
Data Science para SEO e Marketing Digital: um guia sugerido para iniciantes
Publicados: 2021-12-07Como a maior parte do nosso trabalho gira em torno de dados e como o campo da Ciência de Dados está se tornando muito maior e muito mais acessível para iniciantes, gostaria de compartilhar algumas ideias sobre como você pode entrar nesse campo para aumentar seu SEO e marketing habilidades em geral.
O que é a ciência dos dados?
Um diagrama muito conhecido que é usado para dar uma visão geral deste campo é o diagrama de Venn de Drew Conway mostrando Data Science como a interseção de estatísticas, hacking (habilidades avançadas de programação em geral, e não necessariamente penetrar redes e causar danos) e especialização ou “conhecimento de domínio”:
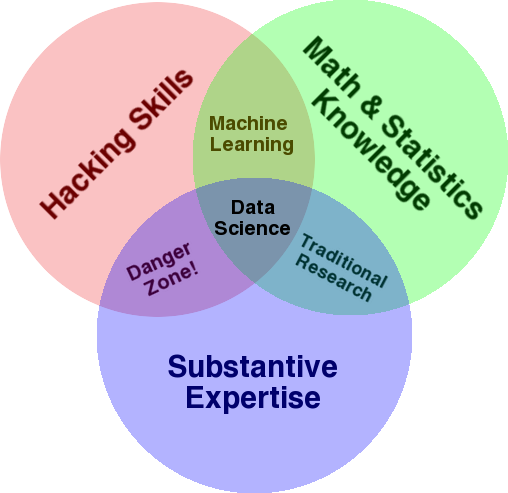
Fonte: oreilly.com
Quando comecei a aprender, rapidamente percebi que isso é exatamente o que já fazemos. A única diferença é que eu estava fazendo isso com ferramentas mais básicas e manuais.
Se você observar o diagrama, verá facilmente como provavelmente já faz isso. Você usa um computador (habilidades de hacking), para analisar dados (estatísticas), para resolver um problema prático usando sua experiência substancial em SEO (ou qualquer especialidade em que você se concentre).
Sua “linguagem de programação” atual provavelmente é uma planilha (Excel, Google Sheets, etc.), e você provavelmente usa Powerpoint ou algo semelhante para comunicar ideias. Vamos expandir um pouco esses elementos.
- Conhecimento de domínio: Vamos começar com sua principal força, pois você já conhece sua área de atuação. Lembre-se de que essa é uma parte essencial de ser um cientista de dados, e é aqui que você pode desenvolver e proteger seu conhecimento. Alguns meses atrás, eu estava discutindo a análise de um conjunto de dados de rastreamento com um amigo meu. Ele é um físico, fazendo pesquisa de pós-doutorado em computadores quânticos. Seus conhecimentos e habilidades em matemática e estatística estão muito além dos meus, e ele realmente sabe analisar dados muito melhor do que eu. Um problema. Ele não sabia o que era um “404” (ou por que nos importaríamos com um “301”). Portanto, com todo o seu conhecimento de matemática, ele não conseguiu entender a coluna "status" no conjunto de dados de rastreamento. Naturalmente, ele não saberia o que fazer com esses dados, com quem falar e quais estratégias construir com base nesses códigos de status (ou se deveria procurar em outro lugar). Você e eu sabemos o que fazer com eles, ou pelo menos sabemos onde mais procurar se quisermos ir mais fundo.
- Matemática e estatística: se você usa o Excel para obter a média de uma amostra de dados, está usando estatísticas. A média é uma estatística que descreve um determinado aspecto de uma amostra de dados. Estatísticas mais avançadas ajudarão a entender seus dados. Isso também é essencial, e não sou especialista nessa área. Quanto mais distribuições estatísticas você estiver familiarizado, mais ideias você terá sobre como analisar dados. Quanto mais tópicos fundamentais você conhece, melhor você formula suas hipóteses e faz declarações precisas sobre seus conjuntos de dados.
- Habilidades de programação: discutirei isso com mais detalhes abaixo, mas principalmente é aqui que você cria a flexibilidade de dizer ao computador para fazer exatamente o que você deseja, em vez de ficar preso a ferramentas fáceis de usar, mas um pouco restritivas. Ferramentas. Esta é a sua principal maneira de obter, remodelar e limpar seus dados, da maneira que você quiser, abrindo caminho para que você tenha “conversas” abertas e flexíveis com seus dados.
Vamos agora dar uma olhada no que normalmente fazemos em Data Science.
O ciclo da ciência de dados
Um projeto típico de ciência de dados ou até mesmo uma tarefa geralmente se parece com isso:
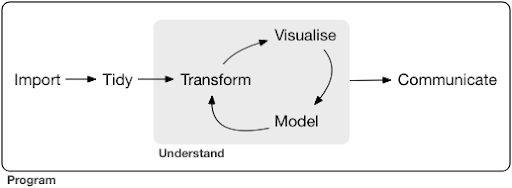
Fonte: r4ds.had.co.nz
Eu também recomendo a leitura deste livro de Hadley Wickham e Garrett Grolemund, que serve como uma ótima introdução à Ciência de Dados. Ele é escrito com exemplos da linguagem de programação R, mas os conceitos e o código podem ser facilmente entendidos se você souber apenas Python.
Como você pode ver no diagrama, primeiro precisamos importar nossos dados de alguma forma, organizá-los e, em seguida, começar a trabalhar no ciclo interno de transformação, visualização e modelagem. Depois disso, comunicamos os resultados com os outros.
Essas etapas podem variar de extremamente simples a muito complexas. Por exemplo, a etapa "Importar" pode ser tão simples quanto ler um arquivo CSV e, em alguns casos, pode consistir em um projeto de raspagem da Web muito complicado para obter os dados. Vários dos elementos do processo são especialidades de pleno direito por direito próprio.
Podemos facilmente mapear isso para alguns processos familiares que conhecemos. Por exemplo, você pode começar obtendo alguns metadados sobre um site, baixando seu robots.txt e sitemaps XML. Você provavelmente rastrearia e possivelmente também obteria alguns dados sobre posições SERP ou dados de links, por exemplo. Agora que você tem alguns conjuntos de dados, provavelmente deseja mesclar algumas tabelas, imputar alguns dados adicionais e começar a explorar/entender. A visualização de dados pode expor padrões ocultos ou ajudá-lo a descobrir o que está acontecendo ou talvez levantar mais questões. Você provavelmente também deseja modelar seus dados usando algumas estatísticas básicas ou modelos de aprendizado de máquina e, esperançosamente, obter alguns insights. Claro, você precisa comunicar as descobertas e perguntas para outras partes interessadas no projeto.
