
علم البيانات لتحسين محركات البحث والتسويق الرقمي: دليل مقترح للمبتدئين
نشرت: 2021-12-07نظرًا لأن معظم عملنا يدور حول البيانات ، وبما أن مجال علوم البيانات أصبح أكبر بكثير وأكثر سهولة في الوصول للمبتدئين ، أود مشاركة بعض الأفكار حول كيفية دخولك في هذا المجال لزيادة تحسين محركات البحث والتسويق لديك المهارات بشكل عام.
ما هو علم البيانات؟
رسم تخطيطي معروف جيدًا يستخدم لإعطاء نظرة عامة على هذا المجال هو مخطط Venn لدرو كونواي الذي يوضح علم البيانات باعتباره تقاطع الإحصائيات والقرصنة (مهارات البرمجة المتقدمة بشكل عام ، وليس بالضرورة اختراق الشبكات والتسبب في ضرر) ، وموضوعي الخبرة أو "معرفة المجال":
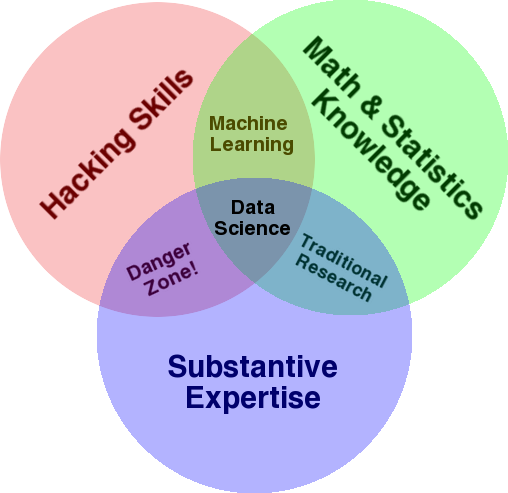
المصدر: oreilly.com
عندما بدأت التعلم ، أدركت بسرعة أن هذا هو بالضبط ما نقوم به بالفعل. الاختلاف الوحيد هو أنني كنت أقوم بذلك باستخدام أدوات أساسية ويدوية أكثر.
إذا نظرت إلى الرسم التخطيطي ، سترى بسهولة كيف ربما تفعل ذلك بالفعل. أنت تستخدم الكمبيوتر (مهارات القرصنة) ، لتحليل البيانات (الإحصائيات) ، لحل مشكلة عملية باستخدام خبرتك الموضوعية في تحسين محركات البحث (أو أي تخصص تركز عليه).
من المحتمل أن تكون "لغة البرمجة" الحالية الخاصة بك عبارة عن جدول بيانات (Excel أو Google Sheets ، وما إلى ذلك) ، ومن المرجح أنك تستخدم Powerpoint أو شيء مشابه لتوصيل الأفكار. دعونا نتوسع في هذه العناصر قليلاً.
- معرفة المجال: لنبدأ بقوتك الرئيسية ، كما تعلم بالفعل عن مجال خبرتك. ضع في اعتبارك أن هذا جزء أساسي من كونك عالم بيانات ، وهذا هو المكان الذي يمكنك فيه البناء على معرفتك وحمايتها. قبل بضعة أشهر ، كنت أناقش تحليل مجموعة بيانات الزحف مع صديق لي. وهو فيزيائي يقوم بأبحاث ما بعد الدكتوراه على أجهزة الكمبيوتر الكمومية. إن معرفته ومهاراته في الرياضيات والإحصاء تتجاوز بكثير ما لدي ، وهو يعرف حقًا كيفية تحليل البيانات بطريقة أفضل مني. مشكلة واحدة. لم يكن يعرف ما هو "404" (أو لماذا نهتم بـ "301"). لذلك ، مع كل معرفته بالرياضيات ، لم يكن قادرًا على فهم عمود "الحالة" في مجموعة بيانات الزحف. بطبيعة الحال ، لن يعرف ماذا يفعل بهذه البيانات ، ومن يتحدث إليه ، وما هي الاستراتيجيات التي يجب بناؤها بناءً على أكواد الحالة هذه (أو ما إذا كان سيبحث في مكان آخر). أنا وأنت نعرف ماذا نفعل معهم ، أو على الأقل نعرف أين نبحث إذا أردنا التعمق أكثر.
- الرياضيات والإحصاءات: إذا كنت تستخدم Excel للحصول على متوسط عينة من البيانات ، فأنت تستخدم الإحصائيات. المتوسط عبارة عن إحصائية تصف جانبًا معينًا من عينة البيانات. ستساعد الإحصائيات الأكثر تقدمًا في فهم بياناتك. هذا ضروري أيضًا ، ولست خبيرًا في هذا المجال. كلما زادت التوزيعات الإحصائية التي تعرفها ، زادت الأفكار التي لديك حول كيفية تحليل البيانات. كلما زادت الموضوعات الأساسية التي تعرفها ، كان من الأفضل لك صياغة فرضياتك ، والإدلاء ببيانات دقيقة حول مجموعات البيانات الخاصة بك.
- مهارات البرمجة: سأناقش هذا بمزيد من التفصيل أدناه ، ولكن هذا هو المكان الذي تبني فيه المرونة في إخبار الكمبيوتر أن يفعل بالضبط ما تريده أن يفعله ، بدلاً من أن يكون عالقًا مع سهولة الاستخدام ولكن مقيدة قليلاً أدوات. هذه هي طريقتك الرئيسية للحصول على بياناتك وإعادة تشكيلها وتنظيفها ، بالطريقة التي تريدها ، مما يمهد الطريق لك لإجراء "محادثات" مفتوحة ومرنة مع بياناتك.
دعنا الآن نلقي نظرة على ما نفعله عادة في علم البيانات.
دورة علم البيانات
عادةً ما يبدو مشروع علم البيانات أو حتى مهمة نموذجية شيئًا كالتالي:
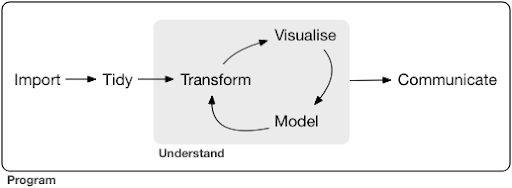
المصدر: r4ds.had.co.nz
أوصي بشدة بقراءة هذا الكتاب من تأليف هادلي ويكهام وجاريت جيروليموند والذي يعد بمثابة مقدمة رائعة لعلوم البيانات. تمت كتابته بأمثلة من لغة البرمجة R ، ولكن يمكن فهم المفاهيم والكود بسهولة إذا كنت تعرف Python فقط.
كما ترى في الرسم التخطيطي ، نحتاج أولاً إلى استيراد بياناتنا بطريقة ما ، وترتيبها ، ثم البدء في العمل على الدورة الداخلية للتحويل ، والتصور ، والنموذج. بعد ذلك نقوم بتوصيل النتائج مع الآخرين.
يمكن أن تتراوح هذه الخطوات من بسيطة للغاية إلى معقدة للغاية. على سبيل المثال ، قد تكون خطوة "الاستيراد" بسيطة مثل قراءة ملف CSV ، وفي بعض الحالات قد تتكون من مشروع تجريف ويب معقد للغاية للحصول على البيانات. العديد من عناصر العملية عبارة عن تخصصات كاملة في حد ذاتها.
