
Data Science dla SEO i marketingu cyfrowego: sugerowany przewodnik dla początkujących
Opublikowany: 2021-12-07Ponieważ większość naszej pracy kręci się wokół danych, a dziedzina Data Science staje się coraz większa i bardziej dostępna dla początkujących, chciałbym podzielić się kilkoma przemyśleniami na temat tego, jak możesz wejść na tę dziedzinę, aby ulepszyć swoje SEO i marketing umiejętności w ogóle.
Czym jest nauka o danych?
Bardzo dobrze znanym diagramem, który służy do przedstawienia przeglądu tej dziedziny, jest diagram Venna Drew Conwaya przedstawiający Data Science jako punkt przecięcia statystyk, hakowania (ogólnie zaawansowane umiejętności programowania, niekoniecznie penetrowanie sieci i powodowanie szkód) i merytoryczne. ekspertyza lub „wiedza dziedzinowa”:
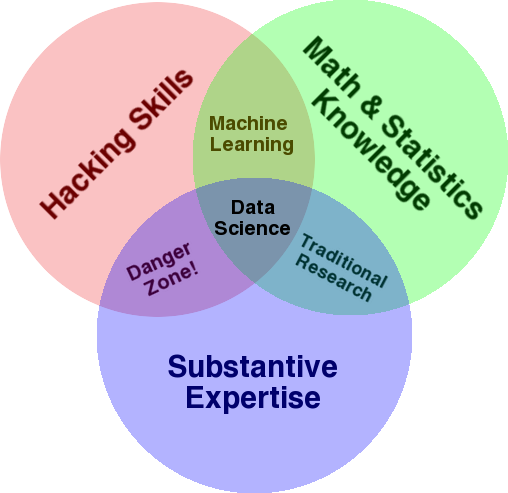
Źródło: oreilly.com
Kiedy zacząłem się uczyć, szybko zdałem sobie sprawę, że właśnie to robimy. Jedyną różnicą jest to, że robiłem to za pomocą bardziej podstawowych i ręcznych narzędzi.
Jeśli spojrzysz na diagram, łatwo zobaczysz, jak prawdopodobnie już to robisz. Korzystasz z komputera (umiejętności hakerskie), analizujesz dane (statystyki), rozwiązujesz praktyczny problem, wykorzystując swoją wiedzę merytoryczną z zakresu SEO (lub jakiejkolwiek specjalizacji, na której się koncentrujesz).
Twój obecny „język programowania” to prawdopodobnie arkusz kalkulacyjny (Excel, Arkusze Google itp.) I najprawdopodobniej używasz programu Powerpoint lub czegoś podobnego do komunikowania pomysłów. Rozwińmy nieco te elementy.
- Znajomość domeny: zacznijmy od Twojej głównej siły, ponieważ już wiesz o swojej specjalizacji. Pamiętaj, że jest to istotna część bycia naukowcem zajmującym się danymi, i to jest miejsce, w którym możesz budować i chronić swoją wiedzę. Kilka miesięcy temu omawiałem analizę zbioru danych indeksowania z moim przyjacielem. Jest fizykiem, prowadzi badania podoktoranckie na komputerach kwantowych. Jego wiedza i umiejętności matematyczne i statystyczne wykraczają daleko poza moje i naprawdę wie, jak analizować dane o wiele lepiej niż ja. Jeden problem. Nie wiedział, czym jest „404” (ani dlaczego obchodzi nas „301”). Tak więc, przy całej swojej wiedzy matematycznej, nie był w stanie zrozumieć kolumny „status” w zbiorze danych indeksowania. Oczywiście nie wiedziałby, co zrobić z tymi danymi, z kim porozmawiać i jakie strategie zbudować w oparciu o te kody statusu (ani czy szukać gdzie indziej). Ty i ja wiemy, co z nimi zrobić, a przynajmniej wiemy, gdzie jeszcze szukać, jeśli chcemy kopać głębiej.
- Matematyka i statystyka: jeśli używasz programu Excel do uzyskania średniej próbki danych, używasz statystyk. Średnia to statystyka opisująca pewien aspekt próbki danych. Bardziej zaawansowane statystyki pomogą w zrozumieniu Twoich danych. To też jest niezbędne i nie jestem ekspertem w tej dziedzinie. Im więcej znasz rozkładów statystycznych, tym więcej masz pomysłów na analizowanie danych. Im bardziej podstawowe tematy znasz, tym lepiej radzisz sobie z formułowaniem hipotez i precyzyjnymi stwierdzeniami na temat zbiorów danych.
- Umiejętności programowania: omówię to bardziej szczegółowo poniżej, ale głównie w tym miejscu budujesz elastyczność polegającą na tym, że mówisz komputerowi, aby zrobił dokładnie to, czego chcesz, w przeciwieństwie do pozostawania przy łatwych w użyciu, ale nieco restrykcyjnych narzędzia. To jest Twój główny sposób na pozyskiwanie, przekształcanie i czyszczenie danych, w dowolny sposób, torując Ci drogę do otwartych i elastycznych „rozmów” z Twoimi danymi.
Przyjrzyjmy się teraz, co zwykle robimy w Data Science.
Cykl nauki o danych
Typowy projekt lub nawet zadanie związane z nauką o danych zwykle wygląda mniej więcej tak:
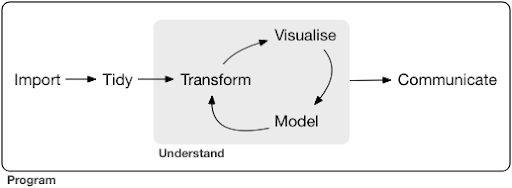
Źródło: r4ds.had.co.nz
Gorąco polecam również przeczytanie tej książki Hadley Wickham i Garretta Grolemunda, która służy jako świetne wprowadzenie do Data Science. Jest napisany z przykładami z języka programowania R, ale koncepcje i kod można łatwo zrozumieć, jeśli znasz tylko Pythona.
Jak widać na diagramie, najpierw musimy jakoś zaimportować nasze dane, uporządkować je, a następnie rozpocząć pracę nad wewnętrznym cyklem transformacji, wizualizacji i modelu. Następnie przekazujemy wyniki innym.
Te kroki mogą być bardzo proste lub bardzo złożone. Na przykład krok „Importuj” może być tak prosty, jak odczytanie pliku CSV, aw niektórych przypadkach może składać się z bardzo skomplikowanego projektu web scrapingu w celu uzyskania danych. Kilka elementów tego procesu to pełnoprawne specjalności same w sobie.
Możemy łatwo odwzorować to na niektóre znane nam procesy. Na przykład możesz zacząć od uzyskania metadanych o witrynie, pobierając jej plik robots.txt i mapy witryny XML. Prawdopodobnie następnie przeszukałbyś i prawdopodobnie również uzyskałbyś dane o pozycjach SERP lub na przykład dane linków. Teraz, gdy masz już kilka zestawów danych, prawdopodobnie chcesz połączyć niektóre tabele, przypisać dodatkowe dane i zacząć eksplorować/zrozumieć. Wizualizacja danych może ujawnić ukryte wzorce lub pomóc w ustaleniu, co się dzieje, lub może wywołać więcej pytań. Prawdopodobnie chcesz również modelować swoje dane za pomocą podstawowych statystyk lub modeli uczenia maszynowego i miejmy nadzieję, że uzyskasz pewne informacje. Oczywiście musisz przekazać wyniki i pytania innym interesariuszom projektu.
