
予測セグメンテーション:真のデータ駆動型パーソナライズ入門
公開: 2021-12-30Avinash Kaushikが言うように、「全体としてのすべてのデータはがらくたです。」 セグメンテーションとデータ駆動型のパーソナライズは、マーケターと製品マネージャーが自由に使える最も強力なツールの一部です。
すべての訪問者またはユーザーを同じように扱う代わりに、ユーザーの固有の行動、サイコグラフィック、人口統計、および企業の特性に基づいてエクスペリエンスを提供できます。
この時点で、誰もがセグメンテーションのアイデアとその論理的な拡張パーソナライズに夢中になっていると思います。
実際、Evergageの調査によると、「マーケターの92%は、マーケティングでパーソナライズ手法を使用していると報告していますが、マーケターの55%は、効果的なパーソナライズを実装するのに十分な顧客データを持っていないと感じています。」
セグメンテーションとパーソナライズの背後にある理論は、多くの場合、その実行の現実よりもバラ色です。 実際には、パーソナライズプログラムを機能させるには、3つのコアコンポーネントが必要です。
この記事では、これらの主要な要素について説明し、次に、従来のセグメンテーションと予測セグメンテーション(機械学習によって駆動される)の違いについて説明します。
- 予測セグメンテーションとは何ですか?
- データ、コンテンツ、およびターゲティングルール:パーソナライズの基本
- データ
- コンテンツ
- ターゲティングロジック
- 予測セグメンテーションとビジネスロジック
- ビジネスロジックセグメンテーション
- 意見主導のパーソナライズ
- テスト後のセグメンテーション
- 探索的データ分析と相関
- 予測セグメンテーション
- クラスタリング
- 分類
- 実験+予測セグメンテーション
- データドリブンパーソナライズを開始する方法
- ステージ1:歩く
- ステージ2:実行
- ステージ3:飛ぶ
この記事の終わりまでに、データ駆動型のパーソナライズと予測セグメンテーションを実装する方法についての良いアイデアが得られます。
まず、「予測セグメンテーション」とは何ですか?
セグメンテーションは、大まかに言えば、何かを別々の部分またはセクションに分割するプロセスです。
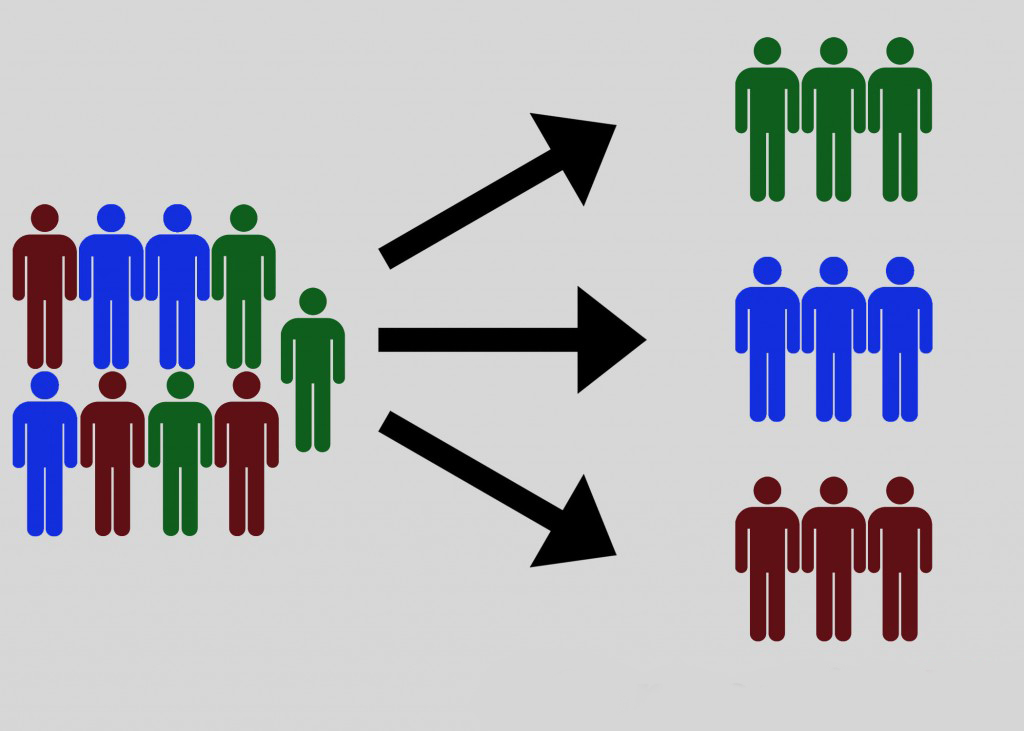
出典:CXL
「セグメンテーション」とは、通常、「市場セグメンテーション」または「顧客セグメンテーション」、あるいは「行動セグメンテーション」を意味します。 このタイプのセグメンテーションは、顧客の1つのサブグループまたはセクションを他のサブグループまたはセクションから区別する特性を識別および定義するプロセスです。