يمكننا بسهولة ربط هذا ببعض العمليات المألوفة التي نعرفها. على سبيل المثال ، قد تبدأ بالحصول على بعض البيانات الوصفية حول موقع ويب ، عن طريق تنزيل ملف (ملفات) ملف robots.txt و XML الخاص به. من المحتمل أن تقوم بالزحف بعد ذلك وربما تحصل أيضًا على بعض البيانات حول مواقع SERP ، أو بيانات الارتباط على سبيل المثال. الآن بعد أن أصبح لديك عدد قليل من مجموعات البيانات ، ربما ترغب في دمج بعض الجداول وإسناد بعض البيانات الإضافية والبدء في الاستكشاف / الفهم. يمكن أن يؤدي تصور البيانات إلى كشف الأنماط المخفية ، أو مساعدتك في معرفة ما يجري ، أو ربما يثير المزيد من الأسئلة. ربما ترغب أيضًا في تصميم بياناتك باستخدام بعض الإحصائيات الأساسية ، أو نماذج التعلم الآلي ، ونأمل أن تحصل على بعض الأفكار. بالطبع ، أنت بحاجة إلى توصيل النتائج والأسئلة إلى أصحاب المصلحة الآخرين في المشروع.
بمجرد أن تصبح على دراية كافية بالأدوات المختلفة المتاحة لكل من هذه العمليات ، يمكنك البدء في إنشاء خطوط الأنابيب المخصصة الخاصة بك والمخصصة لموقع ويب معين ، لأن كل عمل فريد من نوعه ، وله مجموعة خاصة من المتطلبات. في النهاية ، ستبدأ في العثور على أنماط ولن تضطر إلى إعادة العمل بأكمله لمشاريع / مواقع ويب مماثلة.
هناك العديد من الأدوات والمكتبات المتاحة لكل عنصر في هذه العملية ويمكن أن تكون مربكة للغاية ، ما الأداة التي تختارها (وتستثمر وقتك في التعلم). دعنا نلقي نظرة على النهج المحتمل الذي أجده مفيدًا في اختيار الأدوات التي أستخدمها.
اختيار الأدوات والمفاضلات (3 طرق للحصول على البيتزا)
هل يجب أن تستخدم برنامج Excel في عملك اليومي في معالجة البيانات ، أم أن تعلم لغة Python يستحق العناء؟
هل من الأفضل أن تتخيل شيئًا مثل Power BI ، أم يجب أن تستثمر في تعلم القواعد النحوية للرسومات ، وتعلم كيفية استخدام المكتبات التي تنفذها؟
هل ستنتج عملًا أفضل من خلال إنشاء لوحات معلومات تفاعلية خاصة بك باستخدام R أو Python ، أم يجب عليك فقط استخدام Google Data Studio؟
دعنا أولاً نستكشف المفاضلات التي ينطوي عليها اختيار الأدوات المختلفة على مستويات مختلفة من التجريد. هذا مقتطف من كتابي حول إنشاء لوحات معلومات تفاعلية وتطبيقات بيانات باستخدام Plotly و Dash وأجد أن هذا الأسلوب مفيد:
ضع في اعتبارك ثلاث طرق مختلفة لتناول البيتزا:
- نهج الطلب: تتصل بمطعم وتطلب البيتزا الخاصة بك. تصل إلى عتبة داركم خلال نصف ساعة ، وتبدأ في الأكل.
- نهج السوبر ماركت: تذهب إلى السوبر ماركت وتشتري العجين والجبن والخضروات وجميع المكونات الأخرى. ثم تقوم بعمل البيتزا بنفسك.
- نهج المزرعة: أنت تزرع الطماطم في الفناء الخلفي الخاص بك. أنت تربي أبقارًا وتحلبها وتحول اللبن إلى جبن ، وهكذا.
عندما نرتقي إلى واجهات ذات مستوى أعلى ، نحو نهج الترتيب ، تقل كمية المعرفة المطلوبة كثيرًا. شخص آخر يتحمل المسؤولية ، ويتم فحص الجودة من قبل قوى السوق للسمعة والمنافسة.
الثمن الذي ندفعه مقابل ذلك هو تضاؤل الحرية والخيارات. يحتوي كل مطعم على مجموعة من الخيارات للاختيار من بينها ، وعليك الاختيار من بين تلك الخيارات.
بالانتقال إلى المستويات الأدنى ، يزداد مقدار المعرفة المطلوبة ، وعلينا التعامل مع المزيد من التعقيد ، ونتحمل المزيد من المسؤولية عن النتائج ، ويستغرق الأمر وقتًا أطول بكثير. ما نكتسبه هنا هو المزيد من الحرية والقوة لتخصيص نتائجنا بالطريقة التي نريدها. التكلفة هي أيضا فائدة كبيرة ، ولكن فقط على نطاق واسع بما فيه الكفاية. إذا كنت ترغب في الحصول على بيتزا اليوم فقط ، فمن المحتمل أن يكون طلبها أرخص. ولكن إذا كنت تخطط للحصول على واحدة كل يوم ، فيمكنك توقع توفير كبير في التكلفة إذا قمت بذلك بنفسك.
هذه هي أنواع الخيارات التي سيتعين عليك اتخاذها عند اختيار الأدوات التي تريد استخدامها وتعلمها. يتطلب استخدام لغة برمجة مثل R أو Python مزيدًا من العمل ، وهو أكثر صعوبة من Excel ، مع ميزة جعلك أكثر إنتاجية وقوة.
الاختيار مهم أيضًا لكل أداة أو عملية. على سبيل المثال ، قد تستخدم زاحفًا عالي المستوى وسهل الاستخدام لجمع البيانات حول موقع ويب ، ومع ذلك قد تفضل استخدام لغة برمجة لتصور البيانات ، مع جميع الخيارات المتاحة. يعتمد اختيار الأداة المناسبة للعملية الصحيحة على احتياجاتك ، ونأمل أن تساعد المقايضة الموضحة أعلاه في اتخاذ هذا الاختيار. من المأمول أن يساعد هذا أيضًا في معالجة مسألة ما إذا كنت تريد تعلم Python أو R أم لا (أو إلى أي مدى).
دعنا نأخذ هذا السؤال إلى أبعد من ذلك ونرى لماذا قد لا يكون تعلم Python for SEO هو الكلمة الرئيسية الصحيحة.
لماذا يُعد مصطلح "python for seo" مضللًا
هل تريد أن تصبح مدونًا رائعًا أم تريد تعلم WordPress؟
هل تريد أن تصبح مصمم رسومات أم أن هدفك هو تعلم Photoshop؟
هل أنت مهتم بتعزيز مهنتك في تحسين محركات البحث (SEO) من خلال نقل مهارات البيانات الخاصة بك إلى المستوى التالي ، أو هل تريد تعلم لغة Python؟
في الدقائق الخمس الأولى من المحاضرة الأولى لدورة علوم الكمبيوتر في معهد ماساتشوستس للتكنولوجيا ، افتتح الأستاذ هارولد أبيلسون الدورة بإخبار الطلاب عن سبب كون "علوم الكمبيوتر" اسمًا سيئًا للتخصص الذي هم على وشك تعلمه. أعتقد أنه من الممتع جدًا مشاهدة الدقائق الخمس الأولى من المحاضرة:
عندما يبدأ حقل ما للتو ، ولا تفهمه جيدًا حقًا ، فمن السهل جدًا الخلط بين جوهر ما تفعله والأدوات التي تستخدمها. - هارولد ابيلسون
نحاول تحسين تواجدنا ونتائجنا على الإنترنت ، ويعتمد الكثير مما نقوم به على فهم البيانات وتصورها ومعالجتها ومعالجتها بشكل عام ، وهذا هو تركيزنا ، بغض النظر عن الأداة المستخدمة. علم البيانات هو المجال الذي يحتوي على أطر عمل فكرية للقيام بذلك ، بالإضافة إلى العديد من الأدوات لتنفيذ ما نريد القيام به. قد تكون Python هي لغة البرمجة (الأداة) التي تختارها ، ومن المهم بالتأكيد تعلمها جيدًا. من المهم أيضًا ، إن لم يكن أكثر أهمية ، التركيز على "جوهر ما تفعله" ، ومعالجة البيانات وتحليلها ، في حالتنا.
