
Le guide ultime de référencement sur site pour votre boutique en ligne
Publié: 2017-03-14Optimisation des moteurs de recherche de commerce électronique - Le guide ultime de référencement sur site…

En tant que blogueurs et propriétaires de magasins, nous voulons rendre nos sites Web attrayants à la fois pour les moteurs de recherche et les utilisateurs.
Un moteur de recherche « regarde » un site Web de manière tout à fait différente de nous, les humains. La conception de votre site Web, les graphismes sophistiqués et les articles de blog bien écrits ne comptent pour rien si vous avez manqué le référencement critique sur site couvert dans cet article.
Le référencement n'est pas mort.
Le référencement moderne ne consiste pas à tromper les moteurs de recherche - il s'agit de travailler avec les moteurs de recherche pour présenter vos produits et votre contenu de la meilleure façon possible.
Dans cet article, SEO Expert -Itamar Gero nous montre exactement comment…
Le guide ultime de référencement sur site pour les propriétaires de magasins et les blogueurs
Le commerce électronique est une entreprise énorme. Selon le United States Census Bureau , les ventes de commerce électronique aux États-Unis ont atteint à elles seules 394,9 milliards de dollars en 2016. La tendance à la hausse des ventes de commerce électronique et son influence sur la vente au détail hors ligne devraient se poursuivre jusque dans les années 2020 dans le monde entier.
Naturellement, les propriétaires de boutiques en ligne se disputent la position pour prendre des parts de plus en plus importantes du gâteau du commerce électronique. À cette fin, le référencement a toujours été une priorité absolue pour la plupart des stratégies de marketing de commerce électronique. Les moteurs de recherche génèrent le trafic le plus qualifié et le plus motivé, qui est plus facile à convertir en clients payants que les visiteurs d'autres canaux. C'est pourquoi les sites Web mènent une « guerre » constante dans les coulisses pour se surclasser les uns les autres pour les mots-clés liés à leurs produits et services.
Et bien qu'il soit décourageant d'avoir beaucoup de concurrents, vous pouvez être rassuré par le fait que de nombreux sites de commerce électronique ne font pas leur référencement correctement. Avec une solide compréhension des meilleures pratiques de référencement et beaucoup de travail acharné, vous pouvez obtenir une grande visibilité de recherche sans vous ruiner.
Guide SEO pour votre boutique en ligne - Supprimez les maux de tête !

