
あなたのオンラインストアのための究極のオンサイトSEOガイド
公開: 2017-03-14eコマース検索エンジン最適化–究極のオンサイトSEOガイド…

ブロガーおよびストアオーナーとして、私たちはウェブサイトを検索エンジンとユーザーの両方にアピールしたいと考えています。
検索エンジンは、私たち人間とはまったく異なる方法でWebサイトを「見ます」。 この投稿でカバーされている重要なオンサイトSEOを見逃した場合、Webサイトのデザイン、派手なグラフィック、よく書かれたブログ投稿は何の価値もありません。
SEOは死んでいません。
最新のSEOは、検索エンジンをだますことではありません。検索エンジンと連携して、製品やコンテンツを可能な限り最良の方法で提示することです。
この投稿では、SEOエキスパート-ItamarGeroが正確な方法を示しています…
店主とブロガーのための究極のオンサイトSEOガイド
eコマースは巨大なビジネスです。 米国国勢調査局によると、2016年の米国だけでのeコマース売上高は3,949億ドルに達しました。eコマース売上高の増加傾向とオフライン小売への影響は、世界中で2020年代まで続くと予想されます。
当然のことながら、オンラインストアの所有者は、eコマースのパイのこれまで以上に大きな部分を手に入れる立場を求めて冗談を言っています。 そのために、SEOはほとんどのeコマースマーケティング戦略の最優先事項でした。 検索エンジンは、他のチャネルからの訪問者よりも有料の顧客に変換するのが簡単な、最も適格で意欲的なトラフィックを促進します。 そのため、Webサイトは、自社の製品やサービスに関連するキーワードで互いに勝つために、舞台裏で絶え間ない「戦争」を繰り広げています。
そして、多くの競合他社がいることは困難ですが、多くのeコマースサイトがSEOを正しく行っていないという事実に安心することができます。 SEOのベストプラクティスをしっかりと把握し、多くのハードワークを行うことで、手間をかけずに検索の可視性を高めることができます。
あなたのオンラインストアへのSEOガイド–頭痛を取り除きます!