يجب أن يكون التركيز الأساسي على العمليات التي تمت مناقشتها أعلاه (الاستيراد ، الترتيب ، التصور ، إلخ) ، بدلاً من لغة البرمجة المختارة. أو الأفضل ، كيفية استخدام لغة البرمجة هذه لتحقيق مهامك ، بدلاً من مجرد تعلم لغة برمجة.
من يهتم بكل هذه الفروق النظرية إذا كنت سأتعلم بايثون على أي حال؟
دعنا نلقي نظرة على ما قد يحدث إذا ركزت على التعرف على الأداة ، بدلاً من جوهر ما تفعله. هنا ، نقارن البحث عن "Learn wordpress" (الأداة) مقابل "Learn blogging" (الشيء الذي نريد القيام به):
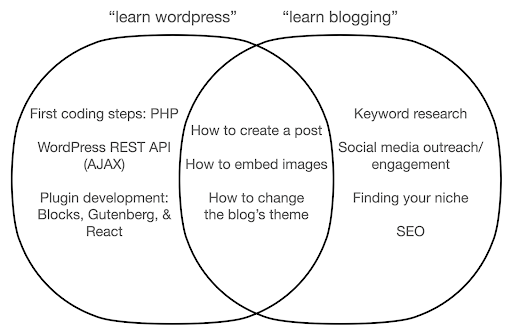
يوضح الرسم التخطيطي الموضوعات المحتملة ضمن كتاب أو دورة تدريبية تعلم عن الكلمة الأساسية في الجزء العلوي. تعرض منطقة التقاطع في المنتصف الموضوعات التي قد تحدث في كلا نوعي الدورة / الكتاب.
إذا ركزت على الأداة ، فسوف ينتهي بك الأمر بلا شك إلى التعرف على أشياء لا تحتاجها حقًا ، خاصة كمبتدئ. قد تربكك هذه الموضوعات وتحبطك ، خاصة إذا لم تكن لديك خلفية فنية أو برمجية.
سوف تتعلم أيضًا أشياء مفيدة لتصبح مدونًا جيدًا (الموضوعات في منطقة التقاطع). من السهل جدًا تدريس هذه الموضوعات (كيفية إنشاء منشور مدونة) ، لكن لا تخبرك كثيرًا عن سبب وجوب التدوين ومتى وماذا. هذا ليس خطأ في كتاب يركز على الأدوات ، لأنه عند التعرف على أداة ، سيكون كافياً أن تتعلم كيفية إنشاء منشور مدونة ، والمضي قدمًا.
بصفتك مدونًا ، ربما تكون مهتمًا أكثر بماذا ولماذا التدوين ، ولن يتم تناول ذلك في الكتب التي تركز على الأدوات.
من الواضح أن الأشياء الإستراتيجية والمهمة مثل مُحسّنات محرّكات البحث ، والعثور على مكانتك ، وما إلى ذلك ، لن تتم تغطيتها ، لذلك ستفقد أشياء مهمة جدًا.
ما هي بعض موضوعات علوم البيانات التي ربما لن تتعلم عنها في كتاب البرمجة؟
كما رأينا ، ربما يعني اختيار بايثون أو كتاب برمجة أنك تريد أن تصبح مهندس برمجيات. من الطبيعي أن تكون الموضوعات موجهة نحو هذه الغاية. إذا كنت تبحث عن كتاب علوم البيانات ، فستحصل على مواضيع وأدوات أكثر توجهاً نحو تحليل البيانات.
يمكننا استخدام الرسم التخطيطي الأول (الذي يوضح دورة علوم البيانات) كدليل ، والبحث بشكل استباقي عن تلك الموضوعات: "استيراد البيانات باستخدام Python" ، و "بيانات مرتبة مع r" ، و "تصور البيانات باستخدام Python" وما إلى ذلك. دعنا نلقي نظرة أعمق على هذه المواضيع ونستكشفها أكثر:
يستورد
من الطبيعي أن نحتاج أولاً إلى الحصول على بعض البيانات. هذا يمكن أن يكون:
- ملف على جهاز الكمبيوتر الخاص بنا: الحالة الأكثر وضوحًا حيث يمكنك ببساطة فتح الملف بلغة البرمجة التي تختارها. من المهم ملاحظة أن هناك العديد من تنسيقات الملفات المختلفة ، وأن لديك العديد من الخيارات أثناء فتح / قراءة الملفات. على سبيل المثال ، تحتوي وظيفة read_csv من مكتبة الباندا (وهي أداة أساسية لمعالجة البيانات في Python) على خمسين خيارًا للاختيار من بينها أثناء فتح الملف. يحتوي على أشياء مثل مسار الملف ، والأعمدة المراد اختيارها ، وعدد الصفوف المراد فتحها ، وتفسير كائنات التاريخ والوقت ، وكيفية التعامل مع القيم المفقودة وغير ذلك الكثير. من المهم أن تكون على دراية بهذه الخيارات والاعتبارات المختلفة أثناء فتح تنسيقات ملفات مختلفة. علاوة على ذلك ، تمتلك الباندا تسعة عشر وظيفة مختلفة تبدأ بـ read_ لتنسيقات ملفات وبيانات مختلفة.
- تصدير من أداة عبر الإنترنت: ربما تكون على دراية بهذا ، وهنا يمكنك تخصيص بياناتك ثم تصديرها ، وبعد ذلك ستفتحها كملف على جهاز الكمبيوتر الخاص بك.
- استدعاءات API للحصول على بيانات محددة: هذا في مستوى أدنى ، وأقرب إلى نهج المزرعة المذكور أعلاه. في هذه الحالة تقوم بإرسال طلب مع متطلبات محددة واستعادة البيانات التي تريدها. الميزة هنا هي أنه يمكنك تخصيص ما تريد الحصول عليه بالضبط ، وتنسيقه بطرق قد لا تكون متاحة في الواجهة عبر الإنترنت. على سبيل المثال ، في Google Analytics ، يمكنك إضافة بُعد ثانوي إلى الجدول الذي تقوم بتحليله ، لكن لا يمكنك إضافة بُعد ثالث. أنت مقيد أيضًا بعدد الصفوف التي يمكنك تصديرها. تمنحك واجهة برمجة التطبيقات مزيدًا من المرونة ، ويمكنك أيضًا أتمتة مكالمات معينة تحدث بشكل دوري ، كجزء من خط أنابيب جمع / تحليل أكبر للبيانات.
- الزحف وكشط البيانات: من المحتمل أن يكون لديك الزاحف المفضل لديك ، ومن المحتمل أن تكون على دراية بالعملية. هذه بالفعل عملية مرنة ، مما يسمح لنا باستخراج عناصر مخصصة من الصفحات ، والزحف إلى صفحات معينة فقط ، وما إلى ذلك.
- مجموعة من الأساليب التي تتضمن الأتمتة والاستخراج المخصص وربما التعلم الآلي للاستخدامات الخاصة.
بمجرد حصولنا على بعض البيانات ، نريد الانتقال إلى المستوى التالي.
أنيق - مرتب
مجموعة البيانات "المرتبة" هي مجموعة بيانات منظمة بطريقة معينة. يشار إليها أيضًا باسم بيانات "التنسيق الطويل". يناقش الفصل 12 في كتاب R for Data Science مفهوم البيانات المرتبة بمزيد من التفصيل إذا كنت مهتمًا.