Remarque spéciale sur ce guide SEO :
Ce guide et tutoriel SEO est l'un des plus approfondis que nous ayons jamais produits. [Plus de 7000 mots et plus de 20 images]
Il est facile d'être submergé et de se sentir confus avec le référencement, mais en réalité, c'est beaucoup plus simple qu'il n'y paraît au départ.
Les récompenses pour obtenir une bonne optimisation pour les moteurs de recherche sont ÉNORMES !
De plus, bien que ce guide soit particulièrement axé sur le référencement du commerce électronique, une grande partie de ce que nous détaillons ici s'applique également à votre blog ou au site Web de votre entreprise.
Deux ressources SEO dont vous aurez besoin :
=> Console de recherche Google
=> Screaming Frog SEO Araignée
Qu'est-ce que le référencement e-commerce ?
En termes simples, le référencement e-commerce est le processus d'optimisation d'une boutique en ligne pour une plus grande visibilité sur les moteurs de recherche. Il a quatre facettes principales, dont :
- Recherche de mots clés
- Référencement sur site
- Création de liens
- Optimisation du signal d'utilisation
Dans cet article, j'aborderai le plus fondamental et sans doute le plus crucial parmi les quatre domaines : le référencement sur site. D'après notre expérience, en travaillant avec des milliers d'agences, nous pouvons attribuer le plus grand impact sur la croissance organique globale du trafic aux optimisations que nous avons effectuées au sein des sites de commerce électronique que nous gérons.
Bien que la création de liens et d'autres activités de référencement hors page soient importantes, le référencement sur site donne le ton du succès à chaque fois.
La résurgence du référencement sur site
Le référencement sur site est le terme collectif utilisé pour décrire toutes les activités de référencement effectuées sur le site Web. Il peut être divisé en deux segments : le référencement technique et le référencement sur la page. Le référencement technique consiste principalement à s'assurer que le site reste opérationnel, opérationnel et disponible pour les explorations de robots de recherche. Le référencement sur page, en revanche, vise davantage à aider les moteurs de recherche à comprendre la pertinence contextuelle de votre site par rapport aux mots clés que vous ciblez.
Je me concentre sur le référencement sur site aujourd'hui en raison de la résurgence indéniable qu'il a connue au cours des 3 dernières années environ. Vous voyez, la communauté SEO a traversé une phase de la fin des années 2000 à environ 2011 lorsque tout le monde était obsédé par l'acquisition de liens entrants. À l'époque, les liens étaient de loin le déterminant le plus puissant du classement Google. Les sites de commerce électronique qui étaient enfermés dans des batailles de classement brutales étaient au cœur de ce mouvement et la concurrence a finalement tourné autour du question de savoir qui est en mesure d'obtenir le plus de liens - éthiquement ou autrement.
Finalement, Google a introduit les mises à jour Panda et Penguin qui ont puni de nombreux sites qui proliféraient le spam de liens et de contenu. Les liens de qualité qui ont amélioré les classements sont devenus plus difficiles à trouver, ce qui rend l'influence du signal SEO sur site plus prononcée sur les classements. La communauté SEO a rapidement commencé à voir des campagnes de référencement de commerce électronique réussies qui se concentraient davantage sur l'optimisation technique et sur la page que sur l'acquisition de liens lourds.
Cet article vous montrera ce que vous pouvez faire sur votre site pour tirer parti de la renaissance du référencement sur site :
Référencement technique
Comme mentionné précédemment, le référencement technique consiste principalement à s'assurer que votre site a une bonne disponibilité, se charge rapidement, offre une navigation sécurisée aux utilisateurs et facilite une bonne navigation des bots et des utilisateurs à travers ses pages. Voici une liste de choses que vous devez surveiller en permanence pour assurer un haut niveau de santé technique :
Le fichier Robots.txt
Le fichier robots.txt est un très petit document auquel les robots de recherche accèdent lorsqu'ils visitent votre site. Ce document leur indique quelles pages peuvent être consultées, quels bots sont les bienvenus et quelles pages sont interdites. Lorsque robots.txt interdit l'accès à une certaine page ou à un chemin de répertoire au sein d'un site Web, les bots des sites responsables adhèrent aux instructions et ne visitent pas du tout cette page. Cela signifie que les pages non autorisées ne seront pas répertoriées dans les résultats de recherche. Quelle que soit l'équité de lien qui leur est transmise, elle est annulée et ces pages ne pourront pas non plus transmettre d'équité de lien.
Lors de la vérification de votre fichier robots.txt, assurez-vous que toutes les pages destinées à l'affichage public ne relèvent d'aucun paramètre d'interdiction. De même, vous voudrez vous assurer que les pages qui ne servent pas l'intention si votre public cible ne peuvent pas être indexées.
Avoir plus de pages indexées par les moteurs de recherche peut sembler une bonne chose, mais ce n'est vraiment pas le cas. Google et d'autres portails Web essaient constamment d'améliorer la qualité des listes affichées dans leurs SERP. (pages de résultats des moteurs de recherche)
Par conséquent, ils s'attendent à ce que les webmasters soient judicieux dans les pages qu'ils soumettent à l'indexation et ils récompensent ceux qui s'y conforment.
En général, les requêtes des moteurs de recherche relèvent de l'une des trois classifications suivantes :
- Navigation
- Transactionnel
- Informationnel
Si vos pages ne satisfont pas les intentions derrière l'un de ces éléments, envisagez d'utiliser robots.txt pour empêcher les robots d'y accéder. Cela permettra de mieux utiliser votre budget de crawl et de faire passer l'équité des liens internes de votre site vers des pages plus importantes. Dans un site de commerce électronique, les types d'URL auxquels vous souhaitez généralement interdire l'accès sont :
- Pages de paiement – Il s'agit d'une série de pages que les acheteurs utilisent pour choisir et confirmer leurs achats. Ces pages sont propres à leurs sessions et n'intéressent donc personne d'autre sur Internet.
- Pages dynamiques – Ces pages sont créées à partir de demandes d'utilisateurs uniques telles que des recherches internes et des combinaisons de filtrage de pages. Comme les pages de paiement, ces pages sont générées pour un utilisateur spécifique qui a fait la demande. Par conséquent, ils ne présentent aucun intérêt pour la plupart des internautes, ce qui rend très faible l'incitation des moteurs de recherche à les indexer. De plus, ces pages finissent par expirer et envoient des réponses 404 Not Found lorsqu'elles sont réexplorées par les moteurs de recherche. Cela peut être considéré comme un signe de mauvaise santé du site qui peut avoir un impact négatif sur la visibilité de recherche d'une boutique en ligne.
Les pages dynamiques sont facilement identifiables par la présence des caractères "?" et "=" dans leurs URL. Vous pouvez empêcher leur indexation en ajoutant une ligne dans le fichier robots.txt indiquant quelque chose comme ceci : disallow: *?
- Pages de mise en scène - Il s'agit de pages en cours de développement et impropres à l'affichage public. Assurez-vous de configurer un chemin dans le répertoire de votre site spécifiquement pour les pages Web intermédiaires et assurez-vous que le fichier robots.txt bloque ce répertoire.
- Pages principales – Ces pages sont réservées aux administrateurs du site. Naturellement, vous souhaiterez que le public ne visite pas les pages – et encore moins les trouve dans les résultats de recherche. Tout, depuis votre page de connexion administrateur jusqu'aux pages de contrôle du site interne, doit être placé sous une restriction robots.txt pour empêcher toute entrée non autorisée.
Notez que le fichier robots.txt n'est pas le seul moyen de restreindre l'indexation des pages. La balise meta directive noindex, entre autres, peut également être utilisée à cette fin. Selon la nature de la situation de désindexation, l'une peut être plus appropriée que l'autre.
Le plan du site XML
Le sitemap XML est un autre document que les robots de recherche lisent pour obtenir des informations utiles. Ce fichier répertorie toutes les pages que vous souhaitez que Google et les autres araignées explorent. Un bon sitemap contient des informations qui donnent aux robots une idée de votre architecture d'informations, de la fréquence à laquelle chaque page est modifiée et de la localisation des ressources, telles que les images, dans les chemins de fichiers de votre domaine.
Bien que les sitemaps XML ne soient pas une nécessité sur un site Web, ils sont très importants pour les magasins en ligne en raison du nombre de pages d'un site de commerce électronique typique. Avec un sitemap en place et soumis à des outils comme Google Search Console , les moteurs de recherche ont tendance à trouver et à indexer les pages qui se trouvent profondément dans la hiérarchie des URL de votre site.
Votre développeur Web doit être en mesure de configurer un sitemap XML pour votre site de commerce électronique. Le plus souvent, les sites de commerce électronique l'ont déjà à la fin de leurs cycles de développement. Vous pouvez vérifier cela en allant sur [www.yoursite.com/sitemap.xml]. Si vous voyez quelque chose comme ceci, votre sitemap XML est déjà opérationnel :