このSEOガイドに関する特記事項:
このSEOガイドとチュートリアルは、これまでに作成した中で最も詳細なものの1つです。 [7000以上の単語と20以上の画像]
圧倒されたり、SEOに混乱したりするのは簡単ですが、実際には、最初に表示される方がはるかに簡単です。
検索エンジン最適化を正しく行うことの見返りは巨大です!
さらに、このガイドは特にeコマースSEOに焦点を当てていますが、ここで詳しく説明する内容の多くは、ブログや会社のWebサイトにも同様に当てはまります。
必要な2つのSEOリソース:
=> Google検索コンソール
=>スクリーミングフロッグSEOスパイダー
eコマースSEOとは何ですか?
簡単に言えば、eコマースSEOは、検索エンジンの可視性を高めるためにオンラインストアを最適化するプロセスです。 これには、次の4つの主要な側面があります。
- キーワード研究
- オンサイトSEO
- リンクビルディング
- 使用信号の最適化
この投稿では、4つの分野の中で最も基本的で間違いなく最も重要なオンサイトSEOに取り組みます。 私たちの経験では、何千もの代理店と協力して、全体的なオーガニックトラフィックの成長に最大の影響を与えたのは、処理するeコマースサイト内で行った最適化によるものです。
リンク構築やその他のオフページSEO活動は重要ですが、オンサイトSEOは毎回成功のトーンを設定します。
オンサイトSEOの復活
オンサイトSEOは、ウェブサイト内で行われるすべてのSEO活動を説明するために使用される総称です。 テクニカルSEOとオンページSEOの2つのセグメントに分けることができます。 テクニカルSEOは主に、サイトが稼働し続け、検索ボットのクロールに利用できるようにすることを扱います。 一方、ページ上のSEOは、検索エンジンがターゲットとするキーワードに対するサイトのコンテキスト関連性を理解できるようにすることを目的としています。
私は今日、オンサイトSEOに焦点を当てています。これは、過去3年ほどの間に否定できない復活があったためです。 ご覧のとおり、SEOコミュニティは、2000年代後半から2011年頃にかけて、すべての人がインバウンドリンクの取得に夢中になっている段階を経ました。 当時、リンクはグーグルのランキングの最も強力な決定要因でした。 残忍なランキングの戦いに閉じ込められたeコマースサイトはこの動きの中心であり、競争は最終的に 倫理的であろうとなかろうと、誰が最も多くのリンクを取得できるかという問題。
最終的に、Googleはパンダとペンギンのアップデートを導入し、リンクとコンテンツのスパムを急増させた多くのサイトを罰しました。 ランキングを押し上げた質の高いリンクを入手するのが難しくなり、オンサイトのSEO信号の影響がランキング全体でより顕著になりました。 SEOコミュニティはすぐに、大量のリンクの取得よりも技術的およびページ上の最適化に重点を置いた成功したeコマースSEOキャンペーンを見始めました。
この投稿では、オンサイトのSEOルネッサンスを活用するためにサイトで何ができるかを示します。
テクニカルSEO
前述のように、技術的なSEOは主に、サイトの稼働時間が長く、読み込みが速く、ユーザーに安全なブラウジングを提供し、ページ内のボットとユーザーのナビゲーションを容易にすることを目的としています。 高レベルの技術的健全性を確保するために常に監視する必要があるもののリストは次のとおりです。
Robots.txtファイル
robots.txtファイルは、検索ボットがサイトにアクセスしたときにアクセスする非常に小さなドキュメントです。 このドキュメントでは、アクセスできるページ、アクセスできるボット、立ち入り禁止のページについて説明しています。 robots.txtがウェブサイト内の特定のページまたはディレクトリパスへのアクセスを許可しない場合、責任のあるサイトのボットは指示に従い、そのページにまったくアクセスしません。 つまり、許可されていないページは検索結果に表示されません。 それらに流れるリンクエクイティはすべて無効になり、これらのページもリンクエクイティを渡すことができなくなります。
robots.txtファイルを確認するときは、一般公開を目的としたすべてのページが許可されていないパラメータに該当しないことを確認してください。 同様に、ターゲットオーディエンスがインデックス作成を禁止されている場合、意図を果たさないページを確認する必要があります。
検索エンジンによってより多くのページがインデックスに登録されることは良いことのように聞こえるかもしれませんが、実際にはそうではありません。 Googleやその他のWebポータルは、SERPに表示されるリストの品質を常に向上させようとしています。 (検索エンジンの結果ページ)
したがって、彼らは、ウェブマスターがインデックス作成のために提出するページで賢明であることを期待し、遵守する人々に報酬を与えます。
一般に、検索エンジンのクエリは次の3つの分類のいずれかに分類されます。
- ナビゲーション
- トランザクション
- 情報
ページがこれらのいずれかの背後にある意図を満たさない場合は、robots.txtを使用してボットがページにアクセスできないようにすることを検討してください。 そうすることで、クロール予算をより有効に活用し、サイトの内部リンクの公平性をより重要なページに流すことができます。 eコマースサイトで、通常アクセスを禁止したいURLのタイプは次のとおりです。
- チェックアウトページ–これらは、買い物客が購入を選択して確認するために使用する一連のページです。 これらのページはセッションに固有であるため、インターネット上の他の誰にも興味がありません。
- 動的ページ–これらのページは、内部検索やページフィルタリングの組み合わせなどの固有のユーザーリクエストによって作成されます。 チェックアウトページと同様に、これらのページは、リクエストを行った1人の特定のユーザーに対して生成されます。 したがって、それらはWeb上のほとんどの人には興味がなく、検索エンジンがそれらをインデックスに登録するための推進力を非常に弱くしています。 さらに、これらのページは最終的に期限切れになり、検索エンジンによって再クロールされると404NotFound応答が送信されます。 これは、オンラインストアの検索の可視性に悪影響を与える可能性のある、サイトの状態が悪いことの兆候と見なすことができます。
動的ページは、「?」という文字の存在によって簡単に識別できます。 URLに「=」が含まれています。 robots.txtファイルに次のような行を追加することで、インデックスが作成されないようにすることができます。disallow:*?
- ステージングページ–これらは現在開発中であり、一般公開には適さないページです。 ウェブページをステージングするためにサイトのディレクトリにパスを設定し、robots.txtファイルがそのディレクトリをブロックしていることを確認してください。
- バックエンドページ–これらのページはサイト管理者専用です。 当然のことながら、一般の人がページにアクセスしないようにする必要があります。検索結果でそれらを見つけることははるかに少ないでしょう。 管理者ログインページから内部サイトコントロールページまで、すべてがrobots.txt制限の下に置かれ、不正なエントリを防ぐ必要があります。
ページのインデックス作成を制限する方法はrobots.txtファイルだけではないことに注意してください。 特に、noindexメタディレクティブタグもこの目的に使用できます。 インデックス解除の状況の性質によっては、一方が他方よりも適切な場合があります。
XMLサイトマップ
XMLサイトマップは、検索ボットが有用な情報を取得するために読み取るもう1つのドキュメントです。 このファイルには、Googleや他のスパイダーにクロールさせたいすべてのページがリストされています。 優れたサイトマップには、ボットに情報アーキテクチャ、各ページが変更される頻度、およびドメインのファイルパス内の画像などのアセットの所在を示す情報が含まれています。
XMLサイトマップはどのWebサイトでも必須ではありませんが、一般的なeコマースサイトのページ数が多いため、オンラインストアにとって非常に重要です。 サイトマップを配置してGoogle検索コンソールなどのツールに送信すると、検索エンジンはサイトのURL階層の奥深くにあるページを見つけてインデックスを作成する傾向があります。
Web開発者は、eコマースサイトのXMLサイトマップを設定できる必要があります。 多くの場合、eコマースサイトは、開発サイクルが終了するまでにすでにそれを持っています。 これは、[www.yoursite.com/sitemap.xml]にアクセスして確認できます。 このようなものが表示された場合は、XMLサイトマップがすでに稼働しています。

