
SEO和数字营销的数据科学:初学者的建议指南
已发表: 2021-12-07由于我们的大部分工作都围绕数据展开,并且随着数据科学领域变得越来越大,初学者也越来越容易获得,我想分享一些关于如何进入该领域以增强您的 SEO 和营销的想法技能一般。
什么是数据科学?
用于概述该领域的一个非常著名的图表是 Drew Conway 的维恩图,将数据科学显示为统计、黑客(一般高级编程技能,不一定穿透网络并造成伤害)和实质性的交集专业知识或“领域知识”:
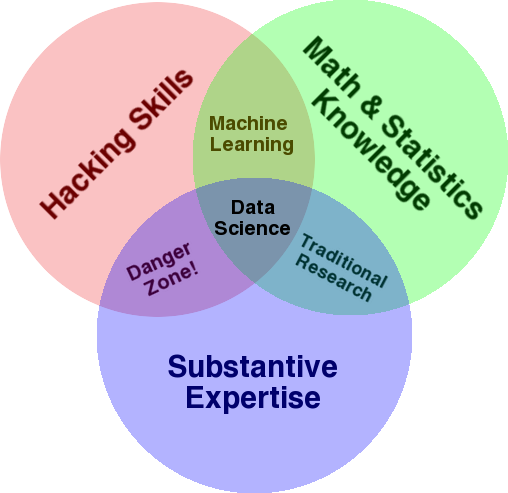
资料来源:oreilly.com
当我开始学习时,我很快意识到这正是我们已经在做的事情。 唯一的区别是我是用更基本的手动工具来做的。
如果您查看图表,您会很容易地看到您可能已经这样做了。 您使用计算机(黑客技能),分析数据(统计数据),使用您在 SEO(或您关注的任何专业)方面的实质性专业知识来解决实际问题。
您当前的“编程语言”可能是电子表格(Excel、Google 表格等),并且您很可能使用 Powerpoint 或类似的东西来交流想法。 让我们稍微扩展一下这些元素。
- 领域知识:让我们从您的主要优势开始,因为您已经了解您的专业领域。 请记住,这是成为数据科学家的重要组成部分,您可以在这里建立和保护您的知识。 几个月前,我正在和我的一个朋友讨论分析爬网数据集。 他是一名物理学家,从事量子计算机方面的博士后研究。 他的数学和统计知识和技能远超我,他真的比我更懂得如何分析数据。 一个问题。 他不知道什么是“404”(或者我们为什么要关心“301”)。 因此,凭借他所有的数学知识,他无法理解爬网数据集中的“状态”列。 自然地,他不知道如何处理这些数据,与谁交谈,以及根据这些状态代码构建什么策略(或者是否到别处寻找)。 你和我都知道如何处理它们,或者至少我们知道如果我们想深入挖掘,还能去哪里寻找。
- 数学和统计:如果您使用 Excel 来获取数据样本的平均值,那么您就是在使用统计。 平均值是描述数据样本某个方面的统计量。 更高级的统计数据将有助于理解您的数据。 这也很重要,我不是这方面的专家。 您熟悉的统计分布越多,您对如何分析数据的想法就越多。 您了解的基本主题越多,您就越能更好地制定假设,并对数据集做出准确的陈述。
- 编程技巧:我将在下面更详细地讨论这一点,但主要是在这里你可以灵活地告诉计算机完全按照你的意愿去做,而不是被困在易于使用但略有限制的地方工具。 这是您获取、重塑和清理数据的主要方式,无论您想要哪种方式,都为您与数据进行开放式和灵活的“对话”铺平了道路。
现在让我们来看看我们通常在数据科学中做什么。
数据科学周期
一个典型的数据科学项目甚至任务,通常看起来像这样:
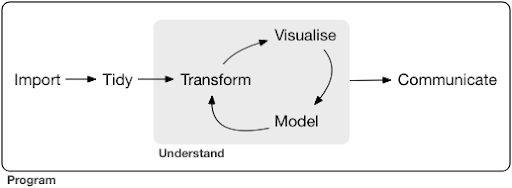
资料来源:r4ds.had.co.nz
我还强烈推荐阅读 Hadley Wickham 和 Garrett Grolemund 的这本书,它是对数据科学的一个很好的介绍。 它是用 R 编程语言的示例编写的,但是如果您只了解 Python,则可以很容易地理解这些概念和代码。
正如您在图中看到的,我们首先需要以某种方式导入我们的数据,对其进行整理,然后开始处理转换、可视化和建模的内部循环。 之后,我们与其他人交流结果。
这些步骤可以从非常简单到非常复杂。 例如,“导入”步骤可能就像读取 CSV 文件一样简单,并且在某些情况下可能包含一个非常复杂的网络抓取项目来获取数据。 该过程的一些要素本身就是成熟的专业。
我们可以轻松地将其映射到我们知道的一些熟悉的过程。 例如,您可以通过下载其 robots.txt 和 XML 站点地图来获取有关网站的一些元数据。 然后,您可能会爬网并可能还会获取一些有关 SERP 位置的数据,或链接数据。 现在您有一些数据集,您可能想要合并一些表,估算一些额外的数据并开始探索/理解。 可视化数据可以揭示隐藏的模式,或者帮助您了解正在发生的事情,或者可能会引发更多问题。 您可能还想使用一些基本统计数据或机器学习模型对数据进行建模,并希望获得一些见解。 当然,您需要将发现和问题传达给项目中的其他利益相关者。
一旦您对每个流程可用的各种工具足够熟悉,您就可以开始构建您自己的特定于某个网站的自定义管道,因为每个业务都是独一无二的,并且有一组特殊的要求。 最终,您将开始寻找模式,而不必为类似的项目/网站重做整个工作。
在此过程中,每个元素都有许多可用的工具和库,您选择哪种工具(并投入时间学习)可能会让人不知所措。 让我们看一下我认为在选择我使用的工具时有用的一种可能方法。
工具的选择和权衡(吃披萨的 3 种方式)
您应该在日常处理数据的工作中使用 excel,还是值得学习 Python 的痛苦?