Quando você estiver familiarizado o suficiente com as várias ferramentas disponíveis para cada um desses processos, poderá começar a criar seus próprios pipelines personalizados específicos para um determinado site, porque cada empresa é única e possui um conjunto especial de requisitos. Eventualmente, você começará a encontrar padrões e não terá que refazer todo o trabalho para projetos/sites semelhantes.
Existem inúmeras ferramentas e bibliotecas disponíveis para cada elemento neste processo e pode ser bastante cansativo, qual ferramenta você escolhe (e investe seu tempo no aprendizado). Vamos dar uma olhada em uma abordagem possível que considero útil na seleção das ferramentas que uso.
Escolha de ferramentas e compensações (3 maneiras de comer uma pizza)
Você deve usar o Excel para o seu trabalho diário no processamento de dados ou vale a pena aprender Python?
É melhor visualizar com algo como o Power BI ou deve investir em aprender sobre a Gramática dos Gráficos e aprender a usar as bibliotecas que a implementam?
Você produziria um trabalho melhor criando seus próprios painéis interativos com R ou Python ou deveria apenas usar o Google Data Studio?
Vamos primeiro explorar os trade-offs envolvidos na seleção de várias ferramentas em diferentes níveis de abstração. Este é um trecho do meu livro sobre a criação de painéis interativos e aplicativos de dados com Plotly e Dash e acho essa abordagem útil:
Considere três abordagens diferentes para comer uma pizza:
- A abordagem do pedido: você liga para um restaurante e pede sua pizza. Ele chega à sua porta em meia hora e você começa a comer.
- A abordagem do supermercado: você vai ao supermercado, compra massa, queijo, legumes e todos os outros ingredientes. Então você mesmo faz a pizza.
- A abordagem da fazenda: você cultiva tomates em seu quintal. Você cria vacas, ordenha-as e converte o leite em queijo, e assim por diante.
À medida que avançamos para interfaces de nível superior, em direção à abordagem de ordenação, a quantidade de conhecimento necessária diminui muito. Outra pessoa assume a responsabilidade, e a qualidade é verificada pelas forças de mercado da reputação e da concorrência.
O preço que pagamos por isso é a diminuição da liberdade e das opções. Cada restaurante tem um conjunto de opções para escolher, e você deve escolher entre essas opções.
Descendo para níveis mais baixos, a quantidade de conhecimento necessária aumenta, temos que lidar com mais complexidade, temos mais responsabilidade pelos resultados e leva muito mais tempo. O que ganhamos aqui é muito mais liberdade e poder para personalizar nossos resultados da maneira que queremos. O custo também é um grande benefício, mas apenas em uma escala grande o suficiente. Se você só quer comer uma pizza hoje, provavelmente é mais barato pedir. Mas se você planeja ter um todos os dias, pode esperar grandes economias de custos se fizer isso sozinho.
Esses são os tipos de escolhas que você terá que fazer ao escolher quais ferramentas usar e aprender. Usar uma linguagem de programação como R ou Python requer muito mais trabalho e é mais difícil que o Excel, com o benefício de torná-lo muito mais produtivo e poderoso.
A escolha também é importante para cada ferramenta ou processo. Por exemplo, você pode usar um rastreador de alto nível e fácil de usar para coletar dados sobre um site e, ainda assim, preferir usar uma linguagem de programação para visualizar os dados, com todas as opções disponíveis. A escolha da ferramenta certa para o processo certo depende de suas necessidades e a compensação descrita acima pode ajudar a fazer essa escolha. Espero que isso também ajude a resolver a questão de saber se ou não (ou quanto) Python ou R você deseja aprender.
Vamos levar essa questão um pouco mais longe e ver por que aprender Python para SEO pode não ser a palavra-chave certa.
Por que “python para seo” é enganoso
Você gostaria de se tornar um grande blogueiro ou quer aprender WordPress?
Você gostaria de se tornar um designer gráfico ou seu objetivo é aprender Photoshop?
Você está interessado em impulsionar sua carreira em SEO levando suas habilidades de dados para o próximo nível ou quer aprender Python?
Nos primeiros cinco minutos da primeira aula do curso de ciência da computação no MIT, o professor Harold Abelson abre o curso contando aos alunos por que “ciência da computação” é um nome tão ruim para a disciplina que eles estão prestes a aprender. Acho muito interessante assistir aos primeiros cinco minutos da palestra:
Quando algum campo está apenas começando e você não o entende muito bem, é muito fácil confundir a essência do que você está fazendo com as ferramentas que você usa. – Harold Abelson
Estamos tentando melhorar nossa presença online e resultados, e muito do que fazemos é baseado na compreensão, visualização, manipulação e manipulação de dados em geral, e esse é o nosso foco, independente da ferramenta utilizada. Data Science é o campo que possui as estruturas intelectuais para fazer isso, além de muitas ferramentas para implementar o que queremos fazer. Python pode ser sua linguagem de programação (ferramenta) de escolha, e é definitivamente importante aprendê-la bem. Também é tão importante, se não mais importante, focar na “essência do que você está fazendo”, processando e analisando dados, no nosso caso.
O foco principal deve estar nos processos discutidos acima (importação, organização, visualização, etc.), em oposição à linguagem de programação escolhida. Ou melhor, como usar essa linguagem de programação para realizar suas tarefas, em vez de simplesmente aprender uma linguagem de programação.
Quem se importa com todas essas distinções teóricas se eu vou aprender Python de qualquer maneira?
Vamos dar uma olhada no que pode acontecer se você se concentrar em aprender sobre a ferramenta, em oposição à essência do que você está fazendo. Aqui, comparamos a pesquisa por “aprender wordpress” (a ferramenta) versus “aprender a blogar” (o que queremos fazer):
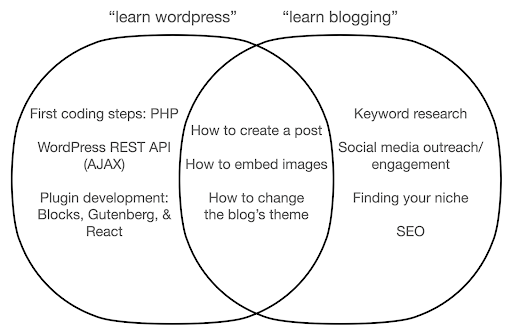
O diagrama mostra possíveis tópicos em um livro ou curso que ensina sobre a palavra-chave no topo. A área de interseção no meio mostra tópicos que podem ocorrer em ambos os tipos de curso/livro.
Se você se concentrar na ferramenta, sem dúvida, acabará tendo que aprender sobre coisas que realmente não precisa, principalmente como iniciante. Esses tópicos podem confundir e frustrar você, especialmente se você não tiver experiência técnica ou de programação.
