
Data Science for SEO and Digital Marketing : un guide suggéré pour les débutants
Publié: 2021-12-07Comme la plupart de notre travail tourne autour des données, et que le domaine de la science des données devient beaucoup plus vaste et beaucoup plus accessible aux débutants, j'aimerais partager quelques réflexions sur la façon dont vous pourriez entrer dans ce domaine pour augmenter votre référencement et votre marketing. compétences en général.
Qu'est-ce que la science des données ?
Un diagramme très connu qui est utilisé pour donner un aperçu de ce domaine est le diagramme de Venn de Drew Conway montrant la science des données comme l'intersection des statistiques, du piratage (compétences avancées en programmation en général, et pas nécessairement pénétrant les réseaux et causant des dommages) et substantiel. expertise ou « connaissance du domaine » :
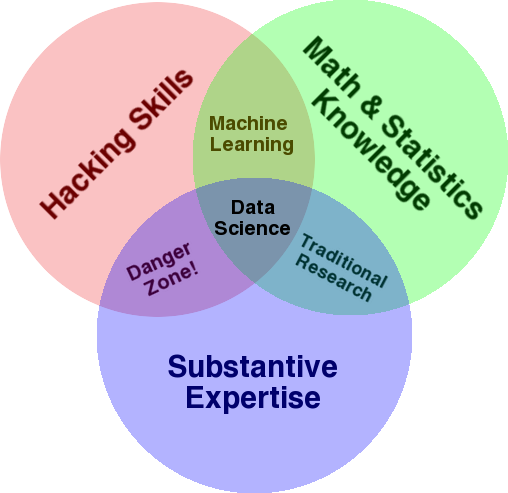
Source : oreilly.com
Quand j'ai commencé à apprendre, j'ai vite compris que c'était exactement ce que nous faisions déjà. La seule différence est que je le faisais avec des outils plus basiques et manuels.
Si vous regardez le diagramme, vous verrez facilement comment vous le faites probablement déjà. Vous utilisez un ordinateur (compétences en piratage), pour analyser des données (statistiques), pour résoudre un problème pratique en utilisant votre expertise substantielle en SEO (ou toute autre spécialité sur laquelle vous vous concentrez).
Votre "langage de programmation" actuel est probablement une feuille de calcul (Excel, Google Sheets, etc.), et vous utilisez très probablement Powerpoint ou quelque chose de similaire pour communiquer des idées. Développons un peu ces éléments.
- Connaissance du domaine : Commençons par votre principale force, car vous connaissez déjà votre domaine d'expertise. Gardez à l'esprit qu'il s'agit d'un élément essentiel pour être un scientifique des données, et c'est là que vous pouvez développer et protéger vos connaissances. Il y a quelques mois, je discutais de l'analyse d'un ensemble de données de crawl avec un de mes amis. Il est physicien et effectue des recherches postdoctorales sur les ordinateurs quantiques. Ses connaissances et ses compétences en mathématiques et en statistiques sont bien au-delà des miennes, et il sait vraiment comment analyser les données bien mieux que moi. Un problème. Il ne savait pas ce qu'était un « 404 » (ou pourquoi nous nous soucierions d'un « 301 »). Ainsi, avec toutes ses connaissances en mathématiques, il n'a pas été en mesure de donner un sens à la colonne "statut" dans l'ensemble de données d'exploration. Naturellement, il ne saurait pas quoi faire de ces données, à qui parler et quelles stratégies élaborer en fonction de ces codes de statut (ou s'il faut chercher ailleurs). Vous et moi savons quoi en faire, ou du moins nous savons où chercher si nous voulons creuser plus profondément.
- Mathématiques et statistiques : si vous utilisez Excel pour obtenir la moyenne d'un échantillon de données, vous utilisez des statistiques. La moyenne est une statistique qui décrit un certain aspect d'un échantillon de données. Des statistiques plus avancées aideront à comprendre vos données. C'est essentiel aussi, et je ne suis pas un expert dans ce domaine. Plus vous connaissez les distributions statistiques, plus vous avez d'idées sur la façon d'analyser les données. Plus vous connaissez des sujets fondamentaux, mieux vous arrivez à formuler vos hypothèses et à faire des déclarations précises sur vos ensembles de données.
- Compétences en programmation : j'en discuterai plus en détail ci-dessous, mais c'est principalement là que vous construisez la flexibilité de dire à l'ordinateur de faire exactement ce que vous voulez qu'il fasse, au lieu d'être coincé avec des outils faciles à utiliser mais légèrement restrictifs. outils. C'est votre principal moyen d'obtenir, de remodeler et de nettoyer vos données, comme vous le souhaitez, vous ouvrant la voie à des «conversations» ouvertes et flexibles avec vos données.
Voyons maintenant ce que nous faisons habituellement en Data Science.
Le cycle de la science des données
Un projet ou même une tâche typique de science des données ressemble généralement à ceci :
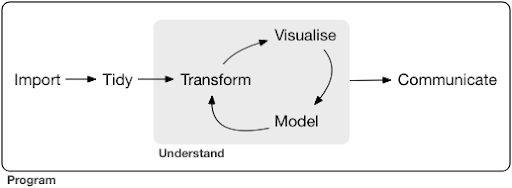
Source : r4ds.had.co.nz
Je recommande également fortement la lecture de ce livre de Hadley Wickham et Garrett Grolemund qui constitue une excellente introduction à la science des données. Il est écrit avec des exemples du langage de programmation R, mais les concepts et le code peuvent facilement être compris si vous ne connaissez que Python.
Comme vous pouvez le voir dans le diagramme, nous devons d'abord importer nos données d'une manière ou d'une autre, les ranger, puis commencer à travailler sur le cycle interne de transformation, visualisation et modélisation. Après cela, nous communiquons les résultats aux autres.
Ces étapes peuvent aller d'extrêmement simples à très complexes. Par exemple, l'étape « Importer » peut être aussi simple que la lecture d'un fichier CSV et, dans certains cas, peut consister en un projet de grattage Web très compliqué pour obtenir les données. Plusieurs des éléments du processus sont des spécialités à part entière.
Nous pouvons facilement mapper cela à certains processus familiers que nous connaissons. Par exemple, vous pouvez commencer par obtenir des métadonnées sur un site Web, en téléchargeant son fichier robots.txt et son sitemap XML. Vous exploreriez alors probablement et obtiendriez peut-être aussi des données sur les positions SERP, ou des données de lien par exemple. Maintenant que vous disposez de quelques ensembles de données, vous souhaitez probablement fusionner certaines tables, imputer des données supplémentaires et commencer à explorer/comprendre. La visualisation des données peut révéler des modèles cachés, ou vous aider à comprendre ce qui se passe, ou peut-être soulever plus de questions. Vous souhaitez probablement également modéliser vos données à l'aide de statistiques de base ou de modèles d'apprentissage automatique et, espérons-le, obtenir des informations. Bien sûr, vous devez communiquer les résultats et les questions aux autres parties prenantes du projet.