これは通常、ビジネスロジックを介して行われます。 たとえば、モバイルデバイスユーザーはデスクトップユーザーとは別のセグメントであると言えます。 または、より一般的には、訪問者を地理的表現(NAMユーザーとEMEAユーザー)でグループ化できます。
予測セグメンテーションは、プログラムで、または機械学習を使用してユーザークラスターを識別する場合です。 続きを読む-@webengage経由クリックしてツイートこの方法では、通常、追跡している目標または結果があり、逆方向に作業して、この目標に関連してサブグループが共有する共通の特性を特定できます。
たとえば、ブログで「メールリストの登録コンバージョン」を追跡できます。 予測セグメンテーションは、ブログにアクセスしたときに一貫して動作する別個のグループがあることを発見する場合があります。
モバイルビジターの1つのグループは、サイトにほとんど時間を費やさず、高い割合でバウンスする傾向があります。 有機チャネルからのデスクトップ訪問者の別のグループは、ほとんど時間を費やさず、同様に高い割合でバウンスします。
データ分析を使用してこれらのセグメントを自分で発見することもできますが、予測セグメンテーションツールは、これらのユーザーセグメントを識別してクラスター化しようとします。 通常、このようなツールは、これらのセグメントが実行するアクションを予測しようとするため、パーソナライズルールをトリガーできます。
データ、コンテンツ、およびターゲティングルール:パーソナライズの基本
パーソナライズされたエクスペリエンスをさまざまなユーザーセグメントに正常に提供するには、次の3つのコンポーネントが必要です。
- データ
- コンテンツ
- ターゲティングロジック
1.データ
セグメンテーションとパーソナライズに関しては、データがすべてを支えています。
必要なときに必要なデータがない場合、ユーザーセグメントを特定することはできず、パーソナライズされたエクスペリエンスをトリガーすることもできません。 さらに、データが不正確または不完全である場合、パーソナライズは効果がない可能性があります。
したがって、セグメンテーションを実行する前に、次の3つのことを確認してください。
- 必要なものすべてを測定していますか? 目標が適切に設定されているか、カスタムディメンションなどがありますか? あなたのデータは「完全」ですか?
- あなたのデータは信頼できますか? 100%「正確」である必要はありませんが、ロギングで一貫性があり正確ですか?
- 必要なときにデータにアクセスできますか? データから洞察を引き出すために、どのくらいのクリーニングと準備を行う必要がありますか? 集約され、他のソース(ソーシャル、Web、電子メール、顧客データ)に接続されていますか? すぐに使用・分析できる場所に保管されていますか?