XMLサイトマップがあるからといって、そこにリストされているすべてのURLがインデックスに登録されるとは限りません。
サイトマップをGoogle検索コンソールに送信すると、検索の巨人のボットがサイトマップを見つけて読み取ることができます。 これを行うには、検索コンソールアカウントにログインして、管理するプロパティを見つけます。 [クロール]>[サイトマップ]に移動し、右上の[新しいサイトマップを追加/テスト]ボタンをクリックします。 XMLサイトマップのURLスラッグを入力し、[送信]をクリックするだけです。
2〜4日でサイトマップにデータが表示されるはずです。 これはどのように見えるかです:
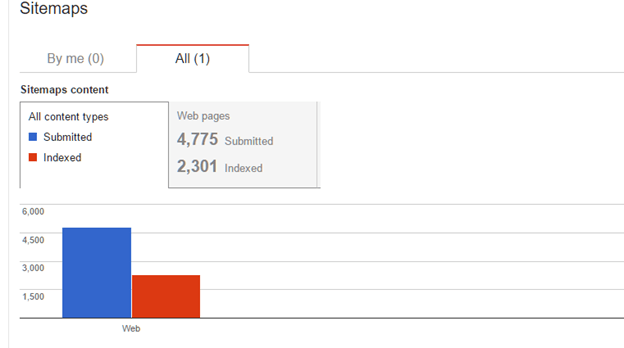
レポートには、サイトマップで送信(リスト)されたページの数と、インデックスに登録されたGoogleの数が示されていることに注意してください。 多くの場合、eコマースサイトは、Googleによってインデックス付けされたサイトマップで送信するすべてのページを取得するわけではありません。 次のようないくつかの理由により、ページがインデックスに登録されない場合があります。
- URLが無効–ページが意図的に削除されているか、技術的な問題が発生している場合、4xxまたは5xxエラーが発生する可能性があります。 URLがサイトマップにリストされている場合、Googleは正しく機能していないURLからページをインデックスに登録しません。 同様に、サイトマップにリストされている1回限りのページが長期間ダウンすると、Googleのインデックスから削除される可能性があります。
- URLがリダイレクトされる– URLがリダイレクトされ、301または302応答コードが生成される場合、サイトマップにそのURLを含める意味はありません。 リダイレクトのターゲットページがまだ表示されていない場合は、代わりに一覧表示する必要があります。 リダイレクトURLがサイトマップにリストされている場合、Googleがそれを単に無視し、インデックスに登録されていないものとして報告する可能性が高くなります。
- URLがブロックされています– robots.txtセクションで説明されているように、eコマースサイトのすべてのページにインデックスを付ける必要はありません。 ウェブページがrobots.txtまたはnoindexメタタグによってブロックされている場合、XMLサイトマップにリストする意味はありません。 Search Consoleは、インデックスに登録されていないことを要求したため、インデックスに登録されていないものとしてカウントします。
チェックアウトページ、ブログタグページ、およびコンテンツが重複しているその他の製品ページは、XMLサイトマップにリストする必要のないページの例です。
- URLには正規リンクがあります– rel = canonical HTMLタグは、オンラインストアでよく使用され、いくつかの非常に類似したページからインデックスを作成するページを検索エンジンに通知します。 これは、製品に非常に小さな識別属性を持つ複数のSKUがある場合によく発生します。 GoogleにSERPに表示するページを選択させる代わりに、ウェブマスターは検索エンジンに、どのページが注目されたい「本物の」ページであるかを伝える機能を獲得しました。
eコマースサイトにrel=canonical要素を持つ製品ページがある場合、それらをサイトマップにリストする必要はありません。 グーグルはとにかくそれらを無視し、彼らが指しているものを尊重するでしょう。
- ページに薄いコンテンツがある– Googleは、薄いコンテンツを付加価値がほとんどまたはまったくないページとして定義しています。 例としては、テキストコンテンツがほとんどまたはまったくないページや、テキストはあるがサイト内またはWebの他の場所から他のページを複製しているページがあります。 グーグルがページが薄いとみなすとき、それは検索結果でそれを嫌うか、それを完全に無視します。
メーカーサイトから持ち上げられた定型文のコンテンツを掲載している製品ページや、サイトの他のページがある場合は、より豊富でユニークな説明を書く時間と労力が得られるまで、それらのインデックス作成をブロックするのが通常は賢明です。 また、これらのページがインデックスに登録される可能性が低いという理由だけで、これらのページをXMLサイトマップにリストすることは避けてください。
- ページレベルのペナルティがあります–まれに、検索エンジンが品質ガイドラインに違反するサイトに対して手動またはアルゴリズムによるアクションを実行する場合があります。 ページがスパムである場合、またはハッキングされてマルウェアが注入されている場合は、インデックスから削除される可能性があります。 当然、このようなページはサイトマップから外したいと思うでしょう。
- URLは冗長です–ご想像のとおり、XMLサイトマップ内の重複するURLは2回表示されません。 2つ目は無視され、インデックスから除外される可能性があります。 この問題を解決するには、ブラウザでサイトマップを開き、Excelで開くことができるXMLドキュメントとして保存します。 そこから、[データ]タブに移動します。 サイトマップでURLが含まれている列を強調表示し、[重複の削除]をクリックします。
- 制限付きページ–パスワードで保護されているページ、または特定のIPへのアクセスのみを許可しているページは、検索エンジンによってクロールされないため、インデックスに登録されません。
サイトマップにリストする不適切なページが少ないほど、インデックス作成に対する提出の比率が高くなります。 これにより、検索エンジンはドメイン内のどのページが最も重要度が高いかを理解し、検索エンジンが表すキーワードのパフォーマンスを向上させることができます。
クロールエラー
オンラインストアでは、多くの要因に応じて商品が定期的に追加および削除されます。 インデックスに登録された商品やカテゴリのページが削除されても、検索エンジンがそれらを自動的に忘れてしまうとは限りません。 ボットは、これらのURLが修正されるか、慢性的に利用できないためにインデックスから削除されるまで、数か月間これらのURLのクロールを試み続けます。
技術用語では、クロールエラーは、ボットがHTTPエラーコードを返すために正常にアクセスできないページです。 これらのコードの中で、404が最も一般的ですが、4xx範囲の他のコードが適用されます。 検索エンジンは、クロールエラーがどのWebサイトでも通常発生することを認識していますが、クロールエラーが多すぎると、検索の可視性が低下する可能性があります。 クロールエラーは、サイトのルーズエンドのように見える傾向があり、ページ間の内部リンクの公平性の適切な流れを妨げる可能性があります。
クロールエラーは通常、次の場合に発生します。
- 意図的に削除されたページ
- 誤って削除されたページ
- 期限切れの動的ページ
- サーバーの問題
eコマースサイトで発生しているクロールエラーの数と影響を受けるURLを確認するには、Google検索コンソールにアクセスして関連するプロパティにアクセスします。 左側のサイドバーメニューで、 [クロール]>[クロールエラー]に移動します。 次のようなレポートが表示されます。
![左側のサイドバーメニューで、[クロール]>[クロールエラー]に移動します](/uploads/article/97/asMbhIZASx8BDjmy.jpg)
クロールエラーレポートで見つけたページの種類に応じて、次のようないくつかの異なる方法でそれらに取り組むことができます。
- 誤って削除されたページを修正する– URLが意図せずに削除されたページに属している場合、同じWebアドレスでページを再公開するだけで問題が修正されます。
- 動的ページのインデックス作成をブロックする–前述のように、robots.txtを使用してボットアクセスをブロックすることで、期限切れになってクロールエラーになる動的ページを防ぐことができます。 そもそも動的ページのインデックスが作成されていない場合、検索エンジンによってクロールエラーは検出されません。
- 301古いページを新しいページにリダイレクトする–ページが意図的に削除され、新しいページが公開されて置き換えられた場合は、301リダイレクトを使用して、検索ボットと人間のユーザーをその場所にあるページに誘導します。 これにより、クロールエラーの発生が防止されるだけでなく、削除されたページがかつて保持していたリンクエクイティも渡されます。 ただし、すべてのクロールエラーの修正が301リダイレクトであると想定しないでください。 リダイレクトが多すぎると、サイトの速度に悪影響を与える可能性があります。
- サーバーの問題に対処する–サーバーの問題がダウンタイムの根本的な原因である場合は、Web開発者およびホスティングサービスプロバイダーと協力することが最善の手段です。
- それらを無視する–ページが意図的に削除されたが、それらがそれほど重要ではなく、置換ページが計画されていない場合、検索エンジンが数か月以内にそれらをインデックスからフラッシュすることを許可できます。
クロールエラーをできるだけ少なくすることは、責任あるオンラインストア管理の特徴です。 クロールエラーレポートを毎月チェックすることで、最新情報を入手できます。
壊れたリンクへのSEOガイド
リンク切れにより、検索スパイダーがページ間を移動できなくなります。 また、訪問者をサイトの行き止まりに導くため、ユーザーエクスペリエンスにも悪影響を及ぼします。 ほとんどのeコマースサイトのページの量と複雑な情報アーキテクチャのために、壊れたリンクがあちこちで発生するのが一般的です。
リンク切れは通常、リンクのターゲットURLのエラー、または404Notfoundサーバー応答コードを表示しているページへのリンクが原因で発生します。 クロールエラーがないかサイトをチェックするには、 Screaming FrogSEOSpiderと呼ばれるツールを使用できます。 無料の限定バージョンと、年間99GBPのフルバージョンがあります。 小規模なオンラインストアの場合は、無料バージョンで十分です。 数千ページのサイトの場合、徹底的にスキャンするには有料版が必要です。
Screaming Frogを使用してリンク切れをチェックするには、デフォルトのスパイダーモードで機能するようにアプリを設定するだけです。 ホームページのURLを入力し、[スタート]ボタンをクリックします。
クロールが終了するのを待ちます。 ページ数と接続速度によっては、クロールに数分から1時間かかる場合があります。