Le fait d'avoir un sitemap XML ne garantit pas que toutes les URL qui y sont répertoriées seront prises en compte pour l'indexation.
La soumission du plan du site à Google Search Console garantit que le bot du géant de la recherche trouve et lit le plan du site. Pour ce faire, connectez-vous simplement à votre compte Search Console et recherchez la propriété que vous souhaitez gérer. Allez dans Crawl>Sitemaps et cliquez sur le bouton "Ajouter/Tester un nouveau sitemap" en haut à droite. Entrez simplement le slug d'URL de votre plan de site XML et cliquez sur "Soumettre".
Vous devriez pouvoir voir les données sur votre sitemap dans 2 à 4 jours. Voici à quoi cela ressemblera :
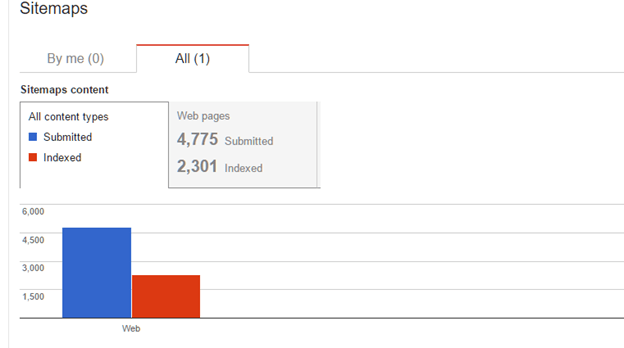
Notez que le rapport vous indique combien de pages sont soumises (répertoriées) dans le sitemap et combien de pages indexées par Google. Dans de nombreux cas, les sites de commerce électronique n'obtiendront pas toutes les pages qu'ils soumettent dans le sitemap indexé par Google. Une page peut ne pas être indexée pour l'une des raisons suivantes :
- L'URL est morte - Si une page a été délibérément supprimée ou est affligée de problèmes techniques, elle produira probablement des erreurs 4xx ou 5xx. Si l'URL est répertoriée dans le sitemap, Google n'indexera pas une page à partir d'une URL qui ne fonctionne pas correctement. De même, si une page en ligne répertoriée dans le plan du site reste indisponible pendant de longues périodes, elle peut être retirée de l'index Google.
- L'URL est redirigée - Lorsqu'une URL est redirigée et produit un code de réponse 301 ou 302, cela n'a aucun sens de l'avoir dans le sitemap. La page cible de la redirection devrait plutôt être répertoriée si elle n'y est pas déjà. Si une URL de redirection est répertoriée dans un sitemap, il y a de fortes chances que Google l'ignore simplement et la signale comme non indexée.
- L'URL est bloquée - Comme indiqué dans la section robots.txt, toutes les pages d'un site de commerce électronique n'ont pas besoin d'être indexées. Si une page Web est bloquée par robots.txt ou la balise meta noindex, cela n'a aucun sens de la lister sur le sitemap XML. La Search Console le considérera comme n'étant pas indexé précisément parce que vous lui avez demandé de ne pas l'être.
Les pages de paiement, les pages de balises de blog et d'autres pages de produits avec un contenu dupliqué sont des exemples de pages qui n'ont pas besoin d'être répertoriées dans le plan de site XML.
- L'URL a un lien canonique - La balise HTML rel=canonical est souvent utilisée dans les magasins en ligne pour indiquer aux moteurs de recherche quelle page ils souhaitent indexer parmi plusieurs pages très similaires. Cela se produit souvent lorsqu'un produit a plusieurs SKU avec de très petits attributs distinctifs. Au lieu de laisser Google choisir laquelle afficher sur les SERP, les webmasters ont eu la possibilité de dire aux moteurs de recherche quelle page est la "vraie" page qu'ils souhaitent voir apparaître.
Si votre site de commerce électronique contient des pages de produits contenant l'élément rel=canonical, il n'est pas nécessaire de les répertorier sur votre sitemap. Google les ignorera probablement de toute façon et honorera celui vers lequel ils pointent.
- La page a un contenu léger - Google définit le contenu léger comme des pages avec peu ou pas de valeur ajoutée. Les exemples incluent des pages avec peu ou pas de contenu textuel ou des pages qui contiennent du texte mais qui dupliquent d'autres pages du site ou d'ailleurs sur le Web. Lorsque Google considère qu'une page est mince, il la défavorise dans les résultats de recherche ou l'ignore carrément.
Si vous avez des pages de produits contenant du contenu passe-partout provenant de sites de fabricants ou d'autres pages de votre site, il est généralement judicieux de bloquer leur indexation jusqu'à ce que vous ayez le temps et la main-d'œuvre nécessaires pour rédiger des descriptions plus riches et plus uniques. Il s'ensuit également que vous devez éviter de répertorier ces pages sur votre sitemap XML simplement parce qu'elles sont moins susceptibles d'être indexées.
- Il y a une pénalité au niveau de la page - Dans de rares cas, les moteurs de recherche peuvent prendre des mesures manuelles ou algorithmiques contre les sites qui violent leurs directives de qualité. Si une page contient du spam ou a été piratée et infusée de logiciels malveillants, elle peut être retirée de l'index. Naturellement, vous voudrez des pages comme celles-ci hors de votre sitemap.
- L'URL est redondante - Les URL en double dans le sitemap XML, comme vous pouvez vous y attendre, ne seront pas répertoriées deux fois. Le second sera probablement ignoré et omis de l'index. Vous pouvez résoudre ce problème en ouvrant votre sitemap sur votre navigateur et en l'enregistrant en tant que document XML que vous pouvez ouvrir dans Excel. De là, allez dans l'onglet Données. Mettez en surbrillance la colonne où se trouvent les URL dans votre sitemap et cliquez sur supprimer les doublons.
- Pages restreintes - Les pages protégées par un mot de passe ou qui n'accordent l'accès qu'à des adresses IP spécifiques ne seront pas explorées par les moteurs de recherche et ne seront donc pas indexées.
Moins vous répertoriez de pages inappropriées dans votre sitemap, meilleur sera votre rapport de soumission sur indexation. Cela aide les moteurs de recherche à comprendre quelles pages de votre domaine ont les niveaux d'importance les plus élevés, ce qui leur permet d'être plus performants pour les mots-clés qu'ils représentent.
Erreurs d'exploration
Dans les magasins en ligne, des produits sont régulièrement ajoutés et supprimés en fonction de nombreux facteurs. Lorsque des pages de produits ou de catégories indexées sont supprimées, cela ne signifie pas nécessairement que les moteurs de recherche les oublient automatiquement. Les robots continueront d'essayer d'explorer ces URL pendant quelques mois jusqu'à ce qu'elles soient corrigées ou retirées de l'index en raison d'une indisponibilité chronique.
En termes techniques, les erreurs d'exploration sont des pages auxquelles les bots ne peuvent pas accéder avec succès car elles renvoient des codes d'erreur HTTP. Parmi ces codes, 404 est le plus courant mais d'autres de la gamme 4xx s'appliquent. Bien que les moteurs de recherche reconnaissent que les erreurs d'exploration sont normales sur n'importe quel site Web, leur nombre excessif peut nuire à la visibilité de la recherche. Les erreurs de crawl ont tendance à ressembler à des détails sur un site, ce qui peut perturber le bon flux d'équité des liens internes entre les pages.
Les erreurs d'exploration sont généralement causées par les événements suivants :
- Pages délibérément supprimées
- Pages supprimées accidentellement
- Pages dynamiques expirées
- Problèmes de serveur
Pour voir combien d'erreurs de crawl vous avez dans votre site ecommerce et quelles URL sont concernées, vous pouvez accéder à Google Search Console et vous rendre sur le bien concerné. Dans le menu latéral de gauche, accédez à Crawl>Crawl Errors . Vous devriez voir un rapport semblable à celui-ci :

