
Наука о данных для SEO и цифрового маркетинга: рекомендуемое руководство для начинающих
Опубликовано: 2021-12-07Поскольку большая часть нашей работы связана с данными, а область науки о данных становится намного больше и доступнее для начинающих, я хотел бы поделиться некоторыми мыслями о том, как вы можете войти в эту область, чтобы улучшить свои SEO и маркетинг. навыки в целом.
Что такое наука о данных?
Очень хорошо известная диаграмма, которая используется для обзора этой области, — диаграмма Венна Дрю Конвея, показывающая науку о данных как пересечение статистики, хакерства (продвинутые навыки программирования в целом, и не обязательно проникновение в сети и причинение вреда) и существенных опыт или «знание предметной области»:
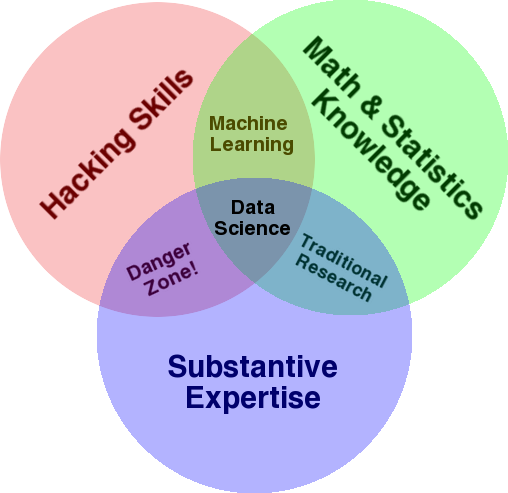
Источник: oreilly.com
Когда я начал учиться, я быстро понял, что это именно то, чем мы уже занимаемся. Единственная разница в том, что я делал это с помощью более простых и ручных инструментов.
Если вы посмотрите на схему, вы легко увидите, как вы, вероятно, уже это делаете. Вы используете компьютер (хакерские навыки), для анализа данных (статистики), для решения практической задачи, используя свои существенные знания в области SEO (или любой другой специальности, на которой вы сосредоточены).
Ваш текущий «язык программирования», вероятно, представляет собой электронную таблицу (Excel, Google Sheets и т. д.), и вы, скорее всего, используете Powerpoint или что-то подобное для обмена идеями. Давайте немного расширим эти элементы.
- Знание предметной области: давайте начнем с вашей сильной стороны, поскольку вы уже знаете о своей области знаний. Имейте в виду, что это неотъемлемая часть работы специалиста по данным, и именно здесь вы можете развивать и защищать свои знания. Несколько месяцев назад я обсуждал анализ набора данных сканирования со своим другом. Он физик, проводит докторские исследования в области квантовых компьютеров. Его математические и статистические знания и навыки намного превосходят мои, и он действительно умеет анализировать данные намного лучше меня. Одна проблема. Он не знал, что такое «404» (или зачем нам «301»). Итак, со всеми своими математическими знаниями он не смог разобраться в столбце «статус» в наборе данных обхода. Естественно, он не знал, что делать с этими данными, с кем разговаривать и какие стратегии строить на основе этих кодов состояния (или искать в другом месте). Мы с вами знаем, что с ними делать, или, по крайней мере, знаем, где еще искать, если хотим копнуть глубже.
- Математика и статистика. Если вы используете Excel для получения среднего значения выборки данных, вы используете статистику. Среднее значение — это статистика, описывающая определенный аспект выборки данных. Более продвинутая статистика поможет в понимании ваших данных. Это тоже важно, и я не эксперт в этой области. Чем больше статистических распределений вы знаете, тем больше у вас идей о том, как анализировать данные. Чем больше фундаментальных тем вы знаете, тем лучше вы формулируете свои гипотезы и делаете точные утверждения о своих наборах данных.
- Навыки программирования: я рассмотрю это более подробно ниже, но в основном это то, где вы создаете гибкость, говоря компьютеру, чтобы он делал именно то, что вы хотите, вместо того, чтобы зацикливаться на простых в использовании, но немного ограничительных инструменты. Это ваш основной способ получения, изменения и очистки ваших данных любым удобным для вас способом, открывающий вам путь к открытым и гибким «беседам» с вашими данными.
Давайте теперь посмотрим, что мы обычно делаем в науке о данных.
Цикл науки о данных
Типичный проект или даже задача по науке о данных обычно выглядит примерно так:
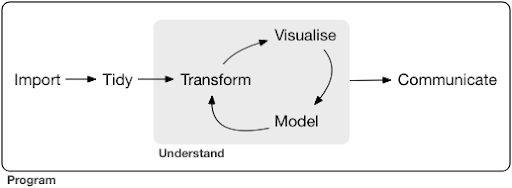
Источник: r4ds.had.co.nz
Я также настоятельно рекомендую прочитать эту книгу Хэдли Уикхэма и Гаррета Гролемунда, которая служит отличным введением в науку о данных. Он написан с примерами из языка программирования R, но концепции и код легко понять, если вы знаете только Python.
Как вы можете видеть на диаграмме, сначала нам нужно каким-то образом импортировать наши данные, привести их в порядок, а затем начать работать над внутренним циклом преобразования, визуализации и моделирования. После этого мы сообщаем результаты другим.
Эти шаги могут варьироваться от чрезвычайно простых до очень сложных. Например, шаг «Импорт» может быть таким же простым, как чтение CSV-файла, а в некоторых случаях может состоять из очень сложного проекта веб-скрейпинга для получения данных. Некоторые элементы процесса являются полноценными самостоятельными специальностями.
Мы можем легко сопоставить это с некоторыми знакомыми нам процессами. Например, вы можете начать с получения некоторых метаданных о веб-сайте, загрузив его файлы robots.txt и XML-карты сайта. Затем вы, вероятно, просканируете и, возможно, также получите некоторые данные о позициях в поисковой выдаче или, например, данные о ссылках. Теперь, когда у вас есть несколько наборов данных, вы, вероятно, захотите объединить некоторые таблицы, ввести некоторые дополнительные данные и начать исследовать/понимать. Визуализация данных может выявить скрытые закономерности, помочь понять, что происходит, или, возможно, вызвать дополнительные вопросы. Вероятно, вы также захотите смоделировать свои данные, используя некоторую базовую статистику или модели машинного обучения, и, надеюсь, получить некоторое представление. Конечно, вам необходимо сообщить о результатах и вопросах другим заинтересованным сторонам проекта.