Você também aprenderá coisas úteis para se tornar um bom blogueiro (os tópicos na área de interseção). Esses tópicos são extremamente fáceis de ensinar (como criar uma postagem no blog), mas não dizem muito sobre por que você deve blogar, quando e sobre o quê. Isso não é uma falha em um livro focado em ferramentas, porque ao aprender sobre uma ferramenta, bastaria aprender a criar uma postagem no blog e seguir em frente.
Como um blogueiro, você provavelmente está mais interessado no quê e no porquê dos blogs, e isso não seria abordado em livros focados em ferramentas.
Obviamente, as coisas estratégicas e importantes, como SEO, encontrar seu nicho e assim por diante, não serão abordadas, então você estaria perdendo coisas muito importantes.
Quais são alguns dos tópicos de Ciência de Dados que você provavelmente não aprenderá em um livro de programação?
Como vimos, pegar um Python ou um livro de programação provavelmente significa que você quer se tornar um engenheiro de software. Os tópicos seriam naturalmente voltados para esse fim. Se você procurar um livro de Ciência de Dados, encontrará tópicos e ferramentas mais voltados para a análise de dados.
Podemos usar o primeiro diagrama (mostrando o ciclo de Data Science) como um guia e pesquisar proativamente por esses tópicos: “importar dados com python”, “arrumar dados com r”, “visualizar dados com python” e assim por diante. Vamos dar uma olhada mais profunda nesses tópicos e explorá-los ainda mais:
Importar
Naturalmente, precisamos primeiro obter alguns dados. Isso pode ser:
- Um arquivo em nosso computador: O caso mais simples em que você simplesmente abre o arquivo com a linguagem de programação de sua escolha. É importante observar que existem muitos formatos de arquivo diferentes e que você tem muitas opções ao abrir/ler os arquivos. Por exemplo, a função read_csv da biblioteca pandas (uma ferramenta essencial de manipulação de dados em Python) tem cinquenta opções para escolher ao abrir o arquivo. Ele contém coisas como o caminho do arquivo, as colunas a serem escolhidas, o número de linhas a serem abertas, a interpretação de objetos de data e hora, como lidar com valores ausentes e muito mais. É importante estar familiarizado com essas opções e as várias considerações ao abrir diferentes formatos de arquivo. Além disso, o pandas possui dezenove funções diferentes que começam com read_ para vários formatos de arquivo e dados.
- Exportar de uma ferramenta online: Você provavelmente está familiarizado com isso, e aqui você pode personalizar seus dados e exportá-los, após o que você os abrirá como um arquivo no seu computador.
- Chamadas de API para obter dados específicos: isso está em um nível mais baixo e mais próximo da abordagem de farm mencionada acima. Neste caso, você envia uma solicitação com requisitos específicos e recebe de volta os dados que deseja. A vantagem aqui é que você pode personalizar exatamente o que deseja obter e formatá-lo de maneiras que podem não estar disponíveis na interface online. Por exemplo, no Google Analytics, você pode adicionar uma dimensão secundária a uma tabela que está analisando, mas não pode adicionar uma terceira. Você também está limitado pelo número de linhas que pode exportar. A API oferece mais flexibilidade e você também pode automatizar determinadas chamadas para acontecer periodicamente, como parte de um pipeline maior de coleta/análise de dados.
- Rastreamento e raspagem de dados: você provavelmente tem seu rastreador favorito e provavelmente está familiarizado com o processo. Este já é um processo flexível, permitindo-nos extrair elementos personalizados de páginas, rastrear apenas determinadas páginas e assim por diante.
- Uma combinação de métodos envolvendo automação, extração personalizada e possivelmente aprendizado de máquina para usos especiais.
Assim que tivermos alguns dados, queremos ir para o próximo nível.
Arrumado
Um conjunto de dados “arrumado” é um conjunto de dados organizado de uma determinada maneira. Também são chamados de dados de “formato longo”. O Capítulo 12 do livro R for Data Science discute o conceito de dados organizados com mais detalhes, se você estiver interessado.
Dê uma olhada nas três tabelas abaixo e tente encontrar as diferenças:
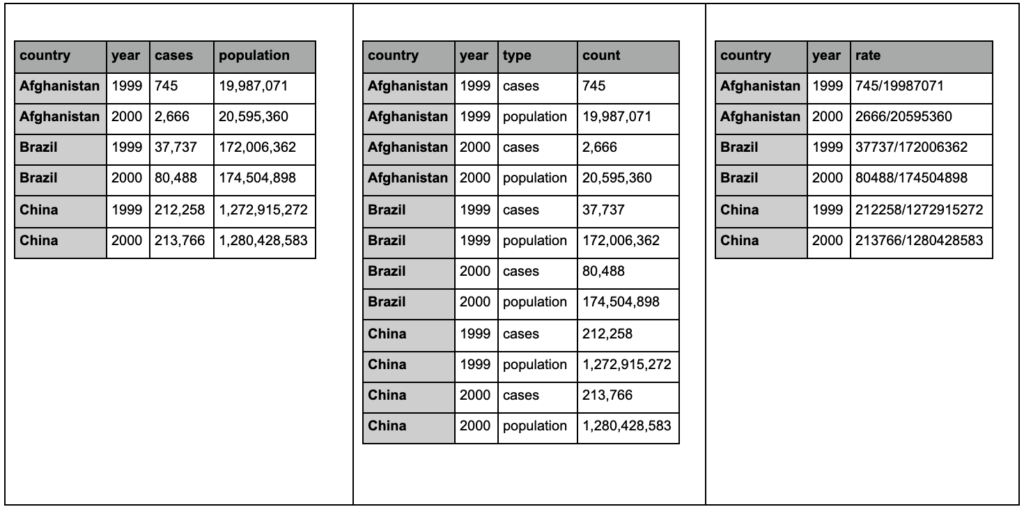
Tabelas de amostra do pacote arrumador.
Você verá que as três tabelas contêm exatamente as mesmas informações, mas organizadas e apresentadas de maneiras diferentes. Podemos ter casos e população em duas colunas separadas (tabela 1), ou ter uma coluna para nos dizer qual é a observação (casos ou população), e uma coluna de “contagem” para contar esses casos (tabela 2). Na tabela 3, eles são apresentados como taxas.
Ao lidar com dados, você descobrirá que diferentes fontes organizam os dados de maneira diferente e que muitas vezes você precisará mudar de/para determinados formatos para uma análise melhor e mais fácil. Estar familiarizado com essas operações de limpeza é crucial, e o pacote cleanr em R contém ferramentas especiais para isso. Você também pode usar pandas se preferir Python, e pode conferir as funções de fusão e pivô para isso.
