
Ilmu Data untuk SEO dan Pemasaran Digital : panduan yang disarankan untuk pemula
Diterbitkan: 2021-12-07Karena sebagian besar pekerjaan kami berkisar pada data, dan karena bidang Ilmu Data menjadi jauh lebih besar, dan lebih mudah diakses oleh pemula, saya ingin berbagi beberapa pemikiran tentang bagaimana Anda bisa masuk ke bidang ini untuk meningkatkan SEO dan pemasaran Anda. keterampilan secara umum.
Apa itu ilmu data?
Diagram yang sangat terkenal yang digunakan untuk memberikan gambaran tentang bidang ini adalah diagram Venn Drew Conway yang menunjukkan Ilmu Data sebagai persimpangan statistik, peretasan (keterampilan pemrograman tingkat lanjut secara umum, dan belum tentu menembus jaringan dan menyebabkan kerusakan), dan substantif keahlian atau "pengetahuan domain":
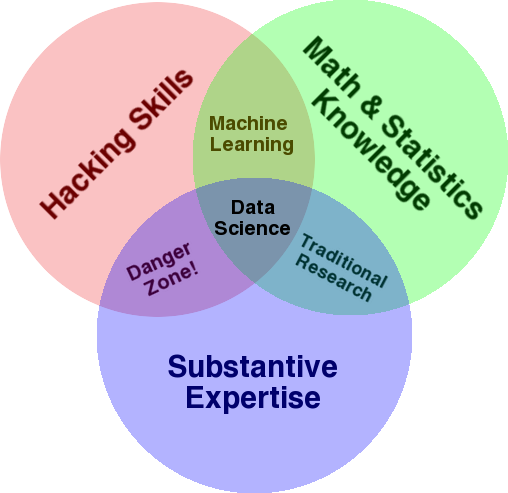
Sumber: oreilly.com
Ketika saya mulai belajar, saya segera menyadari bahwa inilah tepatnya yang telah kami lakukan. Satu-satunya perbedaan adalah saya melakukannya dengan alat yang lebih mendasar dan manual.
Jika Anda melihat diagram, Anda akan dengan mudah melihat bagaimana Anda mungkin sudah melakukan ini. Anda menggunakan komputer (keterampilan meretas), untuk menganalisis data (statistik), untuk memecahkan masalah praktis menggunakan keahlian substantif Anda dalam SEO (atau spesialisasi apa pun yang Anda fokuskan).
"Bahasa pemrograman" Anda saat ini mungkin adalah spreadsheet (Excel, Google Sheets, dll.), dan kemungkinan besar Anda menggunakan Powerpoint atau yang serupa untuk mengkomunikasikan ide. Mari kita sedikit memperluas elemen-elemen ini.
- Pengetahuan domain: Mari kita mulai dengan kekuatan utama Anda, seperti yang sudah Anda ketahui tentang bidang keahlian Anda. Ingatlah bahwa ini adalah bagian penting dari menjadi ilmuwan data, dan di sinilah Anda dapat membangun, dan melindungi, pengetahuan Anda. Beberapa bulan yang lalu, saya berdiskusi tentang menganalisis kumpulan data perayapan dengan seorang teman saya. Dia adalah seorang fisikawan, melakukan penelitian pasca-doktoral pada komputer kuantum. Pengetahuan dan keterampilan matematika dan statistiknya jauh di luar kemampuan saya, dan dia benar-benar tahu cara menganalisis data jauh lebih baik daripada saya. Satu masalah. Dia tidak tahu apa itu "404" (atau mengapa kita peduli dengan "301"). Jadi, dengan semua pengetahuan matematikanya, dia tidak dapat memahami kolom "status" di kumpulan data perayapan. Secara alami, dia tidak akan tahu apa yang harus dilakukan dengan data itu, dengan siapa harus berbicara, dan strategi apa yang harus dibangun berdasarkan kode status tersebut (atau apakah akan mencari di tempat lain). Anda dan saya tahu apa yang harus dilakukan dengan mereka, atau setidaknya kita tahu ke mana lagi harus mencari jika kita ingin menggali lebih dalam.
- Matematika dan statistik: Jika Anda menggunakan Excel untuk mendapatkan rata-rata sampel data, Anda menggunakan statistik. Rata-rata adalah statistik yang menggambarkan aspek tertentu dari sampel data. Statistik yang lebih maju akan membantu dalam memahami data Anda. Ini juga penting, dan saya bukan ahli di bidang ini. Semakin banyak distribusi statistik yang Anda kenal, semakin banyak ide yang Anda miliki tentang cara menganalisis data. Semakin banyak topik mendasar yang Anda ketahui, semakin baik Anda dalam merumuskan hipotesis, dan membuat pernyataan yang tepat tentang kumpulan data Anda.
- Keahlian pemrograman: Saya akan membahas ini secara lebih rinci di bawah, tetapi terutama di sinilah Anda membangun fleksibilitas untuk memberi tahu komputer untuk melakukan apa yang Anda inginkan, sebagai lawan terjebak dengan mudah digunakan tetapi sedikit membatasi peralatan. Ini adalah cara utama Anda untuk mendapatkan, membentuk kembali, dan membersihkan data Anda, dengan cara apa pun yang Anda inginkan, membuka jalan bagi Anda untuk melakukan "percakapan" terbuka dan fleksibel dengan data Anda.
Sekarang mari kita lihat apa yang biasanya kita lakukan dalam Ilmu Data.
Siklus ilmu data
Proyek atau bahkan tugas ilmu data yang khas, biasanya terlihat seperti ini:
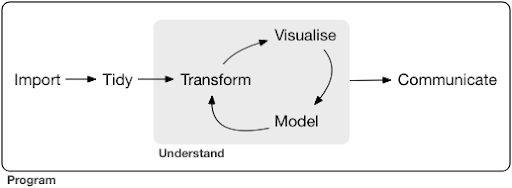
Sumber: r4ds.had.co.nz
Saya juga sangat merekomendasikan membaca buku ini oleh Hadley Wickham dan Garrett Grolemund yang berfungsi sebagai pengantar yang bagus untuk Ilmu Data. Itu ditulis dengan contoh-contoh dari bahasa pemrograman R, tetapi konsep dan kode dapat dengan mudah dipahami jika Anda hanya tahu Python.
Seperti yang Anda lihat dalam diagram, pertama-tama kita perlu mengimpor data kita, merapikannya, dan kemudian mulai mengerjakan siklus dalam dari transformasi, visualisasi, dan model. Setelah itu kami mengomunikasikan hasilnya dengan orang lain.
Langkah-langkah tersebut dapat berkisar dari yang sangat sederhana hingga yang sangat kompleks. Misalnya, langkah "Impor" mungkin sesederhana membaca file CSV, dan dalam beberapa kasus mungkin terdiri dari proyek pengikisan web yang sangat rumit untuk mendapatkan data. Beberapa elemen dari proses tersebut merupakan spesialisasi penuh dalam hak mereka sendiri.
Kita dapat dengan mudah memetakan ini ke beberapa proses yang kita kenal. Misalnya, Anda dapat memulai dengan mendapatkan beberapa metadata tentang situs web, dengan mengunduh robots.txt dan peta situs XML-nya. Anda mungkin kemudian akan merangkak dan mungkin juga mendapatkan beberapa data tentang posisi SERP, atau data tautan misalnya. Sekarang setelah Anda memiliki beberapa kumpulan data, Anda mungkin ingin menggabungkan beberapa tabel, memasukkan beberapa data tambahan, dan mulai menjelajahi/memahami. Memvisualisasikan data dapat mengekspos pola tersembunyi, atau membantu Anda mengetahui apa yang sedang terjadi, atau mungkin menimbulkan lebih banyak pertanyaan. Anda mungkin juga ingin memodelkan data Anda menggunakan beberapa statistik dasar, atau model pembelajaran mesin, dan semoga mendapatkan beberapa wawasan. Tentu saja, Anda perlu mengomunikasikan temuan dan pertanyaan kepada pemangku kepentingan lain dalam proyek.