さらに、データソースを一元化されたストレージテーブルに接続する必要があります。 現在、Hull.ioやSegmentなどのカスタマーデータプラットフォーム(CDP)がゲームの名前ですが、HubSpotなどのCRMを使用して、マーケティングおよび顧客データを一元化、保存、運用することもできます。
これらは、購入前のデータを購入後のデータに接続するときに重要になります。 これにより、予測される生涯価値や解約率などの重要なビジネス指標に基づいてセグメントを特定できます。
2.コンテンツ
コンテンツ部分は、はるかに簡単に理解できます。
基本的に、パーソナライズを行う場合は、最初にデータソースを使用してユーザーセグメントを定義します。 次に、そのセグメントに提供する新しいエクスペリエンスを作成する必要もあります。
新しいコンテンツやエクスペリエンスを作成するには、時間とお金の両面でリソースが必要です。 さらに、提供および管理するコンテンツとエクスペリエンスが多いほど、組織内で複雑さが増します。
ConductricsのCEOであるMattGershoffは、これについてDigital AnalyticsPowerHourポッドキャストで優れたアナロジーを示しました。
彼は、パーソナライズを本質的に多元宇宙を作成するものとして説明しました。
Webサイトの1つのバージョンをすべての人に実行することは、1つのユニバースを持つようなものです。おそらく、A / Bテストを使用すると、カウンターファクトを実行して、パラレルユニバース(または「バージョンB」)での生活がどのようになるかを確認できます。
A / Bテストでは、バージョンBが目標変換によって定義された訪問者にとってより良い「ユニバース」であるかどうかを確認し、それが本当に最適であることがわかった場合は、ユニバースA(元の)を閉じてからもう一度実行します。特異な宇宙に再び入る。
ただし、複数の固有のセグメントに配信される複数のコンテンツバリアントは、エクスペリエンスがそれらのセグメントに固有であるいくつかの異なるユニバースを開いたままにするようなものです。
これの魔法は、個々のセグメントとその経験の価値を高めることでWebサイトの価値を高めることができることですが、それらすべての作成と管理の両方の観点から、何千もの「ユニバース」を開くにはコストがかかることを理解できます。経験。
3.ターゲティングロジック
最後に、コンテンツを作成するための有用なデータとリソースがある場合は、ユーザーセグメントに対してターゲティングまたはパーソナライズロジックをどの程度正確にトリガーするかを決定する必要があります。
これは、データとエクスペリエンスを結び付ける方法です。
ビジネスロジックを使用できます(特定のセグメントに特定の値が必要であると想定します。A/ Bテストも可能です)。または、機械学習と予測セグメンテーション/ RFMを導入して、ユーザーをさまざまなグループに分類できます。最も価値のあるユーザーは、解約しようとしています。ユーザー、休止中のユーザーなど。RFMセグメンテーションを使用すると、どのユーザーセグメントがどのコンテンツエクスペリエンスに対してより多様に応答するかを知ることもできます。