Uma vez que nossos dados estão em um determinado formato, podemos querer manipulá-los ainda mais.
Transformar
Outra habilidade crucial a ser desenvolvida é a capacidade de fazer as alterações desejadas nos dados com os quais está trabalhando. O cenário ideal é chegar ao estágio em que você pode conversar com seus dados e ser capaz de cortar e cortar da maneira que quiser fazer perguntas muito específicas e, esperançosamente, obter insights interessantes. Aqui estão algumas das tarefas de transformação mais importantes que você provavelmente precisará muito com algumas tarefas de exemplo nas quais você pode estar interessado:
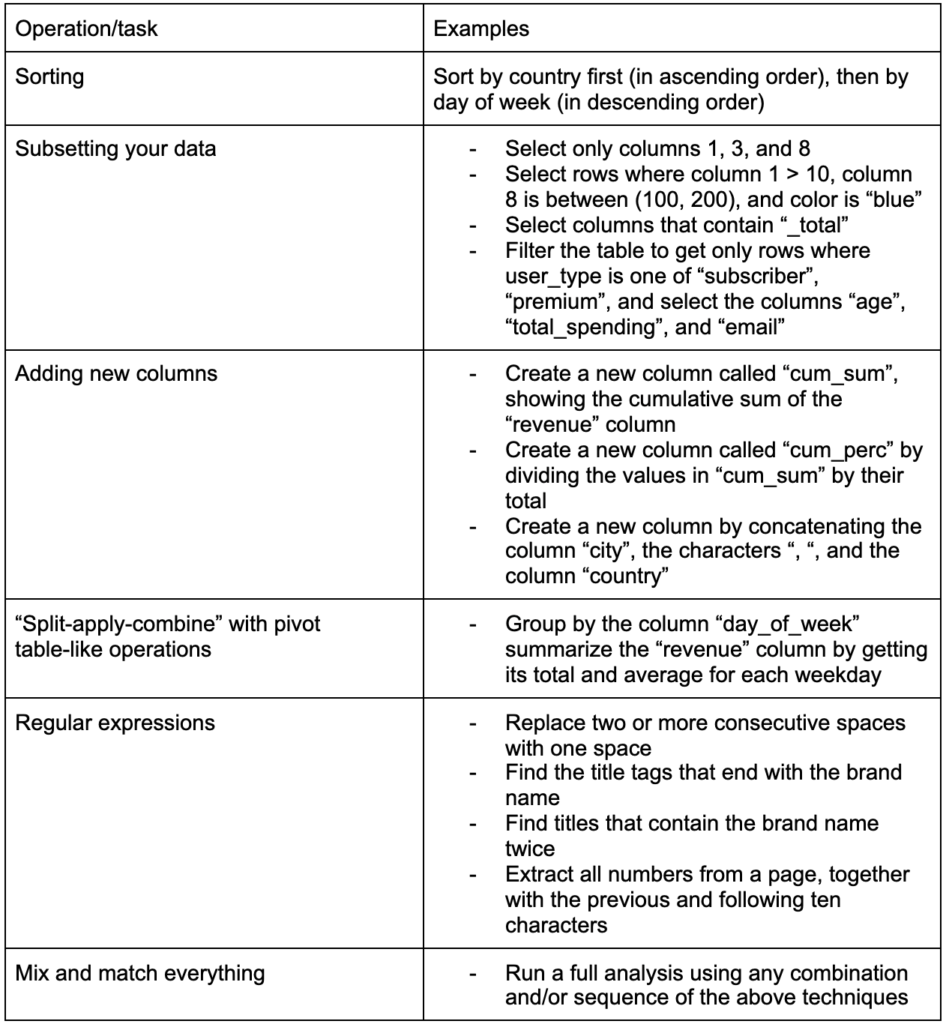
Depois de obter, arrumar e colocar nossos dados no formato desejado, seria bom visualizá-los.
Visualizar
A visualização de dados é um tópico enorme, e existem livros inteiros sobre alguns de seus subtópicos. É uma daquelas coisas que podem fornecer muitos insights sobre nossos dados, especialmente porque usa elementos visuais intuitivos para comunicar informações. A altura relativa das barras em um gráfico de barras nos mostra imediatamente sua quantidade relativa, por exemplo. A intensidade da cor, a localização relativa e muitos outros atributos visuais são facilmente reconhecíveis e compreendidos pelos leitores.
Um bom gráfico vale mais que mil palavras (chave)!
Como existem vários tópicos sobre visualização de dados, vou simplesmente compartilhar alguns exemplos que podem ser interessantes. Vários deles são os blocos de construção para este painel de dados da pobreza, se você quiser os detalhes completos.
Às vezes, um gráfico de barras simples é tudo o que você precisa para comparar valores, onde as barras podem ser exibidas verticalmente ou horizontalmente:
Você pode estar interessado em explorar determinados países e se aprofundar, vendo como eles progrediram em determinadas métricas. Nesse caso, você pode querer exibir vários gráficos de barras no mesmo gráfico:
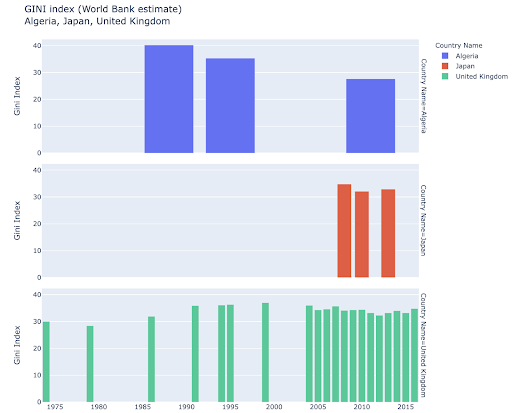
A comparação de vários valores para várias observações também pode ser feita colocando várias barras em cada posição do eixo X, aqui estão as principais maneiras de fazer isso:
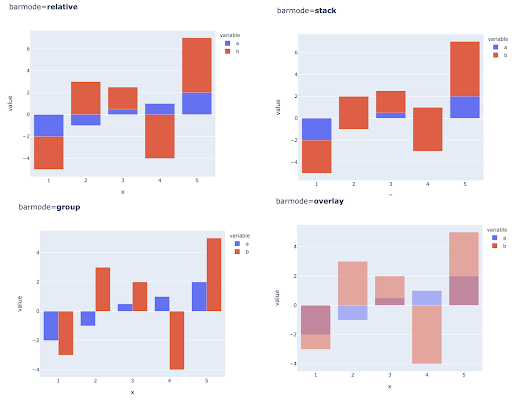
Escolha de cores e escalas de cores: Uma parte essencial da visualização de dados e algo que pode comunicar informações de forma extremamente eficiente e intuitiva, se feito corretamente.
