
Data Science für SEO und digitales Marketing: ein empfohlener Leitfaden für Anfänger
Veröffentlicht: 2021-12-07Da sich der Großteil unserer Arbeit um Daten dreht und das Feld der Datenwissenschaft immer größer und für Anfänger viel zugänglicher wird, möchte ich Ihnen einige Gedanken darüber mitteilen, wie Sie in dieses Feld einsteigen können, um Ihre SEO und Ihr Marketing zu verbessern Fähigkeiten im Allgemeinen.
Was ist die Wissenschaft der Daten?
Ein sehr bekanntes Diagramm, das verwendet wird, um einen Überblick über dieses Feld zu geben, ist das Venn-Diagramm von Drew Conway, das Data Science als Schnittpunkt von Statistik, Hacking (fortgeschrittene Programmierkenntnisse im Allgemeinen und nicht unbedingt das Eindringen in Netzwerke und das Verursachen von Schaden) und Substanz zeigt Fachwissen oder „Domänenwissen“:
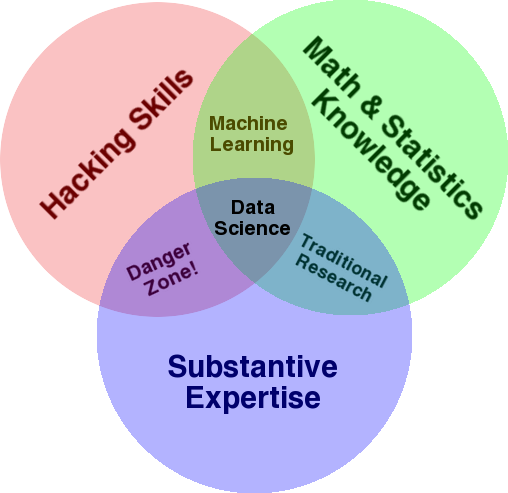
Quelle: oreilly.com
Als ich mit dem Lernen anfing, wurde mir schnell klar, dass wir genau das bereits tun. Der einzige Unterschied ist, dass ich es mit einfacheren und manuellen Werkzeugen gemacht habe.
Wenn Sie sich das Diagramm ansehen, werden Sie leicht erkennen, wie Sie dies wahrscheinlich bereits tun. Sie verwenden einen Computer (Hacking-Fähigkeiten), um Daten zu analysieren (Statistiken), um ein praktisches Problem zu lösen, indem Sie Ihr fundiertes Fachwissen in SEO (oder was auch immer Ihr Schwerpunkt ist) einsetzen.
Ihre aktuelle „Programmiersprache“ ist wahrscheinlich eine Tabellenkalkulation (Excel, Google Sheets usw.), und Sie verwenden höchstwahrscheinlich Powerpoint oder ähnliches, um Ideen zu kommunizieren. Lassen Sie uns diese Elemente ein wenig erweitern.
- Domänenwissen: Beginnen wir mit Ihrer Hauptstärke, da Sie bereits über Ihr Fachgebiet Bescheid wissen. Denken Sie daran, dass dies ein wesentlicher Bestandteil des Seins eines Datenwissenschaftlers ist, und hier können Sie auf Ihrem Wissen aufbauen und es schützen. Vor ein paar Monaten diskutierte ich mit einem Freund über die Analyse eines Crawl-Datensatzes. Er ist Physiker und forscht als Postdoktorand an Quantencomputern. Seine Kenntnisse und Fähigkeiten in Mathematik und Statistik übertreffen meine bei weitem, und er weiß wirklich viel besser als ich, wie man Daten analysiert. Ein Problem. Er wusste nicht, was eine „404“ ist (oder warum uns eine „301“ interessieren würde). Mit all seinen mathematischen Kenntnissen war er also nicht in der Lage, die „Status“-Spalte im Crawl-Datensatz zu verstehen. Natürlich wüsste er nicht, was er mit diesen Daten anfangen sollte, mit wem er sprechen und welche Strategien er basierend auf diesen Statuscodes entwickeln sollte (oder ob er woanders suchen sollte). Sie und ich wissen, was mit ihnen zu tun ist, oder zumindest wissen wir, wo wir sonst suchen müssen, wenn wir tiefer graben wollen.
- Mathematik und Statistik: Wenn Sie Excel verwenden, um den Durchschnitt einer Stichprobe von Daten zu erhalten, verwenden Sie Statistiken. Der Durchschnitt ist eine Statistik, die einen bestimmten Aspekt einer Datenstichprobe beschreibt. Fortgeschrittenere Statistiken helfen beim Verständnis Ihrer Daten. Dies ist auch wichtig, und ich bin kein Experte auf diesem Gebiet. Je mehr statistische Verteilungen Sie kennen, desto mehr Ideen haben Sie, wie Sie Daten analysieren können. Je mehr grundlegende Themen Sie kennen, desto besser können Sie Ihre Hypothesen formulieren und präzise Aussagen zu Ihren Datensätzen treffen.
- Programmierkenntnisse: Ich werde dies weiter unten ausführlicher besprechen, aber hauptsächlich bauen Sie hier die Flexibilität auf, dem Computer zu sagen, dass er genau das tun soll, was Sie von ihm wollen, anstatt an einfach zu bedienenden, aber leicht restriktiven Programmen festzuhalten Werkzeug. Dies ist Ihre Hauptmethode, um Ihre Daten zu erhalten, umzugestalten und zu bereinigen, wie immer Sie möchten, und ebnet Ihnen den Weg für offene und flexible „Gespräche“ mit Ihren Daten.
Werfen wir nun einen Blick darauf, was wir normalerweise in Data Science tun.
Der Data-Science-Zyklus
Ein typisches Data-Science-Projekt oder sogar eine Aufgabe sieht normalerweise so aus:
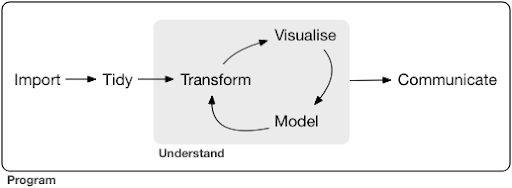
Quelle: r4ds.had.co.nz
Ich empfehle auch dringend, dieses Buch von Hadley Wickham und Garrett Grolemund zu lesen, das als großartige Einführung in die Datenwissenschaft dient. Es ist mit Beispielen aus der Programmiersprache R geschrieben, aber die Konzepte und der Code sind leicht verständlich, wenn Sie nur Python kennen.
Wie Sie im Diagramm sehen können, müssen wir unsere Daten zuerst irgendwie importieren, aufräumen und dann mit der Arbeit am inneren Kreislauf von Transformieren, Visualisieren und Modellieren beginnen. Danach kommunizieren wir die Ergebnisse mit anderen.
Diese Schritte können von extrem einfach bis sehr komplex reichen. Beispielsweise kann der Schritt „Importieren“ so einfach sein wie das Lesen einer CSV-Datei und in einigen Fällen aus einem sehr komplizierten Web-Scraping-Projekt bestehen, um die Daten zu erhalten. Einige der Elemente des Prozesses sind vollwertige Spezialitäten für sich.
Wir können dies leicht einigen vertrauten Prozessen zuordnen, die wir kennen. Sie könnten beispielsweise damit beginnen, einige Metadaten über eine Website abzurufen, indem Sie ihre robots.txt- und XML-Sitemap(s) herunterladen. Sie würden dann wahrscheinlich crawlen und möglicherweise auch einige Daten über SERP-Positionen oder beispielsweise Linkdaten erhalten. Jetzt, da Sie einige Datensätze haben, möchten Sie wahrscheinlich einige Tabellen zusammenführen, einige zusätzliche Daten imputieren und mit dem Erkunden/Verstehen beginnen. Die Visualisierung von Daten kann verborgene Muster aufdecken oder Ihnen dabei helfen, herauszufinden, was vor sich geht, oder vielleicht weitere Fragen aufwerfen. Wahrscheinlich möchten Sie Ihre Daten auch mithilfe einiger grundlegender Statistiken oder Modelle für maschinelles Lernen modellieren und hoffentlich einige Erkenntnisse gewinnen. Natürlich müssen Sie die Ergebnisse und Fragen an andere Projektbeteiligte kommunizieren.
