
Segmentation prédictive : Premiers pas avec la véritable personnalisation basée sur les données
Publié: 2021-12-30Comme le dit Avinash Kaushik, "Toutes les données agrégées sont de la merde." La segmentation et la personnalisation basée sur les données font partie des outils les plus puissants dont disposent les spécialistes du marketing et les chefs de produit.
Au lieu de traiter chaque visiteur ou utilisateur de la même manière, vous pouvez proposer des expériences basées sur les caractéristiques comportementales, psychographiques, démographiques et firmographiques uniques de vos utilisateurs.
À ce stade, je pense que tout le monde est convaincu par l'idée de segmentation, ainsi que par son extension logique - la personnalisation.
En fait, selon une étude d'Evergage, "92 % des spécialistes du marketing ont déclaré utiliser des techniques de personnalisation dans leur marketing, mais 55 % des spécialistes du marketing estiment ne pas disposer de suffisamment de données client pour mettre en œuvre une personnalisation efficace".
La théorie derrière la segmentation et la personnalisation est souvent plus rose que la réalité de son exécution. En réalité, vous avez besoin de trois composants de base pour faire fonctionner un programme de personnalisation.
Cet article passera en revue ces éléments essentiels, puis j'expliquerai la différence entre la segmentation traditionnelle et la segmentation prédictive (pilotée par l'apprentissage automatique).
- Qu'est-ce que la segmentation prédictive ?
- Règles de données, de contenu et de ciblage : les bases de la personnalisation
- Données
- Teneur
- Logique de ciblage
- Segmentation prédictive vs logique métier
- Segmentation de la logique métier
- Personnalisation basée sur l'opinion
- Segmentation post-test
- Analyse exploratoire des données et corrélations
- Segmentation prédictive
- Regroupement
- Classification
- Expérimentation + Segmentation prédictive
- Comment démarrer avec la personnalisation basée sur les données
- Première étape : marcher
- Deuxième étape : courir
- Troisième étape : Voler
À la fin de cet article, vous aurez une bonne idée de la façon de mettre en œuvre la personnalisation basée sur les données et la segmentation prédictive.
Tout d'abord, qu'est-ce que la « segmentation prédictive » ?
La segmentation, à un niveau élevé, est le processus de division de quelque chose en parties ou sections distinctes.
Source : CXL
Lorsque nous parlons de «segmentation», nous entendons généralement «segmentation du marché» ou «segmentation de la clientèle», ou peut-être «segmentation comportementale». Ce type de segmentation est le processus d'identification et de définition des caractéristiques qui distinguent un sous-groupe ou une section de clients de l'autre.
Cela se fait généralement via la logique métier. Par exemple, nous pourrions dire que les utilisateurs d'appareils mobiles constituent un segment distinct des utilisateurs d'ordinateurs de bureau. Ou plus communément, nous pouvons regrouper les visiteurs par représentation géographique : utilisateurs NAM vs EMEA.
La segmentation prédictive consiste à identifier des clusters d'utilisateurs par programmation ou à l'aide de l'apprentissage automatique. En savoir plus - via @webengage Cliquez pour tweeterDans cette méthode, vous avez généralement un objectif ou un résultat que vous suivez, et vous pouvez revenir en arrière pour identifier les caractéristiques communes que les sous-groupes partagent par rapport à cet objectif.
Par exemple, vous pouvez suivre les "conversions d'inscription à la liste de diffusion" sur votre blog. La segmentation prédictive peut découvrir qu'il existe des groupes distincts qui se comportent de manière cohérente lors de la visite de votre blog.
Un groupe de visiteurs mobiles a tendance à passer très peu de temps sur le site et à rebondir à un rythme élevé. Un autre groupe de visiteurs de bureau provenant de canaux organiques passe très peu de temps et rebondit à un rythme tout aussi élevé.
Vous pouvez découvrir ces segments par vous-même en utilisant l'analyse des données, mais les outils de segmentation prédictive cherchent à identifier et à regrouper ces segments d'utilisateurs. Habituellement, des outils comme celui-ci essaient de prédire les actions que ces segments prendront afin que vous puissiez déclencher des règles de personnalisation.
Règles de données, de contenu et de ciblage : les bases de la personnalisation
Pour proposer avec succès des expériences personnalisées à différents segments d'utilisateurs, vous avez besoin de trois éléments :
- Données
- Teneur
- Logique de ciblage
1. Données
Les données sous-tendent tout en matière de segmentation et de personnalisation.
Si vous ne disposez pas des données dont vous avez besoin au moment où vous en avez besoin, vous ne pouvez pas identifier les segments d'utilisateurs et encore moins déclencher des expériences personnalisées pour eux. De plus, si vos données sont imprécises et/ou incomplètes, votre personnalisation peut être inefficace.
