
Data Science per SEO e Digital Marketing: una guida consigliata per i principianti
Pubblicato: 2021-12-07Poiché la maggior parte del nostro lavoro ruota attorno ai dati e poiché il campo della scienza dei dati sta diventando molto più grande e molto più accessibile ai principianti, vorrei condividere alcune riflessioni su come potresti entrare in questo campo per aumentare il tuo SEO e marketing abilità in generale.
Qual è la scienza dei dati?
Un diagramma molto noto che viene utilizzato per fornire una panoramica di questo campo è il diagramma di Venn di Drew Conway che mostra la scienza dei dati come l'intersezione di statistiche, hacking (abilità di programmazione avanzate in generale e non necessariamente penetrare nelle reti e causare danni) e sostanziali competenza o “conoscenza di dominio”:
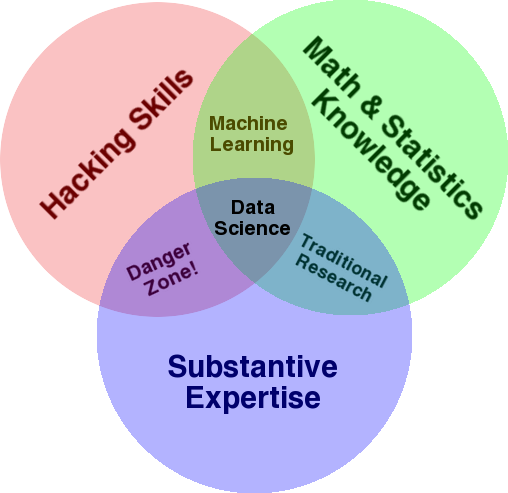
Fonte: oreilly.com
Quando ho iniziato a imparare, ho subito capito che questo è esattamente quello che già facciamo. L'unica differenza è che lo stavo facendo con strumenti più basilari e manuali.
Se guardi il diagramma, vedrai facilmente come probabilmente lo fai già. Utilizzi un computer (abilità di hacking), per analizzare dati (statistiche), per risolvere un problema pratico usando la tua esperienza sostanziale in SEO (o qualsiasi specialità su cui ti concentri).
Il tuo attuale "linguaggio di programmazione" è probabilmente un foglio di calcolo (Excel, Fogli Google, ecc.) e molto probabilmente usi Powerpoint o qualcosa di simile per comunicare idee. Espandiamo un po' questi elementi.
- Conoscenza del dominio: iniziamo con il tuo principale punto di forza, poiché già conosci la tua area di competenza. Tieni presente che questa è una parte essenziale dell'essere un data scientist ed è qui che puoi costruire e proteggere le tue conoscenze. Alcuni mesi fa, stavo discutendo dell'analisi di un set di dati di scansione con un mio amico. È un fisico, svolge attività di ricerca post-dottorato sui computer quantistici. Le sue conoscenze e abilità in matematica e statistica sono ben oltre le mie e sa davvero come analizzare i dati molto meglio di me. Un problema. Non sapeva cosa fosse un "404" (o perché ci interessasse un "301"). Quindi, con tutta la sua conoscenza di matematica non è stato in grado di dare un senso alla colonna "stato" nel set di dati di scansione. Naturalmente, non saprebbe cosa fare con quei dati, con chi parlare e quali strategie costruire sulla base di quei codici di stato (o se cercare altrove). Io e te sappiamo cosa fare con loro, o almeno sappiamo dove altro cercare se vogliamo scavare più a fondo.
- Matematica e statistica: se utilizzi Excel per ottenere la media di un campione di dati, stai utilizzando le statistiche. La media è una statistica che descrive un certo aspetto di un campione di dati. Statistiche più avanzate ti aiuteranno a comprendere i tuoi dati. Anche questo è essenziale e non sono un esperto in questo settore. Più distribuzioni statistiche conosci, più idee hai su come analizzare i dati. Più argomenti fondamentali conosci, meglio riesci a formulare le tue ipotesi e fare affermazioni precise sui tuoi set di dati.
- Abilità di programmazione: ne parlerò più dettagliatamente di seguito, ma principalmente è qui che costruisci la flessibilità di dire al computer di fare esattamente quello che vuoi che faccia, invece di rimanere bloccato con facile da usare ma leggermente restrittivo Strumenti. Questo è il tuo modo principale per ottenere, rimodellare e pulire i tuoi dati, come preferisci, aprendo la strada a "conversazioni" aperte e flessibili con i tuoi dati.
Diamo ora un'occhiata a ciò che di solito facciamo in Data Science.
Il ciclo della scienza dei dati
Un tipico progetto di scienza dei dati o anche un'attività, di solito assomiglia a questo:
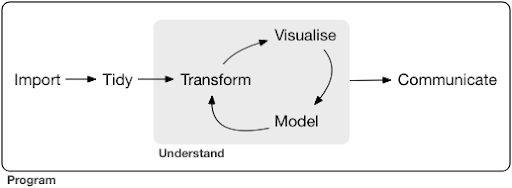
Fonte: r4ds.had.co.nz
Consiglio vivamente anche di leggere questo libro di Hadley Wickham e Garrett Grolemund che funge da ottima introduzione alla scienza dei dati. È scritto con esempi dal linguaggio di programmazione R, ma i concetti e il codice possono essere facilmente compresi se conosci solo Python.
Come puoi vedere nel diagramma, dobbiamo prima importare i nostri dati in qualche modo, metterli in ordine e quindi iniziare a lavorare sul ciclo interno di trasformazione, visualizzazione e modello. Dopodiché comunichiamo i risultati con gli altri.
Questi passaggi possono variare da estremamente semplici a molto complessi. Ad esempio, il passaggio "Importa" potrebbe essere semplice come leggere un file CSV e in alcuni casi potrebbe consistere in un progetto di scraping web molto complicato per ottenere i dati. Molti degli elementi del processo sono specialità a tutti gli effetti.
Possiamo facilmente mappare questo su alcuni processi familiari che conosciamo. Ad esempio, potresti iniziare ottenendo alcuni metadati su un sito Web, scaricando le relative mappe del sito robots.txt e XML. Probabilmente quindi eseguiresti la scansione e forse anche ottenere alcuni dati sulle posizioni SERP o collegare i dati, ad esempio. Ora che hai alcuni set di dati, probabilmente vorrai unire alcune tabelle, imputare alcuni dati aggiuntivi e iniziare a esplorare/comprendere. La visualizzazione dei dati può esporre schemi nascosti, aiutarti a capire cosa sta succedendo o forse sollevare più domande. Probabilmente vorrai anche modellare i tuoi dati utilizzando alcune statistiche di base o modelli di apprendimento automatico e, si spera, ottenere alcune informazioni. Naturalmente, è necessario comunicare i risultati e le domande alle altre parti interessate al progetto.
