
Data Science for SEO และ Digital Marketing : คู่มือแนะนำสำหรับผู้เริ่มต้น
เผยแพร่แล้ว: 2021-12-07เนื่องจากงานส่วนใหญ่ของเราเกี่ยวข้องกับข้อมูล และในขณะที่สาขา Data Science กำลังขยายใหญ่ขึ้น และสามารถเข้าถึงได้มากขึ้นสำหรับผู้เริ่มต้น ฉันต้องการแบ่งปันความคิดบางประการเกี่ยวกับวิธีการที่คุณจะเข้าสู่สาขานี้เพื่อเพิ่ม SEO และการตลาดของคุณ ทักษะโดยทั่วไป
ศาสตร์แห่งข้อมูลคืออะไร?
ไดอะแกรมที่รู้จักกันดีซึ่งใช้ในการให้ภาพรวมของฟิลด์นี้คือแผนภาพเวนน์ของ Drew Conway ที่แสดง Data Science เป็นจุดตัดของสถิติ การแฮ็ก (ทักษะการเขียนโปรแกรมขั้นสูงโดยทั่วไปและไม่จำเป็นต้องเจาะเครือข่ายและก่อให้เกิดอันตราย) และเนื้อหาสาระ ความเชี่ยวชาญหรือ “ความรู้โดเมน”:
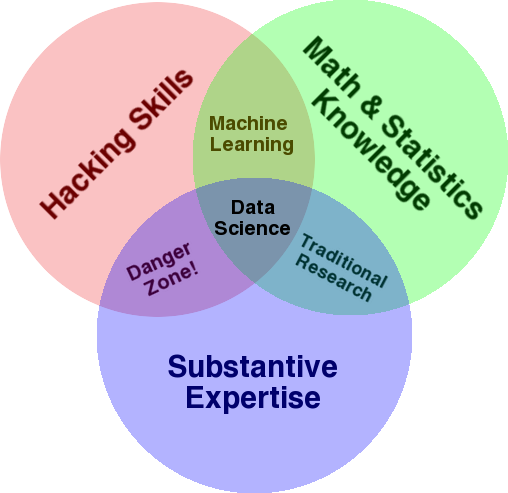
ที่มา: oreilly.com
เมื่อฉันเริ่มเรียนรู้ ฉันรู้ทันทีว่านี่คือสิ่งที่เราทำอยู่แล้ว ข้อแตกต่างเพียงอย่างเดียวคือฉันใช้เครื่องมือพื้นฐานและเครื่องมือแบบแมนนวลมากขึ้น
หากคุณดูแผนภาพ คุณจะเห็นได้อย่างง่ายดายว่าคุณทำสิ่งนี้ไปแล้วได้อย่างไร คุณใช้คอมพิวเตอร์ (ทักษะการแฮ็ก) เพื่อวิเคราะห์ข้อมูล (สถิติ) เพื่อแก้ปัญหาในทางปฏิบัติโดยใช้ความเชี่ยวชาญที่สำคัญของคุณใน SEO (หรืออะไรก็ตามที่คุณมุ่งเน้นเฉพาะด้าน)
“ภาษาการเขียนโปรแกรม” ปัจจุบันของคุณน่าจะเป็นสเปรดชีต (Excel, Google ชีต ฯลฯ) และคุณมักจะใช้ Powerpoint หรือสิ่งที่คล้ายกันในการสื่อสารแนวคิด ลองขยายองค์ประกอบเหล่านี้เล็กน้อย
- ความรู้ด้านโดเมน: เริ่มจากจุดแข็งหลักของคุณ อย่างที่คุณรู้อยู่แล้วเกี่ยวกับความเชี่ยวชาญของคุณ โปรดทราบว่านี่เป็นส่วนสำคัญของการเป็นนักวิทยาศาสตร์ข้อมูล และนี่คือที่ที่คุณสามารถสร้างและปกป้องความรู้ของคุณ ไม่กี่เดือนที่ผ่านมา ฉันกำลังคุยเรื่องการวิเคราะห์ชุดข้อมูลการรวบรวมข้อมูลกับเพื่อนของฉัน เขาเป็นนักฟิสิกส์ กำลังทำวิจัยเกี่ยวกับคอมพิวเตอร์ควอนตัมหลังปริญญาเอก ความรู้และทักษะทางคณิตศาสตร์และสถิติของเขานั้นเหนือกว่าฉันมาก และเขารู้วิธีวิเคราะห์ข้อมูลได้ดีกว่าฉันจริงๆ ปัญหาหนึ่ง. เขาไม่รู้ว่า "404" คืออะไร (หรือทำไมเราถึงสนใจ "301") ดังนั้น ด้วยความรู้ทางคณิตศาสตร์ทั้งหมดของเขา เขาจึงไม่เข้าใจคอลัมน์ "สถานะ" ในชุดข้อมูลการรวบรวมข้อมูล โดยธรรมชาติแล้ว เขาจะไม่รู้ว่าจะทำอย่างไรกับข้อมูลนั้น จะพูดคุยกับใคร และกลยุทธ์ใดที่จะสร้างตามรหัสสถานะเหล่านั้น (หรือจะมองหาที่อื่นหรือไม่) คุณกับฉันรู้ดีว่าต้องทำอย่างไรกับพวกเขา หรืออย่างน้อยเราก็รู้ว่าต้องดูที่ไหนอีกถ้าเราต้องการเจาะลึกลงไป
- คณิตศาสตร์และสถิติ: ถ้าคุณใช้ Excel เพื่อหาค่าเฉลี่ยของตัวอย่างข้อมูล แสดงว่าคุณกำลังใช้สถิติ ค่าเฉลี่ยเป็นสถิติที่อธิบายลักษณะเฉพาะของตัวอย่างข้อมูล สถิติขั้นสูงจะช่วยในการทำความเข้าใจข้อมูลของคุณ นี่เป็นสิ่งสำคัญเช่นกัน และฉันไม่ใช่ผู้เชี่ยวชาญในด้านนี้ ยิ่งคุณคุ้นเคยกับการแจกแจงทางสถิติมากเท่าไร คุณก็จะมีแนวคิดเกี่ยวกับวิธีวิเคราะห์ข้อมูลมากขึ้น ยิ่งคุณเข้าใจหัวข้อที่เป็นพื้นฐานมากเท่าไหร่ คุณก็จะยิ่งสามารถกำหนดสมมติฐานของคุณได้ดีขึ้นเท่านั้น และการสร้างข้อความที่แม่นยำเกี่ยวกับชุดข้อมูลของคุณ
- ทักษะการเขียนโปรแกรม: ฉันจะพูดถึงเรื่องนี้ในรายละเอียดเพิ่มเติมด้านล่าง แต่โดยหลักแล้ว นี่คือที่ที่คุณสร้างความยืดหยุ่นในการบอกให้คอมพิวเตอร์ทำสิ่งที่คุณต้องการให้ทำ แทนที่จะติดอยู่กับใช้งานง่ายแต่มีข้อจำกัดเล็กน้อย เครื่องมือ นี่เป็นวิธีหลักในการรับ ปรับแต่ง และล้างข้อมูลของคุณ ไม่ว่าคุณจะต้องการด้วยวิธีใด ซึ่งจะปูทางให้คุณมี "การสนทนา" แบบปลายเปิดและยืดหยุ่นกับข้อมูลของคุณ
ตอนนี้เรามาดูสิ่งที่เรามักจะทำใน Data Science
วัฏจักรข้อมูล
โครงการวิทยาศาสตร์ข้อมูลทั่วไปหรือแม้แต่งาน มักจะมีลักษณะดังนี้:
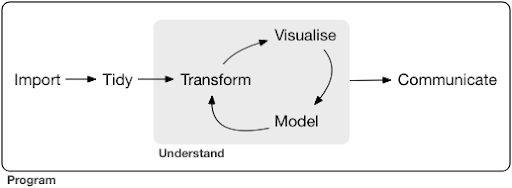
ที่มา: r4ds.had.co.nz
ฉันยังแนะนำให้อ่านหนังสือเล่มนี้โดย Hadley Wickham และ Garrett Grolemund ซึ่งเป็นบทนำที่ดีของ Data Science มันเขียนด้วยตัวอย่างจากภาษาการเขียนโปรแกรม R แต่แนวคิดและรหัสสามารถเข้าใจได้ง่ายถ้าคุณรู้เฉพาะ Python
ดังที่คุณเห็นในไดอะแกรม ขั้นแรกเราต้องนำเข้าข้อมูลของเรา จัดระเบียบ และจากนั้นเริ่มทำงานในวงจรภายในของการแปลงรูปแบบ แสดงภาพ และแบบจำลอง หลังจากนั้นเราจะสื่อสารผลลัพธ์กับผู้อื่น
ขั้นตอนเหล่านี้มีตั้งแต่ง่ายสุดไปจนถึงซับซ้อนมาก ตัวอย่างเช่น ขั้นตอน "นำเข้า" อาจง่ายพอๆ กับการอ่านไฟล์ CSV และในบางกรณีอาจประกอบด้วยโครงการดึงข้อมูลเว็บที่ซับซ้อนมากเพื่อรับข้อมูล องค์ประกอบหลายประการของกระบวนการนี้เป็นความเชี่ยวชาญเฉพาะด้านอย่างเต็มที่
เราสามารถแมปสิ่งนี้กับกระบวนการที่เราคุ้นเคยได้อย่างง่ายดาย ตัวอย่างเช่น คุณอาจเริ่มต้นด้วยการรับข้อมูลเมตาเกี่ยวกับเว็บไซต์ โดยการดาวน์โหลด robots.txt และแผนผังเว็บไซต์ XML คุณอาจจะรวบรวมข้อมูลและอาจได้รับข้อมูลบางอย่างเกี่ยวกับตำแหน่ง SERP หรือเชื่อมโยงข้อมูลเป็นต้น ตอนนี้คุณมีชุดข้อมูลสองสามชุดแล้ว คุณอาจต้องการรวมตารางบางตาราง ใส่ข้อมูลเพิ่มเติม และเริ่มสำรวจ/ทำความเข้าใจ การแสดงข้อมูลด้วยภาพสามารถเปิดเผยรูปแบบที่ซ่อนอยู่ หรือช่วยให้คุณเข้าใจว่าเกิดอะไรขึ้น หรืออาจตั้งคำถามเพิ่มเติม คุณยังอาจต้องการสร้างแบบจำลองข้อมูลของคุณโดยใช้สถิติพื้นฐาน หรือแบบจำลองการเรียนรู้ของเครื่อง และหวังว่าจะได้รับข้อมูลเชิงลึก แน่นอน คุณต้องสื่อสารสิ่งที่ค้นพบและคำถามกับผู้มีส่วนได้ส่วนเสียอื่นๆ ในโครงการ
เมื่อคุณคุ้นเคยกับเครื่องมือต่างๆ ที่พร้อมใช้งานสำหรับแต่ละกระบวนการเหล่านี้มากพอแล้ว คุณสามารถเริ่มสร้างไปป์ไลน์แบบกำหนดเองของคุณที่เจาะจงสำหรับเว็บไซต์บางแห่ง เนื่องจากทุกธุรกิจมีเอกลักษณ์เฉพาะตัว และมีข้อกำหนดพิเศษชุดหนึ่ง ในที่สุด คุณจะเริ่มค้นหารูปแบบและไม่ต้องทำงานใหม่ทั้งหมดสำหรับโครงการ/เว็บไซต์ที่คล้ายคลึงกัน
มีเครื่องมือและไลบรารีมากมายที่พร้อมใช้งานสำหรับแต่ละองค์ประกอบในกระบวนการนี้ และอาจใช้งานได้ค่อนข้างมาก ซึ่งเครื่องมือที่คุณเลือก (และใช้เวลาของคุณในการเรียนรู้) มาดูแนวทางที่เป็นไปได้ที่ฉันพบว่ามีประโยชน์ในการเลือกเครื่องมือที่ฉันใช้
ทางเลือกของเครื่องมือและการแลกเปลี่ยน (3 วิธีในการมีพิซซ่า)
คุณควรใช้ excel ในการทำงานประจำวันในการประมวลผลข้อมูลหรือว่าคุ้มค่ากับความเจ็บปวดในการเรียนรู้ Python หรือไม่?
