
SEO ve Dijital Pazarlama için Veri Bilimi: yeni başlayanlar için önerilen bir rehber
Yayınlanan: 2021-12-07Çalışmalarımızın çoğu veri etrafında döndüğünden ve Veri Bilimi alanı çok daha büyük ve yeni başlayanlar için çok daha erişilebilir hale geldiğinden, SEO ve pazarlamanızı geliştirmek için bu alana nasıl girebileceğiniz konusunda bazı düşünceleri paylaşmak istiyorum. genel olarak beceriler.
Veri bilimi nedir?
Bu alana genel bir bakış sağlamak için kullanılan çok iyi bilinen bir diyagram, Drew Conway'in Veri Bilimini istatistiklerin kesişimi, bilgisayar korsanlığı (genel olarak gelişmiş programlama becerileri ve mutlaka ağlara nüfuz etme ve zarar verme) olarak gösteren Venn şemasıdır. uzmanlık veya “alan bilgisi”:
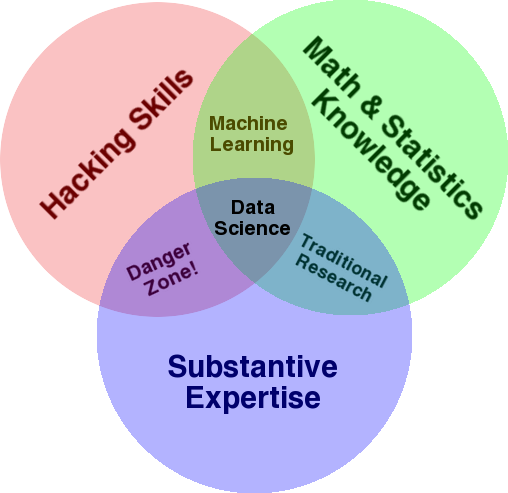
Kaynak: oreilly.com
Öğrenmeye başladığımda, bunun zaten yaptığımız şeyin tam olarak bu olduğunu hemen anladım. Tek fark, daha basit ve manuel araçlarla yapıyor olmamdı.
Şemaya bakarsanız, muhtemelen bunu zaten nasıl yaptığınızı kolayca göreceksiniz. Bir bilgisayar (hack becerileri), verileri analiz etmek (istatistikler), SEO konusundaki temel uzmanlığınızı (veya hangi uzmanlık alanına odaklanırsanız odaklanın) kullanarak pratik bir sorunu çözmek için kullanırsınız.
Mevcut "programlama diliniz" muhtemelen bir elektronik tablodur (Excel, Google E-Tablolar, vb.) ve fikirleri iletmek için büyük olasılıkla Powerpoint veya benzeri bir şey kullanıyorsunuz. Bu unsurları biraz genişletelim.
- Alan bilgisi: Uzmanlık alanınız hakkında zaten bildiğiniz gibi, ana gücünüzle başlayalım. Bunun bir veri bilimcisi olmanın önemli bir parçası olduğunu ve bilginizi geliştirebileceğiniz ve koruyabileceğiniz yerin burası olduğunu unutmayın. Birkaç ay önce, bir arkadaşımla bir tarama veri setini analiz etmeyi tartışıyordum. Kuantum bilgisayarlar üzerinde doktora sonrası araştırma yapan bir fizikçidir. Matematik ve istatistik bilgisi ve becerileri benimkinin çok ötesinde ve verileri nasıl analiz edeceğini gerçekten benden çok daha iyi biliyor. Bir problem. "404"ün ne olduğunu (ya da "301"i neden umursadığımızı) bilmiyordu. Bu nedenle, tüm matematik bilgisi ile tarama veri kümesindeki "durum" sütununu anlamlandıramadı. Doğal olarak, bu verilerle ne yapacağını, kiminle konuşacağını ve bu durum kodlarına dayalı olarak hangi stratejileri oluşturacağını (veya başka bir yere bakıp bakmayacağını) bilemezdi. Sen ve ben onlarla ne yapacağımızı biliyoruz ya da en azından daha derine inmek istiyorsak başka nereye bakacağımızı biliyoruz.
- Matematik ve istatistik: Bir veri örneğinin ortalamasını almak için Excel kullanıyorsanız, istatistikleri kullanıyorsunuz demektir. Ortalama, bir veri örneğinin belirli bir yönünü tanımlayan bir istatistiktir. Daha gelişmiş istatistikler, verilerinizi anlamanıza yardımcı olacaktır. Bu da önemlidir ve ben bu alanda uzman değilim. Ne kadar çok istatistiksel dağılıma aşina olursanız, verileri nasıl analiz edeceğiniz konusunda daha fazla fikriniz olur. Ne kadar temel konular bilirseniz, hipotezlerinizi formüle etmede ve veri kümeleriniz hakkında kesin açıklamalar yapmada o kadar iyi olursunuz.
- Programlama becerileri: Bunu aşağıda daha ayrıntılı olarak tartışacağım, ancak temel olarak bu, kullanımı kolay ancak biraz kısıtlayıcı becerilere takılıp kalmak yerine, bilgisayara tam olarak yapmak istediğiniz şeyi yapmasını söyleme esnekliğini oluşturduğunuz yerdir. aletler. Bu, verilerinizi istediğiniz şekilde elde etmenin, yeniden şekillendirmenin ve temizlemenin ana yoludur ve verilerinizle açık uçlu ve esnek “görüşmeler” yapmanızın yolunu açar.
Şimdi Veri Biliminde tipik olarak ne yaptığımıza bir göz atalım.
veri bilimi döngüsü
Tipik bir veri bilimi projesi veya görevi, genellikle şöyle görünür:
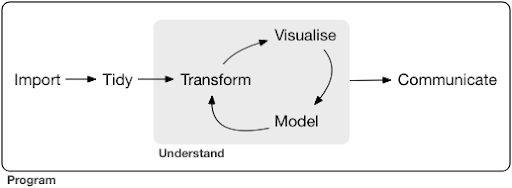
Kaynak: r4ds.had.co.nz
Ayrıca, Veri Bilimine harika bir giriş niteliğinde olan Hadley Wickham ve Garrett Grolemund'un bu kitabını okumanızı şiddetle tavsiye ederim. R programlama dilinden örneklerle yazılmıştır, ancak sadece Python biliyorsanız kavramlar ve kodlar kolayca anlaşılabilir.
Diyagramda görebileceğiniz gibi, önce verilerimizi bir şekilde içe aktarmamız, düzenlememiz ve ardından dönüştürme, görselleştirme ve modellemenin iç döngüsü üzerinde çalışmaya başlamamız gerekiyor. Bundan sonra sonuçları başkalarıyla paylaşıyoruz.
Bu adımlar son derece basitten çok karmaşığa kadar değişebilir. Örneğin, "İçe Aktar" adımı bir CSV dosyasını okumak kadar basit olabilir ve bazı durumlarda verileri almak için çok karmaşık bir web kazıma projesini içerebilir. Sürecin unsurlarından bazıları, kendi başlarına tam teşekküllü uzmanlıklardır.
Bunu bildiğimiz bazı tanıdık süreçlerle kolayca eşleştirebiliriz. Örneğin, robots.txt ve XML site haritalarını indirerek bir web sitesi hakkında bazı meta veriler alarak başlayabilirsiniz. Muhtemelen daha sonra tarama yapar ve muhtemelen SERP pozisyonları hakkında bazı veriler elde edersiniz veya örneğin verileri bağlarsınız. Artık birkaç veri kümeniz olduğuna göre, muhtemelen bazı tabloları birleştirmek, bazı ek veriler eklemek ve keşfetmeye/anlamaya başlamak istersiniz. Verileri görselleştirmek, gizli kalıpları ortaya çıkarabilir veya neler olup bittiğini anlamanıza yardımcı olabilir veya belki daha fazla soru ortaya çıkarabilir. Muhtemelen bazı temel istatistikleri veya makine öğrenimi modellerini kullanarak verilerinizi modellemek ve umarız bazı içgörüler elde etmek istersiniz. Tabii ki, bulguları ve soruları projedeki diğer paydaşlara iletmeniz gerekiyor.