Gdy już wystarczająco zapoznasz się z różnymi narzędziami dostępnymi dla każdego z tych procesów, możesz zacząć tworzyć własne niestandardowe potoki, które są specyficzne dla określonej witryny, ponieważ każda firma jest wyjątkowa i ma specjalny zestaw wymagań. W końcu zaczniesz szukać wzorców i nie będziesz musiał przerabiać całej pracy dla podobnych projektów/stron internetowych.
Dla każdego elementu w tym procesie dostępnych jest wiele narzędzi i bibliotek, a wybór narzędzia może być dość przytłaczający (i zainwestować swój czas w naukę). Przyjrzyjmy się możliwemu podejściu, które uważam za przydatne przy doborze narzędzi, których używam.
Wybór narzędzi i kompromisów (3 sposoby na pizzę)
Czy powinieneś używać programu Excel do codziennej pracy przy przetwarzaniu danych, czy warto nauczyć się Pythona?
Czy lepiej jest wizualizować za pomocą czegoś takiego jak Power BI, czy warto zainwestować w poznanie gramatyki grafiki i dowiedzieć się, jak korzystać z bibliotek, które ją implementują?
Czy stworzyłbyś lepszą pracę, budując własne interaktywne pulpity nawigacyjne w języku R lub Python, czy po prostu skorzystaj z Google Data Studio?
Przyjrzyjmy się najpierw kompromisom związanym z wyborem różnych narzędzi na różnych poziomach abstrakcji. To jest fragment mojej książki o budowaniu interaktywnych pulpitów nawigacyjnych i aplikacji do obsługi danych za pomocą Plotly i Dash i uważam, że to podejście jest przydatne:
Rozważ trzy różne podejścia do pizzy:
- Sposób zamawiania: dzwonisz do restauracji i zamawiasz pizzę. Dociera do twoich drzwi za pół godziny i zaczynasz jeść.
- Podejście do supermarketu: Idziesz do supermarketu, kupujesz ciasto, ser, warzywa i wszystkie inne składniki. Następnie sam robisz pizzę.
- Podejście do farmy: Uprawiasz pomidory na swoim podwórku. Hodujesz krowy, dojysz je i przetwarzasz mleko na ser i tak dalej.
W miarę, jak przechodzimy do interfejsów wyższego poziomu, w kierunku podejścia do zamawiania, ilość wymaganej wiedzy znacznie się zmniejsza. Ktoś inny ponosi odpowiedzialność, a jakość jest sprawdzana przez siły rynkowe reputacji i konkurencji.
Ceną, jaką za to płacimy, jest ograniczona wolność i opcje. Każda restauracja ma zestaw opcji do wyboru i musisz wybierać spośród tych opcji.
Schodząc na niższe poziomy zwiększa się ilość wymaganej wiedzy, musimy radzić sobie z większą złożonością, ponosimy większą odpowiedzialność za wyniki i zajmuje to znacznie więcej czasu. To, co zyskujemy tutaj, to znacznie więcej wolności i mocy, aby dostosować nasze wyniki tak, jak chcemy. Istotną korzyścią jest również koszt, ale tylko na wystarczająco dużą skalę. Jeśli chcesz mieć dzisiaj tylko pizzę, prawdopodobnie taniej jest ją zamówić. Ale jeśli planujesz mieć go codziennie, możesz spodziewać się znacznych oszczędności, jeśli zrobisz to sam.
Są to rodzaje wyborów, których będziesz musiał dokonać, wybierając narzędzia, których będziesz używać i których będziesz się uczyć. Korzystanie z języka programowania, takiego jak R lub Python, wymaga znacznie więcej pracy i jest trudniejsze niż Excel, z tą korzyścią, że jest znacznie bardziej produktywny i wydajny.
Wybór jest również ważny dla każdego narzędzia lub procesu. Na przykład możesz użyć wysokiego poziomu i łatwego w użyciu robota do zbierania danych o witrynie, a mimo to wolisz używać języka programowania do wizualizacji danych ze wszystkimi dostępnymi opcjami. Wybór odpowiedniego narzędzia do właściwego procesu zależy od Twoich potrzeb, a opisany powyżej kompromis może pomóc w dokonaniu tego wyboru. Miejmy nadzieję, że pomoże to również odpowiedzieć na pytanie, czy (lub ile) Pythona lub R chcesz się nauczyć.
Zajmijmy się tym pytaniem nieco dalej i zobaczmy, dlaczego nauka Pythona pod kątem SEO może nie być właściwym słowem kluczowym.
Dlaczego „python dla SEO” wprowadza w błąd
Chcesz zostać świetnym blogerem, czy chcesz nauczyć się WordPressa?
Czy chcesz zostać grafikiem, czy Twoim celem jest nauczenie się Photoshopa?
Czy jesteś zainteresowany rozwinięciem swojej kariery SEO poprzez przeniesienie swoich umiejętności związanych z danymi na wyższy poziom, czy też chcesz nauczyć się Pythona?
W ciągu pierwszych pięciu minut pierwszego wykładu kursu informatyki na MIT profesor Harold Abelson otwiera kurs, mówiąc uczniom, dlaczego „informatyka” to tak zła nazwa dla dyscypliny, której mają się uczyć. Myślę, że oglądanie pierwszych pięciu minut wykładu jest bardzo interesujące:
Kiedy jakaś dziedzina dopiero się zaczyna i tak naprawdę nie rozumiesz jej zbyt dobrze, bardzo łatwo jest pomylić istotę tego, co robisz, z używanymi narzędziami. – Harold Abelson
Staramy się poprawić naszą obecność w Internecie i wyniki, a wiele z tego, co robimy, opiera się na ogólnym zrozumieniu, wizualizacji, manipulowaniu i przetwarzaniu danych, i na tym się skupiamy, niezależnie od używanego narzędzia. Data Science to dziedzina, która ma do tego ramy intelektualne, a także wiele narzędzi do realizacji tego, co chcemy robić. Python może być Twoim ulubionym językiem programowania (narzędziem) i zdecydowanie ważne jest, aby dobrze się go nauczyć. Równie ważne, jeśli nie ważniejsze, jest skupienie się na „istotie tego, co robisz”, przetwarzaniu i analizowaniu danych, w naszym przypadku.
Główny nacisk należy położyć na procesy omówione powyżej (importowanie, porządkowanie, wizualizacja itp.), a nie na wybrany język programowania. Albo lepiej, jak używać tego języka programowania do wykonywania swoich zadań, zamiast po prostu uczyć się języka programowania.
Kogo obchodzi te wszystkie teoretyczne rozróżnienia, jeśli i tak mam się uczyć Pythona?