Как только вы достаточно ознакомитесь с различными инструментами, доступными для каждого из этих процессов, вы можете начать создавать свои собственные настраиваемые пайплайны, специфичные для определенного веб-сайта, потому что каждый бизнес уникален и имеет особый набор требований. Со временем вы начнете находить закономерности и вам не придется переделывать всю работу для похожих проектов/сайтов.
Существует множество инструментов и библиотек, доступных для каждого элемента в этом процессе, и может быть довольно сложно выбрать тот инструмент, который вы выберете (и потратите свое время на обучение). Давайте рассмотрим возможный подход, который я считаю полезным при выборе инструментов, которые я использую.
Выбор инструментов и компромиссов (3 способа получить пиццу)
Следует ли вам использовать Excel для повседневной работы по обработке данных или стоит затрачивать усилия на изучение Python?
Вам лучше визуализировать с помощью чего-то вроде Power BI, или вам следует инвестировать в изучение грамматики графики и научиться использовать библиотеки, которые ее реализуют?
Будете ли вы работать лучше, создавая свои собственные интерактивные информационные панели с помощью R или Python, или вам следует просто использовать Google Data Studio?
Давайте сначала рассмотрим компромиссы, связанные с выбором различных инструментов на разных уровнях абстракции. Это отрывок из моей книги о создании интерактивных информационных панелей и приложений данных с помощью Plotly и Dash, и я считаю этот подход полезным:
Рассмотрим три разных подхода к приготовлению пиццы:
- Подход к заказу: вы звоните в ресторан и заказываете пиццу. Он прибывает к вашему порогу через полчаса, и вы начинаете есть.
- Подход супермаркета: вы идете в супермаркет, покупаете тесто, сыр, овощи и все остальные ингредиенты. Затем вы делаете пиццу сами.
- Фермерский подход: вы выращиваете помидоры на своем заднем дворе. Вы выращиваете коров, доите их, превращаете молоко в сыр и так далее.
По мере того, как мы переходим к интерфейсам более высокого уровня, к подходу упорядочивания, объем требуемых знаний значительно уменьшается. Кто-то другой несет ответственность, а качество проверяется рыночными силами репутации и конкуренции.
Цена, которую мы платим за это, — уменьшение свободы и возможностей. У каждого ресторана есть набор опций на выбор, и вы должны выбирать из этих опций.
Спускаясь на более низкие уровни, объем необходимых знаний увеличивается, нам приходится справляться с большей сложностью, мы несем больше ответственности за результаты, и это занимает гораздо больше времени. Здесь мы получаем гораздо больше свободы и возможностей для настройки наших результатов так, как мы хотим. Стоимость также является важным преимуществом, но только в достаточно больших масштабах. Если вы хотите съесть пиццу только сегодня, вероятно, дешевле заказать ее. Но если вы планируете делать это каждый день, вы можете рассчитывать на значительную экономию средств, если будете делать это самостоятельно.
Это виды выбора, которые вам придется сделать, выбирая, какие инструменты использовать и изучать. Использование таких языков программирования, как R или Python, требует гораздо больше работы и является более сложным, чем Excel, с преимуществом, которое делает вас намного более продуктивным и мощным.
Выбор также важен для каждого инструмента или процесса. Например, вы можете использовать высокоуровневый и простой в использовании сканер для сбора данных о веб-сайте, но при этом предпочитаете использовать язык программирования для визуализации данных со всеми доступными опциями. Выбор правильного инструмента для правильного процесса зависит от ваших потребностей, и мы надеемся, что описанный выше компромисс может помочь в этом выборе. Это также, надеюсь, поможет решить вопрос о том, хотите ли вы изучать Python или R (и в каком объеме).
Давайте рассмотрим этот вопрос немного подробнее и посмотрим, почему изучение Python для SEO может быть неправильным ключевым словом.
Почему «python для SEO» вводит в заблуждение
Вы хотите стать отличным блоггером или хотите изучить WordPress?
Вы хотите стать графическим дизайнером или ваша цель изучить Photoshop?
Вы заинтересованы в продвижении своей карьеры в SEO, подняв свои навыки работы с данными на новый уровень, или вы хотите изучить Python?
В первые пять минут первой лекции по курсу компьютерных наук в Массачусетском технологическом институте профессор Гарольд Абельсон открывает курс, рассказывая студентам, почему «информатика» — такое дурное название для дисциплины, которую они собираются изучать. Думаю, очень интересно посмотреть первые пять минут лекции:
Когда какая-то область только зарождается, и ты не очень хорошо в ней разбираешься, очень легко спутать суть того, что ты делаешь, с инструментами, которые ты используешь. — Гарольд Абельсон
Мы пытаемся улучшить наше присутствие в Интернете и результаты, и многое из того, что мы делаем, основано на понимании, визуализации, манипулировании и обработке данных в целом, и это наша цель, независимо от используемого инструмента. Наука о данных — это область, в которой есть интеллектуальные основы для этого, а также множество инструментов для реализации того, что мы хотим сделать. Python может быть вашим предпочтительным языком (инструментом) программирования, и, безусловно, важно хорошо его изучить. Не менее важно, если не важнее, сосредоточиться на «сути того, что вы делаете», в нашем случае на обработке и анализе данных.
Основное внимание должно быть сосредоточено на рассмотренных выше процессах (импорт, очистка, визуализация и т. д.), а не на выбранном языке программирования. Или лучше, как использовать этот язык программирования для решения ваших задач, а не просто изучать язык программирования.
Кого волнуют все эти теоретические различия, если я все равно собираюсь изучать Python?
Давайте посмотрим, что может произойти, если вы сосредоточитесь на изучении инструмента, а не на сути того, что вы делаете. Здесь мы сравниваем поиск «изучить WordPress» (инструмент) и «изучить блог» (то, чем мы хотим заниматься):
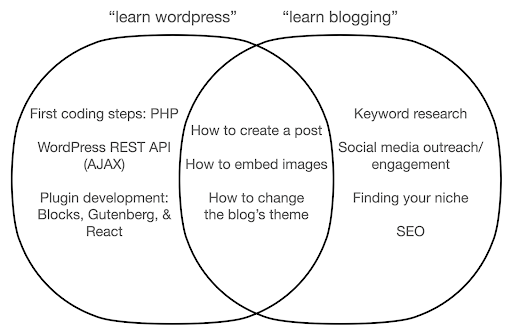
На диаграмме показаны возможные темы книги или курса, в которых рассказывается о ключевом слове вверху. Область пересечения в середине показывает темы, которые могут встречаться в обоих типах курсов/книг.
Если вы сосредоточитесь на инструменте, вам, несомненно, придется узнать о вещах, которые вам на самом деле не нужны, особенно новичку. Эти темы могут сбить вас с толку и разочаровать, особенно если у вас нет технического образования или опыта программирования.