Una volta che hai acquisito sufficiente familiarità con i vari strumenti disponibili per ciascuno di questi processi, puoi iniziare a creare le tue pipeline personalizzate specifiche per un determinato sito Web, perché ogni azienda è unica e ha una serie speciale di requisiti. Alla fine, inizierai a trovare schemi e non dovrai rifare l'intero lavoro per progetti/siti web simili.
Ci sono numerosi strumenti e librerie disponibili per ogni elemento in questo processo e può diventare piuttosto opprimente, quale strumento scegli (e investi il tuo tempo nell'apprendimento). Diamo un'occhiata a un possibile approccio che trovo utile nella selezione degli strumenti che utilizzo.
Scelta di strumenti e compromessi (3 modi di avere una pizza)
Dovresti usare Excel per il tuo lavoro quotidiano nell'elaborazione dei dati o vale la pena imparare Python?
Faresti meglio a visualizzare con qualcosa come Power BI o dovresti investire nell'apprendimento della grammatica della grafica e imparare a usare le librerie che la implementano?
Produrresti un lavoro migliore costruendo le tue dashboard interattive con R o Python o dovresti semplicemente utilizzare Google Data Studio?
Per prima cosa esploriamo i compromessi coinvolti nella selezione di vari strumenti a diversi livelli di astrazione. Questo è un estratto dal mio libro sulla creazione di dashboard interattive e app di dati con Plotly e Dash e trovo utile questo approccio:
Considera tre diversi approcci per mangiare una pizza:
- L'approccio all'ordinazione: chiami un ristorante e ordini la tua pizza. Arriva alla tua porta in mezz'ora e inizi a mangiare.
- L'approccio del supermercato: vai al supermercato, compri pasta, formaggio, verdure e tutti gli altri ingredienti. Quindi fai la pizza da solo.
- L'approccio alla fattoria: coltivi pomodori nel tuo giardino. Allevi le mucche, le munge e trasformi il latte in formaggio e così via.
Man mano che saliamo alle interfacce di livello superiore, verso l'approccio di ordinamento, la quantità di conoscenza richiesta diminuisce molto. Qualcun altro ha la responsabilità e la qualità è controllata dalle forze di mercato della reputazione e della concorrenza.
Il prezzo che paghiamo per questo è la diminuzione della libertà e delle opzioni. Ogni ristorante ha una serie di opzioni tra cui scegliere e devi scegliere tra quelle opzioni.
Scendendo ai livelli più bassi, la quantità di conoscenza richiesta aumenta, dobbiamo gestire più complessità, abbiamo più responsabilità per i risultati e ci vuole molto più tempo. Quello che otteniamo qui è molta più libertà e potere di personalizzare i nostri risultati nel modo che vogliamo. Anche il costo è un grande vantaggio, ma solo su una scala sufficientemente ampia. Se vuoi mangiare solo una pizza oggi, probabilmente è più economico ordinarla. Ma se prevedi di averne uno ogni giorno, puoi aspettarti un notevole risparmio sui costi se lo fai da solo.
Questi sono i tipi di scelte che dovrai fare quando scegli quali strumenti usare e imparare. L'uso di un linguaggio di programmazione come R o Python richiede molto più lavoro ed è più difficile di Excel, con il vantaggio di renderti molto più produttivo e potente.
La scelta è importante anche per ogni strumento o processo. Ad esempio, potresti utilizzare un crawler di alto livello e facile da usare per raccogliere dati su un sito Web, e tuttavia potresti preferire utilizzare un linguaggio di programmazione per visualizzare i dati, con tutte le opzioni disponibili. La scelta dello strumento giusto per il processo giusto dipende dalle tue esigenze e si spera che il compromesso sopra descritto possa aiutare a fare questa scelta. Si spera che questo aiuti anche a rispondere alla domanda se (o quanto) Python o R vuoi imparare.
Prendiamo questa domanda un po' oltre e vediamo perché imparare Python per SEO potrebbe non essere la parola chiave giusta.
Perché "python for seo" è fuorviante
Vorresti diventare un grande blogger o vuoi imparare WordPress?
Vorresti diventare un grafico o il tuo obiettivo è imparare Photoshop?
Sei interessato a migliorare la tua carriera SEO portando le tue competenze sui dati al livello successivo o vuoi imparare Python?
Nei primi cinque minuti della prima lezione del corso di informatica al MIT, il professor Harold Abelson apre il corso spiegando agli studenti perché “informatica” è un brutto nome per la disciplina che stanno per imparare. Penso che sia molto interessante guardare i primi cinque minuti della lezione:
Quando un campo è appena iniziato e non lo capisci molto bene, è molto facile confondere l'essenza di ciò che stai facendo, con gli strumenti che usi. – Harold Abelson
Stiamo cercando di migliorare la nostra presenza online e i risultati, e molto di ciò che facciamo si basa sulla comprensione, visualizzazione, manipolazione e gestione dei dati in generale, e questo è il nostro obiettivo, indipendentemente dallo strumento utilizzato. La scienza dei dati è il campo che ha le strutture intellettuali per farlo, oltre a molti strumenti per implementare ciò che vogliamo fare. Python potrebbe essere il tuo linguaggio di programmazione (strumento) preferito ed è sicuramente importante impararlo bene. Altrettanto importante, se non più importante, è anche concentrarsi sull'“essenza di ciò che si sta facendo”, nel nostro caso elaborando e analizzando i dati.
L'obiettivo principale dovrebbe essere sui processi discussi sopra (importazione, riordino, visualizzazione, ecc.), in contrapposizione al linguaggio di programmazione scelto. O meglio, come usare quel linguaggio di programmazione per portare a termine i tuoi compiti, invece di imparare semplicemente un linguaggio di programmazione.
A chi importa di tutte queste distinzioni teoriche se imparerò comunque Python?