Selon les types de pages que vous trouvez dans votre rapport d'erreur de crawl, il existe plusieurs façons distinctes de les traiter, notamment :
- Correction des pages supprimées accidentellement - Si l'URL appartient à une page qui a été supprimée par inadvertance, il suffit de republier la page sous la même adresse Web pour résoudre le problème.
- Bloquer l'indexation dynamique des pages – Comme recommandé précédemment, les pages dynamiques qui expirent et deviennent des erreurs d'exploration peuvent être évitées en bloquant l'accès des robots à l'aide de robots.txt. Si aucune page dynamique n'est indexée en premier lieu, aucune erreur de crawl ne sera détectée par les moteurs de recherche.
- 301 Rediriger l'ancienne page vers la nouvelle page – Si une page a été supprimée délibérément et qu'une nouvelle a été publiée pour la remplacer, utilisez une redirection 301 pour diriger les robots de recherche et les utilisateurs humains vers la page qui a pris sa place. Cela empêche non seulement l'apparition d'une erreur d'exploration, mais transmet également toute équité de lien que la page supprimée détenait autrefois. Cependant, ne présumez pas que le correctif pour chaque erreur d'exploration est une redirection 301. Avoir trop de redirections peut affecter négativement la vitesse du site.
- Résoudre les problèmes de serveur – Si les problèmes de serveur sont à l'origine des temps d'arrêt, travailler avec votre développeur Web et votre fournisseur de services d'hébergement est votre meilleur recours.
- Ignorez -les – Lorsque des pages sont supprimées délibérément mais qu'elles ne sont pas d'une grande importance et qu'aucune page de remplacement n'est prévue, vous pouvez simplement autoriser les moteurs de recherche à les éliminer de l'index en quelques mois.
Avoir le moins d'erreurs d'exploration possible est la marque d'une administration responsable d'une boutique en ligne. Une vérification mensuelle de votre rapport d'erreurs de crawl devrait vous permettre de rester au top.
Guide SEO des liens brisés
Les liens brisés empêchent le mouvement des araignées de recherche d'une page à l'autre. Ils sont également mauvais pour l'expérience utilisateur car ils conduisent les visiteurs à des impasses sur un site. En raison du volume de pages et des architectures d'informations complexes de la plupart des sites de commerce électronique, il est courant que des liens brisés se produisent ici et là.
Les liens brisés sont généralement causés soit par des erreurs dans les URL cibles des liens, soit par des liens vers des pages qui affichent des codes de réponse de serveur 404 Not found. Pour vérifier si votre site contient des erreurs de crawl, vous pouvez utiliser un outil appelé Screaming Frog SEO Spider . Il a une version gratuite et limitée et une version complète qui coûte 99GBP par an. Pour les petites boutiques en ligne, la version gratuite devrait suffire. Pour les sites avec des milliers de pages, vous aurez besoin de la version payante pour une analyse approfondie.
Pour vérifier les liens rompus à l'aide de Screaming Frog, configurez simplement l'application pour qu'elle fonctionne en mode Spider par défaut. Entrez l'URL de votre page d'accueil et cliquez sur le bouton Démarrer.
Attendez que le crawl se termine. Selon le nombre de pages et la vitesse de votre connexion, le crawl peut prendre plusieurs minutes à une heure.

Une fois l'exploration terminée, accédez à Exportation en bloc et cliquez sur "Tous les textes d'ancrage". Vous devrez ensuite enregistrer les données sous forme de fichier CSV et l'ouvrir dans Excel. Ça devrait ressembler à ça:

Allez à la colonne F (code d'état) et triez les valeurs de la plus grande à la plus petite. Vous devriez pouvoir trouver les liens brisés en haut. Dans ce cas, ce site n'a que 4 liens brisés.
La colonne B (Source) fait référence à la page où le lien peut être trouvé et modifié. La colonne C (Destination) fait référence à l'URL vers laquelle pointe le lien. La colonne E (ancre) se rapporte au texte où le lien sur la page source est joint.
Vous pouvez réparer les liens rompus via l'une des méthodes suivantes :
- Corrigez l'URL de destination – Si l'URL de destination a été mal orthographiée, corrigez la faute de frappe et activez le lien.
- Supprimer le lien - S'il n'y a pas eu d'erreur d'écriture sur l'URL de destination mais que la page vers laquelle il était lié n'existe plus, supprimez simplement le lien hypertexte.
- Remplacer le lien – Si le lien pointe vers une page qui a été supprimée mais qu'il existe une page de remplacement ou une autre page qui peut la remplacer, remplacez l'URL de destination dans votre CMS.
La réparation des liens brisés améliore la circulation de l'équité des liens et donne aux moteurs de recherche une meilleure impression de la santé technique de votre site.
Contenu dupliqué et référencement pour votre boutique en ligne
Comme mentionné précédemment, les magasins en ligne ont plus tendance à souffrir de problèmes de duplication de contenu en raison du nombre de produits qu'ils proposent et des similitudes dans les noms de leurs SKU. Lorsque Google détecte suffisamment de similitudes entre les pages, il prend des décisions sur les pages à afficher dans ses résultats de recherche. Malheureusement, le choix de pages de Google ne correspond généralement pas au vôtre.
Pour trouver les pages de votre site de commerce électronique susceptibles d'être affectées par des problèmes de duplication, accédez à Google Search Console et cliquez sur Search Appearance dans la barre latérale gauche. Cliquez sur le rapport sur les améliorations HTML et vous devriez voir quelque chose comme ceci :