Une fois que vous êtes suffisamment familiarisé avec les différents outils disponibles pour chacun de ces processus, vous pouvez commencer à créer vos propres pipelines personnalisés spécifiques à un certain site Web, car chaque entreprise est unique et a un ensemble d'exigences particulières. Finalement, vous commencerez à trouver des modèles et n'aurez pas à refaire tout le travail pour des projets/sites Web similaires.
Il existe de nombreux outils et bibliothèques disponibles pour chaque élément de ce processus et il peut être assez difficile de choisir l'outil que vous choisissez (et d'investir votre temps dans l'apprentissage). Jetons un coup d'œil à une approche possible que je trouve utile dans la sélection des outils que j'utilise.
Choix d'outils et compromis (3 façons de manger une pizza)
Devriez-vous utiliser Excel pour votre travail quotidien de traitement de données, ou vaut-il la peine d'apprendre Python ?
Vaut-il mieux visualiser avec quelque chose comme Power BI, ou devriez-vous investir dans l'apprentissage de la grammaire des graphiques et apprendre à utiliser les bibliothèques qui l'implémentent ?
Produiriez-vous un meilleur travail en créant vos propres tableaux de bord interactifs avec R ou Python, ou devriez-vous simplement opter pour Google Data Studio ?
Explorons d'abord les compromis impliqués dans la sélection de divers outils à différents niveaux d'abstraction. Ceci est un extrait de mon livre sur la création de tableaux de bord interactifs et d'applications de données avec Plotly et Dash et je trouve cette approche utile :
Envisagez trois approches différentes pour manger une pizza :
- L'approche de commande : Vous appelez un restaurant et commandez votre pizza. Il arrive à votre porte dans une demi-heure et vous commencez à manger.
- L'approche du supermarché : Vous allez dans un supermarché, achetez de la pâte, du fromage, des légumes et tous les autres ingrédients. Vous faites ensuite la pizza vous-même.
- L'approche de la ferme : Vous cultivez des tomates dans votre jardin. Vous élevez des vaches, les traitez et transformez le lait en fromage, etc.
Au fur et à mesure que nous montons vers des interfaces de niveau supérieur, vers l'approche de commande, la quantité de connaissances requises diminue beaucoup. Quelqu'un d'autre en détient la responsabilité et la qualité est contrôlée par les forces du marché que sont la réputation et la concurrence.
Le prix que nous payons pour cela est la diminution de la liberté et des options. Chaque restaurant a un ensemble d'options à choisir, et vous devez choisir parmi ces options.
En descendant vers les niveaux inférieurs, la quantité de connaissances requises augmente, nous devons gérer plus de complexité, nous sommes plus responsables des résultats et cela prend beaucoup plus de temps. Ce que nous gagnons ici, c'est beaucoup plus de liberté et de pouvoir pour personnaliser nos résultats comme nous le souhaitons. Le coût est également un avantage majeur, mais seulement à une échelle suffisamment grande. Si vous ne voulez qu'une pizza aujourd'hui, il est probablement moins cher de la commander. Mais si vous prévoyez d'en avoir un tous les jours, vous pouvez vous attendre à des économies importantes si vous le faites vous-même.
Ce sont les types de choix que vous devrez faire lorsque vous choisirez les outils à utiliser et à apprendre. L'utilisation d'un langage de programmation comme R ou Python nécessite beaucoup plus de travail et est plus difficile qu'Excel, avec l'avantage de vous rendre beaucoup plus productif et puissant.
Le choix est également important pour chaque outil ou processus. Par exemple, vous pouvez utiliser un robot d'exploration de haut niveau et facile à utiliser pour collecter des données sur un site Web, et pourtant vous préférerez peut-être utiliser un langage de programmation pour visualiser les données, avec toutes les options disponibles. Le choix du bon outil pour le bon processus dépend de vos besoins et le compromis décrit ci-dessus peut, espérons-le, vous aider à faire ce choix. Cela aide également, espérons-le, à répondre à la question de savoir si oui ou non (ou combien) Python ou R vous voulez apprendre.
Poussons cette question un peu plus loin et voyons pourquoi apprendre Python pour le référencement n'est peut-être pas le bon mot-clé.
Pourquoi "python pour le référencement" est trompeur
Voudriez-vous devenir un grand blogueur ou voulez-vous apprendre WordPress ?
Souhaitez-vous devenir graphiste ou votre objectif est-il d'apprendre Photoshop ?
Êtes-vous intéressé à dynamiser votre carrière SEO en faisant passer vos compétences en données au niveau supérieur, ou souhaitez-vous apprendre Python ?
Dans les cinq premières minutes du premier cours magistral du cours d'informatique au MIT, le professeur Harold Abelson ouvre le cours en expliquant aux étudiants pourquoi "l'informatique" est une si mauvaise réputation pour la discipline qu'ils sont sur le point d'apprendre. Je pense qu'il est très intéressant de regarder les cinq premières minutes de la conférence :
Lorsqu'un domaine ne fait que commencer et que vous ne le comprenez pas très bien, il est très facile de confondre l'essence de ce que vous faites avec les outils que vous utilisez. – Harold Abelson
Nous essayons d'améliorer notre présence en ligne et nos résultats, et une grande partie de ce que nous faisons est basée sur la compréhension, la visualisation, la manipulation et le traitement des données en général, et c'est notre objectif, quel que soit l'outil utilisé. La science des données est le domaine qui dispose des cadres intellectuels pour le faire, ainsi que de nombreux outils pour mettre en œuvre ce que nous voulons faire. Python pourrait être votre langage de programmation (outil) de choix, et il est certainement important de bien l'apprendre. Il est aussi important, sinon plus important, de se concentrer sur « l'essence de ce que vous faites », le traitement et l'analyse des données, dans notre cas.
L'accent devrait être mis sur les processus décrits ci-dessus (importation, rangement, visualisation, etc.), par opposition au langage de programmation de votre choix. Ou mieux, comment utiliser ce langage de programmation pour accomplir vos tâches, par opposition au simple apprentissage d'un langage de programmation.
Qui se soucie de toutes ces distinctions théoriques si je dois quand même apprendre Python ?
Jetons un coup d'œil à ce qui pourrait arriver si vous vous concentrez sur l'apprentissage de l'outil, par opposition à l'essence de ce que vous faites. Ici, nous comparons la recherche de « apprendre wordpress » (l'outil) et « apprendre le blogging » (la chose que nous voulons faire) :
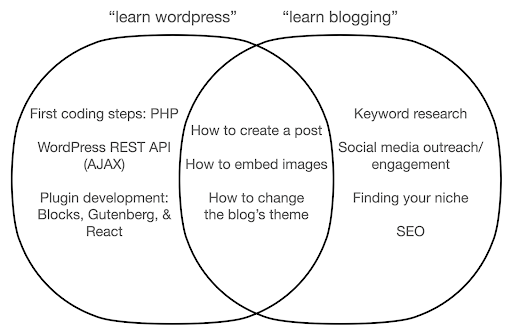
Le diagramme montre les sujets possibles sous un livre ou un cours qui enseigne le mot-clé en haut. La zone d'intersection au milieu montre les sujets qui peuvent apparaître dans les deux types de cours/livre.
