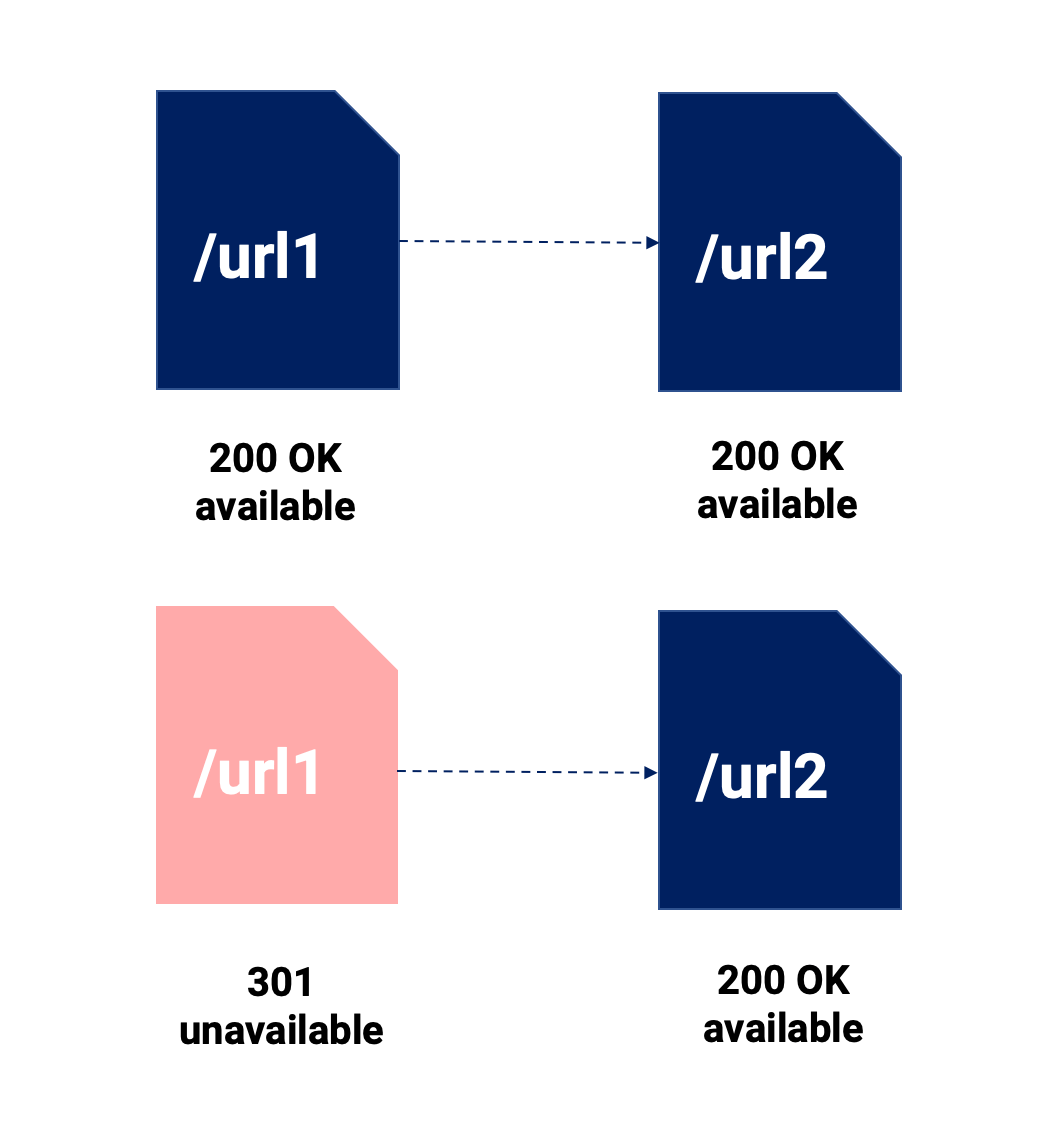
À l'aide de ce résumé visuel, nous souhaitons mettre en évidence les éléments suivants :
- La redirection 301 fusionne deux éléments de contenu, ce qui signifie que le contenu d'origine cesse d'exister. C'est direct et suivi à 100% par Google (et les utilisateurs).
- Le canonique, ce qu'il fait, c'est nous permettre de garder différentes URL disponibles pour n'importe quel canal, et si Google respecte la directive, seule l'URL canonique sera indexée pour le canal SEO.
- Les deux peuvent éventuellement impliquer une dilution du signal, et cela pourrait avoir un effet plus important lorsque nous n'utilisons pas de redirection 301, car les URL canonisées peuvent avoir des liens internes et externes pointant vers elles, nous obligeant à répartir nos efforts entre plusieurs URL.
Procédures de mise en œuvre
Il existe plusieurs façons d'implémenter des balises canoniques :
Balise HTML
La façon la plus courante d'implémenter un canonique est de placer un élément de lien avec l'attribut rel="canonical" et le chemin absolu vers la version canonique dans le <head> de chaque URL. Voici la syntaxe correcte :
<link rel="canonical" href="https://www.sistrix.com/ask-sistrix/what-is-the-canonical-tag-and-how-to-use-it/" />En-tête HTTP
Cette méthode est normalement utilisée sur les pages non HTML. Par exemple : fichiers PDF, XML ou TXT.