Bu süreçlerin her biri için mevcut çeşitli araçlara yeterince aşina olduğunuzda, belirli bir web sitesine özgü kendi özel işlem hatlarınızı oluşturmaya başlayabilirsiniz, çünkü her işletme benzersizdir ve özel gereksinimleri vardır. Sonunda, kalıplar bulmaya başlayacaksınız ve benzer projeler/web siteleri için tüm işi yeniden yapmak zorunda kalmayacaksınız.
Bu süreçte her öğe için çok sayıda araç ve kitaplık mevcuttur ve hangi aracı seçerseniz (ve öğrenmeye zaman ayırın) oldukça bunaltıcı olabilir. Kullandığım araçları seçerken faydalı bulduğum olası bir yaklaşıma bir göz atalım.
Araç seçimi ve takaslar (pizza sahip olmanın 3 yolu)
Günlük işlerinizde veri işlemede excel kullanmalı mısınız, yoksa Python'u öğrenmeye değer mi?
Power BI gibi bir şeyle görselleştirmeniz daha mı iyi, yoksa Grammar of Graphics hakkında bilgi edinmeye ve onu uygulayan kitaplıkları nasıl kullanacağınızı öğrenmeye yatırım mı yapmalısınız?
R veya Python ile kendi etkileşimli gösterge tablolarınızı oluşturarak daha iyi işler mi üreteceksiniz yoksa Google Data Studio ile mi gitmelisiniz?
Önce farklı soyutlama seviyelerinde çeşitli araçların seçilmesiyle ilgili ödünleşimleri inceleyelim. Bu, Plotly ve Dash ile etkileşimli panolar ve veri uygulamaları oluşturma hakkındaki kitabımdan bir alıntıdır ve bu yaklaşımı yararlı buluyorum:
Pizza yemek için üç farklı yaklaşım düşünün:
- Sipariş yaklaşımı: Bir restoranı arar ve pizzanızı sipariş edersiniz. Yarım saat sonra kapınıza geliyor ve yemeye başlıyorsunuz.
- Süpermarket yaklaşımı: Bir süpermarkete gidiyorsunuz, hamur, peynir, sebze ve diğer tüm malzemeleri satın alıyorsunuz. Daha sonra pizzayı kendin yapıyorsun.
- Çiftlik yaklaşımı: Arka bahçenizde domates yetiştiriyorsunuz. İnek yetiştirirsiniz, sağarsınız ve sütü peynire dönüştürürsünüz, vb.
Üst seviye arayüzlere çıktıkça, sipariş verme yaklaşımına doğru ihtiyaç duyulan bilgi miktarı çok azalmaktadır. Sorumluluğu başka biri üstlenir ve kalite, itibar ve rekabetin piyasa güçleri tarafından kontrol edilir.
Bunun için ödediğimiz bedel, azalan özgürlük ve seçeneklerdir. Her restoranın seçebileceği bir dizi seçeneği vardır ve bu seçeneklerden birini seçmeniz gerekir.
Daha düşük seviyelere inildikçe, gereken bilgi miktarı artar, daha fazla karmaşıklıkla baş etmek zorunda kalırız, sonuçlar için daha fazla sorumluluk alırız ve bu çok daha fazla zaman alır. Burada kazandığımız şey, sonuçlarımızı istediğimiz şekilde özelleştirmek için çok daha fazla özgürlük ve güç. Maliyet de önemli bir avantajdır, ancak yalnızca yeterince büyük bir ölçekte. Bugün sadece pizza yemek istiyorsanız, sipariş vermek muhtemelen daha ucuzdur. Ancak her gün bir tane almayı planlıyorsanız, bunu kendiniz yaparsanız büyük maliyet tasarrufları bekleyebilirsiniz.
Bunlar, hangi araçları kullanacağınızı ve öğreneceğinizi seçerken yapmanız gereken seçimlerdir. R veya Python gibi bir programlama dili kullanmak çok daha fazla çalışma gerektirir ve sizi çok daha üretken ve güçlü kılma avantajıyla Excel'den daha zordur.
Seçim, her araç veya süreç için de önemlidir. Örneğin, bir web sitesi hakkında veri toplamak için üst düzey ve kullanımı kolay bir tarayıcı kullanabilir, ancak verileri mevcut tüm seçeneklerle görselleştirmek için bir programlama dili kullanmayı tercih edebilirsiniz. Doğru süreç için doğru aracın seçimi, ihtiyaçlarınıza bağlıdır ve yukarıda açıklanan ödünleşim, bu seçimi yapmanıza yardımcı olabilir. Bu ayrıca umarım Python veya R öğrenmek isteyip istemediğiniz (veya ne kadar) sorusunun ele alınmasına yardımcı olur.
Bu soruyu biraz daha ileri götürelim ve SEO için Python öğrenmenin neden doğru anahtar kelime olmayabileceğini görelim.
Neden “seo için python” yanıltıcıdır?
Harika bir blogger olmak mı yoksa WordPress öğrenmek mi istiyorsunuz?
Grafik tasarımcı olmak ister miydiniz yoksa amacınız Photoshop öğrenmek mi?
Veri becerilerinizi bir sonraki seviyeye taşıyarak SEO kariyerinizi geliştirmek mi istiyorsunuz yoksa Python'u öğrenmek mi istiyorsunuz?
MIT'deki bilgisayar bilimi dersinin ilk dersinin ilk beş dakikasında Profesör Harold Abelson, öğrencilere “bilgisayar biliminin” öğrenmek üzere oldukları disiplin için neden bu kadar kötü bir isim olduğunu söyleyerek dersi açar. Dersin ilk beş dakikasını izlemenin çok ilginç olduğunu düşünüyorum:
Bir alan yeni başladığında ve bunu gerçekten çok iyi anlamadığınızda, yaptığınız şeyin özünü kullandığınız araçlarla karıştırmak çok kolaydır. – Harold Abelson
Çevrimiçi varlığımızı ve sonuçlarımızı iyileştirmeye çalışıyoruz ve yaptığımız şeylerin çoğu genel olarak verileri anlamaya, görselleştirmeye, işlemeye ve işlemeye dayanıyor ve kullanılan araçtan bağımsız olarak odak noktamız bu. Veri Bilimi, bunu yapmak için entelektüel çerçevelere ve yapmak istediklerimizi uygulamak için birçok araca sahip bir alandır. Python, seçtiğiniz programlama dili (araç) olabilir ve onu iyi öğrenmek kesinlikle önemlidir. Bizim durumumuzda, verileri işlemek ve analiz etmek için “yaptığınız şeyin özüne” odaklanmak, hatta daha önemli değilse de aynı derecede önemlidir.
Ana odak, seçilen programlama dilinin aksine, yukarıda tartışılan süreçler (içe aktarma, toplama, görselleştirme vb.) üzerinde olmalıdır. Ya da daha iyisi, sadece bir programlama dili öğrenmek yerine, görevlerinizi gerçekleştirmek için bu programlama dilini nasıl kullanacağınızı.
Python'u zaten öğreneceksem, tüm bu teorik ayrımlar kimin umurunda?