Le texte lié bleu indique que votre site a des problèmes avec un type spécifique de problème HTML. Dans ce cas, il s'agit de balises de titre en double. Cliquer dessus permet de voir les pages concernées. Vous pouvez ensuite exporter le rapport dans un fichier CSV et l'ouvrir dans Excel.
Examinez le rapport et les URL concernées. Analysez pourquoi les balises de titre et les méta descriptions peuvent se dupliquer. Dans les boutiques en ligne, cela peut être dû à :
- Écriture paresseuse des balises de titre – Dans certains sites mal optimisés, les développeurs Web peuvent laisser toutes les pages avec les mêmes balises de titre. Il s'agit généralement de la marque du site. Cela peut être résolu en modifiant les balises de titre et en nommant chaque page de manière appropriée en fonction de l'essence de son contenu.
- Produits très similaires – Certaines boutiques en ligne proposent des produits aux propriétés très similaires. Par exemple, un magasin de commerce électronique qui vend des vêtements peut vendre une chemise disponible en 10 couleurs différentes. Si chaque couleur est traitée comme un SKU unique et est livrée avec sa propre page, les balises de titre et les méta descriptions peuvent être très similaires.
Comme mentionné dans une section précédente, l'utilisation de l'élément HTML rel=canonical peut pointer les bots vers la version de ces pages que vous souhaitez indexer. Cela aidera également les moteurs de recherche à comprendre que la duplication dans votre site est intentionnelle.
- Duplication accidentelle - Dans certains cas, les plates-formes CMS de commerce électronique peuvent être mal configurées et se déchaîner avec des duplications de pages. Si cela se produit, l'aide d'un développeur Web pour traiter la cause première est nécessaire. Vous devrez probablement supprimer les pages en double et les rediriger 301 vers l'original.
Bonus : les pages identifiées comme ayant des balises de titre courtes ou longues et des méta descriptions peuvent être traitées simplement en éditant ces champs et en veillant à respecter les paramètres de longueur. Plus d'informations à ce sujet dans la section Balises de titre et méta descriptions de ce guide.
Vitesse du site
Au fil des ans, la vitesse du site est devenue l'un des facteurs de classement les plus importants de Google. Pour que votre boutique en ligne atteigne son plein potentiel de classement, elle doit se charger rapidement pour les appareils mobiles et de bureau. Dans les batailles de mots-clés compétitives entre les magasins en ligne rivaux, le site qui a l'avantage en termes de vitesse de site surpasse généralement ses concurrents plus lents.
Pour tester les performances de votre site dans le domaine de la vitesse, accédez à Google PageSpeed insights . Copiez et collez l'URL de la page que vous souhaitez tester et appuyez sur Entrée.


Google évaluera la page sur une échelle de 1 à 100. 85 et plus sont les scores préférés. Dans cet exemple, le site testé était bien en dessous de la vitesse idéale sur ordinateur et mobile. Heureusement, Google fournit des conseils techniques sur la façon de résoudre les problèmes de temps de chargement. La compression des pages, une meilleure mise en cache, la réduction des fichiers CSS et d'autres techniques peuvent grandement améliorer les performances. Votre développeur et concepteur Web pourra vous aider avec ces améliorations.
URL sécurisées
Il y a quelques années, Google a annoncé qu'il faisait des URL sécurisées un facteur de classement. Cela a obligé de nombreux sites de commerce électronique à adopter le protocole à la recherche de gains de trafic organiques. Bien que nous ayons observé que les avantages du référencement étaient marginaux, les vrais gagnants sont les utilisateurs finaux qui bénéficient d'expériences d'achat plus sécurisées où la sécurité des données est plus difficile à compromettre.

Vous pouvez vérifier si votre boutique en ligne utilise des URL sécurisées en recherchant l'icône de cadenas dans la barre d'adresse de votre navigateur Web. Si ce n'est pas le cas, vous voudrez peut-être envisager de le faire implémenter par votre développeur. À ce jour, la plupart des sites de commerce électronique n'ont que des URL sécurisées dans leurs pages de paiement. Cependant, de plus en plus de propriétaires de boutiques en ligne passent au protocole SSL.
La mise en œuvre d'URL sécurisées dans un site de commerce électronique peut être une tâche ardue. Les moteurs de recherche voient les pages homologues HTTP et HTTPS comme deux adresses Web différentes. Par conséquent, vous devrez recréer chaque page de votre site en HTTPS et rediriger 301 tous les anciens équivalents HTTP pour que les choses fonctionnent. Inutile de dire qu'il s'agit d'une décision majeure où le référencement n'est qu'un des nombreux facteurs à prendre en compte.
Référencement sur la page
Le référencement sur la page fait référence au processus d'optimisation des pages individuelles pour une plus grande visibilité de la recherche. Cela implique principalement d'augmenter la qualité du contenu et de s'assurer que les mots-clés sont présents dans les éléments de chaque page où ils comptent.
Le référencement sur la page peut être une tâche énorme pour les grands sites de commerce électronique, mais cela doit être fait à un moment donné. Voici les éléments de chaque page que vous devriez chercher à peaufiner :
Slugs d'URL canoniques
L'une des choses que les moteurs de recherche examinent lorsqu'ils évaluent la pertinence d'une page par rapport aux mots-clés est son slug d'URL. Les moteurs de recherche préfèrent les URL contenant de vrais mots aux caractères indéchiffrables. Par exemple, une URL comme [www.clothes.com/112-656-11455] pourrait techniquement fonctionner, mais les moteurs de recherche auraient une meilleure idée de ce dont il s'agit si elle ressemblait davantage à [www.yourshop.com/pants]. Les URL qui utilisent de vrais mots au lieu de combinaisons alphanumériques sont appelées "URL canoniques". Ceux-ci ne doivent pas être confondus avec les liens rel=canonical mentionnés précédemment, qui n'ont rien à voir avec les slugs d'URL.
La plupart des plateformes d'achat en ligne utilisent facilement les URL canoniques. Cependant, certains pourraient ne pas le faire et c'est quelque chose que vous devez surveiller. Votre développeur Web pourra vous aider à configurer des slugs d'URL canoniques si ce n'est pas ce que votre CMS utilise par défaut.
Guide SEO – Méta Directives
Outre le fichier robots.txt, il existe un autre moyen de restreindre l'indexation de vos pages. C'est en utilisant ce que l'on appelle les balises meta directives. En termes simples, ce sont des instructions HTML dans la partie <head> du code source de chaque page qui indiquent aux robots ce qu'ils peuvent et ne peuvent pas faire avec une page. Les plus courants sont :
- Noindex – Cette balise indique aux moteurs de recherche de ne pas indexer une page. Semblable aux effets d'un refus de robots.txt, une page ne sera pas répertoriée dans les SERP si elle a cette balise. La différence, cependant, est le fait qu'un bot responsable n'explorera pas une page restreinte par robots.txt alors qu'une page sans index sera toujours explorée - elle ne sera tout simplement pas indexée. À cet égard, les araignées de recherche peuvent toujours passer par les liens d'une page non indexée et l'équité des liens peut toujours passer par ces liens.
La balise noindex est mieux utilisée pour exclure les pages de balises de blog, les pages de catégories non optimisées et les pages de paiement.
- Noarchive – Cette balise meta permet aux bots d'indexer votre page mais pas d'en conserver une version en cache dans leur espace de stockage.
- Noodp - Cette balise indique aux robots de ne pas répertorier un site dans l'Open Directory Project (DMOZ)
- Nofollow - Cette balise indique aux moteurs de recherche que la page peut être indexée mais que les liens qu'elle contient ne doivent pas être suivis.
Comme indiqué précédemment, il est préférable d'être judicieux lorsque vous décidez quelles pages vous devez autoriser Google à indexer. Voici quelques conseils rapides sur la façon de gérer l'indexation pour les types de pages courants :
- Page d'accueil – Autoriser l'indexation.
- Pages de catégories de produits - Autoriser l'indexation. Autant que possible, ajoutez de l'ampleur à ces pages en améliorant la copie de la page. Plus d'informations à ce sujet dans la section "Catégorie unique et copie du produit".
- Pages de produits - Autorisez l'indexation uniquement si vos pages ont une copie unique écrite pour elles. Si vous avez récupéré les descriptions de produits dans un catalogue ou sur le site d'un fabricant, interdisez l'indexation avec la balise méta "noindex, follow".
- Pages d'articles de blog – Si votre boutique en ligne a un blog, autorisez par tous les moyens les moteurs de recherche à indexer vos articles.
- Pages de catégorie de blog – Autorisez l'indexation uniquement si vous avez ajouté un contenu unique. Sinon, utilisez la balise "noindex,follow".
- Pages de balises de blog – Utilisez la balise « noindex,follow ».
- Archives des auteurs de blog – Utilisez la balise « noindex,follow ».
- Blog Date Archives – Utilisez la balise « noindex,follow ».
Les plates-formes de commerce électronique populaires telles que Shopify, Magento et WordPress ont toutes des fonctionnalités intégrées ou des plugins qui permettent aux administrateurs Web de gérer facilement les méta-directives dans une page.
Dans les cas où vous vous demandez pourquoi une page particulière n'est pas indexée ou pourquoi une page soi-disant restreinte apparaît dans les SERP, vous pouvez vérifier manuellement leurs codes sources. Alternativement, vous pouvez auditer la liste des méta-directives de votre site entier en exécutant une analyse Screaming Frog.