C'est la méthode typique utilisée, lorsque nous avons à la fois un PDF et une page HTML correspondante. Grâce au canonique, nous pouvons montrer à Google que nous voulons que la page HTML se classe.
Néanmoins, étant donné la variété des cas différents qui peuvent exister, nous recommandons ce post, couvrant la mise en œuvre plus technique via le fichier .htaccess.
<Files "seo-guide.pdf"> Header add Link "< http://www.sistrix.com/seo-guide/ >; rel=\"canonical\"" </Files>Autres signaux : sitemap et liens internes
Dans ce cas, nous n'allons pas implémenter la directive canonique, mais nous affirmons, implicitement, que cette URL (par opposition à ses autres versions) est celle d'origine, et qu'elle a plus de poids et de valeur.
Quelque chose d'aussi simple que d'ajouter des URL à un sitemap ou de lier une URL à partir de la navigation du site Web a déjà une importance tacite et implicite , nous envoyons donc à peu près un signal SEO concernant l'importance de cette version d'URL pour nous. Si nous nous contredisons ou s'il y a d'autres signaux ambigus ou non concluants, nous enfreindrons la loi de la simplicité en matière de référencement : ne rendez pas les choses plus compliquées pour Google qu'elles ne le sont déjà.
- Avec 2 URL en double, utilisant des canoniques, l'URL d'origine sera incluse dans le plan du site, la canonisée ne le sera pas.
- Avec 2 URL en double, utilisant des canoniques, l'URL d'origine sera bien en évidence, la canonisée ne le sera pas (bien que ce ne soit pas toujours possible, et l'URL canonisée peut avoir un lien pointant vers elle).
Cas d'effet et de référencement
Le plus grand impact que l'utilisation de canonique peut avoir, est qu'une fois qu'il est respecté par Google, l'URL vers laquelle pointe la balise canonique devient indexable , et celui qui émet la canonique se retirera et se sacrifiera, de sorte que le contenu le plus original puisse être indexé.

En revanche, si l'URL émettant le canonique reçoit des liens internes quelque part dans la structure de navigation, Google pourra crawler cette page et y investir du temps . Cela devrait sérieusement nous faire réfléchir à notre utilisation combinée de Robots.txt (voire "noindex") et canonique. Si nous voulons économiser notre budget de crawl, il est possible que nous empêchions Google de comprendre où se trouvent le doublon et son canonique.
En parlant de cas plus particuliers, nous pouvons préciser un peu plus :
- Paramètres passifs : sont utilisés par précaution, en combinaison avec la gestion des paramètres de Google Search Console. Cependant, ces paramètres sont utilisés pour taguer des campagnes (payantes, email, sociales…).
- Paramètres actifs : langue, filtres. La clé ici est d'identifier ceux qui ont un contenu peu original que nous pouvons positionner, en plus de savoir avec certitude s'ils répondent ou non à une intention de recherche. Des problèmes supplémentaires peuvent être les liens internes et le gaspillage d'autorité via les liens internes de ces filtres.
- Pagination : le scénario actuel en matière de pagination est encore une controverse en soi. Google a supprimé la directive rel prev rel next, et maintenant le monde du référencement se demande si nous devrions utiliser noindex, un canonique à la première page, un défilement infini ou des technologies dynamiques comme AJAX pour maintenir la fonctionnalité pour l'utilisateur sans générer de nouvelles pages/liens, selon les cas. Ce n'est pas du tout une décision anodine.
- Pages produits avec des attributs similaires (couleur, taille) : Similaire à ce que nous avons dit à propos des filtres, nous devons identifier quand leur contenu n'est pas minimalement original pour être classé, et nous devons savoir s'ils répondent à une intention de recherche. Nous devons garder à l'esprit la règle du « ce qui n'est pas recherché ne doit pas être indexé » .
Comment analyser ou auditer les balises canoniques
Passons maintenant à l'identification ou à l'audit des balises canoniques. Nous avons des méthodes adaptées aux préférences de chacun :
Explorer le code source
Visitez la page et faites un clic droit n'importe où sur la page pour afficher le menu avec l'option "Afficher la source de la page" (Ctrl + U si vous utilisez Windows ; CMD + Alt + U si vous utilisez Mac).
