
Ciencia de datos para SEO y marketing digital: una guía sugerida para principiantes
Publicado: 2021-12-07Dado que la mayor parte de nuestro trabajo gira en torno a los datos, y dado que el campo de la ciencia de datos se está volviendo mucho más grande y mucho más accesible para los principiantes, me gustaría compartir algunas ideas sobre cómo puede ingresar a este campo para mejorar su SEO y marketing. habilidades en general.
¿Qué es la ciencia de los datos?
Un diagrama muy conocido que se utiliza para dar una visión general de este campo es el diagrama de Venn de Drew Conway que muestra la ciencia de datos como la intersección de estadísticas, piratería (habilidades de programación avanzadas en general, y no necesariamente penetrar redes y causar daños) y análisis sustantivo. experiencia o “conocimiento del dominio”:
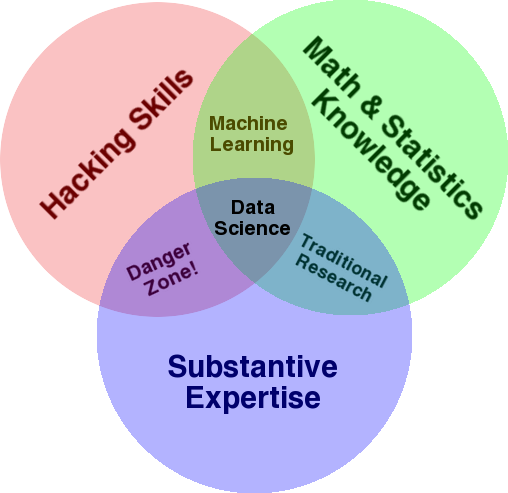
Fuente: oreilly.com
Cuando comencé a aprender, rápidamente me di cuenta de que esto es exactamente lo que ya hacemos. La única diferencia es que lo estaba haciendo con herramientas más básicas y manuales.
Si miras el diagrama, verás fácilmente que probablemente ya lo hayas hecho. Utiliza una computadora (habilidades de piratería), para analizar datos (estadísticas), para resolver un problema práctico utilizando su experiencia sustantiva en SEO (o cualquier especialidad en la que se concentre).
Su “lenguaje de programación” actual es probablemente una hoja de cálculo (Excel, Google Sheets, etc.), y lo más probable es que use Powerpoint o algo similar para comunicar ideas. Ampliemos un poco estos elementos.
- Conocimiento del dominio: comencemos con su principal fortaleza, ya que ya conoce su área de especialización. Tenga en cuenta que esta es una parte esencial de ser un científico de datos, y aquí es donde puede desarrollar y proteger su conocimiento. Hace unos meses, estaba discutiendo el análisis de un conjunto de datos de rastreo con un amigo mío. Es físico y realiza una investigación posdoctoral en computadoras cuánticas. Sus conocimientos y habilidades en matemáticas y estadísticas van mucho más allá de los míos, y realmente sabe cómo analizar datos mucho mejor que yo. Un problema. No sabía qué era un "404" (o por qué nos importaría un "301"). Entonces, con todo su conocimiento matemático, no pudo entender la columna "estado" en el conjunto de datos de rastreo. Naturalmente, no sabría qué hacer con esos datos, con quién hablar y qué estrategias construir en función de esos códigos de estado (o si buscar en otra parte). Tú y yo sabemos qué hacer con ellos, o al menos sabemos dónde más buscar si queremos profundizar más.
- Matemáticas y estadísticas: si usa Excel para obtener el promedio de una muestra de datos, está usando estadísticas. El promedio es una estadística que describe un cierto aspecto de una muestra de datos. Las estadísticas más avanzadas ayudarán a comprender sus datos. Esto también es esencial, y no soy un experto en esta área. Cuantas más distribuciones estadísticas conozca, más ideas tendrá sobre cómo analizar datos. Cuantos más temas fundamentales conozca, mejor podrá formular sus hipótesis y hacer afirmaciones precisas sobre sus conjuntos de datos.
- Habilidades de programación: Discutiré esto con más detalle a continuación, pero principalmente aquí es donde desarrollas la flexibilidad de decirle a la computadora que haga exactamente lo que quieres que haga, en lugar de quedarte atrapado con un programa fácil de usar pero ligeramente restrictivo. instrumentos. Esta es su forma principal de obtener, remodelar y limpiar sus datos, de la forma que desee, allanando el camino para que pueda tener "conversaciones" abiertas y flexibles con sus datos.
Ahora echemos un vistazo a lo que normalmente hacemos en Data Science.
El ciclo de la ciencia de datos
Un proyecto típico de ciencia de datos o incluso una tarea, por lo general se parece a esto:
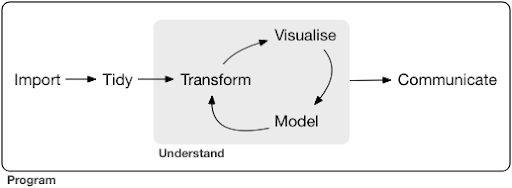
Fuente: r4ds.had.co.nz
También recomiendo leer este libro de Hadley Wickham y Garrett Grolemund, que sirve como una excelente introducción a la ciencia de datos. Está escrito con ejemplos del lenguaje de programación R, pero los conceptos y el código se pueden entender fácilmente si solo conoces Python.
Como puede ver en el diagrama, primero debemos importar nuestros datos de alguna manera, ordenarlos y luego comenzar a trabajar en el ciclo interno de transformación, visualización y modelo. Después de eso, comunicamos los resultados a los demás.
Esos pasos pueden variar desde extremadamente simples hasta muy complejos. Por ejemplo, el paso "Importar" puede ser tan simple como leer un archivo CSV y, en algunos casos, puede consistir en un proyecto de web scraping muy complicado para obtener los datos. Varios de los elementos del proceso son especialidades completas por derecho propio.
Podemos asignar fácilmente esto a algunos procesos familiares que conocemos. Por ejemplo, puede comenzar obteniendo algunos metadatos sobre un sitio web, descargando sus robots.txt y mapas del sitio XML. Probablemente luego rastrearía y posiblemente también obtendría algunos datos sobre posiciones SERP o datos de enlaces, por ejemplo. Ahora que tiene algunos conjuntos de datos, probablemente quiera fusionar algunas tablas, imputar algunos datos adicionales y comenzar a explorar/comprender. La visualización de datos puede exponer patrones ocultos, ayudarlo a descubrir qué está sucediendo o quizás plantear más preguntas. Probablemente también desee modelar sus datos utilizando algunas estadísticas básicas o modelos de aprendizaje automático y, con suerte, obtener algunas ideas. Por supuesto, debe comunicar los hallazgos y las preguntas a otras partes interesadas en el proyecto.