Yaptığınız şeyin özüne değil de araç hakkında öğrenmeye odaklanırsanız neler olabileceğine bir göz atalım. Burada, "wordpress öğren" (araç) araması ile "blog yazmayı öğren" (yapmak istediğimiz şey) aramasını karşılaştırıyoruz:
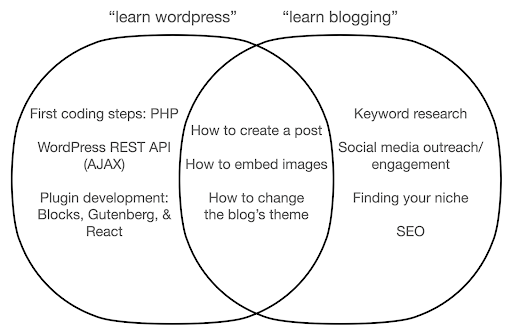
Diyagram, en üstteki anahtar kelimeyi öğreten bir kitap veya kurs altındaki olası konuları gösterir. Ortadaki kesişme alanı, her iki ders/kitap türünde de olabilecek konuları gösterir.
Araca odaklanırsanız, şüphesiz, özellikle yeni başlayanlar için gerçekten ihtiyacınız olmayan şeyleri öğrenmek zorunda kalacaksınız. Bu konular, özellikle teknik veya programlama geçmişiniz yoksa kafanızı karıştırabilir ve hayal kırıklığına uğratabilir.
Ayrıca iyi bir blogger olmak için faydalı olacak şeyleri de öğreneceksiniz (kavşak alanındaki konular). Bu konuları öğretmek son derece kolaydır (bir blog yazısı nasıl oluşturulur), ancak size neden, ne zaman ve ne hakkında blog yazmanız gerektiği hakkında fazla bir şey söylemeyin. Bu, araç odaklı bir kitapta bir kusur değildir, çünkü bir araç hakkında bilgi edinirken, bir blog yazısının nasıl oluşturulacağını öğrenmek ve devam etmek yeterli olacaktır.
Bir blogcu olarak, muhtemelen blog yazmanın ne ve neden olduğuyla daha çok ilgileniyorsunuzdur ve bu, araç odaklı kitaplarda ele alınmaz.
Açıkçası, SEO, nişinizi bulma vb. gibi stratejik ve önemli şeyler ele alınmayacaktır, bu nedenle çok önemli şeyleri kaçırmış olursunuz.
Bir programlama kitabında muhtemelen öğrenemeyeceğiniz Veri Bilimi konularından bazıları nelerdir?
Gördüğümüz gibi, bir Python veya bir programlama kitabı almak, muhtemelen bir yazılım mühendisi olmak istediğiniz anlamına gelir. Konular doğal olarak bu amaca yönelik olacaktır. Bir Veri Bilimi kitabı ararsanız, verileri analiz etmeye yönelik konular ve araçlar elde edersiniz.
İlk diyagramı (Veri Bilimi döngüsünü gösteren) bir kılavuz olarak kullanabilir ve proaktif olarak şu konuları arayabiliriz: "python ile verileri içe aktar", "r ile verileri düzenli hale getir", "python ile verileri görselleştir" vb. Bu konulara daha yakından bakalım ve daha fazla keşfedelim:
İçe aktarmak
Doğal olarak önce bazı verileri elde etmemiz gerekiyor. Bu olabilir:
- Bilgisayarımızdaki bir dosya: Dosyayı seçtiğiniz programlama diliyle açabileceğiniz en basit durum. Birçok farklı dosya formatı olduğunu ve dosyaları açarken/okurken birçok seçeneğiniz olduğunu unutmamak önemlidir. Örneğin, pandas kitaplığındaki (Python'daki temel bir veri işleme aracı) read_csv işlevi, dosyayı açarken aralarından seçim yapabileceğiniz elli seçeneğe sahiptir. Dosya yolu, seçilecek sütunlar, açılacak satır sayısı, datetime nesnelerinin yorumlanması, eksik değerlerle nasıl başa çıkılacağı ve daha pek çok şey gibi şeyleri içerir. Farklı dosya biçimlerini açarken bu seçeneklere ve çeşitli hususlara aşina olmak önemlidir. Ayrıca pandaların çeşitli dosya ve veri formatları için read_ ile başlayan on dokuz farklı işlevi vardır.
- Çevrimiçi bir araçtan dışa aktarma: Muhtemelen buna aşinasınızdır ve burada verilerinizi özelleştirebilir ve ardından dışa aktarabilir, ardından bilgisayarınızda bir dosya olarak açabilirsiniz.
- Belirli verileri almak için API çağrıları: Bu, daha düşük bir düzeydedir ve yukarıda bahsedilen çiftlik yaklaşımına daha yakındır. Bu durumda, belirli gereksinimleri olan bir istek gönderir ve istediğiniz verileri geri alırsınız. Buradaki avantaj, tam olarak ne elde etmek istediğinizi özelleştirebilmeniz ve çevrimiçi arayüzde bulunmayan şekillerde biçimlendirebilmenizdir. Örneğin, Google Analytics'te analiz ettiğiniz bir tabloya ikincil bir boyut ekleyebilirsiniz, ancak üçüncü bir boyut ekleyemezsiniz. Ayrıca dışa aktarabileceğiniz satır sayısıyla da sınırlıdır. API size daha fazla esneklik sağlar ve ayrıca daha büyük bir veri toplama/analiz hattının parçası olarak belirli çağrıların periyodik olarak gerçekleşmesini otomatikleştirebilirsiniz.
- Tarama ve kazıma verileri: Muhtemelen en sevdiğiniz tarayıcıya sahipsiniz ve muhtemelen sürece aşinasınız. Bu, sayfalardan özel öğeler çıkarmamıza, yalnızca belirli sayfaları taramamıza vb. izin veren zaten esnek bir süreçtir.
- Özel kullanımlar için otomasyon, özel çıkarma ve muhtemelen makine öğrenimini içeren yöntemlerin bir kombinasyonu.
Bazı verilere sahip olduğumuzda, bir sonraki seviyeye geçmek istiyoruz.
Düzenli
"Düzenli" bir veri kümesi, belirli bir şekilde düzenlenen bir veri kümesidir. "Uzun biçimli" veriler olarak da adlandırılır. R for Data Science kitabındaki 12. Bölüm, eğer ilgileniyorsanız düzenli veri kavramını daha ayrıntılı olarak tartışır.
Aşağıdaki üç tabloya bir göz atın ve farklılıkları bulmaya çalışın:
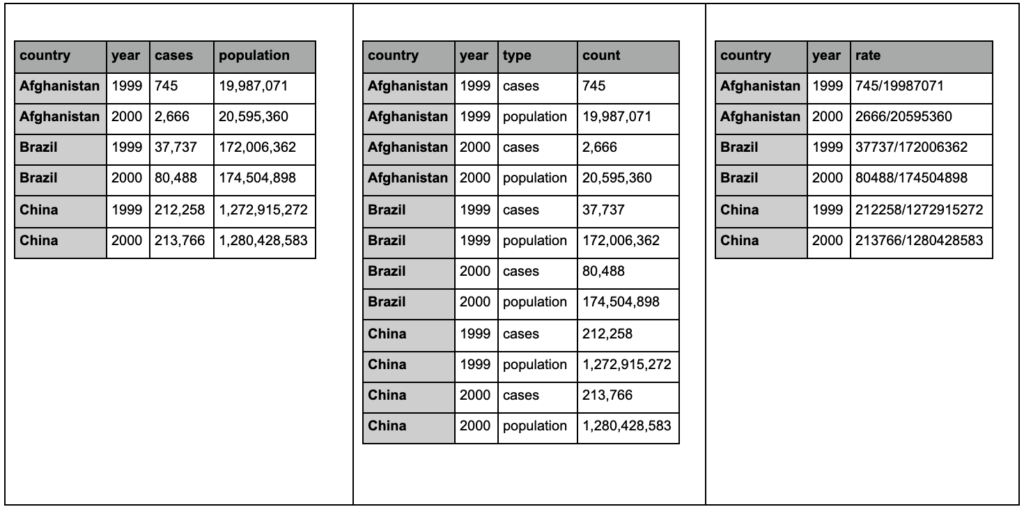
tidyr paketinden örnek tablolar.