คุณควรสร้างภาพด้วยบางอย่างเช่น Power BI หรือคุณควรลงทุนในการเรียนรู้เกี่ยวกับไวยากรณ์ของกราฟิก และเรียนรู้วิธีใช้ไลบรารีที่ปรับใช้
คุณจะสร้างผลงานที่ดีขึ้นด้วยการสร้างแดชบอร์ดเชิงโต้ตอบของคุณเองด้วย R หรือ Python หรือคุณควรไปกับ Google Data Studio หรือไม่
ขั้นแรก มาสำรวจข้อแลกเปลี่ยนที่เกี่ยวข้องกับการเลือกเครื่องมือต่างๆ ในระดับต่าง ๆ ของสิ่งที่เป็นนามธรรม นี่เป็นข้อความที่ตัดตอนมาจากหนังสือของฉันเกี่ยวกับการสร้างแดชบอร์ดแบบโต้ตอบและแอปข้อมูลด้วย Plotly และ Dash และฉันพบว่าวิธีนี้มีประโยชน์:
พิจารณาสามวิธีในการกินพิซซ่า:
- วิธีการสั่งซื้อ: คุณโทรหาร้านอาหารและสั่งพิซซ่าของคุณ มันมาถึงหน้าประตูของคุณในครึ่งชั่วโมง และคุณเริ่มกิน
- แนวทางของซูเปอร์มาร์เก็ต: คุณไปซูเปอร์มาร์เก็ต ซื้อแป้ง ชีส ผัก และส่วนผสมอื่นๆ ทั้งหมด จากนั้นคุณทำพิซซ่าด้วยตัวเอง
- แนวทางการทำฟาร์ม: คุณปลูกมะเขือเทศในสวนหลังบ้านของคุณ คุณเลี้ยงวัว รีดนม แปลงนมเป็นชีส และอื่นๆ
เมื่อเราไปถึงอินเทอร์เฟซระดับสูง ไปสู่แนวทางการสั่งซื้อ ปริมาณความรู้ที่ต้องการลดลงอย่างมาก คนอื่นเป็นผู้รับผิดชอบ และคุณภาพจะถูกตรวจสอบโดยกลไกตลาดของชื่อเสียงและการแข่งขัน
ราคาที่เราจ่ายสำหรับสิ่งนี้คือเสรีภาพและทางเลือกที่ลดลง ร้านอาหารแต่ละร้านมีตัวเลือกมากมายให้คุณเลือก และคุณต้องเลือกจากตัวเลือกเหล่านั้น
เมื่อลงไปที่ระดับที่ต่ำกว่า ปริมาณความรู้ที่ต้องการเพิ่มขึ้น เราต้องจัดการกับความซับซ้อนมากขึ้น เรามีความรับผิดชอบต่อผลลัพธ์มากขึ้น และต้องใช้เวลามากขึ้น สิ่งที่เราได้รับคืออิสระและอำนาจที่มากขึ้นในการปรับแต่งผลลัพธ์ในแบบที่เราต้องการ ต้นทุนก็เป็นประโยชน์หลักเช่นกัน แต่ในขนาดที่ใหญ่เพียงพอเท่านั้น ถ้าจะทานแค่พิซซ่าวันนี้ สั่งเลยน่าจะถูกกว่า แต่ถ้าคุณวางแผนที่จะมีทุกวัน คุณจะสามารถประหยัดค่าใช้จ่ายได้มากหากคุณทำเอง
นี่คือตัวเลือกประเภทต่างๆ ที่คุณจะต้องทำเมื่อเลือกเครื่องมือที่จะใช้และเรียนรู้ การใช้ภาษาโปรแกรมอย่าง R หรือ Python นั้นต้องการงานมากกว่ามากและยากกว่า Excel ด้วยประโยชน์ที่จะทำให้คุณมีประสิทธิภาพและประสิทธิผลมากขึ้น
การเลือกก็มีความสำคัญสำหรับเครื่องมือหรือกระบวนการแต่ละอย่าง ตัวอย่างเช่น คุณอาจใช้โปรแกรมรวบรวมข้อมูลระดับสูงและใช้งานง่ายเพื่อรวบรวมข้อมูลเกี่ยวกับเว็บไซต์ แต่คุณอาจต้องการใช้ภาษาการเขียนโปรแกรมเพื่อแสดงข้อมูลด้วยตัวเลือกที่มีทั้งหมด การเลือกเครื่องมือที่เหมาะสมสำหรับกระบวนการที่เหมาะสมนั้นขึ้นอยู่กับความต้องการของคุณ และการประนีประนอมที่อธิบายข้างต้นสามารถช่วยในการตัดสินใจเลือกได้ หวังว่าสิ่งนี้จะช่วยตอบคำถามว่าคุณต้องการเรียนรู้ Python หรือ R หรือไม่ (หรือเท่าไหร่)
มาดูคำถามนี้กันอีกสักหน่อยและดูว่าเหตุใดการเรียนรู้ Python สำหรับ SEO จึงอาจไม่ใช่คีย์เวิร์ดที่ถูกต้อง
ทำไม “python for seo” ถึงทำให้เข้าใจผิด
คุณต้องการที่จะเป็นบล็อกเกอร์ที่ยอดเยี่ยมหรือต้องการเรียนรู้ WordPress หรือไม่?
คุณต้องการที่จะเป็นนักออกแบบกราฟิกหรือเป็นเป้าหมายของคุณในการเรียนรู้ Photoshop หรือไม่?
คุณสนใจที่จะส่งเสริมอาชีพ SEO ของคุณโดยนำทักษะด้านข้อมูลของคุณไปสู่อีกระดับหรือต้องการเรียนรู้ Python หรือไม่?
ในช่วงห้านาทีแรกของการบรรยายครั้งแรกของหลักสูตรวิทยาการคอมพิวเตอร์ใน MIT ศาสตราจารย์ Harold Abelson ได้เปิดหลักสูตรโดยบอกกับนักเรียนว่าเหตุใด "วิทยาการคอมพิวเตอร์" จึงเป็นชื่อที่ไม่ดีสำหรับสาขาวิชาที่พวกเขากำลังจะเรียนรู้ ฉันคิดว่ามันน่าสนใจมากที่จะดูห้านาทีแรกของการบรรยาย:
เมื่อบางสาขาเพิ่งเริ่มต้น และคุณไม่เข้าใจจริงๆ เป็นอย่างดี เป็นเรื่องง่ายมากที่จะสร้างความสับสนให้กับสาระสำคัญของสิ่งที่คุณทำ ด้วยเครื่องมือที่คุณใช้ – ฮาโรลด์ อาเบลสัน
เรากำลังพยายามปรับปรุงสถานะออนไลน์และผลลัพธ์ของเรา สิ่งที่เราทำหลายอย่างขึ้นอยู่กับความเข้าใจ การแสดงภาพ การจัดการและการจัดการข้อมูลโดยทั่วไป และนี่คือจุดสนใจของเรา โดยไม่คำนึงถึงเครื่องมือที่ใช้ Data Science เป็นสาขาที่มีกรอบความคิดทางปัญญาในการทำเช่นนั้น เช่นเดียวกับเครื่องมือมากมายที่จะนำไปใช้ในสิ่งที่เราต้องการจะทำ Python อาจเป็นภาษาการเขียนโปรแกรม (เครื่องมือ) ที่คุณเลือก และการเรียนรู้ให้ดีเป็นสิ่งสำคัญอย่างยิ่ง ในกรณีของเรา สิ่งที่สำคัญกว่าคือต้องให้ความสำคัญกับ “สาระสำคัญของสิ่งที่คุณกำลังทำ” การประมวลผลและวิเคราะห์ข้อมูล หากไม่มีความสำคัญมากกว่านั้นก็สำคัญเช่นกัน
จุดเน้นหลักควรอยู่ที่กระบวนการที่กล่าวถึงข้างต้น (การนำเข้า การจัดระเบียบ การสร้างภาพ ฯลฯ) แทนที่จะเป็นภาษาโปรแกรมที่เลือก หรือดีกว่า วิธีการใช้ภาษาโปรแกรมนั้นเพื่อให้งานของคุณสำเร็จ แทนที่จะเรียนรู้ภาษาโปรแกรมง่ายๆ
ใครจะสนเกี่ยวกับความแตกต่างทางทฤษฎีเหล่านี้ถ้าฉันจะเรียน Python ล่ะ?