Вы также узнаете вещи, которые помогут стать хорошим блоггером (темы в области пересечения). Этим темам чрезвычайно легко научить (как создать сообщение в блоге), но они не говорят вам много о том, почему вы должны вести блог, когда и о чем. Это не ошибка книги, ориентированной на инструменты, потому что при изучении инструмента было бы достаточно научиться создавать сообщение в блоге и двигаться дальше.
Как блогер, вы, вероятно, больше заинтересованы в том, что и почему блоги, и это не было бы освещено в книгах, ориентированных на инструменты.
Очевидно, что стратегические и важные вещи, такие как SEO, поиск своей ниши и т. д., не будут охвачены, поэтому вы упустите очень важные вещи.
О каких темах Data Science вы, вероятно, не узнаете из книги по программированию?
Как мы видели, выбор Python или книги по программированию, вероятно, означает, что вы хотите стать инженером-программистом. Темы, естественно, будут ориентированы на эту цель. Если вы ищете книгу по науке о данных, вы получите темы и инструменты, более ориентированные на анализ данных.
Мы можем использовать первую диаграмму (показывающую цикл науки о данных) в качестве руководства и активно искать эти темы: «импорт данных с помощью python», «аккуратные данные с помощью r», «визуализация данных с помощью python» и так далее. Давайте более подробно рассмотрим эти темы и изучим их подробнее:
импорт
Нам, естественно, нужно сначала получить некоторые данные. Это может быть:
- Файл на нашем компьютере: самый простой случай, когда вы просто открываете файл с помощью выбранного вами языка программирования. Важно отметить, что существует множество различных форматов файлов и что у вас есть много вариантов при открытии/чтении файлов. Например, функция read_csv из библиотеки pandas (основной инструмент для обработки данных в Python) имеет пятьдесят опций на выбор при открытии файла. Он содержит такие вещи, как путь к файлу, столбцы для выбора, количество строк для открытия, интерпретация объектов даты и времени, как работать с пропущенными значениями и многое другое. Важно быть знакомым с этими параметрами и различными соображениями при открытии файлов разных форматов. Кроме того, pandas имеет девятнадцать различных функций, которые начинаются с read_ для различных форматов файлов и данных.
- Экспорт из онлайн-инструмента: вы, вероятно, знакомы с этим, и здесь вы можете настроить свои данные, а затем экспортировать их, после чего вы откроете их в виде файла на своем компьютере.
- Вызовы API для получения конкретных данных: это более низкий уровень и ближе к подходу фермы, упомянутому выше. В этом случае вы отправляете запрос с конкретными требованиями и получаете обратно нужные вам данные. Преимущество здесь в том, что вы можете настроить именно то, что хотите получить, и отформатировать его способами, которые могут быть недоступны в онлайн-интерфейсе. Например, в Google Analytics вы можете добавить дополнительное измерение к анализируемой таблице, но не можете добавить третье. Вы также ограничены количеством строк, которые вы можете экспортировать. API дает вам больше гибкости, а также вы можете автоматизировать определенные вызовы, которые будут происходить периодически, как часть более крупного конвейера сбора/анализа данных.
- Сканирование и парсинг данных: у вас, вероятно, есть любимый поисковый робот, и вы, вероятно, знакомы с этим процессом. Это уже гибкий процесс, позволяющий нам извлекать пользовательские элементы со страниц, сканировать только определенные страницы и так далее.
- Комбинация методов, включающих автоматизацию, выборочное извлечение и, возможно, машинное обучение для специальных целей.
Когда у нас есть некоторые данные, мы хотим перейти на следующий уровень.
Аккуратный
«Аккуратный» набор данных — это набор данных, организованный определенным образом. Их также называют данными «длинного формата». Если вам интересно, в главе 12 книги R for Data Science концепция аккуратных данных обсуждается более подробно.
Взгляните на три таблицы ниже и попытайтесь найти различия:
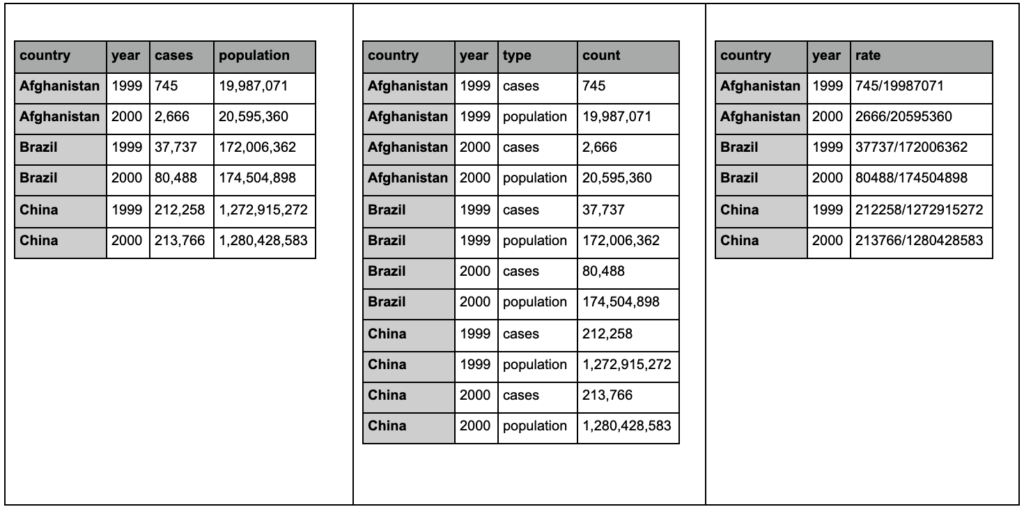
Примеры таблиц из пакета tidyr.
Вы обнаружите, что три таблицы содержат одну и ту же информацию, но организованную и представленную по-разному. У нас могут быть случаи и популяция в двух отдельных столбцах (таблица 1) или столбец, сообщающий нам, что представляет собой наблюдение (случаи или популяция), и столбец «подсчет» для подсчета этих случаев (таблица 2). В таблице 3 они показаны в виде ставок.
При работе с данными вы обнаружите, что разные источники упорядочивают данные по-разному, и что вам часто нужно будет менять определенные форматы для лучшего и более легкого анализа. Знание этих операций очистки имеет решающее значение, и пакет tidyr в R содержит специальные инструменты для этого. Вы также можете использовать панд, если предпочитаете Python, и вы можете проверить для этого функции плавления и поворота.
Как только наши данные находятся в определенном формате, мы можем захотеть продолжить манипулировать ими.