您是使用 Power BI 之类的东西进行可视化更好,还是应该投资学习图形语法,并学习如何使用实现它的库?
您会通过使用 R 或 Python 构建自己的交互式仪表板来产生更好的工作,还是应该只使用 Google Data Studio?
让我们首先探讨在不同抽象级别选择各种工具所涉及的权衡。 这是我关于使用 Plotly 和 Dash 构建交互式仪表板和数据应用程序的书中的摘录,我发现这种方法很有用:
考虑吃披萨的三种不同方法:
- 订购方法:您致电餐厅并订购比萨饼。 半小时后到你家门口,你开始吃。
- 超市方法:你去超市,买面团、奶酪、蔬菜和所有其他配料。 然后你自己做披萨。
- 农场方法:你在后院种西红柿。 你养牛,挤奶,然后把牛奶变成奶酪,等等。
随着我们进入更高级别的界面,朝着排序方法,所需的知识量大大减少。 别人负责,质量由信誉和竞争的市场力量来检验。
我们为此付出的代价是减少了自由和选择。 每家餐厅都有一组可供选择的选项,您必须从这些选项中进行选择。
再往下走,所需的知识量就会增加,我们必须处理更多的复杂性,我们对结果承担更多的责任,并且需要更多的时间。 我们在这里获得的是更多的自由和权力,可以按照我们想要的方式定制我们的结果。 成本也是一个主要好处,但仅限于足够大的规模。 如果您今天只想吃披萨,那么订购它可能更便宜。 但是,如果您计划每天都有一个,那么如果您自己做,您可以期待节省大量成本。
这些是您在选择使用和学习哪些工具时必须做出的选择。 使用像 R 或 Python 这样的编程语言需要更多的工作,并且比 Excel 更困难,这样做的好处是让你更有效率和更强大。
选择对于每个工具或过程也很重要。 例如,您可能使用高级且易于使用的爬虫来收集有关网站的数据,但您可能更喜欢使用编程语言来可视化数据,并提供所有可用选项。 为正确的流程选择正确的工具取决于您的需求,上述权衡可能有助于做出选择。 这也有望帮助解决您是否(或多少)想要学习 Python 或 R 的问题。
让我们把这个问题更进一步,看看为什么学习 Python 进行 SEO 可能不是正确的关键字。
为什么“python for seo”具有误导性
您想成为一名出色的博主还是想学习 WordPress?
你想成为一名平面设计师还是你的目标是学习 Photoshop?
您是否有兴趣通过将您的数据技能提升到一个新的水平来提升您的 SEO 职业,或者您想学习 Python?
在麻省理工学院计算机科学课程第一讲的前五分钟,Harold Abelson 教授在课程开始时告诉学生为什么“计算机科学”对于他们将要学习的学科来说是一个如此糟糕的名字。 我觉得看讲座的前五分钟很有趣:
当某个领域刚刚起步,而您还不是很了解它时,很容易将您所做工作的本质与您使用的工具相混淆。 ——哈罗德·阿贝尔森
我们正在努力改善我们的在线形象和结果,我们所做的很多工作都是基于对数据的理解、可视化、操作和处理,无论使用何种工具,这都是我们的重点。 数据科学是具有执行此操作的智能框架以及许多工具来实现我们想做的事情的领域。 Python 可能是您选择的编程语言(工具),学好它绝对很重要。 在我们的案例中,关注“你正在做的事情的本质”、处理和分析数据也同样重要,如果不是更重要的话。
主要关注点应该是上面讨论的过程(导入、整理、可视化等),而不是选择的编程语言。 或者更好的是,如何使用该编程语言来完成您的任务,而不是简单地学习一门编程语言。
如果我还是要学习 Python,谁会关心所有这些理论区别?
让我们看看如果您专注于学习该工具而不是您所做工作的本质,可能会发生什么。 在这里,我们比较搜索“学习 wordpress”(工具)与“学习博客”(我们想做的事情):
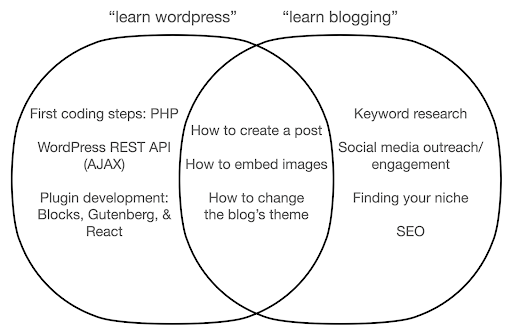
该图显示了在顶部教授关键字的书籍或课程下的可能主题。 中间的交叉区域显示了两种类型的课程/书籍中可能出现的主题。
如果您专注于该工具,那么您无疑最终将不得不学习您并不真正需要的东西,尤其是作为初学者。 这些主题可能会让您感到困惑和沮丧,尤其是在您没有技术或编程背景的情况下。
您还将学习对成为一名优秀博主有用的东西(交叉区域中的主题)。 这些主题非常容易教授(如何创建博客文章),但不会告诉您为什么应该写博客、何时以及关于什么。 这不是一本以工具为中心的书的错误,因为在学习工具时,学习如何创建博客文章并继续前进就足够了。
作为博客作者,您可能对博客的内容和原因更感兴趣,而以工具为中心的书籍不会涵盖这些内容。
显然,诸如 SEO、寻找你的利基等战略性和重要的事情不会被涵盖,所以你会错过非常重要的事情。
您可能不会在编程书籍中了解哪些数据科学主题?