Sobald Sie mit den verschiedenen Tools vertraut sind, die für jeden dieser Prozesse verfügbar sind, können Sie damit beginnen, Ihre eigenen benutzerdefinierten Pipelines zu erstellen, die spezifisch für eine bestimmte Website sind, da jedes Unternehmen einzigartig ist und spezielle Anforderungen hat. Irgendwann werden Sie Muster finden und müssen nicht die ganze Arbeit für ähnliche Projekte/Websites wiederholen.
Für jedes Element in diesem Prozess stehen zahlreiche Tools und Bibliotheken zur Verfügung, und es kann ziemlich überwältigend sein, welches Tool Sie wählen (und Ihre Zeit in das Lernen investieren). Werfen wir einen Blick auf einen möglichen Ansatz, den ich bei der Auswahl der von mir verwendeten Tools nützlich finde.
Auswahl an Werkzeugen und Kompromissen (3 Arten, eine Pizza zu essen)
Sollten Sie Excel für Ihre tägliche Arbeit bei der Verarbeitung von Daten verwenden, oder lohnt es sich, Python zu lernen?
Sind Sie besser dran, mit etwas wie Power BI zu visualisieren, oder sollten Sie in das Erlernen der Grammatik der Grafik investieren und lernen, wie Sie die Bibliotheken verwenden, die sie implementieren?
Würden Sie bessere Ergebnisse erzielen, indem Sie Ihre eigenen interaktiven Dashboards mit R oder Python erstellen, oder sollten Sie sich einfach für Google Data Studio entscheiden?
Lassen Sie uns zunächst die Kompromisse untersuchen, die bei der Auswahl verschiedener Werkzeuge auf unterschiedlichen Abstraktionsebenen auftreten. Dies ist ein Auszug aus meinem Buch über das Erstellen interaktiver Dashboards und Daten-Apps mit Plotly und Dash, und ich finde diesen Ansatz nützlich:
Betrachten Sie drei verschiedene Ansätze, um eine Pizza zu essen:
- Der Bestellansatz: Sie rufen ein Restaurant an und bestellen Ihre Pizza. Es kommt in einer halben Stunde vor Ihrer Haustür an und Sie fangen an zu essen.
- Der Supermarkt-Ansatz: Du gehst in einen Supermarkt, kaufst Teig, Käse, Gemüse und alle anderen Zutaten. Die Pizza machst du dann selbst.
- Der landwirtschaftliche Ansatz: Sie bauen Tomaten in Ihrem Garten an. Sie züchten Kühe, melken sie und verarbeiten die Milch zu Käse und so weiter.
Wenn wir zu den Schnittstellen auf höherer Ebene aufsteigen, hin zum Bestellansatz, nimmt die erforderliche Menge an Wissen stark ab. Jemand anderes trägt die Verantwortung, und die Qualität wird durch die Marktkräfte von Reputation und Wettbewerb geprüft.
Der Preis, den wir dafür zahlen, sind die verringerten Freiheiten und Optionen. Jedes Restaurant hat eine Reihe von Optionen zur Auswahl, und Sie müssen aus diesen Optionen wählen.
Wenn wir auf niedrigere Ebenen hinuntergehen, steigt die Menge an erforderlichem Wissen, wir müssen mit größerer Komplexität umgehen, wir tragen mehr Verantwortung für die Ergebnisse, und es dauert viel länger. Was wir hier gewinnen, ist viel mehr Freiheit und Macht, unsere Ergebnisse so anzupassen, wie wir es wollen. Die Kosten sind ebenfalls ein großer Vorteil, aber nur in einem ausreichend großen Maßstab. Wenn Sie heute nur eine Pizza essen möchten, ist es wahrscheinlich günstiger, sie zu bestellen. Aber wenn Sie vorhaben, jeden Tag einen zu haben, können Sie mit erheblichen Kosteneinsparungen rechnen, wenn Sie es selbst tun.
Dies sind die Arten von Entscheidungen, die Sie treffen müssen, wenn Sie auswählen, welche Tools Sie verwenden und lernen möchten. Die Verwendung einer Programmiersprache wie R oder Python erfordert viel mehr Arbeit und ist schwieriger als Excel, mit dem Vorteil, dass Sie viel produktiver und leistungsfähiger werden.
Die Wahl ist auch für jedes Werkzeug oder jeden Prozess wichtig. Sie könnten beispielsweise einen hochentwickelten und einfach zu verwendenden Crawler verwenden, um Daten über eine Website zu sammeln, und dennoch ziehen Sie es vielleicht vor, eine Programmiersprache mit allen verfügbaren Optionen zu verwenden, um die Daten zu visualisieren. Die Wahl des richtigen Werkzeugs für den richtigen Prozess hängt von Ihren Bedürfnissen ab, und die oben beschriebene Abwägung kann Ihnen hoffentlich dabei helfen, diese Wahl zu treffen. Dies hilft hoffentlich auch dabei, die Frage zu beantworten, ob (oder wie viel) Sie Python oder R lernen möchten oder nicht.
Lassen Sie uns diese Frage etwas weiter ausführen und sehen, warum das Erlernen von Python für SEO möglicherweise nicht das richtige Schlüsselwort ist.
Warum „Python für SEO“ irreführend ist
Möchten Sie ein großartiger Blogger werden oder WordPress lernen?
Möchtest du Grafikdesigner werden oder ist dein Ziel, Photoshop zu lernen?
Sind Sie daran interessiert, Ihre SEO-Karriere voranzutreiben, indem Sie Ihre Datenkenntnisse auf die nächste Stufe heben, oder möchten Sie Python lernen?
In den ersten fünf Minuten der ersten Vorlesung des Informatikkurses am MIT eröffnet Professor Harold Abelson den Kurs, indem er den Studenten erklärt, warum „Informatik“ ein so schlechter Name für die Disziplin ist, die sie gleich lernen werden. Ich finde es sehr interessant, sich die ersten fünf Minuten des Vortrags anzuschauen:
Wenn ein Gebiet gerade erst anfängt und Sie es nicht wirklich gut verstehen, ist es sehr einfach, die Essenz dessen, was Sie tun, mit den Werkzeugen zu verwechseln, die Sie verwenden. – Harald Abelson
Wir versuchen, unsere Online-Präsenz und Ergebnisse zu verbessern, und vieles, was wir tun, basiert auf dem Verstehen, Visualisieren, Manipulieren und Handhaben von Daten im Allgemeinen, und darauf konzentrieren wir uns, unabhängig vom verwendeten Tool. Data Science ist der Bereich, der über die intellektuellen Rahmenbedingungen dafür verfügt, sowie über viele Werkzeuge, um das umzusetzen, was wir tun möchten. Python könnte die Programmiersprache (Tool) Ihrer Wahl sein, und es ist definitiv wichtig, sie gut zu lernen. Ebenso wichtig, wenn nicht sogar noch wichtiger, ist es in unserem Fall, sich auf das „Wesen dessen zu konzentrieren, was man tut“, nämlich die Verarbeitung und Analyse von Daten.
Das Hauptaugenmerk sollte auf den oben besprochenen Prozessen (Importieren, Aufräumen, Visualisieren usw.) liegen, im Gegensatz zu der Programmiersprache der Wahl. Oder besser gesagt, wie Sie diese Programmiersprache verwenden, um Ihre Aufgaben zu erfüllen, anstatt einfach nur eine Programmiersprache zu lernen.