クロールが終了したら、一括エクスポートに移動し、[すべてのアンカーテキスト]をクリックします。 次に、データをCSVファイルとして保存し、Excelで開く必要があります。 次のようになります。

列F(ステータスコード)に移動し、値を最大から最小に並べ替えます。 あなたは上に壊れたリンクを見つけることができるはずです。 この場合、このサイトには4つの壊れたリンクしかありません。
列B(ソース)は、リンクを見つけて編集できるページを示しています。 列C(宛先)は、リンクが指しているURLを示します。 列E(アンカー)は、ソースページのリンクが添付されているテキストに関連しています。
次のいずれかの方法で壊れたリンクを修正できます。
- 宛先URLの修正–宛先URLのスペルが間違っている場合は、タイプミスを修正してリンクをライブに設定します。
- リンクの削除–リンク先URLに誤記はなかったが、リンク先のページが存在しなくなった場合は、ハイパーリンクを削除するだけです。
- リンクの置換–リンクが削除されたページを指しているが、置換ページまたはその代わりに使用できる別のページがある場合は、CMSのリンク先URLを置換します。
壊れたリンクを修正すると、リンクの公平性の循環が改善され、検索エンジンはサイトの技術的な健全性についてより良い印象を与えることができます。
オンラインストアの重複コンテンツとSEO
前述のように、オンラインストアは、運ぶ製品の数とSKUの名前が類似しているため、コンテンツの重複の問題に悩まされる傾向が高くなります。 Googleはページ間で十分な類似性を検出すると、検索結果に表示するページを決定します。 残念ながら、Googleのページの選択は、通常、あなたのページと一致していません。
重複の問題の影響を受ける可能性のあるeコマースサイトのページを見つけるには、Google検索コンソールに移動し、左側のサイドバーにある[検索の外観]をクリックします。 HTML改善レポートをクリックすると、次のように表示されます。