Трансформировать
Еще один важный навык, который необходимо развить, — это способность вносить любые изменения в данные, с которыми вы работаете. Идеальный сценарий — достичь стадии, когда вы можете вести беседы со своими данными и иметь возможность нарезать и нарезать кубики любым способом, которым вы хотите задать очень конкретные вопросы, и, надеюсь, получить интересные идеи. Вот некоторые из наиболее важных задач преобразования, которые вам, вероятно, часто понадобятся, с некоторыми примерами задач, которые могут вас заинтересовать:
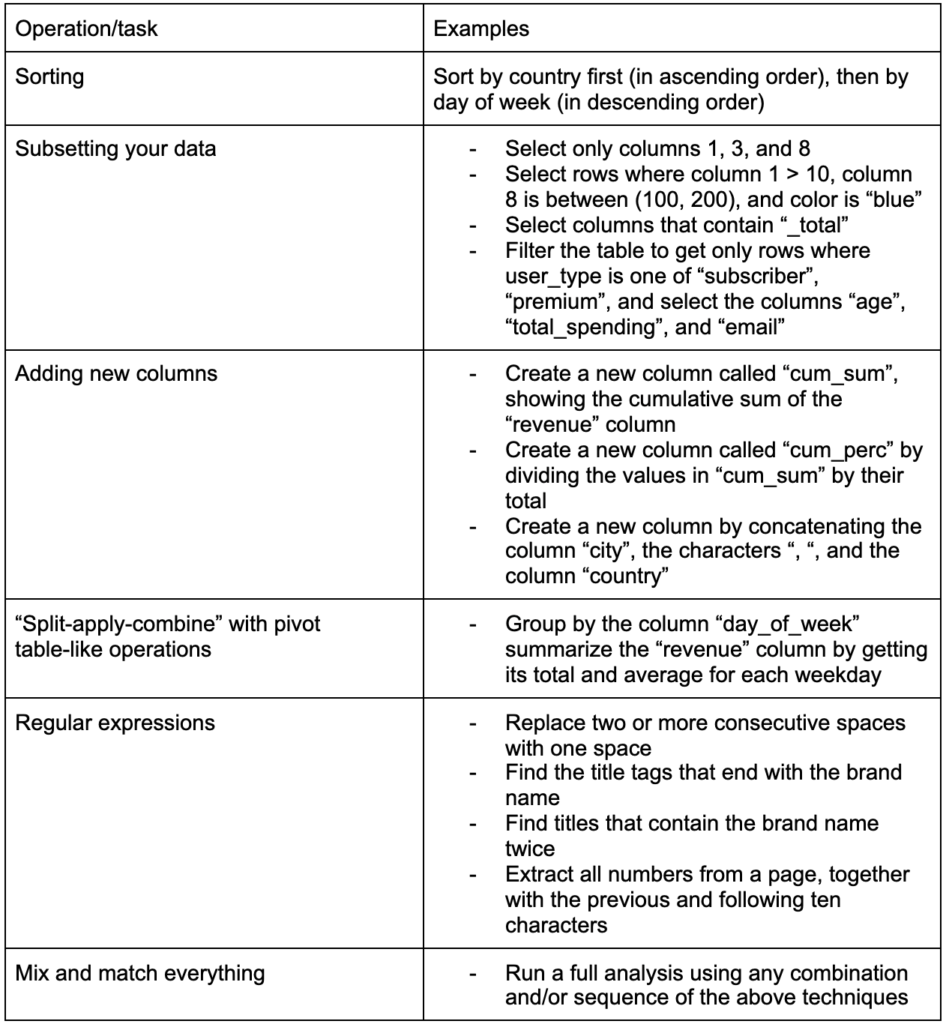
Получив, приведя в порядок и приведя наши данные в нужный формат, хорошо бы их визуализировать.
визуализировать
Визуализация данных — обширная тема, и по некоторым ее подтемам написаны целые книги. Это одна из тех вещей, которые могут дать много информации о наших данных, особенно то, что она использует интуитивно понятные визуальные элементы для передачи информации. Например, относительная высота баров на гистограмме сразу показывает нам их относительное количество. Интенсивность цвета, относительное расположение и многие другие визуальные атрибуты легко узнаваемы и понятны читателям.
Хорошая диаграмма стоит тысячи (ключевых) слов!
Поскольку существует множество тем, связанных с визуализацией данных, я просто поделюсь несколькими примерами, которые могут быть интересны. Некоторые из них являются строительными блоками для этой информационной панели данных о бедности, если вы хотите получить полную информацию.
Иногда для сравнения значений может потребоваться простая гистограмма, где столбцы могут отображаться вертикально или горизонтально:
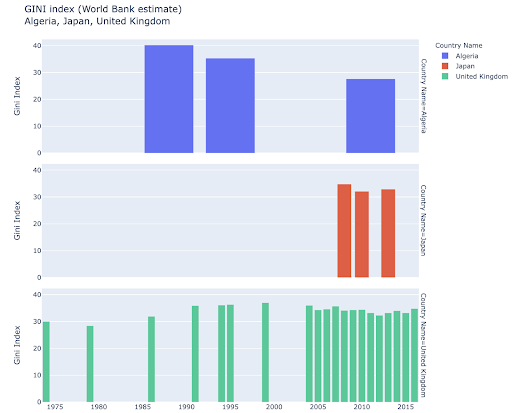
Возможно, вам будет интересно изучить некоторые страны и копнуть глубже, увидев, как они продвинулись по определенным показателям. В этом случае вы можете захотеть отобразить несколько гистограмм на одном графике:
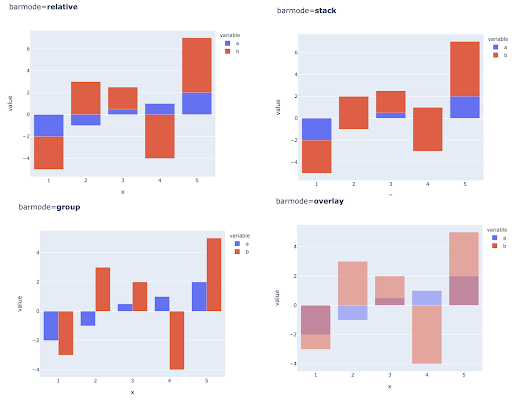
Сравнение нескольких значений для нескольких наблюдений также можно выполнить, поместив несколько столбцов в каждую позицию по оси X, вот основные способы сделать это:
Выбор цвета и цветовых шкал: неотъемлемая часть визуализации данных и то, что может чрезвычайно эффективно и интуитивно передавать информацию, если все сделано правильно.