Escalas de cores categóricas: Úteis para expressar dados categóricos. Como o nome sugere, este é o tipo de dado que mostra a qual categoria uma determinada observação pertence. Nesse caso, queremos que as cores sejam tão distintas umas das outras quanto possível para mostrar diferenças claras nas categorias (especialmente para elementos visuais exibidos próximos uns dos outros).
O exemplo a seguir usa uma escala de cores categórica para mostrar qual sistema de governo está implementado em cada país. É muito fácil conectar as cores dos países à legenda que mostra qual sistema de governo é usado. Isso também é chamado de mapa coroplético:
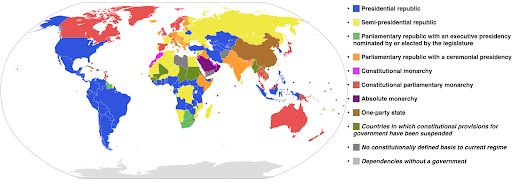
Fonte: Wikipédia
Às vezes, os dados que queremos visualizar são para a mesma métrica, e cada país (ou qualquer outro tipo de observação) cai em um determinado ponto em um continuum que varia entre os pontos mínimo e máximo. Em outras palavras, queremos visualizar graus dessa métrica.
Nesses casos, precisamos encontrar uma escala de cores contínua (ou sequencial) . Fica imediatamente claro no exemplo a seguir quais países são mais azuis (e, portanto, recebem mais tráfego), e podemos entender intuitivamente as diferenças sutis entre os países.
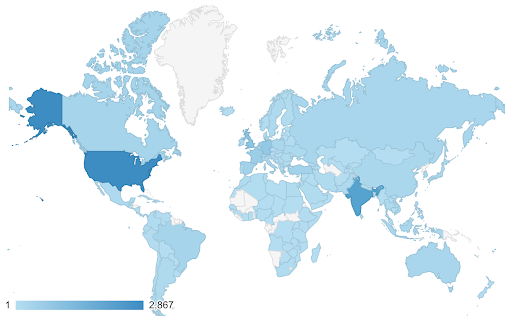
Seus dados podem ser contínuos (como o gráfico do mapa de tráfego acima), mas o importante sobre os números pode ser o quanto eles divergem de um determinado ponto. As escalas de cores divergentes são úteis neste caso.
O gráfico abaixo mostra as taxas líquidas de crescimento populacional. Nesse caso, é interessante saber primeiro se um determinado país tem ou não uma taxa de crescimento positiva ou negativa. Ou queremos saber a que distância cada país está de zero (e quanto). Olhando para o mapa imediatamente nos mostra quais a população dos países está crescendo e qual está diminuindo. A legenda também nos mostra que a taxa máxima positiva é de 3,5% e que a máxima negativa é -0,5%. Isso também nos dá uma indicação sobre a faixa de valores (positivos e negativos).

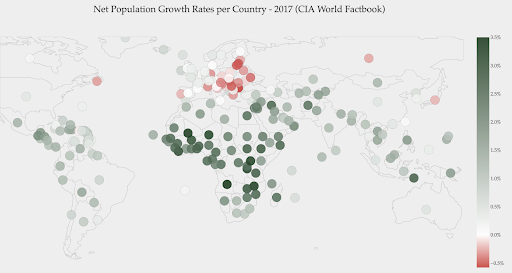
Fonte: Dashboardom.com
Infelizmente, as cores escolhidas para esta escala não são as ideais, porque as pessoas daltônicas podem não conseguir distinguir corretamente entre vermelho e verde. Esta é uma consideração muito importante ao escolher nossas escalas de cores.
O gráfico de dispersão é um dos tipos de gráfico mais usados e versáteis. A posição dos pontos (ou qualquer outro marcador) transmite a quantidade que estamos tentando comunicar. Além da posição, podemos usar vários outros atributos visuais como cor, tamanho e forma para comunicar ainda mais informações. O exemplo a seguir mostra a porcentagem da população vivendo a US$ 1,9/dia, que podemos ver claramente como a distância horizontal dos pontos.
Também podemos adicionar uma nova dimensão ao nosso gráfico usando cores. Isso corresponde a visualizar uma terceira coluna do mesmo conjunto de dados, que neste caso mostra os dados populacionais.
Podemos ver agora que o caso mais extremo em termos de população (EUA), é muito baixo na métrica do nível de pobreza. Isso adiciona riqueza aos nossos gráficos. Também poderíamos ter usado tamanho e forma para visualizar ainda mais colunas de nosso conjunto de dados. No entanto, precisamos encontrar um bom equilíbrio entre riqueza e legibilidade.
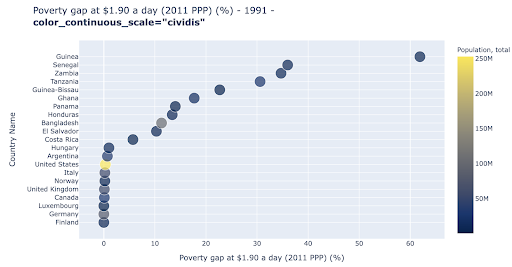
Podemos estar interessados em verificar se existe uma relação entre a população e os níveis de pobreza, e assim podemos visualizar o mesmo conjunto de dados de uma forma ligeiramente diferente para ver se existe tal relação:
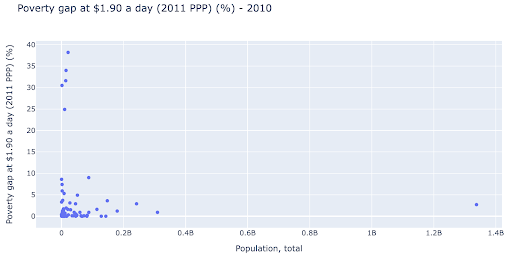
Temos um valor discrepante na população em torno de 1,35B, e isso significa que temos muitos espaços em branco no gráfico, o que também significa que muitos valores estão comprimidos em uma área muito pequena. Também temos muitos pontos sobrepostos, o que torna muito difícil identificar diferenças ou tendências.
O gráfico a seguir contém as mesmas informações, mas visualizadas de forma diferente usando duas técnicas:
- Escala logarítmica : geralmente vemos dados em uma escala aditiva. Em outras palavras, cada ponto no eixo (X ou Y) representa uma adição de uma certa quantidade de dados visualizados. Também podemos ter escalas multiplicativas, caso em que para cada novo ponto no eixo X multiplicamos (por dez neste exemplo). Isso permite que os pontos sejam distribuídos e precisamos pensar em múltiplos ao invés de adições, como fizemos no gráfico anterior.