青いリンクされたテキストは、サイトに特定の種類のHTMLの問題があることを示しています。 この場合、重複するタイトルタグです。 これをクリックすると、関連するページが表示されます。 次に、レポートをCSVファイルにエクスポートして、Excelで開くことができます。
レポートと関連するURLを調査します。 タイトルタグとメタディスクリプションが重複している理由を分析します。 オンラインストアでは、これは次の理由で発生する可能性があります。
- 怠惰なタイトルタグの作成–最適化が不十分なサイトでは、Web開発者がすべてのページに同じタイトルタグを残す場合があります。 通常、これはサイトのブランド名です。 これは、タイトルタグを編集し、コンテンツの本質に応じて各ページに適切な名前を付けることで対処できます。
- 非常に類似した製品–一部のオンラインストアには、非常に類似した特性を持つ製品があります。 たとえば、衣服を販売するeコマースストアでは、10色のシャツを販売できます。 各色が一意のSKUとして扱われ、独自のページが付属している場合、タイトルタグとメタディスクリプションは非常に似ている可能性があります。
前のセクションで説明したように、rel = canonical HTML要素を使用すると、インデックスを作成するこれらのページのバージョンをボットに指定できます。 また、検索エンジンがサイト内の重複が仕様によるものであることを理解するのにも役立ちます。
- 偶発的な重複–場合によっては、eコマースCMSプラットフォームが誤って構成され、ページの重複で正常に実行される可能性があります。 これが発生した場合、根本的な原因に対処するためのWeb開発者の支援が必要です。 重複するページを削除し、301で元のページにリダイレクトする必要があります。
ボーナス:短いまたは長いタイトルタグとメタディスクリプションがあると識別されたページは、これらのフィールドを編集し、長さパラメータが守られていることを確認するだけで処理できます。 詳細については、このガイドの「タイトルタグとメタディスクリプション」セクションを参照してください。
サイトの速度
何年にもわたって、サイトの速度はGoogleの最も重要なランキング要素の1つになりました。 オンラインストアが完全なランキングの可能性に到達するには、モバイルデバイスとデスクトップデバイスの両方ですばやくロードする必要があります。 ライバルのオンラインストア間の競争力のあるキーワードの戦いでは、サイトの速度が優れているサイトは、通常、遅い競合他社よりも優れています。
速度部門でサイトのパフォーマンスをテストするには、 GooglePageSpeedInsightsにアクセスしてください。 テストするページのURLをコピーして貼り付け、Enterキーを押します。

Googleは、ページを1〜100のスケールで評価します。 85以上が優先スコアです。 この例では、テストされたサイトはデスクトップとモバイルの理想的な速度をはるかに下回っていました。 幸い、Googleは読み込み時間の問題に対処する方法について技術的なアドバイスを提供しています。 ページ圧縮、より優れたキャッシュ、CSSファイルの縮小、およびその他の手法により、パフォーマンスを大幅に向上させることができます。 Web開発者とデザイナーは、これらの改善を支援することができます。
安全なURL
数年前、Googleは安全なURLをランキング要素にしていると発表しました。 これにより、多くのeコマースサイトは、有機的なトラフィックの増加を追求するためにプロトコルを採用することを余儀なくされました。 SEOのメリットはごくわずかであることがわかりましたが、真の勝者は、データセキュリティが危険にさらされにくい、より安全なショッピング体験を楽しむエンドユーザーです。

Webブラウザのアドレスバーにある南京錠のアイコンを確認することで、オンラインストアが安全なURLを使用しているかどうかを確認できます。 そこにない場合は、開発者に実装してもらうことを検討してください。 現在まで、ほとんどのeコマースサイトのチェックアウトページには安全なURLしかありません。 ただし、ますます多くのオンラインストアの所有者がSSLプロトコルに切り替えています。
eコマースサイトに安全なURLを実装することは、困難な作業になる可能性があります。 検索エンジンは、HTTPとHTTPSの対応するページを2つの異なるWebアドレスと見なします。 したがって、サイト内のすべてのページをHTTPSで再作成し、301で古いHTTPに相当するものをすべてリダイレクトして機能させる必要があります。 言うまでもなく、これはSEOが考慮すべきいくつかの要因の1つにすぎない主要な決定です。
ページ上のSEO
ページ上のSEOとは、検索の可視性を高めるために個々のページを最適化するプロセスを指します。 これには主に、コンテンツの品質を向上させ、キーワードが重要な各ページの要素に存在することを確認することが含まれます。
ページ上のSEOは、大規模なeコマースサイトにとって大きなタスクになる可能性がありますが、ある時点で実行する必要があります。 微調整する必要がある各ページの要素は次のとおりです。
標準URLスラッグ
キーワードとのページの関連性を測定するときに検索エンジンが見るものの1つは、そのURLスラッグです。 検索エンジンは、解読できない文字よりも実際の単語を含むURLを好みます。 たとえば、[www.clothes.com/112-656-11455]のようなURLは技術的には機能するかもしれませんが、検索エンジンは[www.yourshop.com/pants]のように見えると、それが何であるかについてより良いアイデアを得るでしょう。 英数字の組み合わせの代わりに実際の単語を使用するURLは、「正規URL」と呼ばれます。 これらは、URLスラッグとは関係のない前述のrel=canonicalリンクと混同しないでください。

