
Segmentasi Prediktif: Memulai Personalisasi Berbasis Data Sejati
Diterbitkan: 2021-12-30Seperti yang dikatakan Avinash Kaushik, "Semua data secara agregat adalah omong kosong." Segmentasi dan personalisasi berdasarkan data adalah beberapa alat paling ampuh yang dimiliki pemasar dan manajer produk.
Alih-alih memperlakukan setiap pengunjung atau pengguna dengan cara yang sama, Anda dapat memberikan pengalaman berdasarkan karakteristik perilaku, psikografis, demografi, dan firmografi yang unik dari pengguna Anda.
Pada titik ini, saya pikir semua orang tertarik pada gagasan segmentasi, serta perluasan logisnya-personalisasi.
Faktanya, menurut sebuah studi Evergage, “92% pemasar melaporkan menggunakan teknik personalisasi dalam pemasaran mereka, namun 55% pemasar tidak merasa mereka memiliki data pelanggan yang cukup untuk menerapkan personalisasi yang efektif.”
Teori di balik segmentasi dan personalisasi seringkali lebih cerah daripada kenyataan pelaksanaannya. Pada kenyataannya, Anda memerlukan tiga komponen inti untuk membuat program personalisasi berfungsi.
Artikel ini akan membahas esensi inti tersebut, dan kemudian saya akan menjelaskan perbedaan antara segmentasi tradisional dan segmentasi prediktif (didorong oleh pembelajaran mesin).
- Apa itu Segmentasi Prediktif?
- Data, Konten, dan Aturan Penargetan: Dasar-dasar Personalisasi
- Data
- Isi
- Logika Penargetan
- Segmentasi Prediktif vs. Logika Bisnis
- Segmentasi Logika Bisnis
- Personalisasi yang didorong oleh opini
- Segmentasi pasca-tes
- Analisis dan korelasi data eksplorasi
- Segmentasi Prediktif
- Kekelompokan
- Klasifikasi
- Eksperimen + Segmentasi Prediktif
- Cara Memulai Personalisasi Berdasarkan Data
- Tahap Satu: Berjalan
- Tahap Dua: Lari
- Tahap Tiga: Terbang
Di akhir artikel ini, Anda akan memiliki ide bagus tentang cara menerapkan personalisasi berbasis data dan segmentasi prediktif.
Pertama, Apa itu 'Segmentasi Prediktif'?
Segmentasi, pada tingkat tinggi, adalah proses membagi sesuatu menjadi bagian atau bagian yang terpisah.
Sumber: CXL
Ketika kami mengatakan "segmentasi," kami biasanya berarti "segmentasi pasar" atau "segmentasi pelanggan," atau mungkin "segmentasi perilaku." Segmentasi jenis ini adalah proses mengidentifikasi dan mendefinisikan karakteristik yang menggambarkan satu sub-kelompok atau bagian pelanggan dari yang lain.
Ini biasanya dilakukan melalui logika bisnis. Misalnya, kita dapat mengatakan bahwa pengguna perangkat seluler adalah segmen yang terpisah dari pengguna desktop. Atau yang lebih umum, kami dapat mengelompokkan pengunjung menurut representasi geografis: pengguna NAM vs EMEA.
Segmentasi prediktif adalah saat Anda mengidentifikasi kluster pengguna secara terprogram atau dengan menggunakan pembelajaran mesin. Baca lebih lanjut - melalui @webengage Klik Untuk TweetDalam metode ini, Anda biasanya memiliki tujuan atau hasil yang Anda lacak, dan Anda dapat bekerja mundur untuk mengidentifikasi karakteristik umum yang dimiliki sub-grup terkait dengan tujuan ini.
Misalnya, Anda dapat melacak "konversi pendaftaran daftar email" di blog Anda. Segmentasi prediktif mungkin menemukan bahwa ada kelompok berbeda yang berperilaku secara konsisten saat mengunjungi blog Anda.
Satu kelompok pengunjung seluler cenderung menghabiskan sedikit waktu di situs dan terpental dengan kecepatan tinggi. Kelompok pengunjung desktop lain dari saluran organik menghabiskan sangat sedikit waktu dan memantul pada tingkat yang sama tinggi.