Diamo un'occhiata a cosa potrebbe accadere se ti concentri sull'apprendimento dello strumento, in contrapposizione all'essenza di ciò che stai facendo. Qui, confrontiamo la ricerca di "learn wordpress" (lo strumento) con "learn blogging" (la cosa che vogliamo fare):
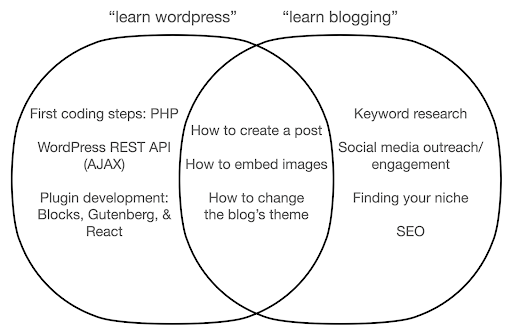
Il diagramma mostra i possibili argomenti in un libro o in un corso che insegna la parola chiave in alto. L'area di intersezione al centro mostra argomenti che potrebbero verificarsi in entrambi i tipi di corso/libro.
Se ti concentri sullo strumento, finirai senza dubbio per dover imparare cose di cui non hai davvero bisogno, soprattutto come principiante. Questi argomenti potrebbero confonderti e frustrarti, soprattutto se non hai un background tecnico o di programmazione.
Imparerai anche cose utili per diventare un buon blogger (gli argomenti nell'area di incrocio). Questi argomenti sono estremamente facili da insegnare (come creare un post sul blog), ma non ti dicono molto sul perché dovresti bloggare, quando e cosa. Questo non è un difetto in un libro incentrato sugli strumenti, perché quando si impara a conoscere uno strumento, sarebbe sufficiente imparare a creare un post sul blog e andare avanti.
Come blogger probabilmente sei più interessato al cosa e al perché del blog, e questo non sarebbe trattato in libri incentrati sugli strumenti.
Ovviamente, le cose strategiche e importanti come SEO, trovare la tua nicchia e così via, non saranno coperte, quindi ti perderai cose molto importanti.
Quali sono alcuni degli argomenti di Data Science che probabilmente non imparerai in un libro di programmazione?
Come abbiamo visto, prendere in mano un Python o un libro di programmazione significa probabilmente che vuoi diventare un ingegnere del software. Gli argomenti sarebbero naturalmente orientati verso tale fine. Se cerchi un libro di Data Science, ottieni argomenti e strumenti più orientati all'analisi dei dati.
Possiamo utilizzare il primo diagramma (che mostra il ciclo di Data Science) come guida e cercare in modo proattivo quegli argomenti: "importare i dati con python", "ordinare i dati con r", "visualizzare i dati con python" e così via. Diamo uno sguardo più approfondito a questi argomenti ed esploriamoli ulteriormente:
Importare
Naturalmente dobbiamo prima ottenere alcuni dati. Questo può essere:
- Un file sul nostro computer: il caso più semplice in cui apri semplicemente il file con il tuo linguaggio di programmazione preferito. È importante notare che ci sono molti formati di file diversi e che hai molte opzioni durante l'apertura/lettura dei file. Ad esempio, la funzione read_csv della libreria pandas (uno strumento essenziale per la manipolazione dei dati in Python) ha cinquanta opzioni tra cui scegliere, durante l'apertura del file. Contiene cose come il percorso del file, le colonne da scegliere, il numero di righe da aprire, l'interpretazione degli oggetti datetime, come gestire i valori mancanti e molto altro. È importante conoscere queste opzioni e le varie considerazioni durante l'apertura di diversi formati di file. Inoltre panda ha diciannove diverse funzioni che iniziano con read_ per vari formati di file e dati.
- Esporta da uno strumento online: probabilmente hai familiarità con questo, e qui puoi personalizzare i tuoi dati e quindi esportarli, dopodiché li aprirai come file sul tuo computer.
- Chiamate API per ottenere dati specifici: questo è a un livello inferiore e più vicino all'approccio farm menzionato sopra. In questo caso si invia una richiesta con requisiti specifici e si ottengono i dati desiderati. Il vantaggio qui è che puoi personalizzare esattamente ciò che desideri ottenere e formattarlo in modi che potrebbero non essere disponibili nell'interfaccia online. Ad esempio in Google Analytics puoi aggiungere una dimensione secondaria a una tabella che stai analizzando, ma non puoi aggiungerne una terza. Sei anche limitato dal numero di righe che puoi esportare. L'API offre maggiore flessibilità e puoi anche automatizzare determinate chiamate in modo che avvengano periodicamente, come parte di una più ampia pipeline di raccolta/analisi dei dati.
- Scansione e scraping dei dati: probabilmente hai il tuo crawler preferito e probabilmente hai familiarità con il processo. Questo è già un processo flessibile, che ci consente di estrarre elementi personalizzati dalle pagine, eseguire la scansione solo di determinate pagine e così via.
- Una combinazione di metodi che coinvolgono l'automazione, l'estrazione personalizzata e possibilmente l'apprendimento automatico per usi speciali.
Una volta che abbiamo alcuni dati, vogliamo passare al livello successivo.
Ordinato
Un set di dati "ordinato" è un set di dati organizzato in un certo modo. Vengono anche chiamati dati di "formato lungo". Il capitolo 12 del libro R for Data Science discute il concetto di dati ordinati in modo più dettagliato, se sei interessato.
Dai un'occhiata alle tre tabelle seguenti e prova a trovare eventuali differenze:
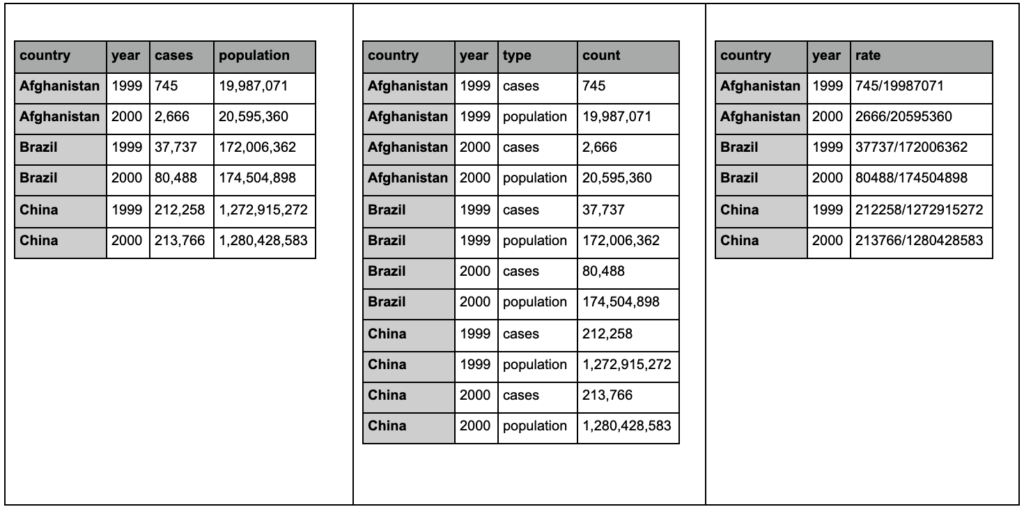
Tabelle di esempio dal pacchetto tidyr.