Après avoir exécuté un crawl, vérifiez simplement la colonne Meta Robots. Vous devriez être en mesure de voir quelles balises de directive méta chaque page contient sur votre site. Comme pour tout rapport Screaming Frog, vous pouvez l'exporter vers une feuille Excel pour une gestion plus facile des données.
Balises de titre
La balise de titre reste le facteur de classement le plus important sur la page pour la plupart des moteurs de recherche. Il s'agit du texte qui titre le résultat de la recherche et sa fonction principale est de dire aux chercheurs humains et aux robots de quoi parle une page en 60 caractères ou moins.

En raison de la brièveté et de l'importance des balises de titre, il est crucial pour toute campagne de référencement pour le commerce électronique de les faire correctement. Les balises de titre bien écrites doivent avoir les qualités suivantes pour maximiser la capacité d'une page à se classer :
- 60 caractères ou moins, espaces compris
- Donnez simplement l'essentiel de ce que la page contient
- Doit mentionner le mot-clé principal de la page dès le début
- Doit répondre à l'intention d'achat en mentionnant les mots d'action d'achat
- Facultativement, mentionnez la marque du site
- Utilise des séparateurs tels que "-" et "|" pour délimiter le noyau de la balise de titre et le nom de la marque.
Voici un exemple d'une bonne balise de titre :
Acheter des jeans en ligne | Men'sWear.com
Nous voyons que le mot d'achat "Acheter" est présent mais le type de produit "Jeans en denim" est encore mentionné au début. Le mot « en ligne » est également mentionné pour indiquer que l'achat peut être effectué sur Internet et la page n'indiquera pas seulement au chercheur où il ou elle peut acheter physiquement. La marque de la boutique en ligne est également mentionnée, mais l'ensemble du bloc de texte respecte toujours la longueur recommandée de 60 caractères.
Guide SEO – Méta descriptions
Les méta descriptions sont les blocs de texte que vous pouvez voir sous les balises de titre dans les résultats de recherche. Contrairement aux balises de titre, ce ne sont pas des facteurs de classement directs. En fait, vous pouvez vous en tirer sans les écrire et Google ne ferait que récupérer le texte du contenu de la page qu'il juge le plus pertinent pour une requête.

Cela ne signifie pas pour autant que vous ne devriez pas vous soucier des méta-descriptions. Lorsqu'ils sont rédigés d'une manière bien formulée et convaincante, ceux-ci peuvent déterminer si un utilisateur clique sur votre annonce ou se rend sur la page d'un concurrent. La méta description n'est peut-être pas un facteur de classement, mais le taux de clics (CTR) d'une page l'est certainement. Le CTR est un signal d'engagement important que Google utilise pour voir quels résultats de recherche satisfont le mieux l'intention de leurs utilisateurs.
Les bonnes méta descriptions ont les qualités suivantes :
- Environ 160 caractères (espaces compris)
- Fournit aux utilisateurs une idée de ce à quoi s'attendre de la page
- Mentionne au moins une fois le mot-clé principal de la page
- Fait un cas court mais convaincant sur la raison pour laquelle l'utilisateur devrait cliquer sur la liste
Voici un bel échantillon d'une boutique en ligne qui se classe numéro 1 sur Google pour le mot-clé "encres d'imprimante bon marché".

Notice how the meta description makes it clear from the start that they sell the products mentioned in the query with the phrase “Shop for ink cartridges, printer cartridges and toner cartridges.” This part also mentions the main keywords that the site targets. Meanwhile, the phrase “Find cheap printer ink for all brands at Carrotink.com. Free Shipping!” conveys additional details such as the brands covered and the value-add offer that promises free shipping. In much less than 160 characters, the listing tells shoppers looking for affordable inks that CarrotInk.com is a good destination for them.
SEO Guide – Header Text
Header text is the general term for text on a webpage that's formatted with the H1, H2, and H3 elements. This text is used to make headline and sub-headline text stand out, giving it more visual weight to users and contextual weight to search engines.
In online stores, it's important to format main page headlines with the H1 tag. Typically, the product or category name is automatically made the main header text like we see in the example blow. Sub-headings that indicate the page's various sections can then be marked up as H2, H3 and so on.