Si vous vous concentrez sur l'outil, vous finirez sans doute par apprendre des choses dont vous n'avez pas vraiment besoin, surtout en tant que débutant. Ces sujets peuvent vous dérouter et vous frustrer, surtout si vous n'avez aucune formation technique ou en programmation.
Vous apprendrez également des choses utiles pour devenir un bon blogueur (les sujets dans la zone d'intersection). Ces sujets sont extrêmement faciles à enseigner (comment créer un article de blog), mais ne vous disent pas grand-chose sur pourquoi vous devriez bloguer, quand et sur quoi. Ce n'est pas un défaut dans un livre axé sur les outils, car lors de l'apprentissage d'un outil, il suffirait d'apprendre à créer un article de blog et de passer à autre chose.
En tant que blogueur, vous êtes probablement plus intéressé par le quoi et le pourquoi du blogging, et cela ne serait pas couvert dans les livres axés sur les outils.
De toute évidence, les éléments stratégiques et importants tels que le référencement, la recherche de votre créneau, etc. ne seront pas couverts, vous manqueriez donc des éléments très importants.
Quels sont certains des sujets de science des données que vous n'apprendrez probablement pas dans un livre de programmation ?
Comme nous l'avons vu, prendre un Python ou un livre de programmation signifie probablement que vous voulez devenir ingénieur logiciel. Les sujets seraient naturellement orientés vers cette fin. Si vous recherchez un livre sur la science des données, vous obtenez des sujets et des outils plus axés sur l'analyse des données.
Nous pouvons utiliser le premier diagramme (montrant le cycle de la science des données) comme guide et rechercher de manière proactive ces sujets : "importer des données avec python", "ranger des données avec r", "visualiser des données avec python", etc. Examinons ces sujets plus en profondeur et explorons-les davantage :
Importer
Naturellement, nous devons d'abord obtenir des données. Cela peut être:
- Un fichier sur notre ordinateur : le cas le plus simple où vous ouvrez simplement le fichier avec le langage de programmation de votre choix. Il est important de noter qu'il existe de nombreux formats de fichiers différents et que vous disposez de nombreuses options lors de l'ouverture/de la lecture des fichiers. Par exemple, la fonction read_csv de la bibliothèque pandas (un outil de manipulation de données essentiel en Python) propose une cinquantaine d'options lors de l'ouverture du fichier. Il contient des éléments tels que le chemin du fichier, les colonnes à choisir, le nombre de lignes à ouvrir, l'interprétation des objets datetime, la gestion des valeurs manquantes et bien d'autres. Il est important de se familiariser avec ces options et les diverses considérations lors de l'ouverture de différents formats de fichiers. De plus, pandas a dix-neuf fonctions différentes qui commencent par read_ pour divers formats de fichiers et de données.
- Exporter à partir d'un outil en ligne : vous êtes probablement familier avec cela, et ici vous pouvez personnaliser vos données, puis les exporter, après quoi vous les ouvrirez sous forme de fichier sur votre ordinateur.
- Appels d'API pour obtenir des données spécifiques : il s'agit d'un niveau inférieur, et plus proche de l'approche de ferme mentionnée ci-dessus. Dans ce cas, vous envoyez une demande avec des exigences spécifiques et récupérez les données que vous souhaitez. L'avantage ici est que vous pouvez personnaliser exactement ce que vous voulez obtenir et le formater d'une manière qui pourrait ne pas être disponible dans l'interface en ligne. Par exemple, dans Google Analytics, vous pouvez ajouter une dimension secondaire à un tableau que vous analysez, mais vous ne pouvez pas en ajouter une troisième. Vous êtes également limité par le nombre de lignes que vous pouvez exporter. L'API vous offre plus de flexibilité et vous pouvez également automatiser certains appels pour qu'ils se produisent périodiquement, dans le cadre d'un pipeline de collecte/analyse de données plus large.
- Explorer et récupérer des données : vous avez probablement votre robot d'exploration préféré et vous êtes probablement familiarisé avec le processus. Il s'agit déjà d'un processus flexible, nous permettant d'extraire des éléments personnalisés des pages, d'explorer certaines pages uniquement, etc.
- Une combinaison de méthodes impliquant l'automatisation, l'extraction personnalisée et éventuellement l'apprentissage automatique pour des utilisations spéciales.
Une fois que nous avons des données, nous voulons passer au niveau suivant.
Bien rangé
Un jeu de données « rangé » est un jeu de données organisé d'une certaine manière. On parle aussi de données « format long ». Le chapitre 12 du livre R for Data Science aborde plus en détail le concept de données ordonnées si cela vous intéresse.
Jetez un œil aux trois tableaux ci-dessous et essayez de trouver les différences :
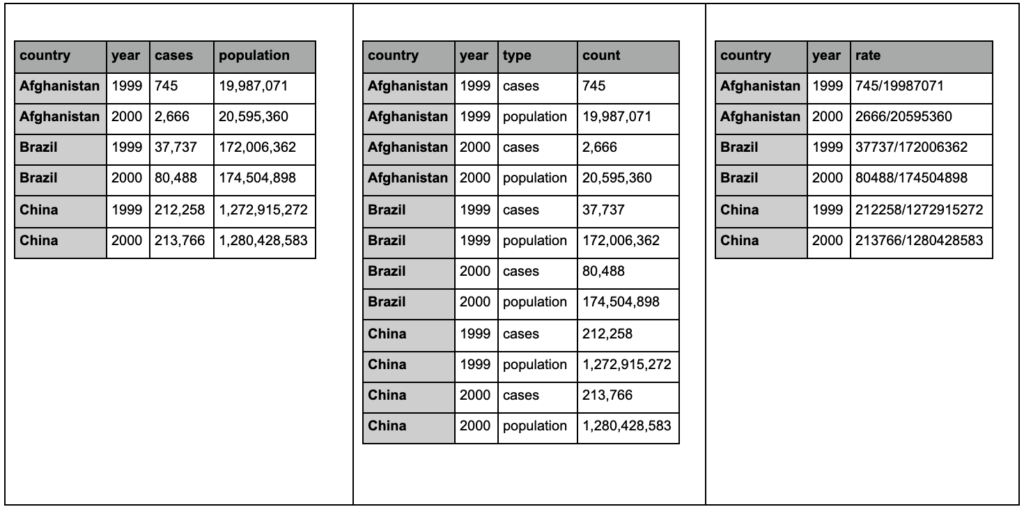
Exemples de tableaux du package tidyr.