Wen interessieren all diese theoretischen Unterscheidungen, wenn ich sowieso Python lerne?
Werfen wir einen Blick darauf, was passieren könnte, wenn Sie sich darauf konzentrieren, etwas über das Tool zu lernen, anstatt sich auf das Wesentliche dessen zu konzentrieren, was Sie tun. Hier vergleichen wir die Suche nach „WordPress lernen“ (das Tool) mit der Suche nach „Bloggen lernen“ (das, was wir tun wollen):
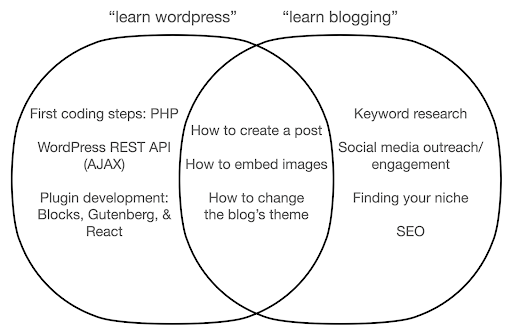
Das Diagramm zeigt mögliche Themen unter einem Buch oder Kurs, in dem das Schlüsselwort ganz oben behandelt wird. Der Schnittpunktbereich in der Mitte zeigt Themen, die in beiden Kurs-/Bucharten vorkommen können.
Wenn Sie sich auf das Tool konzentrieren, müssen Sie zweifellos Dinge lernen, die Sie nicht wirklich brauchen, insbesondere als Anfänger. Diese Themen könnten Sie verwirren und frustrieren, insbesondere wenn Sie keinen technischen oder Programmierhintergrund haben.
Sie werden auch Dinge lernen, die nützlich sind, um ein guter Blogger zu werden (die Themen im Schnittpunktbereich). Diese Themen sind extrem einfach zu lehren (wie man einen Blogbeitrag erstellt), sagen Ihnen aber nicht viel darüber, warum Sie bloggen sollten, wann und worüber. Dies ist kein Fehler in einem Buch, das sich auf Tools konzentriert, denn wenn Sie etwas über ein Tool lernen, würde es ausreichen, zu lernen, wie man einen Blogbeitrag erstellt, und weiterzumachen.
Als Blogger interessieren Sie sich wahrscheinlich mehr für das Was und Warum des Bloggens, und das würde in Büchern, die sich auf Tools konzentrieren, nicht behandelt werden.
Offensichtlich werden die strategischen und wichtigen Dinge wie SEO, das Finden Ihrer Nische usw. nicht behandelt, sodass Sie sehr wichtige Dinge verpassen würden.
Was sind einige der Data Science-Themen, die Sie wahrscheinlich nicht in einem Programmierbuch lernen werden?
Wie wir gesehen haben, bedeutet die Aufnahme eines Python- oder Programmierbuchs wahrscheinlich, dass Sie Softwareentwickler werden möchten. Die Themen wären natürlich darauf ausgerichtet. Wenn Sie nach einem Data Science-Buch suchen, erhalten Sie Themen und Tools, die mehr auf die Analyse von Daten ausgerichtet sind.
Wir können das erste Diagramm (das den Zyklus von Data Science zeigt) als Leitfaden verwenden und proaktiv nach diesen Themen suchen: „Daten importieren mit Python“, „Daten aufräumen mit r“, „Daten mit Python visualisieren“ und so weiter. Lassen Sie uns einen tieferen Blick auf diese Themen werfen und sie weiter untersuchen:
Importieren
Natürlich müssen wir zuerst einige Daten beschaffen. Das kann sein:
- Eine Datei auf unserem Computer: Der einfachste Fall, bei dem Sie die Datei einfach mit der Programmiersprache Ihrer Wahl öffnen. Es ist wichtig zu beachten, dass es viele verschiedene Dateiformate gibt und dass Sie beim Öffnen/Lesen der Dateien viele Optionen haben. Zum Beispiel hat die read_csv-Funktion aus der pandas-Bibliothek (ein wesentliches Datenbearbeitungstool in Python) beim Öffnen der Datei fünfzig Optionen zur Auswahl. Es enthält Dinge wie den Dateipfad, die zu wählenden Spalten, die Anzahl der zu öffnenden Zeilen, die Interpretation von Datetime-Objekten, den Umgang mit fehlenden Werten und vieles mehr. Es ist wichtig, mit diesen Optionen und den verschiedenen Überlegungen beim Öffnen verschiedener Dateiformate vertraut zu sein. Außerdem hat Pandas neunzehn verschiedene Funktionen, die mit read_ für verschiedene Datei- und Datenformate beginnen.
- Export aus einem Online-Tool: Sie kennen das wahrscheinlich, und hier können Sie Ihre Daten anpassen und dann exportieren, um sie dann als Datei auf Ihrem Computer zu öffnen.
- API-Aufrufe zum Abrufen bestimmter Daten: Dies ist auf einer niedrigeren Ebene und näher am oben erwähnten Farmansatz. In diesem Fall senden Sie eine Anfrage mit spezifischen Anforderungen und erhalten die gewünschten Daten zurück. Der Vorteil hierbei ist, dass Sie genau das anpassen können, was Sie erhalten möchten, und es auf eine Weise formatieren können, die in der Online-Oberfläche möglicherweise nicht verfügbar ist. Beispielsweise können Sie in Google Analytics einer Tabelle, die Sie analysieren, eine sekundäre Dimension hinzufügen, aber Sie können keine dritte hinzufügen. Sie sind auch durch die Anzahl der Zeilen beschränkt, die Sie exportieren können. Die API gibt Ihnen mehr Flexibilität, und Sie können auch bestimmte Aufrufe so automatisieren, dass sie regelmäßig als Teil einer größeren Datenerfassungs-/Analyse-Pipeline erfolgen.
- Crawling und Scraping von Daten: Sie haben wahrscheinlich Ihren Lieblings-Crawler und sind wahrscheinlich mit dem Prozess vertraut. Dies ist bereits ein flexibler Prozess, der es uns ermöglicht, benutzerdefinierte Elemente aus Seiten zu extrahieren, nur bestimmte Seiten zu crawlen und so weiter.
- Eine Kombination von Methoden, die Automatisierung, benutzerdefinierte Extraktion und möglicherweise maschinelles Lernen für spezielle Anwendungen umfassen.
Sobald wir einige Daten haben, wollen wir zum nächsten Level gehen.
Aufgeräumt
Ein „aufgeräumter“ Datensatz ist ein Datensatz, der auf eine bestimmte Weise organisiert ist. Sie werden auch als „Long-Format“-Daten bezeichnet. In Kapitel 12 des Buches „R for Data Science“ wird das Konzept der aufgeräumten Daten ausführlicher behandelt, falls Sie daran interessiert sind.