If your online store publishes articles and blog posts, remember to format main headlines in H1 and sub-headings in H2 and H3 as well. Effective header text is brief, direct and indicative of the context that the text under it conveys. It preferably mentions the main keyword in the text it headlines at least once.
If you want to check whether all your pages have proper header text, you can do an audit with Screaming Frog. Simply run a crawl and filter the results to just HTML using the Filter drop-down on the top left section of the app window. You can find column headings that say “H1-1”and “H2-1” when you scroll right. The text there are the headings in the page.

You can export these to Excel for easy data management and reference when applying changes.
SEO Guide – Image Alt Text
Google and other search engines have gotten dramatically smarter these past two decades. They're now so much better at understanding language, reading code and interpreting user behavior as engagement signals. What they haven't refined to a science just yet is their ability to understand what a picture shows and what it means in relation to a page's content.
Since bots read code and don't necessarily “see” pages the way human eyes do, it's our responsibility to help them understand visual content. With images, the most powerful relevance signal is the alt text (shorthand for alternate text). This is a string of text included in the image's code that provides a short description of what's being shown.
Adding accurate, descriptive and keyword-laced anchor text is very important to online stores since online shoppers tend to buy from sites with richer visual content. Adding alt text helps enhance your pages' relevance to their target keywords and it gets you incremental traffic from Google Image Search.
To check if your site uses proper image alt text, we can use trusty Screaming Frog once more. Do a crawl of your site from the home page and wait for the session to finish. Go to the main menu and click Bulk Export>Images>All Alt Tex t. Name the file and save it. Open the file in Excel and you should see something like this:

Column B (Source) tells us which page the image was found on. Column C (Destination) tells us the web address of the image file. Column D (Anchor) is where we'll find the anchor text if something has already been written. If you see a blank cell, it means no anchor text is in place and you'll need to write it at some point.
Good image alt texts have the following qualities:
- About 50 characters long at most
- Describes what's depicted in the image directly in one phrase
- Mentions the image's main keyword at least once
Different CMS platforms have different means of editing image alt texts. In a lot of cases, a spreadsheet being fed into the CMS for bulk uploads can contain image alt text information.
SEO Guide – Unique Category and Product Copy
SEO has everything to do with the age-old Internet adage “content is king” and that applies even to ecommerce websites. Analyses have continually shown that Google tends to favor pages and sites with more breadth and depth in their content. While most online store owners would cringe at the idea of turning their site into “some kind of library,” smarter online retailers know that content can co-exist with their desired web design schemes to produce positive results.
One of the fundamental flaws that a lot of ecommerce sites face from an on-page SEO perspective is the proliferation of thin content on unoptimized category pages and product pages with boilerplate content. Regular category pages have little text and no fundamental reason for existence other than to link to subcategory pages or product pages. Product pages with boilerplate content, on the other hand, don't deliver unique value to searchers. If your online store is guilty of both shortcomings, search engines won't look at it with much favor, allowing other pages with better content to outrank yours.
Category pages are of particularly high importance due to the fact that they usually represent non-branded, short and medium-length keywords. These keywords represent query intents that correspond with the top and middle parts of sales funnels. In short, these pages are the ones that users look for when they're in the early stages of forming their buying decisions.
Category pages can be optimized for SEO by adding one or both of the following:
- A short text blurb that states what the category is about and issues a call to action. This is usually a 2-3 sentence paragraph situated between the H1 text and the selection of subcategory product links.

- Longer copy that further discusses the category and the items listed under it. This can be one or more paragraphs and is positioned near the bottom of the page's body, under the list of subcategories or products in the page. This text isn't meant for human readers as much as it is for bots to consume and understand text.

For both text block types, the goal is to increase the amount of text and provide greater relevance between the page and its target keyword. The text blocks also provide opportunities for internal linking as the text can be used as anchors for links to other pages.
Les pages de produits, en revanche, représentent des intentions de requête situées près du bas de l'entonnoir de vente. Les pages de produits correspondent aux intentions des utilisateurs qui ont déjà une bonne idée de ce qu'ils veulent acheter et qui recherchent simplement le meilleur fournisseur pour le leur vendre. Les mots-clés représentés par les pages de produits ont généralement un volume de recherche plus faible mais un taux de conversion plus élevé.
L'optimisation de la copie sur les pages de produits n'est généralement pas trop difficile car cela demande beaucoup de travail. Rechercher des centaines, voire des milliers de détails sur les produits, puis les réécrire pour les rendre uniques peut consommer une tonne d'heures de travail. En règle générale, les propriétaires de magasins en ligne avertis en matière de référencement le font de manière sélective uniquement pour leurs gammes de produits prioritaires. Les pages de produits qui ne sont pas remplies avec un contenu unique sont généralement restreintes à l'aide de la balise noindex pour concentrer l'équité des liens et le budget d'exploration sur les pages qui ont été optimisées avec une copie unique.
Lorsque vous rédigez une copie unique pour les pages de produits, concentrez-vous sur la rédaction des éléments suivants à votre manière :
- La déclaration des avantages - La partie de la copie qui répertorie 3 ou 4 puces indiquant comment le produit résout un problème ou améliore la vie du client cible.
- Cas d'utilisation - Une section dans la copie où vous mentionnez les utilisations et applications possibles du produit.
- Section pratique – Une partie de la copie où vous fournissez des instructions sur la façon dont le produit peut être utilisé ou installé.
- Avis clients – La partie de la copie où vous autorisez les acheteurs à écrire des commentaires sur un produit. Assurez-vous simplement de n'autoriser que les clients vérifiés à publier. Modérer le contenu pour la qualité et la lisibilité peut également être utile.
Si vous voulez voir un bon exemple de copie de page produit riche, unique et utile, en voici une .
Le contenu des catégories et des pages de produits peut également aider vos pages à atteindre la position zéro sur Google. Il s'agit de la boîte de réponse instantanée qui s'affiche au-dessus de tout le reste dans certaines requêtes. Si le contenu que vous avez écrit répond à une question de manière claire et directe, utilise des balises d'en-tête appropriées et utilise des balises HTML appropriées pour les listes à puces et numérotées, vous constaterez peut-être que votre contenu figure en bonne place dans les SERP.
Pagination
Les pages de catégories de produits contiennent parfois tellement d'articles qu'il serait horrible de les afficher tous sur une seule page. Pour résoudre ce problème de conception, les concepteurs de sites Web utilisent du contenu paginé. Il s'agit d'une méthode qui permet à une page de catégorie d'afficher une partie des listes en dessous tout en gardant le reste caché. Si un utilisateur veut voir le reste, il peut cliquer sur les numéros de page qui l'amènent à une page identique où d'autres éléments de la liste sont affichés.