Anda dapat menemukan segmen ini sendiri menggunakan analisis data, tetapi alat segmentasi prediktif berusaha mengidentifikasi dan mengelompokkan segmen pengguna ini. Biasanya, alat seperti ini mencoba memprediksi tindakan yang akan diambil segmen ini sehingga Anda dapat memicu aturan personalisasi.
Data, Konten, dan Aturan Penargetan: Dasar-dasar Personalisasi
Agar berhasil memberikan pengalaman yang dipersonalisasi ke segmen pengguna yang berbeda, Anda memerlukan tiga komponen:
- Data
- Isi
- Logika Penargetan
1. Data
Data menopang segalanya dalam hal segmentasi dan personalisasi.
Jika Anda tidak memiliki data yang diperlukan saat Anda membutuhkannya, Anda tidak dapat mengidentifikasi segmen pengguna apalagi memicu pengalaman yang dipersonalisasi untuk mereka. Selain itu, jika data Anda tidak tepat dan/atau tidak lengkap, personalisasi Anda mungkin tidak efektif.
Oleh karena itu, sebelum Anda melakukan segmentasi, pastikan tiga hal ini:
- Apakah Anda mengukur semua yang Anda butuhkan? Apakah Anda memiliki sasaran yang disiapkan dengan benar, dimensi khusus, dll.? Apakah data Anda “lengkap”?
- Apakah data Anda dapat dipercaya? Tidak perlu 100% 'akurat', tetapi apakah konsisten dan tepat dalam pencatatannya?
- Apakah data Anda dapat diakses saat Anda membutuhkannya? Berapa banyak pembersihan dan persiapan yang perlu Anda lakukan untuk mendapatkan wawasan dari data Anda? Apakah dikumpulkan dan terhubung ke sumber lain (sosial, web, email, data pelanggan)? Apakah disimpan di tempat yang dapat langsung digunakan dan dianalisis?
Selanjutnya, Anda ingin menghubungkan sumber data Anda ke beberapa tabel penyimpanan terpusat. Saat ini, platform data pelanggan (CDP) seperti Hull.io dan Segment adalah nama permainannya, tetapi Anda juga dapat menggunakan CRM seperti HubSpot untuk memusatkan, menyimpan, dan mengoperasionalkan data pemasaran dan pelanggan Anda.
Ini menjadi penting saat Anda menghubungkan data pra-pembelian ke data pasca-pembelian Anda. Hal ini memungkinkan Anda untuk mengidentifikasi segmen berdasarkan metrik bisnis penting seperti perkiraan nilai umur atau tingkat churnnya.
2. Konten
Porsi isi jauh lebih mudah grok.
Pada dasarnya, jika Anda ingin melakukan personalisasi, Anda terlebih dahulu menentukan segmen pengguna menggunakan sumber data Anda. Kemudian Anda juga perlu membuat pengalaman baru untuk disampaikan ke segmen tersebut.
Membuat konten atau pengalaman baru membutuhkan sumber daya, baik dari segi waktu maupun uang. Lebih jauh, semakin banyak konten dan pengalaman yang Anda berikan dan kelola, semakin banyak kompleksitas yang Anda bangun di organisasi Anda.
Matt Gershoff, CEO Conductrics, memberikan analogi yang bagus dalam podcast Digital Analytics Power Hour tentang hal ini.
Dia menggambarkan personalisasi sebagai dasarnya menciptakan multiverse.
Menjalankan satu versi situs web Anda untuk semua orang seperti memiliki satu alam semesta, dan mungkin pengujian A/B memungkinkan Anda menjalankan kontrafaktual untuk melihat seperti apa kehidupan di alam semesta paralel (atau "versi B").
Dalam pengujian A/B, Anda ingin melihat apakah versi B adalah "alam semesta" yang lebih baik bagi pengunjung Anda seperti yang ditentukan oleh konversi sasaran Anda, dan jika Anda menemukan bahwa itu memang optimal, Anda menutup semesta A (asli) dan lagi masuk kembali ke alam semesta tunggal.
Namun, beberapa varian konten yang dikirimkan ke beberapa segmen unik seperti membuka beberapa alam semesta yang berbeda di mana pengalamannya unik untuk segmen tersebut.