Scoprirai che le tre tabelle contengono esattamente le stesse informazioni, ma organizzate e presentate in modi diversi. Possiamo avere casi e popolazione in due colonne separate (tabella 1) o avere una colonna per dirci qual è l'osservazione (casi o popolazione) e una colonna "conta" per contare quei casi (tabella 2). Nella tabella 3 sono indicati come tariffe.
Quando hai a che fare con i dati, scoprirai che origini diverse organizzano i dati in modo diverso e che spesso dovrai passare da/a determinati formati per un'analisi migliore e più semplice. Conoscere queste operazioni di pulizia è fondamentale e il pacchetto tidyr in R contiene strumenti speciali per questo. Puoi anche usare i panda se preferisci Python e puoi controllare le funzioni melt e pivot per quello.
Una volta che i nostri dati sono in un determinato formato, potremmo voler manipolarli ulteriormente.
Trasformare
Un'altra abilità cruciale da costruire è la capacità di apportare le modifiche desiderate ai dati con cui si sta lavorando. Lo scenario ideale è raggiungere la fase in cui puoi avere conversazioni con i tuoi dati ed essere in grado di affettare e tagliare in qualsiasi modo desideri porre domande molto specifiche e, si spera, ottenere spunti interessanti. Ecco alcune delle attività di trasformazione più importanti di cui probabilmente avrai molto bisogno con alcune attività di esempio che potrebbero interessarti:
Dopo aver ottenuto, riordinato e messo i nostri dati nel formato desiderato, sarebbe bene visualizzarli.
Visualizzare
La visualizzazione dei dati è un argomento enorme e ci sono interi libri su alcuni dei suoi argomenti secondari. È una di quelle cose che possono fornire molte informazioni sui nostri dati, in particolare il fatto che utilizza elementi visivi intuitivi per comunicare le informazioni. L'altezza relativa delle barre in un grafico a barre ci mostra immediatamente la loro quantità relativa, ad esempio. L'intensità del colore, la posizione relativa e molti altri attributi visivi sono facilmente riconoscibili e comprensibili dai lettori.
Un buon grafico vale più di mille parole (chiave)!
Poiché ci sono numerosi argomenti da affrontare sulla visualizzazione dei dati, condividerò semplicemente alcuni esempi che potrebbero essere interessanti. Molti di questi sono gli elementi costitutivi di questa dashboard dei dati sulla povertà, se vuoi i dettagli completi.
A volte un semplice grafico a barre è tutto ciò di cui potresti aver bisogno per confrontare i valori, in cui le barre possono essere visualizzate verticalmente o orizzontalmente:
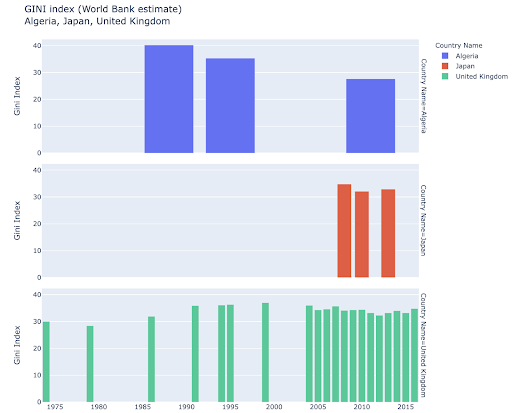
Potresti essere interessato a esplorare determinati paesi e approfondire, vedendo come sono progrediti su determinate metriche. In questo caso potresti voler visualizzare più grafici a barre nello stesso grafico:
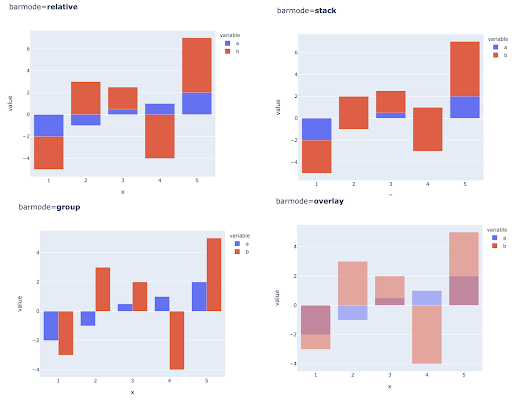
Il confronto di più valori per più osservazioni può essere eseguito anche posizionando più barre in ciascuna posizione dell'asse X, ecco i modi principali per farlo:
Scelta del colore e delle scale di colore: una parte essenziale della visualizzazione dei dati e qualcosa che può comunicare informazioni in modo estremamente efficiente e intuitivo se eseguito correttamente.
Scale di colore categoriali: utili per esprimere dati categoriali. Come suggerisce il nome, questo è il tipo di dati che mostra a quale categoria appartiene una determinata osservazione. In questo caso vogliamo che i colori siano il più distinti possibile tra loro per mostrare chiare differenze nelle categorie (soprattutto per gli elementi visivi che vengono visualizzati uno accanto all'altro).
L'esempio seguente utilizza una scala di colori categorica per mostrare quale sistema di governo è implementato in ciascun paese. È abbastanza facile collegare i colori dei paesi alla legenda che mostra quale sistema di governo viene utilizzato. Questa è anche chiamata mappa coropletica:
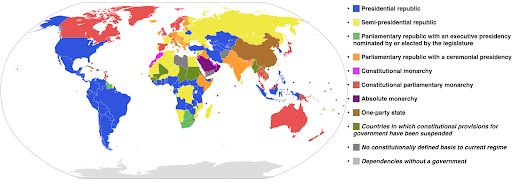
Fonte: Wikipedia
A volte i dati che vogliamo visualizzare sono per la stessa metrica e ogni paese (o qualsiasi altro tipo di osservazione) cade su un certo punto in un continuum che va tra il punto minimo e massimo. In altre parole, vogliamo visualizzare i gradi di quella metrica.
In questi casi dobbiamo trovare una scala di colori continua (o sequenziale) . Nell'esempio seguente è immediatamente chiaro quali paesi sono più blu (e quindi ottengono più traffico) e possiamo comprendere intuitivamente le differenze sfumate tra i paesi.