正如我们所见,拿起 Python 或编程书籍可能意味着您想成为一名软件工程师。 这些主题自然会针对这一目标。 如果您寻找一本数据科学书籍,您将获得更适合分析数据的主题和工具。
我们可以以第一张图(显示数据科学的循环)为指导,主动搜索这些主题:“用python导入数据”、“用r整理数据”、“用python可视化数据”等。 让我们更深入地了解这些主题并进一步探索它们:
进口
我们自然需要先获取一些数据。 这可以是:
- 我们计算机上的文件:最简单的情况,您只需使用您选择的编程语言打开文件。 重要的是要注意有许多不同的文件格式,并且您在打开/读取文件时有许多选项。 例如,pandas 库(Python 中必不可少的数据操作工具)中的 read_csv 函数在打开文件时有 50 个选项可供选择。 它包含文件路径、要选择的列、要打开的行数、解释日期时间对象、如何处理缺失值等等。 熟悉这些选项以及打开不同文件格式时的各种注意事项非常重要。 此外,pandas 有 19 个不同的函数,以 read_ 开头,用于各种文件和数据格式。
- 从在线工具导出:您可能对此很熟悉,在这里您可以自定义数据,然后将其导出,之后您将在计算机上将其作为文件打开。
- 获取特定数据的 API 调用:这是较低级别的,更接近于上面提到的农场方法。 在这种情况下,您发送具有特定要求的请求并取回您想要的数据。 这里的好处是您可以准确地自定义您想要获得的内容,并以在线界面中可能不可用的方式对其进行格式化。 例如,在 Google Analytics(分析)中,您可以向正在分析的表格添加二级维度,但不能添加第三个维度。 您还受到可以导出的行数的限制。 API 为您提供了更大的灵活性,您还可以将某些调用自动化,使其定期发生,作为更大的数据收集/分析管道的一部分。
- 爬取和抓取数据:您可能拥有自己喜欢的爬虫,并且可能熟悉该过程。 这已经是一个灵活的过程,允许我们从页面中提取自定义元素、仅抓取某些页面等等。
- 涉及自动化、自定义提取以及可能用于特殊用途的机器学习的方法组合。
一旦我们有了一些数据,我们就想进入下一个层次。
整齐的
“整洁”的数据集是以某种方式组织的数据集。 它也被称为“长格式”数据。 如果您有兴趣,R for Data Science 一书的第 12 章会更详细地讨论 tidy data 概念。
查看下面的三个表格并尝试找出任何差异:
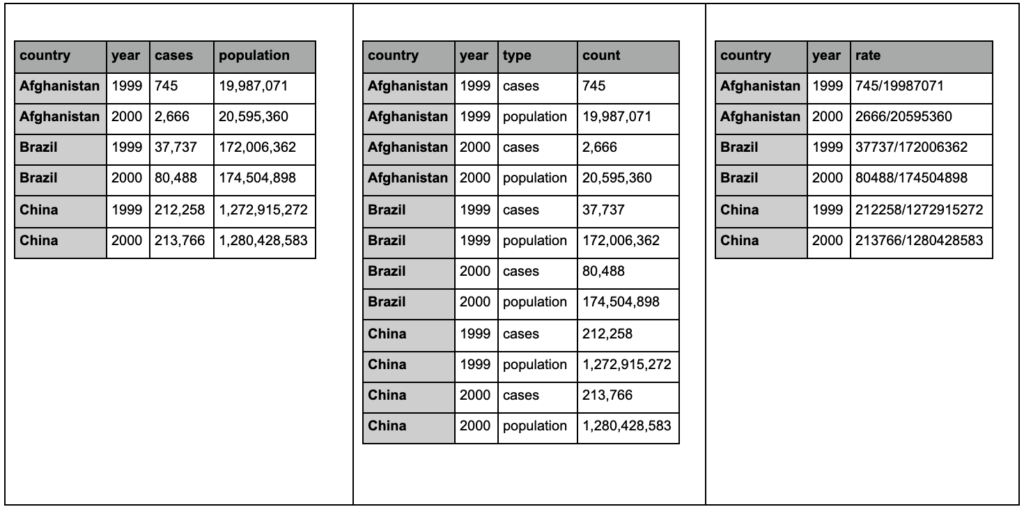
tidyr 包中的示例表。
您会发现这三个表包含完全相同的信息,但以不同的方式组织和呈现。 我们可以将病例和人口放在两个单独的列中(表 1),或者有一列告诉我们观察结果是什么(病例或人口),还有一个“计数”列来计算这些病例(表 2)。 在表 3 中,它们以比率显示。
在处理数据时,您会发现不同的来源以不同的方式组织数据,并且您经常需要更改某些格式以便更好、更轻松地进行分析。 熟悉这些清理操作至关重要,R 中的 tidyr 包包含用于此目的的特殊工具。 如果你更喜欢 Python,你也可以使用 pandas,你可以查看一下 melt 和 pivot 函数。
一旦我们的数据采用某种格式,我们可能想要进一步操作它。
转换
构建的另一个关键技能是能够对正在使用的数据进行任何更改。 理想的情况是达到可以与数据进行对话的阶段,并且能够以任何您想提出非常具体的问题的方式进行切片和切块,并希望获得有趣的见解。 以下是一些您可能非常需要的最重要的转换任务以及您可能感兴趣的一些示例任务:
在获取、整理并以所需格式放置我们的数据之后,最好将其可视化。
可视化
数据可视化是一个庞大的主题,其中一些子主题有整本书。 它是可以为我们的数据提供大量洞察力的东西之一,尤其是它使用直观的视觉元素来传达信息。 例如,条形图中条形的相对高度会立即向我们显示它们的相对数量。 颜色的强度、相对位置和许多其他视觉属性很容易被读者识别和理解。
一张好的图表胜过一千个(关键)字!