Keajaiban dari hal ini adalah Anda dapat meningkatkan nilai situs web Anda dengan meningkatkan nilai setiap segmen individu dan pengalaman mereka, tetapi Anda dapat memahami bagaimana membuka ribuan "alam semesta" akan memakan biaya baik dalam hal menciptakan dan mengelola semua itu. pengalaman.
3. Logika Penargetan
Terakhir, jika Anda memiliki data dan sumber daya yang berguna untuk membuat konten, Anda perlu menentukan bagaimana tepatnya Anda memicu logika penargetan atau personalisasi ke segmen pengguna.
Ini adalah bagaimana Anda menghubungkan data dengan pengalaman.
Anda dapat menggunakan logika bisnis (dengan asumsi segmen tertentu harus memiliki nilai tertentu – Anda bahkan dapat mengujinya A/B), atau Anda dapat memperkenalkan pembelajaran mesin dan segmentasi prediktif/RFM untuk mengklasifikasikan pengguna Anda ke dalam grup yang berbeda – pengguna yang paling berharga, akan segera berpindah pengguna, pengguna yang tidak aktif, dll. Dengan menggunakan segmentasi RFM, Anda juga dapat mempelajari segmen pengguna mana yang merespons secara lebih bervariasi terhadap pengalaman konten mana.
Secara teknis, untuk langkah ini, Anda memerlukan sistem pengiriman konten yang terhubung ke database Anda atau dapat mengintegrasikan dan menarik dari database Anda. WebEngage adalah sistem operasi penyimpanan dan otomatisasi pemasaran lengkap yang dapat terhubung secara mulus dengan CRM Anda dan membantu Anda melibatkan pengguna Anda dengan basis 1:1 di seluruh saluran seperti Email, SMS, WhatsApp, Facebook, Mobile & Web Push, dan banyak lagi.
Namun, sekali lagi, semakin banyak aturan penargetan yang Anda picu, semakin kompleks sistem yang Anda bangun. Jadi ada tradeoff dalam ROI yang dapat Anda manfaatkan dengan menargetkan segmen tertentu dan kompleksitas marjinal yang diperkenalkan ke sistem. Sangat mudah untuk menggabungkan nama depan ke token email khusus (kebanyakan alat email melakukannya di luar kotak sekarang), tetapi itu tidak memberi tahu Anda ROI dari aturan penargetan itu.
Sumber: GMass
Itu sebabnya, alih-alih hanya menyiapkan banyak personalisasi hanya karena Anda bisa, Anda harus melihatnya secara strategis dan metodologis, menentukan ROI dan efisiensi penargetan segmen tertentu.
Segmentasi Prediktif vs. Logika Bisnis
Saya telah menjatuhkan beberapa jargon terkait dengan logika penargetan — seperti “logika bisnis” dan “segmentasi prediktif”.
Logika bisnis pada dasarnya berdiri di sisi lain spektrum dari "personalisasi berbasis data," "segmentasi prediktif," atau "personalisasi berbasis pembelajaran mesin." Tetapi kedua metode ini memiliki tujuan yang sama: mengidentifikasi segmen untuk diperlakukan dengan pengalaman yang dipersonalisasi.
Mari kita definisikan kedua kutub ini dan perbedaannya.
Segmentasi Logika Bisnis
“Logika bisnis” adalah metode yang biasa digunakan orang untuk memilih aturan penargetan. Dalam metode ini, pada dasarnya Anda memutuskan segmen mana yang memiliki peluang dampak tertinggi menggunakan data historis dan korelasi atau logika bisnis, strategi, atau opini. Ada tiga cara utama untuk mendapatkan aturan penargetan logika bisnis:
- Personalisasi yang didorong oleh opini
- Segmentasi pasca-tes
- Analisis data eksplorasi
1. Personalisasi yang didorong oleh opini
Misalnya, Anda mungkin hanya ingin menghindari memicu popup invasif di ponsel hanya karena alasan subjektif. Ini bukan pengalaman pengguna yang baik, jadi Anda menghindarinya. Anda bahkan tidak memerlukan data untuk memprediksi reaksi segmen tersebut.
Memperlakukan pengguna seluler secara berbeda adalah penggunaan personalisasi yang umum
Ini adalah metode yang digunakan sebagian besar perusahaan ketika mereka mengatakan mereka melakukan segmentasi atau personalisasi berbasis data. Mereka secara sewenang-wenang menebak segmen mana yang akan merespons dengan baik pengalaman mana dan mempersonalisasikannya berdasarkan pendapat mereka.