มาดูกันว่าจะเกิดอะไรขึ้นหากคุณจดจ่อกับการเรียนรู้เกี่ยวกับเครื่องมือนี้ แทนที่จะเป็นแก่นแท้ของสิ่งที่คุณกำลังทำอยู่ ในที่นี้ เราเปรียบเทียบการค้นหา "เรียนรู้ wordpress" (เครื่องมือ) กับ "เรียนรู้การเขียนบล็อก" (สิ่งที่เราต้องการทำ):
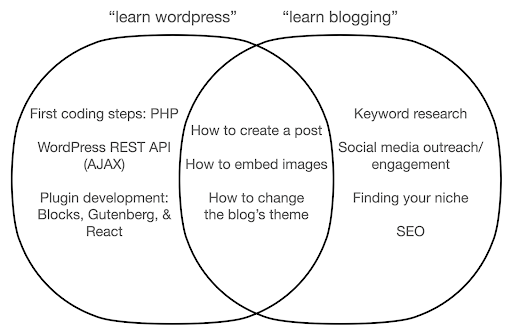
แผนภาพแสดงหัวข้อที่เป็นไปได้ภายใต้หนังสือหรือหลักสูตรที่สอนเกี่ยวกับคำหลักที่ด้านบน พื้นที่ทางแยกตรงกลางแสดงหัวข้อที่อาจจะเกิดขึ้นในรายวิชา/หนังสือทั้งสองประเภท
หากคุณมุ่งเน้นที่เครื่องมือ คุณจะต้องเรียนรู้เกี่ยวกับสิ่งที่คุณไม่ต้องการจริงๆ โดยเฉพาะอย่างยิ่งในฐานะมือใหม่อย่างไม่ต้องสงสัย หัวข้อเหล่านี้อาจทำให้คุณสับสนและหงุดหงิด โดยเฉพาะอย่างยิ่งหากคุณไม่มีพื้นฐานด้านเทคนิคหรือการเขียนโปรแกรม
คุณยังจะได้เรียนรู้สิ่งต่าง ๆ ที่เป็นประโยชน์ต่อการเป็นบล็อกเกอร์ที่ดี (หัวข้อบริเวณทางแยก) หัวข้อเหล่านี้สอนได้ง่ายมาก (วิธีสร้างโพสต์บนบล็อก) แต่อย่าบอกคุณมากว่าทำไมคุณจึงควรบล็อก เมื่อใด และเกี่ยวกับอะไร นี่ไม่ใช่ความผิดในหนังสือที่เน้นเครื่องมือ เพราะเมื่อเรียนรู้เกี่ยวกับเครื่องมือแล้ว การเรียนรู้วิธีสร้างโพสต์บนบล็อกก็เพียงพอแล้วและไปต่อ
ในฐานะบล็อกเกอร์ คุณน่าจะสนใจในเหตุผลและเหตุผลของการเขียนบล็อกมากกว่า ซึ่งจะไม่ครอบคลุมถึงหนังสือที่เน้นเครื่องมือ
เห็นได้ชัดว่ากลยุทธ์และสิ่งสำคัญ เช่น SEO การค้นหาเฉพาะกลุ่มของคุณ และอื่นๆ จะไม่ครอบคลุม ดังนั้นคุณจะพลาดสิ่งที่สำคัญมาก
หัวข้อ Data Science ใดบ้างที่คุณอาจไม่เคยเรียนรู้ในหนังสือการเขียนโปรแกรม
อย่างที่เราเห็น การเลือก Python หรือหนังสือการเขียนโปรแกรมอาจหมายความว่าคุณต้องการเป็นวิศวกรซอฟต์แวร์ หัวข้อจะมุ่งไปที่จุดสิ้นสุดนั้นโดยธรรมชาติ หากคุณมองหาหนังสือ Data Science คุณจะได้รับหัวข้อและเครื่องมือที่เหมาะกับการวิเคราะห์ข้อมูลมากขึ้น
เราสามารถใช้ไดอะแกรมแรก (แสดงวงจรของ Data Science) เป็นแนวทาง และค้นหาหัวข้อเหล่านั้นในเชิงรุก: "นำเข้าข้อมูลด้วย python", "จัดระเบียบข้อมูลด้วย r", "แสดงข้อมูลด้วย python" เป็นต้น มาดูหัวข้อเหล่านั้นให้ลึกซึ้งยิ่งขึ้นและสำรวจเพิ่มเติมกัน:
นำเข้า
โดยธรรมชาติแล้วเราต้องได้รับข้อมูลบางอย่างก่อน นี้สามารถ:
- ไฟล์บนคอมพิวเตอร์ของเรา: กรณีตรงไปตรงมาที่สุดที่คุณเพียงแค่เปิดไฟล์ด้วยภาษาโปรแกรมที่คุณเลือก สิ่งสำคัญคือต้องทราบว่ามีรูปแบบไฟล์ต่างๆ มากมาย และคุณมีตัวเลือกมากมายในขณะเปิด/อ่านไฟล์ ตัวอย่างเช่น ฟังก์ชัน read_csv จากไลบรารี pandas (เครื่องมือจัดการข้อมูลที่จำเป็นใน Python) มี 50 ตัวเลือกให้เลือกขณะเปิดไฟล์ ประกอบด้วยสิ่งต่างๆ เช่น เส้นทางของไฟล์ คอลัมน์สำหรับเลือก จำนวนแถวที่จะเปิด การตีความออบเจ็กต์วันที่และเวลา วิธีจัดการกับค่าที่หายไป และอื่นๆ อีกมากมาย สิ่งสำคัญคือต้องทำความคุ้นเคยกับตัวเลือกเหล่านั้น และข้อควรพิจารณาต่างๆ ในขณะที่เปิดรูปแบบไฟล์ต่างๆ นอกจากนี้ แพนด้ายังมีฟังก์ชันต่างๆ กว่า 19 ฟังก์ชันที่ขึ้นต้นด้วย read_ สำหรับไฟล์และรูปแบบข้อมูลต่างๆ
- ส่งออกจากเครื่องมือออนไลน์: คุณอาจคุ้นเคยกับสิ่งนี้ และที่นี่คุณสามารถปรับแต่งข้อมูลของคุณแล้วส่งออก หลังจากนั้นคุณจะเปิดเป็นไฟล์บนคอมพิวเตอร์ของคุณ
- การเรียก API เพื่อรับข้อมูลเฉพาะ: นี่คือระดับที่ต่ำกว่า และใกล้เคียงกับแนวทางฟาร์มที่กล่าวถึงข้างต้น ในกรณีนี้ คุณส่งคำขอที่มีข้อกำหนดเฉพาะและรับข้อมูลที่ต้องการกลับคืนมา ข้อดีคือคุณสามารถปรับแต่งสิ่งที่คุณต้องการได้อย่างแม่นยำ และจัดรูปแบบในลักษณะที่อาจไม่มีในอินเทอร์เฟซออนไลน์ ตัวอย่างเช่น ใน Google Analytics คุณสามารถเพิ่มมิติข้อมูลรองลงในตารางที่คุณกำลังวิเคราะห์ แต่คุณไม่สามารถเพิ่มมิติข้อมูลที่สามได้ คุณยังถูกจำกัดด้วยจำนวนแถวที่คุณสามารถส่งออกได้ API ช่วยให้คุณมีความยืดหยุ่นมากขึ้น และคุณยังสามารถทำให้การเรียกบางอย่างเกิดขึ้นโดยอัตโนมัติเป็นระยะๆ ได้ โดยเป็นส่วนหนึ่งของไปป์ไลน์การรวบรวม/วิเคราะห์ข้อมูลที่ใหญ่ขึ้น
- การรวบรวมข้อมูลและการขูดข้อมูล: คุณอาจมีโปรแกรมรวบรวมข้อมูลที่คุณชื่นชอบ และน่าจะคุ้นเคยกับกระบวนการนี้ นี่เป็นกระบวนการที่ยืดหยุ่นอยู่แล้ว ทำให้เราสามารถแยกองค์ประกอบที่กำหนดเองออกจากหน้าเว็บ รวบรวมข้อมูลเฉพาะบางหน้าเท่านั้น และอื่นๆ