- Usando um marcador diferente (círculos vazios maiores) : A seleção de uma forma diferente para nossos marcadores resolveu o problema de “over-plotting” onde poderíamos ter vários pontos um sobre o outro no mesmo local, o que torna muito difícil até mesmo ver quantos pontos temos.
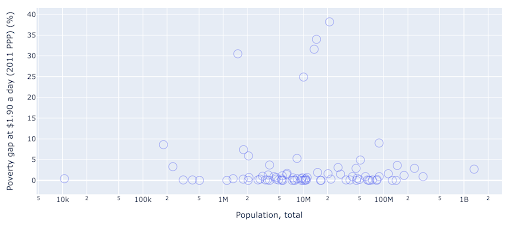
Agora podemos ver que há um aglomerado de países em torno da marca de 10 milhões e outros aglomerados menores também.
Como mencionei, existem muitos outros tipos de chars e opções de visualização, e livros inteiros escritos sobre o assunto. Espero que isso lhe dê alguns pensamentos interessantes para experimentar.
Dados de rastreamento³
 Saber mais
Saber maisModelo
Precisamos simplificar nossos dados e encontrar padrões, fazer previsões ou simplesmente entendê-los melhor. Este é outro tópico grande, e pode variar desde simplesmente obter algumas estatísticas resumidas (média, mediana, desvio padrão, etc), até modelar visualmente nossos dados, usando um modelo que resume ou encontra uma tendência, até usar técnicas mais complexas para obter uma fórmula matemática para nossos dados. Também podemos usar o aprendizado de máquina para nos ajudar a descobrir mais insights em nossos dados.
Novamente, esta não é uma discussão completa do tópico, mas gostaria de compartilhar alguns exemplos em que você pode usar algumas técnicas de aprendizado de máquina para ajudá-lo.
Em um conjunto de dados de rastreamento, eu estava tentando aprender um pouco mais sobre as 404 páginas e se posso descobrir algo sobre elas. Minha primeira tentativa foi verificar se havia uma correlação entre o tamanho da página e seu código de status, e houve – uma correlação quase perfeita!
Me senti um gênio, por alguns minutos, e rapidamente voltei ao planeta Terra.
As páginas 404 estavam todas em uma faixa muito estreita de tamanho de página que quase todas as páginas com um certo número de kilobytes tinham um código de status 404. Então percebi que as páginas 404, por definição, não têm nenhum conteúdo além de, bem, “página de erro 404”! E é por isso que eles tinham o mesmo tamanho.
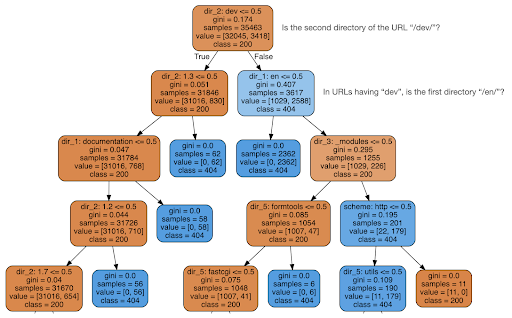
Decidi então verificar se o conteúdo poderia me dizer algo sobre o código de status, então dividi as URLs em seus elementos e executei um classificador de árvore de decisão usando sklearn. Esta é basicamente uma técnica que produz uma árvore de decisão, onde seguir suas regras pode nos levar a aprender como encontrar nosso alvo, 404 páginas neste caso.
Na árvore de decisão a seguir, a primeira linha em cada caixa mostra a regra a seguir ou verificar, a linha “amostras” é o número de observações encontradas nesta caixa e a linha “classe” nos diz a classe da observação atual , neste caso, independentemente de seu código de status ser 200 ou 404.
Não entrarei em mais detalhes e sei que a árvore de decisão pode não estar clara se você não estiver familiarizado com ela, e você pode explorar o conjunto de dados de rastreamento bruto e o código de análise se estiver interessado.
Basicamente, o que a árvore de decisão descobriu foi como encontrar quase todas as 404 páginas, usando a estrutura de diretórios das URLs. Como você pode ver, encontramos 3.617 URLs, simplesmente verificando se o segundo diretório da URL era ou não “/dev/” (primeira caixa azul clara na segunda linha de cima). Então agora sabemos como localizar nossos 404's, e parece que eles estão quase todos na seção “/dev/” do site. Isso definitivamente foi uma grande economia de tempo. Imagine passar manualmente por todas as estruturas e combinações de URL possíveis para encontrar essa regra.
Ainda não temos a imagem completa e por que isso está acontecendo, e isso pode ser levado adiante, mas pelo menos agora localizamos esses URLs com muita facilidade.
Outra técnica que você pode estar interessado em usar é o agrupamento KMeans, que agrupa pontos de dados em vários grupos/clusters. Esta é uma técnica de “aprendizagem não supervisionada”, onde o algoritmo nos ajuda a descobrir padrões que não sabíamos que existiam.
Imagine que você tivesse um monte de números, digamos a população de países, e você quisesse agrupá-los em dois grupos, grande e pequeno. Como você faria isso? Onde você traçaria a linha?
Isso é diferente de obter os dez principais países, ou os primeiros X% dos países. Isso seria muito fácil, podemos classificar os países por população e obter os principais X como queremos.
O que queremos é agrupá-los como “grandes” e “pequenos” em relação a este conjunto de dados, e assumindo que não sabemos nada sobre as populações dos países.
Isso pode ser estendido ainda mais para tentar agrupar os países em três categorias: pequenos, médios e grandes. Isso se torna muito mais difícil de fazer manualmente, se quisermos cinco, seis ou mais grupos.
