
SEOとデジタルマーケティングのためのデータサイエンス:初心者向けの推奨ガイド
公開: 2021-12-07私たちの仕事のほとんどはデータを中心に展開しており、データサイエンスの分野がはるかに大きくなり、初心者にとってはるかにアクセスしやすくなっているので、SEOとマーケティングを強化するためにこの分野に入る方法についていくつかの考えを共有したいと思います一般的なスキル。
データの科学とは何ですか?
この分野の概要を説明するために使用される非常によく知られている図は、統計、ハッキング(一般に高度なプログラミングスキルであり、必ずしもネットワークに侵入して害を及ぼすとは限らない)、および実質的な交差点としてデータサイエンスを示すDrewConwayのベン図です。専門知識または「ドメイン知識」:
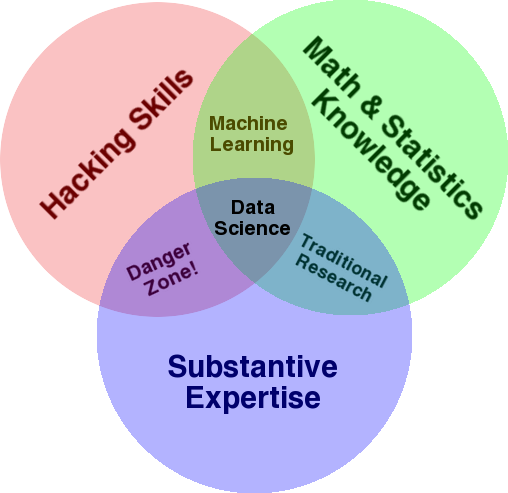
出典:oreilly.com
私が学び始めたとき、私はすぐにこれがまさに私たちがすでに行っていることであることに気づきました。 唯一の違いは、私がより基本的な手動ツールでそれを行っていたことです。
この図を見ると、おそらくすでにこれをどのように行っているかが簡単にわかります。 コンピューター(ハッキングスキル)を使用して、データ(統計)を分析し、SEO(またはあなたが焦点を当てている専門知識)の実質的な専門知識を使用して実際の問題を解決します。
現在の「プログラミング言語」はおそらくスプレッドシート(Excel、Googleスプレッドシートなど)であり、アイデアを伝えるためにPowerpointなどを使用している可能性があります。 これらの要素を少し拡張してみましょう。
- ドメイン知識:あなたはすでにあなたの専門分野について知っているので、あなたの主な強みから始めましょう。 これはデータサイエンティストであるための重要な部分であり、知識を構築して保護できる場所であることに注意してください。 数か月前、友人とクロールデータセットの分析について話し合っていました。 彼は物理学者であり、量子コンピューターの博士研究員です。 彼の数学と統計の知識とスキルは私のものをはるかに超えており、彼は私よりもはるかに優れたデータ分析方法を本当に知っています。 1つの問題。 彼は「404」が何であるか(またはなぜ「301」を気にするのか)を知りませんでした。 そのため、彼は数学の知識をすべて持っていたため、クロールデータセットの「ステータス」列を理解できませんでした。 当然のことながら、彼はそのデータをどう処理するか、誰と話すか、そしてそれらのステータスコードに基づいてどのような戦略を構築するか(または他の場所を探すかどうか)を知りません。 あなたと私は彼らをどうするかを知っています、あるいは少なくとも私たちがもっと深く掘り下げたいのなら他にどこを見るべきかを知っています。
- 数学と統計: Excelを使用してデータのサンプルの平均を取得する場合は、統計を使用しています。 平均は、データのサンプルの特定の側面を説明する統計です。 より高度な統計は、データを理解するのに役立ちます。 これも不可欠であり、私はこの分野の専門家ではありません。 よく知っている統計分布が多ければ多いほど、データの分析方法についてより多くのアイデアが得られます。 知っている基本的なトピックが多ければ多いほど、仮説を立て、データセットについて正確なステートメントを作成することができます。
- プログラミングスキル:これについては以下で詳しく説明しますが、主にこれは、使いやすいがわずかに制限されていることに固執するのではなく、コンピューターに実行したいことを正確に実行するように指示する柔軟性を構築する場所です。ツール。 これは、データを取得、再形成、およびクリーンアップするための主な方法であり、データとの自由で柔軟な「会話」を行うための道を開きます。
次に、データサイエンスで通常行うことを見てみましょう。
データサイエンスサイクル
典型的なデータサイエンスプロジェクトまたはタスクでさえ、通常は次のようになります。
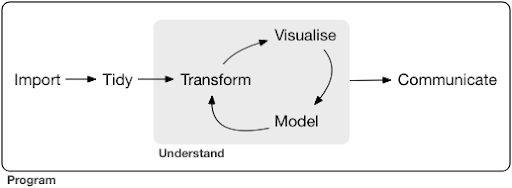
出典:r4ds.had.co.nz
また、ハドリーウィッカムとギャレットグロレムンドによるこの本を読むことを強くお勧めします。これは、データサイエンスの優れた入門書として役立ちます。 Rプログラミング言語の例で書かれていますが、Pythonだけを知っていれば概念やコードを簡単に理解できます。
図からわかるように、最初にデータをインポートして整理し、次に変換、視覚化、モデル化の内部サイクルの作業を開始する必要があります。 その後、結果を他の人に伝えます。
これらの手順は、非常に単純なものから非常に複雑なものまでさまざまです。 たとえば、「インポート」の手順は、CSVファイルを読み取るのと同じくらい簡単な場合があり、場合によっては、データを取得するための非常に複雑なWebスクレイピングプロジェクトで構成される場合があります。 プロセスの要素のいくつかは、それ自体が本格的な専門分野です。
これは、私たちが知っているいくつかのよく知られたプロセスに簡単にマッピングできます。 たとえば、robots.txtとXMLサイトマップをダウンロードして、Webサイトに関するメタデータを取得することから始めることができます。 次に、クロールして、SERP位置に関するデータや、リンクデータなどを取得する可能性があります。 いくつかのデータセットができたので、おそらくいくつかのテーブルをマージし、いくつかの追加データを代入して、調査/理解を開始する必要があります。 データを視覚化すると、隠れたパターンが明らかになったり、何が起こっているのかを理解したり、さらに多くの質問を提起したりするのに役立ちます。 また、いくつかの基本的な統計または機械学習モデルを使用してデータをモデル化し、うまくいけばいくつかの洞察を得たいと思うでしょう。 もちろん、調査結果や質問をプロジェクトの他の利害関係者に伝える必要があります。
これらの各プロセスで使用できるさまざまなツールに精通したら、特定のWebサイトに固有の独自のカスタムパイプラインの構築を開始できます。これは、すべてのビジネスが固有であり、特別な要件が設定されているためです。 最終的には、パターンを見つけ始め、同様のプロジェクト/Webサイトの作業全体をやり直す必要がなくなります。
このプロセスの各要素で利用できるツールとライブラリは多数あり、どのツールを選択するか(そして学習に時間を費やすか)、非常に圧倒される可能性があります。 使用するツールを選択する際に役立つと思われるアプローチを見てみましょう。
ツールの選択とトレードオフ(ピザを食べる3つの方法)
データ処理の日常業務にExcelを使用する必要がありますか、それともPythonを学ぶのに苦労する価値がありますか?