Setelah Anda cukup terbiasa dengan berbagai alat yang tersedia untuk setiap proses ini, Anda dapat mulai membangun saluran pipa kustom Anda sendiri yang khusus untuk situs web tertentu, karena setiap bisnis itu unik, dan memiliki serangkaian persyaratan khusus. Akhirnya, Anda akan mulai menemukan pola dan tidak perlu mengulang seluruh pekerjaan untuk proyek/situs web serupa.
Ada banyak alat dan pustaka yang tersedia untuk setiap elemen dalam proses ini dan itu bisa sangat melelahkan, alat mana yang Anda pilih (dan menginvestasikan waktu Anda untuk belajar). Mari kita lihat kemungkinan pendekatan yang menurut saya berguna dalam memilih alat yang saya gunakan.
Pilihan alat dan pertukaran (3 cara menikmati pizza)
Haruskah Anda menggunakan excel untuk pekerjaan sehari-hari Anda dalam memproses data, atau apakah itu sepadan dengan rasa sakit untuk belajar Python?
Apakah Anda lebih baik memvisualisasikan dengan sesuatu seperti Power BI, atau haruskah Anda berinvestasi dalam mempelajari Tata Bahasa Grafik, dan mempelajari cara menggunakan perpustakaan yang mengimplementasikannya?
Apakah Anda akan menghasilkan pekerjaan yang lebih baik dengan membuat dasbor interaktif Anda sendiri dengan R atau Python, atau haruskah Anda menggunakan Google Data Studio?
Pertama-tama mari kita jelajahi trade-off yang terlibat dalam memilih berbagai alat di berbagai tingkat abstraksi. Ini adalah kutipan dari buku saya tentang membangun dasbor interaktif dan aplikasi data dengan Plotly dan Dash dan menurut saya pendekatan ini berguna:
Pertimbangkan tiga pendekatan berbeda untuk menikmati pizza:
- Pendekatan pemesanan: Anda menelepon restoran dan memesan pizza Anda. Itu tiba di depan pintu Anda dalam setengah jam, dan Anda mulai makan.
- Pendekatan supermarket: Anda pergi ke supermarket, membeli adonan, keju, sayuran, dan semua bahan lainnya. Anda kemudian membuat pizza sendiri.
- Pendekatan pertanian: Anda menanam tomat di halaman belakang Anda. Anda memelihara sapi, memerah susunya, dan mengubah susu menjadi keju, dan seterusnya.
Saat kami naik ke antarmuka tingkat yang lebih tinggi, menuju pendekatan pemesanan, jumlah pengetahuan yang dibutuhkan berkurang banyak. Orang lain memegang tanggung jawab, dan kualitas diperiksa oleh kekuatan pasar reputasi dan persaingan.
Harga yang kita bayar untuk ini adalah berkurangnya kebebasan dan pilihan. Setiap restoran memiliki serangkaian opsi untuk dipilih, dan Anda harus memilih dari opsi tersebut.
Turun ke tingkat yang lebih rendah, jumlah pengetahuan yang dibutuhkan meningkat, kita harus menangani lebih banyak kompleksitas, kita memegang lebih banyak tanggung jawab untuk hasil, dan itu membutuhkan lebih banyak waktu. Apa yang kami peroleh di sini adalah lebih banyak kebebasan dan kekuatan untuk menyesuaikan hasil kami seperti yang kami inginkan. Biaya merupakan keuntungan utama juga, tetapi hanya dalam skala yang cukup besar. Jika Anda hanya ingin makan pizza hari ini, mungkin lebih murah untuk memesannya. Tetapi jika Anda berencana untuk memilikinya setiap hari, maka Anda dapat mengharapkan penghematan biaya yang besar jika Anda melakukannya sendiri.
Ini adalah jenis pilihan yang harus Anda buat ketika memilih alat mana yang akan digunakan dan dipelajari. Menggunakan bahasa pemrograman seperti R atau Python membutuhkan lebih banyak pekerjaan, dan lebih sulit daripada Excel, dengan manfaat membuat Anda jauh lebih produktif dan kuat.
Pilihan juga penting untuk setiap alat atau proses. Misalnya, Anda mungkin menggunakan perayap tingkat tinggi dan mudah digunakan untuk mengumpulkan data tentang situs web, namun Anda mungkin lebih suka menggunakan bahasa pemrograman untuk memvisualisasikan data, dengan semua opsi yang tersedia. Pilihan alat yang tepat untuk proses yang tepat tergantung pada kebutuhan Anda dan pertukaran yang dijelaskan di atas semoga dapat membantu dalam membuat pilihan ini. Ini juga semoga membantu menjawab pertanyaan apakah (atau berapa banyak) Python atau R yang ingin Anda pelajari atau tidak.
Mari kita bahas pertanyaan ini lebih jauh dan lihat mengapa mempelajari Python untuk SEO mungkin bukan kata kunci yang tepat.
Mengapa "python untuk seo" menyesatkan
Apakah Anda ingin menjadi blogger yang hebat atau Anda ingin belajar WordPress?
Apakah Anda ingin menjadi seorang desainer grafis atau apakah Anda ingin belajar Photoshop?
Apakah Anda tertarik untuk meningkatkan karir SEO Anda dengan membawa keterampilan data Anda ke tingkat berikutnya, atau apakah Anda ingin belajar Python?
Dalam lima menit pertama kuliah pertama kursus ilmu komputer di MIT, profesor Harold Abelson membuka kursus dengan memberi tahu para siswa mengapa "ilmu komputer" adalah nama yang buruk untuk disiplin ilmu yang akan mereka pelajari. Saya pikir sangat menarik untuk menonton lima menit pertama kuliah:
Ketika beberapa bidang baru saja dimulai, dan Anda tidak benar-benar memahaminya dengan baik, sangat mudah untuk mengacaukan esensi dari apa yang Anda lakukan, dengan alat yang Anda gunakan. – Harold Abelson
Kami mencoba meningkatkan kehadiran dan hasil online kami, dan banyak hal yang kami lakukan didasarkan pada pemahaman, visualisasi, manipulasi, dan penanganan data secara umum, dan ini adalah fokus kami, terlepas dari alat yang digunakan. Ilmu Data adalah bidang yang memiliki kerangka kerja intelektual untuk melakukan itu, serta banyak alat untuk mengimplementasikan apa yang ingin kita lakukan. Python mungkin bahasa pemrograman (alat) pilihan Anda, dan sangat penting untuk mempelajarinya dengan baik. Ini juga sama pentingnya, jika tidak lebih penting, untuk fokus pada "esensi dari apa yang Anda lakukan", memproses dan menganalisis data, dalam kasus kami.
Fokus utama harus pada proses yang dibahas di atas (mengimpor, merapikan, memvisualisasikan, dll.), sebagai lawan dari bahasa pemrograman pilihan. Atau lebih baik, bagaimana menggunakan bahasa pemrograman itu untuk mencapai tugas Anda, bukan hanya belajar bahasa pemrograman.
Siapa yang peduli dengan semua perbedaan teoretis ini jika saya tetap akan belajar Python?