Schauen Sie sich die drei folgenden Tabellen an und versuchen Sie, Unterschiede zu finden:
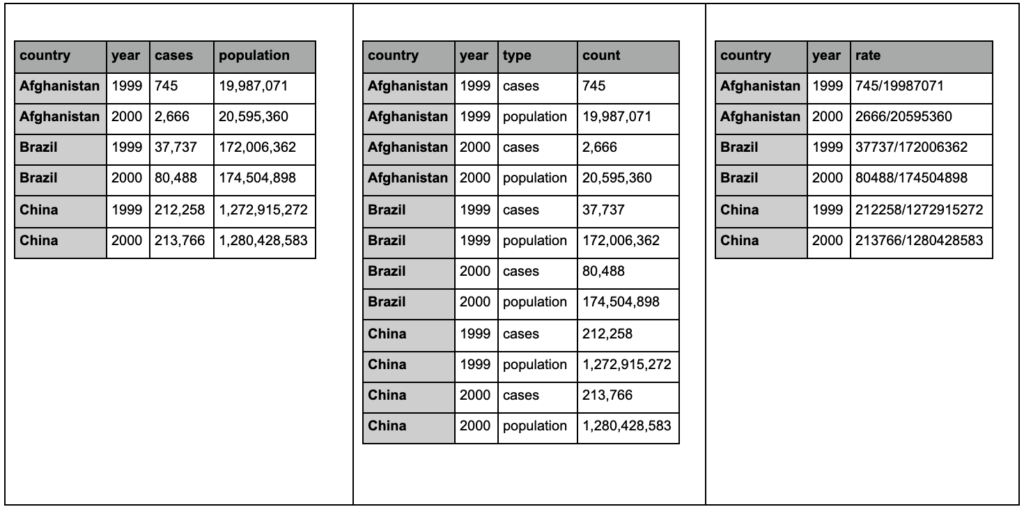
Beispieltabellen aus dem tidyr-Paket.
Sie werden feststellen, dass die drei Tabellen genau die gleichen Informationen enthalten, aber auf unterschiedliche Weise organisiert und dargestellt werden. Wir können Fälle und Population in zwei getrennten Spalten haben (Tabelle 1) oder eine Spalte haben, die uns sagt, was die Beobachtung ist (Fälle oder Population), und eine Spalte „Anzahl“, um diese Fälle zu zählen (Tabelle 2). In Tabelle 3 sind sie als Raten dargestellt.
Beim Umgang mit Daten werden Sie feststellen, dass verschiedene Quellen Daten unterschiedlich organisieren und dass Sie für eine bessere und einfachere Analyse häufig von/zu bestimmten Formaten wechseln müssen. Es ist entscheidend, mit diesen Reinigungsvorgängen vertraut zu sein, und das tidyr-Paket in R enthält spezielle Tools dafür. Sie können auch Pandas verwenden, wenn Sie Python bevorzugen, und Sie können sich dafür die Melt- und Pivot-Funktionen ansehen.
Sobald unsere Daten in einem bestimmten Format vorliegen, möchten wir sie möglicherweise weiter manipulieren.
Verwandeln
Eine weitere wichtige Fähigkeit zum Aufbau ist die Fähigkeit, beliebige Änderungen an den Daten vorzunehmen, mit denen Sie arbeiten. Das ideale Szenario ist, die Phase zu erreichen, in der Sie Gespräche mit Ihren Daten führen können und in der Lage sind, ganz bestimmte Fragen auf ganz bestimmte Weise zu stellen und hoffentlich interessante Einblicke zu erhalten. Hier sind einige der wichtigsten Transformationsaufgaben, die Sie wahrscheinlich häufig benötigen werden, mit einigen Beispielaufgaben, die Sie interessieren könnten:
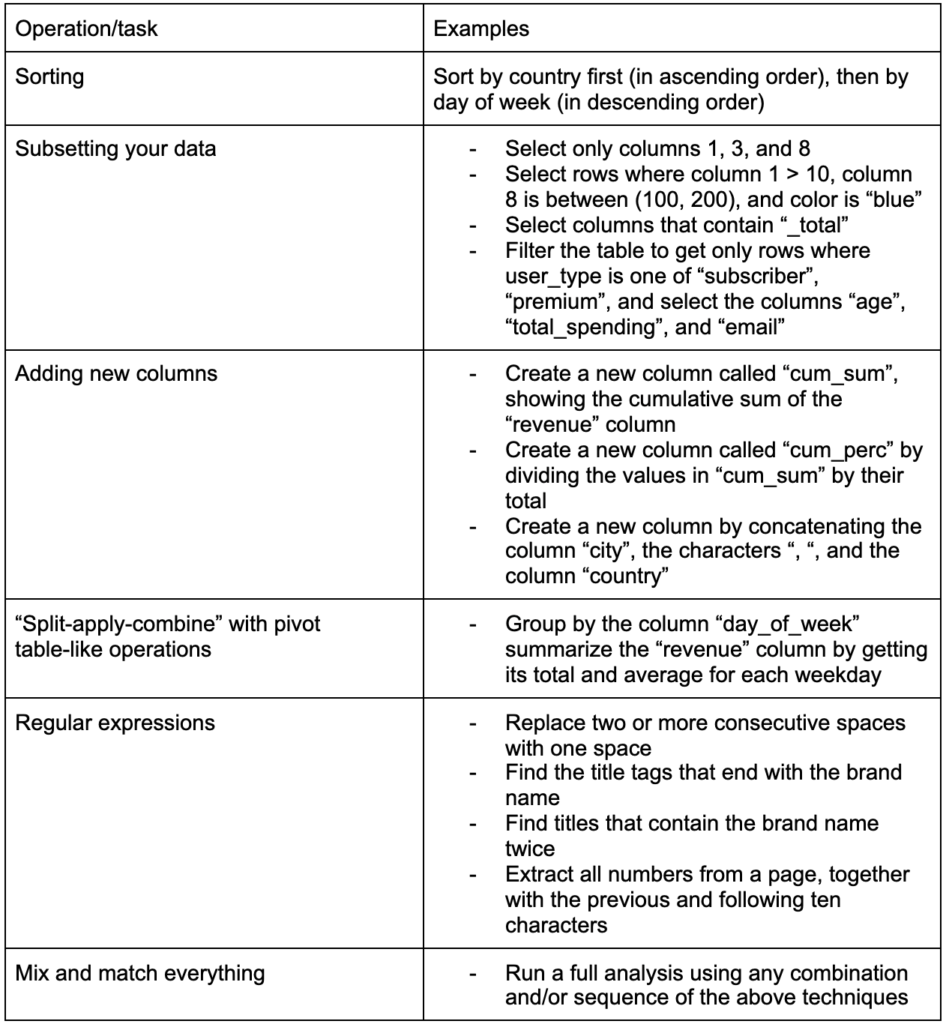
Nachdem wir unsere Daten erhalten, aufgeräumt und in das gewünschte Format gebracht haben, wäre es gut, sie zu visualisieren.
Visualisieren
Datenvisualisierung ist ein riesiges Thema, und zu einigen seiner Unterthemen gibt es ganze Bücher. Es ist eines dieser Dinge, die viele Einblicke in unsere Daten geben können, insbesondere, dass es intuitive visuelle Elemente verwendet, um Informationen zu kommunizieren. Die relative Höhe von Balken in einem Balkendiagramm zeigt uns zum Beispiel sofort ihre relative Menge. Die Farbintensität, die relative Position und viele andere visuelle Attribute sind für Leser leicht erkennbar und verständlich.
Eine gute Grafik sagt mehr als tausend (Schlüssel-)Wörter!
Da es zahlreiche Themen zur Datenvisualisierung gibt, teile ich einfach einige Beispiele, die interessant sein könnten. Einige von ihnen sind die Bausteine für dieses Armutsdaten-Dashboard, wenn Sie die vollständigen Details wünschen.
Manchmal genügt ein einfaches Balkendiagramm, um Werte zu vergleichen, wobei die Balken vertikal oder horizontal angezeigt werden können:
Sie könnten daran interessiert sein, bestimmte Länder zu erkunden und tiefer zu graben, indem Sie sehen, wie sie bei bestimmten Metriken Fortschritte gemacht haben. In diesem Fall möchten Sie möglicherweise mehrere Balkendiagramme im selben Diagramm anzeigen:
Der Vergleich mehrerer Werte für mehrere Beobachtungen kann auch durch Platzieren mehrerer Balken an jeder X-Achsenposition erfolgen. Hier sind die wichtigsten Möglichkeiten, dies zu tun:
Auswahl von Farben und Farbskalen: Ein wesentlicher Bestandteil der Datenvisualisierung und etwas, das Informationen äußerst effizient und intuitiv vermitteln kann, wenn es richtig gemacht wird.