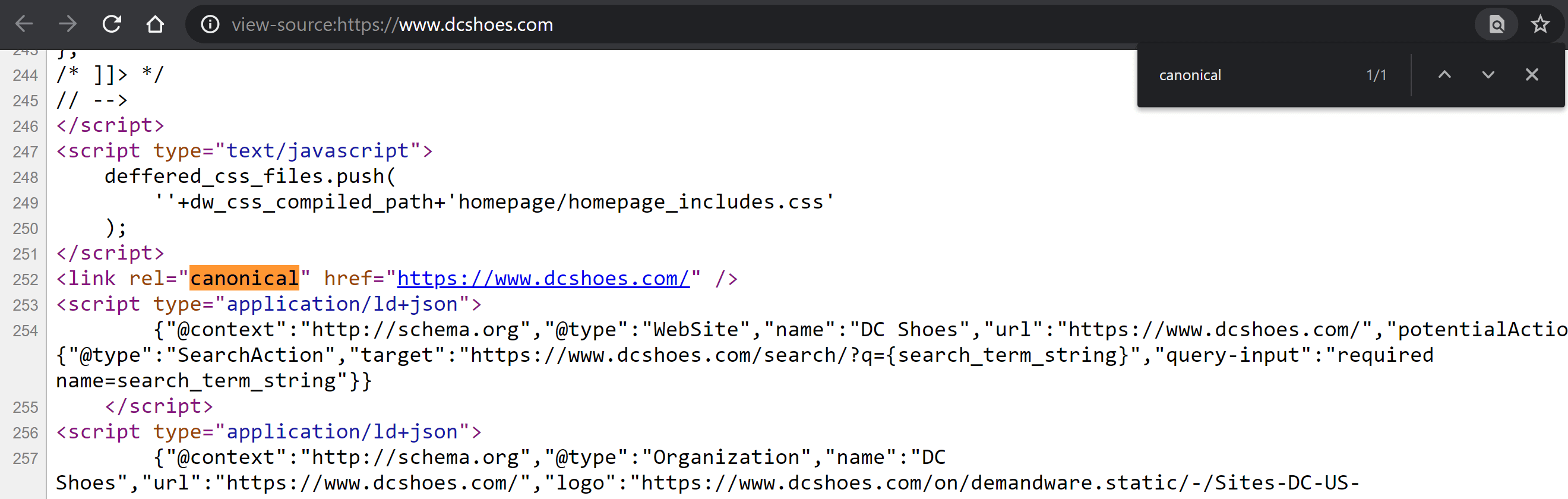
Une fois à l'intérieur, appuyez sur Control + F sous Windows ou CMD + F sur Mac pour rechercher dans le code. Tapez "canonical", de sorte que la balise soit mise en surbrillance dans une couleur différente, si elle est là. Comparez son contenu et déterminez si cette valeur a été correctement définie ou non.
Outils de développement Chrome
En utilisant Chrome, nous pouvons ouvrir le site Web que nous voulons analyser, cliquer avec le bouton droit sur l'écran et cliquer sur "Inspecter". Cela ouvrira les outils de développement, où nous pourrons rechercher la balise avec Control + F ou Cmd + F, comme nous l'avons fait au point précédent.
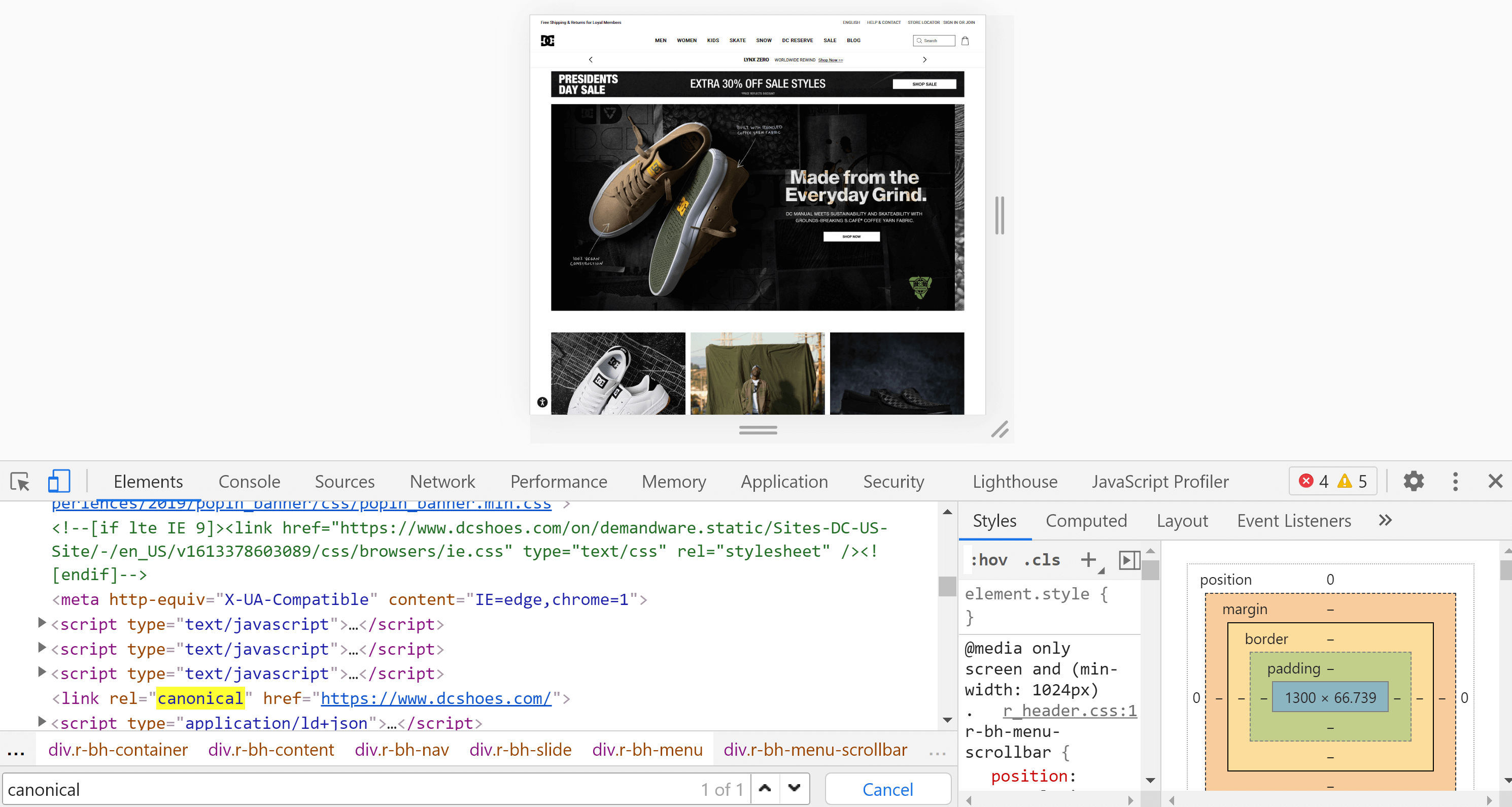
La principale différence entre le code source de la page et l'inspecteur est que le second a déjà rendu la page et nous voyons le contenu une fois ce processus (y compris l'exécution de JavaScript) terminé.