Mari kita lihat apa yang mungkin terjadi jika Anda fokus mempelajari alat ini, bukan esensi dari apa yang Anda lakukan. Di sini, kami membandingkan pencarian untuk "belajar wordpress" (alat) vs. "belajar blogging" (hal yang ingin kami lakukan):
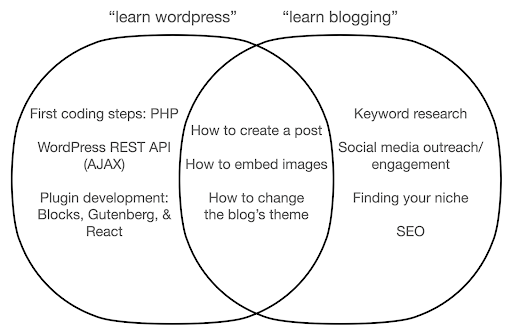
Diagram menunjukkan kemungkinan topik di bawah buku atau kursus yang mengajarkan tentang kata kunci di atas. Area persimpangan di tengah menunjukkan topik yang mungkin terjadi di kedua jenis kursus/buku.
Jika Anda fokus pada alat, Anda pasti akan berakhir harus mempelajari hal-hal yang sebenarnya tidak Anda butuhkan, terutama sebagai pemula. Topik-topik ini mungkin membingungkan dan membuat Anda frustrasi, terutama jika Anda tidak memiliki latar belakang teknis atau pemrograman.
Anda juga akan belajar hal-hal yang berguna untuk menjadi blogger yang baik (topik di daerah persimpangan). Topik-topik ini sangat mudah diajarkan (cara membuat posting blog), tetapi tidak banyak memberi tahu Anda tentang mengapa Anda harus membuat blog, kapan, dan tentang apa. Ini bukan kesalahan dalam buku yang berfokus pada alat, karena ketika belajar tentang alat, itu akan cukup untuk mempelajari cara membuat posting blog, dan melanjutkan.
Sebagai seorang blogger, Anda mungkin lebih tertarik pada apa dan mengapa blogging, dan itu tidak akan dibahas dalam buku-buku yang berfokus pada alat.
Jelas, hal-hal strategis dan penting seperti SEO, menemukan niche Anda, dan sebagainya, tidak akan tercakup, sehingga Anda akan kehilangan hal-hal yang sangat penting.
Apa saja topik Ilmu Data yang mungkin tidak akan Anda pelajari dalam buku pemrograman?
Seperti yang kita lihat, mengambil Python atau buku pemrograman mungkin berarti Anda ingin menjadi insinyur perangkat lunak. Topik secara alami akan diarahkan ke tujuan itu. Jika Anda mencari buku Ilmu Data, Anda mendapatkan topik dan alat yang lebih diarahkan untuk menganalisis data.
Kita dapat menggunakan diagram pertama (menunjukkan siklus Ilmu Data) sebagai panduan, dan secara proaktif mencari topik tersebut: “impor data dengan python”, “rapi data dengan r”, “visualisasikan data dengan python” dan seterusnya. Mari kita lihat lebih dalam topik-topik itu dan jelajahi lebih jauh:
Impor
Kami secara alami perlu terlebih dahulu mendapatkan beberapa data. Ini bisa berupa:
- File di komputer kami: Kasus paling mudah di mana Anda cukup membuka file dengan bahasa pemrograman pilihan Anda. Penting untuk dicatat bahwa ada banyak format file yang berbeda, dan Anda memiliki banyak pilihan saat membuka/membaca file. Misalnya fungsi read_csv dari perpustakaan pandas (alat manipulasi data penting dalam Python) memiliki lima puluh opsi untuk dipilih, saat membuka file. Ini berisi hal-hal seperti jalur file, kolom untuk dipilih, jumlah baris untuk dibuka, menafsirkan objek datetime, cara menangani nilai yang hilang dan banyak lagi. Sangat penting untuk mengetahui opsi tersebut, dan berbagai pertimbangan saat membuka format file yang berbeda. Selanjutnya panda memiliki sembilan belas fungsi berbeda yang dimulai dengan read_ untuk berbagai format file dan data.
- Ekspor dari alat online: Anda mungkin akrab dengan ini, dan di sini Anda dapat menyesuaikan data Anda dan kemudian mengekspornya, setelah itu Anda akan membukanya sebagai file di komputer Anda.
- Panggilan API untuk mendapatkan data spesifik: Ini berada pada level yang lebih rendah, dan lebih dekat dengan pendekatan pertanian yang disebutkan di atas. Dalam hal ini Anda mengirim permintaan dengan persyaratan tertentu dan mendapatkan kembali data yang Anda inginkan. Keuntungannya di sini adalah Anda dapat menyesuaikan persis apa yang ingin Anda dapatkan, dan memformatnya dengan cara yang mungkin tidak tersedia di antarmuka online. Misalnya di Google Analytics Anda dapat menambahkan dimensi sekunder ke tabel yang Anda analisis, tetapi Anda tidak dapat menambahkan yang ketiga. Anda juga dibatasi oleh jumlah baris yang dapat Anda ekspor. API memberi Anda lebih banyak fleksibilitas, dan Anda juga dapat mengotomatiskan panggilan tertentu agar terjadi secara berkala, sebagai bagian dari jalur pengumpulan/analisis data yang lebih besar.
- Perayapan dan pengikisan data: Anda mungkin memiliki perayap favorit Anda, dan mungkin akrab dengan prosesnya. Ini sudah merupakan proses yang fleksibel, memungkinkan kami mengekstrak elemen khusus dari halaman, merayapi halaman tertentu saja, dan seterusnya.
- Kombinasi metode yang melibatkan otomatisasi, ekstraksi kustom, dan kemungkinan pembelajaran mesin untuk penggunaan khusus.
Setelah kami memiliki beberapa data, kami ingin pergi ke tingkat berikutnya.
Rapi
Kumpulan data "rapi" adalah kumpulan data yang diatur dengan cara tertentu. Ini juga disebut sebagai data "format panjang". Bab 12 dalam buku R untuk Ilmu Data membahas konsep rapi data lebih detail jika Anda tertarik.
Lihatlah tiga tabel di bawah ini dan coba temukan perbedaannya:
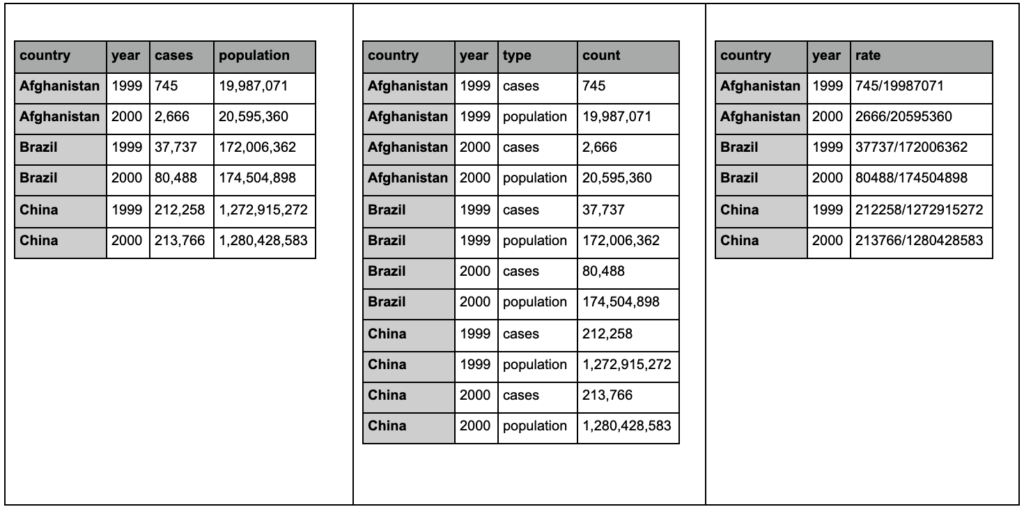
Contoh tabel dari paket yang lebih rapi.