2. Segmentasi pasca-tes
Namun, yang kurang umum (tetapi lebih efektif) adalah menjalankan eksperimen dan kemudian melakukan analisis pasca-tes untuk mengetahui apakah variasi tertentu memiliki area dampak yang lebih tinggi pada segmen tertentu.
Bayangkan Anda menjalankan pengujian pada alur pembayaran eCommerce.
Anda memutuskan untuk menguji beberapa varian – satu varian dengan serangkaian simbol kepercayaan dan keamanan, satu dengan popup yang menggunakan pesan urgensi, dan satu lagi tanpa simbol (versi asli).
Setelah menganalisis eksperimen, Anda telah menentukan bahwa versi B "menang" dan memiliki perkiraan peningkatan 10%. Sebuah kemenangan besar.
Namun, Anda menggali data dan melihat segmen berdampak tinggi, seperti pengunjung seluler vs desktop, pengunjung kembali vs pengunjung baru, dan pengunjung dari pengunjung AS vs pengunjung non-AS.
Dengan melakukan itu, Anda telah menemukan bahwa pengguna iPhone benar-benar berkonversi 35% lebih baik pada varian B. Pengguna iPhone mewakili persentase besar audiens Anda, kira-kira 25% dari semua pengunjung. Ini berarti bahwa memicu pengalaman yang dipersonalisasi ke segmen ini dapat bermanfaat dan ROI positif.

Selain itu, pengguna Android sebenarnya berkonversi 20% lebih rendah pada varian B dan 15% lebih tinggi daripada kontrol pada varian C. Pengguna Android mewakili 10% audiens Anda, jadi sekali lagi, populasi yang cukup besar.
Jadi Anda bisa saja meluncurkan varian B karena menang secara agregat. Atau sebagai alternatif, Anda dapat menyiapkan aturan penargetan untuk memicu pengguna iPhone menerima varian B dan pengguna Android menerima varian C. Semua orang mendapatkan yang asli.
3. Analisis dan korelasi data eksplorasi
Cara terakhir Anda dapat menggunakan "logika bisnis" untuk segmentasi adalah dengan hanya menjelajahi data yang Anda akses dan mencari korelasi antara karakteristik segmen dan kemungkinan konversi.