ألق نظرة على الجداول الثلاثة أدناه وحاول إيجاد أي اختلافات:
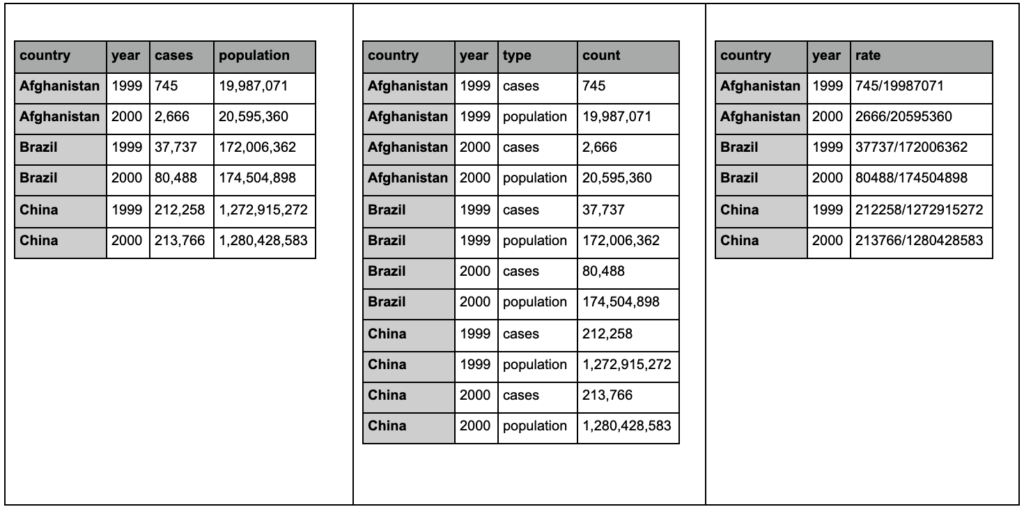
نماذج الجداول من حزمة المدّ.
ستجد أن الجداول الثلاثة تحتوي على نفس المعلومات بالضبط ، لكنها منظمة ومعروضة بطرق مختلفة. يمكن أن يكون لدينا الحالات والسكان في عمودين منفصلين (الجدول 1) ، أو أن يكون لدينا عمود لإخبارنا ما هي الملاحظة (الحالات أو السكان) ، وعمود "العد" لحساب تلك الحالات (الجدول 2). في الجدول 3 ، يتم عرضها كمعدلات.
عند التعامل مع البيانات ، ستجد أن المصادر المختلفة تنظم البيانات بشكل مختلف ، وأنك ستحتاج غالبًا إلى التغيير من / إلى تنسيقات معينة لتحليل أفضل وأسهل. يعد التعرف على عمليات التنظيف هذه أمرًا بالغ الأهمية ، وتحتوي حزمة Tidyr في R على أدوات خاصة لذلك. يمكنك أيضًا استخدام الباندا إذا كنت تفضل Python ، ويمكنك التحقق من وظائف الذوبان والمحور لذلك.
بمجرد أن تصبح بياناتنا بتنسيق معين ، قد نرغب في مزيد من التلاعب بها.
تحول
هناك مهارة أخرى مهمة يجب بناؤها وهي القدرة على إجراء أي تغييرات تريدها على البيانات التي تعمل بها. السيناريو المثالي هو الوصول إلى المرحلة حيث يمكنك إجراء محادثات مع بياناتك ، والقدرة على التقسيم والتقطيع بالطريقة التي تريد طرح أسئلة محددة للغاية عليها ، ونأمل أن تحصل على رؤى مثيرة للاهتمام. فيما يلي بعض أهم مهام التحويل التي من المحتمل أن تحتاجها كثيرًا مع بعض أمثلة المهام التي قد تكون مهتمًا بها:
بعد الحصول على بياناتنا وترتيبها ووضعها بالتنسيق المطلوب ، سيكون من الجيد تصورها.
تصور
يعد تصور البيانات موضوعًا ضخمًا ، وهناك كتب كاملة حول بعض موضوعاته الفرعية. إنها واحدة من تلك الأشياء التي يمكن أن توفر الكثير من الأفكار حول بياناتنا ، خاصة أنها تستخدم عناصر مرئية بديهية لتوصيل المعلومات. يُظهر لنا الارتفاع النسبي للأشرطة في مخطط شريطي على الفور كميتها النسبية على سبيل المثال. يمكن للقراء التعرف بسهولة على كثافة اللون والموقع النسبي والعديد من السمات المرئية الأخرى.
الرسم البياني الجيد يستحق ألف كلمة (مفتاح)!
نظرًا لوجود العديد من الموضوعات التي يجب تناولها حول تصور البيانات ، سأشارك ببساطة بعض الأمثلة التي قد تكون مثيرة للاهتمام. العديد منها هي اللبنات الأساسية للوحة بيانات الفقر هذه ، إذا كنت تريد التفاصيل الكاملة.
أحيانًا يكون المخطط الشريطي البسيط هو كل ما تحتاجه لمقارنة القيم ، حيث يمكن عرض الأشرطة رأسيًا أو أفقيًا:
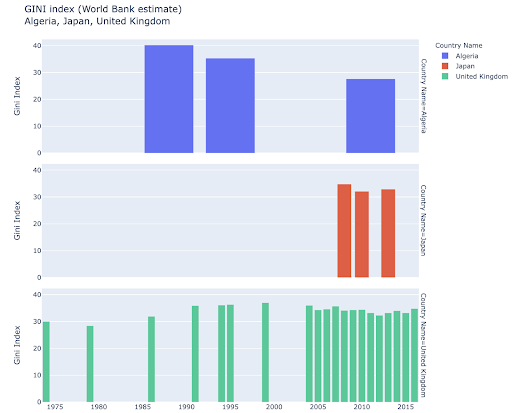
قد تكون مهتمًا باستكشاف بلدان معينة ، والتعمق أكثر ، من خلال معرفة مدى تقدمها في مقاييس معينة. في هذه الحالة ، قد ترغب في عرض مخططات شريطية متعددة في نفس الرسم البياني:
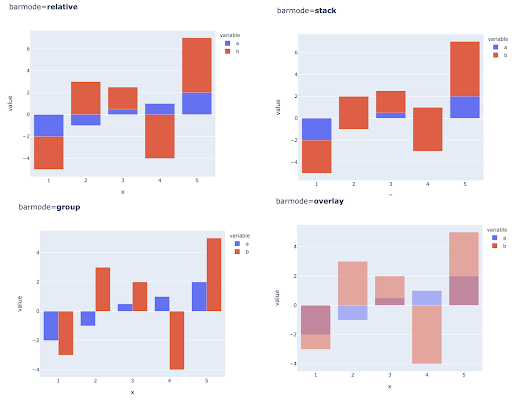
يمكن أيضًا إجراء مقارنة قيم متعددة لملاحظات متعددة عن طريق وضع أشرطة متعددة في كل موضع على المحور X ، وإليك الطرق الرئيسية للقيام بذلك:
اختيار مقاييس الألوان واللون: جزء أساسي من تصور البيانات ، وهو شيء يمكنه توصيل المعلومات بكفاءة عالية وبديهية إذا تم القيام به بشكل صحيح.
مقاييس الألوان الفئوية: مفيدة للتعبير عن البيانات الفئوية. كما يوحي الاسم ، فإن هذا هو نوع البيانات الذي يظهر الفئة التي تنتمي إليها ملاحظة معينة. في هذه الحالة ، نريد ألوانًا متميزة عن بعضها البعض قدر الإمكان لإظهار اختلافات واضحة في الفئات (خاصة بالنسبة للعناصر المرئية التي يتم عرضها بجانب بعضها البعض).