Par conséquent, avant de faire une segmentation, confirmez ces trois choses :
- Mesurez-vous tout ce dont vous avez besoin ? Avez-vous des objectifs correctement configurés, des dimensions personnalisées, etc. ? Vos données sont-elles « complètes » ?
- Vos données sont-elles fiables ? Il n'a pas besoin d'être 100 % "précis", mais est-il cohérent et précis dans son journalisation ?
- Vos données sont-elles accessibles quand vous en avez besoin ? Combien de nettoyage et de préparation devez-vous faire pour tirer des enseignements de vos données ? Est-il agrégé et connecté à d'autres sources (réseaux sociaux, web, e-mail, données clients) ? Est-il stocké dans un endroit qui peut être utilisé et analysé immédiatement ?
De plus, vous souhaiterez connecter vos sources de données à une table de stockage centralisée. De nos jours, les plateformes de données client (CDP) telles que Hull.io et Segment sont le nom du jeu, mais vous pouvez également utiliser des CRM comme HubSpot pour centraliser, stocker et opérationnaliser vos données marketing et client.
Celles-ci deviennent importantes lorsque vous connectez vos données de pré-achat à vos données de post-achat. Cela vous permet d'identifier les segments en fonction de mesures commerciales importantes telles que leur valeur de durée de vie prévue ou leur taux de désabonnement.
2. Contenu
La partie contenu est beaucoup plus facile à comprendre.
Essentiellement, si vous souhaitez faire de la personnalisation, vous définissez d'abord un segment d'utilisateurs à l'aide de vos sources de données. Ensuite, vous devez également créer une nouvelle expérience à offrir à ce segment.
La création de nouveaux contenus ou expériences nécessite des ressources, à la fois en termes de temps et d'argent. De plus, plus vous diffusez et gérez de contenus et d'expériences, plus vous augmentez la complexité de votre organisation.
Matt Gershoff, PDG de Conductrics, a fait une excellente analogie dans le podcast Digital Analytics Power Hour à ce sujet.
Il a décrit la personnalisation comme créant essentiellement un multivers.
Exécuter une version de votre site Web pour tout le monde, c'est comme avoir un univers, et peut-être qu'un test A/B vous permet d'exécuter un contrefactuel pour voir à quoi ressemblerait la vie dans un univers parallèle (ou "version B").
Dans un test A/B, vous voulez voir si la version B est un meilleur "univers" pour vos visiteurs tel que défini par votre objectif de conversion, et si vous trouvez qu'il est effectivement optimal, vous fermez l'univers A (l'original) et encore réintégrer un univers singulier.
Cependant, plusieurs variantes de contenu fournies à plusieurs segments uniques revient à garder ouverts plusieurs univers distincts dans lesquels les expériences sont uniques à ces segments.
La magie de cela est que vous pouvez augmenter la valeur de votre site Web en augmentant la valeur de chaque segment individuel et leur expérience, mais vous pouvez comprendre à quel point l'ouverture de milliers d '«univers» serait coûteuse à la fois en termes de création et de gestion de tous ces expériences.
3. Logique de ciblage
Enfin, si vous disposez de données et de ressources utiles pour créer du contenu, vous devez déterminer comment vous déclenchez exactement la logique de ciblage ou de personnalisation pour les segments d'utilisateurs.
C'est ainsi que vous reliez les données aux expériences.
Vous pouvez utiliser la logique métier (en supposant que certains segments doivent avoir certaines valeurs - vous pouvez même les tester A/B), ou vous pouvez introduire l'apprentissage automatique et la segmentation prédictive/RFM pour classer vos utilisateurs en différents groupes - les utilisateurs les plus précieux, sur le point de se désabonner. utilisateurs, utilisateurs dormants, etc. En utilisant la segmentation RFM, vous pouvez également savoir quels segments d'utilisateurs réagissent de manière plus variable à quelles expériences de contenu.
Techniquement, pour cette étape, vous avez besoin d'un système de diffusion de contenu qui est soit connecté à votre base de données, soit qui peut s'intégrer et s'extraire de votre base de données. WebEngage est un système d'exploitation complet d'automatisation et de rétention du marketing qui peut se connecter de manière transparente à votre CRM et vous aider à engager vos utilisateurs sur une base individuelle sur des canaux tels que les e-mails, SMS, WhatsApp, Facebook, Mobile & Web Push, etc.