- การผสมผสานวิธีการต่างๆ ที่เกี่ยวข้องกับระบบอัตโนมัติ การดึงข้อมูลแบบกำหนดเอง และอาจเป็นไปได้ว่าแมชชีนเลิร์นนิงสำหรับการใช้งานพิเศษ
เมื่อเรามีข้อมูลบางอย่างแล้ว เราต้องการไปยังระดับถัดไป
เรียบร้อย
ชุดข้อมูล "เป็นระเบียบเรียบร้อย" คือชุดข้อมูลที่มีการจัดระเบียบในลักษณะเฉพาะ นอกจากนี้ยังเรียกว่าข้อมูล "รูปแบบยาว" บทที่ 12 ในหนังสือ R for Data Science กล่าวถึงแนวคิดเกี่ยวกับข้อมูลที่เป็นระเบียบเรียบร้อยในรายละเอียดเพิ่มเติมหากคุณสนใจ
ดูตารางทั้งสามด้านล่างและพยายามค้นหาความแตกต่าง:
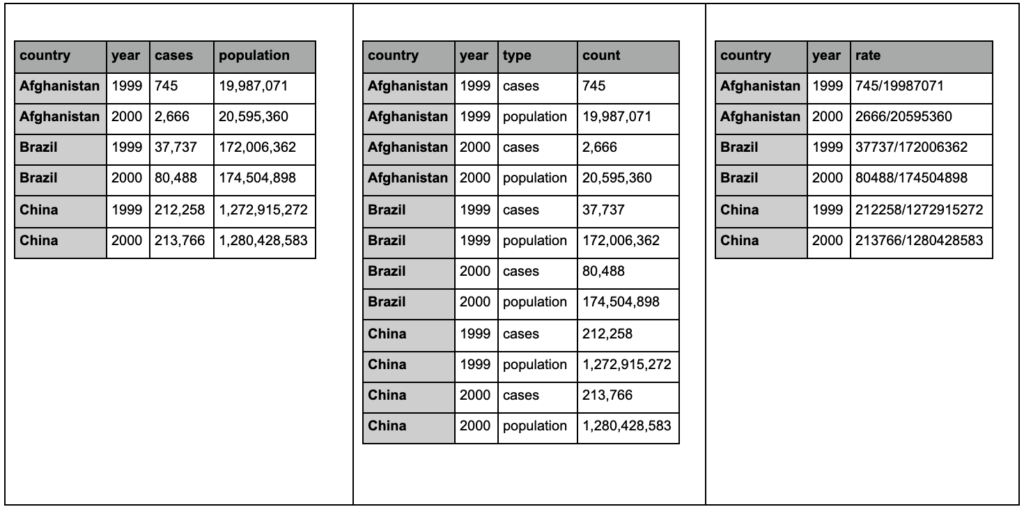
ตารางตัวอย่างจากแพ็คเกจ tidyr
คุณจะพบว่าตารางทั้งสามมีข้อมูลที่เหมือนกันทุกประการ แต่มีการจัดระเบียบและนำเสนอในรูปแบบต่างๆ เราสามารถมีกรณีและประชากรในสองคอลัมน์แยกกัน (ตารางที่ 1) หรือมีคอลัมน์สำหรับบอกเราว่าการสังเกตคืออะไร (กรณีหรือประชากร) และคอลัมน์ "นับ" เพื่อนับกรณีเหล่านั้น (ตารางที่ 2) ในตารางที่ 3 จะแสดงเป็นอัตรา
เมื่อต้องจัดการกับข้อมูล คุณจะพบว่าแหล่งข้อมูลต่างๆ จัดระเบียบข้อมูลต่างกัน และมักจะต้องเปลี่ยนจาก/เป็นรูปแบบบางรูปแบบเพื่อการวิเคราะห์ที่ดีและง่ายขึ้น การทำความคุ้นเคยกับการดำเนินการทำความสะอาดเหล่านี้เป็นสิ่งสำคัญ และชุดจัดระเบียบใน R มีเครื่องมือพิเศษสำหรับการดำเนินการดังกล่าว คุณยังสามารถใช้แพนด้าได้หากต้องการ Python และคุณสามารถตรวจสอบฟังก์ชันการละลายและการหมุนของแพนด้าได้
เมื่อข้อมูลของเราอยู่ในรูปแบบใดรูปแบบหนึ่งแล้ว เราอาจต้องการจัดการข้อมูลต่อไป
แปลง
ทักษะที่สำคัญอีกประการหนึ่งในการสร้างคือความสามารถในการเปลี่ยนแปลงอะไรก็ได้ที่คุณต้องการกับข้อมูลที่คุณกำลังทำงานด้วย สถานการณ์ในอุดมคติคือการไปถึงขั้นตอนที่คุณสามารถสนทนากับข้อมูลของคุณ และสามารถแบ่งส่วนและแยกแยะวิธีที่คุณต้องการถามคำถามเฉพาะเจาะจง และหวังว่าจะได้รับข้อมูลเชิงลึกที่น่าสนใจ ต่อไปนี้คืองานการเปลี่ยนแปลงที่สำคัญที่สุดบางส่วนที่คุณน่าจะต้องการมากด้วยงานตัวอย่างที่คุณอาจสนใจ:
หลังจากได้รับ จัดระเบียบ และใส่ข้อมูลของเราในรูปแบบที่ต้องการแล้ว จะเป็นการดีที่จะเห็นภาพนั้น
เห็นภาพ
การสร้างภาพข้อมูลเป็นหัวข้อขนาดใหญ่ และมีหนังสือทั้งเล่มในหัวข้อย่อยบางส่วน เป็นหนึ่งในสิ่งเหล่านี้ที่สามารถให้ข้อมูลเชิงลึกมากมายเกี่ยวกับข้อมูลของเรา โดยเฉพาะอย่างยิ่งการใช้องค์ประกอบภาพที่ใช้งานง่ายเพื่อสื่อสารข้อมูล ความสูงสัมพัทธ์ของแท่งกราฟในแผนภูมิแท่งจะแสดงให้เราเห็นปริมาณสัมพัทธ์ในทันที เช่น ความเข้มของสี ตำแหน่งสัมพัทธ์ และคุณลักษณะทางภาพอื่นๆ อีกมากมายสามารถจดจำและเข้าใจได้ง่ายโดยผู้อ่าน
แผนภูมิที่ดีมีค่าหนึ่งพันคำ (คีย์)!
เนื่องจากมีหัวข้อมากมายที่ต้องดำเนินการเกี่ยวกับการแสดงข้อมูลเป็นภาพ ฉันจะแบ่งปันตัวอย่างบางส่วนที่อาจน่าสนใจ หลายรายการเป็นส่วนสำคัญสำหรับแดชบอร์ดข้อมูลความยากจนนี้ หากคุณต้องการรายละเอียดทั้งหมด
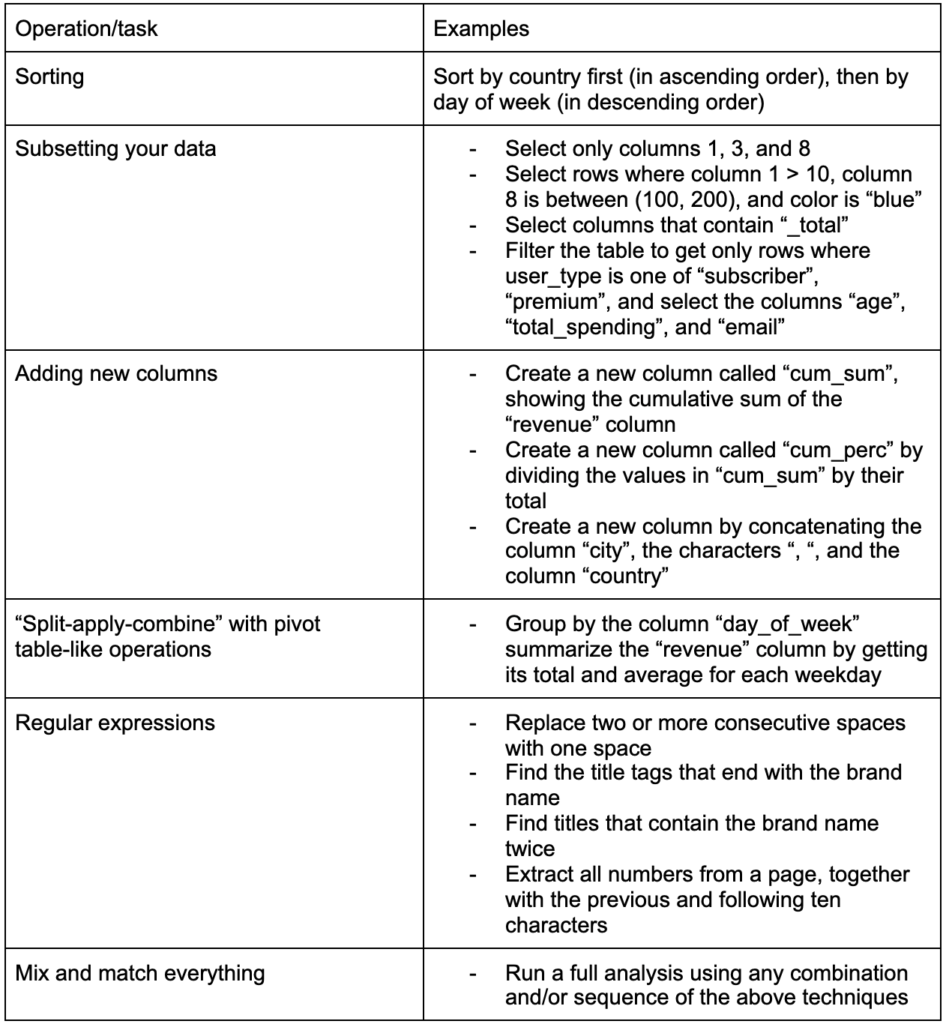
ในบางครั้ง แผนภูมิแท่งแบบธรรมดาก็เป็นสิ่งที่คุณอาจต้องเปรียบเทียบในบางครั้ง ซึ่งสามารถแสดงแท่งในแนวตั้งหรือแนวนอนได้:
คุณอาจสนใจที่จะสำรวจบางประเทศและเจาะลึกโดยดูว่าพวกเขาก้าวหน้าไปอย่างไรในบางเมตริก ในกรณีนี้ คุณอาจต้องการแสดงแผนภูมิแท่งหลายอันในพล็อตเดียวกัน:
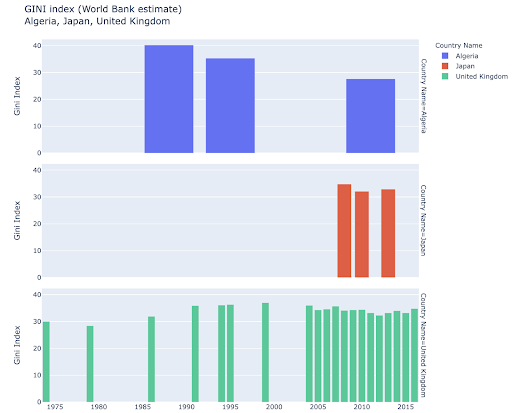
การเปรียบเทียบหลายค่าสำหรับการสังเกตหลายครั้งอาจทำได้โดยการวางแท่งหลายแท่งในตำแหน่งแกน X แต่ละตำแหน่ง ต่อไปนี้คือวิธีหลักในการทำเช่นนี้:
การเลือกระดับสีและสี: ส่วนสำคัญของการแสดงข้อมูลเป็นภาพ และบางสิ่งที่สามารถสื่อสารข้อมูลได้อย่างมีประสิทธิภาพอย่างยิ่งและโดยสัญชาตญาณหากทำถูกต้อง
ระดับสีตามหมวดหมู่: มีประโยชน์สำหรับการแสดงข้อมูลหมวดหมู่ ตามชื่อที่แนะนำ นี่คือประเภทของข้อมูลที่แสดงว่าการสังเกตนั้นอยู่ในหมวดหมู่ใด ในกรณีนี้ เราต้องการสีที่แยกจากกันมากที่สุดเพื่อแสดงความแตกต่างที่ชัดเจนในหมวดหมู่ (โดยเฉพาะอย่างยิ่งสำหรับองค์ประกอบภาพที่แสดงติดกัน)
