
Предиктивная сегментация: начало работы с персонализацией, основанной на реальных данных
Опубликовано: 2021-12-30Как говорит Авинаш Кошик, «все данные в совокупности — чушь». Сегментация и персонализация на основе данных — одни из самых мощных инструментов, которыми располагают маркетологи и продакт-менеджеры.
Вместо того, чтобы относиться ко всем посетителям или пользователям одинаково, вы можете создавать впечатления, основанные на уникальных поведенческих, психографических, демографических и фирмографических характеристиках ваших пользователей.
На данный момент, я думаю, все увлеклись идеей сегментации, а также ее логическим продолжением — персонализацией.
На самом деле, согласно исследованию Evergage, «92% маркетологов сообщили об использовании методов персонализации в своем маркетинге, однако 55% маркетологов считают, что у них недостаточно данных о клиентах для реализации эффективной персонализации».
Теория, лежащая в основе сегментации и персонализации, часто более радужна, чем реальность ее реализации. На самом деле вам нужны три основных компонента, чтобы программа персонализации работала.
В этой статье будут рассмотрены эти основные принципы, а затем я объясню разницу между традиционной сегментацией и сегментацией с прогнозированием (управляемой машинным обучением).
- Что такое предиктивная сегментация?
- Данные, контент и правила таргетинга: основы персонализации
- Данные
- Содержание
- Логика таргетинга
- Предиктивная сегментация против бизнес-логики
- Сегментация бизнес-логики
- Персонализация на основе мнений
- Сегментация после тестирования
- Исследовательский анализ данных и корреляции
- Предиктивная сегментация
- Кластеризация
- Классификация
- Экспериментирование + предиктивная сегментация
- Как начать работу с персонализацией на основе данных
- Этап первый: прогулка
- Второй этап: бег
- Третий этап: полет
К концу этой статьи у вас будет хорошее представление о том, как реализовать персонализацию на основе данных и прогнозную сегментацию.
Во-первых, что такое «прогностическая сегментация»?
Сегментация на высоком уровне — это процесс разделения чего-либо на отдельные части или разделы.
Источник: CXL
Когда мы говорим «сегментация», мы обычно имеем в виду «сегментацию рынка», «сегментацию клиентов» или, возможно, «сегментацию поведения». Этот тип сегментации представляет собой процесс выявления и определения характеристик, которые отделяют одну подгруппу или часть клиентов от другой.
Обычно это делается с помощью бизнес-логики. Например, можно сказать, что пользователи мобильных устройств — это отдельный сегмент от пользователей настольных компьютеров. Или, что чаще, мы можем сгруппировать посетителей по географическому признаку: пользователи NAM и EMEA.
Прогнозирующая сегментация — это когда вы идентифицируете пользовательские кластеры программно или с помощью машинного обучения. Подробнее - через @webengage Click To TweetВ этом методе у вас обычно есть цель или результат, который вы отслеживаете, и вы можете работать в обратном направлении, чтобы определить общие характеристики, которые разделяют подгруппы по отношению к этой цели.
Например, вы можете отслеживать «конверсии подписки на список рассылки» в своем блоге. Предиктивная сегментация может обнаружить, что существуют отдельные группы, которые ведут себя последовательно при посещении вашего блога.
Одна группа мобильных посетителей, как правило, проводит очень мало времени на сайте и часто отказывается от посещения. Другая группа посетителей компьютеров из органических каналов тратит очень мало времени и уходит с такой же высокой скоростью.
Вы можете обнаружить эти сегменты самостоятельно, используя анализ данных, но инструменты предиктивной сегментации стремятся идентифицировать и группировать эти пользовательские сегменты. Обычно такие инструменты пытаются предсказать действия этих сегментов, чтобы вы могли активировать правила персонализации.
Данные, контент и правила таргетинга: основы персонализации
Чтобы успешно предоставлять персонализированный опыт различным сегментам пользователей, вам нужны три компонента:
- Данные
- Содержание
- Логика таргетинга
1. Данные
Данные лежат в основе всего, что касается сегментации и персонализации.
Если у вас нет данных, которые вам нужны, когда они вам нужны, вы не можете идентифицировать сегменты пользователей, не говоря уже о том, чтобы инициировать для них персонализированный опыт. Кроме того, если ваши данные неточны и/или неполны, ваша персонализация может оказаться неэффективной.