Przyjrzyjmy się, co może się stać, jeśli skupisz się na poznawaniu narzędzia, a nie na istocie tego, co robisz. Tutaj porównujemy wyszukiwanie „naucz się wordpress” (narzędzie) z „naucz się blogowania” (rzecz, którą chcemy zrobić):
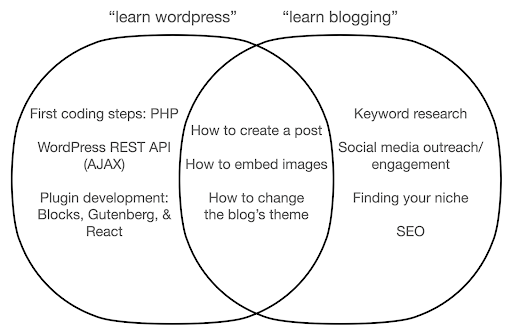
Diagram pokazuje możliwe tematy pod książką lub kursem, który uczy o słowie kluczowym znajdującym się na górze. Środkowy obszar skrzyżowania pokazuje tematy, które mogą występować w obu rodzajach kursów/książek.
Jeśli skupisz się na narzędziu, bez wątpienia będziesz musiał uczyć się o rzeczach, których tak naprawdę nie potrzebujesz, zwłaszcza jako początkujący. Te tematy mogą Cię dezorientować i frustrować, zwłaszcza jeśli nie masz doświadczenia technicznego lub programistycznego.
Dowiesz się również rzeczy, które są przydatne, aby zostać dobrym blogerem (tematy w obszarze skrzyżowania). Te tematy są niezwykle łatwe do nauczenia (jak stworzyć post na blogu), ale nie mówią ci zbyt wiele o tym, dlaczego powinieneś blogować, kiedy i o czym. Nie jest to wadą książki zorientowanej na narzędzia, ponieważ poznając narzędzie, wystarczy nauczyć się tworzyć post na blogu i przejść dalej.
Jako bloger jesteś prawdopodobnie bardziej zainteresowany tym, co i dlaczego bloguje, a to nie zostałoby omówione w książkach poświęconych narzędziom.
Oczywiście strategiczne i ważne rzeczy, takie jak SEO, znajdowanie swojej niszy i tak dalej, nie zostaną omówione, więc stracisz bardzo ważne rzeczy.
O jakich tematach Data Science prawdopodobnie nie dowiesz się w książce o programowaniu?
Jak widzieliśmy, wybranie Pythona lub książki o programowaniu prawdopodobnie oznacza, że chcesz zostać inżynierem oprogramowania. Tematy byłyby naturalnie nastawione na ten cel. Jeśli szukasz książki Data Science, znajdziesz tematy i narzędzia bardziej ukierunkowane na analizę danych.
Możemy użyć pierwszego diagramu (przedstawiającego cykl Data Science) jako przewodnika i proaktywnie wyszukiwać te tematy: „importuj dane za pomocą Pythona”, „porządkuj dane za pomocą r”, „wizualizuj dane za pomocą Pythona” i tak dalej. Przyjrzyjmy się bliżej tym tematom i zbadajmy je dalej:
Import
Oczywiście najpierw musimy uzyskać pewne dane. To może być:
- Plik na naszym komputerze: Najprostszy przypadek, w którym po prostu otwierasz plik w wybranym języku programowania. Ważne jest, aby pamiętać, że istnieje wiele różnych formatów plików i że masz wiele opcji podczas otwierania/odczytywania plików. Na przykład funkcja read_csv z biblioteki pandas (niezbędne narzędzie do manipulacji danymi w Pythonie) ma pięćdziesiąt opcji do wyboru podczas otwierania pliku. Zawiera takie rzeczy, jak ścieżka pliku, kolumny do wyboru, liczba wierszy do otwarcia, interpretacja obiektów daty i godziny, sposób postępowania z brakującymi wartościami i wiele innych. Ważne jest, aby zapoznać się z tymi opcjami i różnymi względami podczas otwierania różnych formatów plików. Ponadto pandas ma dziewiętnaście różnych funkcji, które zaczynają się od read_ dla różnych formatów plików i danych.
- Eksportuj z narzędzia online: Prawdopodobnie to znasz i tutaj możesz dostosować swoje dane, a następnie je wyeksportować, po czym otworzysz je jako plik na swoim komputerze.
- Wywołania API w celu uzyskania określonych danych: Jest to na niższym poziomie i bliższe wspomnianemu wyżej podejściu farmy. W takim przypadku wysyłasz zapytanie z określonymi wymaganiami i odzyskujesz żądane dane. Zaletą jest to, że możesz dostosować dokładnie to, co chcesz uzyskać, i sformatować to w sposób, który może nie być dostępny w interfejsie online. Na przykład w Google Analytics możesz dodać dodatkowy wymiar do analizowanej tabeli, ale nie możesz dodać trzeciego. Jesteś również ograniczony liczbą wierszy, które możesz wyeksportować. Interfejs API zapewnia większą elastyczność, a także pozwala zautomatyzować niektóre wywołania, aby odbywały się okresowo, w ramach większego potoku zbierania/analizy danych.
- Indeksowanie i skrobanie danych: prawdopodobnie masz swojego ulubionego robota indeksującego i prawdopodobnie znasz ten proces. Jest to już elastyczny proces, który pozwala nam wyodrębniać niestandardowe elementy ze stron, indeksować tylko niektóre strony i tak dalej.
- Połączenie metod obejmujących automatyzację, niestandardową ekstrakcję i ewentualnie uczenie maszynowe do specjalnych zastosowań.
Gdy mamy już jakieś dane, chcemy przejść na wyższy poziom.
Czysty
„Uporządkowany” zbiór danych to zbiór danych zorganizowany w określony sposób. Są one również określane jako dane „długiego formatu”. Rozdział 12 książki R for Data Science omawia bardziej szczegółowo koncepcję uporządkowanych danych, jeśli jesteś zainteresowany.
Spójrz na trzy poniższe tabele i spróbuj znaleźć jakiekolwiek różnice:
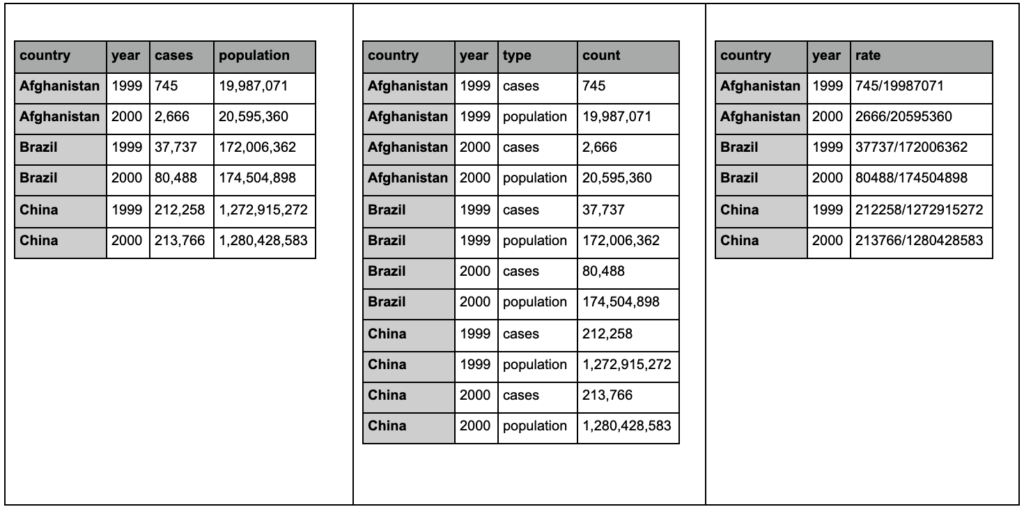
Przykładowe stoły z pakietu tidyr.