ตัวอย่างต่อไปนี้ใช้ระดับสีตามหมวดหมู่เพื่อแสดงว่าระบบของรัฐบาลใดที่ดำเนินการในแต่ละประเทศ การเชื่อมโยงสีของประเทศต่างๆ เข้ากับตำนานที่แสดงให้เห็นว่าใช้ระบบการปกครองใดเป็นเรื่องง่าย นี่เรียกอีกอย่างว่าแผนที่ choropleth:
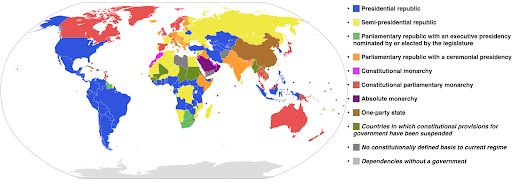
ที่มา: Wikipedia
บางครั้งข้อมูลที่เราต้องการแสดงเป็นภาพสำหรับตัวชี้วัดเดียวกัน และแต่ละประเทศ (หรือการสังเกตประเภทอื่น) จะตกอยู่ที่จุดใดจุดหนึ่งในความต่อเนื่องตั้งแต่จุดต่ำสุดและสูงสุด กล่าวอีกนัยหนึ่ง เราต้องการเห็นภาพองศาของเมตริกนั้น
ในกรณีเหล่านี้ เราจำเป็นต้องค้นหา มาตราส่วนสีต่อเนื่อง (หรือตามลำดับ) ในตัวอย่างต่อไปนี้จะเห็นได้ชัดเจนว่าประเทศใดมีสีน้ำเงินมากกว่า (และทำให้มีการเข้าชมมากขึ้น) และเราสามารถเข้าใจความแตกต่างที่ละเอียดอ่อนระหว่างประเทศต่างๆ ได้โดยสัญชาตญาณ
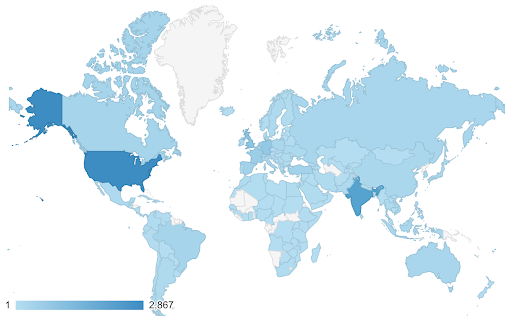
ข้อมูลของคุณอาจต่อเนื่อง (เช่นแผนภูมิแผนที่การจราจรด้านบน) แต่สิ่งสำคัญเกี่ยวกับตัวเลขอาจแตกต่างไปจากจุดใดจุดหนึ่ง สเกลสีที่แยกจากกัน มีประโยชน์ในกรณีนี้
แผนภูมิด้านล่างแสดงอัตราการเติบโตของประชากรสุทธิ ในกรณีนี้ เป็นเรื่องที่น่าสนใจที่จะทราบก่อนว่าประเทศใดประเทศหนึ่งมีอัตราการเติบโตเป็นบวกหรือลบ หรือเราต้องการทราบว่าแต่ละประเทศอยู่ห่างจากศูนย์มากแค่ไหน (และมากน้อยเพียงใด) การดูแผนที่จะแสดงให้เราเห็นว่าประชากรของประเทศใดกำลังเติบโตและประเทศใดกำลังหดตัว ตำนานยังแสดงให้เราเห็นว่าอัตราบวกสูงสุดคือ 3.5% และค่าลบสูงสุดคือ -0.5% นอกจากนี้ยังช่วยให้เราสามารถระบุช่วงของค่าต่างๆ (บวกและลบ)
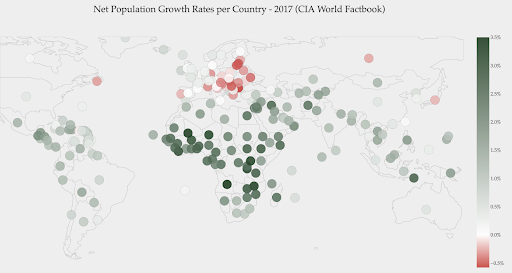
ที่มา : Dashboardom.com
ขออภัย สีที่เลือกสำหรับมาตราส่วนนี้ไม่เหมาะ เนื่องจากคนตาบอดสีอาจไม่สามารถแยกแยะระหว่างสีแดงและสีเขียวได้อย่างถูกต้อง นี่เป็นข้อพิจารณาที่สำคัญมากในการเลือกสเกลสีของเรา
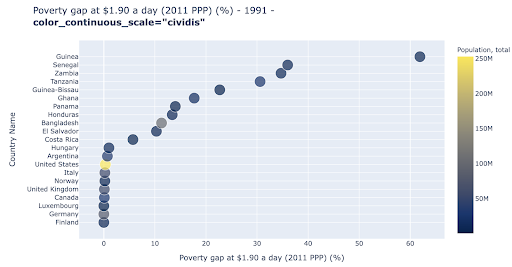
พล็อตกระจายเป็นพล็อต ประเภทหนึ่งที่ใช้กันอย่างแพร่หลายและหลากหลายที่สุด ตำแหน่งของจุด (หรือเครื่องหมายอื่นๆ) บ่งบอกถึงปริมาณที่เราพยายามจะสื่อสาร นอกจากตำแหน่งแล้ว เรายังสามารถใช้คุณลักษณะภาพอื่นๆ อีกหลายอย่าง เช่น สี ขนาด และรูปร่าง เพื่อสื่อสารข้อมูลเพิ่มเติม ตัวอย่างต่อไปนี้แสดงเปอร์เซ็นต์ของประชากรที่อาศัยอยู่ที่ $1.9/วัน ซึ่งเราสามารถเห็นได้ชัดเจนว่าเป็นระยะทางในแนวนอนของจุดต่างๆ
นอกจากนี้เรายังสามารถเพิ่มมิติใหม่ให้กับแผนภูมิของเราโดยใช้สี ซึ่งสอดคล้องกับการแสดงภาพคอลัมน์ที่สามจากชุดข้อมูลเดียวกัน ซึ่งในกรณีนี้จะแสดงข้อมูลประชากร
ตอนนี้เราสามารถเห็นได้ว่ากรณีที่รุนแรงที่สุดในแง่ของจำนวนประชากร (สหรัฐอเมริกา) นั้นต่ำมากในตัวชี้วัดระดับความยากจน ซึ่งจะเพิ่มความสมบูรณ์ให้กับแผนภูมิของเรา เรายังสามารถใช้ขนาดและรูปร่างเพื่อแสดงภาพคอลัมน์เพิ่มเติมจากชุดข้อมูลของเราได้อีกด้วย เราจำเป็นต้องสร้างสมดุลที่ดีระหว่างความสมบูรณ์และความสามารถในการอ่าน

เราอาจสนใจที่จะตรวจสอบว่ามีความสัมพันธ์ระหว่างประชากรกับระดับความยากจนหรือไม่ และเพื่อให้เราสามารถเห็นภาพชุดข้อมูลเดียวกันในวิธีที่ต่างกันเล็กน้อยเพื่อดูว่ามีความสัมพันธ์ดังกล่าวหรือไม่:
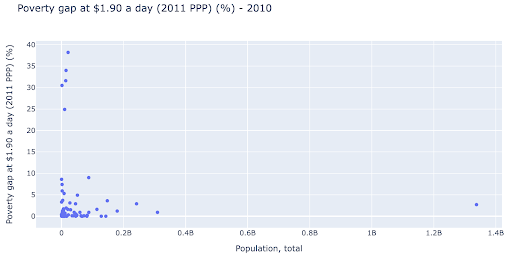
เรามีค่าหนึ่งค่าผิดปกติในประชากรประมาณ 1.35 พันล้านบาท และนี่หมายความว่าเรามีพื้นที่ว่างจำนวนมากในแผนภูมิ ซึ่งหมายความว่าค่าจำนวนมากถูกบีบอัดไว้ในพื้นที่ขนาดเล็กมาก เรายังมีจุดเหลื่อมกันจำนวนมาก ซึ่งทำให้ยากต่อการระบุความแตกต่างหรือแนวโน้มใดๆ
แผนภูมิต่อไปนี้มีข้อมูลเดียวกันแต่แสดงภาพต่างกันโดยใช้สองเทคนิค:
- มาตราส่วนลอการิทึม : เรามักจะเห็นข้อมูลในระดับสารเติมแต่ง กล่าวอีกนัยหนึ่ง ทุกจุดบนแกน (X หรือ Y) แสดงถึงการเพิ่มจำนวนหนึ่งของข้อมูลที่แสดงเป็นภาพ นอกจากนี้เรายังสามารถมีมาตราส่วนการคูณ ซึ่งในกรณีนี้สำหรับจุดใหม่ทุกจุดบนแกน X เราคูณ (ด้วยสิบในตัวอย่างนี้) วิธีนี้ช่วยให้สามารถกระจายคะแนนได้ และเราจำเป็นต้องคิดถึงการทวีคูณแทนที่จะเป็นการเพิ่มเติม ดังที่เรามีในแผนภูมิก่อนหน้านี้