Категориальные цветовые шкалы: полезны для выражения категорийных данных. Как следует из названия, это тип данных, который показывает, к какой категории относится определенное наблюдение. В этом случае мы хотим, чтобы цвета, которые максимально отличаются друг от друга, показывали четкие различия в категориях (особенно для визуальных элементов, которые отображаются рядом друг с другом).
В следующем примере используется категориальная цветовая шкала, чтобы показать, какая система правления реализована в каждой стране. Довольно легко связать цвета стран с легендой, показывающей, какая система правления используется. Это также называется картограммой:
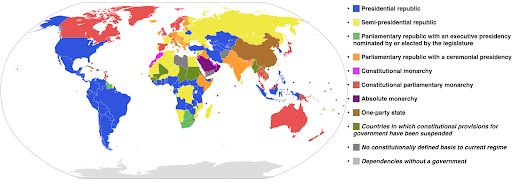
Источник: Википедия
Иногда данные, которые мы хотим визуализировать, относятся к одной и той же метрике, и каждая страна (или любой другой тип наблюдения) попадает в определенную точку в континууме, находящемся между минимальной и максимальной точками. Другими словами, мы хотим визуализировать степени этой метрики.
В этих случаях нам нужно найти непрерывную (или последовательную) цветовую шкалу . В следующем примере сразу видно, какие страны более синие (и, следовательно, получают больше трафика), и мы можем интуитивно понять нюансы различий между странами.
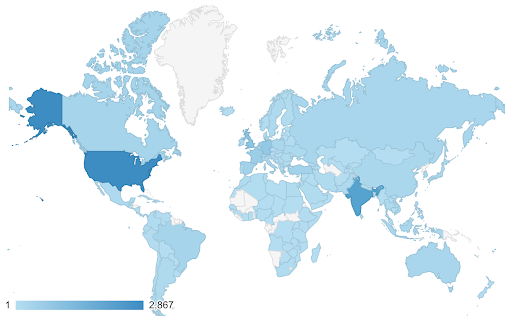
Ваши данные могут быть непрерывными (как в приведенной выше диаграмме карты трафика), но важным моментом в числах может быть то, насколько они отличаются от определенной точки. В этом случае полезны расходящиеся цветовые шкалы .
На приведенной ниже диаграмме показаны чистые темпы прироста населения. В этом случае интересно сначала узнать, имеет ли определенная страна положительный или отрицательный темп роста. Или мы хотим знать, насколько далеко каждая страна от нуля (и насколько). Взглянув на карту, мы сразу видим, в каких странах население растет, а в каких сокращается. Легенда также показывает нам, что максимальная положительная ставка составляет 3,5%, а максимальная отрицательная — -0,5%. Это также дает нам указание на диапазон значений (положительных и отрицательных).

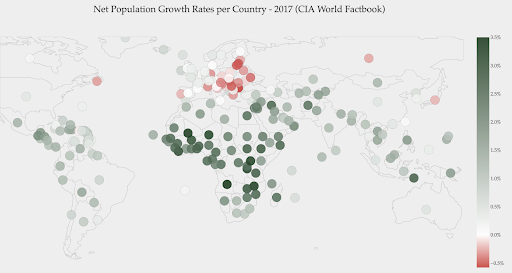
Источник: Dashboardom.com
К сожалению, цвета, выбранные для этой шкалы, не идеальны, поскольку дальтоники могут не различать красный и зеленый цвета должным образом. Это очень важное соображение при выборе наших цветовых шкал.
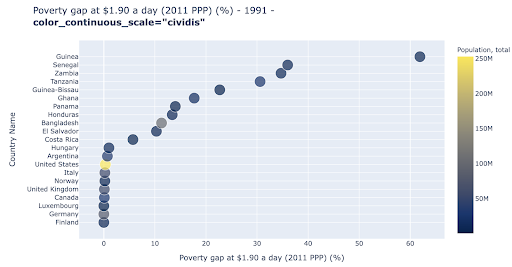
Точечная диаграмма является одним из наиболее широко используемых и универсальных типов графиков. Положение точек (или любого другого маркера) передает количество, которое мы пытаемся передать. В дополнение к положению мы можем использовать несколько других визуальных атрибутов, таких как цвет, размер и форма, чтобы передавать еще больше информации. В следующем примере показан процент населения, живущего на 1,9 долл. США в день, что мы можем ясно увидеть как горизонтальное расстояние точек.
Мы также можем добавить новое измерение в нашу диаграмму, используя цвет. Это соответствует визуализации третьего столбца из того же набора данных, который в данном случае показывает данные о населении.
Теперь мы можем видеть, что самый крайний случай с точки зрения населения (США) очень низок по показателю уровня бедности. Это добавляет богатства нашим графикам. Мы могли бы также использовать размер и форму, чтобы визуализировать еще больше столбцов из нашего набора данных. Однако нам нужно найти хороший баланс между богатством и удобочитаемостью.
Нам может быть интересно проверить, существует ли связь между населением и уровнем бедности, поэтому мы можем визуализировать тот же набор данных немного по-другому, чтобы увидеть, существует ли такая связь:
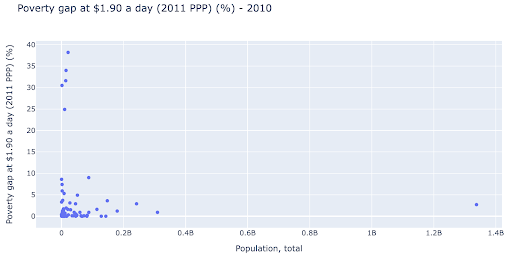
У нас есть одно значение выброса в популяции около 1,35 млрд, и это означает, что у нас много пробелов на диаграмме, что также означает, что многие значения втиснуты в очень маленькую область. У нас также есть много перекрывающихся точек, что очень затрудняет выявление каких-либо различий или тенденций.
Следующая диаграмма содержит ту же информацию, но по-разному визуализирована с использованием двух методов:
- Логарифмическая шкала : обычно мы видим данные в аддитивной шкале. Другими словами, каждая точка на оси (X или Y) представляет собой добавление определенного количества визуализируемых данных. У нас также могут быть мультипликативные шкалы, и в этом случае для каждой новой точки на оси X мы умножаем (на десять в этом примере). Это позволяет разбросать точки, и нам нужно думать о множителях, а не о добавлениях, как мы делали это на предыдущем графике.
- Использование другого маркера (большие пустые круги) : выбор другой формы для наших маркеров решил проблему «перерисовки», когда у нас может быть несколько точек друг над другом в одном и том же месте, что делает их очень трудными даже для просмотра. сколько у нас очков.