Encore une fois, cependant, plus vous déclenchez de règles de ciblage, plus le système que vous construisez est complexe. Il existe donc un compromis entre le retour sur investissement que vous pouvez exploiter en ciblant un segment donné et la complexité marginale introduite dans le système. Il est facile de fusionner les prénoms avec des jetons d'e-mail personnalisés (la plupart des outils de messagerie le font maintenant), mais cela ne vous indique pas le retour sur investissement de cette règle de ciblage.
Source : G Mass
C'est pourquoi, au lieu de simplement mettre en place des tonnes de personnalisation juste parce que vous le pouvez, vous devriez l'examiner de manière stratégique et méthodologique, en déterminant le retour sur investissement et l'efficacité du ciblage d'un segment donné.
Segmentation prédictive vs logique métier
J'ai déjà laissé tomber un peu de jargon en ce qui concerne la logique de ciblage - comme la "logique métier" et la "segmentation prédictive".
La logique métier se situe essentiellement de l'autre côté du spectre de la « personnalisation basée sur les données », de la « segmentation prédictive » ou de la « personnalisation basée sur l'apprentissage automatique ». Mais ces deux méthodes ont le même objectif : identifier les segments à traiter avec des expériences personnalisées.
Définissons ces deux pôles et leurs différences.
Segmentation de la logique métier
La « logique métier » est la méthode habituelle par laquelle les gens choisissent les règles de ciblage. Dans cette méthode, vous décidez essentiellement quels segments ont les opportunités d'impact les plus élevées en utilisant des données historiques et des corrélations ou une logique métier, une stratégie ou des opinions. Il existe trois façons principales de dériver des règles de ciblage de logique métier :
- Personnalisation basée sur l'opinion
- Segmentation post-test
- L'analyse exploratoire des données
1. Personnalisation basée sur l'opinion
Par exemple, vous pouvez simplement vouloir éviter de déclencher un popup invasif sur mobile pour des raisons purement subjectives. Ce n'est pas une bonne expérience utilisateur, donc vous l'évitez. Vous n'avez même pas besoin de données pour prédire la réaction de ce segment.
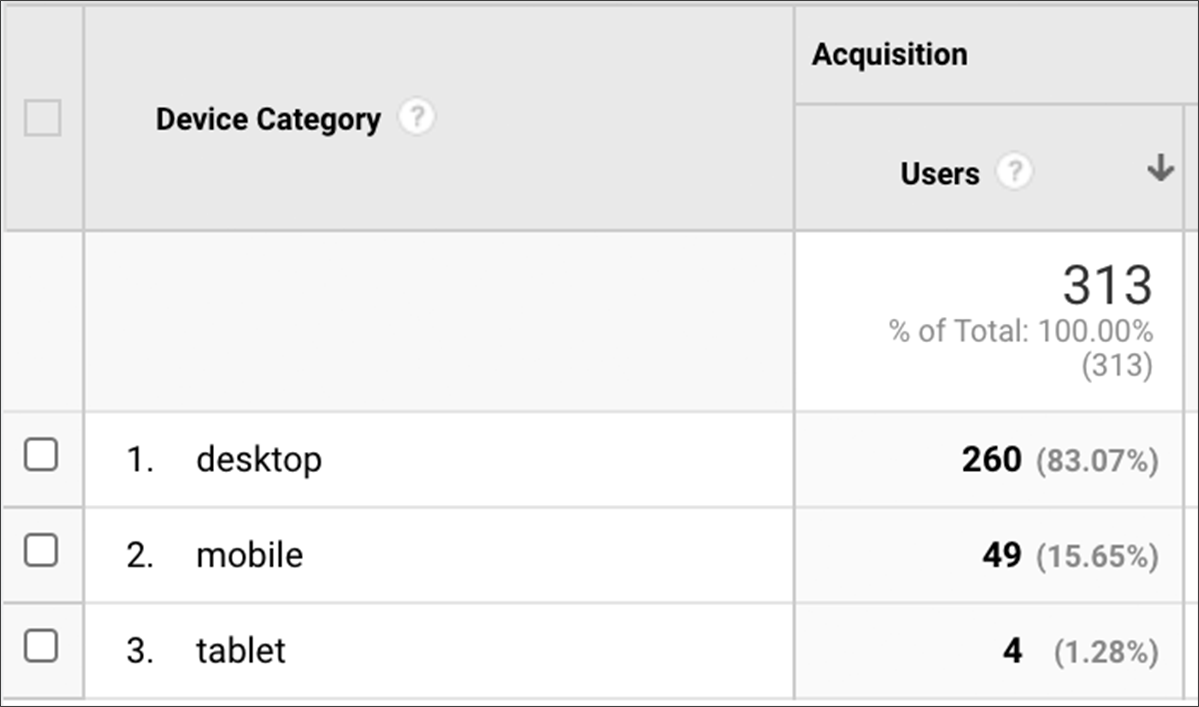
Traiter différemment les utilisateurs mobiles est une utilisation courante de la personnalisation
C'est la méthode que la grande majorité des entreprises utilisent lorsqu'elles disent faire de la segmentation ou de la personnalisation basée sur les données. Ils devinent arbitrairement quel segment répondra favorablement à quelle expérience et le personnalisent en fonction de leur opinion.