Przekonasz się, że te trzy tabele zawierają dokładnie te same informacje, ale zorganizowane i przedstawione na różne sposoby. Możemy mieć obserwacje i populację w dwóch oddzielnych kolumnach (tabela 1) lub mieć kolumnę, która mówi nam, czym jest obserwacja (przypadki lub populacja) i kolumnę „liczba” do zliczania tych przypadków (tabela 2). W tabeli 3 są one pokazane jako stawki.
Kiedy masz do czynienia z danymi, zauważysz, że różne źródła w różny sposób organizują dane i że często będziesz musiał zmienić z/na określone formaty w celu lepszej i łatwiejszej analizy. Znajomość tych operacji czyszczenia jest kluczowa, a pakiet tidyr w R zawiera specjalne narzędzia do tego. Możesz także użyć pand, jeśli wolisz Pythona, i możesz sprawdzić w tym celu funkcje melt i pivot.
Gdy nasze dane są już w określonym formacie, możemy chcieć dalej nimi manipulować.
Przekształcać
Kolejną kluczową umiejętnością do zbudowania jest możliwość wprowadzania dowolnych zmian w danych, z którymi pracujesz. Idealnym scenariuszem jest dotarcie do etapu, na którym możesz prowadzić rozmowy ze swoimi danymi i być w stanie pokroić w kostkę w dowolny sposób, w jaki chcesz zadawać bardzo konkretne pytania, i miejmy nadzieję, że uzyskasz interesujący wgląd. Oto niektóre z najważniejszych zadań transformacji, których prawdopodobnie będziesz potrzebować, wraz z przykładowymi zadaniami, które mogą Cię zainteresować:
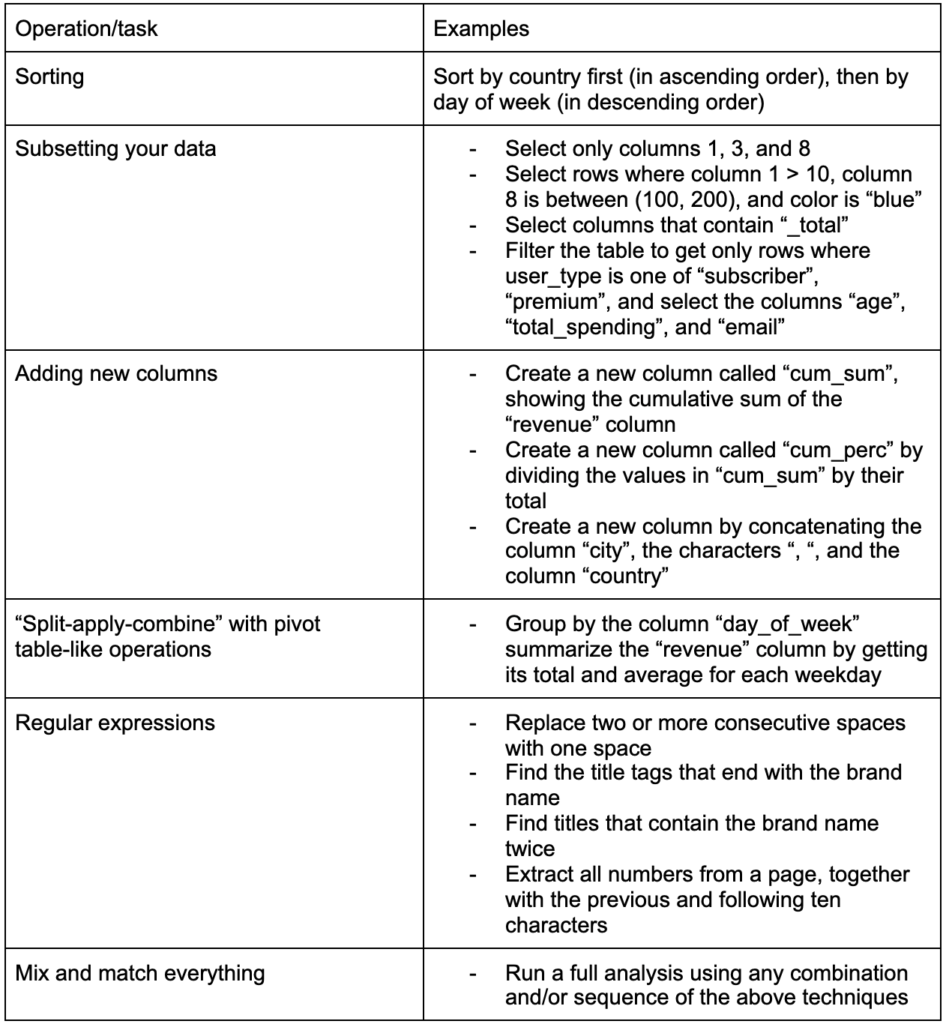
Po zdobyciu, uporządkowaniu i umieszczeniu naszych danych w pożądanym formacie dobrze byłoby je zwizualizować.
Wyobrażać sobie
Wizualizacja danych to ogromny temat, a na niektóre z jego podtematów są całe książki. Jest to jedna z tych rzeczy, która może dać dużo wglądu w nasze dane, zwłaszcza, że wykorzystuje intuicyjne elementy wizualne do przekazywania informacji. Względna wysokość słupków na wykresie słupkowym natychmiast pokazuje nam na przykład ich względną ilość. Intensywność koloru, względna lokalizacja i wiele innych atrybutów wizualnych są łatwo rozpoznawalne i zrozumiałe dla czytelników.
Dobry wykres jest wart tysiąca (kluczowych) słów!
Ponieważ istnieje wiele tematów do omówienia na temat wizualizacji danych, po prostu podzielę się kilkoma przykładami, które mogą być interesujące. Kilka z nich to elementy składowe tego panelu danych dotyczących ubóstwa, jeśli chcesz uzyskać pełne informacje.
Prosty wykres słupkowy to czasami wszystko, czego możesz potrzebować do porównania wartości, gdzie słupki mogą być wyświetlane pionowo lub poziomo:
Możesz chcieć poznać niektóre kraje i zagłębić się w szczegóły, obserwując ich postępy w zakresie określonych danych. W takim przypadku możesz chcieć wyświetlić wiele wykresów słupkowych na tym samym wykresie:
Porównywania wielu wartości dla wielu obserwacji można również dokonać, umieszczając wiele słupków w każdej pozycji na osi X, oto główne sposoby, aby to zrobić:
Wybór kolorów i skal kolorów: Niezbędna część wizualizacji danych i coś, co może niezwykle wydajnie i intuicyjnie przekazywać informacje, jeśli zostanie wykonane prawidłowo.
Skale kategoryczne kolorów: przydatne do wyrażania danych kategorycznych. Jak sama nazwa wskazuje, jest to rodzaj danych, który pokazuje, do jakiej kategorii należy dana obserwacja. W tym przypadku chcemy, aby kolory, które jak najbardziej różnią się od siebie, pokazywały wyraźne różnice w kategoriach (zwłaszcza w przypadku elementów wizualnych, które są wyświetlane obok siebie).