Üç tablonun tamamen aynı bilgileri içerdiğini, ancak farklı şekillerde organize edildiğini ve sunulduğunu göreceksiniz. Vakaları ve popülasyonu iki ayrı sütunda (tablo 1) veya bize gözlemin ne olduğunu (vakalar veya popülasyon) söyleyen bir sütunumuz ve bu vakaları saymak için bir "count" sütunumuz olabilir (tablo 2). Tablo 3'te oranlar olarak gösterilmiştir.
Verilerle uğraşırken, farklı kaynakların verileri farklı şekilde düzenlediğini ve daha iyi ve daha kolay analiz için genellikle belirli biçimlerden/biçimlere geçmeniz gerekeceğini göreceksiniz. Bu temizleme işlemlerine aşina olmak çok önemlidir ve R'deki tidyr paketi bunun için özel araçlar içerir. Python'u tercih ederseniz pandaları da kullanabilirsiniz ve bunun için eritme ve döndürme işlevlerine göz atabilirsiniz.
Verilerimiz belirli bir formatta olduğunda, onu daha fazla manipüle etmek isteyebiliriz.
dönüştürmek
Oluşturulması gereken bir diğer önemli beceri, üzerinde çalıştığınız verilerde istediğiniz değişiklikleri yapabilme yeteneğidir. İdeal senaryo, verilerinizle sohbet edebileceğiniz ve istediğiniz şekilde çok özel sorular sorabileceğiniz ve umarız ilginç içgörüler elde edebileceğiniz bir aşamaya ulaşmaktır. İlginizi çekebilecek bazı örnek görevlerle birlikte, muhtemelen çok ihtiyaç duyacağınız en önemli dönüşüm görevlerinden bazıları şunlardır:
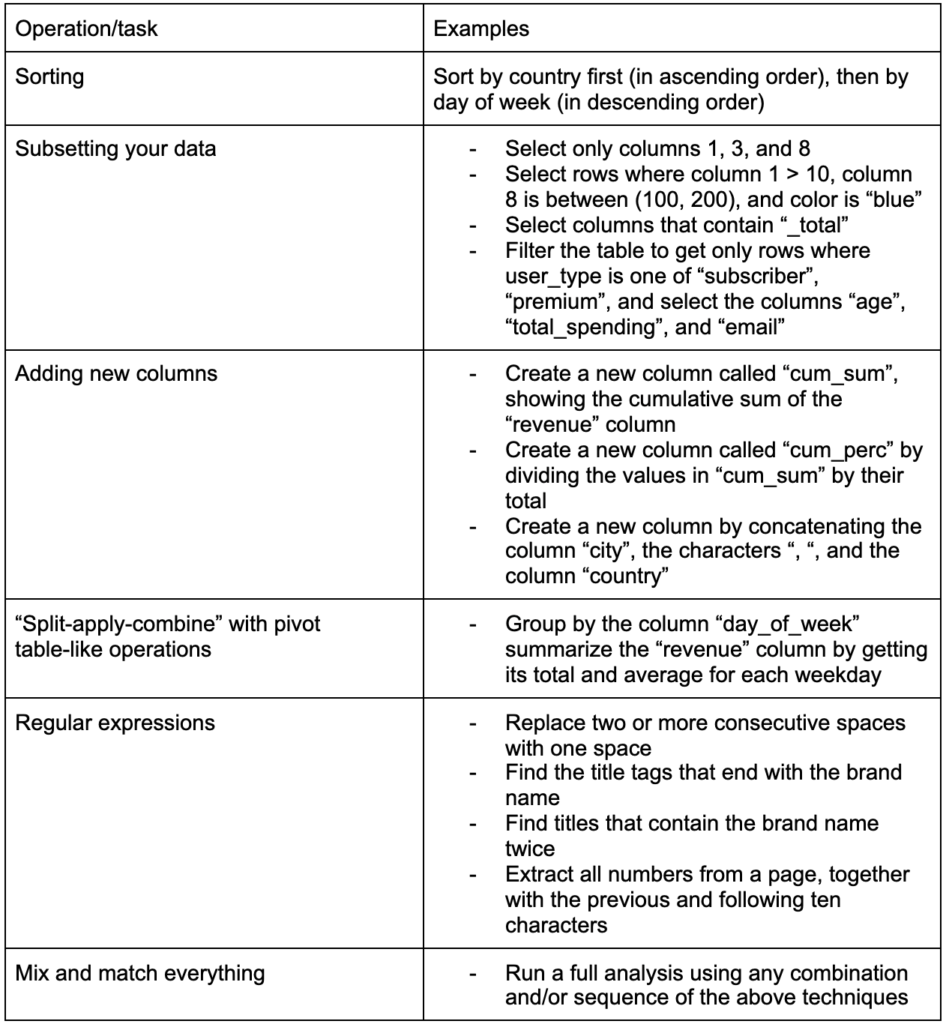
Verilerimizi topladıktan, düzenledikten ve istenilen formatta yerleştirdikten sonra görselleştirmekte fayda var.
görselleştir
Veri görselleştirme çok büyük bir konudur ve bazı alt konuları hakkında kitaplar dolusu kitap vardır. Özellikle bilgi iletmek için sezgisel görsel öğeler kullanması, verilerimiz hakkında çok fazla içgörü sağlayabilecek şeylerden biridir. Bir çubuk grafikteki çubukların göreli yüksekliği, örneğin bize göreli miktarını hemen gösterir. Rengin yoğunluğu, göreceli konumu ve diğer birçok görsel nitelik okuyucular tarafından kolayca tanınabilir ve anlaşılabilir.
İyi bir çizelge bin (anahtar) kelimeye bedeldir!
Veri görselleştirme konusunda geçilecek çok sayıda konu olduğundan, ilginç olabilecek birkaç örnek paylaşacağım. Tüm ayrıntıları istiyorsanız, bunlardan birkaçı bu yoksulluk veri panosunun yapı taşlarıdır.
Çubukların dikey veya yatay olarak görüntülenebildiği, değerleri karşılaştırmak için bazen ihtiyacınız olan tek şey basit bir çubuk grafiktir:
Belirli ülkeleri keşfetmek ilginizi çekebilir ve belirli metriklerde nasıl ilerlediklerini görerek daha derine inebilirsiniz. Bu durumda, aynı çizimde birden çok çubuk grafiği görüntülemek isteyebilirsiniz:
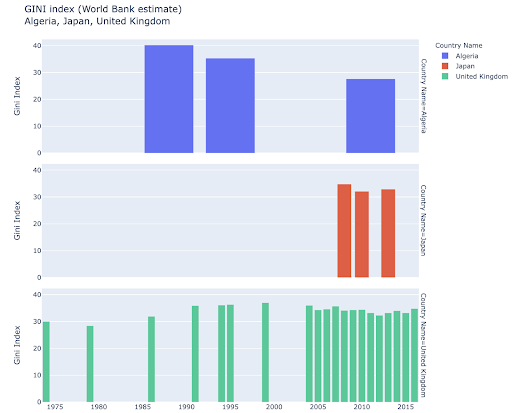
Birden çok gözlem için birden çok değeri karşılaştırmak, her X ekseni konumuna birden çok çubuk yerleştirerek de yapılabilir, bunu yapmanın ana yolları şunlardır:
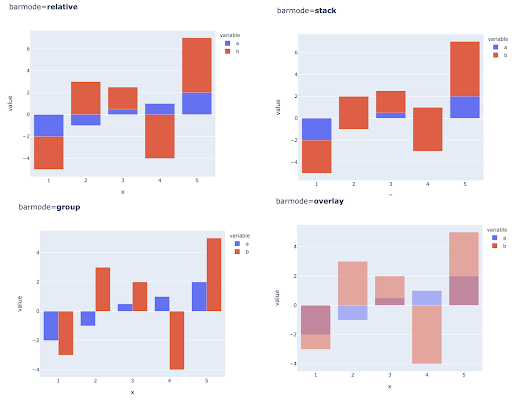
Renk ve renk skalası seçimi: Veri görselleştirmenin önemli bir parçası ve doğru yapıldığında bilgileri son derece verimli ve sezgisel olarak iletebilen bir şey.