ほとんどのオンラインショッピングプラットフォームは、正規のURLをすぐに利用できます。 ただし、そうでないものもあり、これは注意が必要なことです。 CMSがそのまま使用するものでない場合は、Web開発者が正規URLスラッグの設定を支援できます。
SEOガイド–メタディレクティブ
robots.txtファイルとは別に、ページのインデックス作成を制限する別の方法があります。 これは、メタディレクティブタグと呼ばれるものを使用することによるものです。 簡単に言えば、これらは各ページのソースコードの<head>部分にあるHTML命令であり、ボットにページでできることとできないことを伝えます。 最も一般的なものは次のとおりです。
- Noindex –このタグは、検索エンジンにページのインデックスを作成しないように指示します。 robots.txtで許可されていない場合と同様に、このタグが付いているページはSERPに表示されません。 ただし、違いは、責任のあるボットがrobots.txtによって制限されているページをクロールしない一方で、インデックスのないページはクロールされるという事実です。インデックスが作成されないだけです。 その点で、検索スパイダーはインデックス付けされていないページのリンクを通過でき、リンクの公平性はこれらのリンクを通過できます。
noindexタグは、ブログタグページ、最適化されていないカテゴリページ、およびチェックアウトページを除外するために最適に使用されます。
- Noarchive –このメタタグを使用すると、ボットはページのインデックスを作成できますが、キャッシュされたバージョンのページをストレージに保持することはできません。
- Noodp –このタグは、ボットにOpen Directory Project(DMOZ)にサイトをリストしないように指示します
- Nofollow –このタグは、ページにインデックスを付けることができるが、その中のリンクをたどってはならないことを検索エンジンに通知します。
前に説明したように、Googleにインデックスを作成することを許可するページを決定するときは慎重に行うのが最善です。 一般的なページタイプのインデックス作成を処理する方法に関する簡単なヒントを次に示します。
- ホームページ–インデックス作成を許可します。
- 製品カテゴリページ–インデックス作成を許可します。 可能な限り、ページのコピーを拡張して、これらのページに幅を追加します。 詳細については、「固有のカテゴリと製品のコピー」セクションを参照してください。
- 製品ページ–ページに一意のコピーが書き込まれている場合にのみインデックス作成を許可します。 カタログまたは製造元のサイトから製品の説明を取得した場合は、「noindex、follow」メタタグを使用したインデックス作成を禁止してください。
- ブログ記事ページ–オンラインストアにブログがある場合は、必ず検索エンジンが記事のインデックスを作成できるようにしてください。
- ブログカテゴリページ–一意のコンテンツを追加した場合にのみインデックス作成を許可します。 それ以外の場合は、「noindex、follow」タグを使用します。
- ブログタグページ–「noindex、follow」タグを使用します。
- ブログ作成者アーカイブ–「noindex、follow」タグを使用します。
- ブログの日付アーカイブ–「noindex、follow」タグを使用します。
Shopify、Magento、WordPressなどの人気のあるeコマースプラットフォームにはすべて、Web管理者がページ内のメタディレクティブを簡単に管理できるようにする機能またはプラグインが組み込まれています。
特定のページがインデックスに登録されていない理由や、制限されていると思われるページがSERPに表示されている理由がわからない場合は、ソースコードを手動で確認できます。 または、Screaming Frogクロールを実行して、サイト全体のメタディレクティブリストを監査することもできます。

クロールを実行した後、[メタロボット]列を確認するだけです。 各ページのサイトにあるメタディレクティブタグを確認できるはずです。 他のScreamingFrogレポートと同様に、これをExcelシートにエクスポートして、データ管理を容易にすることができます。
タイトルタグ
タイトルタグは、ほとんどの検索エンジンにとって依然として最も重要なページ上のランキング要素です。 これは、検索結果の見出しのテキストであり、その主な機能は、60文字以下でページが何であるかを人間の検索者とボットに伝えることです。

タイトルタグが本質的に持つ簡潔さと重要性のために、eコマースSEOキャンペーンがこれらを正しくすることは非常に重要です。 よく書かれたタイトルタグは、ページのランク付け能力を最大化するために次の品質を備えている必要があります。
- スペースを含めて60文字以下
- ページの内容の要点を説明してください
- 早い段階でページの主要なキーワードに言及する必要があります
- 購入行動の言葉に言及することにより、購入意向に応える必要があります
- 必要に応じて、サイトのブランドについて言及します
- 「-」や「|」などの区切り文字を使用しますタイトルタグのコアとブランド名を区別します。
良いタイトルタグの例を次に示します。
デニムジーンズをオンラインで購入| Men'sWear.com
購入という言葉「購入」が存在することがわかりますが、製品タイプ「デニムジーンズ」はまだ早い段階で言及されています。 「オンライン」という言葉は、インターネット経由で購入できることを示すためにも言及されており、ページは検索者に物理的に購入できる場所を伝えるだけではありません。 オンラインストアのブランドも記載されていますが、テキストブロック全体はまだ60文字の推奨長さの範囲内です。
SEOガイド–メタディスクリプション
メタディスクリプションは、検索結果のタイトルタグの下に表示されるテキストブロックです。 タイトルタグとは異なり、これらは直接的なランキング要素ではありません。 実際のところ、それらを書かずに済ませることができ、Googleはページのコンテンツからクエリに最も関連性があると見なすテキストを取得するだけです。

ただし、メタディスクリプションを気にする必要がないという意味ではありません。 言い回しがよく説得力のある方法で書かれている場合、これらはユーザーがあなたのリストをクリックするか、競合他社のページに行くかを決定することができます。 メタディスクリプションはランキング要素ではないかもしれませんが、ページのクリック率(CTR)は確かにそうです。 CTRは、Googleがユーザーの意図を最もよく満たす検索結果を確認するために使用する重要なエンゲージメントシグナルです。
優れたメタディスクリプションには、次の性質があります。
- 長さ約160文字(スペースを含む)
- ページから何を期待するかについてのアイデアをユーザーに提供します
- ページのメインキーワードに少なくとも1回言及する
- ユーザーがリストをクリックする必要がある理由について、短いが説得力のあるケースを作成します
これは、「安価なプリンタインク」というキーワードでGoogleで1位にランクされているオンラインストアの素晴らしいサンプルです。

Notice how the meta description makes it clear from the start that they sell the products mentioned in the query with the phrase “Shop for ink cartridges, printer cartridges and toner cartridges.” This part also mentions the main keywords that the site targets. Meanwhile, the phrase “Find cheap printer ink for all brands at Carrotink.com. Free Shipping!” conveys additional details such as the brands covered and the value-add offer that promises free shipping. In much less than 160 characters, the listing tells shoppers looking for affordable inks that CarrotInk.com is a good destination for them.
SEO Guide – Header Text
Header text is the general term for text on a webpage that's formatted with the H1, H2, and H3 elements. This text is used to make headline and sub-headline text stand out, giving it more visual weight to users and contextual weight to search engines.
In online stores, it's important to format main page headlines with the H1 tag. Typically, the product or category name is automatically made the main header text like we see in the example blow. Sub-headings that indicate the page's various sections can then be marked up as H2, H3 and so on.

If your online store publishes articles and blog posts, remember to format main headlines in H1 and sub-headings in H2 and H3 as well. Effective header text is brief, direct and indicative of the context that the text under it conveys. It preferably mentions the main keyword in the text it headlines at least once.
If you want to check whether all your pages have proper header text, you can do an audit with Screaming Frog. Simply run a crawl and filter the results to just HTML using the Filter drop-down on the top left section of the app window. You can find column headings that say “H1-1”and “H2-1” when you scroll right. The text there are the headings in the page.