Poniższy przykład wykorzystuje kategoryczną skalę kolorów, aby pokazać, który system rządzenia jest wdrożony w każdym kraju. Dosyć łatwo jest połączyć kolory krajów z legendą, która pokazuje, jaki system rządów jest używany. Nazywa się to również kartogramem:
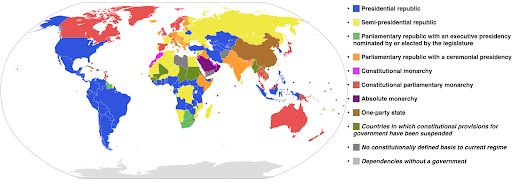
Źródło: Wikipedia
Czasami dane, które chcemy wizualizować, dotyczą tej samej metryki, a każdy kraj (lub jakikolwiek inny rodzaj obserwacji) przypada na pewien punkt w kontinuum wahającym się między punktem minimalnym a maksymalnym. Innymi słowy, chcemy zwizualizować stopnie tej metryki.
W takich przypadkach musimy znaleźć ciągłą (lub sekwencyjną) skalę kolorów . W poniższym przykładzie od razu widać, które kraje są bardziej niebieskie (a tym samym generują większy ruch), i możemy intuicyjnie zrozumieć zróżnicowane różnice między krajami.
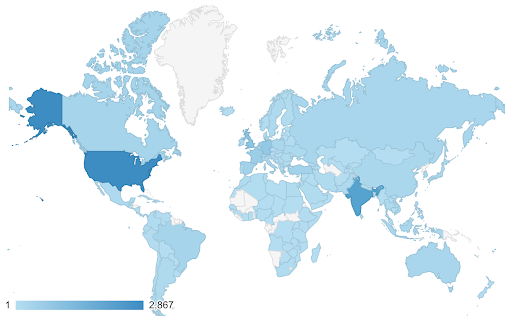
Twoje dane mogą być ciągłe (tak jak powyższy wykres mapy ruchu), ale ważną rzeczą w liczbach może być to, jak bardzo różnią się od określonego punktu. W tym przypadku przydatne są rozbieżne skale kolorów .
Poniższy wykres przedstawia wskaźniki wzrostu populacji netto. W tym przypadku warto najpierw wiedzieć, czy dany kraj ma dodatnią, czy ujemną stopę wzrostu. Lub chcemy wiedzieć, jak daleko każdy kraj jest od zera (i o ile). Spojrzenie na mapę od razu pokazuje nam, w których krajach populacja rośnie, a która się kurczy. Legenda pokazuje nam również, że maksymalna dodatnia stopa wynosi 3,5%, a maksymalna ujemna to -0,5%. Daje nam to również wskazówkę dotyczącą zakresu wartości (dodatnich i ujemnych).

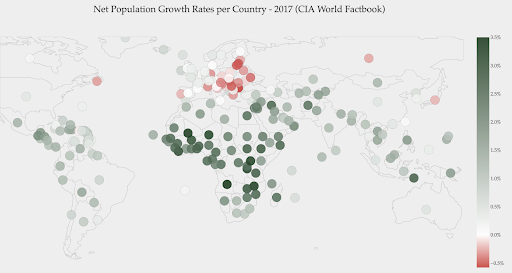
Źródło: Dashboardom.com
Niestety, kolory wybrane dla tej skali nie są idealne, ponieważ osoby nierozróżniające kolorów mogą nie być w stanie prawidłowo odróżnić czerwieni od zieleni. Jest to bardzo ważna kwestia przy wyborze naszej skali kolorów.
Wykres punktowy jest jednym z najczęściej używanych i wszechstronnych typów wykresów. Pozycja kropek (lub dowolnego innego znacznika) określa ilość, którą próbujemy przekazać. Oprócz pozycji możemy użyć kilku innych atrybutów wizualnych, takich jak kolor, rozmiar i kształt, aby przekazać jeszcze więcej informacji. Poniższy przykład pokazuje odsetek ludności żyjącej za 1,9 USD/dzień, co wyraźnie widać jako poziomą odległość punktów.
Możemy również dodać nowy wymiar do naszego wykresu za pomocą koloru. Odpowiada to wizualizacji trzeciej kolumny z tego samego zestawu danych, która w tym przypadku przedstawia dane dotyczące populacji.
Widzimy teraz, że najbardziej ekstremalny przypadek pod względem liczby ludności (USA) to bardzo niski wskaźnik poziomu ubóstwa. To dodaje bogactwa naszym wykresom. Mogliśmy również użyć rozmiaru i kształtu do wizualizacji jeszcze większej liczby kolumn z naszego zestawu danych. Musimy jednak zachować równowagę między bogactwem a czytelnością.
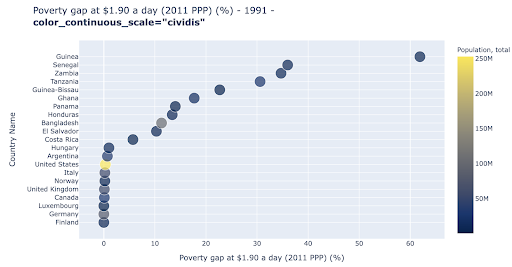
Możemy być zainteresowani sprawdzeniem, czy istnieje związek między populacją a poziomem ubóstwa, a więc możemy zwizualizować ten sam zestaw danych w nieco inny sposób, aby zobaczyć, czy taki związek istnieje:
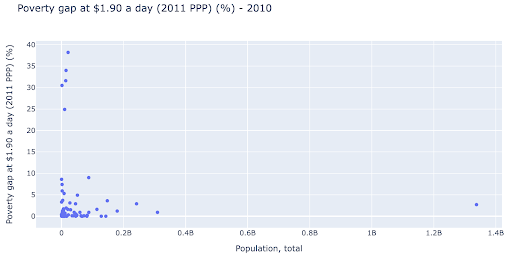
Mamy jedną wartość odstającą w populacji około 1,35 mld, a to oznacza, że na wykresie jest dużo białych znaków, co oznacza również, że wiele wartości jest ściśniętych na bardzo małym obszarze. Mamy też wiele nakładających się kropek, co bardzo utrudnia dostrzeżenie jakichkolwiek różnic czy trendów.
Poniższy wykres zawiera te same informacje, ale inaczej wizualizowane przy użyciu dwóch technik:
- Skala logarytmiczna : zwykle widzimy dane w skali addytywnej. Innymi słowy, każdy punkt na osi (X lub Y) reprezentuje dodanie pewnej ilości wizualizowanych danych. Możemy również mieć skale multiplikatywne, w takim przypadku dla każdego nowego punktu na osi X mnożymy (w tym przykładzie przez dziesięć). Pozwala to na rozłożenie punktów i musimy myśleć o wielokrotnościach, a nie o dodawaniu, tak jak na poprzednim wykresie.
- Korzystanie z innego znacznika (większe puste koła) : Wybranie innego kształtu dla naszych znaczników rozwiązało problem „nadmiernego kreślenia”, w którym możemy mieć kilka punktów jeden na drugim w tym samym miejscu, co bardzo utrudnia nawet zauważenie ile mamy punktów.