يستخدم المثال التالي مقياس ألوان فئوي لإظهار أي نظام حكومي يتم تنفيذه في كل بلد. من السهل جدًا ربط ألوان البلدان بأسطورة توضح نظام الحكومة المستخدم. وهذا ما يسمى أيضًا بالخريطة التصحيحية:
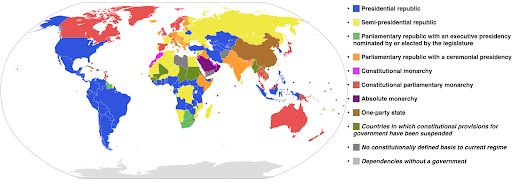
المصدر: ويكيبيديا
في بعض الأحيان ، تكون البيانات التي نريد تصورها لنفس المقياس ، وتقع كل دولة (أو أي نوع آخر من المراقبة) في نقطة معينة في سلسلة متصلة تتراوح بين الحد الأدنى والحد الأقصى للنقاط. بعبارة أخرى ، نريد تصور درجات هذا المقياس.
في هذه الحالات ، نحتاج إلى إيجاد مقياس ألوان مستمر (أو متسلسل) . يتضح على الفور في المثال التالي أي البلدان زرقاء اللون (وبالتالي تحصل على المزيد من الزيارات) ، ويمكننا أن نفهم بشكل بديهي الفروق الدقيقة بين البلدان.
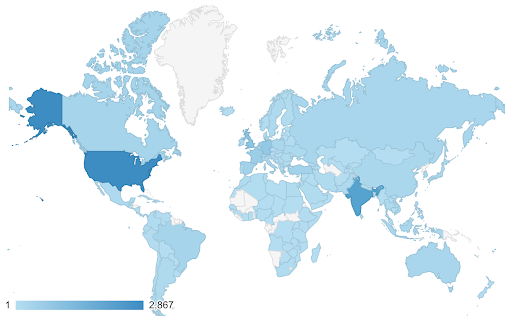
قد تكون بياناتك مستمرة (مثل مخطط خريطة حركة المرور أعلاه) ، ولكن الشيء المهم في الأرقام قد يكون مدى تباعدها عن نقطة معينة. مقاييس الألوان المتباينة مفيدة في هذه الحالة.
يوضح الرسم البياني أدناه معدلات النمو السكاني الصافي. في هذه الحالة ، من المثير للاهتمام أن تعرف أولاً ما إذا كانت دولة معينة لديها معدل نمو إيجابي أم سلبي أم لا. أو نريد أن نعرف كم تبعد كل دولة عن الصفر (ومقدارها). يُظهر لنا إلقاء نظرة خاطفة على الخريطة على الفور البلدان التي يتزايد عدد سكانها وأيها يتقلص. توضح لنا الأسطورة أيضًا أن أقصى معدل موجب يبلغ 3.5٪ وأن أقصى معدل موجب هو -0.5٪. هذا يعطينا أيضًا إشارة إلى نطاق القيم (الإيجابية والسلبية).
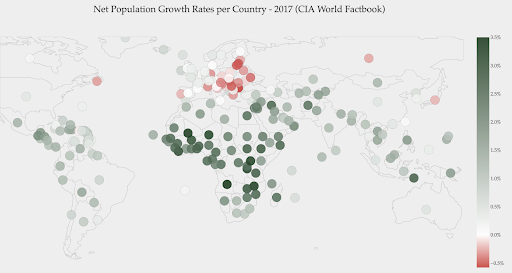
المصدر: Dashboardom.com
لسوء الحظ ، فإن الألوان المختارة لهذا المقياس ليست مثالية ، لأن الأشخاص المصابين بعمى الألوان قد لا يتمكنون من التمييز بشكل صحيح بين الأحمر والأخضر. هذا اعتبار مهم للغاية عند اختيار مقاييس الألوان الخاصة بنا.

مخطط التبعثر هو أحد أكثر أنواع المؤامرات استخدامًا وتنوعًا. ينقل موضع النقاط (أو أي علامة أخرى) الكمية التي نحاول إيصالها. بالإضافة إلى الموضع ، يمكننا استخدام العديد من السمات المرئية الأخرى مثل اللون والحجم والشكل لتوصيل المزيد من المعلومات. يوضح المثال التالي النسبة المئوية للسكان الذين يعيشون عند 1.9 دولار في اليوم ، والتي يمكننا رؤيتها بوضوح على أنها المسافة الأفقية للنقاط.
يمكننا أيضًا إضافة بُعد جديد إلى مخططنا باستخدام اللون. يتوافق هذا مع تصور عمود ثالث من نفس مجموعة البيانات ، والذي يعرض في هذه الحالة بيانات السكان.
يمكننا الآن أن نرى أن الحالة الأكثر تطرفًا من حيث عدد السكان (الولايات المتحدة الأمريكية) ، منخفضة جدًا في مقياس مستوى الفقر. هذا يضيف ثراء لمخططاتنا. كان بإمكاننا أيضًا استخدام الحجم والشكل لتصور المزيد من الأعمدة من مجموعة البيانات الخاصة بنا. نحن بحاجة إلى تحقيق توازن جيد بين الثراء وسهولة القراءة بالرغم من ذلك.
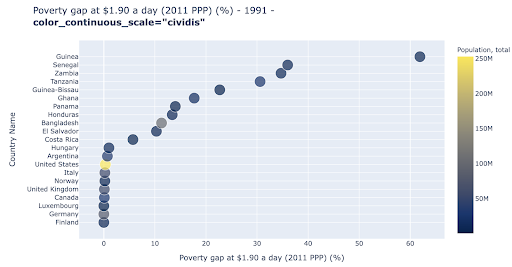
قد نكون مهتمين بالتحقق مما إذا كانت هناك علاقة بين السكان ومستويات الفقر ، وبالتالي يمكننا تصور مجموعة البيانات نفسها بطريقة مختلفة قليلاً لمعرفة ما إذا كانت هذه العلاقة موجودة:
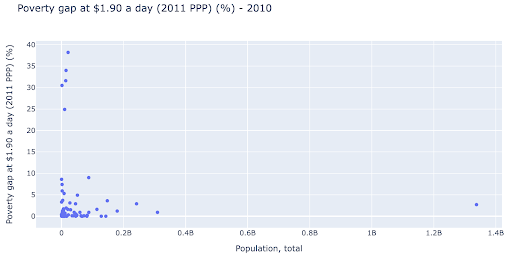
لدينا قيمة شاذة واحدة في عدد السكان عند حوالي 1.35 مليار ، وهذا يعني أن لدينا الكثير من المسافات البيضاء في المخطط ، مما يعني أيضًا أن العديد من القيم مضغوطة في منطقة صغيرة جدًا. لدينا أيضًا العديد من النقاط المتداخلة ، مما يجعل من الصعب جدًا تحديد أي اختلافات أو اتجاهات.
يحتوي المخطط التالي على نفس المعلومات ولكن يتم تصويره بشكل مختلف باستخدام تقنيتين:
- المقياس اللوغاريتمي : عادة ما نرى البيانات على مقياس مضاف. بمعنى آخر ، تمثل كل نقطة على المحور (س أو ص) إضافة كمية معينة من البيانات المرئية. يمكن أن يكون لدينا أيضًا مقاييس ضرب ، وفي هذه الحالة لكل نقطة جديدة على المحور السيني نضرب (بعشرة في هذا المثال). يسمح هذا بتوزيع النقاط ونحتاج إلى التفكير في المضاعفات بدلاً من الإضافات ، كما فعلنا في الرسم البياني السابق.
- استخدام علامة مختلفة (دوائر فارغة أكبر) : أدى تحديد شكل مختلف للعلامات الخاصة بنا إلى حل مشكلة "الإفراط في التخطيط" حيث قد يكون لدينا عدة نقاط فوق بعضها البعض في نفس الموقع ، مما يجعل من الصعب جدًا رؤيتها كم عدد النقاط لدينا.