Una vez que esté lo suficientemente familiarizado con las diversas herramientas disponibles para cada uno de estos procesos, puede comenzar a crear sus propias canalizaciones personalizadas que sean específicas para un determinado sitio web, porque cada empresa es única y tiene un conjunto especial de requisitos. Eventualmente, comenzará a encontrar patrones y no tendrá que rehacer todo el trabajo para proyectos/sitios web similares.
Hay numerosas herramientas y bibliotecas disponibles para cada elemento en este proceso y puede ser bastante abrumador elegir la herramienta (e invertir su tiempo en aprender). Echemos un vistazo a un posible enfoque que encuentro útil para seleccionar las herramientas que uso.
Elección de herramientas y compensaciones (3 formas de tener una pizza)
¿Debería usar Excel para su trabajo diario en el procesamiento de datos, o vale la pena aprender Python?
¿Es mejor visualizar con algo como Power BI, o debería invertir en aprender sobre la gramática de los gráficos y aprender a usar las bibliotecas que la implementan?
¿Produciría un mejor trabajo creando sus propios paneles interactivos con R o Python, o simplemente debería usar Google Data Studio?
Primero exploremos las compensaciones involucradas en la selección de varias herramientas en diferentes niveles de abstracción. Este es un extracto de mi libro sobre la creación de paneles interactivos y aplicaciones de datos con Plotly y Dash, y considero que este enfoque es útil:
Considere tres enfoques diferentes para comer una pizza:
- El enfoque de pedido: Llamas a un restaurante y pides tu pizza. Llega a tu puerta en media hora, y empiezas a comer.
- El enfoque del supermercado: vas a un supermercado, compras masa, queso, verduras y todos los demás ingredientes. Luego haces la pizza tú mismo.
- El enfoque de la granja: cultivas tomates en tu patio trasero. Cría vacas, las ordeña y convierte la leche en queso, y así sucesivamente.
A medida que avanzamos hacia interfaces de nivel superior, hacia el enfoque de pedidos, la cantidad de conocimiento requerida disminuye mucho. Alguien más tiene la responsabilidad y la calidad es controlada por las fuerzas del mercado de la reputación y la competencia.
El precio que pagamos por esto es la disminución de la libertad y las opciones. Cada restaurante tiene un conjunto de opciones para elegir, y usted debe elegir entre esas opciones.
Al bajar a niveles más bajos, aumenta la cantidad de conocimiento requerido, tenemos que manejar más complejidad, tenemos más responsabilidad por los resultados y toma mucho más tiempo. Lo que ganamos aquí es mucha más libertad y poder para personalizar nuestros resultados de la manera que queremos. El costo también es un beneficio importante, pero solo en una escala lo suficientemente grande. Si solo quieres comer una pizza hoy, probablemente sea más barato pedirla. Pero si planea tener uno todos los días, entonces puede esperar grandes ahorros de costos si lo hace usted mismo.
Estos son los tipos de elecciones que tendrá que hacer al elegir qué herramientas usar y aprender. Usar un lenguaje de programación como R o Python requiere mucho más trabajo y es más difícil que Excel, con el beneficio de hacerlo mucho más productivo y poderoso.
La elección también es importante para cada herramienta o proceso. Por ejemplo, puede usar un rastreador de alto nivel y fácil de usar para recopilar datos sobre un sitio web y, sin embargo, puede preferir usar un lenguaje de programación para visualizar los datos, con todas las opciones disponibles. La elección de la herramienta adecuada para el proceso correcto depende de sus necesidades y, con suerte, la compensación descrita anteriormente puede ayudar a tomar esta decisión. Con suerte, esto también ayuda a abordar la cuestión de si Python o R quiere aprender o no (o cuánto).
Llevemos esta pregunta un poco más lejos y veamos por qué aprender Python para SEO podría no ser la palabra clave correcta.
Por qué "Python for SEO" es engañoso
¿Te gustaría convertirte en un gran blogger o quieres aprender WordPress?
¿Te gustaría convertirte en diseñador gráfico o tu objetivo es aprender Photoshop?
¿Está interesado en impulsar su carrera de SEO llevando sus habilidades de datos al siguiente nivel, o quiere aprender Python?
En los primeros cinco minutos de la primera clase del curso de ciencias de la computación en el MIT, el profesor Harold Abelson abre el curso diciéndoles a los estudiantes por qué "ciencias de la computación" es un nombre tan malo para la disciplina que están a punto de aprender. Creo que es muy interesante ver los primeros cinco minutos de la conferencia:
Cuando un campo recién está comenzando y realmente no lo comprende muy bien, es muy fácil confundir la esencia de lo que está haciendo con las herramientas que utiliza. –Harold Abelson
Estamos tratando de mejorar nuestra presencia y resultados en línea, y mucho de lo que hacemos se basa en comprender, visualizar, manipular y manejar datos en general, y este es nuestro enfoque, independientemente de la herramienta utilizada. Data Science es el campo que tiene los marcos intelectuales para hacer eso, así como muchas herramientas para implementar lo que queremos hacer. Python podría ser su lenguaje de programación (herramienta) de elección, y definitivamente es importante aprenderlo bien. También es tan importante, si no más importante, centrarse en la "esencia de lo que está haciendo", procesando y analizando datos, en nuestro caso.
El enfoque principal debe estar en los procesos discutidos anteriormente (importar, ordenar, visualizar, etc.), a diferencia del lenguaje de programación elegido. O mejor, cómo usar ese lenguaje de programación para lograr tus tareas, en lugar de simplemente aprender un lenguaje de programación.
¿A quién le importan todas estas distinciones teóricas si voy a aprender Python de todos modos?
Echemos un vistazo a lo que podría suceder si se enfoca en aprender sobre la herramienta, en lugar de la esencia de lo que está haciendo. Aquí, comparamos la búsqueda de "aprender wordpress" (la herramienta) versus "aprender bloguear" (lo que queremos hacer):
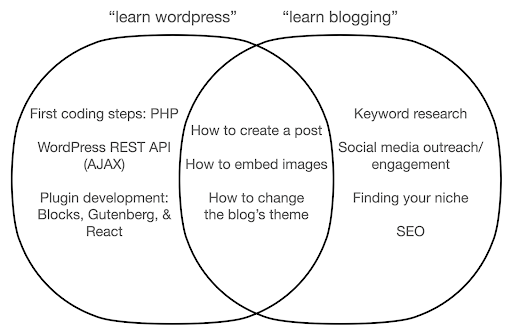
El diagrama muestra posibles temas bajo un libro o curso que enseña sobre la palabra clave en la parte superior. El área de intersección en el medio muestra temas que pueden ocurrir en ambos tipos de curso/libro.