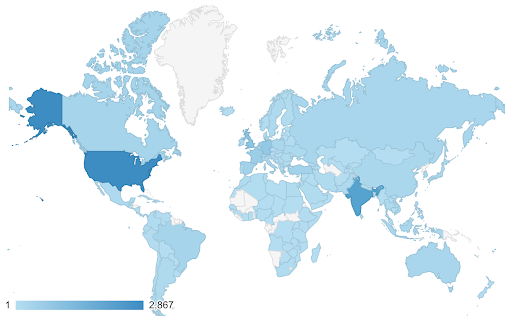
I tuoi dati potrebbero essere continui (come il grafico della mappa del traffico sopra), ma la cosa importante dei numeri potrebbe essere quanto divergono da un certo punto. Le scale di colori divergenti sono utili in questo caso.
Il grafico seguente mostra i tassi di crescita netti della popolazione. In questo caso, è interessante sapere innanzitutto se un determinato Paese ha o meno un tasso di crescita positivo o negativo. Oppure, vogliamo sapere quanto è lontano ogni paese da zero (e di quanto). Uno sguardo alla mappa ci mostra immediatamente quali paesi stanno crescendo e quali stanno diminuendo. La legenda ci mostra anche che il tasso massimo positivo è 3,5% e quello massimo negativo è -0,5%. Questo ci dà anche un'indicazione sull'intervallo di valori (positivo e negativo).

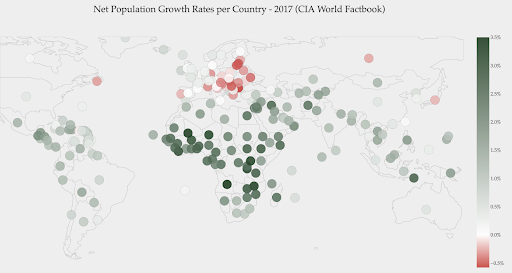
Fonte: Dashboardom.com
Sfortunatamente, i colori scelti per questa scala non sono l'ideale, perché le persone daltoniche potrebbero non essere in grado di distinguere correttamente tra rosso e verde. Questa è una considerazione molto importante quando si scelgono le nostre scale di colori.
Il grafico a dispersione è uno dei tipi di grafico più utilizzati e versatili. La posizione dei punti (o qualsiasi altro marker) esprime la quantità che stiamo cercando di comunicare. Oltre alla posizione, possiamo utilizzare molti altri attributi visivi come colore, dimensione e forma per comunicare ancora più informazioni. L'esempio seguente mostra la percentuale della popolazione che vive a $ 1,9 al giorno, che possiamo vedere chiaramente come la distanza orizzontale dei punti.
Possiamo anche aggiungere una nuova dimensione al nostro grafico usando il colore. Ciò corrisponde alla visualizzazione di una terza colonna dello stesso set di dati, che in questo caso mostra i dati sulla popolazione.
Ora possiamo vedere che il caso più estremo in termini di popolazione (USA) è molto basso nella metrica del livello di povertà. Questo aggiunge ricchezza ai nostri grafici. Avremmo anche potuto utilizzare dimensioni e forma per visualizzare ancora più colonne dal nostro set di dati. Tuttavia, dobbiamo trovare un buon equilibrio tra ricchezza e leggibilità.
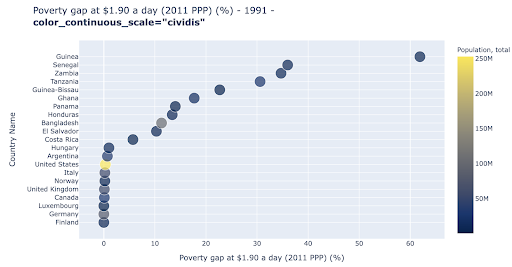
Potremmo essere interessati a verificare se esiste una relazione tra popolazione e livelli di povertà, in modo da poter visualizzare lo stesso set di dati in un modo leggermente diverso per vedere se esiste tale relazione:
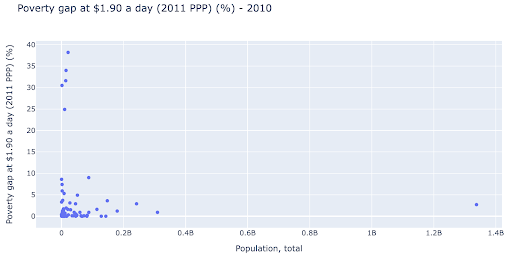
Abbiamo un valore anomalo nella popolazione intorno a 1,35 miliardi, e questo significa che abbiamo molti spazi bianchi nel grafico, il che significa anche che molti valori sono compressi in un'area molto piccola. Abbiamo anche molti punti sovrapposti, il che rende molto difficile individuare eventuali differenze o tendenze.
Il grafico seguente contiene le stesse informazioni ma visualizzate in modo diverso utilizzando due tecniche:
- Scala logaritmica : di solito vediamo i dati su una scala additiva. In altre parole, ogni punto dell'asse (X o Y) rappresenta un'aggiunta di una certa quantità dei dati visualizzati. Possiamo anche avere scale moltiplicative, nel qual caso per ogni nuovo punto sull'asse X moltiplichiamo (per dieci in questo esempio). Ciò consente di distribuire i punti e dobbiamo pensare ai multipli anziché alle addizioni, come abbiamo fatto nel grafico precedente.
- Utilizzo di un marker diverso (cerchi vuoti più grandi) : la selezione di una forma diversa per i nostri marker ha risolto il problema dell'"over-plotting" in cui potremmo avere diversi punti uno sopra l'altro nella stessa posizione, il che rende molto difficile persino vedere quanti punti abbiamo
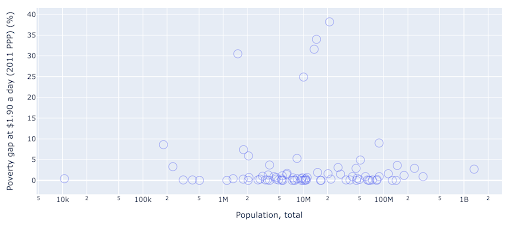
Ora possiamo vedere che c'è un gruppo di paesi intorno alla soglia dei 10 milioni e anche altri gruppi più piccoli.
Come ho già detto, ci sono molti più tipi di caratteri e opzioni di visualizzazione e interi libri scritti sull'argomento. Spero che questo ti dia alcuni pensieri interessanti con cui sperimentare.
Scansione dati³
 Per saperne di più
Per saperne di piùModello
Dobbiamo semplificare i nostri dati e trovare schemi, fare previsioni o semplicemente comprenderli meglio. Questo è un altro argomento di grandi dimensioni e può variare dal semplice ottenere alcune statistiche riassuntive (media, mediana, deviazione standard, ecc.), alla modellazione visiva dei nostri dati, utilizzando un modello che riassume o trova una tendenza, all'utilizzo di tecniche più complesse per ottenere un formula matematica per i nostri dati. Possiamo anche utilizzare l'apprendimento automatico per aiutarci a scoprire più approfondimenti nei nostri dati.