Kategorik renk skalaları: Kategorik verileri ifade etmek için kullanışlıdır. Adından da anlaşılacağı gibi, belirli bir gözlemin hangi kategoriye ait olduğunu gösteren veri türüdür. Bu durumda, kategorilerde (özellikle yan yana görüntülenen görsel öğeler için) net farklılıklar göstermek için birbirinden mümkün olduğunca farklı renkler istiyoruz.
Aşağıdaki örnek, her ülkede hangi hükümet sisteminin uygulandığını göstermek için kategorik bir renk ölçeği kullanır. Hangi yönetim sisteminin kullanıldığını gösteren efsaneye ülkelerin renklerini bağlamak oldukça kolaydır. Buna choropleth haritası da denir:
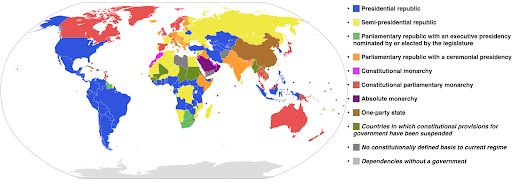
Kaynak: Vikipedi
Bazen görselleştirmek istediğimiz veriler aynı metrik içindir ve her ülke (veya başka herhangi bir gözlem türü), minimum ve maksimum noktalar arasında değişen bir süreklilik içinde belirli bir noktaya düşer. Başka bir deyişle, bu metriğin derecelerini görselleştirmek istiyoruz.
Bu durumlarda sürekli (veya sıralı) bir renk skalası bulmamız gerekir. Aşağıdaki örnekte hangi ülkelerin daha mavi olduğu (ve dolayısıyla daha fazla trafik aldığı) hemen açıktır ve ülkeler arasındaki ince farkları sezgisel olarak anlayabiliriz.
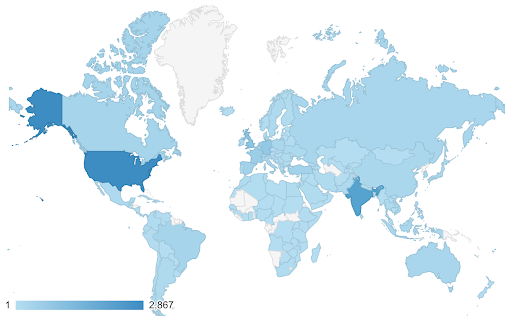
Verileriniz sürekli olabilir (yukarıdaki trafik haritası şeması gibi), ancak sayılarla ilgili önemli olan şey, belirli bir noktadan ne kadar uzaklaştıkları olabilir. Farklı renk skalaları bu durumda kullanışlıdır.
Aşağıdaki grafik net nüfus artış oranlarını göstermektedir. Bu durumda, öncelikle belirli bir ülkenin pozitif veya negatif bir büyüme oranına sahip olup olmadığını bilmek ilginçtir. Veya her ülkenin sıfırdan ne kadar uzakta olduğunu (ve ne kadar) bilmek istiyoruz. Haritaya baktığımızda hangi ülkelerin nüfusunun arttığını ve hangilerinin küçüldüğünü hemen gösteririz. Efsane ayrıca bize maksimum pozitif oranın %3,5 ve maksimum negatif oranın -%0,5 olduğunu gösteriyor. Bu aynı zamanda bize değer aralığı (pozitif ve negatif) hakkında bir gösterge verir.

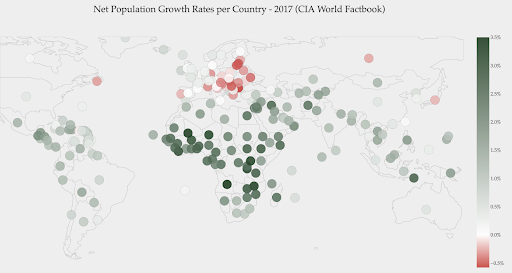
Kaynak : Dashboardom.com
Ne yazık ki, bu ölçek için seçilen renkler ideal değildir, çünkü renk körü insanlar kırmızı ve yeşili doğru şekilde ayırt edemeyebilirler. Renk skalalarımızı seçerken bu çok önemli bir husustur.
Dağılım grafiği , en yaygın kullanılan ve çok yönlü arsa türlerinden biridir. Noktaların (veya başka herhangi bir işaretçinin) konumu, iletmeye çalıştığımız miktarı ifade eder. Pozisyona ek olarak, daha fazla bilgi iletmek için renk, boyut ve şekil gibi başka görsel nitelikleri de kullanabiliriz. Aşağıdaki örnek, noktaların yatay mesafesi olarak açıkça görebileceğimiz, 1,9 $/gün ile yaşayan nüfusun yüzdesini göstermektedir.
Grafiğimize renk kullanarak yeni bir boyut da ekleyebiliriz. Bu, aynı veri kümesinden üçüncü bir sütunun görselleştirilmesine karşılık gelir; bu, bu durumda nüfus verilerini gösterir.
Artık nüfus açısından en uç durumun (ABD) yoksulluk düzeyi metriğinde çok düşük olduğunu görebiliyoruz. Bu, tablolarımıza zenginlik katıyor. Veri kümemizden daha da fazla sütunu görselleştirmek için boyut ve şekil kullanabilirdik. Yine de zenginlik ve okunabilirlik arasında iyi bir denge kurmamız gerekiyor.
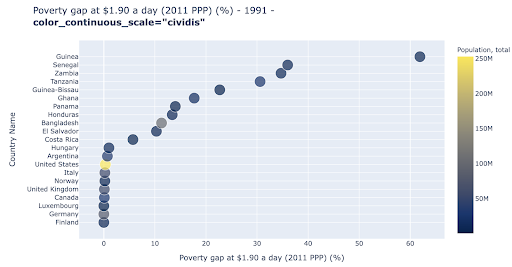
Nüfus ve yoksulluk seviyeleri arasında bir ilişki olup olmadığını kontrol etmekle ilgilenebiliriz ve böylece böyle bir ilişkinin olup olmadığını görmek için aynı veri setini biraz farklı bir şekilde görselleştirebiliriz:
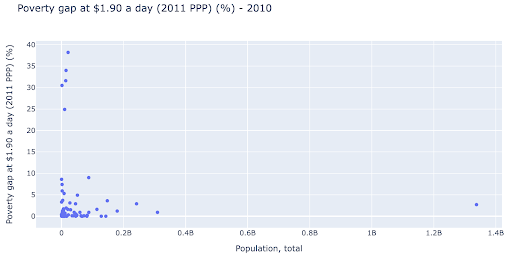
Popülasyonda 1,35B civarında bir aykırı değerimiz var ve bu, grafikte çok fazla boşluk olduğu anlamına geliyor, bu da birçok değerin çok küçük bir alana sıkıştırıldığı anlamına geliyor. Ayrıca, herhangi bir farklılık veya eğilimi tespit etmeyi çok zorlaştıran, örtüşen birçok noktamız var.