技術的には、このステップでは、データベースに接続されているか、データベースを統合してプルできるコンテンツ配信システムが必要です。 WebEngageは、フルスタックのマーケティング自動化および保持オペレーティングシステムであり、CRMとシームレスに接続し、電子メール、SMS、WhatsApp、Facebook、モバイルおよびWebプッシュなどのチャネル全体でユーザーを1対1で関与させるのに役立ちます。
ただし、トリガーするターゲティングルールが多いほど、構築するシステムは複雑になります。 したがって、特定のセグメントをターゲットにすることで利用できるROIと、システムに導入されるわずかな複雑さにはトレードオフがあります。 名をカスタム電子メールトークンにマージするのは簡単ですが(ほとんどの電子メールツールはすぐにそれを実行します)、それはそのターゲティングルールのROIを教えてくれません。
出典:GMass
そのため、できるという理由だけで大量のパーソナライズを設定するのではなく、戦略的かつ方法論的に検討し、特定のセグメントをターゲットとするROIと効率を判断する必要があります。
予測セグメンテーションとビジネスロジック
「ビジネスロジック」や「予測セグメンテーション」などのターゲティングロジックに関しては、すでにいくつかの専門用語を使用していません。
ビジネスロジックは、基本的に、「データ駆動型のパーソナライズ」、「予測セグメンテーション」、または「機械学習ベースのパーソナライズ」の範囲の反対側にあります。 しかし、これらの方法はどちらも同じ目的を持っています。つまり、パーソナライズされたエクスペリエンスで処理されるセグメントを特定することです。
これらの2つの極とそれらの違いを定義しましょう。
ビジネスロジックセグメンテーション
「ビジネスロジック」は、人々がターゲティングルールを選択する通常の方法です。 この方法では、基本的に、履歴データと相関関係、またはビジネスロジック、戦略、または意見を使用して、どのセグメントが最も影響力のある機会があるかを決定します。 ビジネスロジックのターゲティングルールを導き出すには、主に3つの方法があります。
- 意見主導のパーソナライズ
- テスト後のセグメンテーション
- 探索的データ分析
1.意見主導のパーソナライズ
たとえば、純粋に主観的な理由で、モバイルで侵襲的なポップアップをトリガーすることを単に避けたい場合があります。 それは良いユーザーエクスペリエンスではないので、避けてください。 そのセグメントの反応を予測するためのデータさえ必要ありません。
モバイルユーザーを別の方法で扱うことは、パーソナライズの一般的な使用法です
これは、大多数の企業がセグメンテーションまたはデータ駆動型のパーソナライズを行っていると言うときに使用している方法です。 彼らは、どのセグメントがどの経験に好意的に反応するかを恣意的に推測し、彼らの意見に基づいてそれをパーソナライズします。
2.テスト後のセグメンテーション
ただし、あまり一般的ではありませんが(ただし、より効果的です)、実験を実行してからテスト後の分析を実行して、特定のバリエーションが特定のセグメントに大きな影響を与える領域があるかどうかを判断します。
eコマースのチェックアウトフローでテストを実行していると想像してください。