Поэтому, прежде чем приступать к какой-либо сегментации, подтвердите следующие три вещи:
- Вы измеряете все, что вам нужно? Есть ли у вас правильно настроенные цели, специальные параметры и т. д.? Являются ли ваши данные «полными»?
- Ваши данные заслуживают доверия? Он не обязательно должен быть «точным» на 100%, но является ли он последовательным и точным в своей регистрации?
- Доступны ли ваши данные, когда они вам нужны? Сколько очистки и подготовки вам нужно сделать, чтобы извлечь ценную информацию из ваших данных? Собраны ли данные и связаны ли они с другими источниками (социальными сетями, Интернетом, электронной почтой, данными клиентов)? Хранится ли он в месте, которое можно использовать и немедленно проанализировать?
Кроме того, вы захотите подключить свои источники данных к некоторой таблице централизованного хранения. В настоящее время платформы данных о клиентах (CDP), такие как Hull.io и Segment, являются частью игры, но вы также можете использовать CRM, такие как HubSpot, для централизации, хранения и использования ваших маркетинговых и клиентских данных.
Они становятся важными, когда вы соединяете свои данные до покупки с данными после покупки. Это позволяет вам идентифицировать сегменты на основе важных бизнес-показателей, таких как их прогнозируемая пожизненная ценность или скорость оттока.
2. Содержание
Контентную часть понять намного проще.
По сути, если вы хотите выполнить персонализацию, вы сначала определяете пользовательский сегмент, используя свои источники данных. Затем вам также необходимо создать новый опыт для этого сегмента.
Создание нового контента или опыта требует ресурсов, как времени, так и денег. Кроме того, чем больше контента и опыта вы предоставляете и чем больше управляете, тем сложнее становится ваша организация.
Мэтт Гершофф, генеральный директор Conductrics, провел по этому поводу прекрасную аналогию в подкасте Digital Analytics Power Hour.
Он описал персонализацию как создание мультивселенной.
Запуск одной версии вашего веб-сайта для всех — это все равно, что иметь одну вселенную, и, возможно, A/B-тестирование позволяет вам запустить контрфактику, чтобы увидеть, как будет выглядеть жизнь в параллельной вселенной (или «версии B»).
В тесте A/B вы хотите увидеть, является ли версия B лучшей «вселенной» для ваших посетителей, как определено конверсией вашей цели, и если вы обнаружите, что она действительно оптимальна, вы закрываете вселенную A (исходную) и снова снова войти в сингулярную вселенную.
Тем не менее, несколько вариантов контента, доставляемых нескольким уникальным сегментам, — это все равно, что держать открытыми несколько отдельных вселенных, в которых впечатления уникальны для этих сегментов.
Магия этого заключается в том, что вы можете повысить ценность своего веб-сайта, увеличив ценность каждого отдельного сегмента и их опыта, но вы можете понять, насколько дорого открытие тысяч «вселенных» будет дорогостоящим как с точки зрения создания, так и управления всеми этими опыт.
3. Целевая логика
Наконец, если у вас есть полезные данные и ресурсы для создания контента, вам нужно определить, как именно вы запускаете логику таргетинга или персонализации для пользовательских сегментов.
Так вы связываете данные с опытом.
Вы можете использовать бизнес-логику (предполагая, что определенные сегменты должны иметь определенные значения — вы даже можете провести их A/B-тестирование), или вы можете внедрить машинное обучение и предиктивную сегментацию/RFM, чтобы классифицировать своих пользователей по разным группам — наиболее ценные пользователи, которые вот-вот уйдут. пользователи, спящие пользователи и т. д. Используя сегментацию RFM, вы также можете узнать, какие пользовательские сегменты более по-разному реагируют на тот или иной контент.
Технически для этого шага вам нужна система доставки контента, которая либо подключена к вашей базе данных, либо может интегрироваться и извлекать данные из вашей базы данных. WebEngage — это полнофункциональная операционная система для автоматизации маркетинга и удержания клиентов, которая может легко подключаться к вашей CRM и помогать вам привлекать ваших пользователей на основе 1: 1 по таким каналам, как электронная почта, SMS, WhatsApp, Facebook, Mobile & Web Push и т. д.
Опять же, чем больше правил таргетинга вы запускаете, тем сложнее система, которую вы строите. Таким образом, существует компромисс между рентабельностью инвестиций, которую вы можете использовать, ориентируясь на определенный сегмент и предельную сложность системы. Легко объединить имена с пользовательскими токенами электронной почты (большинство почтовых инструментов делают это из коробки), но это не говорит вам о рентабельности инвестиций этого правила таргетинга.