Vous constaterez que les trois tableaux contiennent exactement les mêmes informations, mais organisées et présentées de différentes manières. Nous pouvons avoir les cas et la population dans deux colonnes distinctes (tableau 1), ou avoir une colonne pour nous dire quelle est l'observation (cas ou population), et une colonne « décompte » pour compter ces cas (tableau 2). Dans le tableau 3, ils sont présentés sous forme de taux.
Lorsque vous traitez des données, vous constaterez que différentes sources organisent les données différemment et que vous devrez souvent changer de/vers certains formats pour une analyse meilleure et plus facile. Connaître ces opérations de nettoyage est crucial, et le package tidyr de R contient des outils spéciaux pour cela. Vous pouvez également utiliser des pandas si vous préférez Python, et vous pouvez consulter les fonctions de fusion et de pivot pour cela.
Une fois que nos données sont dans un certain format, nous pourrions vouloir les manipuler davantage.
Transformer
Une autre compétence cruciale à développer est la capacité d'apporter les modifications souhaitées aux données avec lesquelles vous travaillez. Le scénario idéal est d'atteindre le stade où vous pouvez avoir des conversations avec vos données et être capable de trancher et de découper comme vous le souhaitez pour poser des questions très spécifiques et, espérons-le, obtenir des informations intéressantes. Voici quelques-unes des tâches de transformation les plus importantes dont vous aurez probablement besoin avec quelques exemples de tâches qui pourraient vous intéresser :
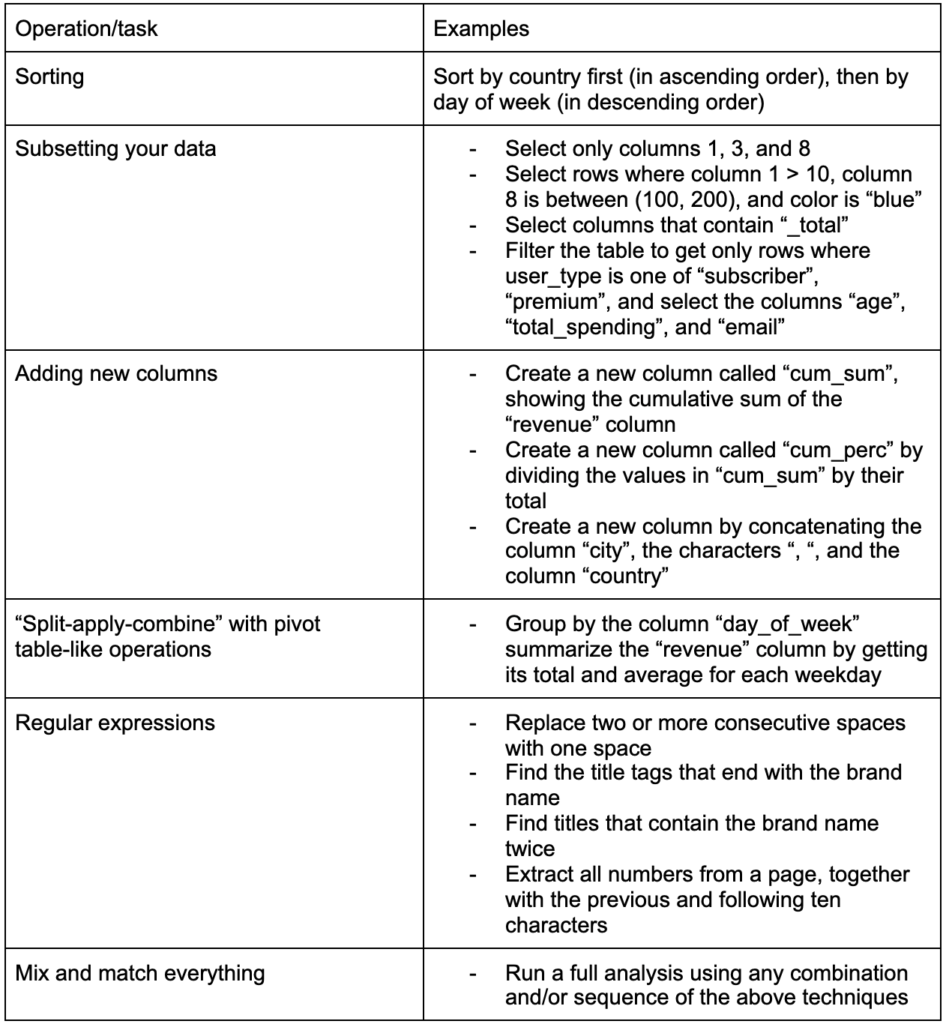
Après avoir récupéré, rangé et mis nos données dans le format souhaité, il serait bon de les visualiser.
Visualiser
La visualisation des données est un vaste sujet, et il existe des livres entiers sur certains de ses sous-sujets. C'est l'une de ces choses qui peuvent fournir beaucoup d'informations sur nos données, en particulier parce qu'elles utilisent des éléments visuels intuitifs pour communiquer des informations. La hauteur relative des barres dans un graphique à barres nous montre immédiatement leur quantité relative par exemple. L'intensité de la couleur, l'emplacement relatif et de nombreux autres attributs visuels sont facilement reconnaissables et compris par les lecteurs.
Un bon tableau vaut mille mots (clés) !
Comme il y a de nombreux sujets à parcourir sur la visualisation de données, je vais simplement partager quelques exemples qui pourraient être intéressants. Plusieurs d'entre eux sont les éléments constitutifs de ce tableau de bord des données sur la pauvreté, si vous voulez tous les détails.
Un simple graphique à barres est parfois tout ce dont vous pourriez avoir besoin pour comparer les valeurs, où les barres peuvent être affichées verticalement ou horizontalement :
Vous pourriez être intéressé à explorer certains pays et à creuser plus profondément en voyant comment ils ont progressé sur certaines mesures. Dans ce cas, vous souhaiterez peut-être afficher plusieurs graphiques à barres dans le même tracé :
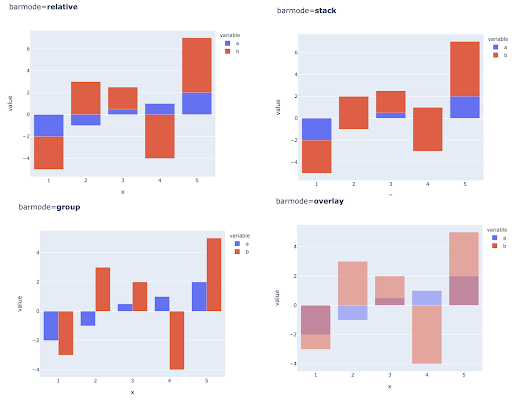
La comparaison de plusieurs valeurs pour plusieurs observations peut également être effectuée en plaçant plusieurs barres dans chaque position de l'axe X, voici les principales façons de procéder :
Choix de couleurs et d'échelles de couleurs : un élément essentiel de la visualisation des données, et quelque chose qui peut communiquer des informations de manière extrêmement efficace et intuitive s'il est bien fait.