由于数据可视化有许多主题需要讨论,我将简单分享一些可能有趣的示例。 如果您想要完整的详细信息,其中几个是此贫困数据仪表板的构建块。
有时您可能只需要一个简单的条形图来比较值,其中条形可以垂直或水平显示:
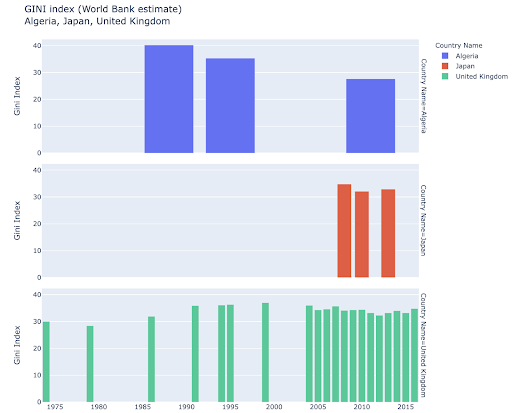
您可能有兴趣探索某些国家,并通过查看它们在某些指标上的进展情况进行更深入的挖掘。 在这种情况下,您可能希望在同一个图中显示多个条形图:
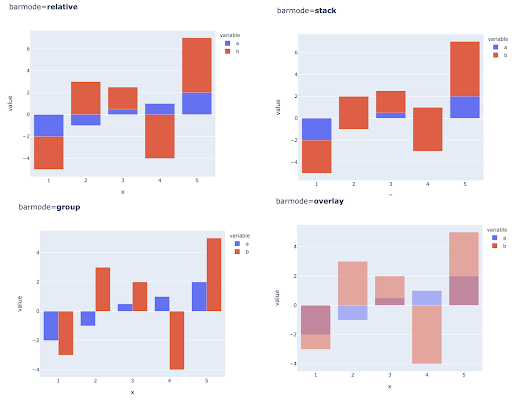
也可以通过在每个 X 轴位置放置多个条来比较多个观察值的多个值,以下是执行此操作的主要方法:
颜色和色标的选择:数据可视化的重要组成部分,如果操作正确,可以非常有效和直观地传达信息。
分类色标:用于表示分类数据。 顾名思义,这是显示某个观察属于哪个类别的数据类型。 在这种情况下,我们希望颜色尽可能不同,以显示类别中的明显差异(特别是对于彼此相邻显示的视觉元素)。
以下示例使用分类色标来显示每个国家/地区实施的政府系统。 将国家的颜色与显示使用哪种政府系统的图例联系起来非常容易。 这也称为等值线图:
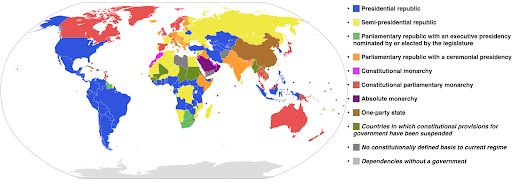
资料来源:维基百科
有时我们想要可视化的数据是针对相同的度量标准的,并且每个国家(或任何其他类型的观察)都落在最小值和最大值之间的连续统一体中的某个点上。 换句话说,我们想要可视化该指标的程度。
在这些情况下,我们需要找到一个连续(或连续)的色标。 在下面的示例中可以立即清楚地看到哪些国家更蓝(因此获得更多流量),我们可以直观地了解国家之间的细微差别。
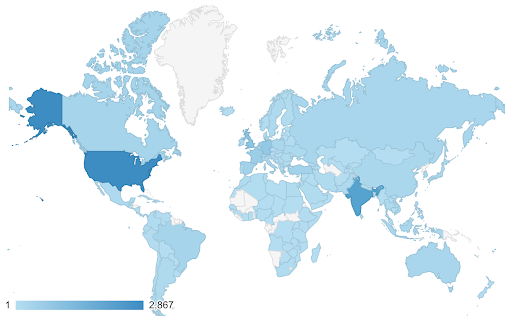
您的数据可能是连续的(如上面的交通地图),但有关数字的重要一点可能是它们与某个点的偏离程度。 在这种情况下,发散色标很有用。
下图显示了净人口增长率。 在这种情况下,首先要知道某个国家的增长率是正数还是负数是很有趣的。 或者,我们想知道每个国家离零有多远(以及多远)。 看一眼地图,我们立即可以看到哪些国家的人口正在增长,哪些正在减少。 图例还向我们展示了最大阳性率为 3.5%,最大阴性率为 -0.5%。 这也为我们提供了值范围(正数和负数)的指示。
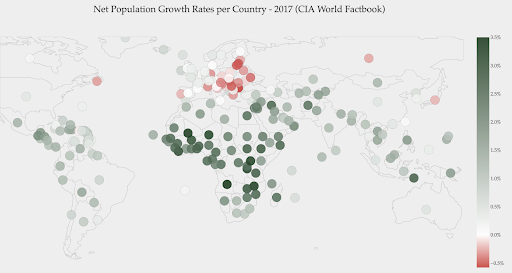
资料来源:Dashboardom.com
不幸的是,为这个尺度选择的颜色并不理想,因为色盲的人可能无法正确区分红色和绿色。 在选择我们的色标时,这是一个非常重要的考虑因素。
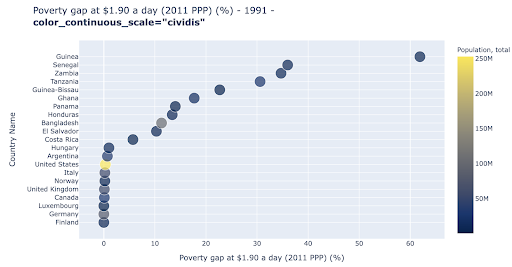