2. Segmentation post-test
Moins courant (mais plus efficace), cependant, est de mener une expérience, puis de faire une analyse post-test pour déterminer si certaines variations ont des zones d'impact plus élevées sur certains segments.
Imaginez que vous exécutez un test sur un flux de paiement de commerce électronique.
Vous décidez de tester plusieurs variantes - une variante avec une série de symboles de confiance et de sécurité, une avec une fenêtre contextuelle qui utilise des messages d'urgence et une sans symboles (la version originale).
Après avoir analysé l'expérience, vous avez déterminé que la version B a "gagné" et qu'elle a une amélioration estimée à 10 %. Une grande victoire.
Cependant, vous explorez les données et examinez les segments à fort impact, tels que les visiteurs mobiles par rapport aux ordinateurs de bureau, les visiteurs récurrents par rapport aux nouveaux visiteurs et les visiteurs américains par rapport aux visiteurs non américains.
Ce faisant, vous avez découvert que les utilisateurs d'iPhone convertissaient en fait 35 % mieux sur la variante B. Les utilisateurs d'iPhone représentent un pourcentage substantiel de votre audience, soit environ 25 % de tous les visiteurs. Cela signifie que déclencher une expérience personnalisée pour ce segment pourrait être intéressant et avoir un retour sur investissement positif.

De plus, les utilisateurs d'Android ont en fait converti 20 % de moins sur la variante B et 15 % de plus que le contrôle sur la variante C. Les utilisateurs d'Android représentent 10 % de votre audience, donc encore une fois, une population assez importante.
Vous pouvez donc simplement lancer la variante B car elle a gagné au total. Ou bien, vous pouvez configurer des règles de ciblage pour inciter les utilisateurs d'iPhone à recevoir la variante B et les utilisateurs d'Android à recevoir la variante C. Tous les autres reçoivent l'original.
3. Analyse exploratoire des données et corrélations
La dernière façon d'utiliser la « logique métier » pour la segmentation consiste simplement à explorer les données auxquelles vous avez accès et à rechercher des corrélations entre les caractéristiques du segment et la probabilité de conversion.