Power BIのようなもので視覚化する方が良いですか、それともグラフィックスの文法について学び、それを実装するライブラリの使用方法を学ぶことに投資する必要がありますか?
RまたはPythonを使用して独自のインタラクティブなダッシュボードを作成することで、より良い作品を作成できますか、それともGoogle Data Studioを使用するだけですか?
まず、さまざまな抽象化レベルでさまざまなツールを選択する際のトレードオフについて説明します。 これは、PlotlyとDashを使用したインタラクティブなダッシュボードとデータアプリの構築に関する私の本からの抜粋であり、このアプローチが役立つと思います。
ピザを食べるための3つの異なるアプローチを考えてみましょう。
- 注文方法:レストランに電話してピザを注文します。 30分で玄関先に到着し、食べ始めます。
- スーパーマーケットのアプローチ:スーパーマーケットに行き、生地、チーズ、野菜、その他すべての材料を購入します。 次に、自分でピザを作ります。
- 農場のアプローチ:あなたは裏庭でトマトを栽培します。 牛を飼育し、搾乳し、牛乳をチーズに変換します。
順序付けのアプローチに向けて、より高いレベルのインターフェースに進むにつれて、必要な知識の量は大幅に減少します。 他の誰かが責任を負い、品質は評判と競争の市場の力によってチェックされます。
これに対して私たちが支払う代償は、自由とオプションの減少です。 各レストランには選択可能なオプションのセットがあり、それらのオプションから選択する必要があります。
より低いレベルに下がると、必要な知識の量が増え、より複雑な処理を行う必要があり、結果に対してより多くの責任を負い、はるかに多くの時間がかかります。 ここで得られるのは、結果を希望どおりにカスタマイズするためのはるかに多くの自由と力です。 コストも大きなメリットですが、それは十分な規模にすぎません。 今日ピザを食べたいだけなら、注文する方がおそらく安いでしょう。 しかし、毎日1つ持つことを計画している場合は、自分で行うと大幅なコスト削減が期待できます。
これらは、使用および学習するツールを選択するときに行う必要のある種類の選択です。 RやPythonなどのプログラミング言語を使用するには、はるかに多くの作業が必要であり、Excelよりも困難であり、生産性と強力性が大幅に向上します。
選択は、各ツールまたはプロセスにとっても重要です。 たとえば、高レベルで使いやすいクローラーを使用してWebサイトに関するデータを収集しても、プログラミング言語を使用してデータを視覚化し、使用可能なすべてのオプションを使用したい場合があります。 適切なプロセスに適切なツールを選択するかどうかはニーズによって異なり、上記のトレードオフがこの選択に役立つことを願っています。 これは、PythonまたはRを学習したいかどうか(またはどれだけ)の問題に対処するのにも役立つことを願っています。
この質問をもう少し進めて、SEOのためのPythonの学習が適切なキーワードではない理由を見てみましょう。
「pythonforseo」が誤解を招く理由
あなたは素晴らしいブロガーになりたいですか、それともWordPressを学びたいですか?
グラフィックデザイナーになりたいですか、それともPhotoshopを学ぶことを目標としていますか?
データスキルを次のレベルに引き上げることでSEOのキャリアを高めることに興味がありますか、それともPythonを学びたいですか?
マサチューセッツ工科大学のコンピュータサイエンスコースの最初の講義の最初の5分間で、ハロルドアベルソン教授は、「コンピュータサイエンス」が、これから学ぼうとしている分野の悪い名前である理由を生徒に説明して、コースを開始します。 講義の最初の5分間を見るのは非常に興味深いと思います。
ある分野が始まったばかりで、それをよく理解していない場合、あなたがしていることの本質をあなたが使っているツールと混同するのは非常に簡単です。 –ハロルド・アベルソン
私たちはオンラインでの存在感と結果を改善しようとしています。私たちが行うことの多くは、データ全般の理解、視覚化、操作、処理に基づいており、使用するツールに関係なく、これが私たちの焦点です。 データサイエンスは、それを行うための知的フレームワークと、私たちがやりたいことを実装するための多くのツールを備えた分野です。 Pythonはあなたが選択するプログラミング言語(ツール)かもしれません、そしてそれをよく学ぶことは間違いなく重要です。 私たちの場合、データの処理と分析という「あなたがしていることの本質」に焦点を当てることも、もっと重要ではないにしても、同じくらい重要です。
主な焦点は、選択したプログラミング言語ではなく、上記で説明したプロセス(インポート、整理、視覚化など)にある必要があります。 または、単にプログラミング言語を学ぶのではなく、そのプログラミング言語を使用してタスクを実行する方法をお勧めします。
とにかくPythonを学ぶつもりなら、誰がこれらすべての理論上の違いを気にしますか?