Observe que não sabemos quantos países terminarão em cada grupo, pois não estamos solicitando os principais X países. Agrupando em dois clusters, podemos ver que temos apenas dois países no grande grupo: China e Índia. Isso faz sentido intuitivo, pois esses dois países têm uma população média muito distante de todos os outros países. Este grupo de países tem sua própria média e seus países estão mais próximos uns dos outros do que os países do outro grupo:
Países agrupados em dois grupos por população 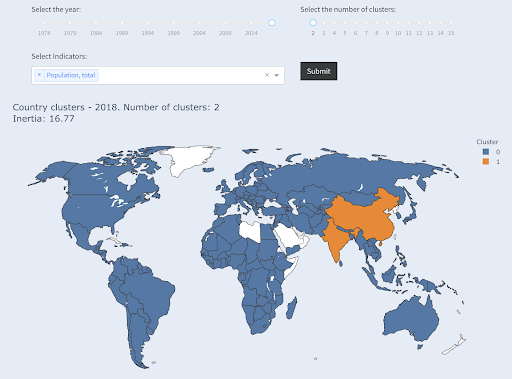
O terceiro maior país em termos de população (EUA ~ 330 milhões) foi agrupado com todos os outros, incluindo países que têm uma população de um milhão. Isso porque 330M é muito mais próximo de 1M do que 1,3 bilhão. Se tivéssemos pedido três clusters, teríamos obtido uma imagem diferente:
Países agrupados em três grupos por população 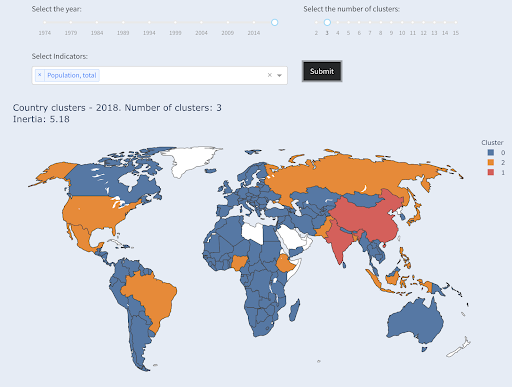
E é assim que os países seriam agrupados se solicitássemos quatro agrupamentos:
Países agrupados em quatro grupos por população 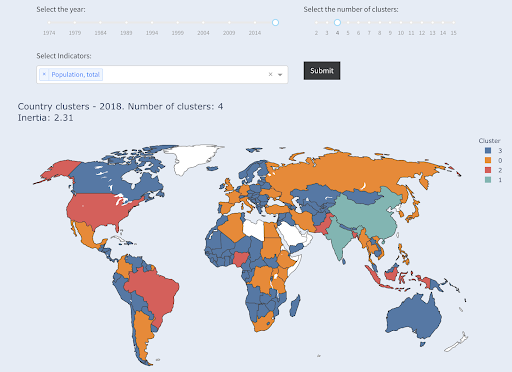
Fonte: pobrezadata.org (guia “Países do Cluster”)
Este foi o agrupamento usando apenas uma dimensão – população – neste caso, e você pode adicionar mais dimensões também e ver onde os países terminam.
Existem muitas outras técnicas e ferramentas, e estes foram apenas alguns exemplos que esperamos que sejam interessantes e práticos.
Agora estamos prontos para comunicar nossas descobertas ao nosso público.
Comunicar
Depois de todo o trabalho que fizemos nas etapas anteriores, precisamos eventualmente comunicar nossas descobertas a outras partes interessadas do projeto.
Uma das ferramentas mais importantes em ciência de dados é o notebook interativo. O notebook Jupyter é o mais usado e suporta praticamente todas as linguagens de programação, e você pode preferir usar o formato de notebook especial do RStudio, que funciona da mesma maneira.
A ideia principal é ter dados, código, narrativa e visualizações em um só lugar, para que outras pessoas possam auditá-los. É importante mostrar como você chegou a essas conclusões e recomendações para transparência e reprodutibilidade. Outras pessoas devem ser capazes de executar o mesmo código e obter os mesmos resultados.
Outra razão importante é a capacidade de outros, incluindo “você do futuro”, de levar a análise adiante e construir sobre o trabalho inicial que você fez, melhorá-lo e expandi-lo de novas maneiras.
Claro, isso pressupõe que o público esteja confortável com o código e que eles até se importem com isso!
Você também tem a opção de exportar seus notebooks para HTML (e vários outros formatos), excluindo o código, para que você tenha um relatório fácil de usar e ainda retenha o código completo para reproduzir as mesmas análises e resultados.
Um elemento importante da comunicação é a visualização de dados, que também foi brevemente abordada acima.
Melhor ainda, é a visualização interativa de dados, caso em que você permite que seu público selecione valores e confira várias combinações de gráficos e métricas para explorar ainda mais os dados.
Aqui estão alguns painéis e aplicativos de dados (alguns deles podem levar alguns segundos para carregar) que criei para dar uma ideia do que pode ser feito.
Eventualmente, você também pode criar aplicativos personalizados para seus projetos, a fim de atender a necessidades e requisitos especiais, e aqui está outro conjunto de aplicativos de SEO e marketing que podem ser interessantes para você.
Percorremos as principais etapas do ciclo de Data Science e agora vamos explorar outro benefício de “aprender python”.
Python é para automação e produtividade: verdadeiro, mas incompleto
Parece-me que existe uma crença de que aprender Python é principalmente para obter produtividade e/ou automatizar tarefas.
Isso é absolutamente verdade, e acho que não precisamos nem discutir o valor de poder fazer algo em uma fração do tempo que levaríamos para fazê-lo manualmente.
A outra parte que falta no argumento é a análise de dados . Uma boa análise de dados nos fornece insights e, idealmente, somos capazes de fornecer insights acionáveis para orientar nosso processo de tomada de decisão, com base em nossa experiência e nos dados que temos.
Grande parte do que fazemos é tentar entender o que está acontecendo, analisar a concorrência, descobrir onde está o conteúdo mais valioso, decidir o que fazer e assim por diante. Somos consultores, assessores e tomadores de decisão. Ser capaz de obter alguns insights de nossos dados é claramente um grande benefício, e as áreas e habilidades mencionadas aqui podem nos ajudar a conseguir isso.
E se você descobrisse que suas tags de título têm um comprimento médio de sessenta caracteres, isso é bom?
E se você cavar um pouco mais fundo e descobrir que metade de seus títulos está bem abaixo de sessenta, enquanto a outra metade tem muito mais personagens (fazendo a média de sessenta)? In order to get practical and provide good recommendations, you need a higher-resolution view of your title tags' lengths, probably a histogram that shows the frequency of your title tag lengths at each interval so you can have a separate strategy for length. A simple table would also do, for example:
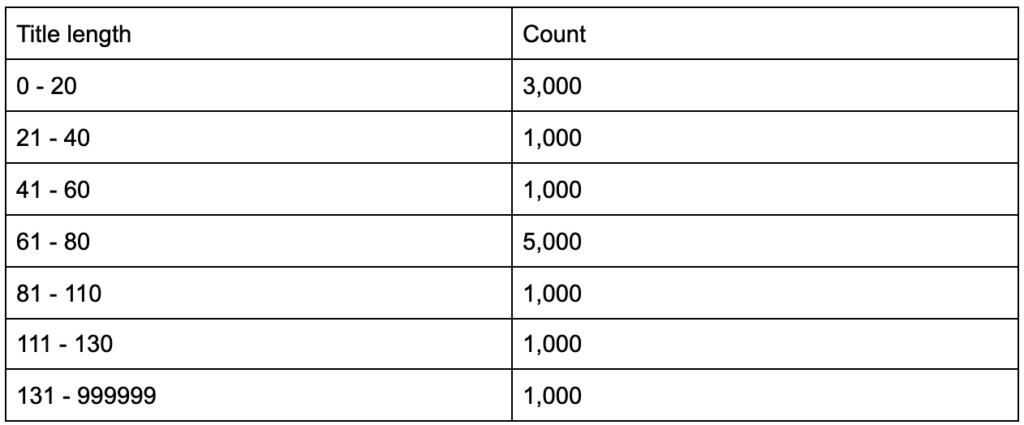
Splitting title lengths by intervals of twenty was an arbitrary decision, and you can split them the way you want. Looking at the table above, and seeing that we have three times more than the average titles in the interval (0, 20), we might want to split it further to better understand what is going on.