Aşağıdaki çizelge aynı bilgileri içerir, ancak iki teknik kullanılarak farklı şekilde görselleştirilmiştir:
- Logaritmik ölçek : Verileri genellikle toplamsal ölçekte görürüz. Başka bir deyişle, eksen üzerindeki her nokta (X veya Y), görselleştirilen verinin belirli bir miktarının eklenmesini temsil eder. Ayrıca çarpımsal ölçeklerimiz de olabilir, bu durumda X eksenindeki her yeni nokta için çarparız (bu örnekte on ile). Bu, noktaların yayılmasını sağlar ve önceki tabloda yaptığımız gibi, toplamaların aksine katları düşünmemiz gerekir.
- Farklı bir işaretleyici kullanma (daha büyük boş daireler) : İşaretçilerimiz için farklı bir şekil seçmek, aynı yerde birbiri üzerine birkaç noktanın olabileceği "fazla çizim" sorununu çözdü, bu da görmeyi bile çok zorlaştırdı. kaç puanımız var
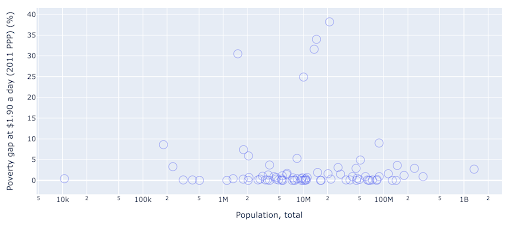
Artık 10M işareti etrafında bir grup ülke ve diğer daha küçük kümeler olduğunu görebiliyoruz.
Bahsettiğim gibi, daha birçok karakter türü ve görselleştirme seçeneği ve konu hakkında yazılmış kitapların tamamı var. Umarım bu size denemeniz için birkaç ilginç fikir verir.
Tarama Verileri³
 Daha fazla bilgi edin
Daha fazla bilgi edinmodeli
Verilerimizi basitleştirmemiz ve kalıpları bulmamız, tahminler yapmamız veya basitçe daha iyi anlamamız gerekiyor. Bu başka bir geniş konudur ve basitçe bazı özet istatistikleri (ortalama, medyan, standart sapma, vb.) almaktan, verilerimizi görsel olarak modellemeye, özetleyen veya bir eğilim bulan bir model kullanmaya, bir verilerimiz için matematiksel formül. Verilerimizde daha fazla içgörü ortaya çıkarmamıza yardımcı olması için makine öğrenimini de kullanabiliriz.
Yine, bu konunun tam bir tartışması değil, ancak size yardımcı olması için bazı makine öğrenimi tekniklerini kullanabileceğiniz birkaç örnek paylaşmak istiyorum.
Bir tarama veri setinde, 404 sayfa hakkında biraz daha fazla şey öğrenmeye çalışıyordum ve eğer onlar hakkında bir şeyler keşfedebilirsem. İlk denemem, sayfanın boyutu ile durum kodu arasında bir korelasyon olup olmadığını kontrol etmekti ve vardı – neredeyse mükemmel bir korelasyon!
Birkaç dakikalığına bir dahi gibi hissettim ve hızla Dünya gezegenine geri döndüm.
404 sayfanın tümü, belirli bir kilobayt sayısına sahip hemen hemen tüm sayfaların 404 durum koduna sahip olduğu çok dar bir sayfa boyutu aralığındaydı. Sonra fark ettim ki, tanım gereği 404 sayfalarında "404 hata sayfası" dışında bir içerik yok! Ve bu yüzden aynı boydaydılar.
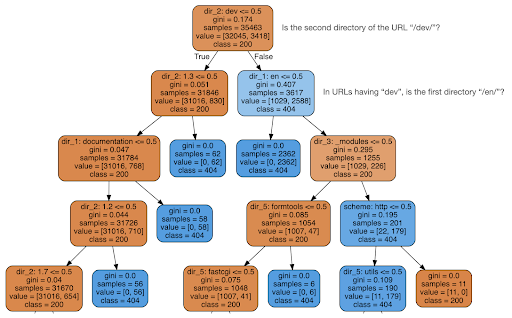
Daha sonra içeriğin durum kodu hakkında bana bir şey söyleyip söylemediğini kontrol etmeye karar verdim, bu yüzden URL'leri öğelerine böldüm ve sklearn kullanarak bir karar ağacı sınıflandırıcısı çalıştırdım. Bu temelde bir karar ağacı üreten bir tekniktir, burada kurallarını takip ederek hedefimizi nasıl bulacağımızı öğrenebiliriz, bu durumda 404 sayfa.
Aşağıdaki karar ağacında, her kutudaki ilk satır izlenecek veya kontrol edilecek kuralı gösterir, “örnekler” satırı bu kutuda bulunan gözlemlerin sayısını ve “sınıf” satırı bize mevcut gözlemin sınıfını söyler. , bu durumda durum kodunun 200 veya 404 olup olmadığı.
Daha fazla ayrıntıya girmeyeceğim ve bunlara aşina değilseniz karar ağacının net olmayabileceğini biliyorum ve ilgileniyorsanız ham tarama veri kümesini ve analiz kodunu inceleyebilirsiniz.
Temel olarak karar ağacının bulduğu şey, URL'lerin dizin yapısını kullanarak neredeyse tüm 404 sayfanın nasıl bulunacağıydı. Gördüğünüz gibi, sadece URL'nin ikinci dizininin “/dev/” olup olmadığını kontrol ederek 3.617 URL bulduk (üstten ikinci satırdaki ilk açık mavi kutu). Artık 404'lerimizi nasıl bulacağımızı biliyoruz ve görünüşe göre neredeyse hepsi sitenin “/dev/” bölümündeler. Bu kesinlikle büyük bir zaman tasarrufu oldu. Bu kuralı bulmak için tüm olası URL yapılarını ve kombinasyonlarını manuel olarak incelediğinizi hayal edin.
Hala tam resme ve bunun neden olduğuna sahip değiliz ve bu daha fazla takip edilebilir, ancak en azından artık bu URL'leri çok kolay bir şekilde bulduk.
İlginizi çekebilecek başka bir teknik, veri noktalarını çeşitli gruplar/kümeler halinde gruplandıran KMeans kümelemedir. Bu, algoritmanın varlığından haberdar olmadığımız kalıpları keşfetmemize yardımcı olduğu bir “denetimsiz öğrenme” tekniğidir.
Diyelim ki ülke nüfusu gibi bir sürü numaranız olduğunu ve bunları büyük ve küçük olmak üzere iki gruba ayırmak istediğinizi hayal edin. Bunu nasıl yaptın? Çizgiyi nereye çekersin?
Bu, ilk on ülkeyi veya ülkelerin ilk % X'ini almaktan farklıdır. Bu çok kolay olurdu, ülkeleri nüfusa göre sıralayabilir ve ilk X'i istediğimiz gibi alabiliriz.
İstediğimiz, bu veri setine göre onları “büyük” ve “küçük” olarak gruplandırmak ve ülke nüfusu hakkında hiçbir şey bilmediğimizi varsayarak.
Bu, ülkeleri üç kategoriye ayırmaya çalışmakla daha da genişletilebilir: küçük, orta ve büyük. Beş, altı veya daha fazla grup istiyorsak, bunu manuel olarak yapmak çok daha zor hale gelir.