Kategoriale Farbskalen: Nützlich zum Ausdrücken kategorialer Daten. Wie der Name schon sagt, ist dies die Art von Daten, die zeigen, zu welcher Kategorie eine bestimmte Beobachtung gehört. In diesem Fall wollen wir möglichst unterschiedliche Farben, um klare Unterschiede in den Kategorien zu zeigen (insbesondere bei visuellen Elementen, die nebeneinander angezeigt werden).
Das folgende Beispiel verwendet eine kategoriale Farbskala, um zu zeigen, welches Regierungssystem in jedem Land implementiert ist. Es ist ganz einfach, die Farben der Länder mit der Legende zu verbinden, die zeigt, welches Regierungssystem verwendet wird. Dies wird auch als Choroplethenkarte bezeichnet:
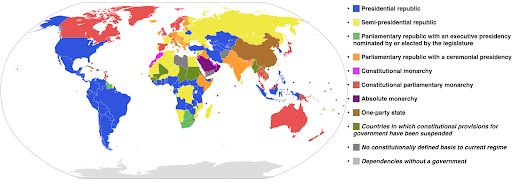
Quelle: Wikipedia
Manchmal beziehen sich die Daten, die wir visualisieren möchten, auf dieselbe Metrik, und jedes Land (oder jede andere Art von Beobachtung) fällt auf einen bestimmten Punkt in einem Kontinuum, das zwischen dem Minimum und dem Maximum liegt. Mit anderen Worten, wir möchten Grade dieser Metrik visualisieren.
In diesen Fällen müssen wir eine kontinuierliche (oder sequentielle) Farbskala finden. Im folgenden Beispiel ist sofort klar, welche Länder blauer sind (und daher mehr Verkehr erhalten), und wir können die nuancierten Unterschiede zwischen den Ländern intuitiv verstehen.
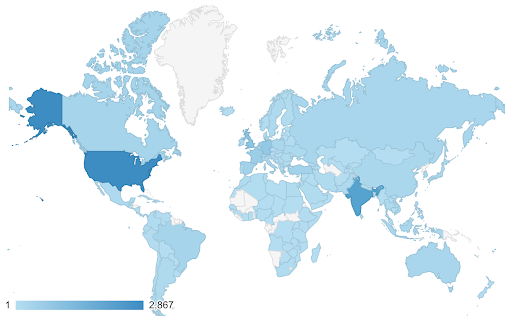
Ihre Daten können kontinuierlich sein (wie das Verkehrskartendiagramm oben), aber das Wichtige an den Zahlen könnte sein, wie stark sie von einem bestimmten Punkt abweichen. In diesem Fall sind die divergierenden Farbskalen hilfreich.
Die folgende Grafik zeigt die Nettowachstumsraten der Bevölkerung. In diesem Fall ist es zunächst interessant zu wissen, ob ein bestimmtes Land eine positive oder negative Wachstumsrate hat oder nicht. Oder wir wollen wissen, wie weit jedes Land von Null entfernt ist (und um wie viel). Ein Blick auf die Karte zeigt uns sofort, in welchen Ländern die Bevölkerung wächst und in welchen schrumpft. Die Legende zeigt uns auch, dass die maximale positive Rate 3,5 % und die maximale negative Rate -0,5 % beträgt. Dies gibt uns auch einen Hinweis auf den Wertebereich (positiv und negativ).

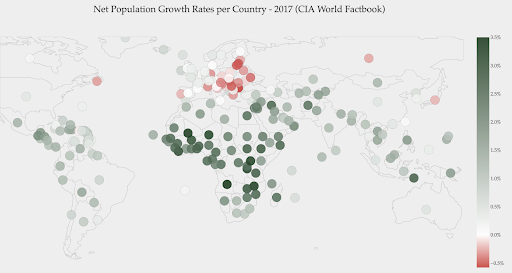
Quelle: Dashboardom.com
Leider sind die für diese Skala gewählten Farben nicht ideal, da farbenblinde Menschen Rot und Grün möglicherweise nicht richtig unterscheiden können. Dies ist ein sehr wichtiger Aspekt bei der Auswahl unserer Farbskalen.
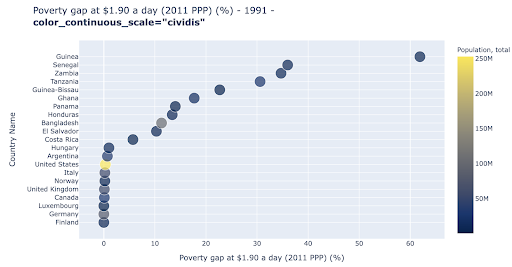
Das Streudiagramm ist einer der am weitesten verbreiteten und vielseitigsten Diagrammtypen. Die Position der Punkte (oder jeder anderen Markierung) vermittelt die Menge, die wir zu kommunizieren versuchen. Zusätzlich zur Position können wir mehrere andere visuelle Attribute wie Farbe, Größe und Form verwenden, um noch mehr Informationen zu kommunizieren. Das folgende Beispiel zeigt den Prozentsatz der Bevölkerung, der mit 1,9 $/Tag lebt, was wir deutlich als horizontalen Abstand der Punkte erkennen können.
Wir können unserem Diagramm auch eine neue Dimension hinzufügen, indem wir Farbe verwenden. Dies entspricht der Visualisierung einer dritten Spalte aus demselben Datensatz, die in diesem Fall Bevölkerungsdaten zeigt.
Wir können jetzt sehen, dass der extremste Fall in Bezug auf die Bevölkerung (USA) in der Armutsmesszahl sehr niedrig ist. Dies bereichert unsere Diagramme. Wir hätten auch Größe und Form verwenden können, um noch mehr Spalten aus unserem Datensatz zu visualisieren. Wir müssen jedoch eine gute Balance zwischen Reichtum und Lesbarkeit finden.
Wir könnten daran interessiert sein zu prüfen, ob es eine Beziehung zwischen Bevölkerung und Armutsniveau gibt, und so können wir denselben Datensatz auf eine etwas andere Weise visualisieren, um zu sehen, ob eine solche Beziehung besteht:
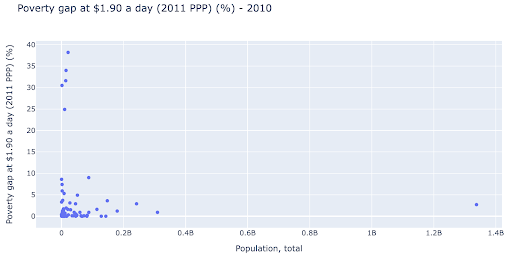
Wir haben einen Ausreißerwert in der Bevölkerung bei etwa 1,35 Mrd., und das bedeutet, dass wir viele Leerzeichen im Diagramm haben, was auch bedeutet, dass viele Werte auf einen sehr kleinen Bereich gequetscht werden. Wir haben auch viele überlappende Punkte, was es sehr schwierig macht, Unterschiede oder Trends zu erkennen.
Das folgende Diagramm enthält dieselben Informationen, wird jedoch mit zwei Techniken unterschiedlich visualisiert:
- Logarithmische Skala : Wir sehen normalerweise Daten auf einer additiven Skala. Mit anderen Worten, jeder Punkt auf der Achse (X oder Y) repräsentiert eine Addition einer bestimmten Menge der visualisierten Daten. Wir können auch multiplikative Skalen haben, in diesem Fall multiplizieren wir für jeden neuen Punkt auf der X-Achse (in diesem Beispiel mit zehn). Dadurch können die Punkte verteilt werden, und wir müssen an Vielfache denken, im Gegensatz zu Additionen, wie wir es im vorherigen Diagramm hatten.