Si te enfocas en la herramienta, sin duda terminarás teniendo que aprender sobre cosas que realmente no necesitas, especialmente como principiante. Estos temas pueden confundirlo y frustrarlo, especialmente si no tiene experiencia técnica o de programación.
También aprenderás cosas que son útiles para convertirte en un buen blogger (los temas en el área de intersección). Estos temas son extremadamente fáciles de enseñar (cómo crear una publicación de blog), pero no le dicen mucho acerca de por qué debe escribir un blog, cuándo y sobre qué. Esto no es una falla en un libro centrado en herramientas, porque al aprender sobre una herramienta, sería suficiente aprender cómo crear una publicación de blog y seguir adelante.
Como blogger, probablemente esté más interesado en el qué y el por qué de los blogs, y eso no se cubriría en libros centrados en herramientas.
Obviamente, las cosas estratégicas e importantes como SEO, encontrar su nicho, etc., no se cubrirán, por lo que se estaría perdiendo cosas muy importantes.
¿Cuáles son algunos de los temas de ciencia de datos que probablemente no aprenderá en un libro de programación?
Como vimos, tomar un Python o un libro de programación probablemente signifique que quieres convertirte en ingeniero de software. Naturalmente, los temas estarían orientados hacia ese fin. Si busca un libro de ciencia de datos, obtendrá temas y herramientas más orientados al análisis de datos.
Podemos usar el primer diagrama (que muestra el ciclo de Data Science) como guía y buscar de manera proactiva esos temas: "importar datos con python", "ordenar datos con r", "visualizar datos con python", etc. Echemos un vistazo más profundo a esos temas y explorémoslos más a fondo:
Importar
Naturalmente, primero necesitamos obtener algunos datos. Esto puede ser:
- Un archivo en nuestra computadora: el caso más sencillo en el que simplemente abre el archivo con el lenguaje de programación que elija. Es importante tener en cuenta que hay muchos formatos de archivo diferentes y que tiene muchas opciones al abrir/leer los archivos. Por ejemplo, la función read_csv de la biblioteca pandas (una herramienta esencial de manipulación de datos en Python) tiene cincuenta opciones para elegir al abrir el archivo. Contiene cosas como la ruta del archivo, las columnas para elegir, la cantidad de filas para abrir, la interpretación de los objetos de fecha y hora, cómo lidiar con los valores faltantes y mucho más. Es importante estar familiarizado con esas opciones y las diversas consideraciones al abrir diferentes formatos de archivo. Además, pandas tiene diecinueve funciones diferentes que comienzan con read_ para varios formatos de archivos y datos.
- Exportar desde una herramienta en línea: probablemente esté familiarizado con esto, y aquí puede personalizar sus datos y luego exportarlos, después de lo cual los abrirá como un archivo en su computadora.
- Llamadas API para obtener datos específicos: esto está en un nivel más bajo y más cerca del enfoque de granja mencionado anteriormente. En este caso, envía una solicitud con requisitos específicos y obtiene los datos que desea. La ventaja aquí es que puede personalizar exactamente lo que desea obtener y formatearlo de formas que podrían no estar disponibles en la interfaz en línea. Por ejemplo, en Google Analytics puede agregar una dimensión secundaria a una tabla que está analizando, pero no puede agregar una tercera. También está limitado por la cantidad de filas que puede exportar. La API le brinda más flexibilidad y también puede automatizar ciertas llamadas para que se realicen periódicamente, como parte de una tubería de análisis/recopilación de datos más grande.
- Rastreo y raspado de datos: probablemente tenga su rastreador favorito y probablemente esté familiarizado con el proceso. Este ya es un proceso flexible, que nos permite extraer elementos personalizados de las páginas, rastrear solo ciertas páginas, etc.
- Una combinación de métodos que involucran automatización, extracción personalizada y posiblemente aprendizaje automático para usos especiales.
Una vez que tenemos algunos datos, queremos pasar al siguiente nivel.
Ordenado
Un conjunto de datos "ordenado" es un conjunto de datos organizado de cierta manera. También se conoce como datos de "formato largo". El capítulo 12 del libro R for Data Science analiza el concepto de datos ordenados con más detalle si está interesado.
Eche un vistazo a las tres tablas a continuación e intente encontrar cualquier diferencia:
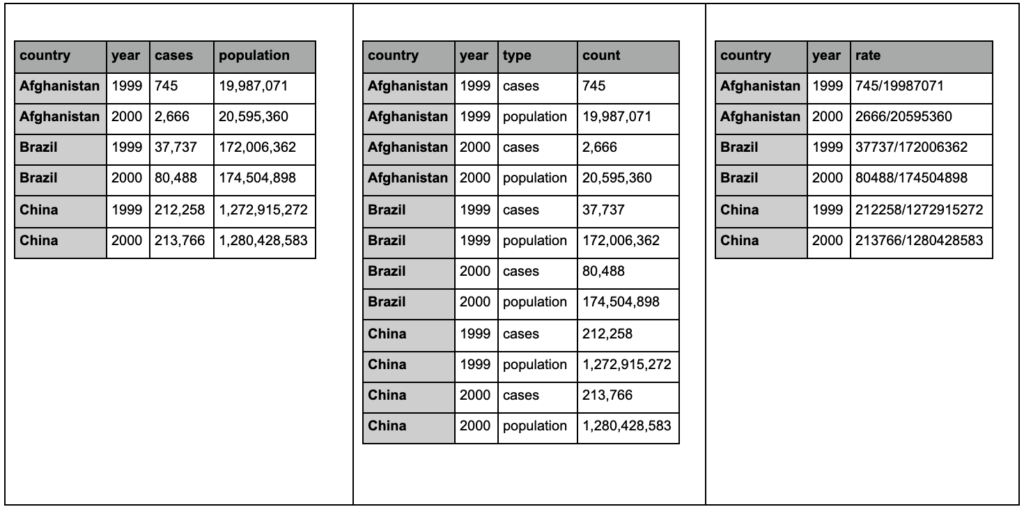
Ejemplos de tablas del paquete tidyr.
Encontrará que las tres tablas contienen exactamente la misma información, pero organizada y presentada de diferentes maneras. Podemos tener casos y población en dos columnas separadas (tabla 1), o tener una columna para decirnos cuál es la observación (casos o población) y una columna de "recuento" para contar esos casos (tabla 2). En la tabla 3, se muestran como tasas.