Vous pouvez constater, par exemple, que les utilisateurs d'iPhone convertissent plus. Ou les personnes qui regardent une vidéo sur votre page d'accueil. Ou des utilisateurs masculins d'Android du Kansas qui ont rempli la moitié des champs de votre formulaire et sont revenus 3 fois en une semaine.
Voici le problème avec cette approche : examinez suffisamment de segments et vous trouverez une corrélation. C'est un problème signal vs bruit.
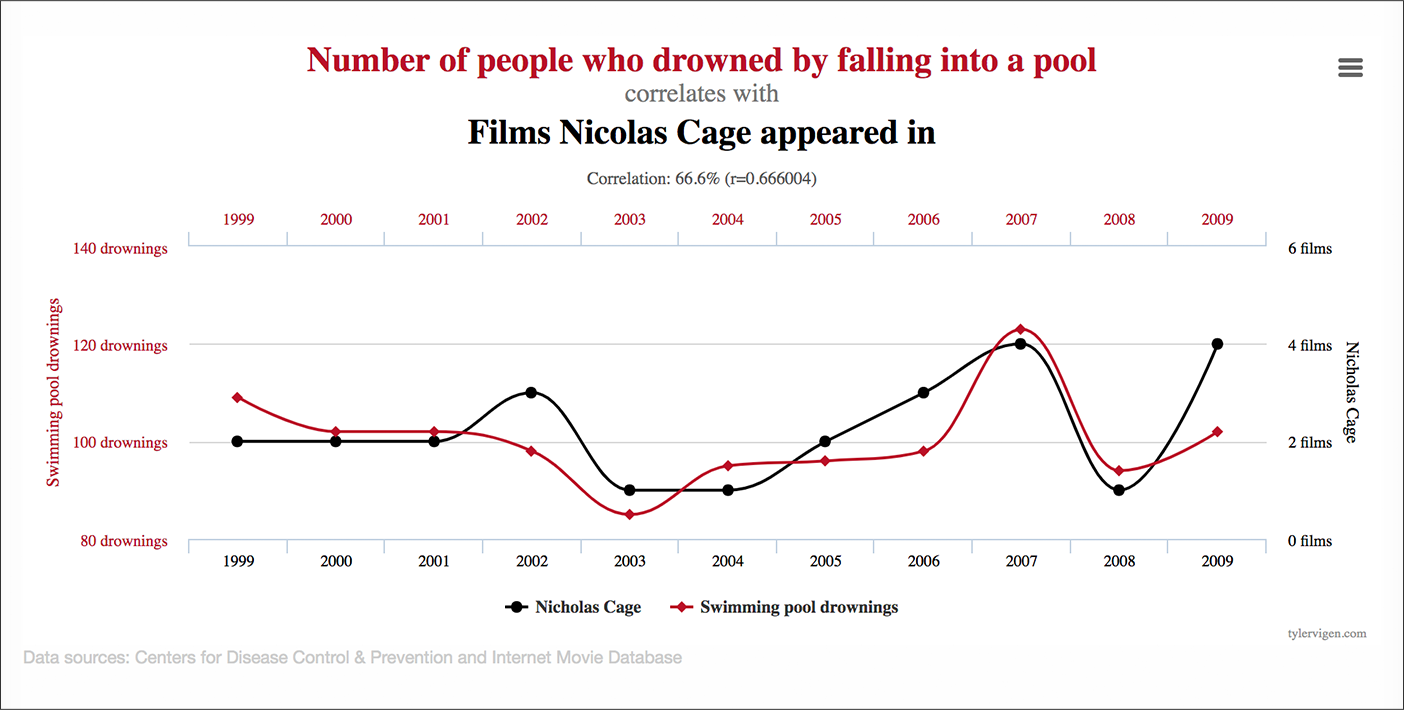
Source : Tyler Vigen
Le plus gros problème avec cette approche est que la corrélation n'implique pas de causalité.
Ce n'est pas parce qu'un visiteur de retour sur ordinateur de Californie convertit plus que cela qu'il s'agit d'un segment qui mérite d'être ciblé via la personnalisation basée sur les données.
Votre meilleur pari dans le monde de la logique métier est d'effectuer des expériences et de découvrir des segments de grande valeur via une segmentation post-test. Ensuite, vous calculez le retour sur investissement d'une règle de ciblage donnée et exécutez une expérience de suivi ciblant uniquement ce segment.
Vous pouvez ensuite démêler la causalité et le véritable retour sur investissement du maintien de cette règle de ciblage. Pour plus d'informations sur cette approche, lisez la merveilleuse procédure pas à pas d'Andrew Anderson sur le sujet.
Segmentation prédictive
La segmentation prédictive (ou sous un autre nom, la segmentation « data-driven » ou « AI-based ») vise à supprimer l'intuition humaine et l'analyse manuelle des données de la définition des segments et de la mise en place des règles de ciblage.
Il existe plusieurs façons de définir des segments à l'aide de l'apprentissage automatique. Cela dépend simplement de vos objectifs et de ce que vous espérez accomplir avec ces segments. Ici, nous allons couvrir trois méthodes clés :
- Regroupement
- Classification
- Expérimentation + mutualisation prédictive
1. Regroupement
Tout d'abord, si vous souhaitez simplement identifier et comprendre différentes personnalités ou segments d'utilisateurs, les algorithmes de clustering (ou apprentissage automatique non supervisé) sont une technique utilisée pour regrouper des segments en fonction de caractéristiques communes.
C'est quelque chose sur lequel j'ai travaillé à l'Institut CXL il y a quelques années.