İlk X ülkeleri istemediğimiz için her grupta kaç ülkenin olacağını bilmediğimizi unutmayın. İki kümeye ayırdığımızda, büyük grupta sadece iki ülkenin olduğunu görebiliriz: Çin ve Hindistan. Bu iki ülke, diğer tüm ülkelerden çok uzak bir ortalama nüfusa sahip olduğundan, bu sezgisel bir anlam ifade ediyor. Bu ülke grubunun kendi ortalaması vardır ve ülkeleri birbirine diğer grubun ülkelerinden daha yakındır:
Nüfusa göre iki gruba ayrılan ülkeler 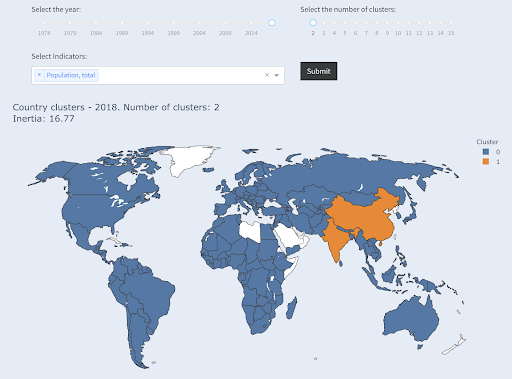
Nüfus bakımından üçüncü en büyük ülke (ABD ~330 milyon), bir milyon nüfusa sahip ülkeler de dahil olmak üzere diğer tüm ülkelerle birlikte gruplandırılmıştır. Bunun nedeni, 330M'nin 1M'ye 1,3 milyardan çok daha yakın olmasıdır. Üç küme isteseydik, farklı bir resim elde ederdik:
Ülkeler nüfusa göre üç gruba ayrıldı 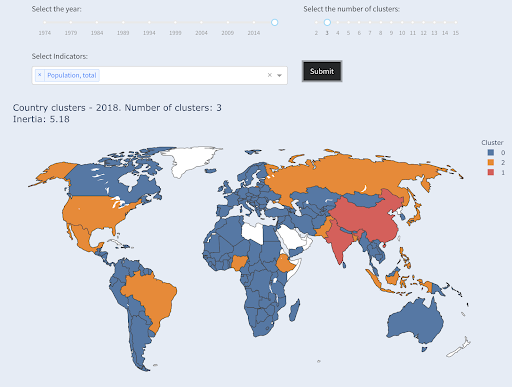
Ve dört küme istersek ülkeler şu şekilde kümelenir:
Ülkeler nüfusa göre dört gruba ayrıldı 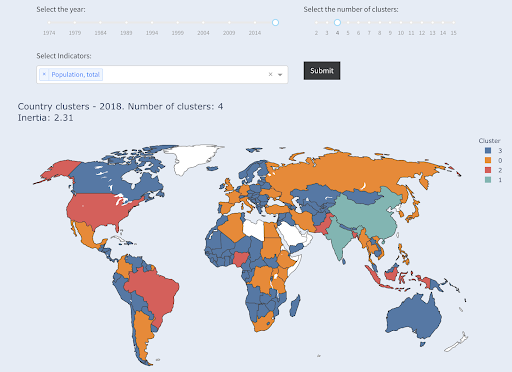
Kaynak: yoksullukdata.org (“Küme Ülkeleri” sekmesi)
Bu, yalnızca bir boyut kullanarak kümelemeydi – bu durumda nüfus – ve daha fazla boyut da ekleyebilir ve ülkelerin nereye vardığını görebilirsiniz.
Başka pek çok teknik ve araç var ve bunlar umarız ilginç ve pratik olan birkaç örnekti.
Artık bulgularımızı izleyicilerimizle paylaşmaya hazırız.
İletişim kurmak
Önceki adımlarda yaptığımız tüm çalışmalardan sonra, sonunda bulgularımızı diğer proje paydaşlarına iletmemiz gerekiyor.
Veri bilimindeki en önemli araçlardan biri etkileşimli defterdir. Jupyter notebook en yaygın kullanılanıdır ve hemen hemen tüm programlama dillerini destekler ve RStudio'nun aynı şekilde çalışan özel notebook formatını kullanmayı tercih edebilirsiniz.
Ana fikir, verilerin, kodun, anlatımın ve görselleştirmelerin tek bir yerde bulunmasıdır, böylece diğer insanlar bunları denetleyebilir. Şeffaflık ve tekrarlanabilirlik için bu sonuçlara ve önerilere nasıl ulaştığınızı göstermek önemlidir. Diğer insanlar aynı kodu çalıştırabilmeli ve aynı sonuçları alabilmelidir.
Diğer bir önemli neden de, “gelecekteki siz” de dahil olmak üzere, başkalarının analizi daha ileri götürme ve yaptığınız ilk çalışma üzerine inşa etme, iyileştirme ve yeni yollarla genişletme yeteneğidir.
Tabii ki, bu, izleyicinin kod konusunda rahat olduğunu ve hatta umursadığını varsayar!
Ayrıca, kod hariç, not defterlerinizi HTML'ye (ve diğer birçok biçime) aktarma seçeneğiniz de vardır, böylece kullanıcı dostu bir rapor elde edersiniz ve yine de aynı analiz ve sonuçları yeniden oluşturmak için tam kodu saklarsınız.
İletişimin önemli bir unsuru da yukarıda kısaca ele alınan veri görselleştirmedir.
Daha da iyisi, etkileşimli veri görselleştirmedir; bu durumda hedef kitlenizin değerleri seçmesine ve verileri daha da fazla keşfetmek için çeşitli grafik ve metrik kombinasyonlarına göz atmasına izin verirsiniz.
Yapılabilecekler hakkında size fikir vermek için oluşturduğum bazı panolar ve veri uygulamaları (bazılarının yüklenmesi birkaç saniye sürebilir).
Sonunda, özel ihtiyaç ve gereksinimleri karşılamak için projeleriniz için özel uygulamalar da oluşturabilirsiniz ve işte sizin için ilginç olabilecek başka bir SEO ve pazarlama uygulaması seti.
Veri Bilimi döngüsündeki ana adımlardan geçtik ve şimdi "piton öğrenmenin" başka bir avantajını keşfedelim.
Python otomasyon ve üretkenlik içindir: doğru ama eksik
Bana öyle geliyor ki Python öğrenmenin temel olarak üretkenlik ve/veya görevleri otomatikleştirmek için olduğuna dair bir inanç var.
Bu kesinlikle doğru ve bir şeyi manuel olarak yapmamızın alacağı zamandan çok daha kısa bir sürede yapabilmenin değerini tartışmamıza bile gerek yok.
Argümanın diğer eksik kısmı veri analizidir . İyi veri analizi bize içgörüler sağlar ve ideal olarak, uzmanlığımıza ve sahip olduğumuz verilere dayanarak karar verme sürecimize rehberlik edecek eyleme geçirilebilir içgörüler sağlayabiliriz.
Yaptığımız şeyin büyük bir kısmı neler olduğunu anlamaya çalışmak, rekabeti analiz etmek, en değerli içeriğin nerede olduğunu bulmak, ne yapacağımıza karar vermek vb. Biz danışmanlarız, danışmanlarız ve karar vericileriz. Verilerimizden bazı içgörüler elde edebilmek açıkça büyük bir faydadır ve burada bahsedilen alanlar ve beceriler bunu başarmamıza yardımcı olabilir.
Başlık etiketlerinizin ortalama altmış karakter uzunluğunda olduğunu öğrendiyseniz, bu iyi mi?