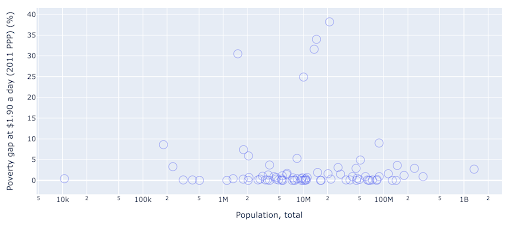
Теперь мы можем видеть, что вокруг отметки 10 миллионов есть группа стран, а также другие более мелкие группы.
Как я уже упоминал, существует гораздо больше типов символов и вариантов визуализации, и на эту тему написаны целые книги. Я надеюсь, что это даст вам несколько интересных идей для экспериментов.
Данные при сканировании³
 Учить больше
Учить большеМодель
Нам нужно упростить наши данные и найти закономерности, сделать прогнозы или просто лучше понять их. Это еще одна большая тема, и она может варьироваться от простого получения некоторой сводной статистики (среднее значение, медиана, стандартное отклонение и т. д.) до визуального моделирования наших данных с использованием модели, которая суммирует или находит тренд, до использования более сложных методов для получения математическая формула для наших данных. Мы также можем использовать машинное обучение, чтобы получить больше информации из наших данных.
Опять же, это не полное обсуждение темы, но я хотел бы поделиться парой примеров, в которых вы можете использовать некоторые методы машинного обучения, чтобы помочь вам.
В наборе данных сканирования я пытался узнать немного больше о страницах 404 и узнать, смогу ли я что-то о них узнать. Моей первой попыткой было проверить, есть ли корреляция между размером страницы и ее кодом состояния, и она была — почти идеальная корреляция!
Я почувствовал себя гением на несколько минут и быстро вернулся на планету Земля.
Все страницы 404 находились в очень узком диапазоне размеров страниц, так что почти все страницы с определенным количеством килобайт имели код состояния 404. Затем я понял, что страницы 404 по определению не содержат никакого контента, кроме «страницы с ошибкой 404»! И именно поэтому они были одинакового размера.
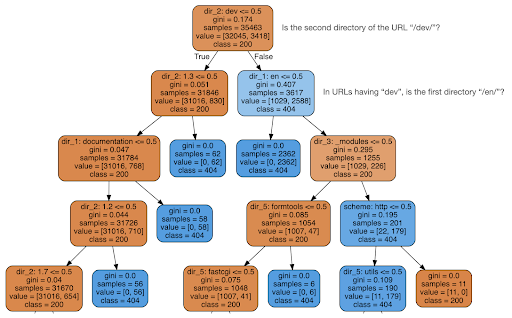
Затем я решил проверить, может ли контент рассказать мне что-нибудь о коде состояния, поэтому я разделил URL-адреса на их элементы и запустил классификатор дерева решений с помощью sklearn. По сути, это метод, который создает дерево решений, где следование его правилам может привести нас к обучению тому, как найти нашу цель, в данном случае 404 страницы.
В следующем дереве решений первая строка в каждом поле показывает правило, которому нужно следовать или проверять, строка «выборки» — это количество наблюдений, найденных в этом поле, а строка «класс» сообщает нам класс текущего наблюдения. , в данном случае независимо от того, является ли его код состояния 200 или 404.
Я не буду вдаваться в подробности, и я знаю, что дерево решений может быть неясным, если вы не знакомы с ним, и вы можете изучить необработанный набор данных сканирования и код анализа, если вам это интересно.
В основном то, что обнаружило дерево решений, заключалось в том, как найти почти все страницы 404, используя структуру каталогов URL-адресов. Как видите, мы нашли 3617 URL-адресов, просто проверив, был ли второй каталог URL-адреса «/dev/» (первое голубое поле во второй строке сверху). Итак, теперь мы знаем, как найти наши ошибки 404, и кажется, что почти все они находятся в разделе «/dev/» сайта. Это определенно здорово сэкономило время. Представьте, что вы вручную перебираете все возможные структуры и комбинации URL, чтобы найти это правило.
У нас все еще нет полной картины и того, почему это происходит, и это можно продолжить, но, по крайней мере, теперь мы очень легко нашли эти URL-адреса.
Другой метод, который может вас заинтересовать, — это кластеризация KMeans, которая группирует точки данных в различные группы/кластеры. Это метод «обучения без учителя», когда алгоритм помогает нам обнаруживать закономерности, о существовании которых мы не знали.
Представьте, что у вас есть куча чисел, скажем, население стран, и вы хотите сгруппировать их в две группы, большие и маленькие. Как бы Вы это сделали? Где бы вы провели линию?
Это отличается от получения первых десяти стран или первых X% стран. Это было бы очень просто, мы можем отсортировать страны по населению и получить X лучших, как мы хотим.
Мы хотим сгруппировать их как «большие» и «маленькие» по отношению к этому набору данных, предполагая, что мы ничего не знаем о населении страны.
Это может быть расширено до попытки сгруппировать страны в три категории: малые, средние и большие. Это становится намного сложнее сделать вручную, если мы хотим пять, шесть или больше групп.