Échelles de couleurs catégorielles : utiles pour exprimer des données catégorielles. Comme son nom l'indique, il s'agit du type de données qui indique à quelle catégorie appartient une certaine observation. Dans ce cas, nous voulons des couleurs aussi distinctes que possible les unes des autres pour montrer des différences claires dans les catégories (en particulier pour les éléments visuels affichés les uns à côté des autres).
L'exemple suivant utilise une échelle de couleurs catégorielle pour montrer quel système de gouvernement est mis en œuvre dans chaque pays. Il est assez facile de relier les couleurs des pays à la légende qui indique quel système de gouvernement est utilisé. Ceci est également appelé une carte choroplèthe :
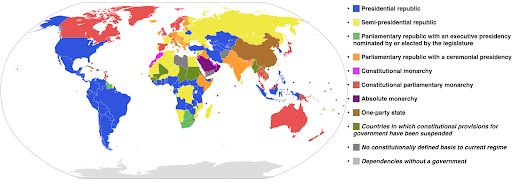
Source : Wikipédia
Parfois, les données que nous voulons visualiser concernent la même métrique, et chaque pays (ou tout autre type d'observation) tombe sur un certain point dans un continuum compris entre les points minimum et maximum. En d'autres termes, nous voulons visualiser les degrés de cette métrique.
Dans ces cas, nous devons trouver une échelle de couleurs continue (ou séquentielle) . Il est immédiatement clair dans l'exemple suivant quels pays sont plus bleus (et donc obtiennent plus de trafic), et nous pouvons intuitivement comprendre les différences nuancées entre les pays.
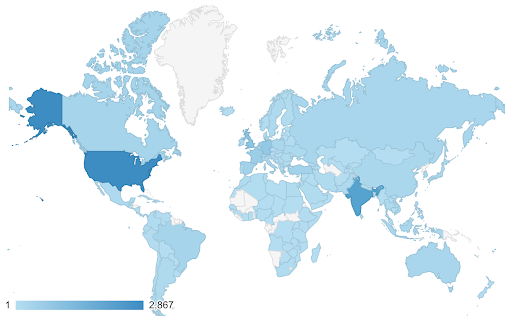

Vos données peuvent être continues (comme le graphique de la carte du trafic ci-dessus), mais la chose importante à propos des chiffres peut être leur degré de divergence à partir d'un certain point. Les échelles de couleurs divergentes sont utiles dans ce cas.
Le graphique ci-dessous montre les taux nets de croissance démographique. Dans ce cas, il est intéressant de savoir d'abord si oui ou non un certain pays a un taux de croissance positif ou négatif. Ou, nous voulons savoir à quelle distance chaque pays est de zéro (et de combien). Un coup d'œil sur la carte nous montre immédiatement quels pays la population augmente et laquelle diminue. La légende nous montre également que le taux positif maximum est de 3,5% et que le taux négatif maximum est de -0,5%. Cela nous donne également une indication sur la plage de valeurs (positives et négatives).
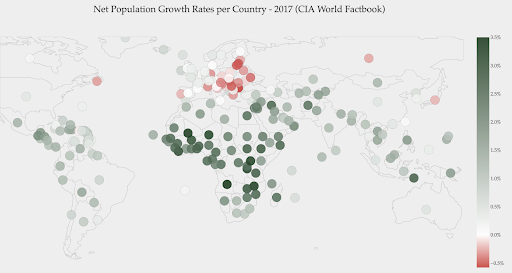
Source : Dashboardom.com
Malheureusement, les couleurs choisies pour cette échelle ne sont pas idéales, car les personnes daltoniennes pourraient ne pas être en mesure de distinguer correctement le rouge et le vert. C'est une considération très importante lors du choix de nos gammes de couleurs.
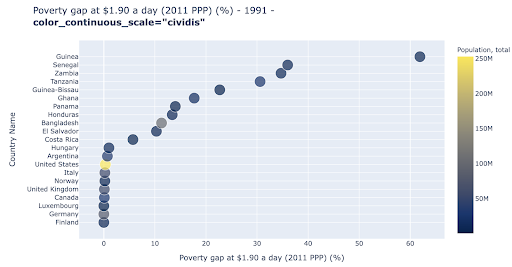
Le nuage de points est l'un des types de tracé les plus utilisés et les plus polyvalents. La position des points (ou de tout autre marqueur) traduit la quantité que nous essayons de communiquer. En plus de la position, nous pouvons utiliser plusieurs autres attributs visuels comme la couleur, la taille et la forme pour communiquer encore plus d'informations. L'exemple suivant montre le pourcentage de la population vivant à 1,9 $/jour, que nous pouvons clairement voir comme la distance horizontale des points.
Nous pouvons également ajouter une nouvelle dimension à notre graphique en utilisant la couleur. Cela correspond à la visualisation d'une troisième colonne du même ensemble de données, qui dans ce cas affiche les données de population.
Nous pouvons maintenant voir que le cas le plus extrême en termes de population (États-Unis) est très bas sur la métrique du niveau de pauvreté. Cela ajoute de la richesse à nos cartes. Nous aurions également pu utiliser la taille et la forme pour visualiser encore plus de colonnes de notre ensemble de données. Il faut cependant trouver un bon équilibre entre richesse et lisibilité.
Nous pourrions être intéressés à vérifier s'il existe une relation entre la population et les niveaux de pauvreté, et ainsi nous pouvons visualiser le même ensemble de données d'une manière légèrement différente pour voir si une telle relation existe :
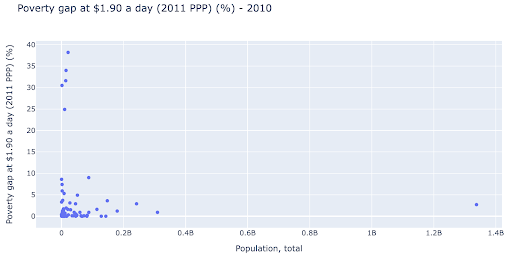
Nous avons une valeur aberrante dans la population à environ 1,35 milliard, ce qui signifie que nous avons beaucoup d'espaces blancs dans le graphique, ce qui signifie également que de nombreuses valeurs sont comprimées dans une très petite zone. Nous avons également de nombreux points qui se chevauchent, ce qui rend très difficile la détection de différences ou de tendances.
Le graphique suivant contient les mêmes informations mais visualisées différemment à l'aide de deux techniques :
- Échelle logarithmique : Nous voyons généralement des données sur une échelle additive. En d'autres termes, chaque point sur l'axe (X ou Y) représente une addition d'une certaine quantité de données visualisées. Nous pouvons également avoir des échelles multiplicatives, auquel cas pour chaque nouveau point sur l'axe X, nous multiplions (par dix dans cet exemple). Cela permet d'étaler les points et nous devons penser aux multiples plutôt qu'aux additions, comme nous l'avions fait dans le tableau précédent.