散点图是使用最广泛、用途广泛的绘图类型之一。 点(或任何其他标记)的位置传达了我们试图传达的数量。 除了位置之外,我们还可以使用颜色、大小和形状等其他几个视觉属性来传达更多信息。 下面的例子显示了生活在 1.9 美元/天的人口百分比,我们可以清楚地看到点的水平距离。
我们还可以使用颜色为图表添加新维度。 这对应于可视化来自同一数据集的第三列,在这种情况下显示人口数据。
我们现在可以看到,就人口(美国)而言,最极端的情况是贫困水平指标非常低。 这增加了我们图表的丰富性。 我们还可以使用大小和形状来可视化我们数据集中的更多列。 不过,我们需要在丰富性和可读性之间取得良好的平衡。
我们可能有兴趣检查人口和贫困水平之间是否存在关系,因此我们可以以稍微不同的方式可视化相同的数据集,看看是否存在这种关系:
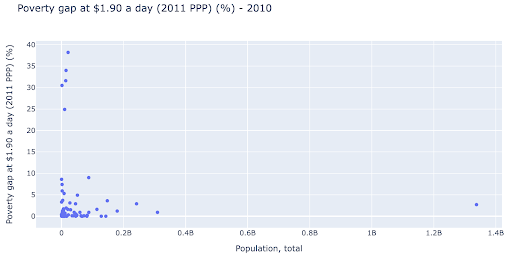
我们在人口中有一个异常值,大约为 1.35B,这意味着我们在图表中有很多空白,这也意味着许多值被压缩在一个非常小的区域中。 我们也有许多重叠的点,这使得很难发现任何差异或趋势。
下图包含相同的信息,但使用两种技术进行了不同的可视化:
- 对数刻度:我们通常会看到加法刻度的数据。 换句话说,轴(X 或 Y)上的每个点都表示添加了一定数量的可视化数据。 我们也可以有乘法尺度,在这种情况下,对于 X 轴上的每个新点,我们乘以(在本例中乘以 10)。 这允许点分散,我们需要考虑倍数而不是加法,就像我们在上一张图表中所做的那样。
- 使用不同的标记(更大的空圆圈) :为我们的标记选择不同的形状解决了“过度绘图”的问题,即我们可能在同一位置有多个点相互重叠,这使得甚至很难看到我们有多少分。
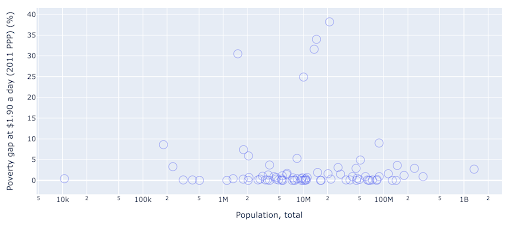
我们现在可以看到,在 1000 万大关附近有一个国家集群,以及其他较小的集群。
正如我所提到的,还有更多类型的字符和可视化选项,以及有关该主题的整本书。 我希望这能给你一些有趣的想法来进行实验。
抓取数据³
 学到更多
学到更多模型
我们需要简化我们的数据,找到模式,做出预测,或者只是更好地理解它。 这是另一个大主题,范围可以从简单地获取一些汇总统计数据(平均值、中位数、标准差等)到可视化我们的数据建模,使用总结或发现趋势的模型,再到使用更复杂的技术来获得我们数据的数学公式。 我们还可以使用机器学习来帮助我们在数据中发现更多见解。
同样,这不是对该主题的完整讨论,但我想分享几个示例,您可能会使用一些机器学习技术来帮助您。
在爬网数据集中,我试图了解更多关于 404 页面的信息,以及是否能发现一些关于它们的信息。 我的第一次尝试是检查页面大小与其状态码之间是否存在相关性,并且存在——几乎完美的相关性!