Alternativement, nous pouvons utiliser la console , en allant dans l'onglet "Console" et en entrant la commande suivante :
$$('lien[rel="canonique"]')[0] 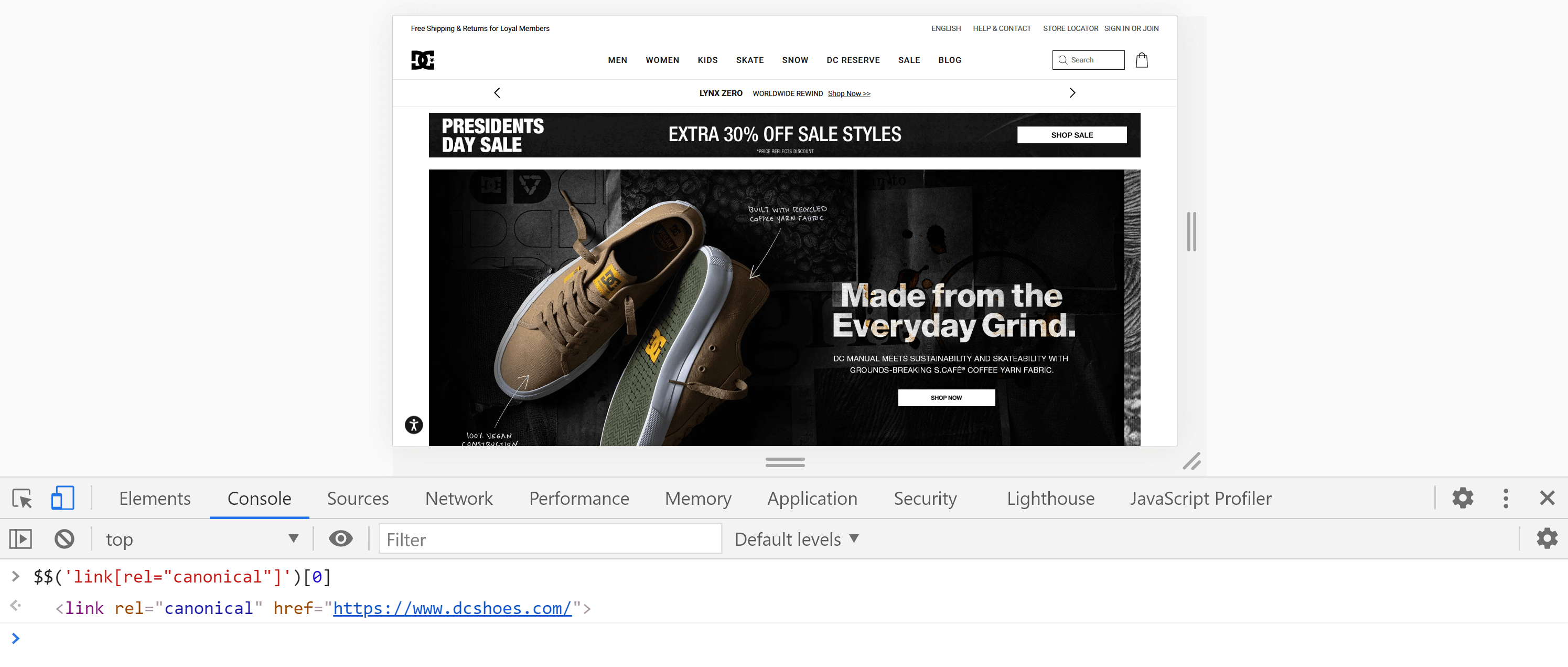
Sur la console de recherche Google
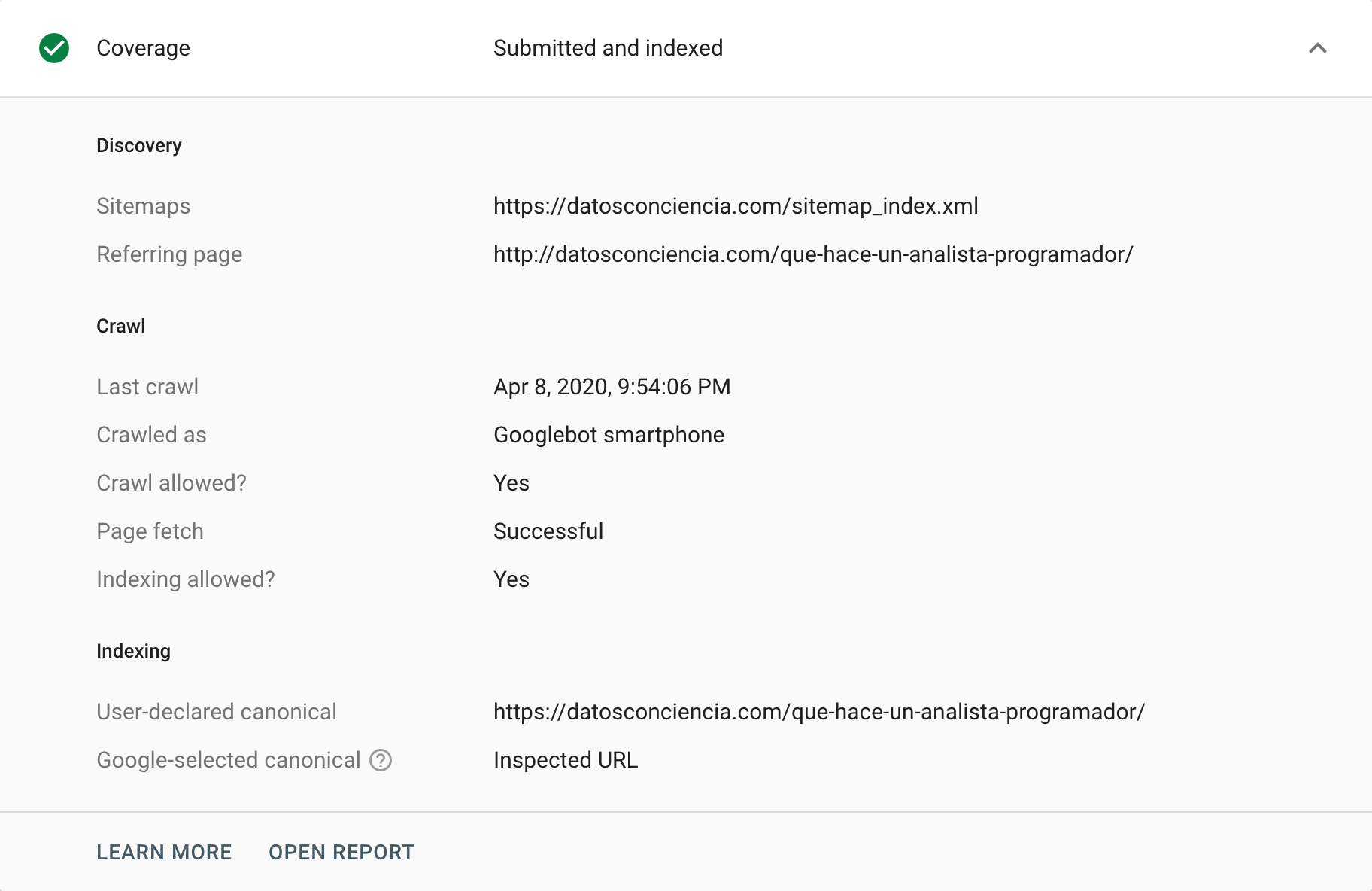
Google Search Console propose différentes manières d'analyser ou d'auditer les balises canoniques. Une façon de le faire est d'aller au rapport "Couverture" , où nous pouvons analyser tout événement responsable de l'exclusion de certaines URL de son index. Dans cette section « Exclu » , nous pouvons parfois trouver des situations liées aux balises canoniques, à la fois des cas corrects et incorrects (correctement et incorrectement interprétés). Sans aucun doute, c'est le moyen idéal pour commencer à tirer sur le fil qui nous aidera à identifier les problèmes.

D'autre part, nous avons l'outil d'inspection d'URL , qui peut fournir des informations sur les balises canoniques des URL individuelles. Nous pouvons lui demander de les explorer et de renvoyer leur statut, surtout s'il y a une différence entre nos instructions et ce que Google choisit d'interpréter.
Comment analyser les balises canoniques à l'aide de SISTRIX Toolbox Optimizer
Il existe plusieurs façons d'analyser les canoniques à l'aide de SISTIX Toolbox Optimizer.
Crawling et détection des avertissements
En tant que crawler, Optimizer visitera votre site Web pour identifier les opportunités d'amélioration, les erreurs et d'autres aspects dont vous serez informé de manière simple et visuelle, afin que vous n'ayez pas à perdre votre temps à traiter les données. Voici un exemple lié aux balises canoniques, dont l'optimiseur vous informera (si vous faites une erreur) :

Explorateur d'URL : analysez des URL individuelles
Cette fonctionnalité est similaire à l'outil d'inspection d'URL de Google Search Console, ce qui signifie que vous pourrez évaluer les URL individuelles qui ont été explorées dans votre projet Optimizer et voir les informations pour cette URL spécifique.