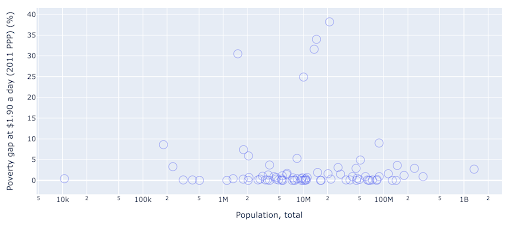
يمكننا الآن أن نرى أن هناك مجموعة من البلدان حول علامة 10 ملايين ، ومجموعات أخرى أصغر أيضًا.
كما ذكرت ، هناك العديد من أنواع الأحرف وخيارات التصور وكتب كاملة مكتوبة حول هذا الموضوع. آمل أن يمنحك هذا بعض الأفكار الشيقة لتجربتها.
بيانات عند الزحف³
 يتعلم أكثر
يتعلم أكثرنموذج
نحتاج إلى تبسيط بياناتنا ، والعثور على الأنماط ، وعمل تنبؤات ، أو ببساطة فهمها بشكل أفضل. هذا موضوع كبير آخر ، ويمكن أن يتراوح من مجرد الحصول على بعض الإحصائيات الموجزة (متوسط ، متوسط ، انحراف معياري ، إلخ) ، إلى نمذجة بياناتنا بصريًا ، باستخدام نموذج يلخص أو يجد اتجاهًا ، إلى استخدام تقنيات أكثر تعقيدًا للحصول على صيغة رياضية لبياناتنا. يمكننا أيضًا استخدام التعلم الآلي لمساعدتنا في الكشف عن المزيد من الأفكار في بياناتنا.
مرة أخرى ، هذه ليست مناقشة كاملة للموضوع ، لكني أود مشاركة بعض الأمثلة حيث يمكنك استخدام بعض تقنيات التعلم الآلي لمساعدتك.
في مجموعة بيانات الزحف ، كنت أحاول معرفة المزيد عن صفحات 404 ، وما إذا كان بإمكاني اكتشاف شيء عنها. كانت محاولتي الأولى هي التحقق مما إذا كان هناك ارتباط بين حجم الصفحة ورمز الحالة الخاص بها ، وكان هناك - ارتباط شبه كامل!
شعرت وكأنني عبقري لبضع دقائق ، وسرعان ما عدت إلى كوكب الأرض.
كانت جميع الصفحات 404 في نطاق ضيق جدًا من حجم الصفحة بحيث تحتوي جميع الصفحات التي تحتوي على عدد معين من الكيلوبايتات تقريبًا على رمز حالة 404. ثم أدركت أن صفحات 404 بحكم التعريف لا تحتوي على أي محتوى عليها بخلاف "صفحة خطأ 404"! ولهذا كان لديهم نفس الحجم.
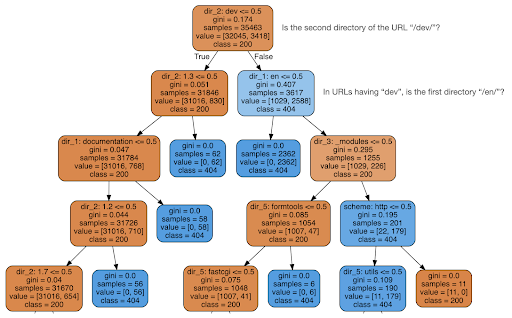
قررت بعد ذلك التحقق مما إذا كان المحتوى يمكن أن يخبرني بشيء عن رمز الحالة ، لذلك قمت بتقسيم عناوين URL إلى عناصرها ، وقمت بتشغيل مصنف شجرة قرار باستخدام sklearn. هذه في الأساس تقنية تنتج شجرة قرار ، حيث يمكن أن يقودنا اتباع قواعدها إلى تعلم كيفية العثور على هدفنا ، 404 صفحات في هذه الحالة.
في شجرة القرار التالية ، يوضح السطر الأول في كل مربع القاعدة التي يجب اتباعها أو التحقق منها ، وسطر "العينات" هو عدد الملاحظات الموجودة في هذا المربع ، وسطر "الفئة" يخبرنا بفئة الملاحظة الحالية ، في هذه الحالة ، سواء أكان رمز الحالة الخاص به هو 200 أو 404 أم لا.
لن أخوض في مزيد من التفاصيل ، وأعلم أن شجرة القرار قد لا تكون واضحة إذا لم تكن على دراية بها ، ويمكنك استكشاف مجموعة بيانات الزحف الأولية ورمز التحليل إذا كنت مهتمًا.
ما توصلت إليه شجرة القرار بشكل أساسي هو كيفية العثور على جميع صفحات 404 تقريبًا ، باستخدام بنية الدليل لعناوين URL. كما ترى ، وجدنا 3617 عنوان URL ، ببساطة عن طريق التحقق مما إذا كان الدليل الثاني لعنوان URL هو "/ dev /" (أول مربع أزرق فاتح في السطر الثاني من الأعلى). والآن نحن نعرف كيفية تحديد موقع 404 الخاص بنا ، ويبدو أنهم جميعًا تقريبًا في قسم "/ dev /" بالموقع. كان هذا بالتأكيد توفيرًا كبيرًا للوقت. تخيل الاطلاع يدويًا على جميع هياكل ومجموعات عناوين URL الممكنة للعثور على هذه القاعدة.
ما زلنا لا نملك الصورة الكاملة وسبب حدوث ذلك ، ويمكن متابعة ذلك بشكل أكبر ، ولكن على الأقل قمنا الآن بتحديد موقع عناوين URL هذه بسهولة.
هناك أسلوب آخر قد تكون مهتمًا باستخدامه وهو تجميع KMeans ، والذي يقوم بتجميع نقاط البيانات في مجموعات / مجموعات مختلفة. هذا هو أسلوب "التعلم غير الخاضع للإشراف" ، حيث تساعدنا الخوارزمية في اكتشاف الأنماط التي لم نكن نعلم بوجودها.
تخيل أن لديك مجموعة من الأرقام ، دعنا نقول عدد سكان البلدان ، وأردت تجميعهم في مجموعتين ، كبيرها وصغيرها. كيف يمكنك أن تفعل ذلك؟ أين سترسم هذا الخط؟
هذا يختلف عن الحصول على البلدان العشرة الأولى ، أو أعلى X٪ من البلدان. سيكون هذا سهلاً للغاية ، يمكننا تصنيف البلدان حسب عدد السكان ، والحصول على أفضل البلدان X كما نريد.
ما نريده هو تجميعها على أنها "كبيرة" و "صغيرة" بالنسبة إلى مجموعة البيانات هذه ، وافتراض أننا لا نعرف أي شيء عن سكان البلد.
يمكن توسيع ذلك ليشمل محاولة تقسيم البلدان إلى ثلاث فئات: صغيرة ومتوسطة وكبيرة. يصبح القيام بذلك أكثر صعوبة يدويًا ، إذا أردنا خمس أو ست مجموعات أو أكثر.