Источник: GMass
Вот почему вместо того, чтобы просто настраивать тонны персонализации только потому, что вы можете, вы должны смотреть на это стратегически и методологически, определяя рентабельность инвестиций и эффективность таргетинга на данный сегмент.
Предиктивная сегментация против бизнес-логики
Я уже отказался от некоторых терминов в отношении логики таргетинга, таких как «бизнес-логика» и «предиктивная сегментация».
Бизнес-логика, по сути, стоит по другую сторону спектра от «персонализации на основе данных», «предиктивной сегментации» или «персонализации на основе машинного обучения». Но оба эти метода преследуют одну и ту же цель: определить сегменты, которые нужно обрабатывать с помощью персонализированного опыта.
Давайте определим эти два полюса и чем они отличаются.
Сегментация бизнес-логики
«Бизнес-логика» — это обычный метод, с помощью которого люди выбирают правила таргетинга. В этом методе вы в основном решаете, какие сегменты имеют наибольшие возможности воздействия, используя исторические данные и корреляции или бизнес-логику, стратегию или мнения. Существует три основных способа получения правил таргетинга бизнес-логики:
- Персонализация на основе мнений
- Сегментация после тестирования
- Исследовательский анализ данных
1. Персонализация на основе мнений
Например, вы можете просто захотеть избежать запуска агрессивного всплывающего окна на мобильном телефоне по чисто субъективным причинам. Это не очень хороший пользовательский опыт, поэтому вы его избегаете. Вам даже не нужны данные, чтобы предсказать реакцию этого сегмента.
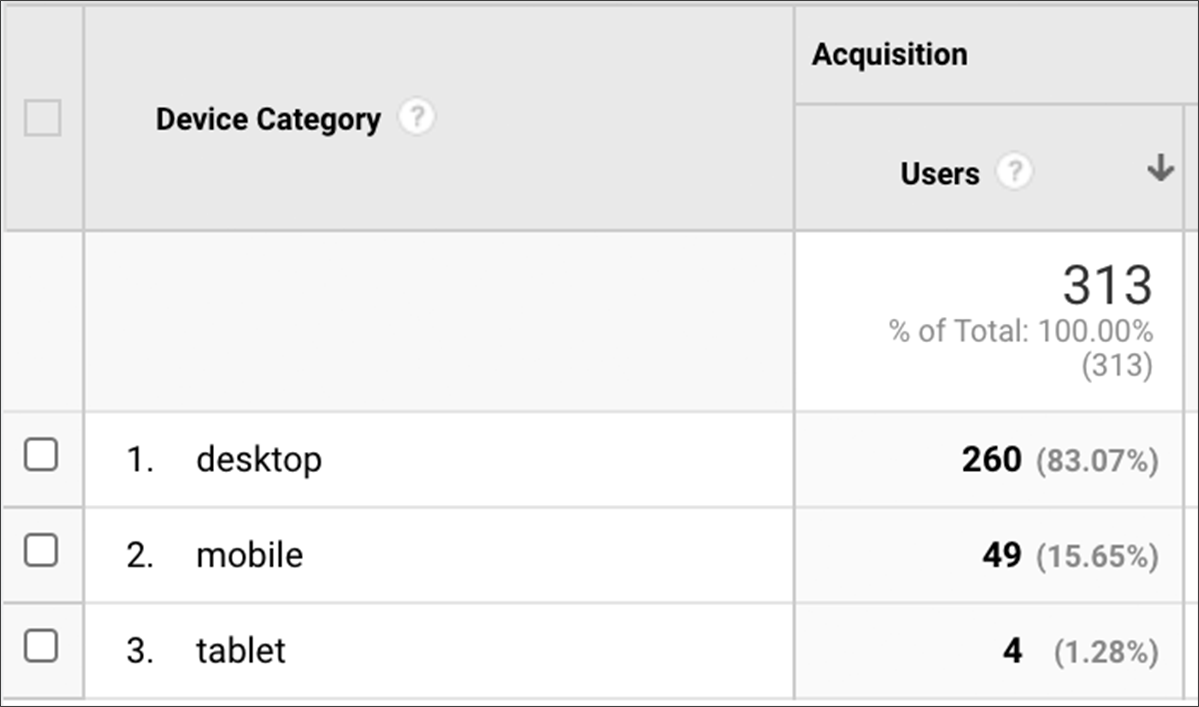
Различное отношение к мобильным пользователям — распространенный способ персонализации.