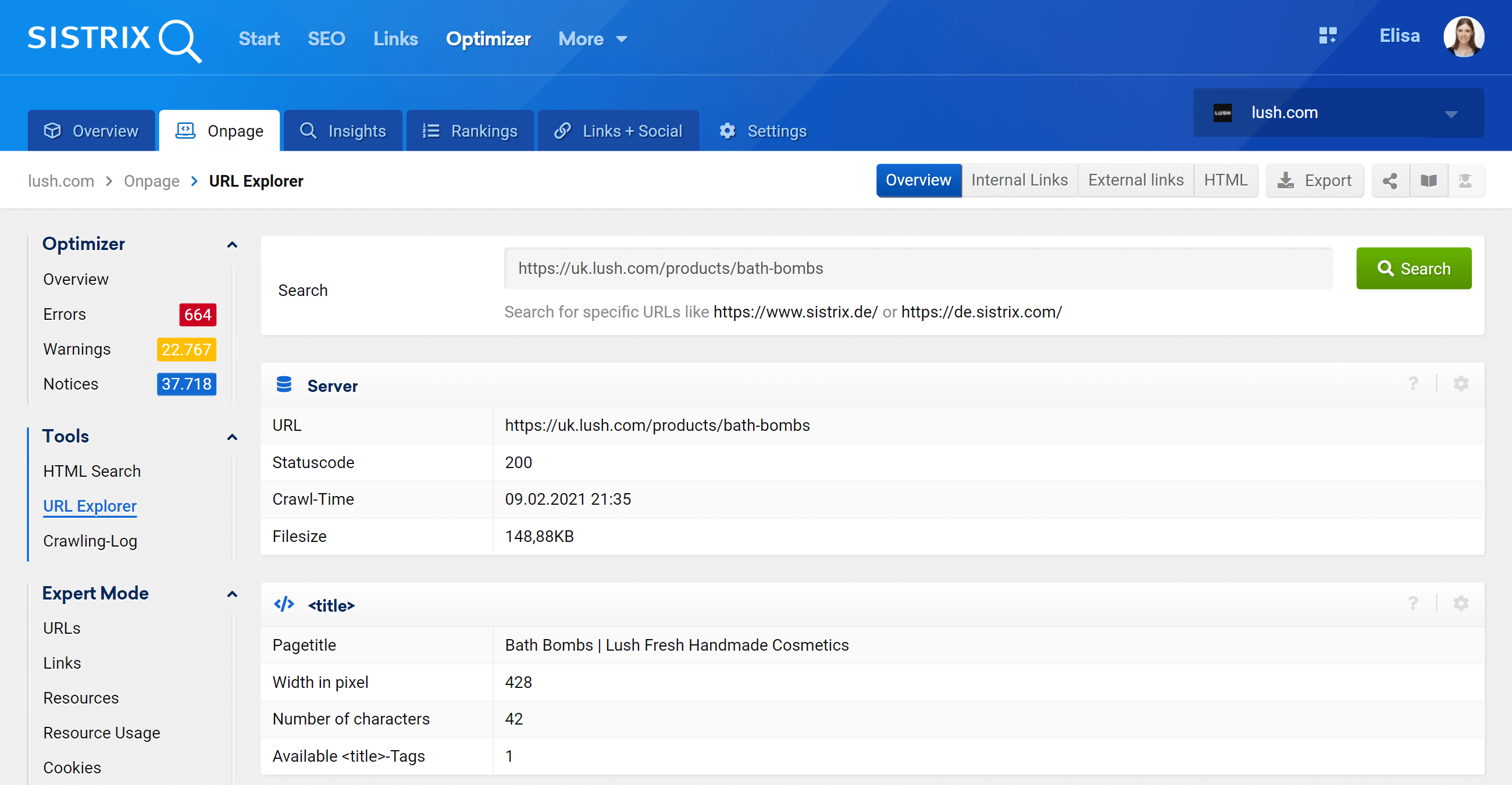
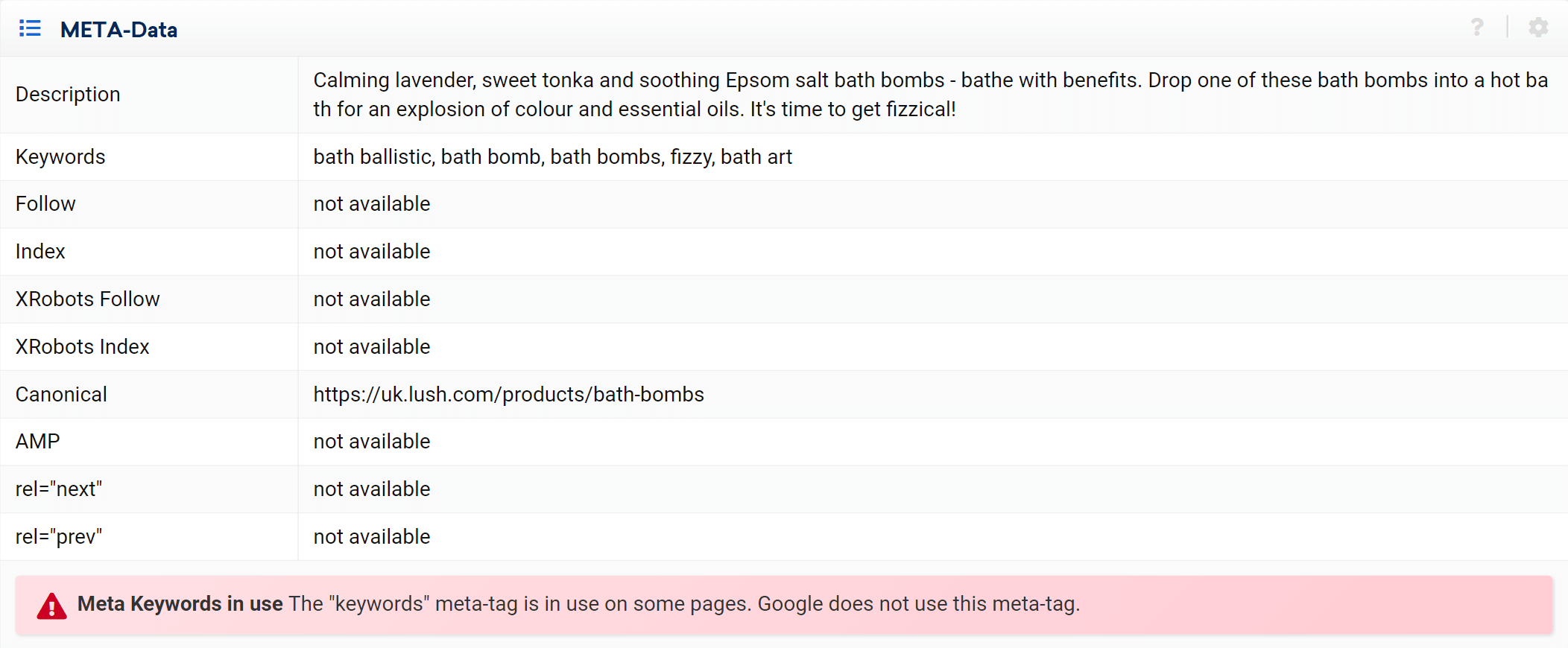
Comme vous pouvez le voir, nous pouvons analyser tous les aspects sur la page concernant cette URL, les liens internes entrants et sortants, les informations sur le serveur, les balises SEO, et c'est là que vous trouverez également l'implémentation canonique, qui est le sujet à portée de main .