Ancora una volta, questa non è una discussione completa dell'argomento, ma vorrei condividere un paio di esempi in cui potresti utilizzare alcune tecniche di apprendimento automatico per aiutarti.
In un set di dati di scansione, stavo cercando di saperne di più sulle 404 pagine e se riesco a scoprire qualcosa su di esse. Il mio primo tentativo è stato quello di verificare se c'era una correlazione tra la dimensione della pagina e il suo codice di stato, e c'era una correlazione quasi perfetta!
Mi sono sentito un genio, per alcuni minuti, e sono tornato rapidamente sul pianeta Terra.
Le 404 pagine erano tutte in un intervallo molto ristretto di dimensioni della pagina che quasi tutte le pagine con un certo numero di kilobyte avevano un codice di stato 404. Poi mi sono reso conto che 404 pagine per definizione non hanno alcun contenuto su di esse a parte, beh, "404 pagine di errore"! Ed è per questo che avevano le stesse dimensioni.
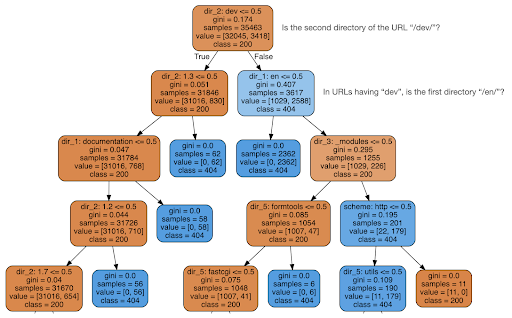
Ho quindi deciso di verificare se il contenuto potesse dirmi qualcosa sul codice di stato, quindi ho diviso gli URL nei loro elementi e ho eseguito un classificatore dell'albero decisionale utilizzando sklearn. Questa è fondamentalmente una tecnica che produce un albero decisionale, dove seguire le sue regole potrebbe portarci a imparare come trovare il nostro obiettivo, 404 pagine in questo caso.
Nel seguente albero decisionale, la prima riga di ogni casella mostra la regola da seguire o controllare, la riga "campioni" è il numero di osservazioni trovate in questa casella e la riga "classe" ci dice la classe dell'osservazione corrente , in questo caso, indipendentemente dal fatto che il suo codice di stato sia 200 o 404.
Non entrerò in ulteriori dettagli e so che l'albero decisionale potrebbe non essere chiaro se non ne hai familiarità e, se sei interessato, puoi esplorare il set di dati di scansione non elaborato e il codice di analisi.
Fondamentalmente ciò che l'albero decisionale ha scoperto è stato come trovare quasi tutte le 404 pagine, utilizzando la struttura delle directory degli URL. Come puoi vedere, abbiamo trovato 3.617 URL, semplicemente controllando se la seconda directory dell'URL fosse o meno "/dev/" (il primo riquadro azzurro nella seconda riga dall'alto). Quindi ora sappiamo come localizzare i nostri 404 e sembra che siano quasi tutti nella sezione "/dev/" del sito. Questo è stato sicuramente un enorme risparmio di tempo. Immagina di passare manualmente attraverso tutte le possibili strutture e combinazioni di URL per trovare questa regola.
Non abbiamo ancora il quadro completo e il motivo per cui ciò sta accadendo, e questo può essere perseguito ulteriormente, ma almeno ora abbiamo individuato molto facilmente quegli URL.
Un'altra tecnica che potrebbe interessarti è il clustering di KMeans, che raggruppa i punti dati in vari gruppi/cluster. Questa è una tecnica di "apprendimento non supervisionato", in cui l'algoritmo ci aiuta a scoprire schemi di cui non sapevamo l'esistenza.
Immagina di avere un mucchio di numeri, diciamo la popolazione dei paesi, e di volerli raggruppare in due gruppi, grandi e piccoli. Come lo faresti? Dove disegneresti la linea?
Questo è diverso dall'ottenere i primi dieci paesi o il primo X% dei paesi. Sarebbe molto facile, possiamo ordinare i paesi per popolazione e ottenere i primi X come vogliamo.
Quello che vogliamo è raggrupparli come "grandi" e "piccoli" rispetto a questo set di dati e supponendo che non sappiamo nulla delle popolazioni dei paesi.
Questo può essere ulteriormente esteso nel tentativo di raggruppare i paesi in tre categorie: piccoli, medi e grandi. Questo diventa molto più difficile da fare manualmente, se vogliamo cinque, sei o più gruppi.
Nota che non sappiamo quanti paesi finiranno in ogni gruppo, dal momento che non stiamo chiedendo i primi X paesi. Raggruppando in due cluster, possiamo vedere che abbiamo solo due paesi nel grande gruppo: Cina e India. Questo ha un senso intuitivo, poiché questi due paesi hanno una popolazione media molto lontana da tutti gli altri paesi. Questo gruppo di paesi ha una propria media e i suoi paesi sono più vicini tra loro rispetto ai paesi dell'altro gruppo:
Paesi raggruppati in due gruppi per popolazione 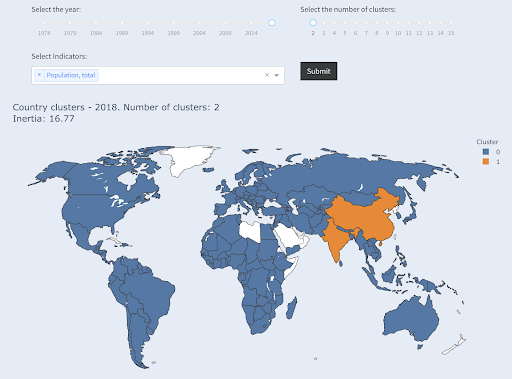
Il terzo paese più grande in termini di popolazione (USA ~ 330 milioni) è stato raggruppato con tutti gli altri, compresi i paesi che hanno una popolazione di un milione. Questo perché 330 milioni sono molto più vicini a 1 milione di 1,3 miliardi. Se avessimo chiesto tre cluster, avremmo ottenuto un'immagine diversa:
Paesi raggruppati in tre gruppi per popolazione 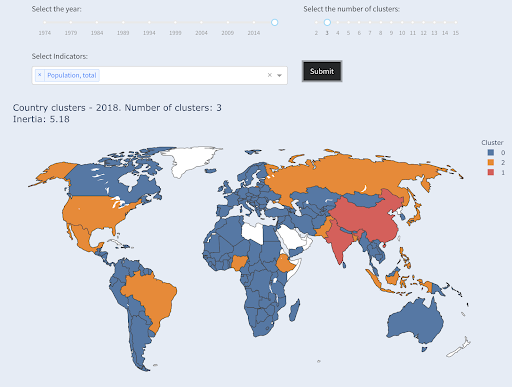
Ed ecco come verrebbero raggruppati i paesi se chiedessimo quattro cluster:
Paesi raggruppati in quattro gruppi per popolazione 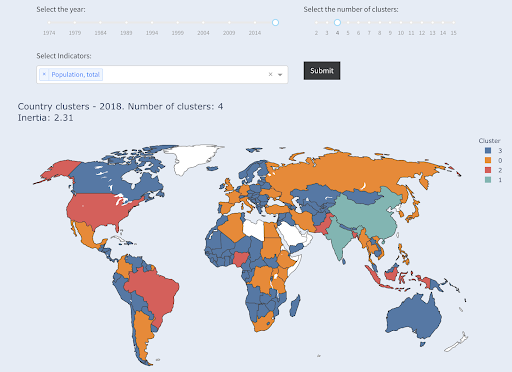
Fonte: povertàdata.org (scheda “Paesi del cluster”)
In questo caso si trattava di raggruppare utilizzando solo una dimensione – popolazione – e puoi anche aggiungere più dimensioni e vedere dove finiscono i paesi.