あなたがしていることの本質ではなく、ツールについて学ぶことに焦点を合わせた場合に何が起こるかを見てみましょう。 ここでは、「ワードプレスを学ぶ」(ツール)と「ブログを学ぶ」(やりたいこと)の検索を比較します。
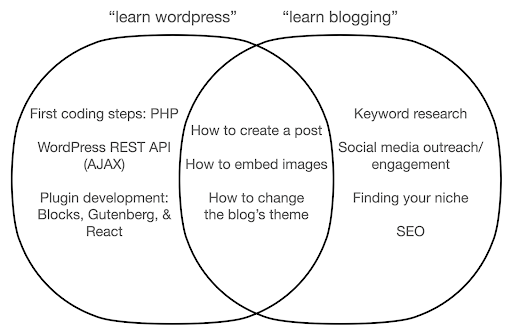
この図は、上部のキーワードについて教える本またはコースの下で考えられるトピックを示しています。 中央の交差点は、両方のタイプのコース/本で発生する可能性のあるトピックを示しています。
ツールに集中すると、特に初心者として、本当に必要のないことについて学ぶ必要があることは間違いありません。 これらのトピックは、特に技術的またはプログラミングのバックグラウンドがない場合、混乱してイライラする可能性があります。
また、優れたブロガーになるために役立つこと(交差点エリアのトピック)についても学びます。 これらのトピックは非常に簡単に教えることができますが(ブログ投稿の作成方法)、ブログを作成する理由、時期、内容についてはあまり説明していません。 これはツールに焦点を当てた本のせいではありません。ツールについて学ぶときは、ブログ投稿の作成方法を学び、先に進むだけで十分だからです。
ブロガーとして、あなたはおそらくブログの内容と理由にもっと興味があり、それはツールに焦点を当てた本ではカバーされないでしょう。
明らかに、SEO、ニッチの発見などの戦略的で重要なことはカバーされないので、非常に重要なことを見逃してしまいます。
プログラミングの本ではおそらく学ばないであろうデータサイエンスのトピックのいくつかは何ですか?
私たちが見たように、Pythonやプログラミングの本を手に入れるということは、おそらくソフトウェアエンジニアになりたいということを意味します。 トピックは当然その目的に向けられます。 データサイエンスの本を探すと、データの分析に適したトピックやツールを入手できます。
最初の図(データサイエンスのサイクルを示す)をガイドとして使用し、「pythonでデータをインポートする」、「rでデータを整理する」、「pythonでデータを視覚化する」などのトピックを積極的に検索できます。 これらのトピックを詳しく見て、さらに詳しく見ていきましょう。
輸入
当然、最初にいくつかのデータを取得する必要があります。 これは次のようになります。
- コンピューター上のファイル:選択したプログラミング言語でファイルを開くだけの最も簡単なケース。 多くの異なるファイル形式があり、ファイルを開いたり読んだりするときに多くのオプションがあることに注意することが重要です。 たとえば、pandasライブラリ(Pythonの必須データ操作ツール)のread_csv関数には、ファイルを開くときに選択できる50のオプションがあります。 これには、ファイルパス、選択する列、開く行数、日時オブジェクトの解釈、欠落値の処理方法などが含まれます。 これらのオプションと、さまざまなファイル形式を開く際のさまざまな考慮事項に精通していることが重要です。 さらに、パンダには、さまざまなファイルおよびデータ形式のread_で始まる19の異なる関数があります。
- オンラインツールからのエクスポート:おそらくこれに精通しているでしょう。ここでデータをカスタマイズしてエクスポートし、その後、コンピューター上でファイルとして開くことができます。
- 特定のデータを取得するためのAPI呼び出し:これは下位レベルであり、上記のファームアプローチに近いものです。 この場合、特定の要件を含むリクエストを送信し、必要なデータを取得します。 ここでの利点は、取得したいものを正確にカスタマイズし、オンラインインターフェイスでは利用できない方法でフォーマットできることです。 たとえば、Google Analyticsでは、分析しているテーブルに2番目のディメンションを追加できますが、3番目のディメンションを追加することはできません。 また、エクスポートできる行数によっても制限されます。 APIを使用すると、柔軟性が向上します。また、より大規模なデータ収集/分析パイプラインの一部として、定期的に発生する特定の呼び出しを自動化できます。
- データのクロールとスクレイピング:おそらくお気に入りのクローラーがあり、プロセスに精通している可能性があります。 これはすでに柔軟なプロセスであり、ページからカスタム要素を抽出したり、特定のページのみをクロールしたりすることができます。
- 自動化、カスタム抽出、場合によっては特別な用途のための機械学習を含む方法の組み合わせ。
データを取得したら、次のレベルに進みます。
几帳面
「整頓された」データセットは、特定の方法で編成されたデータセットです。 「ロングフォーマット」データとも呼ばれます。 R for Data Scienceの本の第12章では、興味がある場合は、TidyDataの概念について詳しく説明しています。
以下の3つの表を見て、違いを見つけてください。
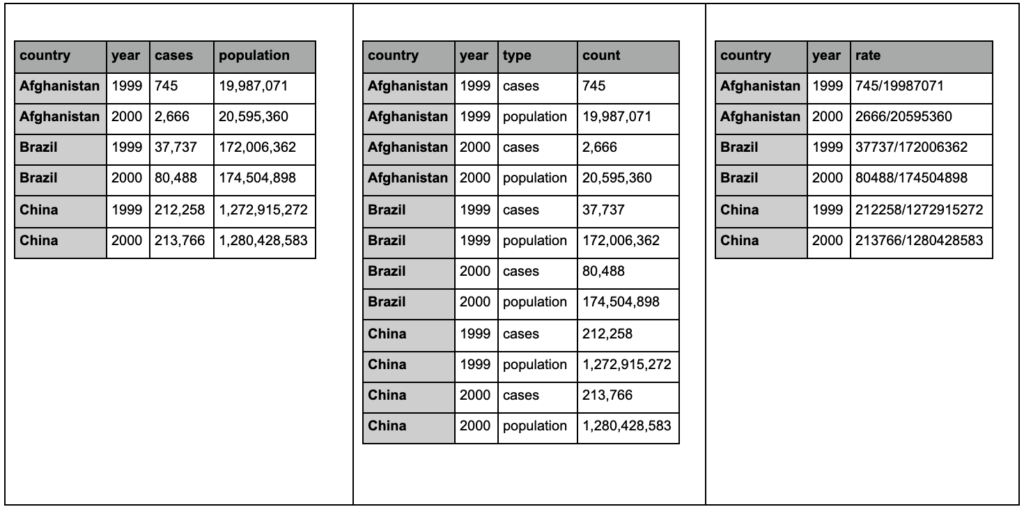
tidyrパッケージのサンプルテーブル。
3つのテーブルにはまったく同じ情報が含まれていますが、さまざまな方法で整理および表示されていることがわかります。 ケースと母集団を2つの別々の列(表1)に含めるか、観測値(ケースまたは母集団)を示す列と、それらのケースをカウントする「カウント」列(表2)を含めることができます。 表3では、それらはレートとして示されています。
データを処理する場合、ソースが異なればデータの編成も異なり、分析をより適切かつ容易にするために、特定の形式から/への変更が必要になることがよくあります。 これらのクリーニング操作に精通することは非常に重要であり、Rのtidyrパッケージにはそのための特別なツールが含まれています。 Pythonが必要な場合は、パンダを使用することもできます。そのためのメルト関数とピボット関数を確認できます。
データが特定の形式になったら、さらに操作したい場合があります。
変身
構築するもう1つの重要なスキルは、操作しているデータに必要な変更を加える機能です。 理想的なシナリオは、データと会話できる段階に到達し、非常に具体的な質問をしたい方法を切り分けて、興味深い洞察を得ることができるようにすることです。 興味があるかもしれないいくつかの例のタスクであなたがたぶんたくさん必要とするであろう最も重要な変換タスクのいくつかはここにあります:
データを取得し、整理し、目的の形式にした後、それを視覚化するとよいでしょう。
視覚化
データの視覚化は大規模なトピックであり、そのサブトピックのいくつかに関する本があります。 これは、特に直感的な視覚要素を使用して情報を伝達することで、データに関する多くの洞察を提供できるものの1つです。 棒グラフの棒の相対的な高さは、たとえば相対的な量をすぐに示します。 色の濃さ、相対的な位置、および他の多くの視覚的属性は、読者が容易に認識および理解できます。
良いチャートは千(キーワード)の言葉の価値があります!