複数のバリアントをテストすることにしました。1つは一連の信頼とセキュリティのシンボル、もう1つは緊急メッセージを使用するポップアップ、もう1つはシンボルなし(元のバージョン)です。
実験を分析した結果、バージョンBが「勝ち」、推定で10%の上昇があることがわかりました。 素晴らしい勝利。
ただし、データを掘り下げて、モバイルとデスクトップの訪問者、リピーターと新規訪問者、米国からの訪問者と米国以外の訪問者など、影響の大きいセグメントを調べます。
そうすることで、iPhoneユーザーは実際にバリアントBで35%向上していることがわかりました。iPhoneユーザーは、オーディエンスのかなりの割合、つまりすべての訪問者の約25%を占めています。 これは、このセグメントにパーソナライズされたエクスペリエンスをトリガーすることは価値があり、ROIがプラスになる可能性があることを意味します。

さらに、Androidユーザーは実際にバリアントBで20%低く、バリアントCでコントロールより15%高く変換しました。Androidユーザーはオーディエンスの10%を占めるため、やはりかなり大きな人口です。
したがって、全体として勝ったので、バリアントBを起動するだけで済みます。 または、ターゲティングルールを設定して、iPhoneユーザーがバリアントBを受け取り、AndroidユーザーがバリアントCを受け取るようにすることもできます。他のすべてのユーザーがオリジナルを取得します。
3.探索的データ分析と相関
セグメンテーションに「ビジネスロジック」を使用できる最後の方法は、アクセスできるデータを調べて、セグメントの特性と変換の確率との相関関係を探すことです。
たとえば、iPhoneユーザーの方がコンバージョン率が高いことがわかります。 またはあなたのホームページでビデオを見ている人。 または、フォームフィールドの半分に入力して1週間に3回戻ってきたカンザスの男性Androidユーザー。
このアプローチの問題は次のとおりです。十分なセグメントを見ると、相関関係が見つかります。 これは信号とノイズの問題です。
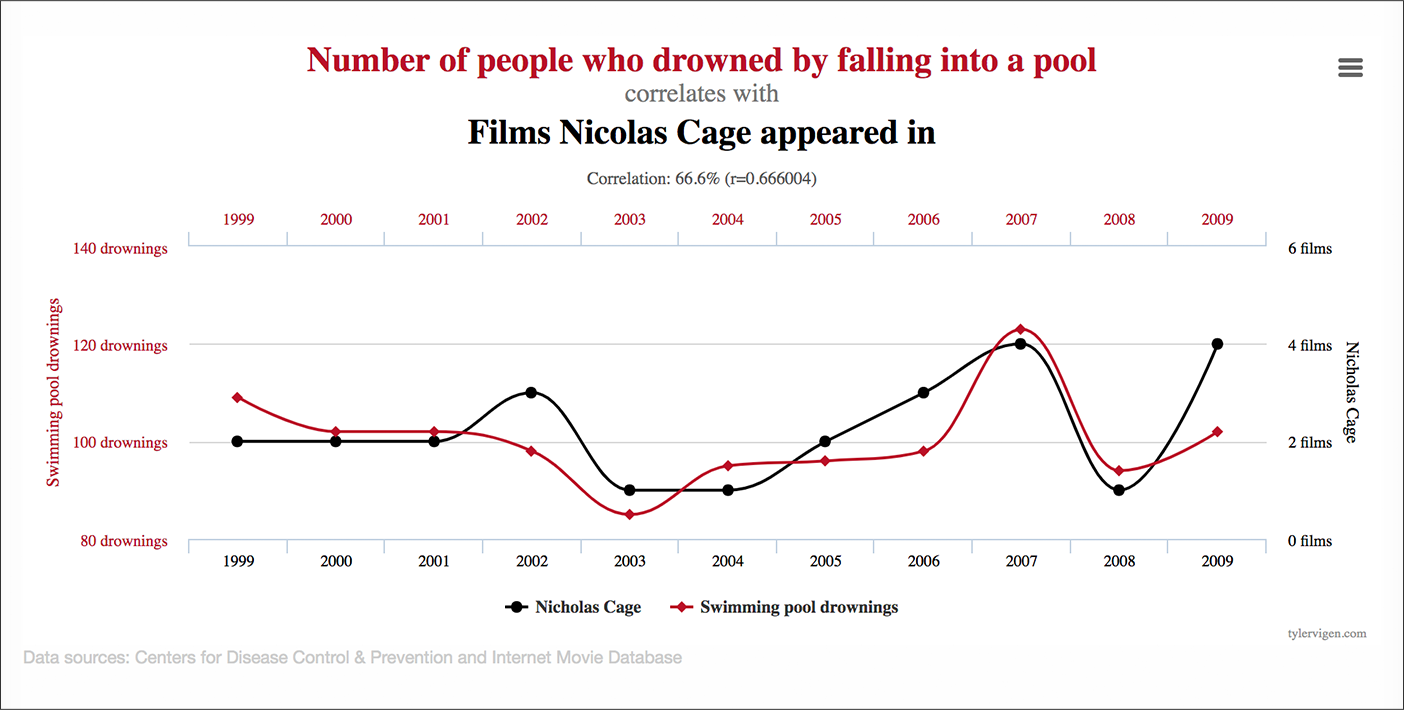
出典:タイラー・ヴィゲン
このアプローチのより大きな問題は、相関関係が因果関係を意味しないことです。
カリフォルニアからのデスクトップリピーターがより高いコンバージョンを達成したからといって、それがデータドリブンパーソナライズを介してターゲティングする価値のあるセグメントであることを意味するわけではありません。
ビジネスロジックの世界での最善の策は、テストを実行し、テスト後のセグメンテーションを介して価値の高いセグメントを発見することです。 次に、特定のターゲティングルールのROIを計算し、そのセグメントのみをターゲティングするフォローアップ実験を実行します。
次に、そのターゲティングルールを維持することの因果関係と真のROIを引き出すことができます。 このアプローチの詳細については、このトピックに関するAndrewAndersonのすばらしいチュートリアルをお読みください。
予測セグメンテーション