You can export these to Excel for easy data management and reference when applying changes.
SEO Guide – Image Alt Text
Google and other search engines have gotten dramatically smarter these past two decades. They're now so much better at understanding language, reading code and interpreting user behavior as engagement signals. What they haven't refined to a science just yet is their ability to understand what a picture shows and what it means in relation to a page's content.
Since bots read code and don't necessarily “see” pages the way human eyes do, it's our responsibility to help them understand visual content. With images, the most powerful relevance signal is the alt text (shorthand for alternate text). This is a string of text included in the image's code that provides a short description of what's being shown.
Adding accurate, descriptive and keyword-laced anchor text is very important to online stores since online shoppers tend to buy from sites with richer visual content. Adding alt text helps enhance your pages' relevance to their target keywords and it gets you incremental traffic from Google Image Search.
To check if your site uses proper image alt text, we can use trusty Screaming Frog once more. Do a crawl of your site from the home page and wait for the session to finish. Go to the main menu and click Bulk Export>Images>All Alt Tex t. Name the file and save it. Open the file in Excel and you should see something like this:

Column B (Source) tells us which page the image was found on. Column C (Destination) tells us the web address of the image file. Column D (Anchor) is where we'll find the anchor text if something has already been written. If you see a blank cell, it means no anchor text is in place and you'll need to write it at some point.
Good image alt texts have the following qualities:
- About 50 characters long at most
- Describes what's depicted in the image directly in one phrase
- Mentions the image's main keyword at least once
Different CMS platforms have different means of editing image alt texts. In a lot of cases, a spreadsheet being fed into the CMS for bulk uploads can contain image alt text information.
SEO Guide – Unique Category and Product Copy
SEO has everything to do with the age-old Internet adage “content is king” and that applies even to ecommerce websites. Analyses have continually shown that Google tends to favor pages and sites with more breadth and depth in their content. While most online store owners would cringe at the idea of turning their site into “some kind of library,” smarter online retailers know that content can co-exist with their desired web design schemes to produce positive results.
One of the fundamental flaws that a lot of ecommerce sites face from an on-page SEO perspective is the proliferation of thin content on unoptimized category pages and product pages with boilerplate content. Regular category pages have little text and no fundamental reason for existence other than to link to subcategory pages or product pages. Product pages with boilerplate content, on the other hand, don't deliver unique value to searchers. If your online store is guilty of both shortcomings, search engines won't look at it with much favor, allowing other pages with better content to outrank yours.
Category pages are of particularly high importance due to the fact that they usually represent non-branded, short and medium-length keywords. These keywords represent query intents that correspond with the top and middle parts of sales funnels. In short, these pages are the ones that users look for when they're in the early stages of forming their buying decisions.
Category pages can be optimized for SEO by adding one or both of the following:
- A short text blurb that states what the category is about and issues a call to action. This is usually a 2-3 sentence paragraph situated between the H1 text and the selection of subcategory product links.

- Longer copy that further discusses the category and the items listed under it. This can be one or more paragraphs and is positioned near the bottom of the page's body, under the list of subcategories or products in the page. This text isn't meant for human readers as much as it is for bots to consume and understand text.

For both text block types, the goal is to increase the amount of text and provide greater relevance between the page and its target keyword. The text blocks also provide opportunities for internal linking as the text can be used as anchors for links to other pages.
一方、商品ページは、販売目標到達プロセスの下部にあるクエリインテントを表します。 製品ページは、購入したいものをすでによく理解していて、それを販売するのに最適なベンダーを探しているユーザーの意図と一致しています。 製品ページが表すキーワードは、通常、検索ボリュームは少なくなりますが、コンバージョン率は高くなります。
製品ページのコピーを最適化することは、通常、作業が集中するため、それほど難しくありません。 数百または数千もの製品の詳細を調査し、それらを独自性のために書き直すと、膨大な工数がかかる可能性があります。 通常、SEOに精通したオンラインストアの所有者は、優先する製品ラインに対してのみこれを選択的に行います。 一意のコンテンツが入力されていない製品ページは、通常、noindexタグを使用して制限され、一意のコピーで最適化されたページにリンクの公平性とクロール予算を集中させます。
製品ページの独自のコピーを作成するときは、独自の方法で次のように作成することに重点を置いてください。
- メリットステートメント–コピーの一部で、製品が問題を解決する方法、またはターゲット顧客の生活を改善する方法を示す3つまたは4つの箇条書きをリストします。
- ユースケース–製品の考えられる使用法と用途について言及しているコピーのセクション。
- ハウツーセクション–製品の使用方法またはインストール方法に関する指示を提供するコピーの一部。
- カスタマーレビュー–購入者が製品に関するフィードバックを書くことを許可するコピーの一部。 確認済みの顧客のみに投稿を許可するようにしてください。 品質と読みやすさのためにコンテンツをモデレートすることも役立ちます。
リッチでユニークで便利な製品ページのコピーの良い例を見たい場合は、ここにあります。
カテゴリと製品ページのコンテンツは、ページがGoogleでゼロの位置を達成するのにも役立ちます。 これは、一部のクエリで他のすべての上に表示されるインスタント回答ボックスです。 作成したコンテンツが明確かつ直接的な方法で質問に回答し、適切なヘッダータグを使用し、箇条書きと番号付きリストに適切なHTMLタグを使用している場合、コンテンツがSERPで目立つように表示されていることに気付くかもしれません。
ページ付け
製品カテゴリのページには非常に多くのアイテムが含まれているため、すべてを1つのページに表示すると見栄えが悪くなることがあります。 その設計上の問題を解決するために、Webデザイナーはページ付けされたコンテンツを利用します。 これは、カテゴリページで、残りのリストを非表示にしたまま、その下のリストの一部を表示できるようにする方法です。 ユーザーが残りの部分を見たい場合は、ページ番号をクリックして、リスト内の他のアイテムが表示されている同じページに移動できます。