Cuando trabaje con datos, encontrará que las diferentes fuentes organizan los datos de manera diferente, y que a menudo necesitará cambiar de/a ciertos formatos para un análisis mejor y más fácil. Estar familiarizado con estas operaciones de limpieza es crucial, y el paquete tidyr en R contiene herramientas especiales para eso. También puede usar pandas si prefiere Python, y puede consultar las funciones de fusión y pivote para eso.
Una vez que nuestros datos están en un formato determinado, es posible que deseemos manipularlos aún más.
Transformar
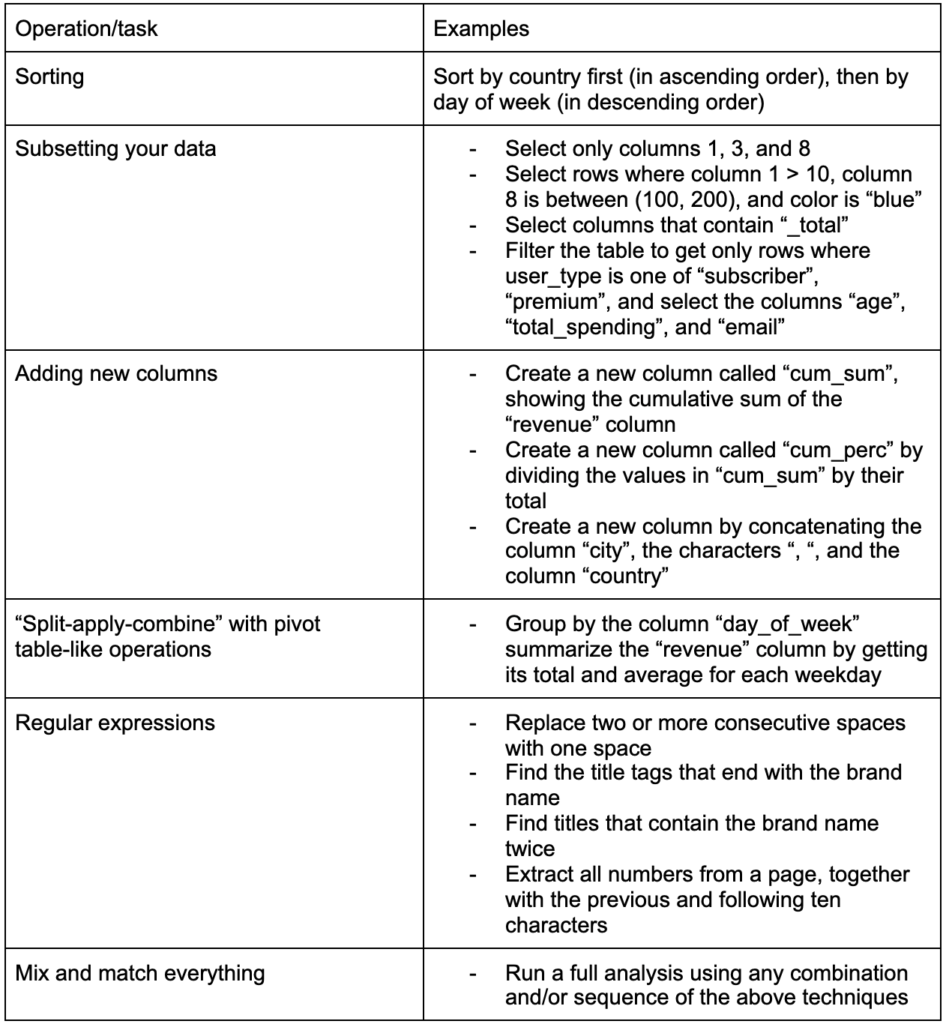
Otra habilidad crucial para desarrollar es la capacidad de realizar los cambios que desee en los datos con los que está trabajando. El escenario ideal es llegar a la etapa en la que pueda tener conversaciones con sus datos y ser capaz de segmentar de la manera que desee para hacer preguntas muy específicas y, con suerte, obtener información interesante. Estas son algunas de las tareas de transformación más importantes que probablemente necesitará mucho con algunas tareas de ejemplo que podrían interesarle:
Después de obtener, ordenar y poner nuestros datos en el formato deseado, sería bueno poder visualizarlos.
Visualizar
La visualización de datos es un tema enorme, y hay libros completos sobre algunos de sus subtemas. Es una de esas cosas que puede proporcionar mucha información sobre nuestros datos, especialmente porque utiliza elementos visuales intuitivos para comunicar información. La altura relativa de las barras en un gráfico de barras nos muestra inmediatamente su cantidad relativa, por ejemplo. La intensidad del color, la ubicación relativa y muchos otros atributos visuales son fácilmente reconocibles y entendidos por los lectores.
¡Un buen gráfico vale más que mil palabras (clave)!
Dado que hay numerosos temas para analizar en la visualización de datos, simplemente compartiré algunos ejemplos que pueden ser interesantes. Varios de ellos son los componentes básicos de este tablero de datos de pobreza, si desea conocer todos los detalles.
A veces, todo lo que necesita para comparar valores es un gráfico de barras simple, donde las barras se pueden mostrar vertical u horizontalmente:
Es posible que le interese explorar ciertos países y profundizar más, al ver cómo han progresado en ciertas métricas. En este caso, es posible que desee mostrar varios gráficos de barras en el mismo gráfico:
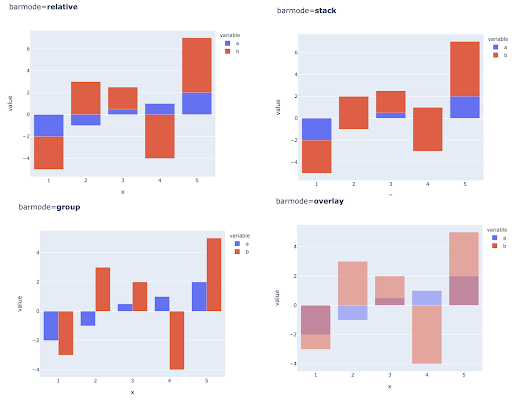
La comparación de múltiples valores para múltiples observaciones también se puede hacer colocando varias barras en cada posición del eje X, estas son las principales formas de hacerlo:
Elección de color y escalas de color: una parte esencial de la visualización de datos y algo que puede comunicar información de manera extremadamente eficiente e intuitiva si se hace correctamente.
Escalas de colores categóricas: útiles para expresar datos categóricos. Como su nombre indica, este es el tipo de datos que muestra a qué categoría pertenece una determinada observación. En este caso, queremos colores que sean lo más distintos posible entre sí para mostrar diferencias claras en las categorías (especialmente para los elementos visuales que se muestran uno al lado del otro).