- Utilisation d'un marqueur différent (cercles vides plus grands) : la sélection d'une forme différente pour nos marqueurs a résolu le problème de "sur-tracé" où nous pourrions avoir plusieurs points les uns sur les autres au même endroit, ce qui rend même très difficile à voir combien de points nous avons.
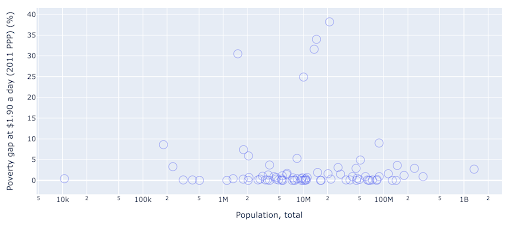
Nous pouvons maintenant voir qu'il existe un groupe de pays autour de la barre des 10 millions, ainsi que d'autres groupes plus petits.
Comme je l'ai mentionné, il existe de nombreux autres types de caractères et d'options de visualisation, ainsi que des livres entiers écrits sur le sujet. J'espère que cela vous donne quelques réflexions intéressantes à expérimenter.
Oncrawl Data³
 Apprendre encore plus
Apprendre encore plusModèle
Nous devons simplifier nos données et trouver des modèles, faire des prédictions ou simplement mieux les comprendre. Ceci est un autre sujet important, et peut aller de la simple obtention de statistiques sommaires (moyenne, médiane, écart type, etc.), à la modélisation visuelle de nos données, en utilisant un modèle qui résume ou trouve une tendance, à l'utilisation de techniques plus complexes pour obtenir un formule mathématique pour nos données. Nous pouvons également utiliser l'apprentissage automatique pour nous aider à découvrir plus d'informations dans nos données.
Encore une fois, ce n'est pas une discussion complète sur le sujet, mais j'aimerais partager quelques exemples où vous pourriez utiliser des techniques d'apprentissage automatique pour vous aider.
Dans un ensemble de données de crawl, j'essayais d'en savoir un peu plus sur les 404 pages, et si je pouvais découvrir quelque chose à leur sujet. Ma première tentative a été de vérifier s'il y avait une corrélation entre la taille de la page et son code d'état, et il y avait - une corrélation presque parfaite !
Je me suis senti comme un génie, pendant quelques minutes, et je suis rapidement revenu sur la planète Terre.
Les 404 pages étaient toutes dans une plage de taille de page très étroite, presque toutes les pages avec un certain nombre de kilo-octets avaient un code d'état 404. Puis j'ai réalisé que les pages 404, par définition, n'ont pas de contenu autre que, eh bien, une "page d'erreur 404" ! Et c'est pourquoi ils avaient la même taille.
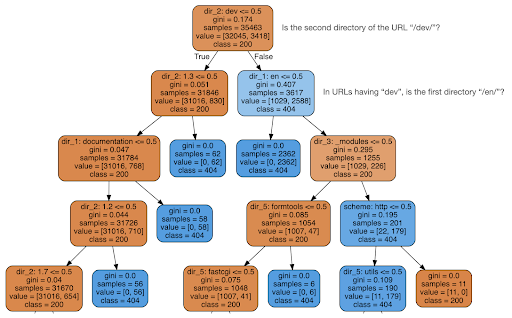
J'ai ensuite décidé de vérifier si le contenu pouvait me dire quelque chose sur le code d'état, j'ai donc divisé les URL en leurs éléments et exécuté un classificateur d'arbre de décision à l'aide de sklearn. Il s'agit essentiellement d'une technique qui produit un arbre de décision, où suivre ses règles pourrait nous amener à apprendre à trouver notre cible, 404 pages dans ce cas.
Dans l'arbre de décision suivant, la première ligne de chaque case indique la règle à suivre ou à vérifier, la ligne "échantillons" est le nombre d'observations trouvées dans cette case, et la ligne "classe" nous indique la classe de l'observation actuelle , dans ce cas, que son code d'état soit 200 ou 404.
Je n'entrerai pas dans plus de détails, et je sais que l'arbre de décision peut ne pas être clair si vous ne les connaissez pas, et vous pouvez explorer l'ensemble de données d'analyse brute et le code d'analyse si vous êtes intéressé.
Fondamentalement, ce que l'arbre de décision a découvert, c'est comment trouver presque toutes les 404 pages, en utilisant la structure de répertoire des URL. Comme vous pouvez le voir, nous avons trouvé 3 617 URL, simplement en vérifiant si oui ou non le deuxième répertoire de l'URL était "/dev/" (première case bleu clair dans la deuxième ligne à partir du haut). Nous savons maintenant comment localiser nos 404, et il semble qu'ils se trouvent presque tous dans la section "/dev/" du site. C'était définitivement un énorme gain de temps. Imaginez parcourir manuellement toutes les structures et combinaisons d'URL possibles pour trouver cette règle.
Nous n'avons toujours pas une image complète et pourquoi cela se produit, et cela peut être approfondi, mais au moins nous avons maintenant très facilement localisé ces URL.
Une autre technique qui pourrait vous intéresser est le clustering KMeans, qui regroupe les points de données en différents groupes/clusters. Il s'agit d'une technique « d'apprentissage non supervisé », où l'algorithme nous aide à découvrir des modèles dont nous ignorons l'existence.
Imaginez que vous ayez un tas de chiffres, disons la population des pays, et que vous vouliez les regrouper en deux groupes, grands et petits. Comment feriez-vous cela? Où traceriez-vous la ligne ?
C'est différent d'obtenir les dix premiers pays ou les X% des meilleurs pays. Ce serait très facile, nous pouvons trier les pays par population et obtenir les X premiers comme nous le voulons.
Ce que nous voulons, c'est les regrouper en « grands » et « petits » par rapport à cet ensemble de données, et en supposant que nous ne savons rien sur les populations des pays.
Cela peut être étendu plus loin en essayant de regrouper les pays en trois catégories : petits, moyens et grands. Cela devient beaucoup plus difficile à faire manuellement, si nous voulons cinq, six groupes ou plus.