Anda akan menemukan bahwa ketiga tabel berisi informasi yang sama persis, tetapi disusun dan disajikan dengan cara yang berbeda. Kita dapat memiliki kasus dan populasi dalam dua kolom terpisah (tabel 1), atau memiliki kolom untuk memberi tahu kita apa yang diamati (kasus atau populasi), dan kolom “hitung” untuk menghitung kasus tersebut (tabel 2). Dalam tabel 3, mereka ditampilkan sebagai tarif.
Saat berurusan dengan data, Anda akan menemukan bahwa sumber yang berbeda mengatur data secara berbeda, dan bahwa Anda sering kali perlu mengubah dari/ke format tertentu untuk analisis yang lebih baik dan lebih mudah. Menjadi akrab dengan operasi pembersihan ini sangat penting, dan paket yang lebih rapi di R berisi alat khusus untuk itu. Anda juga dapat menggunakan panda jika Anda lebih suka Python, dan Anda dapat memeriksa fungsi lelehan dan pivot untuk itu.
Setelah data kita berada dalam format tertentu, kita mungkin ingin memanipulasinya lebih lanjut.
Mengubah
Keterampilan penting lainnya yang harus dibangun adalah kemampuan untuk membuat perubahan apa pun yang Anda inginkan pada data yang sedang Anda kerjakan. Skenario yang ideal adalah untuk mencapai tahap di mana Anda dapat melakukan percakapan dengan data Anda, dan mampu mengiris dan memotong dengan cara apa pun yang Anda inginkan untuk mengajukan pertanyaan yang sangat spesifik, dan mudah-mudahan mendapatkan wawasan yang menarik. Berikut adalah beberapa tugas transformasi terpenting yang mungkin akan sangat Anda butuhkan dengan beberapa contoh tugas yang mungkin Anda minati:
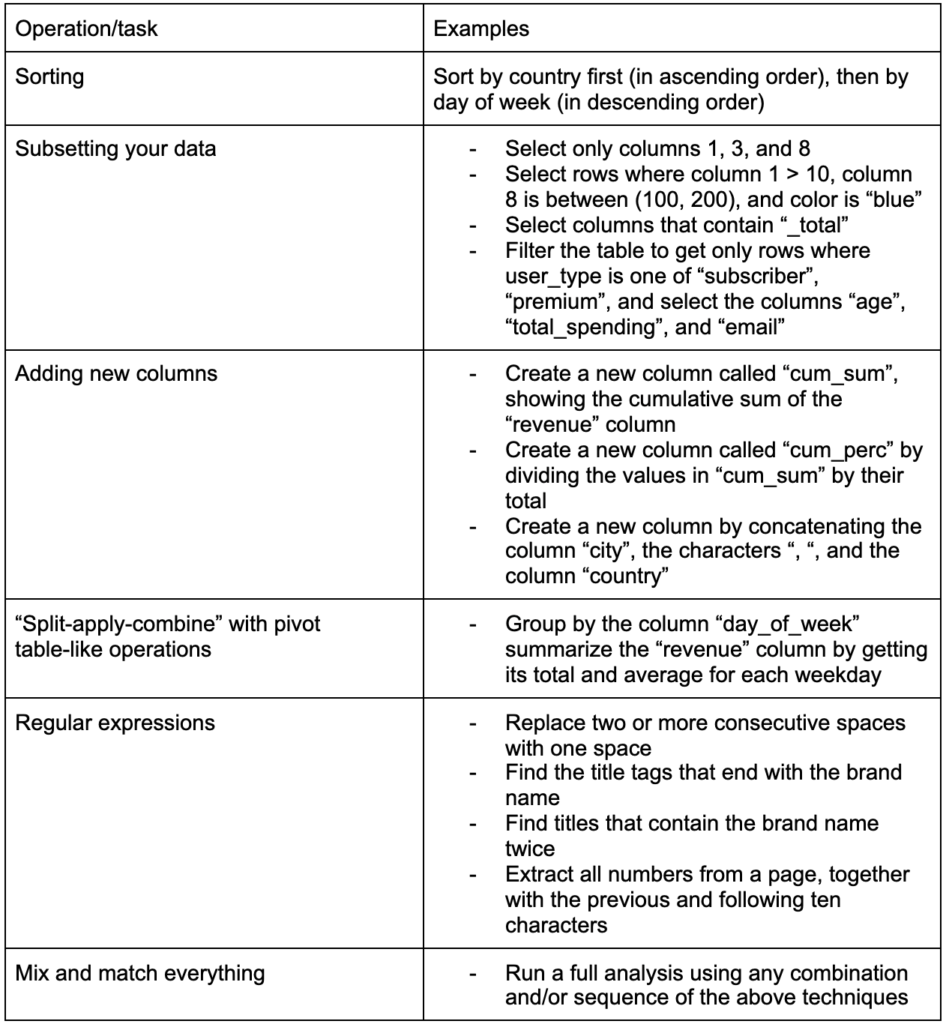
Setelah mendapatkan, merapikan, dan meletakkan data kita dalam format yang diinginkan, ada baiknya untuk memvisualisasikannya.
Membayangkan
Visualisasi data adalah topik besar, dan ada banyak buku tentang beberapa subtopiknya. Ini adalah salah satu hal yang dapat memberikan banyak wawasan tentang data kami, terutama yang menggunakan elemen visual intuitif untuk mengkomunikasikan informasi. Ketinggian relatif batang dalam bagan batang segera menunjukkan kepada kita kuantitas relatifnya, misalnya. Intensitas warna, lokasi relatif, dan banyak atribut visual lainnya mudah dikenali dan dipahami oleh pembaca.
Bagan yang bagus bernilai seribu (kunci) kata!
Karena ada banyak topik yang harus dibahas dalam visualisasi data, saya hanya akan membagikan beberapa contoh yang mungkin menarik. Beberapa di antaranya adalah blok bangunan untuk dasbor data kemiskinan ini, jika Anda menginginkan detail lengkapnya.
Bagan batang sederhana terkadang adalah semua yang mungkin Anda perlukan untuk membandingkan nilai, di mana batang dapat ditampilkan secara vertikal atau horizontal:
Anda mungkin tertarik untuk menjelajahi negara tertentu, dan menggali lebih dalam, dengan melihat kemajuan mereka pada metrik tertentu. Dalam hal ini Anda mungkin ingin menampilkan beberapa diagram batang dalam plot yang sama:
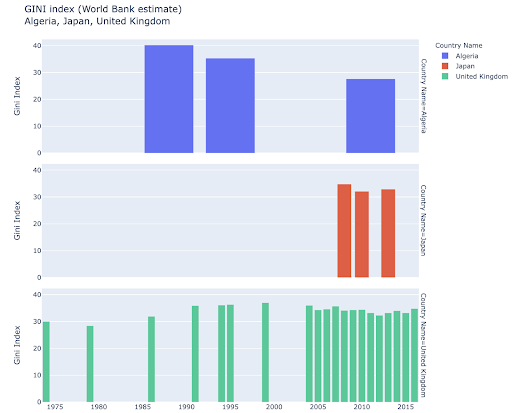
Membandingkan beberapa nilai untuk beberapa pengamatan juga dapat dilakukan dengan menempatkan beberapa batang di setiap posisi sumbu X, berikut adalah cara utama untuk melakukannya:
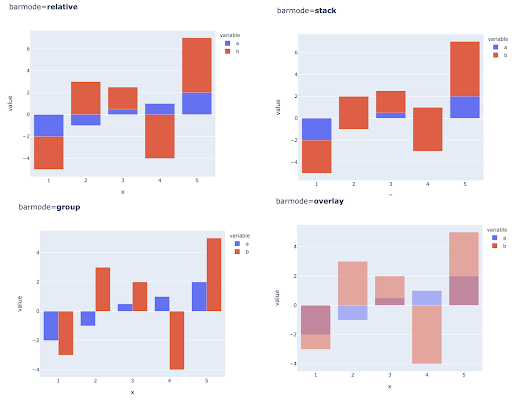
Pilihan warna dan skala warna: Bagian penting dari visualisasi data, dan sesuatu yang dapat mengomunikasikan informasi dengan sangat efisien dan intuitif jika dilakukan dengan benar.