データの視覚化については多くのトピックがありますので、興味深い例をいくつか紹介します。 完全な詳細が必要な場合、それらのいくつかは、この貧困データダッシュボードの構成要素です。
値を比較するために必要なのは、単純な棒グラフだけである場合があります。棒は垂直または水平に表示できます。
特定の国を探索し、特定の国が特定の指標でどのように進んでいるかを確認することで、さらに深く掘り下げることに興味があるかもしれません。 この場合、同じプロットに複数の棒グラフを表示したい場合があります。
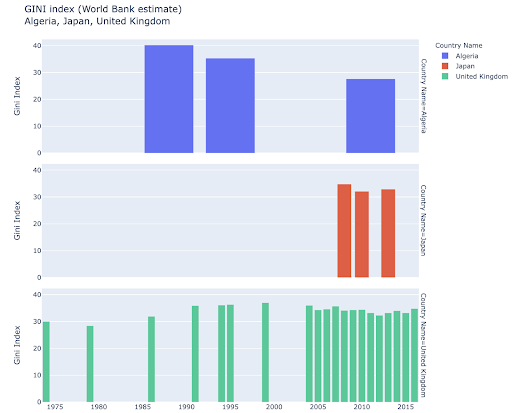
複数の観測値の複数の値を比較するには、各X軸の位置に複数のバーを配置することもできます。これを行う主な方法は次のとおりです。
色とカラースケールの選択:データの視覚化の重要な部分であり、正しく実行されれば非常に効率的かつ直感的に情報を伝達できるものです。
カテゴリカラースケール:カテゴリデータを表現するのに便利です。 名前が示すように、これは特定の観測値がどのカテゴリに属するかを示すデータのタイプです。 この場合、カテゴリの明確な違いを示すために、できるだけ互いに異なる色が必要です(特に、隣り合って表示される視覚要素の場合)。
次の例では、カテゴリ別のカラースケールを使用して、各国でどの政府システムが実装されているかを示しています。 国の色を、どの政府システムが使用されているかを示す伝説に結び付けるのは非常に簡単です。 これは、コロプレスマップとも呼ばれます。
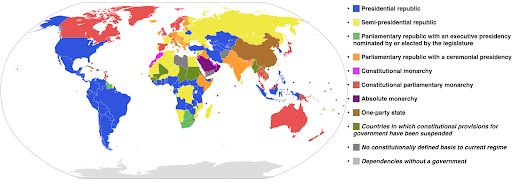
出典:ウィキペディア
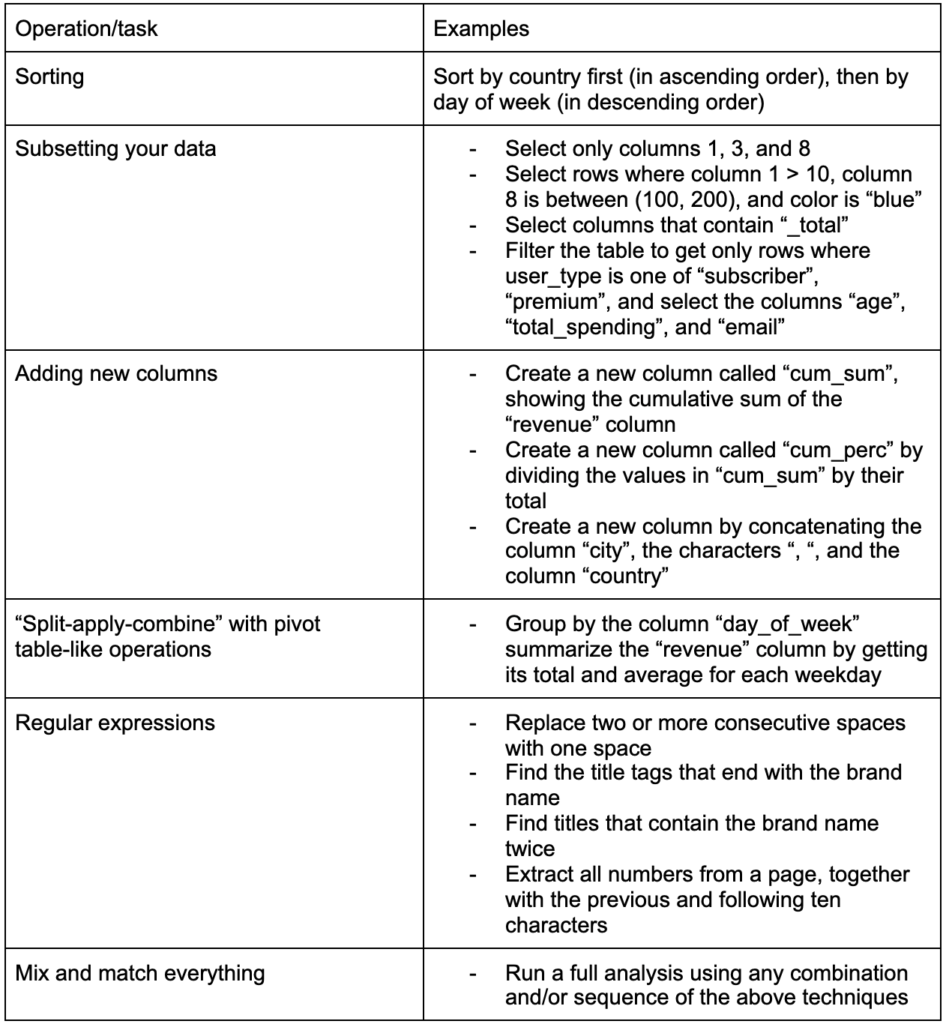
視覚化するデータが同じメトリックのものであり、各国(または他のタイプの観測)が最小ポイントと最大ポイントの間の連続体の特定のポイントに該当する場合があります。 言い換えれば、そのメトリックの程度を視覚化する必要があります。
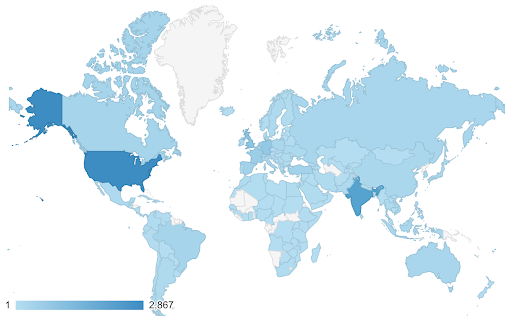
このような場合、連続(または順次)カラースケールを見つける必要があります。 次の例では、どの国がより青い(したがってより多くのトラフィックを得る)かがすぐにわかり、国間の微妙な違いを直感的に理解できます。
データは連続している可能性がありますが(上記の交通マップチャートのように)、数値について重要なことは、特定のポイントからどれだけ離れているかということです。 この場合、発散するカラースケールが役立ちます。
下のグラフは、純人口増加率を示しています。 この場合、ある国の成長率がプラスかマイナスかを最初に知るのは興味深いことです。 または、各国がゼロからどれだけ離れているか(そしてどれだけ)を知りたいのです。 地図を見ると、どの国の人口が増え、どの国が減っているのかがすぐにわかります。 凡例は、最大陽性率が3.5%であり、最大陰性率が-0.5%であることも示しています。 これにより、値の範囲(正と負)もわかります。
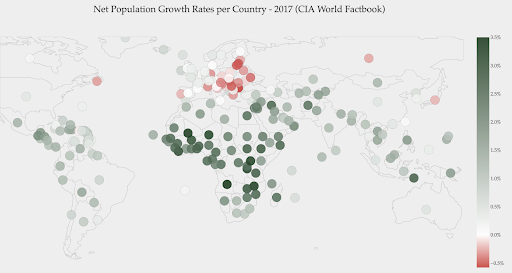
出典:Dashboardom.com
残念ながら、色覚異常の人は赤と緑を適切に区別できない可能性があるため、このスケールに選択された色は理想的ではありません。 これは、カラースケールを選択する際の非常に重要な考慮事項です。
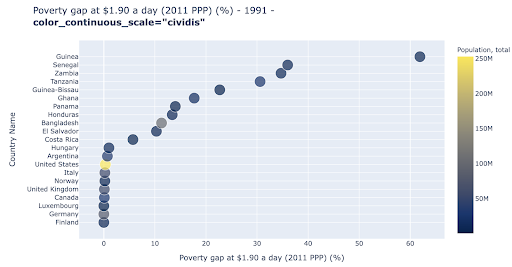
散布図は、最も広く使用されている、用途の広いプロットタイプの1つです。 ドット(または他のマーカー)の位置は、私たちが伝えようとしている量を伝えます。 位置に加えて、色、サイズ、形状などの他のいくつかの視覚的属性を使用して、さらに多くの情報を伝達できます。 次の例は、1日あたり1.9ドルで生活している人口の割合を示しています。これは、ポイントの水平距離として明確に確認できます。
色を使用して、グラフに新しいディメンションを追加することもできます。 これは、同じデータセットの3番目の列を視覚化することに対応します。この場合、人口データが表示されます。