لاحظ أننا لا نعرف عدد البلدان التي سينتهي بها المطاف في كل مجموعة ، لأننا لا نطلب أفضل بلدان X. بالتجمع في مجموعتين ، يمكننا أن نرى أن لدينا دولتين فقط في المجموعة الكبيرة: الصين والهند. هذا أمر منطقي ، حيث أن متوسط عدد سكان هذين البلدين بعيد جدًا عن جميع البلدان الأخرى. هذه المجموعة من البلدان لها متوسطها الخاص ودولها أقرب إلى بعضها البعض من بلدان المجموعة الأخرى:
تتجمع البلدان في مجموعتين حسب عدد السكان 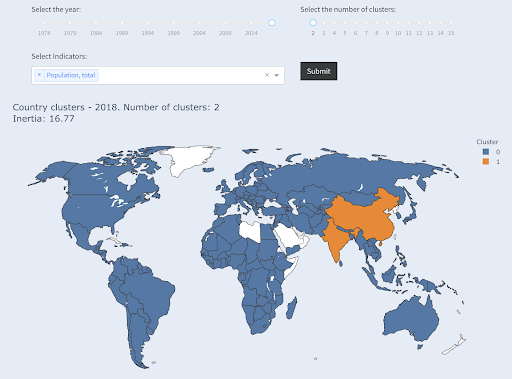
تم تجميع ثالث أكبر دولة من حيث عدد السكان (الولايات المتحدة الأمريكية ~ 330 مليونًا) مع جميع البلدان الأخرى ، بما في ذلك البلدان التي يبلغ عدد سكانها مليون نسمة. ذلك لأن 330 مترًا أقرب بكثير إلى مليون واحد من 1.3 مليار. لو طلبنا ثلاث مجموعات ، لكنا حصلنا على صورة مختلفة:
تتجمع البلدان في ثلاث مجموعات حسب عدد السكان 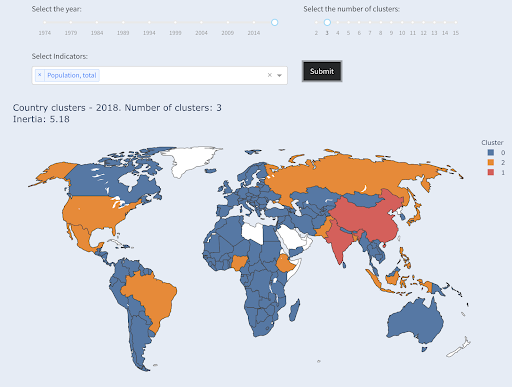
وهذه هي الطريقة التي سيتم بها تجميع البلدان إذا طلبنا أربع مجموعات:
تتجمع البلدان في أربع مجموعات حسب عدد السكان 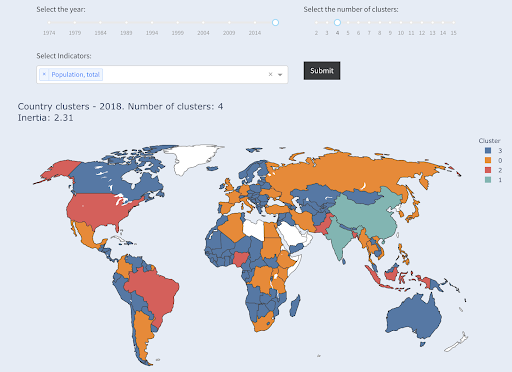
المصدر :overtydata.org (علامة التبويب "بلدان المجموعة")
كان هذا التجميع باستخدام بُعد واحد فقط - السكان - في هذه الحالة ، ويمكنك إضافة المزيد من الأبعاد أيضًا ، ومعرفة أين تنتهي البلدان.
هناك العديد من التقنيات والأدوات الأخرى ، وكانت هذه مجرد أمثلة قليلة نأمل أن تكون ممتعة وعملية.
نحن الآن جاهزون لإيصال نتائجنا إلى جمهورنا.
نقل
بعد كل العمل الذي نقوم به في الخطوات السابقة ، نحتاج في النهاية إلى نقل نتائجنا إلى أصحاب المصلحة الآخرين في المشروع.
يعد دفتر الملاحظات التفاعلي أحد أهم الأدوات في علم البيانات. دفتر الملاحظات Jupyter هو الأكثر استخدامًا ، ويدعم إلى حد كبير جميع لغات البرمجة ، وقد تفضل استخدام تنسيق دفتر الملاحظات الخاص بـ RStudio ، والذي يعمل بنفس الطريقة.
الفكرة الرئيسية هي أن يكون لديك بيانات وكود وسرد وتصورات في مكان واحد ، حتى يتمكن الآخرون من تدقيقها. من المهم أن تُظهر كيف وصلت إلى تلك الاستنتاجات والتوصيات من أجل الشفافية ، وكذلك قابلية التكرار. يجب أن يتمكن الأشخاص الآخرون من تشغيل نفس الكود والحصول على نفس النتائج.
سبب آخر مهم هو قدرة الآخرين ، بما في ذلك "المستقبل أنت" ، على المضي قدمًا في التحليل ، والبناء على العمل الأولي الذي قمت به ، وتحسينه ، وتوسيعه بطرق جديدة.
بالطبع ، هذا يفترض أن الجمهور مرتاح للكود ، وأنهم يهتمون به حتى!
لديك أيضًا خيار تصدير دفاتر الملاحظات الخاصة بك إلى HTML (والعديد من التنسيقات الأخرى) ، باستثناء التعليمات البرمجية ، لذلك ينتهي بك الأمر بتقرير سهل الاستخدام ، ومع ذلك تحتفظ بالشفرة الكاملة لإعادة إنتاج نفس التحليل والنتائج.
يعد تصور البيانات أحد العناصر المهمة في الاتصال ، والذي تمت تغطيته بإيجاز أعلاه.
والأفضل من ذلك ، هو تصور البيانات التفاعلي ، وفي هذه الحالة تسمح لجمهورك بتحديد القيم ، والتحقق من مجموعات مختلفة من الرسوم البيانية والمقاييس لاستكشاف البيانات بشكل أكبر.
فيما يلي بعض لوحات المعلومات وتطبيقات البيانات (قد يستغرق تحميل بعضها بضع ثوانٍ) التي قمت بإنشائها لإعطائك فكرة عما يمكن القيام به.
في النهاية ، يمكنك أيضًا إنشاء تطبيقات مخصصة لمشاريعك ، من أجل تلبية الاحتياجات والمتطلبات الخاصة ، وهنا مجموعة أخرى من تطبيقات تحسين محركات البحث والتسويق التي قد تكون ممتعة بالنسبة لك.
لقد مررنا بالخطوات الرئيسية في دورة علوم البيانات ، ودعنا الآن نستكشف فائدة أخرى لـ "تعلم بيثون".
Python للأتمتة والإنتاجية: صحيح ولكن غير مكتمل
يبدو لي أن هناك اعتقادًا بأن تعلم بايثون هو أساسًا للحصول على مهام منتجة و / أو أتمتة.
هذا صحيح تمامًا ، ولا أعتقد أننا بحاجة حتى إلى مناقشة قيمة القدرة على القيام بشيء ما في جزء صغير من الوقت الذي يستغرقه منا للقيام بذلك يدويًا.
الجزء الآخر المفقود من الحجة هو تحليل البيانات . يوفر لنا تحليل البيانات الجيد رؤى ، ومن الناحية المثالية نحن قادرون على تقديم رؤى قابلة للتنفيذ لتوجيه عملية اتخاذ القرار لدينا ، بناءً على خبرتنا والبيانات التي لدينا.
جزء كبير مما نقوم به هو محاولة فهم ما يحدث ، وتحليل المنافسة ، ومعرفة مكان المحتوى الأكثر قيمة ، وتحديد ما يجب القيام به ، وما إلى ذلك. نحن مستشارون ومستشارون وصناع قرار. من الواضح أن القدرة على الحصول على بعض الأفكار من بياناتنا هي فائدة كبيرة ، ويمكن أن تساعدنا المجالات والمهارات المذكورة هنا في تحقيق ذلك.