Skala warna kategoris: Berguna untuk mengekspresikan data kategoris. Seperti namanya, ini adalah jenis data yang menunjukkan kategori mana yang termasuk dalam pengamatan tertentu. Dalam hal ini kami ingin warna yang berbeda satu sama lain mungkin untuk menunjukkan perbedaan kategori yang jelas (terutama untuk elemen visual yang ditampilkan bersebelahan).
Contoh berikut menggunakan skala warna kategoris untuk menunjukkan sistem pemerintahan mana yang diterapkan di setiap negara. Sangat mudah untuk menghubungkan warna negara dengan legenda yang menunjukkan sistem pemerintahan mana yang digunakan. Ini juga disebut peta choropleth:
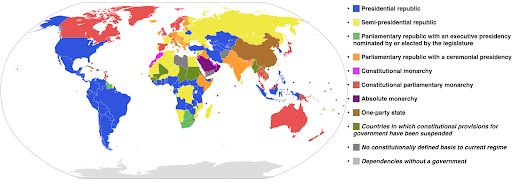
Sumber: Wikipedia
Terkadang data yang ingin kita visualisasikan adalah untuk metrik yang sama, dan setiap negara (atau jenis pengamatan lainnya) berada pada titik tertentu dalam kontinum yang berkisar antara titik minimum dan maksimum. Dengan kata lain, kami ingin memvisualisasikan derajat metrik tersebut.
Dalam kasus ini kita perlu menemukan skala warna kontinu (atau berurutan) . Dalam contoh berikut, akan segera terlihat jelas negara mana yang lebih biru (dan karenanya mendapatkan lebih banyak lalu lintas), dan kami dapat secara intuitif memahami perbedaan bernuansa antar negara.
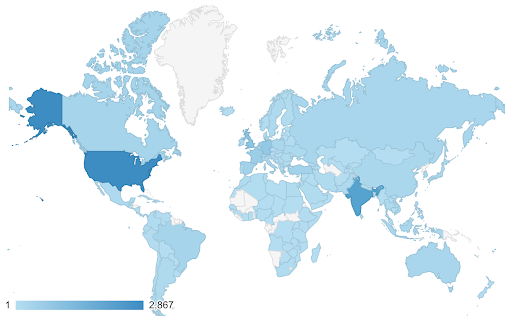
Data Anda mungkin kontinu (seperti bagan peta lalu lintas di atas), namun hal penting tentang angka mungkin adalah seberapa jauh mereka menyimpang dari titik tertentu. Skala warna yang berbeda berguna dalam kasus ini.
Bagan di bawah ini menunjukkan tingkat pertumbuhan penduduk bersih. Dalam hal ini, menarik untuk mengetahui terlebih dahulu apakah suatu negara memiliki tingkat pertumbuhan positif atau negatif. Atau, kami ingin tahu seberapa jauh setiap negara dari nol (dan seberapa jauh). Melirik peta segera menunjukkan kepada kita populasi negara mana yang tumbuh dan mana yang menyusut. Legenda juga menunjukkan kepada kita bahwa tingkat positif maksimum adalah 3,5% dan tingkat negatif maksimum adalah -0,5%. Ini juga memberi kita indikasi tentang kisaran nilai (positif dan negatif).

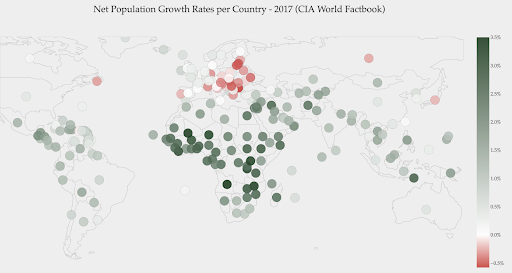
Sumber: Dashboardom.com
Sayangnya, warna yang dipilih untuk skala ini tidak ideal, karena orang buta warna mungkin tidak dapat membedakan dengan benar antara merah dan hijau. Ini adalah pertimbangan yang sangat penting ketika memilih skala warna kami.
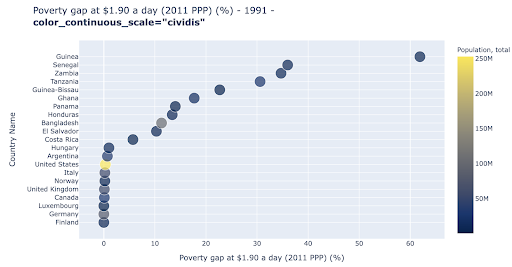
Plot pencar adalah salah satu jenis plot yang paling banyak digunakan dan serbaguna. Posisi titik-titik (atau penanda lainnya) menyampaikan kuantitas yang kita coba komunikasikan. Selain posisi, kita dapat menggunakan beberapa atribut visual lainnya seperti warna, ukuran, dan bentuk untuk mengomunikasikan lebih banyak informasi. Contoh berikut menunjukkan persentase penduduk yang hidup dengan $1,9/hari, yang dapat kita lihat dengan jelas sebagai jarak horizontal titik-titik tersebut.
Kami juga dapat menambahkan dimensi baru ke bagan kami dengan menggunakan warna. Ini sesuai dengan memvisualisasikan kolom ketiga dari kumpulan data yang sama, yang dalam hal ini menunjukkan data populasi.
Kita sekarang dapat melihat bahwa kasus yang paling ekstrim dalam hal populasi (AS), sangat rendah pada metrik tingkat kemiskinan. Ini menambah kekayaan bagan kami. Kita juga bisa menggunakan ukuran dan bentuk untuk memvisualisasikan lebih banyak kolom dari kumpulan data kita. Kita perlu mencapai keseimbangan yang baik antara kekayaan dan keterbacaan.
Kami mungkin tertarik untuk memeriksa apakah ada hubungan antara populasi dan tingkat kemiskinan, sehingga kami dapat memvisualisasikan kumpulan data yang sama dengan cara yang sedikit berbeda untuk melihat apakah ada hubungan seperti itu:
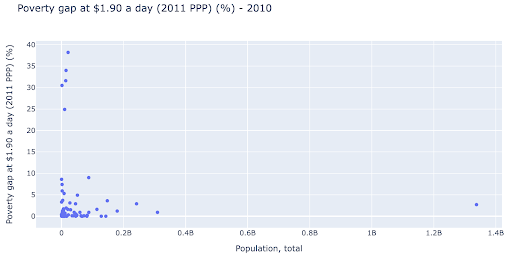
Kami memiliki satu nilai outlier dalam populasi sekitar 1,35 miliar, dan ini berarti kami memiliki banyak spasi putih di bagan, yang juga berarti banyak nilai terjepit di area yang sangat kecil. Kami juga memiliki banyak titik yang tumpang tindih, yang membuatnya sangat sulit untuk menemukan perbedaan atau tren apa pun.
Bagan berikut berisi informasi yang sama tetapi divisualisasikan secara berbeda menggunakan dua teknik:
- Skala logaritmik : Kami biasanya melihat data pada skala aditif. Dengan kata lain, setiap titik pada sumbu (X atau Y) mewakili penambahan sejumlah data yang divisualisasikan. Kita juga dapat memiliki skala perkalian, dalam hal ini untuk setiap titik baru pada sumbu X kita kalikan (dengan sepuluh dalam contoh ini). Hal ini memungkinkan poin untuk menyebar dan kita perlu memikirkan kelipatan sebagai lawan penambahan, seperti yang kita miliki di bagan sebelumnya.