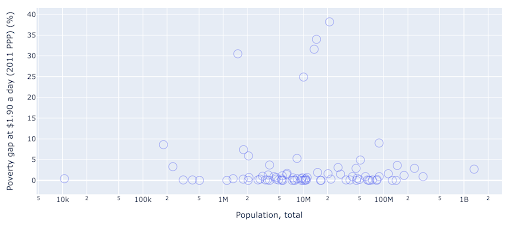
Widzimy teraz, że istnieje klaster krajów w okolicy 10 mln, a także inne mniejsze klastry.
Jak wspomniałem, rodzajów znaków i opcji wizualizacji jest znacznie więcej, a na ten temat napisano całe książki. Mam nadzieję, że to da ci kilka ciekawych przemyśleń do eksperymentowania.
Dane dotyczące indeksowania³
 Ucz się więcej
Ucz się więcejModel
Musimy uprościć nasze dane i znaleźć wzorce, przewidywać lub po prostu lepiej je zrozumieć. To kolejny obszerny temat, który może wahać się od prostego uzyskania statystyk podsumowujących (średnia, mediana, odchylenie standardowe itp.), wizualnego modelowania naszych danych, przy użyciu modelu podsumowującego lub wyszukującego trend, po użycie bardziej złożonych technik w celu uzyskania wzór matematyczny dla naszych danych. Możemy również wykorzystać uczenie maszynowe, aby pomóc nam odkryć więcej wglądu w nasze dane.
Ponownie, to nie jest pełna dyskusja na ten temat, ale chciałbym podzielić się kilkoma przykładami, w których możesz użyć kilku technik uczenia maszynowego, aby ci pomóc.
W zestawie danych indeksowania próbowałem dowiedzieć się trochę więcej o stronach 404 i czy mogę coś o nich odkryć. Moją pierwszą próbą było sprawdzenie, czy istnieje korelacja między rozmiarem strony a jej kodem statusu, i była – prawie idealna korelacja!
Poczułem się przez kilka minut jak geniusz i szybko wróciłem na Ziemię.
Wszystkie strony 404 mieściły się w bardzo wąskim zakresie rozmiaru strony, prawie wszystkie strony z określoną liczbą kilobajtów miały kod stanu 404. Potem zdałem sobie sprawę, że strony 404 z definicji nie zawierają żadnej treści poza, cóż, „stroną błędu 404”! I dlatego miały ten sam rozmiar.
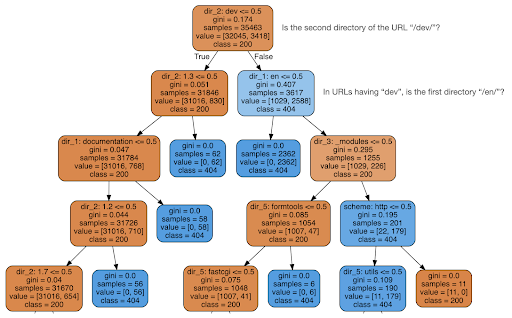
Następnie postanowiłem sprawdzić, czy treść może mi coś powiedzieć o kodzie stanu, więc podzieliłem adresy URL na ich elementy i uruchomiłem klasyfikator drzewa decyzyjnego za pomocą sklearn. Jest to w zasadzie technika, która tworzy drzewo decyzyjne, w którym przestrzeganie jego zasad może doprowadzić nas do nauczenia się, jak znaleźć nasz cel, w tym przypadku 404 strony.
W poniższym drzewie decyzyjnym pierwszy wiersz w każdym polu pokazuje regułę, której należy przestrzegać lub której należy sprawdzić, wiersz „próbki” to liczba obserwacji znalezionych w tym polu, a wiersz „klasa” informuje nas o klasie bieżącej obserwacji , w tym przypadku, niezależnie od tego, czy jego kod stanu to 200 czy 404.
Nie będę wdawał się w więcej szczegółów i wiem, że drzewo decyzyjne może nie być jasne, jeśli nie jesteś z nimi zaznajomiony, a jeśli jesteś zainteresowany, możesz zapoznać się z nieprzetworzonym zestawem danych indeksowania i kodem analizy.
Zasadniczo drzewo decyzyjne odkryło, jak znaleźć prawie wszystkie strony 404, korzystając ze struktury katalogów adresów URL. Jak widać, znaleźliśmy 3617 adresów URL, po prostu sprawdzając, czy drugim katalogiem adresu URL jest „/dev/” (pierwsze jasnoniebieskie pole w drugiej linii od góry). Więc teraz wiemy, jak zlokalizować nasze 404 i wydaje się, że prawie wszystkie znajdują się w sekcji „/dev/” witryny. To zdecydowanie była ogromna oszczędność czasu. Wyobraź sobie, że przeglądasz ręcznie wszystkie możliwe struktury i kombinacje adresów URL, aby znaleźć tę regułę.
Wciąż nie mamy pełnego obrazu przyczyny takiego stanu rzeczy i można to dalej badać, ale przynajmniej teraz bardzo łatwo zlokalizowaliśmy te adresy URL.
Inną techniką, którą możesz być zainteresowany, jest klastrowanie KMeans, które grupuje punkty danych w różne grupy/klastry. Jest to technika „nienadzorowanego uczenia się”, w której algorytm pomaga nam odkryć wzorce, o których istnieniu nie wiedzieliśmy.
Wyobraź sobie, że masz kilka liczb, powiedzmy populację krajów, i chcesz je podzielić na dwie grupy, dużą i małą. Jak byś to zrobił? Gdzie byś narysował linię?
Różni się to od uzyskania dziesięciu najlepszych krajów lub najlepszych X% krajów. Byłoby to bardzo proste, możemy posortować kraje według populacji i uzyskać najlepsze X według potrzeb.
Chcemy pogrupować je jako „duże” i „małe” w odniesieniu do tego zbioru danych i zakładając, że nie wiemy nic o populacjach krajów.
Można to dalej rozszerzyć, próbując podzielić kraje na trzy kategorie: małe, średnie i duże. Jest to znacznie trudniejsze do wykonania ręcznie, jeśli chcemy mieć pięć, sześć lub więcej grup.