人口(米国)の観点から最も極端なケースは、貧困レベルの指標では非常に低いことがわかります。 これにより、チャートに豊かさが加わります。 サイズと形状を使用して、データセットからさらに多くの列を視覚化することもできます。 ただし、豊かさと読みやすさのバランスをとる必要があります。
人口と貧困レベルの間に関係があるかどうかを確認することに興味があるかもしれません。そのため、同じデータセットをわずかに異なる方法で視覚化して、そのような関係が存在するかどうかを確認できます。
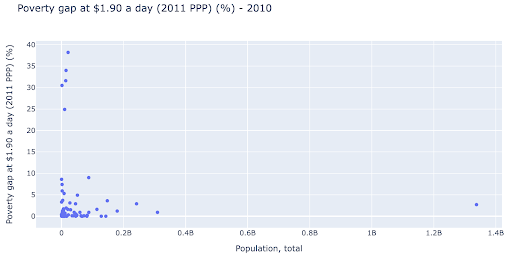
人口の外れ値は約1.35億であり、これはグラフに多くの空白があることを意味します。これは、非常に小さな領域で多くの値が絞り込まれていることも意味します。 また、ドットが重なっているため、違いや傾向を見つけるのが非常に困難です。
次のグラフには同じ情報が含まれていますが、2つの手法を使用して視覚化が異なります。
- 対数目盛:通常、データは加法目盛で表示されます。 つまり、軸上のすべてのポイント(XまたはY)は、視覚化された特定の量のデータの追加を表します。 乗法スケールを使用することもできます。その場合、X軸上の新しいポイントごとに乗算します(この例では10倍)。 これにより、ポイントを分散させることができ、前のグラフのように、加算ではなく倍数を考える必要があります。
- 別のマーカーの使用(大きな空の円) :マーカーに別の形状を選択すると、同じ場所に複数のポイントが重なる可能性がある「オーバープロット」の問題が解決され、見づらくなります。ポイントはいくつありますか。
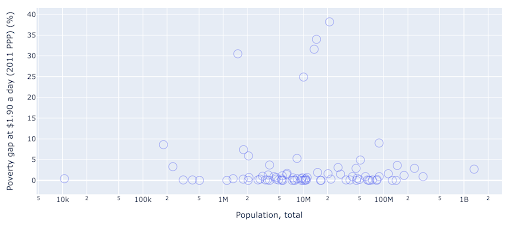
これで、1,000万マーク付近に国のクラスターがあり、他の小さなクラスターもあることがわかります。
私が述べたように、文字と視覚化オプションの多くのタイプがあり、主題について書かれた本全体があります。 これにより、実験するための興味深い考えがいくつか得られることを願っています。
オンクロールデータ³
 もっと詳しく知る
もっと詳しく知るモデル
データを単純化し、パターンを見つけたり、予測を行ったり、単にデータをよりよく理解したりする必要があります。 これは別の大きなトピックであり、単純に要約統計量(平均、中央値、標準偏差など)を取得することから、傾向を要約または検出するモデルを使用してデータを視覚的にモデル化すること、より複雑な手法を使用してデータの数式。 また、機械学習を使用して、データ内のより多くの洞察を明らかにすることができます。
繰り返しになりますが、これはトピックの完全な説明ではありませんが、いくつかの機械学習手法を使用して支援できるいくつかの例を共有したいと思います。

クロールデータセットで、私は404ページについてもう少し学び、それらについて何かを発見できるかどうかを調べようとしていました。 私の最初の試みは、ページのサイズとそのステータスコードの間に相関関係があるかどうかを確認することでしたが、ほぼ完全な相関関係がありました。
私は数分間天才のように感じ、すぐに地球に戻ってきました。
404ページはすべて非常に狭い範囲のページサイズであり、特定のキロバイト数のほとんどすべてのページに404ステータスコードがありました。 それから私は、定義上、404ページには「404エラーページ」以外のコンテンツが含まれていないことに気付きました。 そしてそれが彼らが同じサイズを持っていた理由です。
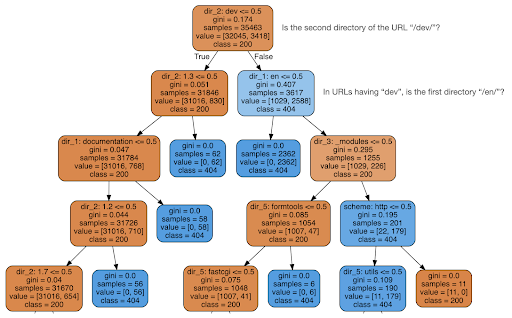
次に、コンテンツがステータスコードについて何かを教えてくれるかどうかを確認することにしました。そこで、URLを要素に分割し、sklearnを使用して決定木分類子を実行しました。 これは基本的に決定木を生成する手法であり、そのルールに従うことで、ターゲット(この場合は404ページ)を見つける方法を学ぶことができます。
次の決定木では、各ボックスの最初の行は従うかチェックするルールを示し、「サンプル」行はこのボックスで見つかった観測値の数であり、「クラス」行は現在の観測値のクラスを示します、この場合、ステータスコードが200または404であるかどうか。
詳細については説明しません。ディシジョンツリーに精通していないと、デシジョンツリーが明確にならない可能性があることを知っています。興味がある場合は、生のクロールデータセットと分析コードを調べることができます。