ماذا لو علمت أن متوسط طول علامات العنوان الخاصة بك يبلغ ستين حرفًا ، فهل هذا جيد؟
ماذا لو تعمقت قليلاً واكتشفت أن نصف ألقابك أقل بكثير من الستين ، في حين أن النصف الآخر يحتوي على العديد من الشخصيات (مما يجعل المتوسط الستين)؟ In order to get practical and provide good recommendations, you need a higher-resolution view of your title tags' lengths, probably a histogram that shows the frequency of your title tag lengths at each interval so you can have a separate strategy for length. A simple table would also do, for example:
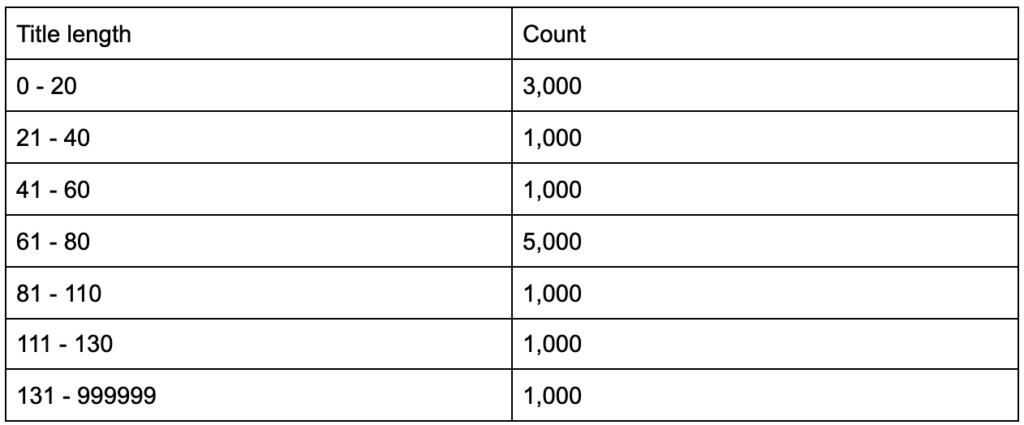
Splitting title lengths by intervals of twenty was an arbitrary decision, and you can split them the way you want. Looking at the table above, and seeing that we have three times more than the average titles in the interval (0, 20), we might want to split it further to better understand what is going on.
Having a better view than the default single-statistic summaries that we get from standard tools, allows us to employ different strategies for different lengths. For example, we can remove the brand name from the titles that are longer than a certain number of characters, and keep it in other titles.
This was an example of very simple insights, which are possible due to the flexibility we get by using a programming language, and a set of data science tools. This also allows us to iterate and modify our approach, until we find a satisfactory point that can take our analysis to the next steps.
Visualization, machine learning, modeling and general data manipulation skills allow us to get better insights on our data, even though those analyses are typically done only once. Still, if you use code to get those insights, you can always take some parts and apply to other projects, or again to the same project. In this case, the insights we got, helped us in our automation, even more. The insights would tell us what needs to be automated and what doesn't.
Should you learn Python?
Is a useless question, and the more useful one is, “How much Python (or R) should you learn?”
My view of how we use computers has evolved in the last few years.
I used to think that there were two main ways of using computers, either you are a regular user, using “point-and-click” applications to do certain tasks, or you are a developer who creates those applications that the rest of us use.

I then realized that it is more like a continuum between very high level use (pizza ordering approach), and the lower levels of the farm approach. I also realized that there is a happy sweet spot in between, where you learn enough programming to get productive and boost your data analysis skills, without having to become a software developer or engineer.
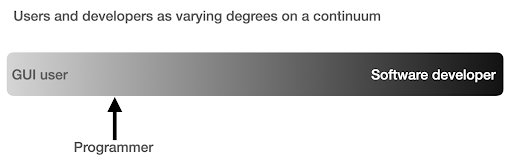
What are the main differences between being a programmer (a software user), and a software developer (or engineer)?
What are the differences between making a great coffee at home, versus establishing and running a cafe?
If making good coffee is one skill, then running a cafe requires ten other skills, most of which have nothing to do with making coffee.
You have to choose a good location (real estate), hire people (management and HR), manage cash flow and finances (accounting and finance), do marketing, legal, manage delivery, adhere to cleanliness and health standards, and so on. You can be a great coffee maker without knowing anything about those fields, but if you want to take it to the next level, you will have to manage all those additional tasks unrelated to making coffee.
The same applies to being a good programmer or data analyst versus being a software developer/engineer. There are so many other things that you have to know and worry about that you don't need as a regular programmer doing stuff for yourself and co-workers and clients. Once you have enough knowledge and skills in programming and data science, you will be in a good position to choose and decide whether you want to continue as an analyst, focusing on data science, or if you want to end up creating software that other people would use.
How do I get into Data Science?
To learn anything I think you have to do two things in parallel:
- Learn the fundamentals and the theory properly: Taking courses and reading books, and getting into the fundamentals can push you forward, as you will be gaining in weeks, knowledge that took decades to establish. It would also immediately give you ideas on things you thought were impossible, or had no idea existed.
- Get as much real world exposure and experience as possible: Experience is always important, and my suggestion is to try as soon as you can to read_csv with Python or R, to actually do so with your GA, GSC, or crawl dataset. See what else you can do (visualize, manipulate, model, etc.). See if you get errors, try to analyze the data only using your programming language.
What does frustration look like, and by when will I get productive?
It's difficult to say, and it depends on your skill, background, the hours you put in, but visualizing it like this might help you on those frustrating unproductive days:
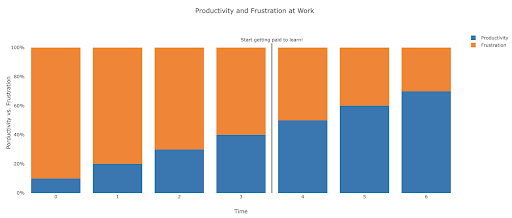
My suggestion is to take a non-trivial task, for example running an SEO audit for a site, only using Python. Your first session will mostly be frustrating, and most of the time will be spent checking documentation, and the definition of basic terms.
In parallel, you are still going through your course, and learning new stuff.
The value of that frustrating session is that it informs and motivates your theoretical learning. You will have questions in mind, and when you learn new things, you will immediately have a place to implement them.
Your next analysis session will probably be a little more productive, but still not productive enough to do at work. You go again to your learning and theory.
Do this enough times, and your time will become mostly productive, eventually you will be doing real work during working hours. The ideal scenario is where you are productive enough to do work, but every time use some time to research better techniques, which improves your work as well. By then you will start to get paid for learning, and your clients will be happily sponsoring you!
Suggested next steps
For the learning path a Data Science course would be great, especially if you get feedback on your work, and you can follow the topics in the order recommended.
If you go with Python I suggest the following libraries:
- pandas: The workhorse of all your tasks in preparing, cleaning, reshaping data whichever way you want. Fluency in pandas allows you to have full control over your data, which will help you immensely in visualization, general analysis, and machine learning
- Plotly and Dash: This is my favorite data visualization library, although there are many others. What I mostly like about it, is that it produces interactive and responsive HTML charts by default. It is very detailed and thorough in its options, yet simple to use. Plotly also includes Plotly Express, which is a high-level plotting tool, which is more intuitive to use, and takes a data-oriented approach (as opposed to a chart-oriented approach). Plotly also created Dash, which is the tool for creating interactive dashboards, but also serves as a full front-end web development framework. Other important data visualization libraries are matplotlib, altair, and bokeh, and for interactive data apps, there is panel and streamlit. Another important feature is that Plotly and Dash are available in all languages used in Data Science. You might use other libraries, and this is just my personal preference. Speaking of personal preferences:
- advertools: This is a library that I created to provide various online marketing tools, most importantly, an SEO crawler, log file parser and compressor, multi robots.txt parser, recursive sitemap parser, SEM keyword and text ad generator for large scale campaigns, weighted frequency word counter, Google SERP downloader, YouTube data API, and a few other tools. It is still evolving, and you are more than welcome to contribute any suggestions, bugs, or issues you might have with it.
These should be enough for beginners, and when you are familiar with them, you can do your own research for more specialized libraries, machine learning and deep learning tools, or libraries that are specialized in performance, or a special niche use-case.