El siguiente ejemplo utiliza una escala de colores categóricos para mostrar qué sistema de gobierno se implementa en cada país. Es bastante fácil conectar los colores de los países con la leyenda que muestra qué sistema de gobierno se usa. Esto también se llama un mapa de coropletas:
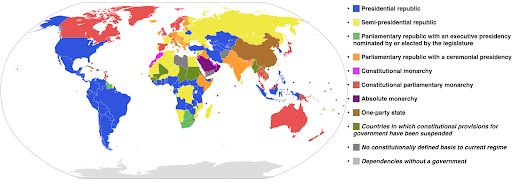
Fuente: Wikipedia
A veces los datos que queremos visualizar son para la misma métrica, y cada país (o cualquier otro tipo de observación) cae en un punto determinado de un continuo que oscila entre los puntos mínimo y máximo. En otras palabras, queremos visualizar los grados de esa métrica.
En estos casos necesitamos encontrar una escala de color continua (o secuencial) . Inmediatamente queda claro en el siguiente ejemplo qué países son más azules (y, por lo tanto, obtienen más tráfico), y podemos comprender intuitivamente las diferencias matizadas entre países.
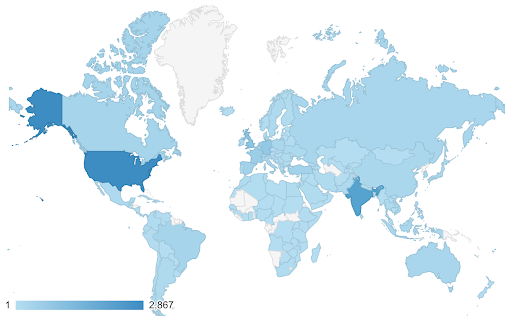
Sus datos pueden ser continuos (como el gráfico del mapa de tráfico anterior), pero lo importante de los números puede ser cuánto divergen de un punto determinado. Las escalas de color divergentes son útiles en este caso.
El siguiente gráfico muestra las tasas netas de crecimiento de la población. En este caso, es interesante saber primero si un determinado país tiene o no una tasa de crecimiento positiva o negativa. O bien, queremos saber qué tan lejos está cada país de cero (y cuánto). Echar un vistazo al mapa nos muestra inmediatamente la población de qué países está creciendo y cuál está disminuyendo. La leyenda también nos muestra que la tasa positiva máxima es del 3,5% y que la negativa máxima es del -0,5%. Esto también nos da una indicación sobre el rango de valores (positivo y negativo).

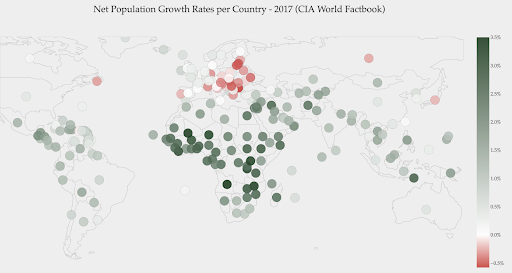
Fuente: Dashboardom.com
Desafortunadamente, los colores elegidos para esta escala no son los ideales, porque es posible que las personas daltónicas no puedan distinguir correctamente entre el rojo y el verde. Esta es una consideración muy importante al elegir nuestras escalas de color.
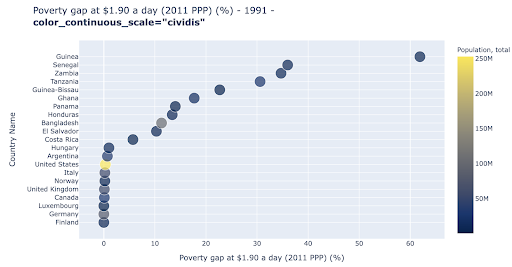
El gráfico de dispersión es uno de los tipos de gráfico más utilizados y versátiles. La posición de los puntos (o cualquier otro marcador) transmite la cantidad que estamos tratando de comunicar. Además de la posición, podemos usar varios otros atributos visuales como el color, el tamaño y la forma para comunicar aún más información. El siguiente ejemplo muestra el porcentaje de población que vive a $1.9/día, que podemos ver claramente como la distancia horizontal de los puntos.
También podemos agregar una nueva dimensión a nuestro gráfico usando color. Esto corresponde a visualizar una tercera columna del mismo conjunto de datos, que en este caso muestra datos de población.
Ahora podemos ver que el caso más extremo en términos de población (EE. UU.), es muy bajo en la métrica del nivel de pobreza. Esto añade riqueza a nuestros gráficos. También podríamos haber usado el tamaño y la forma para visualizar aún más columnas de nuestro conjunto de datos. Sin embargo, debemos lograr un buen equilibrio entre la riqueza y la legibilidad.
Podríamos estar interesados en verificar si existe una relación entre la población y los niveles de pobreza, y así podemos visualizar el mismo conjunto de datos de una manera ligeramente diferente para ver si existe tal relación:
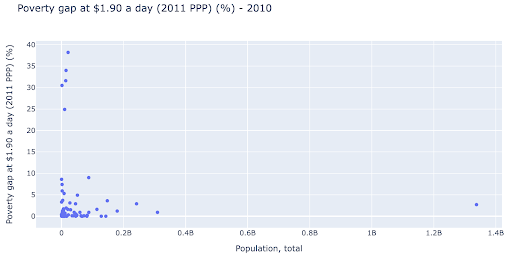
Tenemos un valor atípico en la población de alrededor de 1.35B, y esto significa que tenemos muchos espacios en blanco en el gráfico, lo que también significa que muchos valores están comprimidos en un área muy pequeña. También tenemos muchos puntos superpuestos, lo que hace que sea muy difícil detectar diferencias o tendencias.
El siguiente cuadro contiene la misma información pero se visualiza de manera diferente usando dos técnicas:
- Escala logarítmica : solemos ver los datos en una escala aditiva. En otras palabras, cada punto del eje (X o Y) representa una suma de cierta cantidad de los datos visualizados. También podemos tener escalas multiplicativas, en cuyo caso por cada nuevo punto en el eje X multiplicamos (por diez en este ejemplo). Esto permite que los puntos se dispersen y necesitamos pensar en múltiplos en lugar de sumas, como lo hicimos en el cuadro anterior.
- Usar un marcador diferente (círculos vacíos más grandes) : seleccionar una forma diferente para nuestros marcadores resolvió el problema de "trazado excesivo" donde podríamos tener varios puntos uno encima del otro en la misma ubicación, lo que hace que sea muy difícil incluso ver cuantos puntos tenemos.