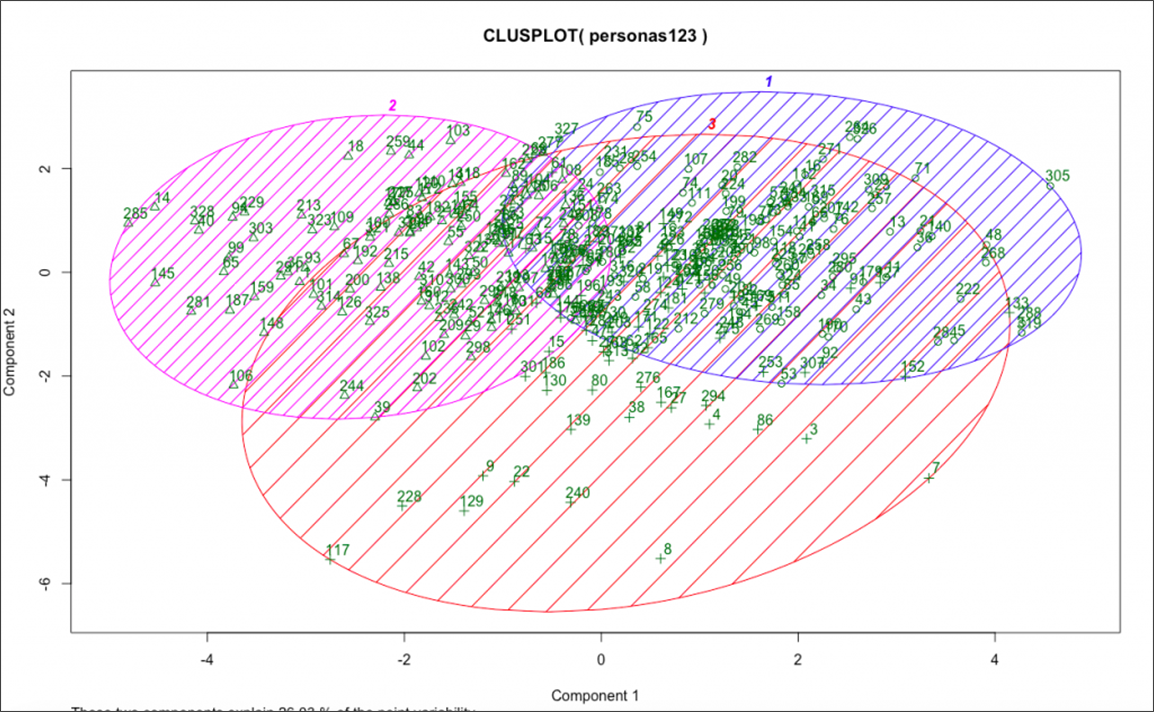
Source : CXL
Nous avons envoyé des sondages à notre clientèle avec un mélange de réponses d'échelle, de variables catégorielles et de questions ouvertes. J'ai ensuite codifié leurs réponses et exécuté l'algorithme de clustering K Means sur eux.
Cela a identifié environ trois segments distincts en fonction de leurs réponses. J'ai ensuite superposé les informations qualitatives de chacun de ces segments et interrogé des personnes hautement représentatives de chaque segment. Cela nous a permis de comprendre en profondeur notre clientèle existante et leurs différents désirs, défis et comportements.
Si vous voulez faire du clustering, sachez que c'est surtout exploratoire et pour l'acquisition de connaissances. Il ne vous indiquera pas le retour sur investissement de l'envoi de communications marketing personnalisées à l'un de ces segments, ni quels segments sont susceptibles de répondre à quelles expériences. Par exemple, vous pouvez constater qu'un certain segment d'abonnés aux e-mails ouvre plus d'e-mails et a une valeur à vie plus élevée, mais vous devez toujours faire le travail créatif d'idéation de nouveaux contenus et expériences à tester.
Mais c'est une bonne couche de base pour commencer avec la personnalisation basée sur les données.
Vous aurez également besoin d'un analyste décent qui peut coder R ou Python ou au moins un outil comme Squark qui permet une analyse prédictive sans code.
2. Classement
L'apprentissage automatique a tendance à être délimité entre l'apprentissage supervisé et non supervisé. Là où les algorithmes de clustering ne sont pas supervisés, les algorithmes de classification sont supervisés.