Mode expert
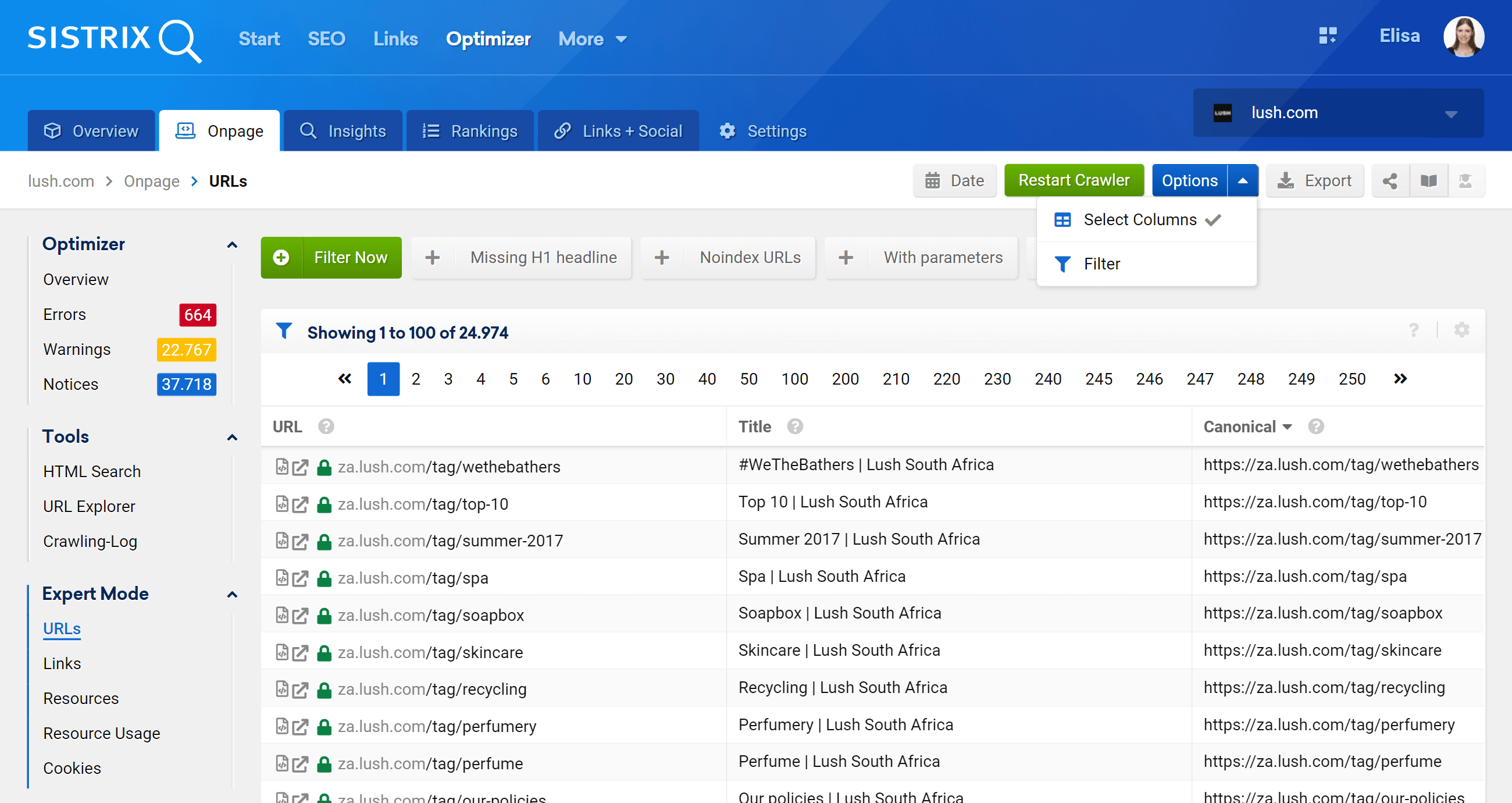
En accédant à la section Mode expert, nous pouvons accéder à toutes les URL explorées de notre projet et utiliser plusieurs filtres pour affiner notre recherche. Dans l'exemple ci-dessous, j'ai inclus les URL qui contiennent /products/ dans leurs URL, mais n'appartiennent pas au marché /en_gb/.