- Menggunakan spidol yang berbeda (lingkaran kosong yang lebih besar) : Memilih bentuk yang berbeda untuk spidol kami memecahkan masalah "over-plotting" di mana kami mungkin memiliki beberapa titik di atas satu sama lain di lokasi yang sama, yang membuatnya sangat sulit untuk dilihat. berapa banyak poin yang kita miliki.
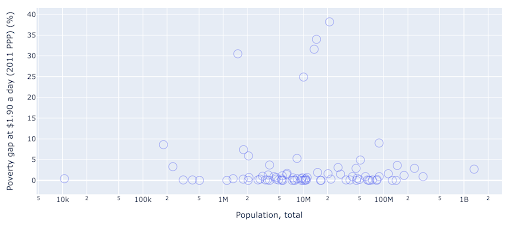
Kita sekarang dapat melihat bahwa ada sekelompok negara di sekitar angka 10 juta, dan kelompok yang lebih kecil lainnya juga.
Seperti yang saya sebutkan, ada lebih banyak jenis karakter dan opsi visualisasi, dan seluruh buku yang ditulis tentang subjek tersebut. Saya harap ini memberi Anda beberapa pemikiran menarik untuk bereksperimen.
Data Perayapan³
 Belajarlah lagi
Belajarlah lagiModel
Kita perlu menyederhanakan data kita, dan menemukan pola, membuat prediksi, atau sekadar memahaminya dengan lebih baik. Ini adalah topik besar lainnya, dan dapat berkisar dari sekadar mendapatkan beberapa statistik ringkasan (rata-rata, median, standar deviasi, dll), hingga memodelkan data kita secara visual, menggunakan model yang merangkum atau menemukan tren, hingga menggunakan teknik yang lebih kompleks untuk mendapatkan rumus matematika untuk data kami. Kami juga dapat menggunakan pembelajaran mesin untuk membantu kami menemukan lebih banyak wawasan dalam data kami.
Sekali lagi, ini bukan diskusi topik yang lengkap, tetapi saya ingin membagikan beberapa contoh di mana Anda mungkin menggunakan beberapa teknik pembelajaran mesin untuk membantu Anda.
Dalam kumpulan data perayapan, saya mencoba mempelajari sedikit lebih banyak tentang halaman 404, dan jika saya dapat menemukan sesuatu tentangnya. Upaya pertama saya adalah memeriksa apakah ada korelasi antara ukuran halaman dan kode statusnya, dan ada – korelasi yang hampir sempurna!
Saya merasa seperti seorang jenius, selama beberapa menit, dan dengan cepat kembali ke planet Bumi.
Halaman 404 semuanya berada dalam kisaran ukuran halaman yang sangat ketat sehingga hampir semua halaman dengan jumlah kilobyte tertentu memiliki kode status 404. Kemudian saya menyadari bahwa 404 halaman menurut definisi tidak memiliki konten apa pun selain, "halaman kesalahan 404"! Dan itulah mengapa mereka memiliki ukuran yang sama.
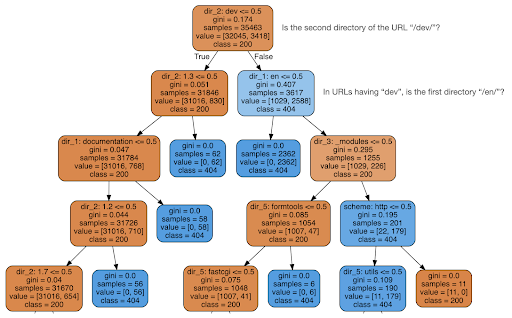
Saya kemudian memutuskan untuk memeriksa apakah konten dapat memberi tahu saya sesuatu tentang kode status, jadi saya membagi URL menjadi elemen-elemennya, dan menjalankan pengklasifikasi pohon keputusan menggunakan sklearn. Ini pada dasarnya adalah teknik yang menghasilkan pohon keputusan, di mana mengikuti aturannya dapat mengarahkan kita untuk belajar bagaimana menemukan target kita, 404 halaman dalam kasus ini.
Dalam pohon keputusan berikut, baris pertama di setiap kotak menunjukkan aturan yang harus diikuti atau diperiksa, garis "sampel" adalah jumlah pengamatan yang ditemukan di kotak ini, dan garis "kelas" memberi tahu kita kelas pengamatan saat ini , dalam hal ini, apakah kode statusnya adalah 200 atau 404.
Saya tidak akan membahas lebih detail, dan saya tahu bahwa pohon keputusan mungkin tidak jelas jika Anda tidak terbiasa dengannya, dan Anda dapat menjelajahi kumpulan data perayapan mentah dan kode analisis jika Anda tertarik.
Pada dasarnya apa yang ditemukan oleh pohon keputusan adalah bagaimana menemukan hampir semua halaman 404, menggunakan struktur direktori URL. Seperti yang Anda lihat, kami menemukan 3.617 URL, cukup dengan memeriksa apakah direktori kedua dari URL tersebut adalah “/dev/” (kotak biru muda pertama di baris kedua dari atas). Jadi sekarang kita tahu bagaimana menemukan 404 kita, dan tampaknya hampir semuanya ada di bagian "/ dev/" situs. Ini jelas merupakan penghemat waktu yang sangat besar. Bayangkan menelusuri semua kemungkinan struktur dan kombinasi URL secara manual untuk menemukan aturan ini.
Kami masih belum memiliki gambaran lengkap dan mengapa ini terjadi, dan ini dapat ditindaklanjuti lebih lanjut, tetapi setidaknya kami sekarang sangat mudah menemukan URL tersebut.
Teknik lain yang mungkin menarik untuk Anda gunakan adalah pengelompokan KMeans, yang mengelompokkan titik data ke dalam berbagai grup/cluster. Ini adalah teknik "belajar tanpa pengawasan", di mana algoritme membantu kami menemukan pola yang tidak kami ketahui ada.
Bayangkan Anda memiliki banyak angka, katakanlah populasi negara, dan Anda ingin mengelompokkannya menjadi dua kelompok, besar dan kecil. Bagaimana Anda melakukannya? Di mana Anda akan menarik garis?
Ini berbeda dengan mendapatkan sepuluh negara teratas, atau X% negara teratas. Ini akan sangat mudah, kita dapat mengurutkan negara berdasarkan populasi, dan mendapatkan yang X teratas seperti yang kita inginkan.
Yang kami inginkan adalah mengelompokkannya sebagai "besar" dan "kecil" relatif terhadap kumpulan data ini, dan dengan asumsi kami tidak tahu apa-apa tentang populasi negara.
Ini dapat diperluas lebih jauh dengan mencoba mengelompokkan negara ke dalam tiga kategori: kecil, menengah, dan besar. Ini menjadi jauh lebih sulit untuk dilakukan secara manual, jika kita menginginkan lima, enam, atau lebih kelompok.