Ci sono molte altre tecniche e strumenti, e questi erano solo un paio di esempi che si spera siano interessanti e pratici.
Ora siamo pronti per comunicare le nostre scoperte al nostro pubblico.
Comunicare
Dopo tutto il lavoro che svolgiamo nei passaggi precedenti, alla fine dobbiamo comunicare i nostri risultati ad altri stakeholder del progetto.
Uno degli strumenti più importanti nella scienza dei dati è il taccuino interattivo. Il notebook Jupyter è il più utilizzato e supporta praticamente tutti i linguaggi di programmazione e potresti preferire utilizzare il formato notebook speciale di RStudio, che funziona allo stesso modo.
L'idea principale è quella di avere dati, codice, narrativa e visualizzazioni in un unico posto, in modo che altre persone possano controllarli. È importante mostrare come si è arrivati a tali conclusioni e raccomandazioni per la trasparenza e la riproducibilità. Altre persone dovrebbero essere in grado di eseguire lo stesso codice e ottenere gli stessi risultati.
Un altro motivo importante è la capacità degli altri, incluso il "futuro di te", di portare ulteriormente l'analisi e basarsi sul lavoro iniziale che hai svolto, migliorarlo ed espanderlo in nuovi modi.
Ovviamente, questo presuppone che il pubblico sia a proprio agio con il codice e che se ne preoccupi!
Hai anche la possibilità di esportare i tuoi taccuini in HTML (e molti altri formati), escludendo il codice, in modo da ottenere un report intuitivo e tuttavia conservare il codice completo per riprodurre la stessa analisi e risultati.
Un elemento importante della comunicazione è la visualizzazione dei dati, che è stata anche brevemente trattata in precedenza.
Ancora meglio, è la visualizzazione interattiva dei dati, nel qual caso consenti al tuo pubblico di selezionare valori e controllare varie combinazioni di grafici e metriche per esplorare ulteriormente i dati.
Ecco alcune dashboard e app di dati (alcune potrebbero richiedere alcuni secondi per essere caricate) che ho creato per darti un'idea su cosa si può fare.
Alla fine, puoi anche creare app personalizzate per i tuoi progetti, al fine di soddisfare esigenze e requisiti speciali, ed ecco un'altra serie di app SEO e di marketing che potrebbero essere interessanti per te.
Abbiamo seguito i passaggi principali del ciclo di Data Science e ora esploriamo un altro vantaggio dell'"apprendimento di Python".
Python è per l'automazione e la produttività: vero ma incompleto
Mi sembra che ci sia la convinzione che l'apprendimento di Python sia principalmente per ottenere attività produttive e/o automatizzare.
Questo è assolutamente vero, e non credo che abbiamo nemmeno bisogno di discutere il valore di essere in grado di fare qualcosa in una frazione del tempo che ci vorrebbe per farlo manualmente.
L'altra parte mancante dell'argomento è l'analisi dei dati . Una buona analisi dei dati ci fornisce informazioni dettagliate e, idealmente, siamo in grado di fornire informazioni utili per guidare il nostro processo decisionale, in base alla nostra esperienza e ai dati di cui disponiamo.
Gran parte di ciò che facciamo è cercare di capire cosa sta succedendo, analizzare la concorrenza, capire dove si trovano i contenuti più preziosi, decidere cosa fare e così via. Siamo consulenti, consulenti e decisori. Essere in grado di ottenere alcune informazioni dai nostri dati è chiaramente un grande vantaggio e le aree e le competenze qui menzionate possono aiutarci a raggiungerlo.
E se scoprissi che i tag del titolo hanno una lunghezza media di sessanta caratteri, va bene?
E se scavi un po' più a fondo e scopri che metà dei tuoi titoli ha meno di sessanta, mentre l'altra metà ha molti più personaggi (una media di sessanta)? In order to get practical and provide good recommendations, you need a higher-resolution view of your title tags' lengths, probably a histogram that shows the frequency of your title tag lengths at each interval so you can have a separate strategy for length. A simple table would also do, for example:
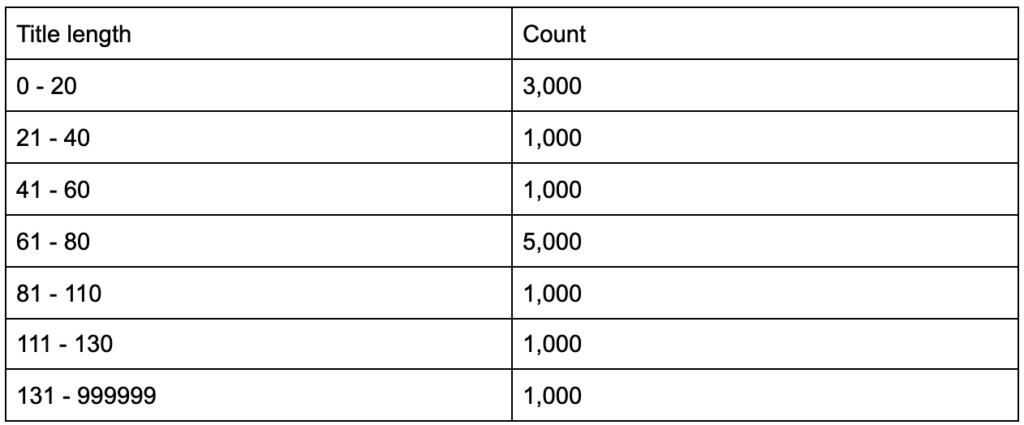
Splitting title lengths by intervals of twenty was an arbitrary decision, and you can split them the way you want. Looking at the table above, and seeing that we have three times more than the average titles in the interval (0, 20), we might want to split it further to better understand what is going on.