Ya biraz daha derine inerseniz ve başlıklarınızın yarısının altmışın çok altında olduğunu, diğer yarısının ise çok daha fazla karaktere sahip olduğunu (ortalama altmış yapar) keşfederseniz? In order to get practical and provide good recommendations, you need a higher-resolution view of your title tags' lengths, probably a histogram that shows the frequency of your title tag lengths at each interval so you can have a separate strategy for length. A simple table would also do, for example:
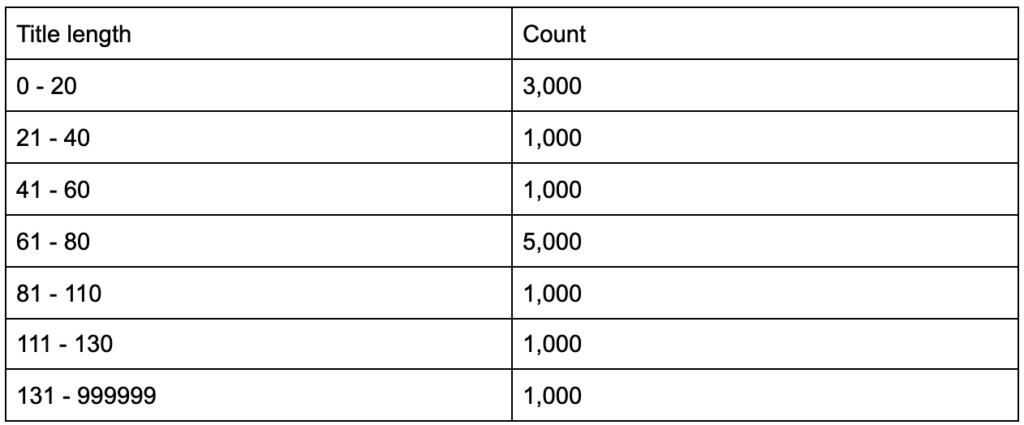
Splitting title lengths by intervals of twenty was an arbitrary decision, and you can split them the way you want. Looking at the table above, and seeing that we have three times more than the average titles in the interval (0, 20), we might want to split it further to better understand what is going on.
Having a better view than the default single-statistic summaries that we get from standard tools, allows us to employ different strategies for different lengths. For example, we can remove the brand name from the titles that are longer than a certain number of characters, and keep it in other titles.
This was an example of very simple insights, which are possible due to the flexibility we get by using a programming language, and a set of data science tools. This also allows us to iterate and modify our approach, until we find a satisfactory point that can take our analysis to the next steps.
Visualization, machine learning, modeling and general data manipulation skills allow us to get better insights on our data, even though those analyses are typically done only once. Still, if you use code to get those insights, you can always take some parts and apply to other projects, or again to the same project. In this case, the insights we got, helped us in our automation, even more. The insights would tell us what needs to be automated and what doesn't.
Should you learn Python?
Is a useless question, and the more useful one is, “How much Python (or R) should you learn?”
My view of how we use computers has evolved in the last few years.
I used to think that there were two main ways of using computers, either you are a regular user, using “point-and-click” applications to do certain tasks, or you are a developer who creates those applications that the rest of us use.

I then realized that it is more like a continuum between very high level use (pizza ordering approach), and the lower levels of the farm approach. I also realized that there is a happy sweet spot in between, where you learn enough programming to get productive and boost your data analysis skills, without having to become a software developer or engineer.
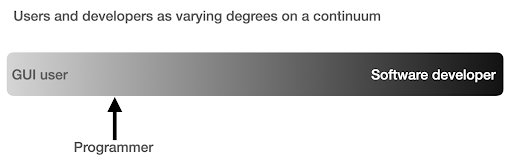
What are the main differences between being a programmer (a software user), and a software developer (or engineer)?
What are the differences between making a great coffee at home, versus establishing and running a cafe?
If making good coffee is one skill, then running a cafe requires ten other skills, most of which have nothing to do with making coffee.
You have to choose a good location (real estate), hire people (management and HR), manage cash flow and finances (accounting and finance), do marketing, legal, manage delivery, adhere to cleanliness and health standards, and so on. You can be a great coffee maker without knowing anything about those fields, but if you want to take it to the next level, you will have to manage all those additional tasks unrelated to making coffee.
The same applies to being a good programmer or data analyst versus being a software developer/engineer. There are so many other things that you have to know and worry about that you don't need as a regular programmer doing stuff for yourself and co-workers and clients. Once you have enough knowledge and skills in programming and data science, you will be in a good position to choose and decide whether you want to continue as an analyst, focusing on data science, or if you want to end up creating software that other people would use.
How do I get into Data Science?
To learn anything I think you have to do two things in parallel:
- Learn the fundamentals and the theory properly: Taking courses and reading books, and getting into the fundamentals can push you forward, as you will be gaining in weeks, knowledge that took decades to establish. It would also immediately give you ideas on things you thought were impossible, or had no idea existed.
- Get as much real world exposure and experience as possible: Experience is always important, and my suggestion is to try as soon as you can to read_csv with Python or R, to actually do so with your GA, GSC, or crawl dataset. See what else you can do (visualize, manipulate, model, etc.). See if you get errors, try to analyze the data only using your programming language.
What does frustration look like, and by when will I get productive?
It's difficult to say, and it depends on your skill, background, the hours you put in, but visualizing it like this might help you on those frustrating unproductive days:
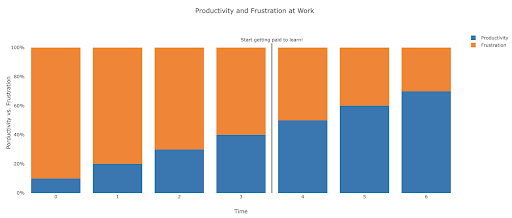
My suggestion is to take a non-trivial task, for example running an SEO audit for a site, only using Python. Your first session will mostly be frustrating, and most of the time will be spent checking documentation, and the definition of basic terms.
In parallel, you are still going through your course, and learning new stuff.
The value of that frustrating session is that it informs and motivates your theoretical learning. You will have questions in mind, and when you learn new things, you will immediately have a place to implement them.
Your next analysis session will probably be a little more productive, but still not productive enough to do at work. You go again to your learning and theory.
Do this enough times, and your time will become mostly productive, eventually you will be doing real work during working hours. The ideal scenario is where you are productive enough to do work, but every time use some time to research better techniques, which improves your work as well. By then you will start to get paid for learning, and your clients will be happily sponsoring you!
Suggested next steps
For the learning path a Data Science course would be great, especially if you get feedback on your work, and you can follow the topics in the order recommended.
If you go with Python I suggest the following libraries:
- pandas: The workhorse of all your tasks in preparing, cleaning, reshaping data whichever way you want. Fluency in pandas allows you to have full control over your data, which will help you immensely in visualization, general analysis, and machine learning
- Plotly and Dash: This is my favorite data visualization library, although there are many others. What I mostly like about it, is that it produces interactive and responsive HTML charts by default. It is very detailed and thorough in its options, yet simple to use. Plotly also includes Plotly Express, which is a high-level plotting tool, which is more intuitive to use, and takes a data-oriented approach (as opposed to a chart-oriented approach). Plotly also created Dash, which is the tool for creating interactive dashboards, but also serves as a full front-end web development framework. Other important data visualization libraries are matplotlib, altair, and bokeh, and for interactive data apps, there is panel and streamlit. Another important feature is that Plotly and Dash are available in all languages used in Data Science. You might use other libraries, and this is just my personal preference. Speaking of personal preferences:
- advertools: This is a library that I created to provide various online marketing tools, most importantly, an SEO crawler, log file parser and compressor, multi robots.txt parser, recursive sitemap parser, SEM keyword and text ad generator for large scale campaigns, weighted frequency word counter, Google SERP downloader, YouTube data API, and a few other tools. It is still evolving, and you are more than welcome to contribute any suggestions, bugs, or issues you might have with it.
These should be enough for beginners, and when you are familiar with them, you can do your own research for more specialized libraries, machine learning and deep learning tools, or libraries that are specialized in performance, or a special niche use-case.