予測セグメンテーション(または別の名前で「データ駆動型」または「AIベース」のセグメンテーション)は、セグメントの定義とターゲティングルールの設定から人間の直感と手動のデータ分析を排除しようとします。
機械学習を使用してセグメントを定義する方法はいくつかあります。 それはあなたの目標が何であるか、そしてあなたがこれらのセグメントで何を達成したいと思っているかに依存します。 ここでは、3つの主要な方法について説明します。
- クラスタリング
- 分類
- 実験+予測プーリング
1.クラスタリング
まず、さまざまなユーザーペルソナまたはセグメントを識別して理解したいだけの場合、クラスタリングアルゴリズム(または教師なし機械学習)は、共通の特性に基づいてセグメントをグループ化するために使用される手法です。
これは私が数年前にCXLインスティテュートで取り組んだことです。
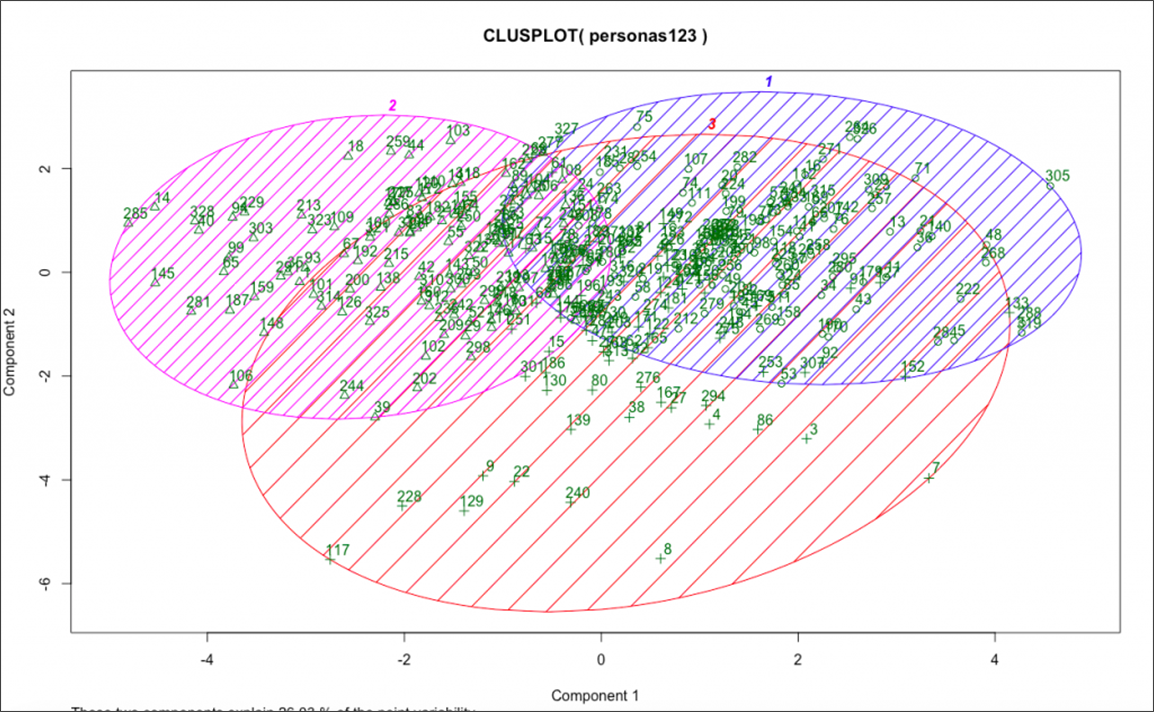
出典:CXL
スケール応答、カテゴリ変数、および自由形式の質問を組み合わせて、顧客ベースに調査を送信しました。 次に、それらの応答をコード化し、KMeansクラスタリングアルゴリズムを実行しました。
これにより、応答に基づいておよそ3つの異なるセグメントが識別されました。 次に、これらの各セグメントからの定性的な洞察を重ね、各セグメントを非常に代表する個人にインタビューしました。 これにより、既存の顧客ベースとそのさまざまな要望、課題、行動を深く理解することができました。
クラスタリングを行いたい場合は、それが主に探索的で知識構築のためであることを知ってください。 これらのセグメントの1つにパーソナライズされたマーケティングコミュニケーションを送信するROIも、どのセグメントがどのエクスペリエンスに反応する可能性が高いかについてもわかりません。 たとえば、電子メールサブスクライバーの特定のセグメントがより多くの電子メールを開き、生涯価値が高いことに気付くかもしれませんが、それでもテストする新しいコンテンツとエクスペリエンスを考案するという創造的な作業を行う必要があります。
ただし、データ駆動型のパーソナライズから始めるのは良いベースレイヤーです。
また、RまたはPythonをコーディングできる適切なアナリスト、または少なくともコード予測分析を行わないSquarkのようなツールも必要です。
2.分類
機械学習は、教師なし学習と教師なし学習の間で区別される傾向があります。 クラスタリングアルゴリズムが監視されていない場合、分類アルゴリズムが監視されます。
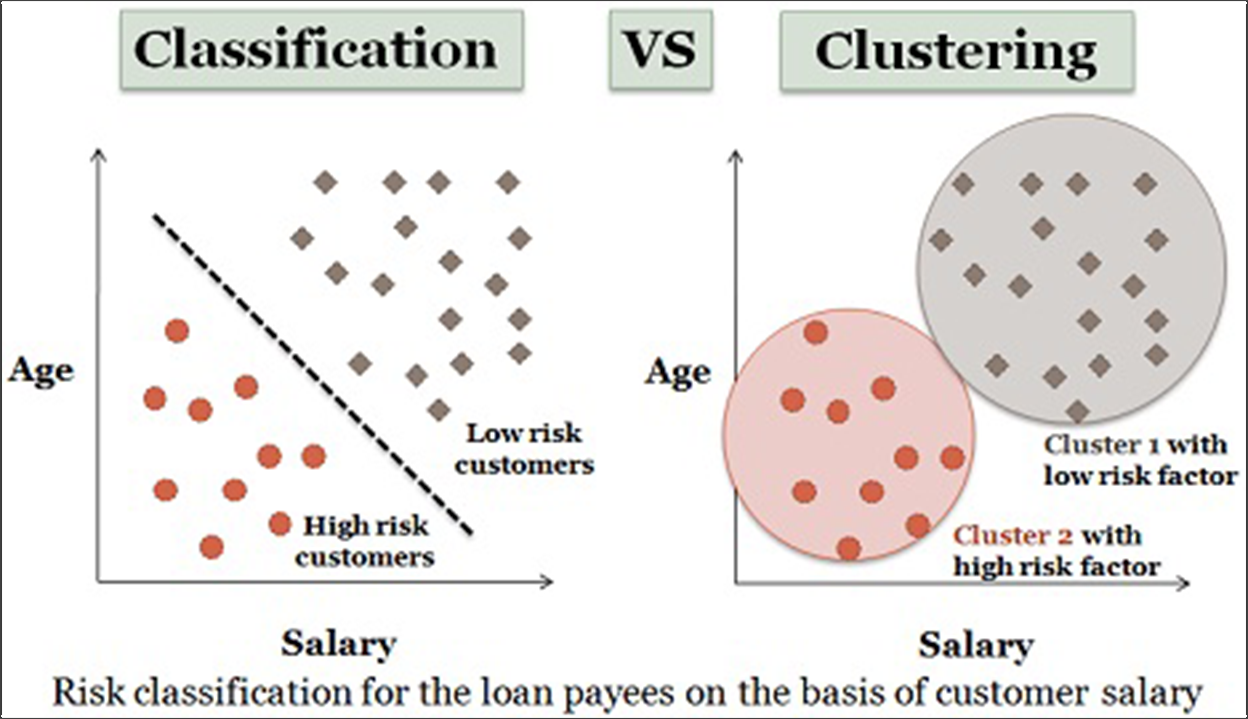
出典:技術の違い
これは、さまざまな「機能」(この場合、デバイスタイプ、訪問したページ、会社の規模、訪問者に関して収集できる特性など)を含むデータセットがあり、次のような結果が得られることを意味します。予測したい(この場合、コンバージョンまたは収益またはLTV)。
データの特徴に基づいて結果を予測しようとする方法論とアルゴリズムは大量にあり、その一部には線形回帰、ロジスティック回帰、ランダムフォレスト、ニューラルネットワークが含まれます。