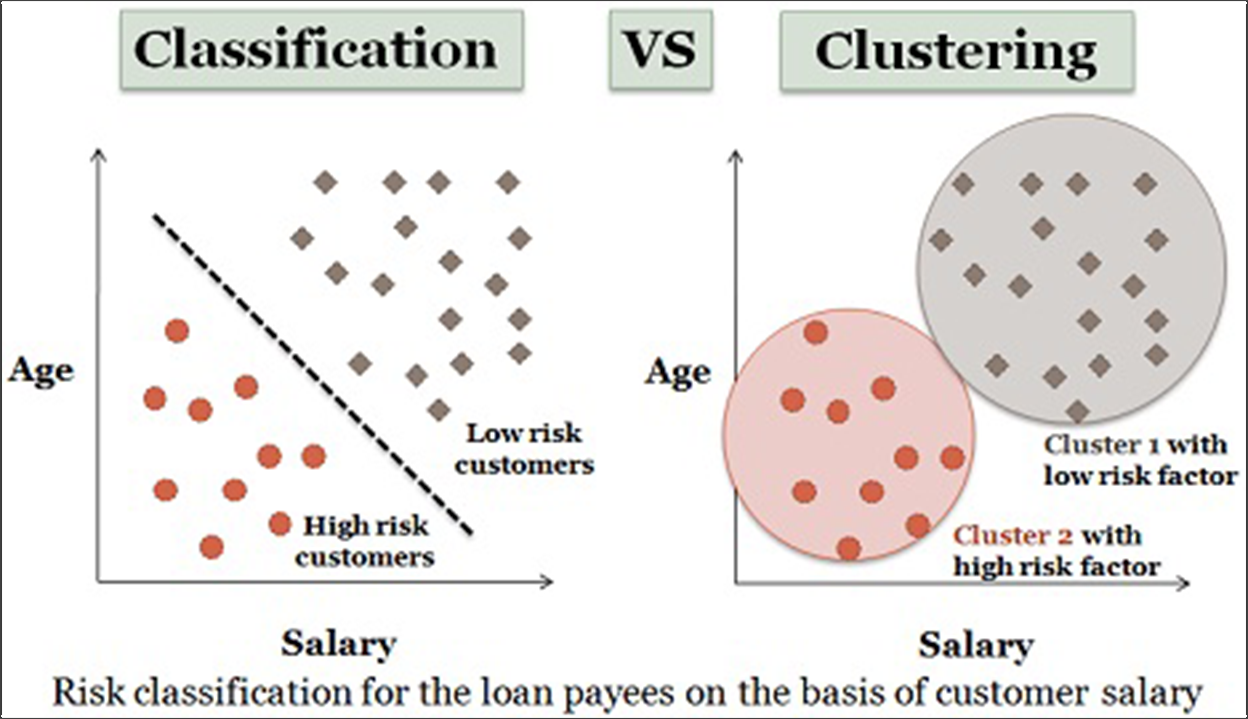
Source : Différences technologiques
Cela signifie que vous disposez d'un ensemble de données qui comprend diverses "caractéristiques" (dans notre cas, il peut s'agir du type d'appareil, des pages visitées, de la taille de l'entreprise ou de toute caractéristique que nous pouvons collecter sur les visiteurs), puis vous avez des résultats que vous souhaitez prédire (dans notre cas, les conversions ou les revenus ou la LTV).
Il existe une quantité massive de méthodologies et d'algorithmes qui tentent de prédire les résultats en fonction des caractéristiques des données, dont certaines incluent des régressions linéaires, des régressions logistiques, des forêts aléatoires et des réseaux de neurones.
Si vous souhaitez utiliser cette méthode, vous aurez besoin d'un excellent analyste capable d'adapter correctement un modèle à vos données (sinon les prédictions sont inutiles), ou d'acheter un outil comme Squark ou DataRobot. Ces outils permettent aux analystes et aux hommes d'affaires d'adapter différents modèles à leurs données et de prédire les résultats sans coder eux-mêmes les algorithmes.
3. Expérimentation + Segmentation prédictive
Souvent, la meilleure façon de trouver des segments d'utilisateurs lucratifs consiste à suivre votre cours normal d'expérimentation contrôlée et à utiliser un outil (ou une méthode d'analyse) qui détecte les segments prometteurs.
Conductrics, par exemple, vous montre un arbre de décision hautement interprétable qui calcule les probabilités de réussite de la conversion pour les segments individuels qui correspondent à chaque variante que vous avez testée.
Des points bonus si votre outil de ciblage prédictif dispose d'une visualisation de données qui vous montre, dans des illustrations simples, les règles de ciblage que vous avez configurées, ainsi que le retour sur investissement estimé et la probabilité de réussite de ces règles.

Source : Conductrices
C'est cool parce que non seulement vous obtenez la probabilité de succès, mais vous pouvez choisir de cibler ou non ce segment en fonction de sa valeur.
Les androïdes masculins reviennent des visiteurs du Kentucky rural ? Cela ne vaut peut-être pas la peine de configurer une nouvelle règle de ciblage. Mais peut-être vaut-il la peine de cibler les Californiens s'ils constituent une population nombreuse et réagissent très favorablement à une expérience donnée.
Comment démarrer avec la personnalisation basée sur les données
Bien qu'il puisse être tentant de plonger dans les profondeurs de la personnalisation basée sur les données, je recommande de commencer lentement.
On ne sait pas quelle est la valeur réelle d'une règle de personnalisation donnée, et souvent les rendements marginaux d'une personnalisation accrue sont inférieurs au coût de complexité marginal introduit.
Par conséquent, je vais vous présenter trois approches de personnalisation d'une complexité croissante (et supposons que l'étape de "crawl" ne consiste qu'à mettre de l'ordre dans vos données et les ressources/outils nécessaires pour offrir des expériences personnalisées).