Anda mungkin menemukan, misalnya, bahwa pengguna iPhone berkonversi lebih tinggi. Atau orang yang menonton video di beranda Anda. Atau pengguna Android pria dari Kansas yang mengisi setengah dari kolom formulir Anda dan kembali 3 kali dalam satu minggu.
Inilah masalahnya dengan pendekatan ini: lihat segmen yang cukup dan Anda akan menemukan korelasinya. Itu masalah sinyal vs kebisingan.
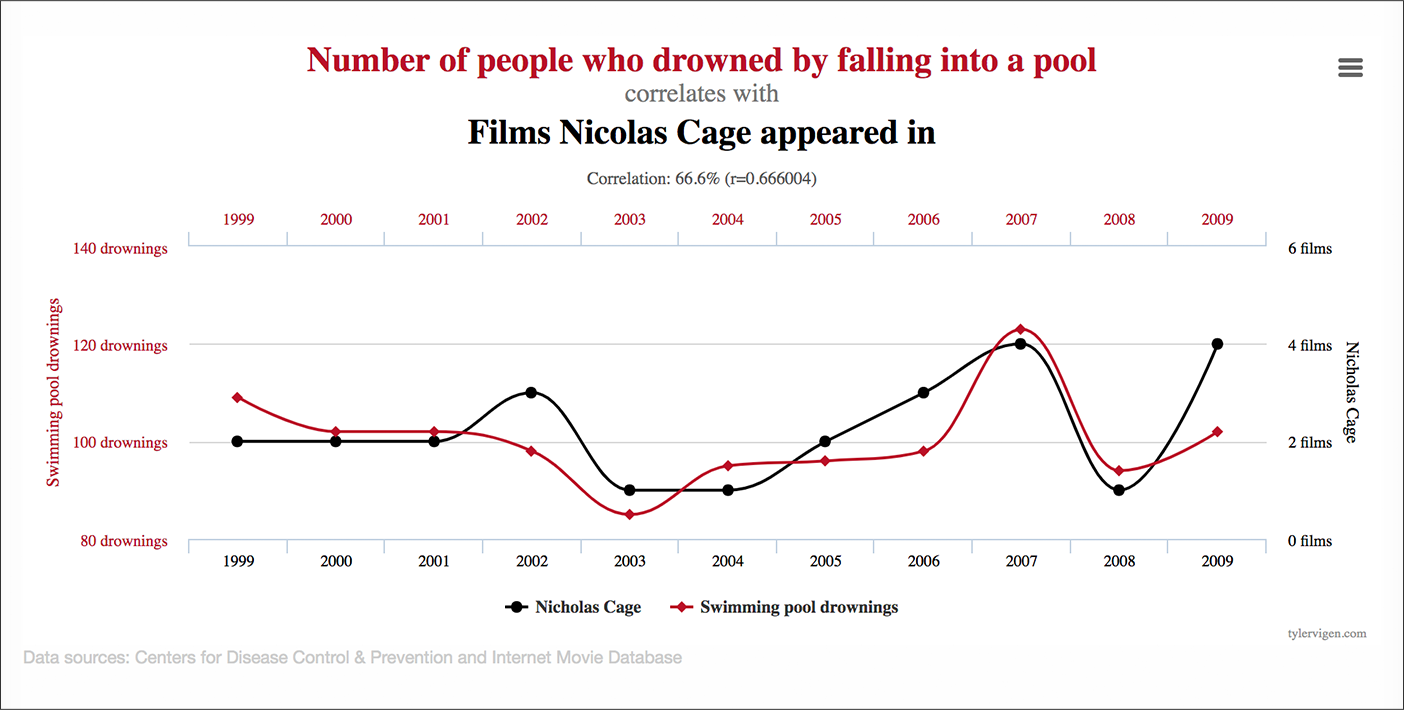
Sumber: Tyler Vigen
Masalah yang lebih besar dengan pendekatan ini adalah bahwa korelasi tidak menyiratkan sebab-akibat.
Hanya karena pengunjung desktop kembali dari California berkonversi lebih tinggi tidak berarti itu adalah segmen yang layak ditargetkan melalui personalisasi berdasarkan data.
Taruhan terbaik Anda di dunia logika bisnis adalah menjalankan eksperimen dan menemukan segmen bernilai tinggi melalui segmentasi pasca-tes. Kemudian Anda menghitung ROI dari aturan penargetan tertentu dan menjalankan eksperimen tindak lanjut yang hanya menargetkan segmen tersebut.
Anda kemudian dapat menghilangkan kausalitas dan ROI sebenarnya dari mempertahankan aturan penargetan tersebut. Untuk informasi lebih lanjut tentang pendekatan ini, baca panduan luar biasa Andrew Anderson tentang topik tersebut.
Segmentasi Prediktif
Segmentasi prediktif (atau dengan nama lain, segmentasi “berbasis data” atau “berbasis AI”) berupaya menghilangkan intuisi manusia dan analisis data manual dari definisi segmen dan menyiapkan aturan penargetan.
Ada beberapa cara untuk menentukan segmen menggunakan machine learning. Itu hanya tergantung pada apa tujuan Anda dan apa yang ingin Anda capai dengan segmen ini. Di sini kita akan membahas tiga metode kunci:
- Kekelompokan
- Klasifikasi
- Eksperimen + kumpulan prediktif
1. Pengelompokan
Pertama, jika Anda hanya ingin mengidentifikasi dan memahami persona atau segmen pengguna yang berbeda, algoritme pengelompokan (atau pembelajaran mesin tanpa pengawasan) adalah teknik yang digunakan untuk mengelompokkan segmen berdasarkan karakteristik umum.
Ini adalah sesuatu yang saya kerjakan di CXL Institute beberapa tahun yang lalu.