Bien que cela fonctionne très bien pour la conception et la convivialité, cela peut devenir un problème de référencement si vous ne faites pas attention. Les moteurs de recherche ne sont pas doués pour comprendre qu'une série de pages peut parfois appartenir à un ensemble plus vaste. En tant que tels, ils ont tendance à explorer et à indexer les pages dans une série paginée et à les considérer comme des doublons en raison des balises de titre, de la méta description et de la copie de page de catégorie identiques affichées.
Pour aider les moteurs de recherche à identifier une série paginée dans vos pages de catégorie, demandez simplement à votre développeur Web d'implémenter l'élément rel=”prev” et rel=”next” dans le contenu paginé. Ces éléments indiquent aux moteurs de recherche que les pages appartiennent à une série et que seule la première doit être indexée. Vous pouvez en savoir plus sur ces éléments HTML ici .
GUIDE SEO - Schéma d'examen agrégé
Vous avez probablement déjà vu des résultats de recherche de produits et services avec des étoiles d'avis apposées sur les listes. Ces étoiles font plus que simplement occuper de l'espace sur les SERP et attirer l'attention visuelle - elles encouragent également un meilleur comportement de clic de la part des chercheurs. Pour les magasins en ligne, faire apparaître des étoiles de révision dans les listes de pages de produits peut être très pratique. Ces extraits enrichis peuvent être le facteur décisif pour déterminer si un utilisateur clique sur votre fiche ou sur celle de votre concurrent.

Heureusement, la mise en place d'étoiles d'examen est relativement facile. Tout ce que vous avez à faire est d'ajouter cette chaîne de code à vos pages de produits et vous devriez être prêt :
<script type="application/ld+json">
{ "@context": "http://schema.org",
"@type": "Produit",
"nom": "##PRODUIT###",
"classement global":
{“@type” : "Classement global",
"ratingValue": "##RATING##",
« reviewCount » : « ##REVIEWS## »
}
}
</script>
Vous devrez remplir la partie ##PRODUCT### avec le nom du produit, la partie ##RATING## avec les notes agrégées des avis du produit et la partie ##REVIEWS## avec le nombre d'avis. Si vous ne vous sentez pas à l'aise avec la manipulation de code, confiez cette tâche à un développeur Web pour faire avancer les choses dans la bonne direction.
Bien sûr, l'ajout de ce balisage ne garantit pas que Google affichera réellement les étoiles de la critique. Le géant de la recherche a un ensemble d'algorithmes à suivre. Pour augmenter vos chances d'obtenir des étoiles d'évaluation globales, gardez à l'esprit ce qui suit :
- Ajoutez le code de balisage uniquement à des pages de produits spécifiques. L'ajouter aux pages d'accueil et de catégorie du site de commerce électronique n'aura aucun effet.
- Encouragez les avis de vrais clients et évitez de fabriquer vos propres notes d'avis.
- Essayez de promouvoir un équilibre sain entre les avis provenant du site et ceux provenant de sources externes.
- Si vous prévoyez que des personnes attribuent des notes à vos pages à votre demande, ne le faites pas pour tous les produits en même temps. Le fait que chaque page obtienne soudainement des notes ne semble pas naturel et peut être mal perçu par Google.
Notez que certaines plates-formes CMS sont meilleures que d'autres avec des balisages Schema. WordPress, par exemple, a des balisages Schema intégrés si vous utilisez un thème basé sur Genesis.
Bonus : stratégie de création de liens
Bien que cet article concerne le référencement sur site, il est inévitable que les propriétaires de sites de commerce électronique envisagent éventuellement de créer des liens s'ils veulent dominer leur créneau sur le marché de la recherche. Income Diary a publié des articles sur la façon de créer des liens de la bonne manière dans le passé, nous n'entrerons donc pas dans les détails à ce sujet. Nous discuterons cependant de l'endroit où pointer ces backlinks.
Généralement, les sites Web suivent des architectures d'information en forme de pyramide. Imaginez la page d'accueil comme la pointe de la pyramide tandis que ses principales catégories et sous-catégories constituent les quelques couches suivantes. A la base de la pyramide se trouvent les pages produits. Ce sont les types de pages les plus nombreux mais ils se situent au bas de la hiérarchie.

Maintenant, imaginez la pyramide comme celle qui a un système interne de distribution d'eau. Dans ce cas, l'eau est l'équité du lien. La majeure partie provient de la pointe (la page d'accueil), car c'est là que pointent la plupart des liens entrants. L'équité descend vers les pages de catégories liées à la page d'accueil, puis descend et se répartit sur les pages de produits.
Cela dit, la page d'accueil est la meilleure page vers laquelle pointer les liens entrants si votre objectif est d'augmenter le pouvoir de classement de toutes vos pages. Cela aide la page d'accueil à mieux se classer pour les mots-clés courts qu'elle représente tout en fournissant des améliorations supplémentaires aux pages de catégories et de produits.
S'il vous arrive d'avoir une gamme de produits que vous privilégiez par rapport aux autres, il vous serait utile de créer des liens vers leurs pages de catégories respectives. Cela aide non seulement la page de catégorie à mieux fonctionner dans les SERP, mais également à cascader une équité de lien plus puissante vers vos pages de produits.
En fin de compte, un bon référencement pour les magasins en ligne consiste à promouvoir un degré plus élevé de crawlabilité et de pertinence pour vos pages. L'ajout de ces tâches d'optimisation à la liste de tâches de maintenance de votre site peut sembler une tâche majeure, mais les récompenses en valent la peine.
Bio de l'auteur : Itamar Gero est sur le net depuis l'époque où il était encore en noir et blanc. Né et élevé en Israël, il vit maintenant aux Philippines. Il est le fondateur de SEOReseller.com et a récemment lancé Siteoscope.com .
Postes en vedette:
=> Rédacteur Ray Edwards | Podcast : comment écrire une copie qui vend
=> GUIDE SEO : 10 étapes de publication d'articles de blog SEO que la plupart des blogueurs oublient