Notez que nous ne savons pas combien de pays se retrouveront dans chaque groupe, puisque nous ne demandons pas les X premiers pays. En regroupant en deux clusters, nous pouvons voir que nous n'avons que deux pays dans le grand groupe : la Chine et l'Inde. Cela a un sens intuitif, car ces deux pays ont une population moyenne très éloignée de tous les autres pays. Ce groupe de pays a sa propre moyenne et ses pays sont plus proches les uns des autres que les pays de l'autre groupe :
Pays regroupés en deux groupes selon la population 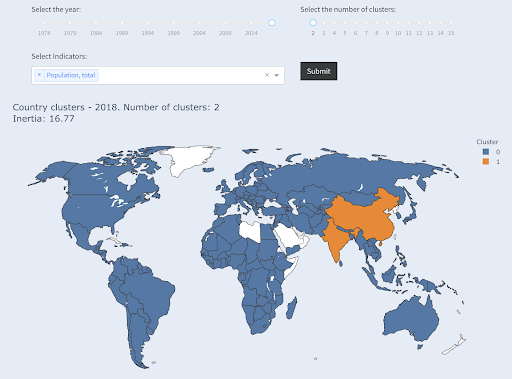
Le troisième plus grand pays en termes de population (USA ~ 330M) a été regroupé avec tous les autres, y compris les pays qui ont une population d'un million d'habitants. C'est parce que 330M est beaucoup plus proche de 1M que de 1,3 milliard. Si nous avions demandé trois clusters, nous aurions obtenu une image différente :
Pays regroupés en trois groupes selon la population 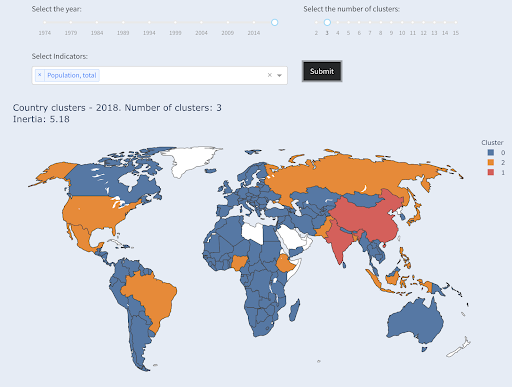
Et voici comment les pays seraient regroupés si nous demandions quatre clusters :
Pays regroupés en quatre groupes selon la population 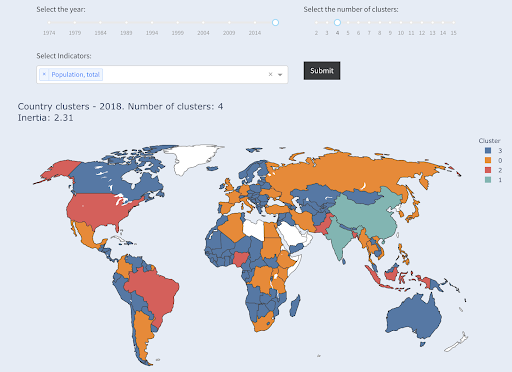
Source : Povertydata.org (onglet "pays du cluster")
Il s'agissait d'un regroupement en utilisant une seule dimension - la population - dans ce cas, et vous pouvez également ajouter d'autres dimensions et voir où les pays finissent.
Il existe de nombreuses autres techniques et outils, et ce ne sont là que quelques exemples qui, espérons-le, sont intéressants et pratiques.
Nous sommes maintenant prêts à communiquer nos découvertes à notre public.
Communiquer
Après tout le travail que nous avons effectué dans les étapes précédentes, nous devons éventuellement communiquer nos résultats aux autres parties prenantes du projet.
L'un des outils les plus importants en science des données est le cahier interactif. Le bloc-notes Jupyter est le plus utilisé et prend en charge à peu près tous les langages de programmation. Vous préférerez peut-être utiliser le format de bloc-notes spécial de RStudio, qui fonctionne de la même manière.
L'idée principale est d'avoir des données, du code, des récits et des visualisations en un seul endroit, afin que d'autres personnes puissent les auditer. Il est important de montrer comment vous êtes arrivé à ces conclusions et recommandations pour la transparence, ainsi que la reproductibilité. D'autres personnes devraient pouvoir exécuter le même code et obtenir les mêmes résultats.
Une autre raison importante est la possibilité pour les autres, y compris le « futur vous », de pousser l'analyse plus loin et de s'appuyer sur le travail initial que vous avez effectué, de l'améliorer et de l'étendre de nouvelles manières.
Bien sûr, cela suppose que le public soit à l'aise avec le code, et qu'il s'en soucie même !
Vous avez également la possibilité d'exporter vos blocs-notes au format HTML (et plusieurs autres formats), à l'exclusion du code, de sorte que vous vous retrouvez avec un rapport convivial, tout en conservant le code complet pour reproduire la même analyse et les mêmes résultats.
Un élément important de la communication est la visualisation des données, qui a également été brièvement abordée ci-dessus.
Encore mieux, la visualisation interactive des données, auquel cas vous permettez à votre public de sélectionner des valeurs et de consulter diverses combinaisons de graphiques et de mesures pour explorer encore plus les données.
Voici quelques tableaux de bord et applications de données (certains d'entre eux peuvent prendre quelques secondes à charger) que j'ai créés pour vous donner une idée de ce qui peut être fait.
Finalement, vous pouvez également créer des applications personnalisées pour vos projets, afin de répondre à des besoins et exigences particuliers, et voici un autre ensemble d'applications de référencement et de marketing qui pourraient vous intéresser.
Nous avons parcouru les principales étapes du cycle Data Science, et explorons maintenant un autre avantage de "l'apprentissage de python".
Python est pour l'automatisation et la productivité : vrai mais incomplet
Il me semble que l'on croit que l'apprentissage de Python sert principalement à obtenir des tâches productives et/ou automatisées.
C'est absolument vrai, et je ne pense pas que nous ayons besoin de discuter de la valeur de pouvoir faire quelque chose en une fraction du temps qu'il nous faudrait pour le faire manuellement.
L'autre partie manquante de l'argument est l'analyse des données . Une bonne analyse des données nous fournit des informations et, idéalement, nous sommes en mesure de fournir des informations exploitables pour guider notre processus de prise de décision, en fonction de notre expertise et des données dont nous disposons.
Une grande partie de ce que nous faisons consiste à essayer de comprendre ce qui se passe, d'analyser la concurrence, de déterminer où se trouve le contenu le plus précieux, de décider quoi faire, etc. Nous sommes des consultants, des conseillers et des décideurs. Pouvoir obtenir des informations à partir de nos données est clairement un avantage considérable, et les domaines et compétences mentionnés ici peuvent nous aider à y parvenir.
Et si vous appreniez que vos balises de titre ont une longueur moyenne de soixante caractères, est-ce bien ?
Et si vous creusiez un peu plus et découvriez que la moitié de vos titres ont bien moins de soixante ans, tandis que l'autre moitié a beaucoup plus de personnages (soit une moyenne de soixante) ? In order to get practical and provide good recommendations, you need a higher-resolution view of your title tags' lengths, probably a histogram that shows the frequency of your title tag lengths at each interval so you can have a separate strategy for length. A simple table would also do, for example:
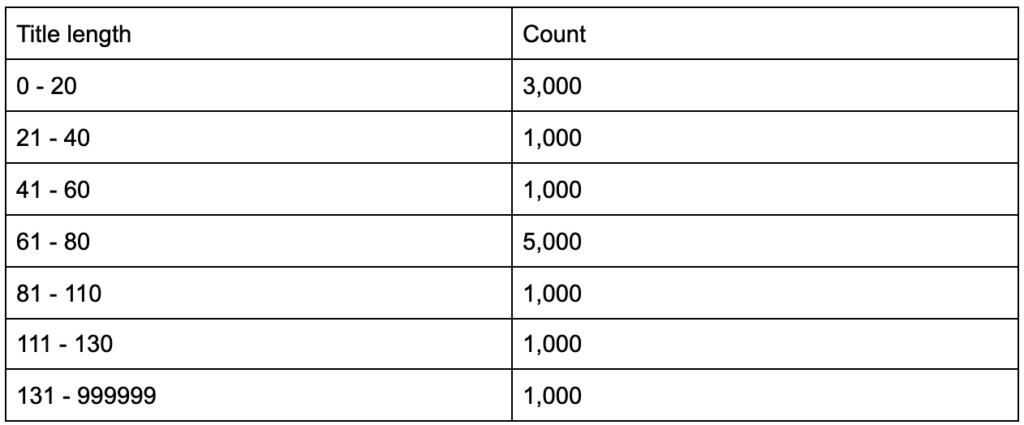
Splitting title lengths by intervals of twenty was an arbitrary decision, and you can split them the way you want. Looking at the table above, and seeing that we have three times more than the average titles in the interval (0, 20), we might want to split it further to better understand what is going on.