- Verwendung einer anderen Markierung (größere leere Kreise) : Die Auswahl einer anderen Form für unsere Markierungen löste das Problem des „Überzeichnens“, bei dem wir möglicherweise mehrere Punkte an derselben Stelle übereinander haben, was es sehr schwierig macht, überhaupt zu sehen wie viele Punkte wir haben.
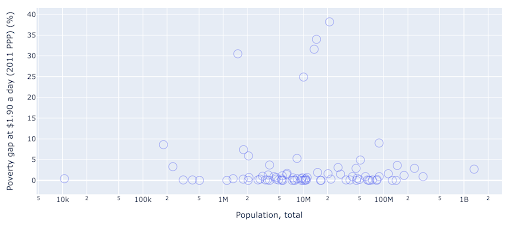
Wir können jetzt sehen, dass es ein Cluster von Ländern um die 10-Millionen-Marke herum gibt, und auch andere kleinere Cluster.
Wie ich bereits erwähnt habe, gibt es viele weitere Arten von Zeichen und Visualisierungsoptionen und ganze Bücher, die über das Thema geschrieben wurden. Ich hoffe, dies gibt Ihnen ein paar interessante Gedanken zum Experimentieren.
Oncrawl-Daten³
 Mehr erfahren
Mehr erfahrenModell
Wir müssen unsere Daten vereinfachen und Muster finden, Vorhersagen treffen oder sie einfach besser verstehen. Dies ist ein weiteres großes Thema und kann vom einfachen Abrufen einiger zusammenfassender Statistiken (Durchschnitt, Median, Standardabweichung usw.) über die visuelle Modellierung unserer Daten mit einem Modell, das einen Trend zusammenfasst oder findet, bis hin zur Verwendung komplexerer Techniken reichen, um einen zu erhalten mathematische Formel für unsere Daten. Wir können auch maschinelles Lernen verwenden, um mehr Einblicke in unsere Daten zu gewinnen.
Auch dies ist keine vollständige Erörterung des Themas, aber ich möchte einige Beispiele nennen, bei denen Sie einige Techniken des maschinellen Lernens verwenden könnten, um Ihnen zu helfen.
In einem Crawl-Datensatz habe ich versucht, etwas mehr über die 404-Seiten zu erfahren und ob ich etwas darüber entdecken kann. Mein erster Versuch war zu überprüfen, ob es eine Korrelation zwischen der Größe der Seite und ihrem Statuscode gibt, und es gab – eine fast perfekte Korrelation!
Ich fühlte mich für ein paar Minuten wie ein Genie und kehrte schnell zum Planeten Erde zurück.
Die 404-Seiten befanden sich alle in einem sehr engen Bereich der Seitengröße, sodass fast alle Seiten mit einer bestimmten Anzahl von Kilobyte einen 404-Statuscode hatten. Dann wurde mir klar, dass 404-Seiten per Definition keinen anderen Inhalt haben als „404-Fehlerseite“! Und deshalb hatten sie die gleiche Größe.
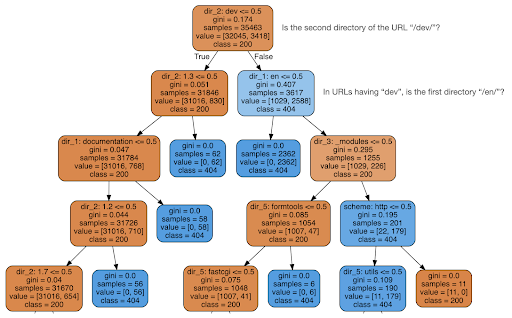
Ich entschied mich dann zu prüfen, ob der Inhalt mir etwas über den Statuscode sagen könnte, also teilte ich die URLs in ihre Elemente auf und führte einen Entscheidungsbaum-Klassifikator mit sklearn aus. Dies ist im Grunde eine Technik, die einen Entscheidungsbaum erzeugt, bei dem das Befolgen seiner Regeln dazu führen könnte, dass wir lernen, wie wir unser Ziel finden, in diesem Fall 404 Seiten.
Im folgenden Entscheidungsbaum zeigt die erste Zeile in jedem Kästchen die zu befolgende oder zu prüfende Regel, die Zeile „Beispiele“ ist die Anzahl der in diesem Kästchen gefundenen Beobachtungen und die Zeile „Klasse“ gibt uns die Klasse der aktuellen Beobachtung an , in diesem Fall unabhängig davon, ob der Statuscode 200 oder 404 lautet oder nicht.
Ich werde nicht auf weitere Details eingehen, und ich weiß, dass der Entscheidungsbaum möglicherweise nicht klar ist, wenn Sie damit nicht vertraut sind, und Sie können den rohen Crawl-Datensatz und den Analysecode untersuchen, wenn Sie interessiert sind.
Im Wesentlichen fand der Entscheidungsbaum heraus, wie fast alle 404-Seiten unter Verwendung der Verzeichnisstruktur der URLs gefunden werden konnten. Wie Sie sehen können, haben wir 3.617 URLs gefunden, indem wir einfach überprüft haben, ob das zweite Verzeichnis der URL „/dev/“ war oder nicht (erstes hellblaues Kästchen in der zweiten Zeile von oben). Jetzt wissen wir also, wie wir unsere 404er finden, und es scheint, dass sie fast alle im Abschnitt „/dev/“ der Website zu finden sind. Dies war definitiv eine enorme Zeitersparnis. Stellen Sie sich vor, Sie gehen manuell alle möglichen URL-Strukturen und -Kombinationen durch, um diese Regel zu finden.
Wir haben immer noch nicht das vollständige Bild und warum dies geschieht, und dies kann weiter verfolgt werden, aber zumindest haben wir diese URLs jetzt sehr leicht gefunden.
Eine andere Technik, an der Sie vielleicht interessiert sind, ist KMeans-Clustering, das Datenpunkte in verschiedene Gruppen/Cluster gruppiert. Dies ist eine Technik des „unüberwachten Lernens“, bei der uns der Algorithmus hilft, Muster zu entdecken, von denen wir nicht wussten, dass sie existieren.
Stellen Sie sich vor, Sie hätten eine Reihe von Zahlen, sagen wir, die Bevölkerung von Ländern, und Sie wollten sie in zwei Gruppen gruppieren, eine große und eine kleine. Wie würdest du das machen? Wo würden Sie die Grenze ziehen?
Dies unterscheidet sich von der Erfassung der Top-Ten-Länder oder der Top-X% der Länder. Das wäre sehr einfach, wir können die Länder nach Bevölkerung sortieren und die besten X bekommen, wie wir wollen.
Was wir wollen, ist, sie relativ zu diesem Datensatz in „groß“ und „klein“ zu gruppieren, und wir gehen davon aus, dass wir nichts über die Bevölkerung der Länder wissen.
Dies kann weiter ausgebaut werden, indem versucht wird, Länder in drei Kategorien einzuteilen: klein, mittel und groß. Dies wird manuell viel schwieriger, wenn wir fünf, sechs oder mehr Gruppen wollen.