Zwróć uwagę, że nie wiemy, ile krajów znajdzie się w każdej grupie, ponieważ nie pytamy o najlepsze kraje X. Grupując w dwa klastry, widzimy, że mamy tylko dwa kraje w dużej grupie: Chiny i Indie. Ma to intuicyjny sens, ponieważ średnia populacja tych dwóch krajów jest bardzo daleka od wszystkich innych krajów. Ta grupa krajów ma swoją średnią, a jej kraje są bliżej siebie niż kraje z drugiej grupy:
Kraje zgrupowane w dwie grupy według populacji 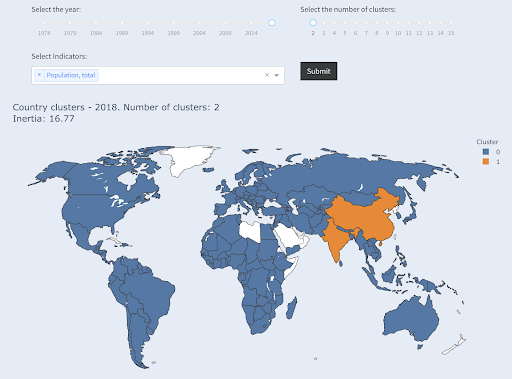
Trzeci co do wielkości kraj pod względem liczby ludności (USA ~330 mln) został zgrupowany ze wszystkimi innymi, w tym z krajami o populacji miliona. To dlatego, że 330 mln jest znacznie bliższe 1 mln niż 1,3 mld. Gdybyśmy poprosili o trzy klastry, otrzymalibyśmy inny obraz:
Kraje zgrupowane w trzy grupy według populacji 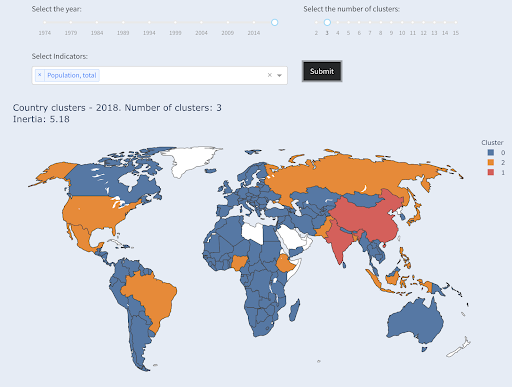
I tak pogrupowane byłyby kraje, gdybyśmy poprosili o cztery klastry:
Kraje zgrupowane w cztery grupy według populacji 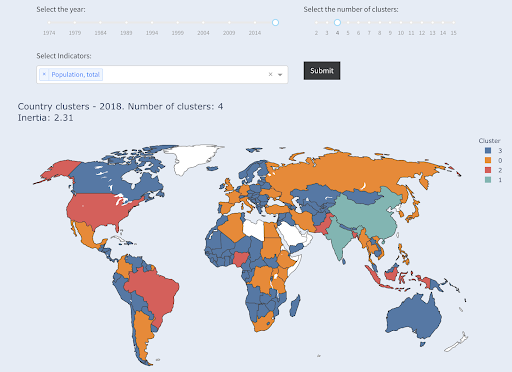
Źródło: ubóstwodata.org (zakładka „Kraje klastra”)
Było to grupowanie przy użyciu tylko jednego wymiaru – populacji – w tym przypadku, można też dodać więcej wymiarów i zobaczyć, gdzie kończą się kraje.
Istnieje wiele innych technik i narzędzi, a to tylko kilka przykładów, które, miejmy nadzieję, są interesujące i praktyczne.
Teraz jesteśmy gotowi do przekazania naszych wyników naszym odbiorcom.
Porozumieć się
Po całej pracy, którą wykonaliśmy w poprzednich krokach, musimy ostatecznie przekazać nasze ustalenia innym interesariuszom projektu.
Jednym z najważniejszych narzędzi nauki o danych jest interaktywny notatnik. Notatnik Jupyter jest najczęściej używany i obsługuje prawie wszystkie języki programowania, a być może wolisz użyć specjalnego formatu notatnika RStudio, który działa w ten sam sposób.
Główną ideą jest zgromadzenie danych, kodu, narracji i wizualizacji w jednym miejscu, aby inne osoby mogły je kontrolować. Ważne jest, aby pokazać, w jaki sposób doszedłeś do tych wniosków i zaleceń dotyczących przejrzystości, a także odtwarzalności. Inne osoby powinny być w stanie uruchomić ten sam kod i uzyskać te same wyniki.
Innym ważnym powodem jest zdolność innych osób, w tym „przyszłego ciebie”, do pogłębienia analizy i wykorzystania początkowej pracy, którą wykonałeś, ulepszania jej i rozwijania na nowe sposoby.
Oczywiście zakłada to, że widzowie czują się swobodnie z kodem i że nawet im na tym zależy!
Masz również możliwość wyeksportowania swoich notatników do HTML (i kilku innych formatów), z wyłączeniem kodu, dzięki czemu otrzymujesz przyjazny dla użytkownika raport, a jednocześnie zachowujesz pełny kod, aby odtworzyć tę samą analizę i wyniki.
Ważnym elementem komunikacji jest wizualizacja danych, o której również pokrótce wspomniano powyżej.
Jeszcze lepsza jest interaktywna wizualizacja danych, w której pozwalasz odbiorcom wybierać wartości i sprawdzać różne kombinacje wykresów i metryk, aby jeszcze dokładniej analizować dane.
Oto kilka pulpitów nawigacyjnych i aplikacji danych (niektóre z nich mogą załadować się kilka sekund), które stworzyłem, aby dać ci wyobrażenie o tym, co można zrobić.
Ostatecznie możesz również tworzyć niestandardowe aplikacje dla swoich projektów, aby zaspokoić specjalne potrzeby i wymagania, a oto kolejny zestaw aplikacji SEO i marketingowych, które mogą być dla Ciebie interesujące.
Przeszliśmy przez główne etapy cyklu Data Science, a teraz przyjrzyjmy się kolejnej korzyści płynącej z „uczenia się Pythona”.
Python służy automatyzacji i produktywności: prawda, ale niekompletna
Wydaje mi się, że istnieje przekonanie, że nauka Pythona służy głównie uzyskiwaniu produktywnych i/lub automatyzacji zadań.
To absolutnie prawda i nie sądzę, że musimy nawet dyskutować o wartości możliwości zrobienia czegoś w ułamku czasu, który zajęłoby nam zrobienie tego ręcznie.
Inną brakującą częścią argumentu jest analiza danych . Dobra analiza danych zapewnia nam spostrzeżenia, a najlepiej byłoby, gdybyśmy byli w stanie dostarczyć praktycznych spostrzeżeń, które pokierują naszym procesem podejmowania decyzji, w oparciu o naszą wiedzę fachową i dane, które posiadamy.
Duża część tego, co robimy, to próba zrozumienia tego, co się dzieje, analizowanie konkurencji, określanie, gdzie znajdują się najcenniejsze treści, decydowanie, co robić i tak dalej. Jesteśmy konsultantami, doradcami i decydentami. Możliwość uzyskania wglądu w nasze dane jest z pewnością dużą korzyścią, a wymienione tutaj obszary i umiejętności mogą nam w tym pomóc.
Co by było, gdybyś dowiedział się, że tagi tytułowe mają średnią długość sześćdziesięciu znaków, czy to dobrze?