基本的に、決定木が見つけたのは、URLのディレクトリ構造を使用して、ほぼすべての404ページを見つける方法でした。 ご覧のとおり、URLの2番目のディレクトリが「/ dev /」(上から2行目の最初の水色のボックス)であるかどうかを確認するだけで、3,617個のURLが見つかりました。 これで、404の場所を特定する方法がわかりました。これらは、ほとんどすべてサイトの「/dev/」セクションにあるようです。 これは間違いなく大幅な時間の節約になりました。 このルールを見つけるために、考えられるすべてのURL構造と組み合わせを手動で調べることを想像してみてください。
まだ全体像とこれが起こっている理由はわかりません。これはさらに追求することができますが、少なくともこれらのURLを非常に簡単に見つけることができました。
使用する可能性のあるもう1つの手法は、データポイントをさまざまなグループ/クラスターにグループ化するKMeansクラスタリングです。 これは「教師なし学習」手法であり、アルゴリズムは、存在することを知らなかったパターンを発見するのに役立ちます。
たくさんの数字があり、たとえば国の人口があり、それらを大小の2つのグループにグループ化したいとします。 どのようにそれをしますか? どこに線を引きますか?
これは、上位10か国、または上位X%の国を取得することとは異なります。 これは非常に簡単です。人口で国を並べ替えて、必要に応じて上位Xか国を取得できます。
私たちが望んでいるのは、このデータセットに対して「大」と「小」にグループ化し、国の人口について何も知らないと仮定することです。
これはさらに、国を小、中、大の3つのカテゴリに分類しようとすることに拡張できます。 5つ、6つ、またはそれ以上のグループが必要な場合、これを手動で行うのははるかに困難になります。
上位Xか国を求めていないため、各グループにいくつの国が含まれるかわからないことに注意してください。 2つのクラスターにグループ化すると、大きなグループには中国とインドの2か国しかないことがわかります。 これら2つの国の平均人口は他のすべての国とはかけ離れているため、これは直感的に理解できます。 この国のグループには独自の平均があり、その国は他のグループの国よりも互いに近いです。
人口によって2つのグループにクラスター化された国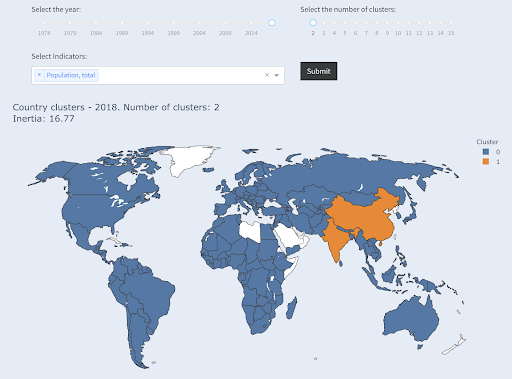
人口で3番目に大きい国(米国〜3億3000万)は、人口が100万人の国を含む他のすべての国とグループ化されました。 これは、330Mが13億よりも100万にはるかに近いためです。 3つのクラスターを要求した場合、別の画像が得られたはずです。
人口によって3つのグループにクラスター化された国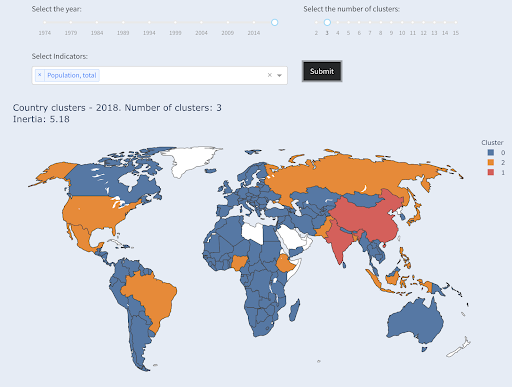
そして、これは、4つのクラスターを要求した場合に国がクラスター化される方法です。
人口によって4つのグループにクラスター化された国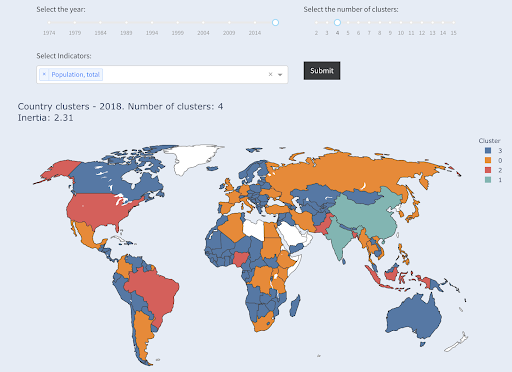
出典:povertydata.org(「クラスター国」タブ)
これは、この場合は1つのディメンション(人口)のみを使用したクラスタリングでした。さらにディメンションを追加して、国がどこに到達するかを確認することもできます。
他にも多くのテクニックやツールがありますが、これらは、興味深く実用的な例のほんの一例です。
これで、調査結果を聴衆に伝える準備が整いました。
伝える
前のステップで行ったすべての作業の後、最終的には、調査結果を他のプロジェクトの利害関係者に伝達する必要があります。
データサイエンスで最も重要なツールの1つは、インタラクティブなノートブックです。 Jupyterノートブックは最も広く使用されており、ほとんどすべてのプログラミング言語をサポートしています。同じように機能するRStudioの特別なノートブック形式を使用することをお勧めします。
主なアイデアは、データ、コード、ナラティブ、および視覚化を1つの場所にまとめて、他の人がそれらを監査できるようにすることです。 透明性と再現性に関するこれらの結論と推奨事項にどのように到達したかを示すことが重要です。 他の人も同じコードを実行して同じ結果を得ることができるはずです。