几分钟后,我感觉自己像个天才,很快就回到了地球。
404 页面都处于非常紧凑的页面大小范围内,几乎所有具有一定千字节数的页面都有 404 状态代码。 然后我意识到,根据定义,404 页面上除了“404 错误页面”之外没有任何内容! 这就是为什么他们有相同的大小。
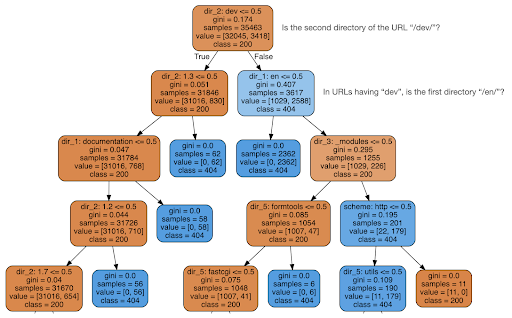
然后我决定检查内容是否可以告诉我有关状态代码的信息,因此我将 URL 拆分为它们的元素,并使用 sklearn 运行决策树分类器。 这基本上是一种产生决策树的技术,遵循它的规则可以引导我们学习如何找到我们的目标,在这种情况下是 404 页。
在下面的决策树中,每个框中的第一行显示要遵循或检查的规则,“samples”行是在此框中找到的观察数,“class”行告诉我们当前观察的类别,在这种情况下,它的状态码是 200 还是 404。
更多细节我就不说了,而且我知道如果你不熟悉决策树可能不太清楚,如果你有兴趣可以探索原始爬取数据集和分析代码。
基本上,决策树发现的是如何使用 URL 的目录结构找到几乎所有的 404 页面。 如您所见,我们找到了 3,617 个 URL,仅通过检查 URL 的第二个目录是否为“/dev/”(顶部第二行中的第一个浅蓝色框)。 所以现在我们知道如何定位我们的 404,而且似乎它们几乎都在站点的“/dev/”部分。 这绝对是一个巨大的节省时间。 想象一下,手动遍历所有可能的 URL 结构和组合以找到此规则。
我们仍然没有完整的图片以及为什么会发生这种情况,这可以进一步研究,但至少我们现在很容易找到这些 URL。

您可能有兴趣使用的另一种技术是 KMeans 聚类,它将数据点分组到不同的组/集群中。 这是一种“无监督学习”技术,算法帮助我们发现我们不知道存在的模式。
想象一下,你有一堆数字,比如说国家的人口,你想把它们分成两组,大的和小的。 你会怎么做? 你会在哪里画线?
这与获得前十个国家或前 X% 的国家不同。 这将非常容易,我们可以按人口对国家进行排序,并根据需要获得前 X 个国家。
我们想要将它们相对于该数据集分为“大”和“小”,并假设我们对国家人口一无所知。
这可以进一步扩展到尝试将国家分为三类:小型、中型和大型。 如果我们想要五个、六个或更多组,手动完成这将变得更加困难。
请注意,我们不知道每个组中最终有多少国家,因为我们不要求排名前 X 的国家。 分成两个集群,我们可以看到我们在这个大集团中只有两个国家:中国和印度。 这很直观,因为这两个国家的平均人口与所有其他国家都相距甚远。 这组国家有自己的平均值,并且其国家之间的距离比另一组国家更接近:
国家按人口分为两组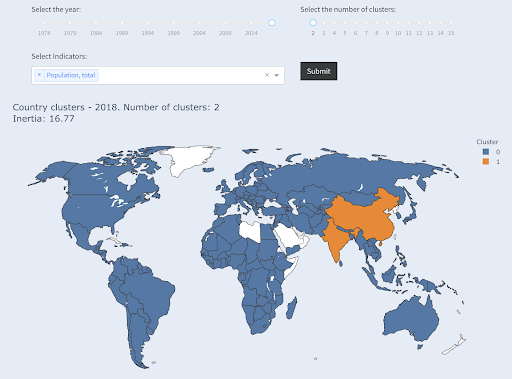
就人口而言,第三大国家(美国约 3.3 亿)与所有其他国家(包括拥有 100 万人口的国家)归为一类。 那是因为 330M 比 13 亿更接近 1M。 如果我们要求三个集群,我们会得到不同的画面:
国家按人口分为三组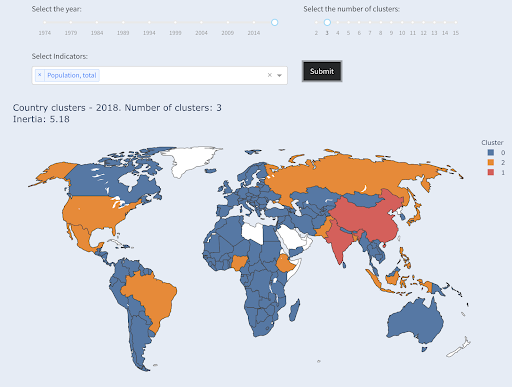
如果我们要求四个集群,这就是国家的集群方式:
国家按人口分为四组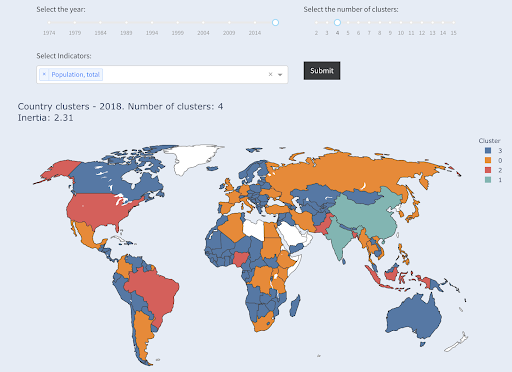
资料来源:pivotdata.org(“集群国家”选项卡)
在这种情况下,这是仅使用一个维度(人口)进行聚类,您还可以添加更多维度,并查看国家的最终结果。
还有许多其他技术和工具,这些只是一些希望有趣和实用的示例。
现在我们准备好与我们的听众交流我们的发现。
交流
在我们在前面的步骤中完成所有工作之后,我们最终需要将我们的发现传达给其他项目利益相关者。
数据科学中最重要的工具之一是交互式笔记本。 Jupyter notebook 是使用最广泛的,几乎支持所有编程语言,您可能更喜欢使用 RStudio 的特殊 notebook 格式,它的工作方式相同。
主要思想是将数据、代码、叙述和可视化放在一个地方,以便其他人可以审核它们。 重要的是要展示你是如何得出这些结论和建议的,以提高透明度和可重复性。 其他人应该能够运行相同的代码并获得相同的结果。
另一个重要原因是其他人(包括“未来的你”)能够进一步分析,并在你所做的初始工作的基础上进行改进,并以新的方式扩展它。
当然,这假设观众对代码感到满意,并且他们甚至关心它!