Это метод, который использует подавляющее большинство компаний, когда говорят, что проводят сегментацию или персонализацию на основе данных. Они произвольно угадывают, какой сегмент положительно отреагирует на какой опыт, и персонализируют его, основываясь на своем мнении.
2. Сегментация после тестирования
Менее распространенным (но более эффективным), однако, является проведение эксперимента с последующим анализом после тестирования, чтобы выяснить, оказали ли определенные варианты более сильное влияние на определенные сегменты.
Представьте, что вы тестируете процесс оплаты электронной коммерции.
Вы решаете протестировать несколько вариантов — один вариант с серией символов доверия и безопасности, один с всплывающим окном, использующим срочные сообщения, и один без символов (исходная версия).
Проанализировав эксперимент, вы определили, что версия Б «выиграла» и что ее расчетный прирост составляет 10 %. Отличная победа.
Однако вы копаетесь в данных и смотрите на сегменты с высокой отдачей, такие как посетители с мобильных и настольных компьютеров, вернувшиеся и новые посетители, а также посетители из США и посетители из других стран.
При этом вы обнаружили, что пользователи iPhone на самом деле конвертировались на 35 % лучше при варианте B. Пользователи iPhone составляют значительный процент вашей аудитории, примерно 25 % всех посетителей. Это означает, что инициирование персонализированного взаимодействия с этим сегментом может быть целесообразным и иметь положительную рентабельность инвестиций.

Кроме того, пользователи Android фактически конвертировали на 20 % ниже по варианту B и на 15 % выше, чем контрольный вариант по варианту C. Пользователи Android составляют 10 % вашей аудитории, так что опять же, довольно большое количество населения.
Таким образом, вы могли просто запустить вариант B, потому что он выиграл в совокупности. Или, в качестве альтернативы, вы можете настроить правила таргетинга, чтобы пользователи iPhone получали вариант B, а пользователи Android — вариант C. Все остальные получают оригинал.
3. Исследовательский анализ данных и корреляции
Последний способ, которым вы можете использовать «бизнес-логику» для сегментации, — просто изучить данные, к которым у вас есть доступ, и найти корреляции между характеристиками сегмента и вероятностью конверсии.