- การใช้เครื่องหมายอื่น (วงกลมว่างขนาดใหญ่) : การเลือกรูปร่างที่แตกต่างกันสำหรับเครื่องหมายของเราช่วยแก้ปัญหา "การวางซ้อน" ซึ่งเราอาจมีหลายจุดวางทับกันในตำแหน่งเดียวกัน ซึ่งทำให้มองเห็นได้ยาก เรามีกี่คะแนน
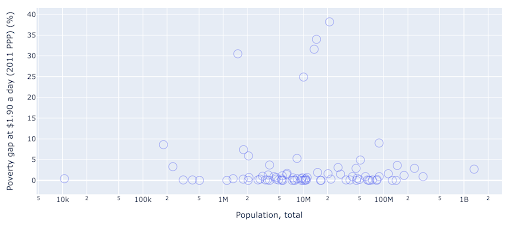
ตอนนี้เราจะเห็นได้ว่ามีกลุ่มประเทศรอบเครื่องหมาย 10 ล้าน และกลุ่มย่อยอื่นๆ ด้วย
ดังที่ฉันได้กล่าวไปแล้ว มีอักขระและตัวเลือกการแสดงภาพอีกหลายประเภท และหนังสือทั้งเล่มที่เขียนเกี่ยวกับหัวข้อนี้ ฉันหวังว่าสิ่งนี้จะช่วยให้คุณมีความคิดที่น่าสนใจในการทดลอง
Oncrawl Data³
 เรียนรู้เพิ่มเติม
เรียนรู้เพิ่มเติมแบบอย่าง
เราจำเป็นต้องลดความซับซ้อนของข้อมูลของเรา และค้นหารูปแบบ คาดการณ์ หรือเพียงแค่ทำความเข้าใจให้ดีขึ้น นี่เป็นหัวข้อใหญ่อีกหัวข้อหนึ่ง และสามารถครอบคลุมได้ตั้งแต่การรับสถิติสรุป (ค่าเฉลี่ย ค่ามัธยฐาน ส่วนเบี่ยงเบนมาตรฐาน ฯลฯ) ไปจนถึงการสร้างแบบจำลองข้อมูลของเราโดยใช้แบบจำลองที่สรุปหรือค้นหาแนวโน้ม ไปจนถึงการใช้เทคนิคที่ซับซ้อนมากขึ้นเพื่อให้ได้ สูตรทางคณิตศาสตร์สำหรับข้อมูลของเรา เรายังใช้แมชชีนเลิร์นนิงเพื่อช่วยให้เราค้นพบข้อมูลเชิงลึกเพิ่มเติมในข้อมูลของเราได้อีกด้วย
อีกครั้ง นี่ไม่ใช่การสนทนาที่สมบูรณ์ในหัวข้อนี้ แต่ฉันอยากจะแบ่งปันตัวอย่างสองสามตัวอย่างที่คุณอาจใช้เทคนิคการเรียนรู้ของเครื่องเพื่อช่วยคุณ
ในชุดข้อมูลการรวบรวมข้อมูล ฉันพยายามเรียนรู้เพิ่มเติมเล็กน้อยเกี่ยวกับหน้า 404 และหากฉันสามารถค้นพบบางอย่างเกี่ยวกับหน้าเหล่านั้น ความพยายามครั้งแรกของฉันคือตรวจสอบว่ามีความสัมพันธ์กันระหว่างขนาดของหน้าและรหัสสถานะของหน้าหรือไม่ และมี – ความสัมพันธ์ที่เกือบจะสมบูรณ์แบบ!
ฉันรู้สึกเหมือนเป็นอัจฉริยะเพียงไม่กี่นาที และกลับมายังดาวเคราะห์โลกอย่างรวดเร็ว
หน้า 404 หน้าทั้งหมดอยู่ในช่วงขนาดหน้าแคบ ซึ่งหน้าเกือบทั้งหมดที่มีจำนวนกิโลไบต์ที่แน่นอนมีรหัสสถานะ 404 จากนั้นฉันก็รู้ว่า 404 หน้าตามคำจำกัดความไม่มีเนื้อหาใด ๆ นอกเหนือจาก "หน้าข้อผิดพลาด 404"! และนั่นเป็นสาเหตุที่พวกมันมีขนาดเท่ากัน
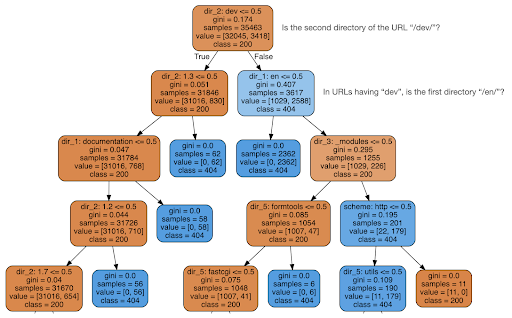
ฉันจึงตัดสินใจตรวจสอบว่าเนื้อหาสามารถบอกบางอย่างเกี่ยวกับรหัสสถานะได้หรือไม่ ดังนั้นฉันจึงแยก URL ออกเป็นองค์ประกอบ และเรียกใช้ตัวแยกประเภทแผนผังการตัดสินใจโดยใช้ sklearn โดยพื้นฐานแล้วนี่เป็นเทคนิคที่สร้างแผนผังการตัดสินใจ ซึ่งการปฏิบัติตามกฎเกณฑ์ดังกล่าวอาจทำให้เราเรียนรู้วิธีค้นหาเป้าหมาย 404 หน้าในกรณีนี้
ในแผนผังการตัดสินใจต่อไปนี้ บรรทัดแรกในแต่ละช่องแสดงกฎที่ต้องปฏิบัติตามหรือตรวจสอบ บรรทัด "ตัวอย่าง" คือจำนวนการสังเกตที่พบในช่องนี้ และบรรทัด "ชั้นเรียน" จะบอกเราถึงชั้นเรียนของการสังเกตปัจจุบัน ในกรณีนี้ รหัสสถานะของมันคือ 200 หรือ 404 หรือไม่
ฉันจะไม่ลงรายละเอียดเพิ่มเติม และฉันรู้ว่าแผนผังการตัดสินใจอาจไม่ชัดเจนหากคุณไม่คุ้นเคย และคุณสามารถสำรวจชุดข้อมูลการรวบรวมข้อมูลดิบและโค้ดการวิเคราะห์ได้หากคุณสนใจ
โดยพื้นฐานแล้วสิ่งที่ผังการตัดสินใจค้นพบคือวิธีค้นหาหน้า 404 เกือบทั้งหมดโดยใช้โครงสร้างไดเรกทอรีของ URL อย่างที่คุณเห็น เราพบ URL 3,617 รายการ เพียงแค่ตรวจสอบว่าไดเร็กทอรีที่สองของ URL เป็น “/dev/” หรือไม่ (กล่องสีฟ้าอ่อนกล่องแรกในบรรทัดที่สองจากด้านบน) ตอนนี้เรารู้วิธีค้นหา 404 ของเราแล้ว และดูเหมือนว่าเกือบทั้งหมดจะอยู่ในส่วน “/dev/” ของเว็บไซต์ นี่เป็นการประหยัดเวลาได้มากอย่างแน่นอน ลองจินตนาการถึงการใช้โครงสร้าง URL และชุดค่าผสมที่เป็นไปได้ทั้งหมดด้วยตนเองเพื่อค้นหากฎนี้
เรายังไม่มีภาพรวมและสาเหตุที่สิ่งนี้เกิดขึ้น และสามารถติดตามต่อไปได้ แต่อย่างน้อยตอนนี้ เราก็หา URL เหล่านั้นได้อย่างง่ายดายมาก
เทคนิคอื่นที่คุณอาจสนใจใช้คือ KMeans clustering ซึ่งจัดกลุ่มจุดข้อมูลออกเป็นกลุ่ม/คลัสเตอร์ต่างๆ นี่คือเทคนิค "การเรียนรู้แบบไม่มีผู้ดูแล" ซึ่งอัลกอริธึมช่วยให้เราค้นพบรูปแบบที่เราไม่รู้ว่ามีอยู่จริง
ลองนึกภาพคุณมีตัวเลขจำนวนหนึ่ง สมมติว่าจำนวนประชากรของประเทศต่างๆ และคุณต้องการจัดกลุ่มเป็นสองกลุ่ม กลุ่มใหญ่และกลุ่มเล็ก คุณจะทำอย่างนั้นได้อย่างไร? คุณจะวาดเส้นไหน?