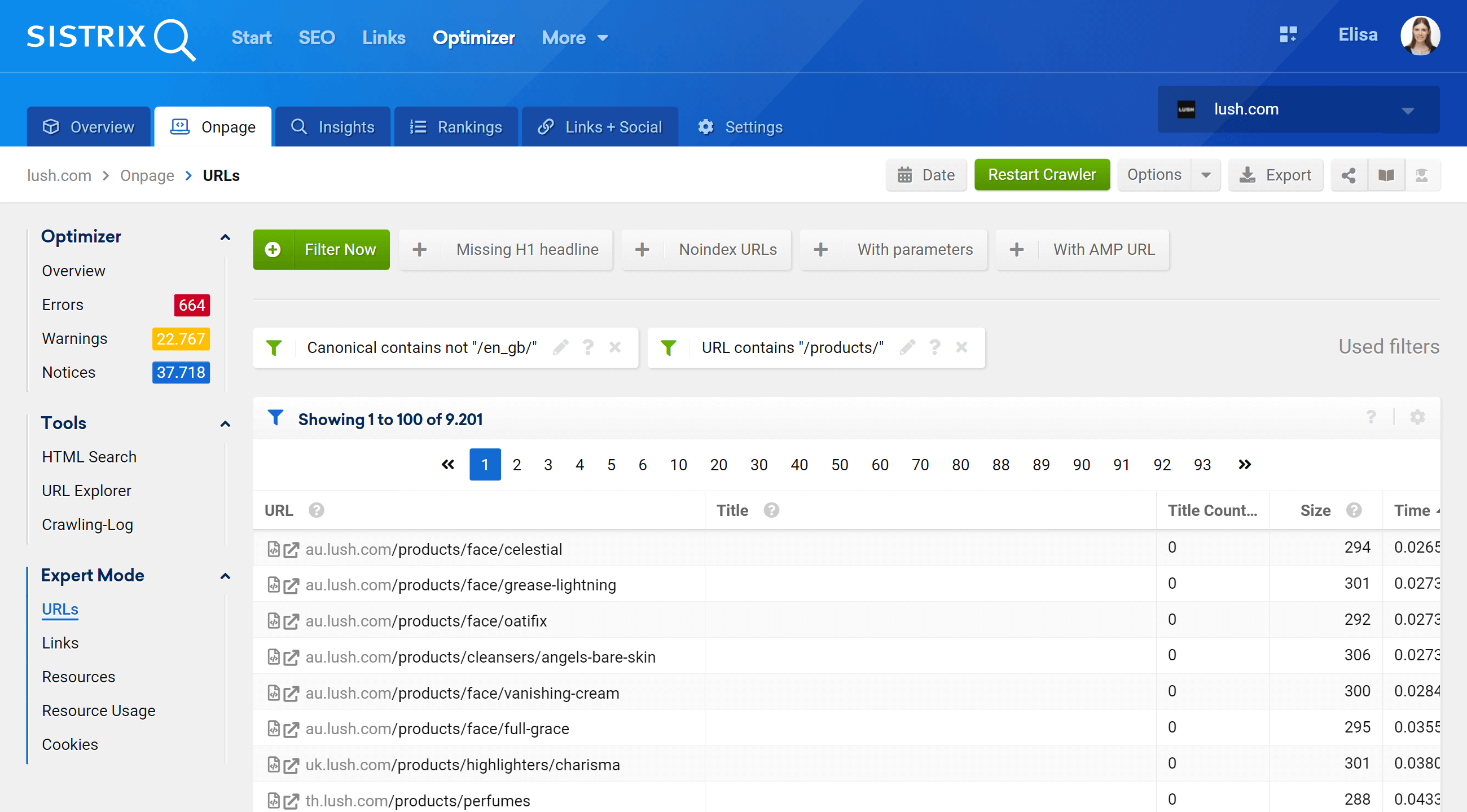
De plus, nous pouvons également configurer les colonnes du tableau pour afficher les champs qui nous intéressent davantage. Dans mon exemple, j'ai choisi d'afficher les codes de statut, le niveau de profondeur, les liens internes, les méta-robots et canoniques, mais nous pourrions également ajouter -par simplement en cochant leur case – le titre, la description, H1, la taille, le type de contenu, etc.