Например, вы можете обнаружить, что пользователи iPhone конвертируются выше. Или люди, которые смотрят видео на вашей домашней странице. Или пользователи Android-мужчины из Канзаса, которые заполнили половину полей вашей формы и вернулись 3 раза за неделю.
Вот проблема с этим подходом: посмотрите на достаточное количество сегментов, и вы найдете корреляцию. Это проблема соотношения сигнала и шума.
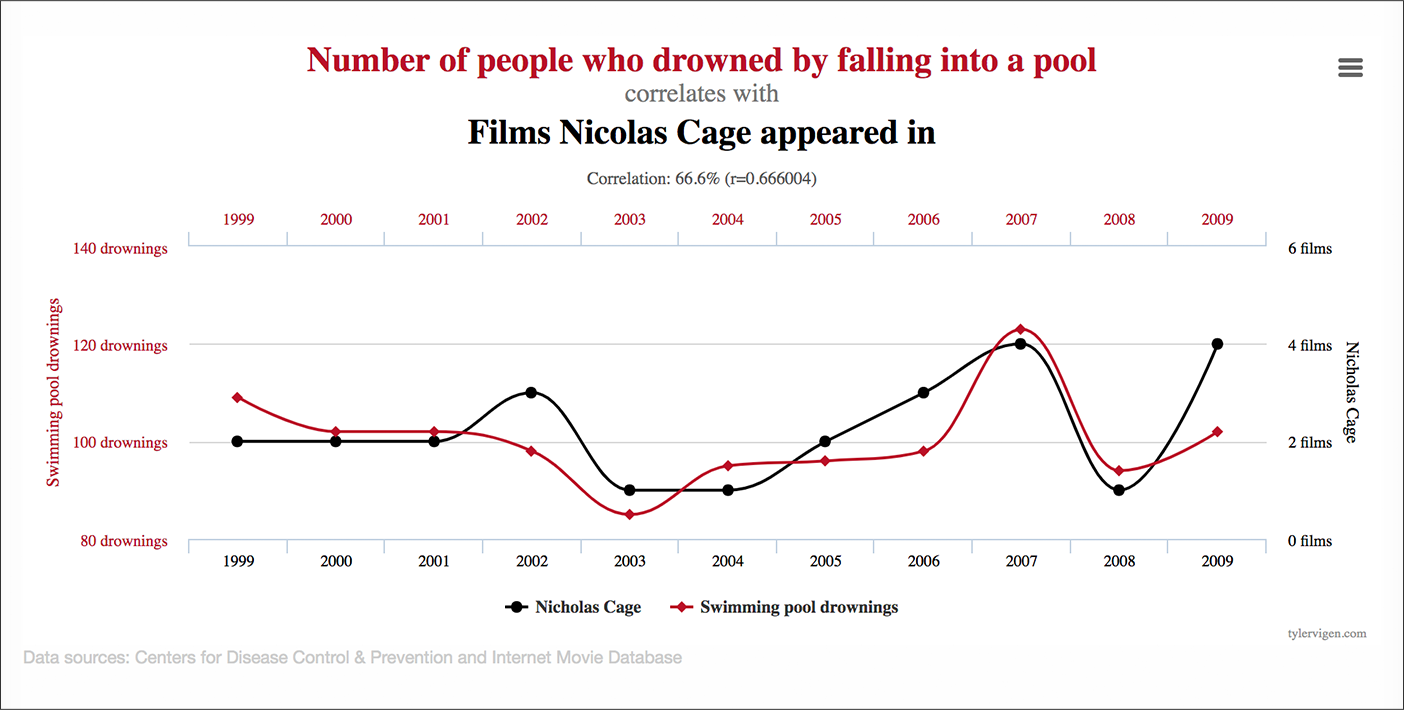
Источник: Тайлер Виген.
Большая проблема с этим подходом заключается в том, что корреляция не подразумевает причинно-следственной связи.
Тот факт, что вернувшийся посетитель компьютера из Калифорнии конвертируется выше, не означает, что на этот сегмент стоит ориентироваться с помощью персонализации на основе данных.
Лучше всего в мире бизнес-логики проводить эксперименты и обнаруживать ценные сегменты с помощью посттестовой сегментации. Затем вы вычисляете рентабельность инвестиций для заданного правила таргетинга и запускаете последующий эксперимент только с таргетингом на этот сегмент.
Затем вы можете выявить причинно-следственную связь и истинную рентабельность инвестиций в поддержание этого правила таргетинга. Для получения дополнительной информации об этом подходе прочитайте замечательное пошаговое руководство Эндрю Андерсона по этой теме.
Предиктивная сегментация
Прогнозирующая сегментация (или, по-другому, «сегментация, управляемая данными» или «сегментация на основе ИИ») стремится исключить человеческую интуицию и ручной анализ данных из определения сегментов и настройки правил таргетинга.
Существует несколько способов определения сегментов с помощью машинного обучения. Это просто зависит от ваших целей и того, чего вы надеетесь достичь с помощью этих сегментов. Здесь мы рассмотрим три метода ключей:
- Кластеризация
- Классификация
- Экспериментирование + предиктивное объединение
1. Кластеризация
Во-первых, если вы просто хотите идентифицировать и понимать различные типы пользователей или сегменты, алгоритмы кластеризации (или неконтролируемое машинное обучение) — это метод, используемый для группировки сегментов на основе общих характеристик.
Это то, над чем я работал в CXL Institute несколько лет назад.