この方法を使用する場合は、モデルをデータに適切に適合させることができる優れたアナリストが必要です(そうでない場合、予測は役に立ちません)。または、SquarkやDataRobotなどのツールを購入してください。 これらのツールを使用すると、アナリストやビジネスマンは、アルゴリズム自体をコーディングしなくても、さまざまなモデルをデータに適合させ、結果を予測できます。
3.実験+予測セグメンテーション
多くの場合、収益性の高いユーザーセグメントを見つけるための最善の方法は、制御された実験の通常のコースを実行し、有望なセグメントを検出するツール(または分析方法)を使用することです。
たとえば、Conductricsは、テストした各バリアントに対応する個々のセグメントの変換成功の確率を計算する、高度に解釈可能な決定木を示します。
予測ターゲティングツールに、設定したターゲティングルールと、これらのルールの推定ROIと成功確率を簡単な図で示すデータ視覚化がある場合のボーナスポイント。

出典:Conductrics
成功の確率が得られるだけでなく、その値に基づいてそのセグメントをターゲットにするかどうかを選択できるため、これはすばらしいことです。
男性のアンドロイドはケンタッキー州の田舎から訪問者を返しますか? 新しいターゲティングルールを設定する価値はないかもしれません。 しかし、彼らが大規模な人口であり、与えられた経験に非常に好意的に反応するならば、多分それはカリフォルニア人をターゲットにする価値があります。
データドリブンパーソナライズを開始する方法
データ駆動型のパーソナライズの最深部に飛び込みたくなるかもしれませんが、ゆっくりと始めることをお勧めします。
特定のパーソナライズルールの真の価値が何であるかは不明であり、多くの場合、パーソナライズの増加による限界利益は、導入された限界複雑コストを下回ります。
したがって、複雑さをエスカレートする3つのパーソナライズアプローチを紹介します(「クロール」段階では、データを整理し、パーソナライズされたエクスペリエンスを提供するために必要なリソース/ツールを取得していると仮定します)。
ステージ1:歩く
したがって、予測ターゲティングツールに投資する前に、Andrew Andersonの方法論を使用することをお勧めします。これは、通常の実験プログラムの単純な継続です(補足:実験用のトラフィックがありませんか?パーソナライズは適していません。そのトラフィックレベルでは、限界リターンは価値がありません。代わりに大きなスイングを打ってください)。
方法論の要点は次のとおりです。
- メッセージまたはエクスペリエンスの複数の実行を作成します
- 管理された実験を通じて、すべてのオファーをすべての人に提供します
- セグメントごとの結果を見て、差別化されたエクスペリエンスを提供することで総利益を計算します。 多くのセグメントを分析するときは、多重比較を修正するようにしてください。
- 見つかった最高の収益を生み出す機会をライブでプッシュします(または、全オーディエンスでテストしたエクスペリエンスを使用して、そのセグメントのみでフォローアップ実験を実行します)。
専用のA/Bテストプラットフォームを使用することも、統合されたマーケティング自動化プラットフォームを使用することもできます。 後者は、Webやアプリだけでなく、複数のチャネルでメッセージをパーソナライズするのに役立ちます。また、パーソナライズされた製品の推奨事項を提供し、収益とCLTVを増やし、コンテンツ/製品の発見を改善することができます。