Обратите внимание, что мы не знаем, сколько стран попадет в каждую группу, так как мы не запрашиваем первые X стран. Объединив их в два кластера, мы видим, что в большой группе у нас всего две страны: Китай и Индия. Это имеет интуитивно понятный смысл, так как среднее население этих двух стран очень далеко от всех других стран. Эта группа стран имеет свое среднее значение, и ее страны ближе друг к другу, чем страны другой группы:
Страны, сгруппированные в две группы по численности населения 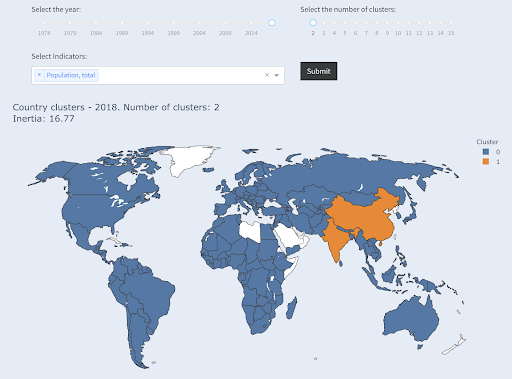
Третья по численности населения страна (США ~330 млн) была сгруппирована со всеми остальными, включая страны с миллионным населением. Это потому, что 330 миллионов гораздо ближе к 1 миллиону, чем 1,3 миллиарда. Если бы мы запросили три кластера, то получили бы другую картину:
Страны, сгруппированные в три группы по численности населения 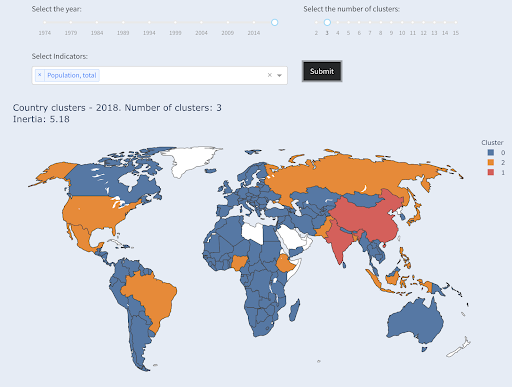
И вот как страны будут сгруппированы, если мы запросим четыре кластера:
Страны, сгруппированные в четыре группы по численности населения 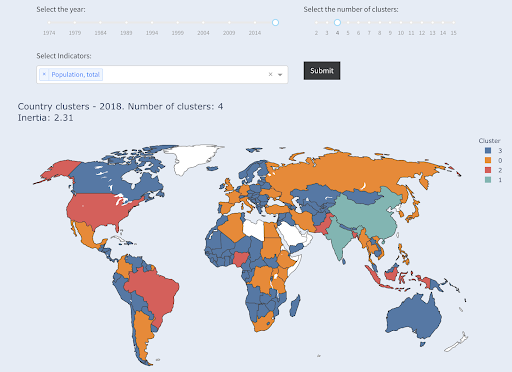
Источник: бедность.org (вкладка «Страны кластера»).
В данном случае это была кластеризация с использованием только одного измерения — населения, и вы также можете добавить больше измерений и посмотреть, где в конечном итоге оказываются страны.
Есть много других техник и инструментов, и это лишь пара примеров, которые, надеюсь, будут интересными и практичными.
Теперь мы готовы сообщить о наших выводах нашей аудитории.
Общаться
После всей работы, которую мы проделали на предыдущих этапах, нам нужно в конечном итоге сообщить о наших выводах другим заинтересованным сторонам проекта.
Одним из наиболее важных инструментов в науке о данных является интерактивный блокнот. Блокнот Jupyter является наиболее широко используемым и поддерживает практически все языки программирования, и вы можете предпочесть использовать специальный формат блокнота RStudio, который работает таким же образом.
Основная идея состоит в том, чтобы хранить данные, код, повествование и визуализации в одном месте, чтобы другие люди могли их проверять. Важно показать, как вы пришли к этим выводам и рекомендациям в отношении прозрачности и воспроизводимости. Другие люди должны иметь возможность запускать тот же код и получать такие же результаты.
Другой важной причиной является возможность для других, в том числе для «будущих вас», продолжить анализ и опираться на проделанную вами первоначальную работу, улучшать ее и расширять по-новому.
Конечно, это предполагает, что аудитории комфортно работать с кодом и что он им вообще небезразличен!
У вас также есть возможность экспортировать свои записные книжки в HTML (и несколько других форматов), исключая код, так что вы получите удобный отчет, но при этом сохраните полный код для воспроизведения того же анализа и результатов.
Важным элементом коммуникации является визуализация данных, о которой также было кратко рассказано выше.
Еще лучше интерактивная визуализация данных, и в этом случае вы позволяете своей аудитории выбирать значения и проверять различные комбинации диаграмм и показателей для дальнейшего изучения данных.
Вот несколько информационных панелей и приложений для работы с данными (загрузка некоторых из них может занять несколько секунд), которые я создал, чтобы дать вам некоторое представление о том, что можно сделать.
В конце концов, вы также можете создавать собственные приложения для своих проектов, чтобы удовлетворить особые потребности и требования, и вот еще один набор приложений для SEO и маркетинга, которые могут вас заинтересовать.
Мы прошли основные этапы цикла Data Science, а теперь давайте рассмотрим еще одно преимущество «изучения Python».
Python для автоматизации и производительности: верно, но неполно
Мне кажется, существует убеждение, что изучение Python нужно в основном для повышения производительности и/или автоматизации задач.
Это абсолютно верно, и я не думаю, что нам нужно даже обсуждать ценность возможности сделать что-то за долю времени, которое потребовалось бы нам, чтобы сделать это вручную.
Другой недостающей частью аргумента является анализ данных . Хороший анализ данных дает нам понимание, и в идеале мы можем предоставить действенную информацию, чтобы направлять наш процесс принятия решений, основываясь на нашем опыте и данных, которые у нас есть.
Большая часть того, что мы делаем, — это попытка понять, что происходит, проанализировать конкуренцию, выяснить, где самый ценный контент, решить, что делать и так далее. Мы консультанты, советники и лица, принимающие решения. Возможность получить некоторую информацию из наших данных, безусловно, является большим преимуществом, и области и навыки, упомянутые здесь, могут помочь нам в этом.
Что, если вы узнаете, что ваши теги заголовков имеют среднюю длину в шестьдесят символов, хорошо ли это?
Что, если вы копнете немного глубже и обнаружите, что в половине ваших заголовков намного меньше шестидесяти, а в другой половине гораздо больше символов (в среднем шестьдесят)? In order to get practical and provide good recommendations, you need a higher-resolution view of your title tags' lengths, probably a histogram that shows the frequency of your title tag lengths at each interval so you can have a separate strategy for length. A simple table would also do, for example:
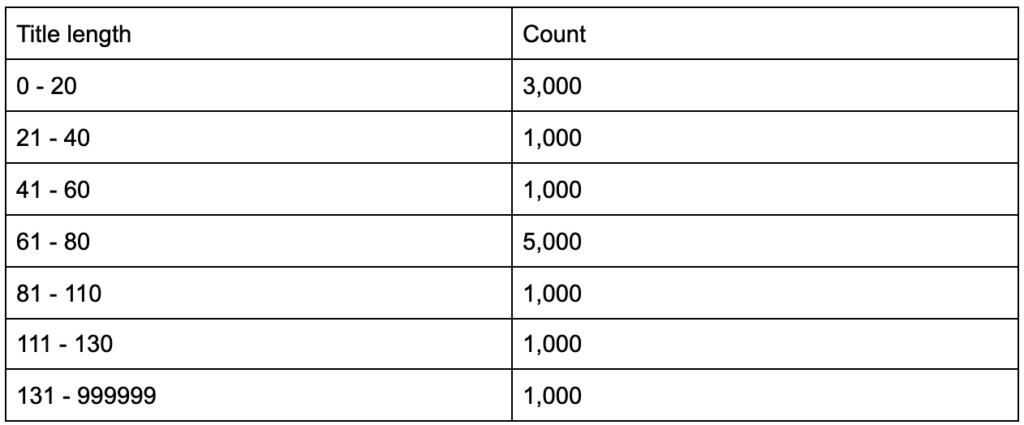
Splitting title lengths by intervals of twenty was an arbitrary decision, and you can split them the way you want. Looking at the table above, and seeing that we have three times more than the average titles in the interval (0, 20), we might want to split it further to better understand what is going on.