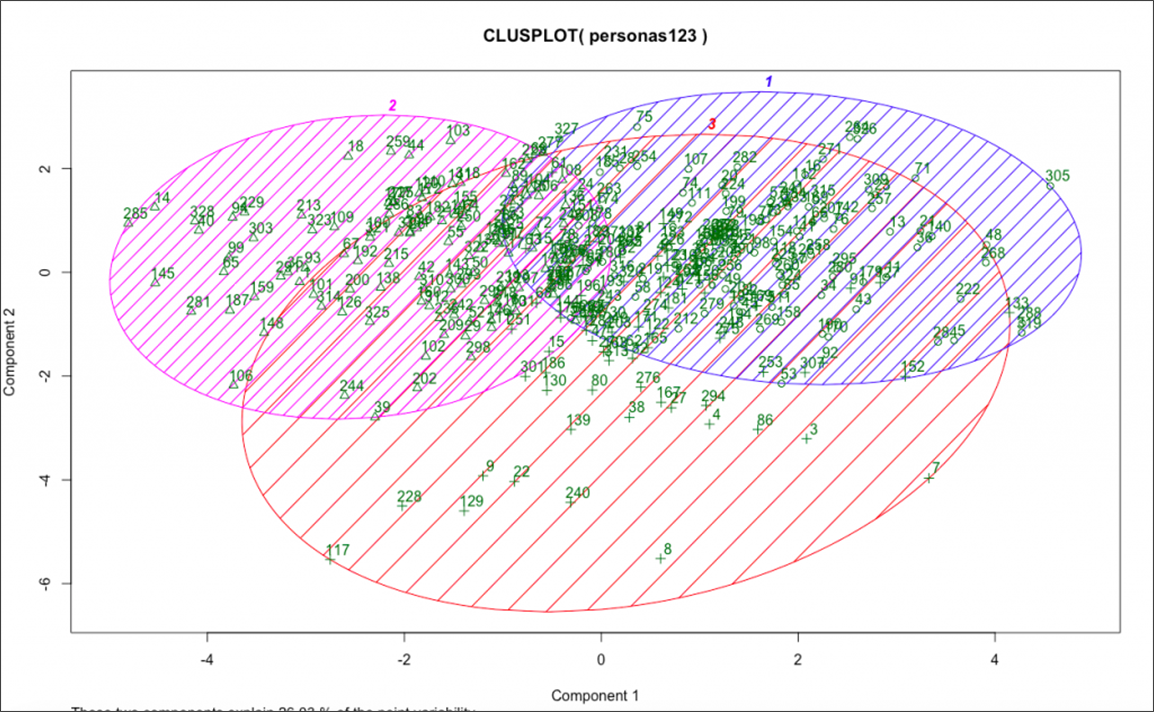
Источник: CXL
Мы разослали опросы нашей клиентской базе со смесью масштабных ответов, категориальных переменных и открытых вопросов. Затем я систематизировал их ответы и применил к ним алгоритм кластеризации K-средних.
Это определило примерно три отдельных сегмента на основе их ответов. Затем я наслаил качественные выводы из каждого из этих сегментов и взял интервью у людей, наиболее репрезентативных для каждого сегмента. Это позволило нам глубоко понять нашу существующую клиентскую базу и их различные желания, проблемы и поведение.
Если вы хотите выполнить кластеризацию, знайте, что это в основном исследовательская деятельность и накопление знаний. Он не расскажет вам о рентабельности инвестиций в персонализированную маркетинговую коммуникацию для одного из этих сегментов, а также не скажет вам, какие сегменты, скорее всего, отреагируют на тот или иной опыт. Например, вы можете обнаружить, что определенный сегмент подписчиков электронной почты открывают больше электронных писем и имеют более высокую пожизненную ценность, но вам все равно нужно проделать творческую работу по придумыванию нового контента и опыта для тестирования.
Но это хороший базовый уровень для начала персонализации на основе данных.
Вам также понадобится достойный аналитик, который может программировать на R или Python, или, по крайней мере, такой инструмент, как Squark, который не позволяет проводить предиктивную аналитику кода.
2. Классификация
Машинное обучение, как правило, разделяется на контролируемое и неконтролируемое обучение. Там, где алгоритмы кластеризации не контролируются, алгоритмы классификации контролируются.