Beachten Sie, dass wir nicht wissen, wie viele Länder in jeder Gruppe landen werden, da wir nicht nach den Top-X-Ländern fragen. Wenn wir uns in zwei Cluster gruppieren, können wir sehen, dass wir nur zwei Länder in der großen Gruppe haben: China und Indien. Dies ist intuitiv sinnvoll, da diese beiden Länder eine durchschnittliche Bevölkerung haben, die sehr weit von allen anderen Ländern entfernt ist. Diese Ländergruppe hat ihren eigenen Durchschnitt und ihre Länder liegen näher beieinander als die Länder der anderen Gruppe:
Länder gruppiert nach Bevölkerungszahl in zwei Gruppen 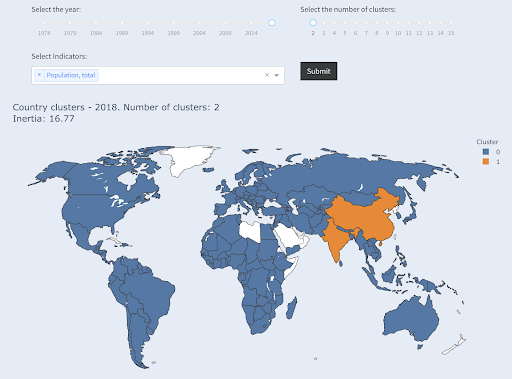
Das drittgrößte Land in Bezug auf die Bevölkerung (USA ~330 Millionen) wurde mit allen anderen gruppiert, einschließlich Ländern mit einer Bevölkerung von einer Million. Das liegt daran, dass 330 Millionen viel näher an 1 Million liegen als 1,3 Milliarden. Hätten wir nach drei Clustern gefragt, hätten wir ein anderes Bild bekommen:
Länder gruppiert nach Bevölkerungszahl in drei Gruppen 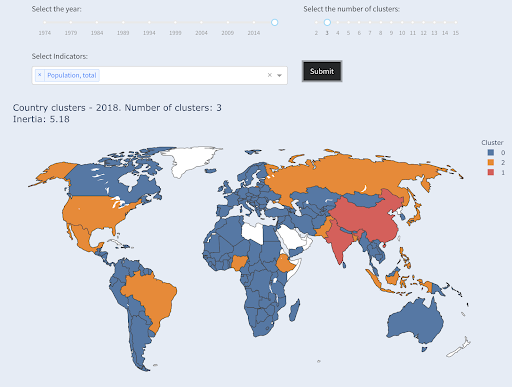
Und so würden die Länder geclustert, wenn wir nach vier Clustern fragen würden:
Länder gruppiert nach Bevölkerungszahl in vier Gruppen 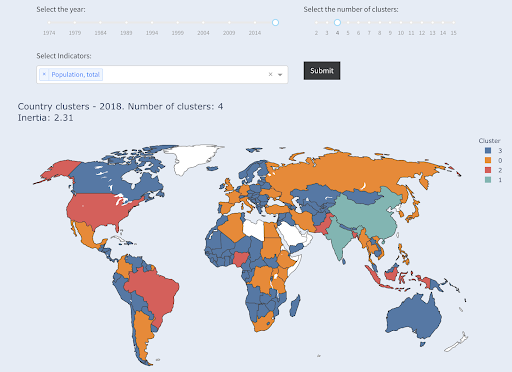
Quelle: armutdata.org (Tab „Cluster-Länder“)
Dies war in diesem Fall Clustering mit nur einer Dimension – Bevölkerung – und Sie können auch weitere Dimensionen hinzufügen und sehen, wo Länder landen.
Es gibt viele andere Techniken und Werkzeuge, und dies waren nur einige Beispiele, die hoffentlich interessant und praktisch sind.
Jetzt sind wir bereit, unsere Ergebnisse mit unserem Publikum zu kommunizieren.
Kommunizieren
Nach all der Arbeit, die wir in den vorherigen Schritten geleistet haben, müssen wir unsere Ergebnisse schließlich an andere Projektbeteiligte weitergeben.
Eines der wichtigsten Werkzeuge in der Datenwissenschaft ist das interaktive Notizbuch. Jupyter Notebook ist das am weitesten verbreitete und unterstützt so ziemlich alle Programmiersprachen, und Sie ziehen es vielleicht vor, das spezielle Notebook-Format von RStudio zu verwenden, das auf die gleiche Weise funktioniert.
Die Hauptidee besteht darin, Daten, Code, Erzählung und Visualisierungen an einem Ort zu haben, damit andere Personen sie prüfen können. Es ist wichtig zu zeigen, wie Sie zu diesen Schlussfolgerungen und Empfehlungen für Transparenz und Reproduzierbarkeit gelangt sind. Andere Personen sollten in der Lage sein, denselben Code auszuführen und dieselben Ergebnisse zu erzielen.
Ein weiterer wichtiger Grund ist die Fähigkeit für andere, einschließlich „future you“, die Analyse weiterzuentwickeln und auf der von Ihnen geleisteten anfänglichen Arbeit aufzubauen, sie zu verbessern und auf neue Weise zu erweitern.
Dies setzt natürlich voraus, dass das Publikum mit Code vertraut ist und sich überhaupt darum kümmert!
Sie haben auch die Möglichkeit, Ihre Notizbücher ohne den Code in HTML (und mehrere andere Formate) zu exportieren, sodass Sie am Ende einen benutzerfreundlichen Bericht erhalten und dennoch den vollständigen Code behalten, um dieselben Analysen und Ergebnisse zu reproduzieren.
Ein wichtiges Element der Kommunikation ist die Datenvisualisierung, die oben ebenfalls kurz angesprochen wurde.
Noch besser ist die interaktive Datenvisualisierung, in diesem Fall erlauben Sie Ihrem Publikum, Werte auszuwählen und sich verschiedene Kombinationen von Diagrammen und Metriken anzusehen, um die Daten noch weiter zu untersuchen.
Hier sind einige Dashboards und Daten-Apps (einige von ihnen können einige Sekunden zum Laden benötigen), die ich erstellt habe, um Ihnen eine Vorstellung davon zu geben, was getan werden kann.
Schließlich können Sie auch benutzerdefinierte Apps für Ihre Projekte erstellen, um auf spezielle Bedürfnisse und Anforderungen einzugehen, und hier ist eine weitere Reihe von SEO- und Marketing-Apps, die für Sie interessant sein könnten.
Wir sind die wichtigsten Schritte im Data Science-Zyklus durchgegangen und wollen uns nun einen weiteren Vorteil des „Lernens von Python“ ansehen.
Python steht für Automatisierung und Produktivität: wahr, aber unvollständig
Es scheint mir, dass es eine Überzeugung gibt, dass das Erlernen von Python hauptsächlich dazu dient, produktive und/oder Aufgaben zu automatisieren.
Das ist absolut richtig, und ich denke, wir müssen nicht einmal darüber diskutieren, wie wertvoll es ist, etwas in einem Bruchteil der Zeit erledigen zu können, die wir für eine manuelle Bearbeitung benötigen würden.
Der andere fehlende Teil des Arguments ist die Datenanalyse . Eine gute Datenanalyse liefert uns Erkenntnisse, und im Idealfall sind wir in der Lage, umsetzbare Erkenntnisse zu liefern, die unseren Entscheidungsprozess leiten, basierend auf unserem Fachwissen und den uns vorliegenden Daten.
Ein großer Teil unserer Arbeit besteht darin, zu versuchen, zu verstehen, was passiert, den Wettbewerb zu analysieren, herauszufinden, wo sich die wertvollsten Inhalte befinden, zu entscheiden, was zu tun ist, und so weiter. Wir sind Berater, Ratgeber und Entscheider. In der Lage zu sein, einige Einblicke aus unseren Daten zu gewinnen, ist eindeutig ein großer Vorteil, und die hier genannten Bereiche und Fähigkeiten können uns dabei helfen, dies zu erreichen.
Was wäre, wenn Sie erfahren würden, dass Ihre Titel-Tags eine durchschnittliche Länge von sechzig Zeichen haben, ist das gut?