Having a better view than the default single-statistic summaries that we get from standard tools, allows us to employ different strategies for different lengths. For example, we can remove the brand name from the titles that are longer than a certain number of characters, and keep it in other titles.
This was an example of very simple insights, which are possible due to the flexibility we get by using a programming language, and a set of data science tools. This also allows us to iterate and modify our approach, until we find a satisfactory point that can take our analysis to the next steps.
Visualization, machine learning, modeling and general data manipulation skills allow us to get better insights on our data, even though those analyses are typically done only once. Still, if you use code to get those insights, you can always take some parts and apply to other projects, or again to the same project. In this case, the insights we got, helped us in our automation, even more. The insights would tell us what needs to be automated and what doesn't.
Should you learn Python?
Is a useless question, and the more useful one is, “How much Python (or R) should you learn?”
My view of how we use computers has evolved in the last few years.
I used to think that there were two main ways of using computers, either you are a regular user, using “point-and-click” applications to do certain tasks, or you are a developer who creates those applications that the rest of us use.

I then realized that it is more like a continuum between very high level use (pizza ordering approach), and the lower levels of the farm approach. I also realized that there is a happy sweet spot in between, where you learn enough programming to get productive and boost your data analysis skills, without having to become a software developer or engineer.
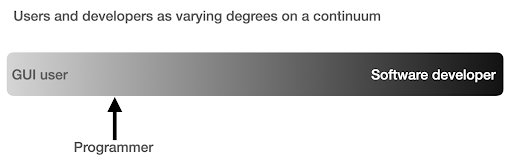
What are the main differences between being a programmer (a software user), and a software developer (or engineer)?
What are the differences between making a great coffee at home, versus establishing and running a cafe?
If making good coffee is one skill, then running a cafe requires ten other skills, most of which have nothing to do with making coffee.
You have to choose a good location (real estate), hire people (management and HR), manage cash flow and finances (accounting and finance), do marketing, legal, manage delivery, adhere to cleanliness and health standards, and so on. You can be a great coffee maker without knowing anything about those fields, but if you want to take it to the next level, you will have to manage all those additional tasks unrelated to making coffee.
The same applies to being a good programmer or data analyst versus being a software developer/engineer. There are so many other things that you have to know and worry about that you don't need as a regular programmer doing stuff for yourself and co-workers and clients. Once you have enough knowledge and skills in programming and data science, you will be in a good position to choose and decide whether you want to continue as an analyst, focusing on data science, or if you want to end up creating software that other people would use.
How do I get into Data Science?
To learn anything I think you have to do two things in parallel:
- Learn the fundamentals and the theory properly: Taking courses and reading books, and getting into the fundamentals can push you forward, as you will be gaining in weeks, knowledge that took decades to establish. It would also immediately give you ideas on things you thought were impossible, or had no idea existed.
- Get as much real world exposure and experience as possible: Experience is always important, and my suggestion is to try as soon as you can to read_csv with Python or R, to actually do so with your GA, GSC, or crawl dataset. See what else you can do (visualize, manipulate, model, etc.). See if you get errors, try to analyze the data only using your programming language.
What does frustration look like, and by when will I get productive?
It's difficult to say, and it depends on your skill, background, the hours you put in, but visualizing it like this might help you on those frustrating unproductive days:
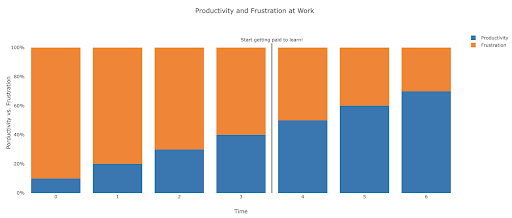
My suggestion is to take a non-trivial task, for example running an SEO audit for a site, only using Python. Your first session will mostly be frustrating, and most of the time will be spent checking documentation, and the definition of basic terms.
In parallel, you are still going through your course, and learning new stuff.
The value of that frustrating session is that it informs and motivates your theoretical learning. You will have questions in mind, and when you learn new things, you will immediately have a place to implement them.
Your next analysis session will probably be a little more productive, but still not productive enough to do at work. You go again to your learning and theory.
Do this enough times, and your time will become mostly productive, eventually you will be doing real work during working hours. The ideal scenario is where you are productive enough to do work, but every time use some time to research better techniques, which improves your work as well. By then you will start to get paid for learning, and your clients will be happily sponsoring you!
Suggested next steps
For the learning path a Data Science course would be great, especially if you get feedback on your work, and you can follow the topics in the order recommended.
If you go with Python I suggest the following libraries:
- pandas: The workhorse of all your tasks in preparing, cleaning, reshaping data whichever way you want. Fluency in pandas allows you to have full control over your data, which will help you immensely in visualization, general analysis, and machine learning
- Plotly and Dash: This is my favorite data visualization library, although there are many others. What I mostly like about it, is that it produces interactive and responsive HTML charts by default. It is very detailed and thorough in its options, yet simple to use. Plotly also includes Plotly Express, which is a high-level plotting tool, which is more intuitive to use, and takes a data-oriented approach (as opposed to a chart-oriented approach). Plotly also created Dash, which is the tool for creating interactive dashboards, but also serves as a full front-end web development framework. Other important data visualization libraries are matplotlib, altair, and bokeh, and for interactive data apps, there is panel and streamlit. Another important feature is that Plotly and Dash are available in all languages used in Data Science. You might use other libraries, and this is just my personal preference. Speaking of personal preferences:
- advertools: This is a library that I created to provide various online marketing tools, most importantly, an SEO crawler, log file parser and compressor, multi robots.txt parser, recursive sitemap parser, SEM keyword and text ad generator for large scale campaigns, weighted frequency word counter, Google SERP downloader, YouTube data API, and a few other tools. It is still evolving, and you are more than welcome to contribute any suggestions, bugs, or issues you might have with it.
These should be enough for beginners, and when you are familiar with them, you can do your own research for more specialized libraries, machine learning and deep learning tools, or libraries that are specialized in performance, or a special niche use-case.