Having a better view than the default single-statistic summaries that we get from standard tools, allows us to employ different strategies for different lengths. For example, we can remove the brand name from the titles that are longer than a certain number of characters, and keep it in other titles.
This was an example of very simple insights, which are possible due to the flexibility we get by using a programming language, and a set of data science tools. This also allows us to iterate and modify our approach, until we find a satisfactory point that can take our analysis to the next steps.
Visualization, machine learning, modeling and general data manipulation skills allow us to get better insights on our data, even though those analyses are typically done only once. Still, if you use code to get those insights, you can always take some parts and apply to other projects, or again to the same project. In this case, the insights we got, helped us in our automation, even more. The insights would tell us what needs to be automated and what doesn't.
Should you learn Python?
Is a useless question, and the more useful one is, “How much Python (or R) should you learn?”
My view of how we use computers has evolved in the last few years.
I used to think that there were two main ways of using computers, either you are a regular user, using “point-and-click” applications to do certain tasks, or you are a developer who creates those applications that the rest of us use.

I then realized that it is more like a continuum between very high level use (pizza ordering approach), and the lower levels of the farm approach. I also realized that there is a happy sweet spot in between, where you learn enough programming to get productive and boost your data analysis skills, without having to become a software developer or engineer.
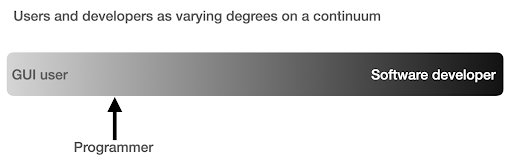
What are the main differences between being a programmer (a software user), and a software developer (or engineer)?
What are the differences between making a great coffee at home, versus establishing and running a cafe?
If making good coffee is one skill, then running a cafe requires ten other skills, most of which have nothing to do with making coffee.
You have to choose a good location (real estate), hire people (management and HR), manage cash flow and finances (accounting and finance), do marketing, legal, manage delivery, adhere to cleanliness and health standards, and so on. You can be a great coffee maker without knowing anything about those fields, but if you want to take it to the next level, you will have to manage all those additional tasks unrelated to making coffee.
The same applies to being a good programmer or data analyst versus being a software developer/engineer. There are so many other things that you have to know and worry about that you don't need as a regular programmer doing stuff for yourself and co-workers and clients. Once you have enough knowledge and skills in programming and data science, you will be in a good position to choose and decide whether you want to continue as an analyst, focusing on data science, or if you want to end up creating software that other people would use.
How do I get into Data Science?
To learn anything I think you have to do two things in parallel:
- Learn the fundamentals and the theory properly: Taking courses and reading books, and getting into the fundamentals can push you forward, as you will be gaining in weeks, knowledge that took decades to establish. It would also immediately give you ideas on things you thought were impossible, or had no idea existed.
- Get as much real world exposure and experience as possible: Experience is always important, and my suggestion is to try as soon as you can to read_csv with Python or R, to actually do so with your GA, GSC, or crawl dataset. See what else you can do (visualize, manipulate, model, etc.). See if you get errors, try to analyze the data only using your programming language.
What does frustration look like, and by when will I get productive?
It's difficult to say, and it depends on your skill, background, the hours you put in, but visualizing it like this might help you on those frustrating unproductive days:
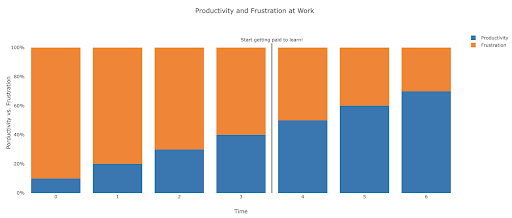
My suggestion is to take a non-trivial task, for example running an SEO audit for a site, only using Python. Your first session will mostly be frustrating, and most of the time will be spent checking documentation, and the definition of basic terms.
In parallel, you are still going through your course, and learning new stuff.
The value of that frustrating session is that it informs and motivates your theoretical learning. You will have questions in mind, and when you learn new things, you will immediately have a place to implement them.
Your next analysis session will probably be a little more productive, but still not productive enough to do at work. You go again to your learning and theory.
Do this enough times, and your time will become mostly productive, eventually you will be doing real work during working hours. The ideal scenario is where you are productive enough to do work, but every time use some time to research better techniques, which improves your work as well. By then you will start to get paid for learning, and your clients will be happily sponsoring you!
Suggested next steps
For the learning path a Data Science course would be great, especially if you get feedback on your work, and you can follow the topics in the order recommended.
If you go with Python I suggest the following libraries:
- pandas: The workhorse of all your tasks in preparing, cleaning, reshaping data whichever way you want. Fluency in pandas allows you to have full control over your data, which will help you immensely in visualization, general analysis, and machine learning
- Plotly and Dash: This is my favorite data visualization library, although there are many others. What I mostly like about it, is that it produces interactive and responsive HTML charts by default. It is very detailed and thorough in its options, yet simple to use. Plotly also includes Plotly Express, which is a high-level plotting tool, which is more intuitive to use, and takes a data-oriented approach (as opposed to a chart-oriented approach). Plotly also created Dash, which is the tool for creating interactive dashboards, but also serves as a full front-end web development framework. Other important data visualization libraries are matplotlib, altair, and bokeh, and for interactive data apps, there is panel and streamlit. Another important feature is that Plotly and Dash are available in all languages used in Data Science. You might use other libraries, and this is just my personal preference. Speaking of personal preferences:
- advertools: This is a library that I created to provide various online marketing tools, most importantly, an SEO crawler, log file parser and compressor, multi robots.txt parser, recursive sitemap parser, SEM keyword and text ad generator for large scale campaigns, weighted frequency word counter, Google SERP downloader, YouTube data API, and a few other tools. It is still evolving, and you are more than welcome to contribute any suggestions, bugs, or issues you might have with it.
These should be enough for beginners, and when you are familiar with them, you can do your own research for more specialized libraries, machine learning and deep learning tools, or libraries that are specialized in performance, or a special niche use-case.