Was ist, wenn Sie ein wenig tiefer graben und feststellen, dass die Hälfte Ihrer Titel weit unter sechzig ist, während die andere Hälfte viel mehr Zeichen hat (was den Durchschnitt von sechzig ergibt)? In order to get practical and provide good recommendations, you need a higher-resolution view of your title tags' lengths, probably a histogram that shows the frequency of your title tag lengths at each interval so you can have a separate strategy for length. A simple table would also do, for example:
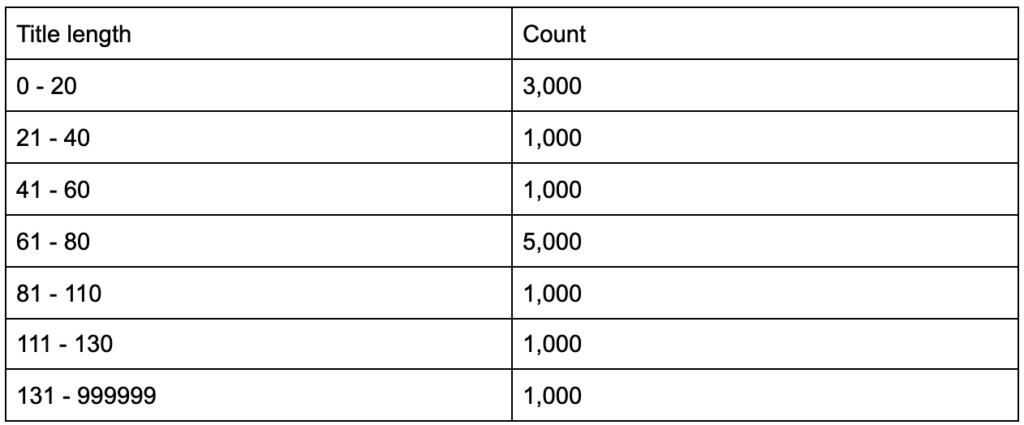
Splitting title lengths by intervals of twenty was an arbitrary decision, and you can split them the way you want. Looking at the table above, and seeing that we have three times more than the average titles in the interval (0, 20), we might want to split it further to better understand what is going on.
Having a better view than the default single-statistic summaries that we get from standard tools, allows us to employ different strategies for different lengths. For example, we can remove the brand name from the titles that are longer than a certain number of characters, and keep it in other titles.
This was an example of very simple insights, which are possible due to the flexibility we get by using a programming language, and a set of data science tools. This also allows us to iterate and modify our approach, until we find a satisfactory point that can take our analysis to the next steps.
Visualization, machine learning, modeling and general data manipulation skills allow us to get better insights on our data, even though those analyses are typically done only once. Still, if you use code to get those insights, you can always take some parts and apply to other projects, or again to the same project. In this case, the insights we got, helped us in our automation, even more. The insights would tell us what needs to be automated and what doesn't.
Should you learn Python?
Is a useless question, and the more useful one is, “How much Python (or R) should you learn?”
My view of how we use computers has evolved in the last few years.
I used to think that there were two main ways of using computers, either you are a regular user, using “point-and-click” applications to do certain tasks, or you are a developer who creates those applications that the rest of us use.

I then realized that it is more like a continuum between very high level use (pizza ordering approach), and the lower levels of the farm approach. I also realized that there is a happy sweet spot in between, where you learn enough programming to get productive and boost your data analysis skills, without having to become a software developer or engineer.
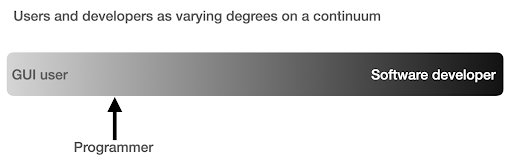
What are the main differences between being a programmer (a software user), and a software developer (or engineer)?
What are the differences between making a great coffee at home, versus establishing and running a cafe?
If making good coffee is one skill, then running a cafe requires ten other skills, most of which have nothing to do with making coffee.
You have to choose a good location (real estate), hire people (management and HR), manage cash flow and finances (accounting and finance), do marketing, legal, manage delivery, adhere to cleanliness and health standards, and so on. You can be a great coffee maker without knowing anything about those fields, but if you want to take it to the next level, you will have to manage all those additional tasks unrelated to making coffee.
The same applies to being a good programmer or data analyst versus being a software developer/engineer. There are so many other things that you have to know and worry about that you don't need as a regular programmer doing stuff for yourself and co-workers and clients. Once you have enough knowledge and skills in programming and data science, you will be in a good position to choose and decide whether you want to continue as an analyst, focusing on data science, or if you want to end up creating software that other people would use.
How do I get into Data Science?
To learn anything I think you have to do two things in parallel:
- Learn the fundamentals and the theory properly: Taking courses and reading books, and getting into the fundamentals can push you forward, as you will be gaining in weeks, knowledge that took decades to establish. It would also immediately give you ideas on things you thought were impossible, or had no idea existed.
- Get as much real world exposure and experience as possible: Experience is always important, and my suggestion is to try as soon as you can to read_csv with Python or R, to actually do so with your GA, GSC, or crawl dataset. See what else you can do (visualize, manipulate, model, etc.). See if you get errors, try to analyze the data only using your programming language.
What does frustration look like, and by when will I get productive?
It's difficult to say, and it depends on your skill, background, the hours you put in, but visualizing it like this might help you on those frustrating unproductive days:
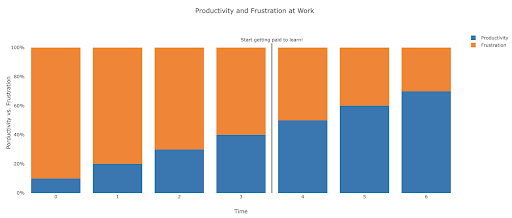
My suggestion is to take a non-trivial task, for example running an SEO audit for a site, only using Python. Your first session will mostly be frustrating, and most of the time will be spent checking documentation, and the definition of basic terms.
In parallel, you are still going through your course, and learning new stuff.
The value of that frustrating session is that it informs and motivates your theoretical learning. You will have questions in mind, and when you learn new things, you will immediately have a place to implement them.
Your next analysis session will probably be a little more productive, but still not productive enough to do at work. You go again to your learning and theory.
Do this enough times, and your time will become mostly productive, eventually you will be doing real work during working hours. The ideal scenario is where you are productive enough to do work, but every time use some time to research better techniques, which improves your work as well. By then you will start to get paid for learning, and your clients will be happily sponsoring you!
Suggested next steps
For the learning path a Data Science course would be great, especially if you get feedback on your work, and you can follow the topics in the order recommended.
If you go with Python I suggest the following libraries:
- pandas: The workhorse of all your tasks in preparing, cleaning, reshaping data whichever way you want. Fluency in pandas allows you to have full control over your data, which will help you immensely in visualization, general analysis, and machine learning
- Plotly and Dash: This is my favorite data visualization library, although there are many others. What I mostly like about it, is that it produces interactive and responsive HTML charts by default. It is very detailed and thorough in its options, yet simple to use. Plotly also includes Plotly Express, which is a high-level plotting tool, which is more intuitive to use, and takes a data-oriented approach (as opposed to a chart-oriented approach). Plotly also created Dash, which is the tool for creating interactive dashboards, but also serves as a full front-end web development framework. Other important data visualization libraries are matplotlib, altair, and bokeh, and for interactive data apps, there is panel and streamlit. Another important feature is that Plotly and Dash are available in all languages used in Data Science. You might use other libraries, and this is just my personal preference. Speaking of personal preferences:
- advertools: This is a library that I created to provide various online marketing tools, most importantly, an SEO crawler, log file parser and compressor, multi robots.txt parser, recursive sitemap parser, SEM keyword and text ad generator for large scale campaigns, weighted frequency word counter, Google SERP downloader, YouTube data API, and a few other tools. It is still evolving, and you are more than welcome to contribute any suggestions, bugs, or issues you might have with it.
These should be enough for beginners, and when you are familiar with them, you can do your own research for more specialized libraries, machine learning and deep learning tools, or libraries that are specialized in performance, or a special niche use-case.