Having a better view than the default single-statistic summaries that we get from standard tools, allows us to employ different strategies for different lengths. For example, we can remove the brand name from the titles that are longer than a certain number of characters, and keep it in other titles.
This was an example of very simple insights, which are possible due to the flexibility we get by using a programming language, and a set of data science tools. This also allows us to iterate and modify our approach, until we find a satisfactory point that can take our analysis to the next steps.
Visualization, machine learning, modeling and general data manipulation skills allow us to get better insights on our data, even though those analyses are typically done only once. Still, if you use code to get those insights, you can always take some parts and apply to other projects, or again to the same project. In this case, the insights we got, helped us in our automation, even more. The insights would tell us what needs to be automated and what doesn't.
Should you learn Python?
Is a useless question, and the more useful one is, “How much Python (or R) should you learn?”
My view of how we use computers has evolved in the last few years.
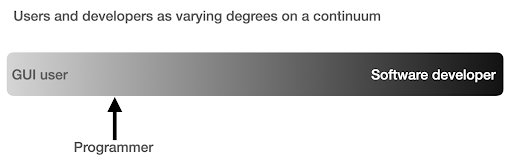
I used to think that there were two main ways of using computers, either you are a regular user, using “point-and-click” applications to do certain tasks, or you are a developer who creates those applications that the rest of us use.

I then realized that it is more like a continuum between very high level use (pizza ordering approach), and the lower levels of the farm approach. I also realized that there is a happy sweet spot in between, where you learn enough programming to get productive and boost your data analysis skills, without having to become a software developer or engineer.
What are the main differences between being a programmer (a software user), and a software developer (or engineer)?
What are the differences between making a great coffee at home, versus establishing and running a cafe?
If making good coffee is one skill, then running a cafe requires ten other skills, most of which have nothing to do with making coffee.
You have to choose a good location (real estate), hire people (management and HR), manage cash flow and finances (accounting and finance), do marketing, legal, manage delivery, adhere to cleanliness and health standards, and so on. You can be a great coffee maker without knowing anything about those fields, but if you want to take it to the next level, you will have to manage all those additional tasks unrelated to making coffee.
The same applies to being a good programmer or data analyst versus being a software developer/engineer. There are so many other things that you have to know and worry about that you don't need as a regular programmer doing stuff for yourself and co-workers and clients. Once you have enough knowledge and skills in programming and data science, you will be in a good position to choose and decide whether you want to continue as an analyst, focusing on data science, or if you want to end up creating software that other people would use.
How do I get into Data Science?
To learn anything I think you have to do two things in parallel:
- Learn the fundamentals and the theory properly: Taking courses and reading books, and getting into the fundamentals can push you forward, as you will be gaining in weeks, knowledge that took decades to establish. It would also immediately give you ideas on things you thought were impossible, or had no idea existed.
- Get as much real world exposure and experience as possible: Experience is always important, and my suggestion is to try as soon as you can to read_csv with Python or R, to actually do so with your GA, GSC, or crawl dataset. See what else you can do (visualize, manipulate, model, etc.). See if you get errors, try to analyze the data only using your programming language.
What does frustration look like, and by when will I get productive?
It's difficult to say, and it depends on your skill, background, the hours you put in, but visualizing it like this might help you on those frustrating unproductive days:
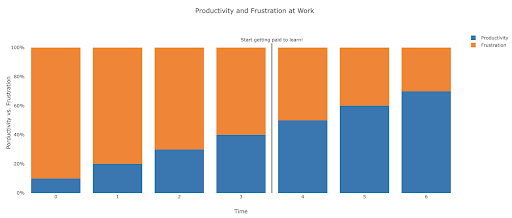
My suggestion is to take a non-trivial task, for example running an SEO audit for a site, only using Python. Your first session will mostly be frustrating, and most of the time will be spent checking documentation, and the definition of basic terms.
In parallel, you are still going through your course, and learning new stuff.
The value of that frustrating session is that it informs and motivates your theoretical learning. You will have questions in mind, and when you learn new things, you will immediately have a place to implement them.
Your next analysis session will probably be a little more productive, but still not productive enough to do at work. You go again to your learning and theory.
Do this enough times, and your time will become mostly productive, eventually you will be doing real work during working hours. The ideal scenario is where you are productive enough to do work, but every time use some time to research better techniques, which improves your work as well. By then you will start to get paid for learning, and your clients will be happily sponsoring you!
Suggested next steps
For the learning path a Data Science course would be great, especially if you get feedback on your work, and you can follow the topics in the order recommended.
If you go with Python I suggest the following libraries:
- pandas: The workhorse of all your tasks in preparing, cleaning, reshaping data whichever way you want. Fluency in pandas allows you to have full control over your data, which will help you immensely in visualization, general analysis, and machine learning
- Plotly and Dash: This is my favorite data visualization library, although there are many others. What I mostly like about it, is that it produces interactive and responsive HTML charts by default. It is very detailed and thorough in its options, yet simple to use. Plotly also includes Plotly Express, which is a high-level plotting tool, which is more intuitive to use, and takes a data-oriented approach (as opposed to a chart-oriented approach). Plotly also created Dash, which is the tool for creating interactive dashboards, but also serves as a full front-end web development framework. Other important data visualization libraries are matplotlib, altair, and bokeh, and for interactive data apps, there is panel and streamlit. Another important feature is that Plotly and Dash are available in all languages used in Data Science. You might use other libraries, and this is just my personal preference. Speaking of personal preferences:
- advertools: This is a library that I created to provide various online marketing tools, most importantly, an SEO crawler, log file parser and compressor, multi robots.txt parser, recursive sitemap parser, SEM keyword and text ad generator for large scale campaigns, weighted frequency word counter, Google SERP downloader, YouTube data API, and a few other tools. It is still evolving, and you are more than welcome to contribute any suggestions, bugs, or issues you might have with it.
These should be enough for beginners, and when you are familiar with them, you can do your own research for more specialized libraries, machine learning and deep learning tools, or libraries that are specialized in performance, or a special niche use-case.