もう1つの重要な理由は、「将来のあなた」を含む他の人が分析をさらに進め、あなたが行った最初の作業に基づいて、それを改善し、新しい方法で拡張する能力です。
もちろん、これは、聴衆がコードに慣れていて、それを気にかけていることを前提としています。
また、コードを除いてノートブックをHTML(および他のいくつかの形式)にエクスポートするオプションもあるため、ユーザーフレンドリーなレポートが作成され、同じ分析と結果を再現するために完全なコードを保持できます。
コミュニケーションの重要な要素はデータの視覚化です。これについても上記で簡単に説明しました。
さらに優れているのは、インタラクティブなデータの視覚化です。この場合、オーディエンスが値を選択し、グラフとメトリックのさまざまな組み合わせをチェックして、データをさらに詳しく調べることができます。
何ができるかについてのアイデアを提供するために私が作成したダッシュボードとデータアプリ(ロードに数秒かかるものもあります)を次に示します。
最終的には、特別なニーズや要件に対応するために、プロジェクト用のカスタムアプリを作成することもできます。これは、興味深いと思われるSEOおよびマーケティングアプリの別のセットです。
データサイエンスサイクルの主な手順を実行しました。次に、「Pythonの学習」のもう1つの利点について説明します。
Pythonは自動化と生産性のためのものです:本当ですが不完全です
Pythonの学習は、主に生産的なタスクや自動化されたタスクを取得するためのものであるという信念があるように思われます。
これは絶対に真実であり、手動で行うのにかかる時間の何分の1かで何かを行うことができることの価値について議論する必要すらないと思います。
議論のもう一つの欠けている部分はデータ分析です。 優れたデータ分析は私たちに洞察を提供し、理想的には私たちの専門知識と私たちが持っているデータに基づいて、意思決定プロセスを導くための実用的な洞察を提供することができます。
私たちが行うことの大部分は、何が起こっているのかを理解し、競争を分析し、最も価値のあるコンテンツがどこにあるかを把握し、何をすべきかを決定することなどです。 私たちはコンサルタント、アドバイザー、そして意思決定者です。 私たちのデータからいくつかの洞察を得ることができることは明らかに大きな利点であり、ここで言及されている分野とスキルは私たちがそれを達成するのに役立ちます。
タイトルタグの平均の長さが60文字であることを知った場合、これは良いことでしょうか。
もう少し深く掘り下げて、タイトルの半分が60をはるかに下回っていて、残りの半分にはさらに多くの文字が含まれている(平均で60になる)ことに気付いた場合はどうなりますか? In order to get practical and provide good recommendations, you need a higher-resolution view of your title tags' lengths, probably a histogram that shows the frequency of your title tag lengths at each interval so you can have a separate strategy for length. A simple table would also do, for example:
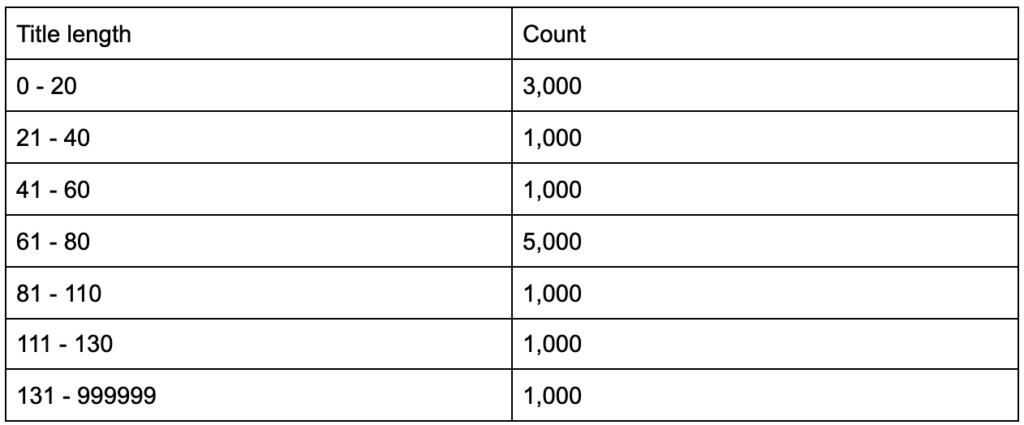
Splitting title lengths by intervals of twenty was an arbitrary decision, and you can split them the way you want. Looking at the table above, and seeing that we have three times more than the average titles in the interval (0, 20), we might want to split it further to better understand what is going on.