ステージ2:実行
ここでいくつかの勝利を得た後、Squarkのようなコードなしの予測分析ソリューションに投資することをお勧めします(または、アルゴリズムを社内でコーディングできる場合は、必ず)。 基本的なプロセスは次のようになります。
成功指標を決定する
データを収集してクリーンアップし、データセットをトレーニングデータとテストデータに分割します。
結果を予測するために使用できる無数のディメンションまたは機能がデータに含まれていることを確認してください。
どの機能が成功指標を予測するかを判断します。
それらのセグメントのパーソナライズエクスペリエンスのROIを計算します。 繰り返しになりますが、人口が少なすぎる場合は、それだけの価値がない可能性があります。
ここで重要なのは、成功を予測する機能またはディメンションを定義した後(たとえば、リピーター)、そのセグメントでどのエクスペリエンスが機能する可能性が高いかをまだ把握していないことです。
大変な作業がまだ残っています。つまり、新しい素晴らしいエクスペリエンスを作成し、実験を実行して、新しいエクスペリエンスの有効性とROIを判断します。
特定のセグメントをターゲットにするために、WebEngageのようなコンテンツ配信ソリューションに投資することをお勧めします。
ステージ3:飛ぶ
最後に、予測ターゲティングを通常の実験と最適化のワークフローに組み込みたい場合は、ConductricsやDynamicYieldなどのツールに勝るものはありません。 これらのツールは、セグメントを識別し、パーソナライズされたエクスペリエンスを提供すると同時に、解釈可能な決定ルールとROIアトリビューションレポートを提供するのに役立ちます。
結論
人工知能が特効薬であるというヘッドラインと会議の話題が支配的な世界では、「データ駆動型のパーソナライズ」または「予測セグメンテーション」プロセスがすべての作業を行うわけではないことを知って驚くかもしれません。
それはあなたがあなたのデータを活用しそして多くの時間(そして間違い)を節約するのを助けることができます。 適切なデータがあり、必要なときにアクセスできる限り、収益性の高いセグメントをより簡単かつ正確に特定できます。
ただし、そのセグメントを活用するかどうかを決定することはできません。 それでも、長所と短所、コスト、および利点を比較検討する必要があります。
ただし、幸いなことに、セグメントの識別とグループ化のプロセスがこれまでになく簡単になり、複数の異なるエクスペリエンスを提供および管理することもこれまでになく簡単になりました。 マーケティング自動化ツールは、データソースまたはCRMにプラグインできます。 有料広告、ソーシャル、ウェブ、プッシュ、メールなど、任意のチャネルを介して無制限のパーソナライズされたエクスペリエンスを管理および配信できます。
データ主導のマーケティング担当者になる絶好の機会です。
 i画像ソース:WebEngage
i画像ソース:WebEngageビジネスに自動化の力を活用する
予測セグメンテーション機能と質の高いカスタマーサポートを備えています!