これはデザインと使いやすさには優れていますが、注意しないとSEOの問題になる可能性があります。 検索エンジンは、一連のページがより大きな全体に属する場合があることを理解するのが得意ではありません。 そのため、同じタイトルタグ、メタディスクリプション、およびカテゴリページのコピーが表示されるため、ページ付けされたシリーズのページをクロールしてインデックスを作成し、重複として表示する傾向があります。
検索エンジンがカテゴリページでページ化されたシリーズを識別できるようにするには、Web開発者にページ化されたコンテンツにrel =” prev”およびrel =” next”要素を実装させるだけです。 これらの要素は、ページがシリーズに属し、最初のページのみにインデックスを付ける必要があることを検索エンジンに通知します。 これらのHTML要素について詳しくは、こちらをご覧ください。
SEOガイド–集計レビュースキーマ
おそらく、リストにレビュースターが付いた製品やサービスの検索結果を見たことがあるでしょう。 これらのスターは、SERPのスペースを占有し、視覚的な注意を引くだけでなく、検索者のクリック動作を促進します。 オンラインストアの場合、レビュースターを商品ページのリストに表示すると非常に便利です。 これらのリッチスニペットは、ユーザーがあなたのリストをクリックするか、競合他社のリストをクリックするかを決定する要因になります。

幸い、レビュースターの実装は比較的簡単です。 このコード文字列を製品ページに追加するだけで、すべての設定が完了します。
<script type =” application / ld + json”>
{「@context」:「http://schema.org」、
「@type」:「Product」、
「名前」:「## PRODUCT ###」、
「aggregateRating」:
{“ @type”:“ AggregateRating”、
「ratingValue」:「## RATING ##」、
“ reviewCount”:“ ## REVIEWS ##”
}
}
</ script>
## PRODUCT ###の部分に製品の名前を入力し、## RATING ##の部分に製品の集計されたレビューのスコアを入力し、##REVIEWS##の部分にレビューの数を入力する必要があります。 コードの処理に不安がある場合は、このタスクをWeb開発者に割り当てると、物事が正しい方向に進むようになります。
もちろん、このマークアップを追加しても、Googleが実際にレビュースターを表示することを保証するものではありません。 検索の巨人には、従うべき一連のアルゴリズムがあります。 集計レビュースターが表示される可能性を高めるために、次の点に注意してください。
- マークアップコードは特定の製品ページにのみ追加してください。 eコマースサイトのホームページとカテゴリページに追加しても効果はありません。
- 実際の顧客レビューを奨励し、独自のレビュースコアを作成することは避けてください。
- サイト内と外部ソースからのレビューの健全なバランスを促進するようにしてください。
- あなたがあなたの命令で人々にあなたのページに評価を割り当てさせることを計画しているなら、すべての製品に対して一度にそれをしないでください。 すべてのページが突然評価を取得することは不自然に見え、Googleによって不利に表示される可能性があります。
一部のCMSプラットフォームは、スキーママークアップを備えた他のプラットフォームよりも優れていることに注意してください。 たとえば、Genesisベースのテーマを実行している場合、WordPressにはスキーママークアップが組み込まれています。
ボーナス:リンク構築戦略
この投稿はオンサイトSEOに関するものですが、eコマースサイトの所有者が検索市場のニッチを支配したいのであれば、最終的にリンク構築について考えることは避けられません。 収入日記は過去に正しい方法でリンクを構築する方法について投稿したので、それについては詳しく説明しません。 ただし、これらの被リンクをどこに向けるかについては説明します。
一般に、Webサイトはピラミッド型の情報アーキテクチャに従います。 ピラミッドの先端としてホームページを想像してみてください。そのメインカテゴリとサブカテゴリは、その下の次の数層を構成しています。 ピラミッドのベースには製品ページがあります。 これらは最も多くのページタイプですが、階層の最下部にあります。

ここで、ピラミッドを内部配水システムを備えたピラミッドとして想像してください。 この場合、水はリンクエクイティです。 これはほとんどのインバウンドリンクが指している場所であるため、そのほとんどはヒント(ホームページ)から来ています。 エクイティは、ホームページからリンクされているカテゴリページに流れ込み、次に下降して製品ページ全体に分配されます。
そうは言っても、あなたの目標がすべてのページのランキング力を高めることである場合、ホームページはインバウンドリンクを指すのに最適なページです。 これにより、ホームページが表す短いキーワードのランクが上がり、カテゴリページと製品ページが段階的に向上します。
残りの製品よりも優先している製品ラインがある場合は、それぞれのカテゴリページへのリンクを作成するのに役立ちます。 これにより、カテゴリページのSERPでのパフォーマンスが向上するだけでなく、より強力なリンクエクイティが製品ページにカスケードされます。
結局のところ、オンラインストアに適したSEOとは、より高度なクロール性とページへの関連性を促進することです。 これらの最適化タスクをサイトのメンテナンスバケットリストに追加することは、主要なタスクのように見えるかもしれませんが、その見返りは努力する価値があります。
著者略歴: Itamar Geroは、まだ白黒であった時代からネット上にありました。 彼はイスラエルで生まれ育ち、現在はフィリピンに住んでいます。 彼はSEOReseller.comの創設者であり、最近Siteoscope.comを立ち上げました。
おすすめの投稿:
=>レイエドワーズコピーライター| ポッドキャスト:売れるコピーの書き方
=> SEOガイド:ほとんどのブロガーが忘れている10のSEOブログ投稿公開手順