A co, jeśli zagłębisz się nieco głębiej i odkryjesz, że połowa twoich tytułów jest znacznie poniżej sześćdziesięciu, podczas gdy druga połowa ma znacznie więcej postaci (co daje średnią sześćdziesiąt)? In order to get practical and provide good recommendations, you need a higher-resolution view of your title tags' lengths, probably a histogram that shows the frequency of your title tag lengths at each interval so you can have a separate strategy for length. A simple table would also do, for example:
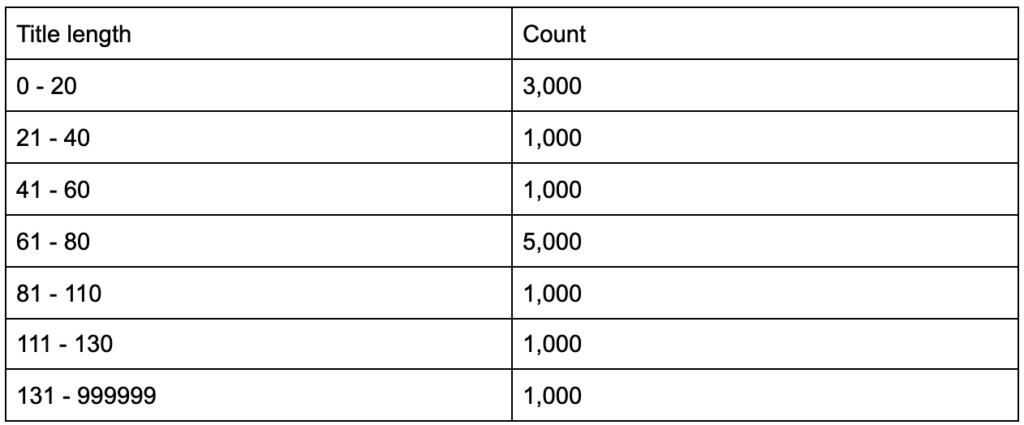
Splitting title lengths by intervals of twenty was an arbitrary decision, and you can split them the way you want. Looking at the table above, and seeing that we have three times more than the average titles in the interval (0, 20), we might want to split it further to better understand what is going on.
Having a better view than the default single-statistic summaries that we get from standard tools, allows us to employ different strategies for different lengths. For example, we can remove the brand name from the titles that are longer than a certain number of characters, and keep it in other titles.
This was an example of very simple insights, which are possible due to the flexibility we get by using a programming language, and a set of data science tools. This also allows us to iterate and modify our approach, until we find a satisfactory point that can take our analysis to the next steps.
Visualization, machine learning, modeling and general data manipulation skills allow us to get better insights on our data, even though those analyses are typically done only once. Still, if you use code to get those insights, you can always take some parts and apply to other projects, or again to the same project. In this case, the insights we got, helped us in our automation, even more. The insights would tell us what needs to be automated and what doesn't.
Should you learn Python?
Is a useless question, and the more useful one is, “How much Python (or R) should you learn?”
My view of how we use computers has evolved in the last few years.
I used to think that there were two main ways of using computers, either you are a regular user, using “point-and-click” applications to do certain tasks, or you are a developer who creates those applications that the rest of us use.

I then realized that it is more like a continuum between very high level use (pizza ordering approach), and the lower levels of the farm approach. I also realized that there is a happy sweet spot in between, where you learn enough programming to get productive and boost your data analysis skills, without having to become a software developer or engineer.
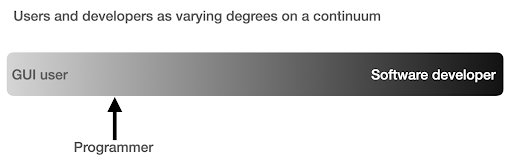
What are the main differences between being a programmer (a software user), and a software developer (or engineer)?
What are the differences between making a great coffee at home, versus establishing and running a cafe?
If making good coffee is one skill, then running a cafe requires ten other skills, most of which have nothing to do with making coffee.
You have to choose a good location (real estate), hire people (management and HR), manage cash flow and finances (accounting and finance), do marketing, legal, manage delivery, adhere to cleanliness and health standards, and so on. You can be a great coffee maker without knowing anything about those fields, but if you want to take it to the next level, you will have to manage all those additional tasks unrelated to making coffee.
The same applies to being a good programmer or data analyst versus being a software developer/engineer. There are so many other things that you have to know and worry about that you don't need as a regular programmer doing stuff for yourself and co-workers and clients. Once you have enough knowledge and skills in programming and data science, you will be in a good position to choose and decide whether you want to continue as an analyst, focusing on data science, or if you want to end up creating software that other people would use.
How do I get into Data Science?
To learn anything I think you have to do two things in parallel:
- Learn the fundamentals and the theory properly: Taking courses and reading books, and getting into the fundamentals can push you forward, as you will be gaining in weeks, knowledge that took decades to establish. It would also immediately give you ideas on things you thought were impossible, or had no idea existed.
- Get as much real world exposure and experience as possible: Experience is always important, and my suggestion is to try as soon as you can to read_csv with Python or R, to actually do so with your GA, GSC, or crawl dataset. See what else you can do (visualize, manipulate, model, etc.). See if you get errors, try to analyze the data only using your programming language.
What does frustration look like, and by when will I get productive?
It's difficult to say, and it depends on your skill, background, the hours you put in, but visualizing it like this might help you on those frustrating unproductive days:
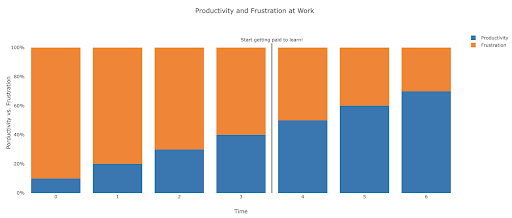
My suggestion is to take a non-trivial task, for example running an SEO audit for a site, only using Python. Your first session will mostly be frustrating, and most of the time will be spent checking documentation, and the definition of basic terms.
In parallel, you are still going through your course, and learning new stuff.
The value of that frustrating session is that it informs and motivates your theoretical learning. You will have questions in mind, and when you learn new things, you will immediately have a place to implement them.
Your next analysis session will probably be a little more productive, but still not productive enough to do at work. You go again to your learning and theory.
Do this enough times, and your time will become mostly productive, eventually you will be doing real work during working hours. The ideal scenario is where you are productive enough to do work, but every time use some time to research better techniques, which improves your work as well. By then you will start to get paid for learning, and your clients will be happily sponsoring you!
Suggested next steps
For the learning path a Data Science course would be great, especially if you get feedback on your work, and you can follow the topics in the order recommended.
If you go with Python I suggest the following libraries:
- pandas: The workhorse of all your tasks in preparing, cleaning, reshaping data whichever way you want. Fluency in pandas allows you to have full control over your data, which will help you immensely in visualization, general analysis, and machine learning
- Plotly and Dash: This is my favorite data visualization library, although there are many others. What I mostly like about it, is that it produces interactive and responsive HTML charts by default. It is very detailed and thorough in its options, yet simple to use. Plotly also includes Plotly Express, which is a high-level plotting tool, which is more intuitive to use, and takes a data-oriented approach (as opposed to a chart-oriented approach). Plotly also created Dash, which is the tool for creating interactive dashboards, but also serves as a full front-end web development framework. Other important data visualization libraries are matplotlib, altair, and bokeh, and for interactive data apps, there is panel and streamlit. Another important feature is that Plotly and Dash are available in all languages used in Data Science. You might use other libraries, and this is just my personal preference. Speaking of personal preferences:
- advertools: This is a library that I created to provide various online marketing tools, most importantly, an SEO crawler, log file parser and compressor, multi robots.txt parser, recursive sitemap parser, SEM keyword and text ad generator for large scale campaigns, weighted frequency word counter, Google SERP downloader, YouTube data API, and a few other tools. It is still evolving, and you are more than welcome to contribute any suggestions, bugs, or issues you might have with it.
These should be enough for beginners, and when you are familiar with them, you can do your own research for more specialized libraries, machine learning and deep learning tools, or libraries that are specialized in performance, or a special niche use-case.