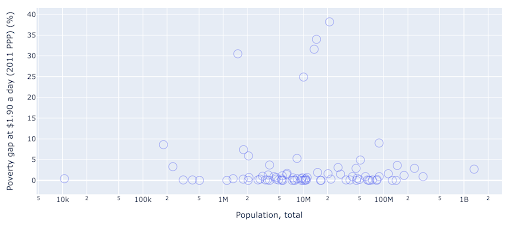
Ahora podemos ver que hay un grupo de países alrededor de la marca de los 10 millones, y también otros grupos más pequeños.
Como mencioné, hay muchos más tipos de caracteres y opciones de visualización, y libros completos escritos sobre el tema. Espero que esto te dé algunos pensamientos interesantes para experimentar.
Datos de seguimiento³
 Aprende más
Aprende másModelo
Necesitamos simplificar nuestros datos y encontrar patrones, hacer predicciones o simplemente entenderlos mejor. Este es otro gran tema, y puede abarcar desde simplemente obtener algunas estadísticas resumidas (promedio, mediana, desviación estándar, etc.) hasta modelar visualmente nuestros datos, usando un modelo que resuma o encuentre una tendencia, hasta usar técnicas más complejas para obtener una fórmula matemática para nuestros datos. También podemos usar el aprendizaje automático para ayudarnos a descubrir más información en nuestros datos.
Nuevamente, esta no es una discusión completa del tema, pero me gustaría compartir un par de ejemplos en los que podría usar algunas técnicas de aprendizaje automático para ayudarlo.
En un conjunto de datos de rastreo, estaba tratando de aprender un poco más sobre las páginas 404 y si puedo descubrir algo sobre ellas. Mi primer intento fue verificar si había una correlación entre el tamaño de la página y su código de estado, y la había, ¡una correlación casi perfecta!
Me sentí como un genio, por unos minutos, y rápidamente regresé al planeta Tierra.
Las páginas 404 estaban todas en un rango muy estrecho de tamaño de página que casi todas las páginas con una cierta cantidad de kilobytes tenían un código de estado 404. Luego me di cuenta de que las páginas 404, por definición, no tienen ningún contenido aparte de, bueno, ¡“página de error 404”! Y por eso tenían el mismo tamaño.
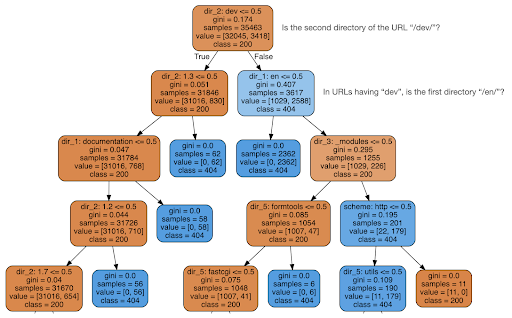
Luego decidí verificar si el contenido podía decirme algo sobre el código de estado, así que dividí las URL en sus elementos y ejecuté un clasificador de árboles de decisión usando sklearn. Esta es básicamente una técnica que produce un árbol de decisión, donde seguir sus reglas podría llevarnos a aprender cómo encontrar nuestro objetivo, 404 páginas en este caso.
En el siguiente árbol de decisiones, la primera línea de cada cuadro muestra la regla a seguir o verificar, la línea de "muestras" es el número de observaciones que se encuentran en este cuadro, y la línea de "clase" nos dice la clase de la observación actual. , en este caso, sea o no su código de estado 200 o 404.
No entraré en más detalles, y sé que el árbol de decisiones puede no ser claro si no está familiarizado con ellos, y puede explorar el conjunto de datos de rastreo sin procesar y el código de análisis si está interesado.
Básicamente, lo que descubrió el árbol de decisiones fue cómo encontrar casi todas las páginas 404, utilizando la estructura de directorios de las URL. Como puede ver, encontramos 3.617 URL, simplemente comprobando si el segundo directorio de la URL era o no “/dev/” (primer cuadro azul claro en la segunda línea desde arriba). Así que ahora sabemos cómo ubicar nuestros 404, y parece que casi todos están en la sección "/dev/" del sitio. Esto definitivamente fue un gran ahorro de tiempo. Imagine recorrer manualmente todas las estructuras y combinaciones de URL posibles para encontrar esta regla.
Todavía no tenemos la imagen completa y por qué sucede esto, y esto se puede seguir investigando, pero al menos ahora hemos localizado fácilmente esas URL.
Otra técnica que le puede interesar es la agrupación en clústeres de KMeans, que agrupa puntos de datos en varios grupos o clústeres. Esta es una técnica de "aprendizaje no supervisado", donde el algoritmo nos ayuda a descubrir patrones que no sabíamos que existían.
Imagina que tienes un montón de números, digamos la población de los países, y quieres agruparlos en dos grupos, grandes y pequeños. ¿Cómo lo harías tú? ¿Dónde dibujarías la línea?
Esto es diferente de obtener los diez primeros países, o el X% superior de los países. Esto sería muy fácil, podemos ordenar los países por población y obtener los X principales como queramos.
Lo que queremos es agruparlos como "grandes" y "pequeños" en relación con este conjunto de datos y suponiendo que no sabemos nada sobre las poblaciones del país.
Esto se puede extender aún más para tratar de agrupar a los países en tres categorías: pequeños, medianos y grandes. Esto se vuelve mucho más difícil de hacer manualmente, si queremos cinco, seis o más grupos.