Perhatikan bahwa kami tidak tahu berapa banyak negara yang akan berakhir di setiap grup, karena kami tidak meminta negara X teratas. Pengelompokan menjadi dua kelompok, kita dapat melihat bahwa kita hanya memiliki dua negara dalam kelompok besar: Cina dan India. Ini masuk akal secara intuitif, karena kedua negara ini memiliki populasi rata-rata yang sangat jauh dari semua negara lain. Kelompok negara ini memiliki rata-ratanya sendiri dan negara-negaranya lebih dekat satu sama lain daripada negara-negara kelompok lainnya:
Negara-negara dikelompokkan menjadi dua kelompok berdasarkan populasi 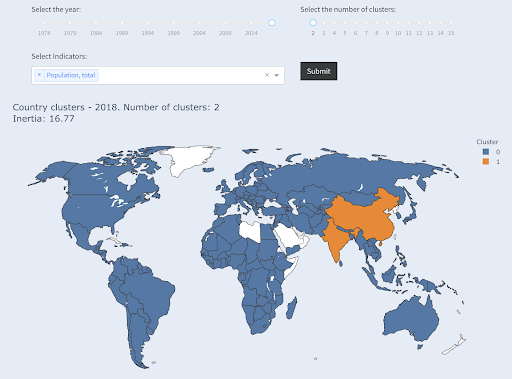
Negara terbesar ketiga dalam hal populasi (AS ~330M) dikelompokkan dengan yang lainnya, termasuk negara-negara yang memiliki populasi satu juta. Itu karena 330M jauh lebih dekat dengan 1M daripada 1,3 miliar. Seandainya kami meminta tiga cluster, kami akan mendapatkan gambaran yang berbeda:
Negara dikelompokkan menjadi tiga kelompok berdasarkan populasi 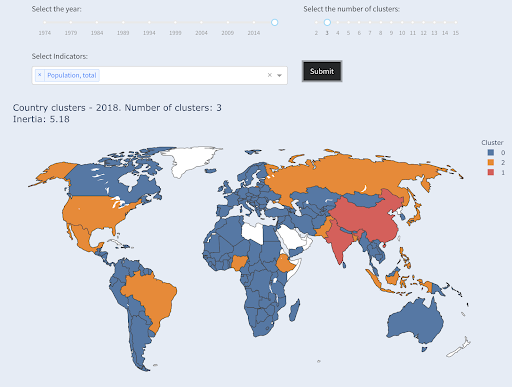
Dan beginilah cara negara-negara akan dikelompokkan jika kita meminta empat kelompok:
Negara-negara dikelompokkan menjadi empat kelompok berdasarkan populasi 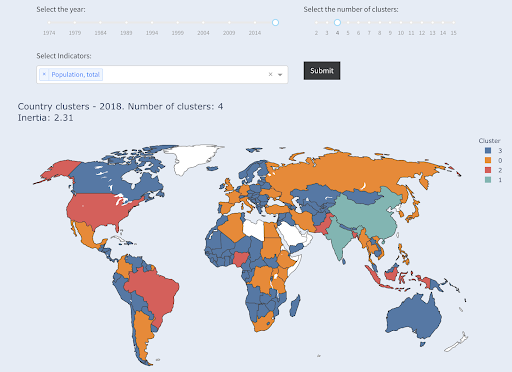
Sumber: poordata.org (tab “Negara Klaster”)
Ini adalah pengelompokan hanya menggunakan satu dimensi – populasi – dalam hal ini, dan Anda dapat menambahkan lebih banyak dimensi juga, dan melihat di mana negara-negara tersebut berakhir.
Ada banyak teknik dan alat lainnya, dan ini hanya beberapa contoh yang mudah-mudahan menarik dan praktis.
Sekarang kami siap untuk mengomunikasikan temuan kami dengan audiens kami.
Menyampaikan
Setelah semua pekerjaan yang kami lakukan di langkah sebelumnya, kami akhirnya harus mengomunikasikan temuan kami kepada pemangku kepentingan proyek lainnya.
Salah satu alat terpenting dalam ilmu data adalah buku catatan interaktif. Notebook Jupyter adalah yang paling banyak digunakan, dan mendukung hampir semua bahasa pemrograman, dan Anda mungkin lebih suka menggunakan format notebook khusus RStudio, yang bekerja dengan cara yang sama.
Ide utamanya adalah memiliki data, kode, narasi, dan visualisasi di satu tempat, sehingga orang lain dapat mengauditnya. Penting untuk menunjukkan bagaimana Anda sampai pada kesimpulan dan rekomendasi tersebut untuk transparansi, serta reproduktifitas. Orang lain harus dapat menjalankan kode yang sama dan mendapatkan hasil yang sama.
Alasan penting lainnya adalah kemampuan orang lain, termasuk "Anda di masa depan", untuk mengambil analisis lebih lanjut, dan membangun pekerjaan awal yang telah Anda lakukan, meningkatkannya, dan mengembangkannya dengan cara baru.
Tentu saja, ini mengasumsikan bahwa audiens merasa nyaman dengan kode, dan mereka bahkan peduli tentangnya!
Anda juga memiliki opsi untuk mengekspor buku catatan Anda ke HTML (dan beberapa format lainnya), tidak termasuk kode, sehingga Anda mendapatkan laporan yang mudah digunakan, namun tetap mempertahankan kode lengkap untuk mereproduksi analisis dan hasil yang sama.
Elemen penting dari komunikasi adalah visualisasi data, yang juga telah dibahas secara singkat di atas.
Lebih baik lagi, adalah visualisasi data interaktif, dalam hal ini Anda mengizinkan audiens Anda untuk memilih nilai, dan memeriksa berbagai kombinasi diagram dan metrik untuk menjelajahi data lebih jauh.
Berikut adalah beberapa dasbor dan aplikasi data (beberapa di antaranya mungkin memerlukan beberapa detik untuk dimuat) yang telah saya buat untuk memberi Anda gambaran tentang apa yang dapat dilakukan.
Akhirnya, Anda juga dapat membuat aplikasi khusus untuk proyek Anda, untuk memenuhi kebutuhan dan persyaratan khusus, dan berikut adalah kumpulan aplikasi SEO dan pemasaran lain yang mungkin menarik bagi Anda.
Kami melewati langkah-langkah utama dalam siklus Ilmu Data, dan sekarang mari kita jelajahi manfaat lain dari "belajar python".
Python adalah untuk otomatisasi dan produktivitas: benar tetapi tidak lengkap
Tampaknya bagi saya ada kepercayaan bahwa belajar Python terutama untuk mendapatkan tugas-tugas yang produktif dan/atau mengotomatisasi.
Ini sepenuhnya benar, dan saya rasa kita bahkan tidak perlu membahas nilai dari kemampuan untuk melakukan sesuatu dalam waktu singkat yang kita perlukan untuk melakukannya secara manual.
Bagian lain yang hilang dari argumen adalah analisis data . Analisis data yang baik memberi kami wawasan, dan idealnya kami dapat memberikan wawasan yang dapat ditindaklanjuti untuk memandu proses pengambilan keputusan kami, berdasarkan keahlian kami dan data yang kami miliki.
Sebagian besar dari apa yang kami lakukan adalah mencoba memahami apa yang terjadi, menganalisis persaingan, mencari tahu di mana konten yang paling berharga, memutuskan apa yang harus dilakukan, dan seterusnya. Kami adalah konsultan, penasihat, dan pengambil keputusan. Mampu mendapatkan beberapa wawasan dari data kami jelas merupakan keuntungan besar, dan bidang serta keterampilan yang disebutkan di sini dapat membantu kami mencapainya.
Bagaimana jika Anda mengetahui bahwa tag judul Anda memiliki panjang rata-rata enam puluh karakter, apakah ini bagus?