ซึ่งแตกต่างจากการได้สิบอันดับแรกของประเทศหรือ X% แรกของประเทศ นี่จะง่ายมาก เราสามารถจัดเรียงประเทศตามจำนวนประชากร และรับ X อันดับต้น ๆ ตามที่เราต้องการ
เราต้องการจัดกลุ่มเป็น "ใหญ่" และ "เล็ก" เมื่อเทียบกับชุดข้อมูลนี้ และสมมติว่าเราไม่รู้อะไรเกี่ยวกับประชากรในประเทศ
สิ่งนี้สามารถขยายเพิ่มเติมไปสู่การพยายามจัดกลุ่มประเทศออกเป็นสามประเภท: เล็ก กลาง และใหญ่ การดำเนินการด้วยตนเองจะยากขึ้นมาก ถ้าเราต้องการห้า หก หรือหลายกลุ่ม
โปรดทราบว่าเราไม่ทราบว่าแต่ละกลุ่มจะลงเอยกี่ประเทศ เนื่องจากเราไม่ได้ขอประเทศ X อันดับต้นๆ เมื่อจัดเป็น 2 กลุ่ม จะเห็นว่ามีเพียง 2 ประเทศในกลุ่มใหญ่ คือ จีนและอินเดีย สิ่งนี้สมเหตุสมผลโดยสัญชาตญาณ เนื่องจากทั้งสองประเทศนี้มีประชากรเฉลี่ยที่ห่างไกลจากประเทศอื่นๆ ทั้งหมด กลุ่มประเทศนี้มีค่าเฉลี่ยของตัวเองและประเทศในกลุ่มนี้อยู่ใกล้กันมากกว่าประเทศในกลุ่มอื่นๆ:
ประเทศที่จัดกลุ่มเป็นสองกลุ่มตามประชากร 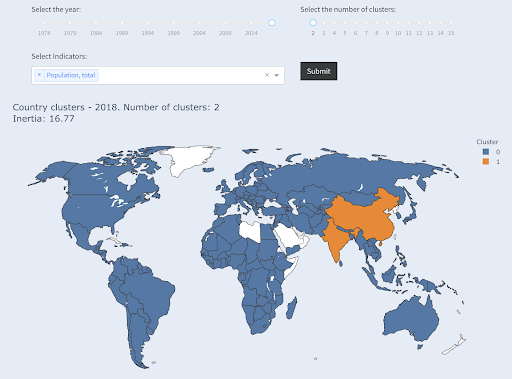
ประเทศที่ใหญ่เป็นอันดับสามในแง่ของประชากร (USA ~ 330M) ถูกจัดกลุ่มกับประเทศอื่นๆ ทั้งหมด รวมถึงประเทศที่มีประชากรหนึ่งล้านคน นั่นเป็นเพราะว่า 330M นั้นใกล้เคียงกับ 1M มากกว่า 1.3 พันล้าน หากเราขอสามกลุ่ม เราก็จะได้ภาพที่ต่างออกไป:
ประเทศที่จัดกลุ่มเป็นสามกลุ่มตามประชากร 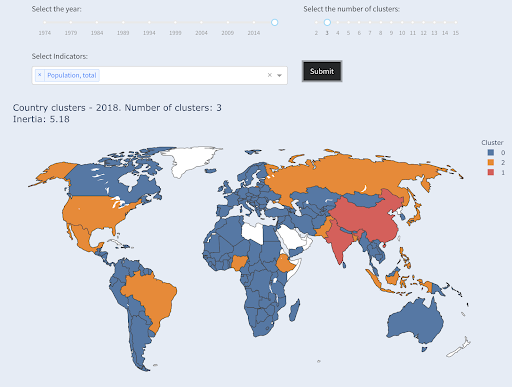
และนี่คือวิธีการรวมกลุ่มของประเทศต่างๆ หากเราขอสี่กลุ่ม:
ประเทศที่จัดกลุ่มเป็นสี่กลุ่มตามประชากร 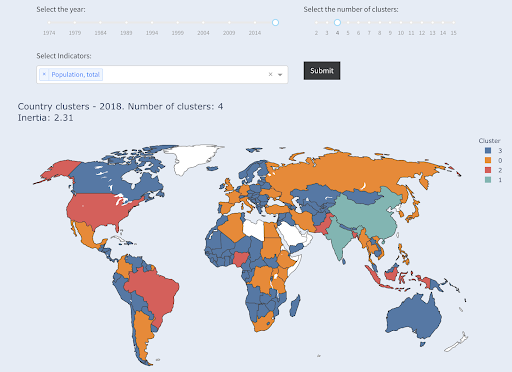
ที่มา: poordata.org (แท็บ "ประเทศในคลัสเตอร์")
นี่คือการจัดกลุ่มโดยใช้มิติข้อมูลเดียวเท่านั้น - ประชากร - ในกรณีนี้ และคุณสามารถเพิ่มมิติข้อมูลเพิ่มเติมได้เช่นกัน และดูว่าประเทศจะจบลงที่ใด
มีเทคนิคและเครื่องมืออื่นๆ มากมาย และนี่เป็นเพียงตัวอย่างบางส่วนที่น่าสนใจและนำไปใช้ได้จริง
ตอนนี้เราพร้อมที่จะสื่อสารสิ่งที่ค้นพบกับผู้ชมของเราแล้ว
สื่อสาร
หลังจากงานทั้งหมดที่เราทำในขั้นตอนก่อนหน้านี้ เราจำเป็นต้องสื่อสารสิ่งที่ค้นพบของเราไปยังผู้มีส่วนได้ส่วนเสียในโครงการอื่น ๆ ในท้ายที่สุด
เครื่องมือที่สำคัญที่สุดอย่างหนึ่งในวิทยาศาสตร์ข้อมูลคือสมุดบันทึกแบบโต้ตอบ โน้ตบุ๊ก Jupyter นั้นใช้กันอย่างแพร่หลายที่สุด และรองรับภาษาการเขียนโปรแกรมเกือบทั้งหมด และคุณอาจต้องการใช้รูปแบบสมุดบันทึกพิเศษของ RStudio ซึ่งทำงานในลักษณะเดียวกัน
แนวคิดหลักคือการมีข้อมูล โค้ด การบรรยาย และการแสดงภาพในที่เดียว เพื่อให้ผู้อื่นสามารถตรวจสอบได้ สิ่งสำคัญคือต้องแสดงให้เห็นว่าคุณได้ข้อสรุปและคำแนะนำเพื่อความโปร่งใส ตลอดจนความสามารถในการทำซ้ำได้อย่างไร คนอื่นๆ ควรจะสามารถเรียกใช้โค้ดเดียวกันและได้ผลลัพธ์แบบเดียวกัน
เหตุผลสำคัญอีกประการหนึ่งคือความสามารถสำหรับผู้อื่น รวมถึง "อนาคตของคุณ" ในการวิเคราะห์เพิ่มเติม และสร้างจากงานแรกเริ่มที่คุณทำ ปรับปรุง และขยายงานในรูปแบบใหม่
แน่นอนว่าสิ่งนี้ถือว่าผู้ชมพอใจกับโค้ด และพวกเขาสนใจมันด้วยซ้ำ!