Tenga en cuenta que no sabemos cuántos países terminarán en cada grupo, ya que no estamos preguntando por los primeros X países. Agrupados en dos grupos, podemos ver que tenemos solo dos países en el grupo grande: China e India. Esto tiene sentido intuitivo, ya que estos dos países tienen una población promedio que está muy lejos de todos los demás países. Este grupo de países tiene su propio promedio y sus países están más cerca entre sí que los países del otro grupo:
Países agrupados en dos grupos por población 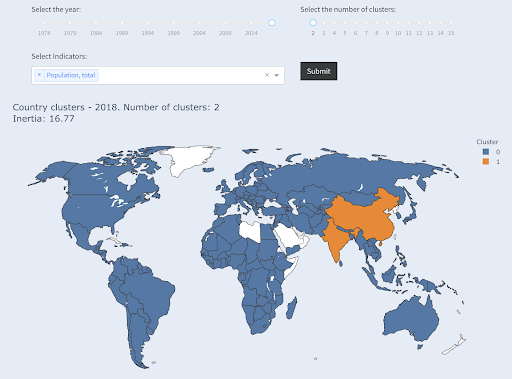
El tercer país más grande en términos de población (EE. UU. ~ 330 millones) se agrupó con todos los demás, incluidos los países que tienen una población de un millón. Eso es porque 330M está mucho más cerca de 1M que de 1.300 millones. Si hubiéramos pedido tres grupos, habríamos obtenido una imagen diferente:
Países agrupados en tres grupos por población 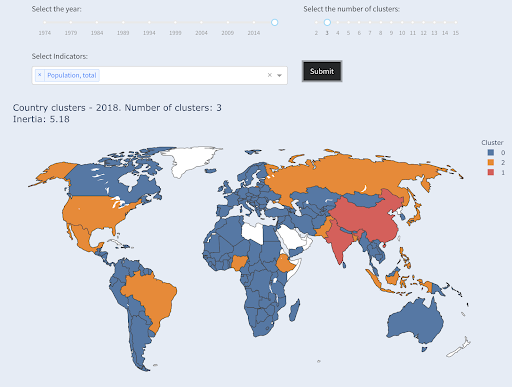
Y así es como se agruparían los países si pidiéramos cuatro clústeres:
Países agrupados en cuatro grupos por población 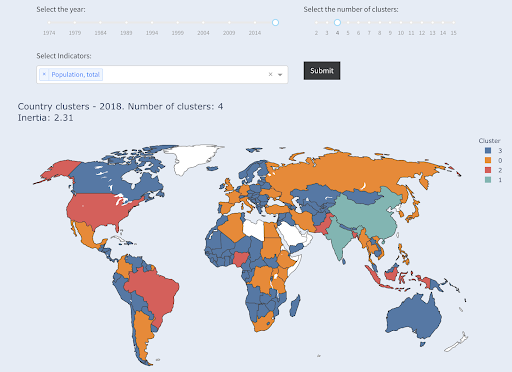
Fuente: pobrezadata.org (pestaña “Países del Clúster”)
Esto fue un agrupamiento utilizando solo una dimensión, la población, en este caso, y también puede agregar más dimensiones y ver dónde terminan los países.
Hay muchas otras técnicas y herramientas, y estos son solo algunos ejemplos que esperamos sean interesantes y prácticos.
Ahora estamos listos para comunicar nuestros hallazgos a nuestra audiencia.
Comunicar
Después de todo el trabajo que realizamos en los pasos anteriores, eventualmente debemos comunicar nuestros hallazgos a otras partes interesadas del proyecto.
Una de las herramientas más importantes en la ciencia de datos es el cuaderno interactivo. El cuaderno Jupyter es el más utilizado y es compatible con casi todos los lenguajes de programación, y es posible que prefiera usar el formato de cuaderno especial de RStudio, que funciona de la misma manera.
La idea principal es tener datos, código, narrativa y visualizaciones en un solo lugar, para que otras personas puedan auditarlos. Es importante mostrar cómo llegó a esas conclusiones y recomendaciones para la transparencia, así como la reproducibilidad. Otras personas deberían poder ejecutar el mismo código y obtener los mismos resultados.
Otra razón importante es la capacidad de otros, incluido el “futuro usted”, de llevar el análisis más allá y aprovechar el trabajo inicial que ha realizado, mejorarlo y expandirlo de nuevas maneras.
Por supuesto, esto supone que la audiencia se siente cómoda con el código, ¡y que incluso les importa!
También tiene la opción de exportar sus cuadernos a HTML (y varios otros formatos), excluyendo el código, de modo que termine con un informe fácil de usar y, sin embargo, conserve el código completo para reproducir el mismo análisis y resultados.
Un elemento importante de la comunicación es la visualización de datos, que también se trató brevemente anteriormente.
Aún mejor, es la visualización interactiva de datos, en cuyo caso le permite a su audiencia seleccionar valores y ver varias combinaciones de gráficos y métricas para explorar los datos aún más.
Aquí hay algunos paneles y aplicaciones de datos (algunos de ellos pueden tardar unos segundos en cargarse) que he creado para darle una idea de lo que se puede hacer.
Eventualmente, también puede crear aplicaciones personalizadas para sus proyectos, con el fin de satisfacer necesidades y requisitos especiales, y aquí hay otro conjunto de aplicaciones de SEO y marketing que pueden ser interesantes para usted.
Pasamos por los pasos principales en el ciclo de ciencia de datos y ahora exploremos otro beneficio de "aprender python".
Python es para automatización y productividad: cierto pero incompleto
Me parece que existe la creencia de que aprender Python es principalmente para volverse productivo y/o automatizar tareas.
Esto es absolutamente cierto, y no creo que tengamos que discutir el valor de poder hacer algo en una fracción del tiempo que nos llevaría hacerlo manualmente.
La otra parte faltante del argumento es el análisis de datos . Un buen análisis de datos nos brinda información e, idealmente, podemos proporcionar información procesable para guiar nuestro proceso de toma de decisiones, en función de nuestra experiencia y los datos que tenemos.
Una gran parte de lo que hacemos es tratar de comprender lo que está sucediendo, analizar la competencia, descubrir dónde está el contenido más valioso, decidir qué hacer, etc. Somos consultores, asesores y tomadores de decisiones. Poder obtener información de nuestros datos es claramente un gran beneficio, y las áreas y habilidades mencionadas aquí pueden ayudarnos a lograrlo.
¿Qué pasaría si supiera que sus etiquetas de título tienen una longitud promedio de sesenta caracteres? ¿Es bueno?
¿Qué pasa si profundizas un poco más y descubres que la mitad de tus títulos están muy por debajo de los sesenta, mientras que la otra mitad tiene muchos más caracteres (haciendo un promedio de sesenta)? In order to get practical and provide good recommendations, you need a higher-resolution view of your title tags' lengths, probably a histogram that shows the frequency of your title tag lengths at each interval so you can have a separate strategy for length. A simple table would also do, for example:
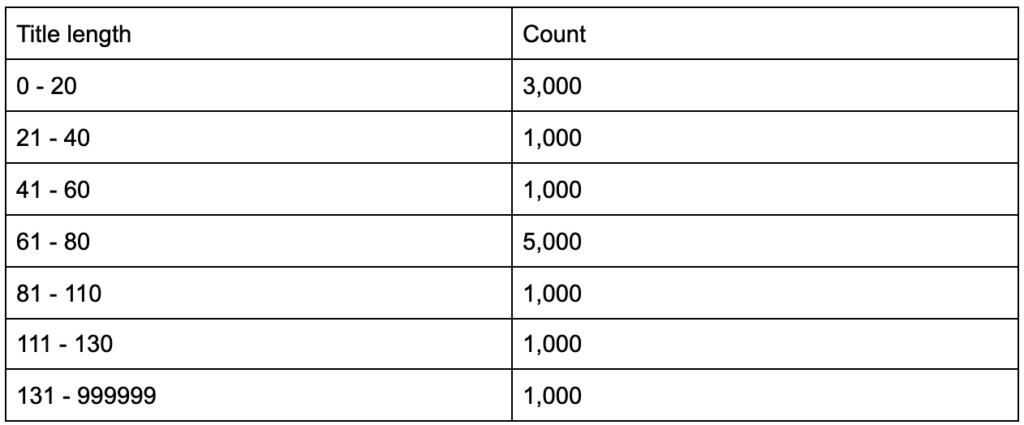
Splitting title lengths by intervals of twenty was an arbitrary decision, and you can split them the way you want. Looking at the table above, and seeing that we have three times more than the average titles in the interval (0, 20), we might want to split it further to better understand what is going on.