您还可以选择将您的笔记本导出为 HTML(和其他几种格式),不包括代码,这样您最终会得到一个用户友好的报告,同时保留完整的代码以重现相同的分析和结果。
通信的一个重要元素是数据可视化,上面也简要介绍了这一点。
更好的是交互式数据可视化,在这种情况下,您允许您的受众选择值,并查看图表和指标的各种组合以进一步探索数据。
以下是我创建的一些仪表板和数据应用程序(其中一些可能需要几秒钟才能加载),以便让您了解可以做什么。
最终,您还可以为您的项目创建自定义应用程序,以满足特殊需求和要求,这是另一组您可能感兴趣的 SEO 和营销应用程序。
我们完成了数据科学周期中的主要步骤,现在让我们探索“学习 python”的另一个好处。
Python 是为了自动化和生产力:真实但不完整
在我看来,人们认为学习 Python 主要是为了获得生产力和/或自动化任务。
这是绝对正确的,我认为我们甚至不需要讨论能够在我们手动完成的一小部分时间内完成某件事的价值。
争论的另一个缺失部分是数据分析。 良好的数据分析为我们提供了洞察力,理想情况下,我们能够根据我们的专业知识和我们拥有的数据提供可操作的洞察力来指导我们的决策过程。
我们所做的大部分工作是尝试了解正在发生的事情,分析竞争,找出最有价值的内容在哪里,决定做什么,等等。 我们是顾问、顾问和决策者。 能够从我们的数据中获得一些见解显然是一个很大的好处,这里提到的领域和技能可以帮助我们实现这一目标。
如果您了解到您的标题标签的平均长度为 60 个字符,这很好吗?
如果您深入挖掘并发现您的标题中有一半远低于 60,而另一半有更多字符(平均为 60),该怎么办? In order to get practical and provide good recommendations, you need a higher-resolution view of your title tags' lengths, probably a histogram that shows the frequency of your title tag lengths at each interval so you can have a separate strategy for length. A simple table would also do, for example:
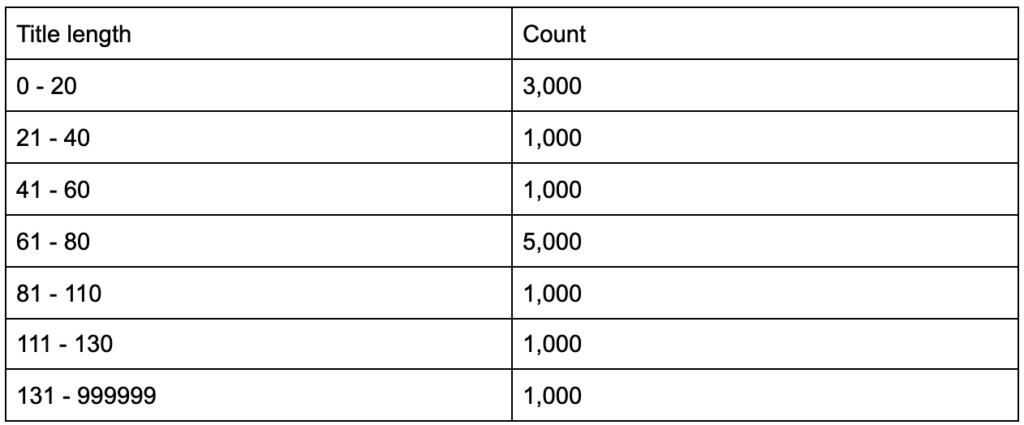
Splitting title lengths by intervals of twenty was an arbitrary decision, and you can split them the way you want. Looking at the table above, and seeing that we have three times more than the average titles in the interval (0, 20), we might want to split it further to better understand what is going on.
Having a better view than the default single-statistic summaries that we get from standard tools, allows us to employ different strategies for different lengths. For example, we can remove the brand name from the titles that are longer than a certain number of characters, and keep it in other titles.
This was an example of very simple insights, which are possible due to the flexibility we get by using a programming language, and a set of data science tools. This also allows us to iterate and modify our approach, until we find a satisfactory point that can take our analysis to the next steps.
Visualization, machine learning, modeling and general data manipulation skills allow us to get better insights on our data, even though those analyses are typically done only once. Still, if you use code to get those insights, you can always take some parts and apply to other projects, or again to the same project. In this case, the insights we got, helped us in our automation, even more. The insights would tell us what needs to be automated and what doesn't.