Bagaimana jika Anda menggali lebih dalam dan menemukan bahwa separuh dari judul Anda jauh di bawah enam puluh, sementara separuh lainnya memiliki lebih banyak karakter (menjadikan rata-rata enam puluh)? In order to get practical and provide good recommendations, you need a higher-resolution view of your title tags' lengths, probably a histogram that shows the frequency of your title tag lengths at each interval so you can have a separate strategy for length. A simple table would also do, for example:
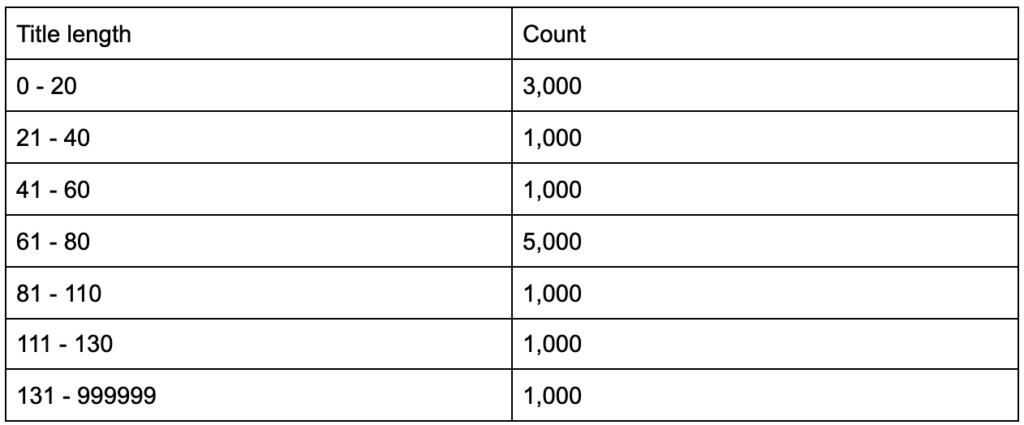
Splitting title lengths by intervals of twenty was an arbitrary decision, and you can split them the way you want. Looking at the table above, and seeing that we have three times more than the average titles in the interval (0, 20), we might want to split it further to better understand what is going on.
Having a better view than the default single-statistic summaries that we get from standard tools, allows us to employ different strategies for different lengths. For example, we can remove the brand name from the titles that are longer than a certain number of characters, and keep it in other titles.
This was an example of very simple insights, which are possible due to the flexibility we get by using a programming language, and a set of data science tools. This also allows us to iterate and modify our approach, until we find a satisfactory point that can take our analysis to the next steps.
Visualization, machine learning, modeling and general data manipulation skills allow us to get better insights on our data, even though those analyses are typically done only once. Still, if you use code to get those insights, you can always take some parts and apply to other projects, or again to the same project. In this case, the insights we got, helped us in our automation, even more. The insights would tell us what needs to be automated and what doesn't.
Should you learn Python?
Is a useless question, and the more useful one is, “How much Python (or R) should you learn?”
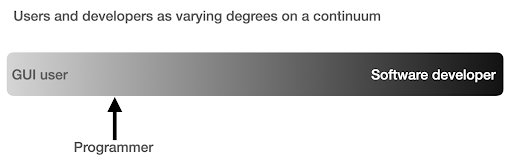
My view of how we use computers has evolved in the last few years.
I used to think that there were two main ways of using computers, either you are a regular user, using “point-and-click” applications to do certain tasks, or you are a developer who creates those applications that the rest of us use.

I then realized that it is more like a continuum between very high level use (pizza ordering approach), and the lower levels of the farm approach. I also realized that there is a happy sweet spot in between, where you learn enough programming to get productive and boost your data analysis skills, without having to become a software developer or engineer.
What are the main differences between being a programmer (a software user), and a software developer (or engineer)?
What are the differences between making a great coffee at home, versus establishing and running a cafe?
If making good coffee is one skill, then running a cafe requires ten other skills, most of which have nothing to do with making coffee.
You have to choose a good location (real estate), hire people (management and HR), manage cash flow and finances (accounting and finance), do marketing, legal, manage delivery, adhere to cleanliness and health standards, and so on. You can be a great coffee maker without knowing anything about those fields, but if you want to take it to the next level, you will have to manage all those additional tasks unrelated to making coffee.
The same applies to being a good programmer or data analyst versus being a software developer/engineer. There are so many other things that you have to know and worry about that you don't need as a regular programmer doing stuff for yourself and co-workers and clients. Once you have enough knowledge and skills in programming and data science, you will be in a good position to choose and decide whether you want to continue as an analyst, focusing on data science, or if you want to end up creating software that other people would use.
How do I get into Data Science?
To learn anything I think you have to do two things in parallel:
- Learn the fundamentals and the theory properly: Taking courses and reading books, and getting into the fundamentals can push you forward, as you will be gaining in weeks, knowledge that took decades to establish. It would also immediately give you ideas on things you thought were impossible, or had no idea existed.
- Get as much real world exposure and experience as possible: Experience is always important, and my suggestion is to try as soon as you can to read_csv with Python or R, to actually do so with your GA, GSC, or crawl dataset. See what else you can do (visualize, manipulate, model, etc.). See if you get errors, try to analyze the data only using your programming language.
What does frustration look like, and by when will I get productive?
It's difficult to say, and it depends on your skill, background, the hours you put in, but visualizing it like this might help you on those frustrating unproductive days:
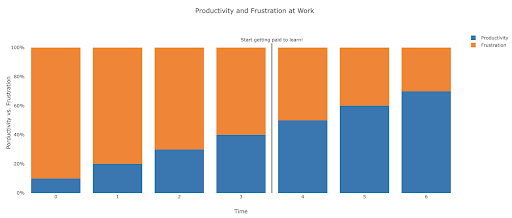
My suggestion is to take a non-trivial task, for example running an SEO audit for a site, only using Python. Your first session will mostly be frustrating, and most of the time will be spent checking documentation, and the definition of basic terms.
In parallel, you are still going through your course, and learning new stuff.
The value of that frustrating session is that it informs and motivates your theoretical learning. You will have questions in mind, and when you learn new things, you will immediately have a place to implement them.
Your next analysis session will probably be a little more productive, but still not productive enough to do at work. You go again to your learning and theory.
Do this enough times, and your time will become mostly productive, eventually you will be doing real work during working hours. The ideal scenario is where you are productive enough to do work, but every time use some time to research better techniques, which improves your work as well. By then you will start to get paid for learning, and your clients will be happily sponsoring you!
Suggested next steps
For the learning path a Data Science course would be great, especially if you get feedback on your work, and you can follow the topics in the order recommended.
If you go with Python I suggest the following libraries:
- pandas: The workhorse of all your tasks in preparing, cleaning, reshaping data whichever way you want. Fluency in pandas allows you to have full control over your data, which will help you immensely in visualization, general analysis, and machine learning
- Plotly and Dash: This is my favorite data visualization library, although there are many others. What I mostly like about it, is that it produces interactive and responsive HTML charts by default. It is very detailed and thorough in its options, yet simple to use. Plotly also includes Plotly Express, which is a high-level plotting tool, which is more intuitive to use, and takes a data-oriented approach (as opposed to a chart-oriented approach). Plotly also created Dash, which is the tool for creating interactive dashboards, but also serves as a full front-end web development framework. Other important data visualization libraries are matplotlib, altair, and bokeh, and for interactive data apps, there is panel and streamlit. Another important feature is that Plotly and Dash are available in all languages used in Data Science. You might use other libraries, and this is just my personal preference. Speaking of personal preferences:
- advertools: This is a library that I created to provide various online marketing tools, most importantly, an SEO crawler, log file parser and compressor, multi robots.txt parser, recursive sitemap parser, SEM keyword and text ad generator for large scale campaigns, weighted frequency word counter, Google SERP downloader, YouTube data API, and a few other tools. It is still evolving, and you are more than welcome to contribute any suggestions, bugs, or issues you might have with it.
These should be enough for beginners, and when you are familiar with them, you can do your own research for more specialized libraries, machine learning and deep learning tools, or libraries that are specialized in performance, or a special niche use-case.