Having a better view than the default single-statistic summaries that we get from standard tools, allows us to employ different strategies for different lengths. For example, we can remove the brand name from the titles that are longer than a certain number of characters, and keep it in other titles.
This was an example of very simple insights, which are possible due to the flexibility we get by using a programming language, and a set of data science tools. This also allows us to iterate and modify our approach, until we find a satisfactory point that can take our analysis to the next steps.
Visualization, machine learning, modeling and general data manipulation skills allow us to get better insights on our data, even though those analyses are typically done only once. Still, if you use code to get those insights, you can always take some parts and apply to other projects, or again to the same project. In this case, the insights we got, helped us in our automation, even more. The insights would tell us what needs to be automated and what doesn't.
Should you learn Python?
Is a useless question, and the more useful one is, “How much Python (or R) should you learn?”
My view of how we use computers has evolved in the last few years.
I used to think that there were two main ways of using computers, either you are a regular user, using “point-and-click” applications to do certain tasks, or you are a developer who creates those applications that the rest of us use.

I then realized that it is more like a continuum between very high level use (pizza ordering approach), and the lower levels of the farm approach. I also realized that there is a happy sweet spot in between, where you learn enough programming to get productive and boost your data analysis skills, without having to become a software developer or engineer.
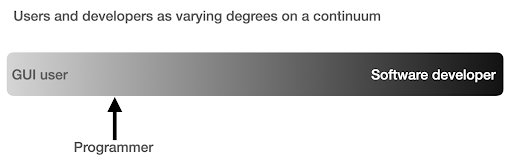
What are the main differences between being a programmer (a software user), and a software developer (or engineer)?
What are the differences between making a great coffee at home, versus establishing and running a cafe?
If making good coffee is one skill, then running a cafe requires ten other skills, most of which have nothing to do with making coffee.
You have to choose a good location (real estate), hire people (management and HR), manage cash flow and finances (accounting and finance), do marketing, legal, manage delivery, adhere to cleanliness and health standards, and so on. You can be a great coffee maker without knowing anything about those fields, but if you want to take it to the next level, you will have to manage all those additional tasks unrelated to making coffee.
The same applies to being a good programmer or data analyst versus being a software developer/engineer. There are so many other things that you have to know and worry about that you don't need as a regular programmer doing stuff for yourself and co-workers and clients. Once you have enough knowledge and skills in programming and data science, you will be in a good position to choose and decide whether you want to continue as an analyst, focusing on data science, or if you want to end up creating software that other people would use.
How do I get into Data Science?
To learn anything I think you have to do two things in parallel:
- Learn the fundamentals and the theory properly: Taking courses and reading books, and getting into the fundamentals can push you forward, as you will be gaining in weeks, knowledge that took decades to establish. It would also immediately give you ideas on things you thought were impossible, or had no idea existed.
- Get as much real world exposure and experience as possible: Experience is always important, and my suggestion is to try as soon as you can to read_csv with Python or R, to actually do so with your GA, GSC, or crawl dataset. See what else you can do (visualize, manipulate, model, etc.). See if you get errors, try to analyze the data only using your programming language.
What does frustration look like, and by when will I get productive?
It's difficult to say, and it depends on your skill, background, the hours you put in, but visualizing it like this might help you on those frustrating unproductive days:
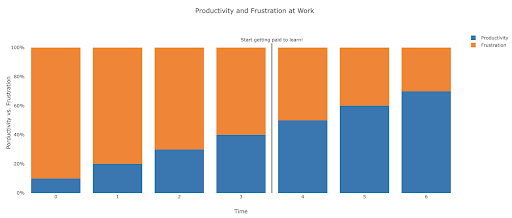
My suggestion is to take a non-trivial task, for example running an SEO audit for a site, only using Python. Your first session will mostly be frustrating, and most of the time will be spent checking documentation, and the definition of basic terms.
In parallel, you are still going through your course, and learning new stuff.
The value of that frustrating session is that it informs and motivates your theoretical learning. You will have questions in mind, and when you learn new things, you will immediately have a place to implement them.
Your next analysis session will probably be a little more productive, but still not productive enough to do at work. You go again to your learning and theory.
Do this enough times, and your time will become mostly productive, eventually you will be doing real work during working hours. The ideal scenario is where you are productive enough to do work, but every time use some time to research better techniques, which improves your work as well. By then you will start to get paid for learning, and your clients will be happily sponsoring you!
Suggested next steps
For the learning path a Data Science course would be great, especially if you get feedback on your work, and you can follow the topics in the order recommended.
If you go with Python I suggest the following libraries:
- pandas: The workhorse of all your tasks in preparing, cleaning, reshaping data whichever way you want. Fluency in pandas allows you to have full control over your data, which will help you immensely in visualization, general analysis, and machine learning
- Plotly and Dash: This is my favorite data visualization library, although there are many others. What I mostly like about it, is that it produces interactive and responsive HTML charts by default. It is very detailed and thorough in its options, yet simple to use. Plotly also includes Plotly Express, which is a high-level plotting tool, which is more intuitive to use, and takes a data-oriented approach (as opposed to a chart-oriented approach). Plotly also created Dash, which is the tool for creating interactive dashboards, but also serves as a full front-end web development framework. Other important data visualization libraries are matplotlib, altair, and bokeh, and for interactive data apps, there is panel and streamlit. Another important feature is that Plotly and Dash are available in all languages used in Data Science. You might use other libraries, and this is just my personal preference. Speaking of personal preferences:
- advertools: This is a library that I created to provide various online marketing tools, most importantly, an SEO crawler, log file parser and compressor, multi robots.txt parser, recursive sitemap parser, SEM keyword and text ad generator for large scale campaigns, weighted frequency word counter, Google SERP downloader, YouTube data API, and a few other tools. It is still evolving, and you are more than welcome to contribute any suggestions, bugs, or issues you might have with it.
These should be enough for beginners, and when you are familiar with them, you can do your own research for more specialized libraries, machine learning and deep learning tools, or libraries that are specialized in performance, or a special niche use-case.