Having a better view than the default single-statistic summaries that we get from standard tools, allows us to employ different strategies for different lengths. For example, we can remove the brand name from the titles that are longer than a certain number of characters, and keep it in other titles.
This was an example of very simple insights, which are possible due to the flexibility we get by using a programming language, and a set of data science tools. This also allows us to iterate and modify our approach, until we find a satisfactory point that can take our analysis to the next steps.
Visualization, machine learning, modeling and general data manipulation skills allow us to get better insights on our data, even though those analyses are typically done only once. Still, if you use code to get those insights, you can always take some parts and apply to other projects, or again to the same project. In this case, the insights we got, helped us in our automation, even more. The insights would tell us what needs to be automated and what doesn't.
Should you learn Python?
Is a useless question, and the more useful one is, “How much Python (or R) should you learn?”
My view of how we use computers has evolved in the last few years.
I used to think that there were two main ways of using computers, either you are a regular user, using “point-and-click” applications to do certain tasks, or you are a developer who creates those applications that the rest of us use.

I then realized that it is more like a continuum between very high level use (pizza ordering approach), and the lower levels of the farm approach. I also realized that there is a happy sweet spot in between, where you learn enough programming to get productive and boost your data analysis skills, without having to become a software developer or engineer.
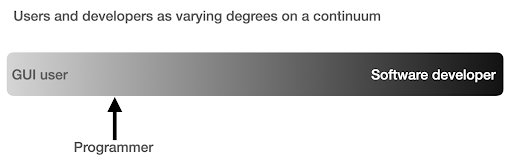
What are the main differences between being a programmer (a software user), and a software developer (or engineer)?
What are the differences between making a great coffee at home, versus establishing and running a cafe?
If making good coffee is one skill, then running a cafe requires ten other skills, most of which have nothing to do with making coffee.
You have to choose a good location (real estate), hire people (management and HR), manage cash flow and finances (accounting and finance), do marketing, legal, manage delivery, adhere to cleanliness and health standards, and so on. You can be a great coffee maker without knowing anything about those fields, but if you want to take it to the next level, you will have to manage all those additional tasks unrelated to making coffee.
The same applies to being a good programmer or data analyst versus being a software developer/engineer. There are so many other things that you have to know and worry about that you don't need as a regular programmer doing stuff for yourself and co-workers and clients. Once you have enough knowledge and skills in programming and data science, you will be in a good position to choose and decide whether you want to continue as an analyst, focusing on data science, or if you want to end up creating software that other people would use.
How do I get into Data Science?
To learn anything I think you have to do two things in parallel:
- Learn the fundamentals and the theory properly: Taking courses and reading books, and getting into the fundamentals can push you forward, as you will be gaining in weeks, knowledge that took decades to establish. It would also immediately give you ideas on things you thought were impossible, or had no idea existed.
- Get as much real world exposure and experience as possible: Experience is always important, and my suggestion is to try as soon as you can to read_csv with Python or R, to actually do so with your GA, GSC, or crawl dataset. See what else you can do (visualize, manipulate, model, etc.). See if you get errors, try to analyze the data only using your programming language.
What does frustration look like, and by when will I get productive?
It's difficult to say, and it depends on your skill, background, the hours you put in, but visualizing it like this might help you on those frustrating unproductive days:
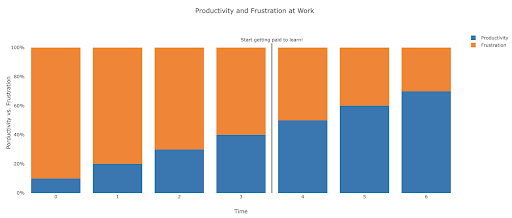
My suggestion is to take a non-trivial task, for example running an SEO audit for a site, only using Python. Your first session will mostly be frustrating, and most of the time will be spent checking documentation, and the definition of basic terms.
In parallel, you are still going through your course, and learning new stuff.
The value of that frustrating session is that it informs and motivates your theoretical learning. You will have questions in mind, and when you learn new things, you will immediately have a place to implement them.
Your next analysis session will probably be a little more productive, but still not productive enough to do at work. You go again to your learning and theory.
Do this enough times, and your time will become mostly productive, eventually you will be doing real work during working hours. The ideal scenario is where you are productive enough to do work, but every time use some time to research better techniques, which improves your work as well. By then you will start to get paid for learning, and your clients will be happily sponsoring you!
Suggested next steps
For the learning path a Data Science course would be great, especially if you get feedback on your work, and you can follow the topics in the order recommended.
If you go with Python I suggest the following libraries:
- pandas: The workhorse of all your tasks in preparing, cleaning, reshaping data whichever way you want. Fluency in pandas allows you to have full control over your data, which will help you immensely in visualization, general analysis, and machine learning
- Plotly and Dash: This is my favorite data visualization library, although there are many others. What I mostly like about it, is that it produces interactive and responsive HTML charts by default. It is very detailed and thorough in its options, yet simple to use. Plotly also includes Plotly Express, which is a high-level plotting tool, which is more intuitive to use, and takes a data-oriented approach (as opposed to a chart-oriented approach). Plotly also created Dash, which is the tool for creating interactive dashboards, but also serves as a full front-end web development framework. Other important data visualization libraries are matplotlib, altair, and bokeh, and for interactive data apps, there is panel and streamlit. Another important feature is that Plotly and Dash are available in all languages used in Data Science. You might use other libraries, and this is just my personal preference. Speaking of personal preferences:
- advertools: This is a library that I created to provide various online marketing tools, most importantly, an SEO crawler, log file parser and compressor, multi robots.txt parser, recursive sitemap parser, SEM keyword and text ad generator for large scale campaigns, weighted frequency word counter, Google SERP downloader, YouTube data API, and a few other tools. It is still evolving, and you are more than welcome to contribute any suggestions, bugs, or issues you might have with it.
These should be enough for beginners, and when you are familiar with them, you can do your own research for more specialized libraries, machine learning and deep learning tools, or libraries that are specialized in performance, or a special niche use-case.