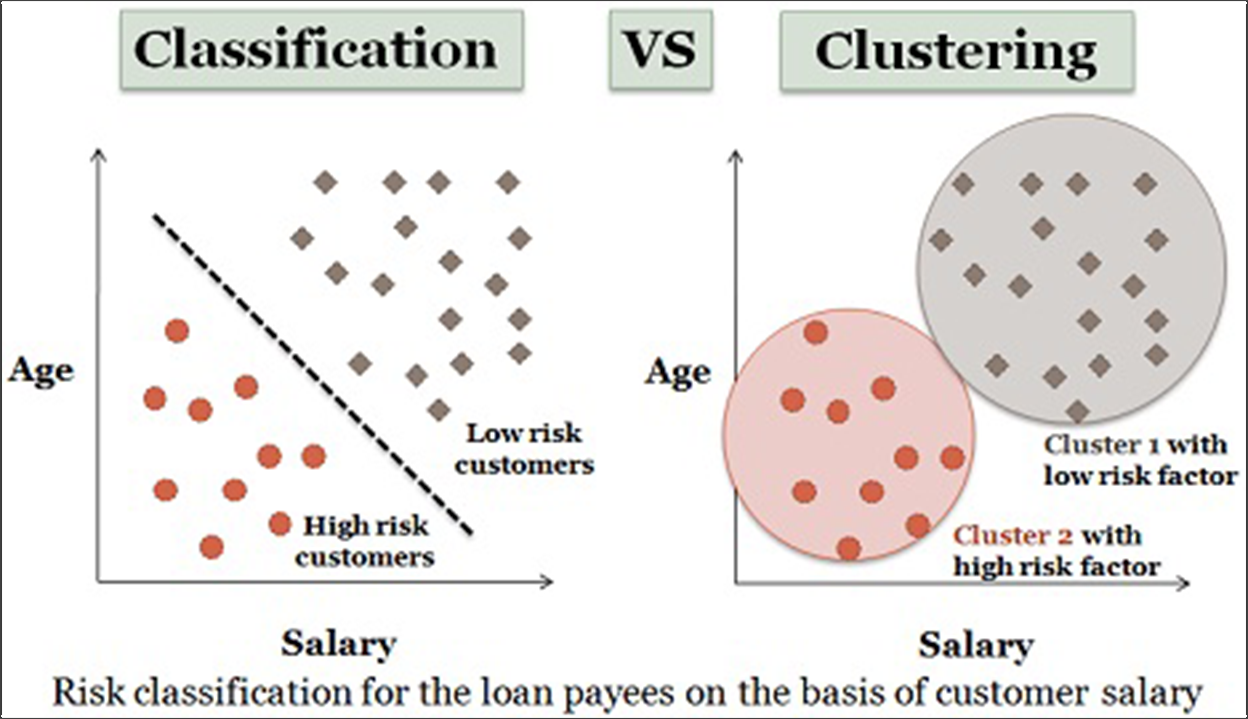
Источник: Технические различия
Это означает, что у вас есть набор данных, который включает в себя различные «функции» (в нашем случае это могут быть такие вещи, как тип устройства, посещенные страницы, размер компании или любые характеристики, которые мы можем собрать о посетителях), а затем у вас есть результаты, которые вы хотите спрогнозировать (в нашем случае это конверсии, доход или LTV).
Существует огромное количество методологий и алгоритмов, которые пытаются предсказать результаты на основе характеристик данных, некоторые из которых включают линейную регрессию, логистическую регрессию, случайный лес и нейронные сети.
Если вы хотите использовать этот метод, вам понадобится отличный аналитик, который сможет правильно подобрать модель к вашим данным (в противном случае прогнозы бесполезны), или купите такой инструмент, как Squark или DataRobot. Эти инструменты позволяют аналитикам и бизнесменам подгонять различные модели к своим данным и прогнозировать результаты, не кодируя сами алгоритмы.
3. Эксперимент + предиктивная сегментация
Часто лучший способ найти прибыльные пользовательские сегменты — это пройти обычный курс контролируемых экспериментов и использовать инструмент (или метод анализа), который обнаруживает многообещающие сегменты.
Conductrics, например, показывает вам легко интерпретируемое дерево решений, которое вычисляет вероятность успешной конверсии для отдельных сегментов, соответствующих каждому протестированному вами варианту.
Бонусные баллы, если ваш инструмент предиктивного таргетинга имеет визуализацию данных, которая показывает вам в простых иллюстрациях, какие правила таргетинга вы установили, а также предполагаемую рентабельность инвестиций и вероятность успеха этих правил.

Источник: Проводники
Это круто, потому что вы не только получаете вероятность успеха, но и можете выбрать, следует ли ориентироваться на этот сегмент, основываясь на его ценности.
Мужчина-андроид возвращает посетителей из сельского Кентукки? Возможно, не стоит устанавливать новое правило таргетинга. Но, возможно, стоит ориентироваться на калифорнийцев, если они составляют большую часть населения и очень положительно реагируют на данный опыт.
Как начать работу с персонализацией на основе данных
Хотя может показаться заманчивым погрузиться в глубокую часть персонализации на основе данных, я рекомендую начинать медленно.
Неизвестно, какова истинная ценность того или иного правила персонализации, и часто предельная отдача от повышенной персонализации не соответствует введенным предельным затратам сложности.