คุณยังมีตัวเลือกในการส่งออกสมุดบันทึกของคุณเป็น HTML (และรูปแบบอื่นๆ อีกหลายรูปแบบ) โดยไม่รวมโค้ด ดังนั้นคุณจึงได้รับรายงานที่ใช้งานง่าย แต่ยังคงเก็บโค้ดทั้งหมดไว้เพื่อสร้างการวิเคราะห์และผลลัพธ์เดียวกัน
องค์ประกอบที่สำคัญของการสื่อสารคือการแสดงภาพข้อมูล ซึ่งได้กล่าวถึงข้างต้นโดยสังเขป
ยิ่งไปกว่านั้น การแสดงภาพข้อมูลเชิงโต้ตอบ ในกรณีนี้ คุณอนุญาตให้ผู้ชมของคุณเลือกค่า และดูชุดค่าผสมต่างๆ ของแผนภูมิและเมตริกเพื่อสำรวจข้อมูลให้ดียิ่งขึ้น
ต่อไปนี้คือแดชบอร์ดและแอปข้อมูลบางส่วน (บางแอปอาจใช้เวลาโหลดไม่กี่วินาที) ที่ฉันสร้างเพื่อให้คุณทราบถึงสิ่งที่สามารถทำได้
ในท้ายที่สุด คุณยังสามารถสร้างแอปที่กำหนดเองสำหรับโครงการของคุณ เพื่อตอบสนองความต้องการและความต้องการพิเศษ และนี่คือชุดแอป SEO และการตลาดอีกชุดหนึ่งที่อาจน่าสนใจสำหรับคุณ
เราได้ดำเนินการตามขั้นตอนหลักในวัฏจักรของ Data Science แล้ว เรามาสำรวจข้อดีอีกอย่างของ “การเรียนรู้งูหลาม” กัน
Python ใช้สำหรับระบบอัตโนมัติและประสิทธิภาพการทำงาน: จริง แต่ไม่สมบูรณ์
สำหรับฉัน ดูเหมือนว่ามีความเชื่อว่าการเรียนรู้ Python เป็นหลักสำหรับการทำงานให้เกิดประสิทธิผลและ/หรือการทำงานอัตโนมัติ
นี่เป็นเรื่องจริงอย่างยิ่ง และฉันไม่คิดว่าเราจำเป็นต้องพูดถึงคุณค่าของความสามารถในการทำอะไรในเวลาเพียงเสี้ยววินาทีที่เราต้องดำเนินการด้วยตนเอง
อีกส่วนที่ขาดหายไปของอาร์กิวเมนต์คือ การวิเคราะห์ข้อมูล การวิเคราะห์ข้อมูลที่ดีจะให้ข้อมูลเชิงลึกแก่เรา และในอุดมคติแล้ว เราจะสามารถให้ข้อมูลเชิงลึกที่นำไปใช้ได้จริงเพื่อเป็นแนวทางในการตัดสินใจของเรา โดยอิงจากความเชี่ยวชาญและข้อมูลที่เรามี
ส่วนใหญ่ของสิ่งที่เราทำคือการพยายามทำความเข้าใจว่าเกิดอะไรขึ้น วิเคราะห์การแข่งขัน ค้นหาว่าเนื้อหาที่มีค่าที่สุดอยู่ที่ใด ตัดสินใจว่าจะทำอย่างไร และอื่นๆ เราเป็นที่ปรึกษา ที่ปรึกษา และผู้มีอำนาจตัดสินใจ ความสามารถในการรับข้อมูลเชิงลึกจากข้อมูลของเรานั้นเป็นประโยชน์อย่างมาก และพื้นที่และทักษะที่กล่าวถึงในที่นี้สามารถช่วยให้เราบรรลุเป้าหมายนั้นได้
จะเกิดอะไรขึ้นถ้าคุณรู้ว่าแท็กชื่อของคุณมีความยาวเฉลี่ยหกสิบอักขระ จะดีไหม
จะเกิดอะไรขึ้นถ้าคุณขุดลึกลงไปอีกเล็กน้อยและพบว่าชื่อของคุณครึ่งหนึ่งต่ำกว่าหกสิบในขณะที่อีกครึ่งหนึ่งมีตัวละครมากกว่านั้น (ทำให้ค่าเฉลี่ยหกสิบ) In order to get practical and provide good recommendations, you need a higher-resolution view of your title tags' lengths, probably a histogram that shows the frequency of your title tag lengths at each interval so you can have a separate strategy for length. A simple table would also do, for example:
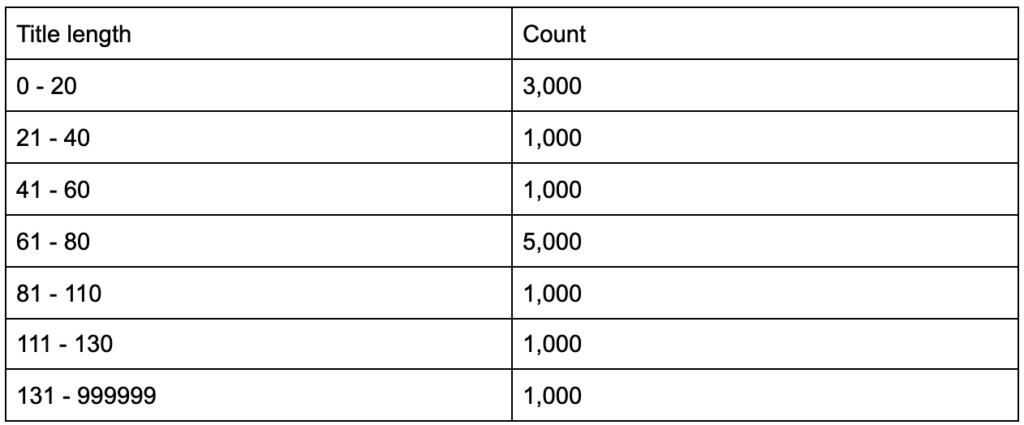
Splitting title lengths by intervals of twenty was an arbitrary decision, and you can split them the way you want. Looking at the table above, and seeing that we have three times more than the average titles in the interval (0, 20), we might want to split it further to better understand what is going on.
Having a better view than the default single-statistic summaries that we get from standard tools, allows us to employ different strategies for different lengths. For example, we can remove the brand name from the titles that are longer than a certain number of characters, and keep it in other titles.
This was an example of very simple insights, which are possible due to the flexibility we get by using a programming language, and a set of data science tools. This also allows us to iterate and modify our approach, until we find a satisfactory point that can take our analysis to the next steps.
Visualization, machine learning, modeling and general data manipulation skills allow us to get better insights on our data, even though those analyses are typically done only once. Still, if you use code to get those insights, you can always take some parts and apply to other projects, or again to the same project. In this case, the insights we got, helped us in our automation, even more. The insights would tell us what needs to be automated and what doesn't.
Should you learn Python?
Is a useless question, and the more useful one is, “How much Python (or R) should you learn?”
My view of how we use computers has evolved in the last few years.
I used to think that there were two main ways of using computers, either you are a regular user, using “point-and-click” applications to do certain tasks, or you are a developer who creates those applications that the rest of us use.

I then realized that it is more like a continuum between very high level use (pizza ordering approach), and the lower levels of the farm approach. I also realized that there is a happy sweet spot in between, where you learn enough programming to get productive and boost your data analysis skills, without having to become a software developer or engineer.
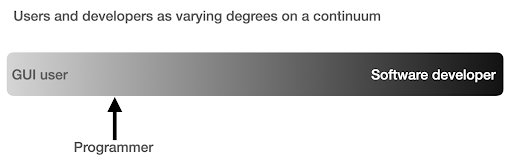
What are the main differences between being a programmer (a software user), and a software developer (or engineer)?
What are the differences between making a great coffee at home, versus establishing and running a cafe?
If making good coffee is one skill, then running a cafe requires ten other skills, most of which have nothing to do with making coffee.
You have to choose a good location (real estate), hire people (management and HR), manage cash flow and finances (accounting and finance), do marketing, legal, manage delivery, adhere to cleanliness and health standards, and so on. You can be a great coffee maker without knowing anything about those fields, but if you want to take it to the next level, you will have to manage all those additional tasks unrelated to making coffee.
The same applies to being a good programmer or data analyst versus being a software developer/engineer. There are so many other things that you have to know and worry about that you don't need as a regular programmer doing stuff for yourself and co-workers and clients. Once you have enough knowledge and skills in programming and data science, you will be in a good position to choose and decide whether you want to continue as an analyst, focusing on data science, or if you want to end up creating software that other people would use.
How do I get into Data Science?
To learn anything I think you have to do two things in parallel:
- Learn the fundamentals and the theory properly: Taking courses and reading books, and getting into the fundamentals can push you forward, as you will be gaining in weeks, knowledge that took decades to establish. It would also immediately give you ideas on things you thought were impossible, or had no idea existed.
- Get as much real world exposure and experience as possible: Experience is always important, and my suggestion is to try as soon as you can to read_csv with Python or R, to actually do so with your GA, GSC, or crawl dataset. See what else you can do (visualize, manipulate, model, etc.). See if you get errors, try to analyze the data only using your programming language.
What does frustration look like, and by when will I get productive?
It's difficult to say, and it depends on your skill, background, the hours you put in, but visualizing it like this might help you on those frustrating unproductive days:
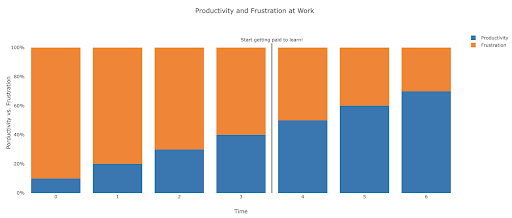
My suggestion is to take a non-trivial task, for example running an SEO audit for a site, only using Python. Your first session will mostly be frustrating, and most of the time will be spent checking documentation, and the definition of basic terms.
In parallel, you are still going through your course, and learning new stuff.
The value of that frustrating session is that it informs and motivates your theoretical learning. You will have questions in mind, and when you learn new things, you will immediately have a place to implement them.
Your next analysis session will probably be a little more productive, but still not productive enough to do at work. You go again to your learning and theory.
Do this enough times, and your time will become mostly productive, eventually you will be doing real work during working hours. The ideal scenario is where you are productive enough to do work, but every time use some time to research better techniques, which improves your work as well. By then you will start to get paid for learning, and your clients will be happily sponsoring you!
Suggested next steps
For the learning path a Data Science course would be great, especially if you get feedback on your work, and you can follow the topics in the order recommended.
If you go with Python I suggest the following libraries:
- pandas: The workhorse of all your tasks in preparing, cleaning, reshaping data whichever way you want. Fluency in pandas allows you to have full control over your data, which will help you immensely in visualization, general analysis, and machine learning
- Plotly and Dash: This is my favorite data visualization library, although there are many others. What I mostly like about it, is that it produces interactive and responsive HTML charts by default. It is very detailed and thorough in its options, yet simple to use. Plotly also includes Plotly Express, which is a high-level plotting tool, which is more intuitive to use, and takes a data-oriented approach (as opposed to a chart-oriented approach). Plotly also created Dash, which is the tool for creating interactive dashboards, but also serves as a full front-end web development framework. Other important data visualization libraries are matplotlib, altair, and bokeh, and for interactive data apps, there is panel and streamlit. Another important feature is that Plotly and Dash are available in all languages used in Data Science. You might use other libraries, and this is just my personal preference. Speaking of personal preferences:
- advertools: This is a library that I created to provide various online marketing tools, most importantly, an SEO crawler, log file parser and compressor, multi robots.txt parser, recursive sitemap parser, SEM keyword and text ad generator for large scale campaigns, weighted frequency word counter, Google SERP downloader, YouTube data API, and a few other tools. It is still evolving, and you are more than welcome to contribute any suggestions, bugs, or issues you might have with it.
These should be enough for beginners, and when you are familiar with them, you can do your own research for more specialized libraries, machine learning and deep learning tools, or libraries that are specialized in performance, or a special niche use-case.