Première étape : marcher
Par conséquent, avant d'investir dans un outil de ciblage prédictif, vous voudrez peut-être utiliser la méthodologie d'Andrew Anderson, qui peut être une simple continuation de votre programme d'expérimentation normal (note complémentaire : vous n'avez pas de trafic pour les expérimentations ? La personnalisation n'est pas pour vous). les rendements marginaux n'en vaudront pas la peine à ce niveau de trafic.
Voici l'essentiel de la méthodologie :
- Créer plusieurs exécutions du message ou de l'expérience
- Servir toutes les offres à tout le monde via une expérience contrôlée
- Regardez les résultats par segment et calculez le gain total en donnant une expérience différenciée. Assurez-vous de corriger les comparaisons multiples lors de l'analyse de nombreux segments.
- Mettez en ligne l'opportunité la plus génératrice de revenus trouvée (ou exécutez une expérience de suivi uniquement sur ce segment avec les expériences que vous avez testées sur l'ensemble de l'audience).
Vous pouvez utiliser des plateformes de test A/B dédiées ou vous pouvez utiliser une plateforme d'automatisation du marketing intégrée. Ce dernier vous aidera à personnaliser les messages sur plusieurs canaux, pas seulement sur le Web ou l'application, et vous pourrez proposer des recommandations de produits personnalisées, augmenter vos revenus et CLTV, améliorer la découverte de contenu/produit, et bien plus encore.
Deuxième étape : courir
Après avoir obtenu quelques victoires ici, vous voudrez peut-être investir dans une solution d'analyse prédictive sans code comme Squark (ou si vous pouvez coder les algorithmes en interne, par tous les moyens). Le processus de base ressemble à ceci :
Déterminez vos indicateurs de réussite
Collectez et nettoyez vos données, en divisant votre ensemble de données en données d'entraînement et de test.
Assurez-vous d'avoir une myriade de dimensions ou de caractéristiques dans vos données qui peuvent être utilisées pour prédire le résultat.
Déterminez quelles fonctionnalités sont prédictives de vos mesures de réussite.
Calculez le retour sur investissement de la personnalisation des expériences pour ces segments. Encore une fois, si la population est trop petite, cela n'en vaut peut-être pas la peine.
Maintenant, la partie importante : une fois que vous avez défini une caractéristique ou une dimension qui est prédictive du succès (disons qu'il s'agit de visiteurs récurrents), vous n'avez toujours pas déterminé quelles expériences sont les plus susceptibles de fonctionner sur ce segment.
Il reste encore beaucoup à faire : c'est-à-dire créer de nouvelles expériences formidables et mener des expériences pour déterminer l'efficacité et le retour sur investissement de vos nouvelles expériences.
Vous voudrez toujours investir dans une solution de diffusion de contenu ici comme WebEngage afin de cibler des segments spécifiques.
Troisième étape : Voler
Enfin, si vous souhaitez intégrer le ciblage prédictif dans votre flux de travail normal d'expérimentation et d'optimisation, vous ne pouvez pas battre un outil comme Conductrics ou Dynamic Yield. Ces outils vous aideront à identifier les segments et à offrir des expériences personnalisées tout en vous fournissant des règles de décision interprétables et des rapports d'attribution du retour sur investissement.
Conclusion
Dans un monde dominé par les gros titres et les conférences sur l'intelligence artificielle comme solution miracle, vous pourriez être surpris d'apprendre que le processus de « personnalisation basée sur les données » ou de « segmentation prédictive » ne fait pas tout le travail à votre place.
Cela peut vous aider à exploiter vos données et à économiser beaucoup de temps (et d'erreurs). Vous pouvez identifier plus facilement et plus précisément les segments lucratifs, tant que vous disposez des données appropriées et qu'elles sont accessibles lorsque vous en avez besoin.
Cependant, il ne peut pas décider à votre place de tirer parti ou non de ce segment. Vous devrez toujours peser le pour et le contre, les coûts et les avantages.
Heureusement, cependant, le processus d'identification et de regroupement des segments n'a jamais été aussi facile, et il n'a jamais été aussi facile de fournir et de gérer plusieurs expériences différentes. Un outil d'automatisation du marketing peut être connecté à votre source de données ou à votre CRM. Vous pouvez gérer et proposer des expériences personnalisées illimitées via n'importe quel canal de votre choix - publicités payantes, réseaux sociaux, Web, push, e-mail, etc.
C'est le moment idéal pour être un spécialiste du marketing axé sur les données.
 i Source de l'image : WebEngage
i Source de l'image : WebEngageTirez parti de la puissance de l'automatisation pour votre entreprise
Avec des fonctionnalités de segmentation prédictive et un support client de qualité !