Поэтому я представлю три подхода к персонализации возрастающей сложности (и давайте предположим, что этап «сканирования» — это просто упорядочивание ваших данных и ресурсов/инструментов, необходимых для предоставления персонализированного опыта).
Этап первый: прогулка
Поэтому, прежде чем инвестировать в инструмент предиктивного таргетинга, вы можете воспользоваться методологией Эндрю Андерсона, которая может стать простым продолжением вашей обычной программы экспериментов (примечание: у вас нет трафика для экспериментов? Персонализация не для вас. предельная доходность не будет стоить того при таком уровне трафика. Вместо этого используйте большие колебания).
Вот суть методики:
- Создайте несколько исполнений сообщения или опыта
- Показывайте все предложения всем с помощью контролируемого эксперимента
- Посмотрите на результаты по сегментам и рассчитайте общий выигрыш, предоставив дифференцированный опыт. Убедитесь, что вы делаете поправку на множественные сравнения при анализе многих сегментов.
- Реализуйте найденную возможность с наибольшим доходом (или проведите дополнительный эксперимент только на этом сегменте с опытом, который вы протестировали на всей аудитории).
Вы можете использовать специальные платформы A/B-тестирования или интегрированную платформу автоматизации маркетинга. Последний поможет вам персонализировать сообщения на нескольких каналах, а не только в Интернете или приложении, и вы сможете предлагать персонализированные рекомендации по продуктам, увеличивать свой доход и CLTV, улучшать поиск контента / продуктов и многое другое.
Второй этап: бег
После того, как вы одержите здесь несколько побед, вы можете захотеть инвестировать в решение для прогнозной аналитики без кода, такое как Squark (или, если вы можете кодировать алгоритмы самостоятельно, во что бы то ни стало). Основной процесс выглядит примерно так:
Определите свои показатели успеха
Собирайте и очищайте свои данные, разделяя набор данных на обучающие и тестовые данные.
Убедитесь, что у вас есть множество измерений или функций в ваших данных, которые можно использовать для прогнозирования результата.
Определите, какие функции предсказывают ваши показатели успеха.
Рассчитайте рентабельность инвестиций в персонализацию для этих сегментов. Опять же, если население слишком мало, оно того не стоит.
Теперь важная часть: после того, как вы определили функцию или параметр, которые предсказывают успех (скажем, это вернувшиеся посетители), вы все еще не выяснили, какой опыт с большей вероятностью будет работать в этом сегменте.
По-прежнему остается тяжелая работа: то есть создание новых замечательных впечатлений и проведение экспериментов, чтобы определить эффективность и рентабельность ваших новых впечатлений.
Вы все равно захотите инвестировать в решение для доставки контента, такое как WebEngage, чтобы ориентироваться на определенные сегменты.
Третий этап: полет
Наконец, если вы хотите включить прогностический таргетинг в свой обычный рабочий процесс экспериментов и оптимизации, вы не сможете превзойти такие инструменты, как Conductrics или Dynamic Yield. Эти инструменты помогут вам определить сегменты и предоставить персонализированный опыт, предоставив вам интерпретируемые правила принятия решений и отчеты об атрибуции ROI.
Вывод
В мире, где доминируют заголовки и доклады на конференциях о том, что искусственный интеллект является серебряной пулей, вы можете быть удивлены, узнав, что процесс «персонализации на основе данных» или «предиктивной сегментации» не делает всю работу за вас.
Это может помочь вам использовать ваши данные и сэкономить много времени (и ошибок). Вы можете более легко и точно определить прибыльные сегменты, если у вас есть надлежащие данные и они доступны, когда вам это нужно.
Однако он не может принимать за вас решение о том, следует ли использовать этот сегмент. Вам все равно придется взвесить все за и против, затраты и выгоды.
Однако, к счастью, процесс идентификации и группировки сегментов никогда не был таким простым, как никогда не было проще предоставлять и управлять множеством различных впечатлений. Инструмент автоматизации маркетинга можно подключить к вашему источнику данных или CRM. Вы можете управлять и предоставлять неограниченные персонализированные возможности по любому каналу, который вы хотите — платная реклама, социальные сети, Интернет, push-уведомления, электронная почта и т. д.
Это прекрасное время, чтобы быть маркетологом, управляемым данными.
 i Источник изображения: WebEngage
i Источник изображения: WebEngageИспользуйте возможности автоматизации для своего бизнеса
С функциями предиктивной сегментации и качественной поддержкой клиентов!