Should you learn Python?
Is a useless question, and the more useful one is, “How much Python (or R) should you learn?”
My view of how we use computers has evolved in the last few years.
I used to think that there were two main ways of using computers, either you are a regular user, using “point-and-click” applications to do certain tasks, or you are a developer who creates those applications that the rest of us use.

I then realized that it is more like a continuum between very high level use (pizza ordering approach), and the lower levels of the farm approach. I also realized that there is a happy sweet spot in between, where you learn enough programming to get productive and boost your data analysis skills, without having to become a software developer or engineer.
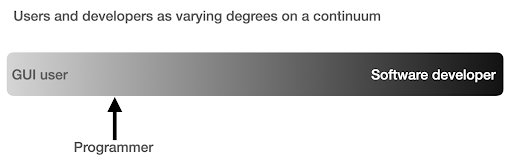
What are the main differences between being a programmer (a software user), and a software developer (or engineer)?
What are the differences between making a great coffee at home, versus establishing and running a cafe?
If making good coffee is one skill, then running a cafe requires ten other skills, most of which have nothing to do with making coffee.
You have to choose a good location (real estate), hire people (management and HR), manage cash flow and finances (accounting and finance), do marketing, legal, manage delivery, adhere to cleanliness and health standards, and so on. You can be a great coffee maker without knowing anything about those fields, but if you want to take it to the next level, you will have to manage all those additional tasks unrelated to making coffee.
The same applies to being a good programmer or data analyst versus being a software developer/engineer. There are so many other things that you have to know and worry about that you don't need as a regular programmer doing stuff for yourself and co-workers and clients. Once you have enough knowledge and skills in programming and data science, you will be in a good position to choose and decide whether you want to continue as an analyst, focusing on data science, or if you want to end up creating software that other people would use.
How do I get into Data Science?
To learn anything I think you have to do two things in parallel:
- Learn the fundamentals and the theory properly: Taking courses and reading books, and getting into the fundamentals can push you forward, as you will be gaining in weeks, knowledge that took decades to establish. It would also immediately give you ideas on things you thought were impossible, or had no idea existed.
- Get as much real world exposure and experience as possible: Experience is always important, and my suggestion is to try as soon as you can to read_csv with Python or R, to actually do so with your GA, GSC, or crawl dataset. See what else you can do (visualize, manipulate, model, etc.). See if you get errors, try to analyze the data only using your programming language.
What does frustration look like, and by when will I get productive?
It's difficult to say, and it depends on your skill, background, the hours you put in, but visualizing it like this might help you on those frustrating unproductive days:
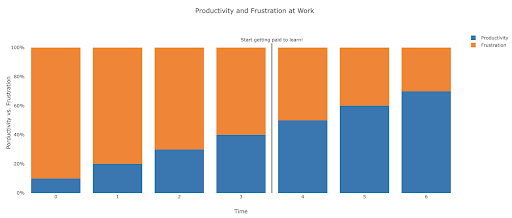
My suggestion is to take a non-trivial task, for example running an SEO audit for a site, only using Python. Your first session will mostly be frustrating, and most of the time will be spent checking documentation, and the definition of basic terms.
In parallel, you are still going through your course, and learning new stuff.
The value of that frustrating session is that it informs and motivates your theoretical learning. You will have questions in mind, and when you learn new things, you will immediately have a place to implement them.
Your next analysis session will probably be a little more productive, but still not productive enough to do at work. You go again to your learning and theory.
Do this enough times, and your time will become mostly productive, eventually you will be doing real work during working hours. The ideal scenario is where you are productive enough to do work, but every time use some time to research better techniques, which improves your work as well. By then you will start to get paid for learning, and your clients will be happily sponsoring you!
建议的后续步骤
For the learning path a Data Science course would be great, especially if you get feedback on your work, and you can follow the topics in the order recommended.
If you go with Python I suggest the following libraries:
- pandas: The workhorse of all your tasks in preparing, cleaning, reshaping data whichever way you want. Fluency in pandas allows you to have full control over your data, which will help you immensely in visualization, general analysis, and machine learning
- Plotly and Dash: This is my favorite data visualization library, although there are many others. What I mostly like about it, is that it produces interactive and responsive HTML charts by default. It is very detailed and thorough in its options, yet simple to use. Plotly also includes Plotly Express, which is a high-level plotting tool, which is more intuitive to use, and takes a data-oriented approach (as opposed to a chart-oriented approach). Plotly also created Dash, which is the tool for creating interactive dashboards, but also serves as a full front-end web development framework. Other important data visualization libraries are matplotlib, altair, and bokeh, and for interactive data apps, there is panel and streamlit. Another important feature is that Plotly and Dash are available in all languages used in Data Science. You might use other libraries, and this is just my personal preference. Speaking of personal preferences:
- advertools: This is a library that I created to provide various online marketing tools, most importantly, an SEO crawler, log file parser and compressor, multi robots.txt parser, recursive sitemap parser, SEM keyword and text ad generator for large scale campaigns, weighted frequency word counter, Google SERP downloader, YouTube data API, and a few other tools. It is still evolving, and you are more than welcome to contribute any suggestions, bugs, or issues you might have with it.
These should be enough for beginners, and when you are familiar with them, you can do your own research for more specialized libraries, machine learning and deep learning tools, or libraries that are specialized in performance, or a special niche use-case.