Having a better view than the default single-statistic summaries that we get from standard tools, allows us to employ different strategies for different lengths. For example, we can remove the brand name from the titles that are longer than a certain number of characters, and keep it in other titles.
This was an example of very simple insights, which are possible due to the flexibility we get by using a programming language, and a set of data science tools. This also allows us to iterate and modify our approach, until we find a satisfactory point that can take our analysis to the next steps.
Visualization, machine learning, modeling and general data manipulation skills allow us to get better insights on our data, even though those analyses are typically done only once. Still, if you use code to get those insights, you can always take some parts and apply to other projects, or again to the same project. In this case, the insights we got, helped us in our automation, even more. The insights would tell us what needs to be automated and what doesn't.
Should you learn Python?
Is a useless question, and the more useful one is, “How much Python (or R) should you learn?”
My view of how we use computers has evolved in the last few years.
I used to think that there were two main ways of using computers, either you are a regular user, using “point-and-click” applications to do certain tasks, or you are a developer who creates those applications that the rest of us use.

I then realized that it is more like a continuum between very high level use (pizza ordering approach), and the lower levels of the farm approach. I also realized that there is a happy sweet spot in between, where you learn enough programming to get productive and boost your data analysis skills, without having to become a software developer or engineer.
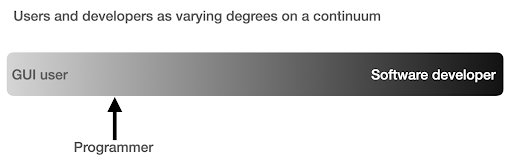
What are the main differences between being a programmer (a software user), and a software developer (or engineer)?
What are the differences between making a great coffee at home, versus establishing and running a cafe?
If making good coffee is one skill, then running a cafe requires ten other skills, most of which have nothing to do with making coffee.
You have to choose a good location (real estate), hire people (management and HR), manage cash flow and finances (accounting and finance), do marketing, legal, manage delivery, adhere to cleanliness and health standards, and so on. You can be a great coffee maker without knowing anything about those fields, but if you want to take it to the next level, you will have to manage all those additional tasks unrelated to making coffee.
The same applies to being a good programmer or data analyst versus being a software developer/engineer. There are so many other things that you have to know and worry about that you don't need as a regular programmer doing stuff for yourself and co-workers and clients. Once you have enough knowledge and skills in programming and data science, you will be in a good position to choose and decide whether you want to continue as an analyst, focusing on data science, or if you want to end up creating software that other people would use.
How do I get into Data Science?
To learn anything I think you have to do two things in parallel:
- Learn the fundamentals and the theory properly: Taking courses and reading books, and getting into the fundamentals can push you forward, as you will be gaining in weeks, knowledge that took decades to establish. It would also immediately give you ideas on things you thought were impossible, or had no idea existed.
- Get as much real world exposure and experience as possible: Experience is always important, and my suggestion is to try as soon as you can to read_csv with Python or R, to actually do so with your GA, GSC, or crawl dataset. See what else you can do (visualize, manipulate, model, etc.). See if you get errors, try to analyze the data only using your programming language.
What does frustration look like, and by when will I get productive?
It's difficult to say, and it depends on your skill, background, the hours you put in, but visualizing it like this might help you on those frustrating unproductive days:
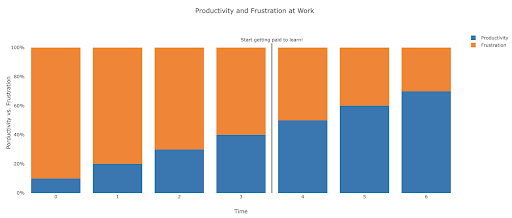
My suggestion is to take a non-trivial task, for example running an SEO audit for a site, only using Python. Your first session will mostly be frustrating, and most of the time will be spent checking documentation, and the definition of basic terms.
In parallel, you are still going through your course, and learning new stuff.
The value of that frustrating session is that it informs and motivates your theoretical learning. You will have questions in mind, and when you learn new things, you will immediately have a place to implement them.
Your next analysis session will probably be a little more productive, but still not productive enough to do at work. You go again to your learning and theory.
Do this enough times, and your time will become mostly productive, eventually you will be doing real work during working hours. The ideal scenario is where you are productive enough to do work, but every time use some time to research better techniques, which improves your work as well. By then you will start to get paid for learning, and your clients will be happily sponsoring you!
提案された次のステップ
For the learning path a Data Science course would be great, especially if you get feedback on your work, and you can follow the topics in the order recommended.
If you go with Python I suggest the following libraries:
- pandas: The workhorse of all your tasks in preparing, cleaning, reshaping data whichever way you want. Fluency in pandas allows you to have full control over your data, which will help you immensely in visualization, general analysis, and machine learning
- Plotly and Dash: This is my favorite data visualization library, although there are many others. What I mostly like about it, is that it produces interactive and responsive HTML charts by default. It is very detailed and thorough in its options, yet simple to use. Plotly also includes Plotly Express, which is a high-level plotting tool, which is more intuitive to use, and takes a data-oriented approach (as opposed to a chart-oriented approach). Plotly also created Dash, which is the tool for creating interactive dashboards, but also serves as a full front-end web development framework. Other important data visualization libraries are matplotlib, altair, and bokeh, and for interactive data apps, there is panel and streamlit. Another important feature is that Plotly and Dash are available in all languages used in Data Science. You might use other libraries, and this is just my personal preference. Speaking of personal preferences:
- advertools: This is a library that I created to provide various online marketing tools, most importantly, an SEO crawler, log file parser and compressor, multi robots.txt parser, recursive sitemap parser, SEM keyword and text ad generator for large scale campaigns, weighted frequency word counter, Google SERP downloader, YouTube data API, and a few other tools. It is still evolving, and you are more than welcome to contribute any suggestions, bugs, or issues you might have with it.
These should be enough for beginners, and when you are familiar with them, you can do your own research for more specialized libraries, machine learning and deep learning tools, or libraries that are specialized in performance, or a special niche use-case.