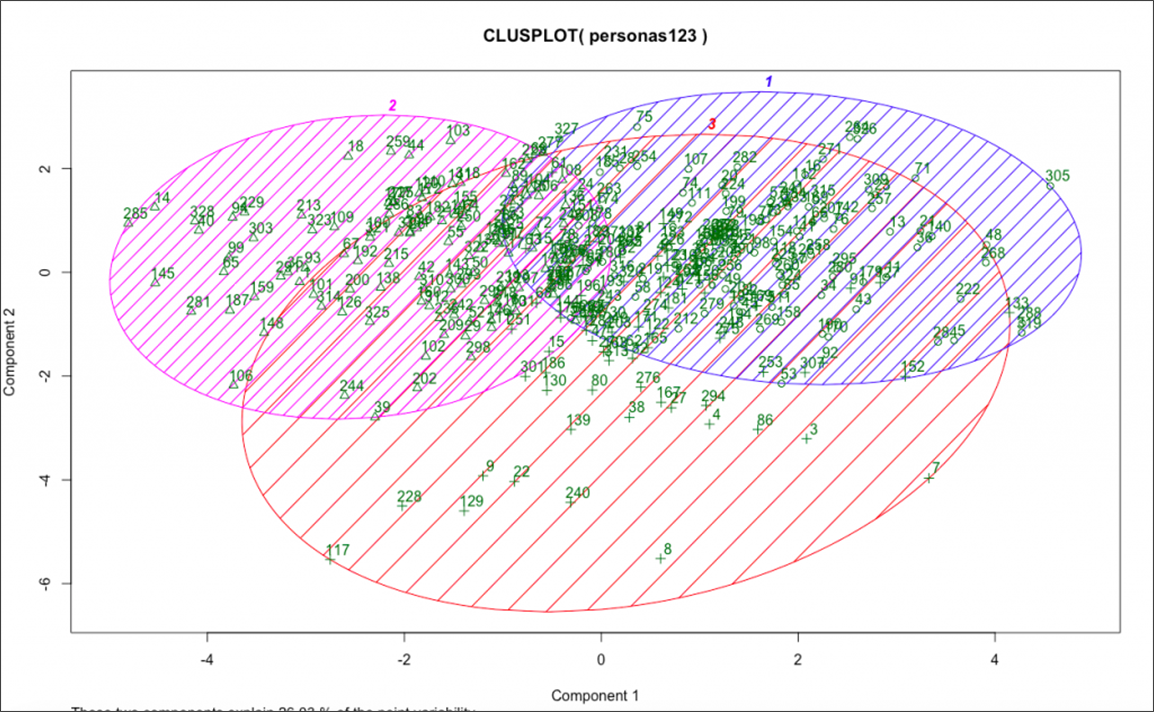
Sumber: CXL
Kami mengirimkan survei ke basis pelanggan kami dengan campuran tanggapan skala, variabel kategoris, dan pertanyaan terbuka. Saya kemudian mengkodifikasi tanggapan mereka dan menjalankan algoritma pengelompokan K Means pada mereka.
Ini mengidentifikasi kira-kira tiga segmen berbeda berdasarkan tanggapan mereka. Saya kemudian melapisi wawasan kualitatif dari masing-masing segmen ini dan mewawancarai individu yang sangat mewakili setiap segmen. Ini memungkinkan kami untuk memahami secara mendalam basis pelanggan kami yang ada dan keinginan, tantangan, dan perilaku mereka yang berbeda.
Jika Anda ingin melakukan pengelompokan, ketahuilah bahwa itu sebagian besar bersifat eksploratif dan untuk membangun pengetahuan. Ini tidak akan memberi tahu Anda ROI pengiriman komunikasi pemasaran yang dipersonalisasi ke salah satu segmen ini, juga tidak akan memberi tahu Anda segmen mana yang cenderung merespons pengalaman mana. Misalnya, Anda mungkin menemukan bahwa segmen pelanggan email tertentu membuka lebih banyak email dan memiliki nilai masa pakai yang lebih tinggi, tetapi Anda masih perlu melakukan pekerjaan kreatif untuk menemukan konten dan pengalaman baru untuk diuji.
Tetapi ini adalah lapisan dasar yang baik untuk memulai dengan personalisasi berbasis data.
Anda juga memerlukan analis yang layak yang dapat mengkodekan R atau Python atau setidaknya alat seperti Squark yang tidak memungkinkan analisis prediktif kode.
2. Klasifikasi
Pembelajaran mesin cenderung digambarkan antara pembelajaran yang diawasi dan tidak diawasi. Di mana algoritma pengelompokan tidak diawasi, algoritma klasifikasi diawasi.
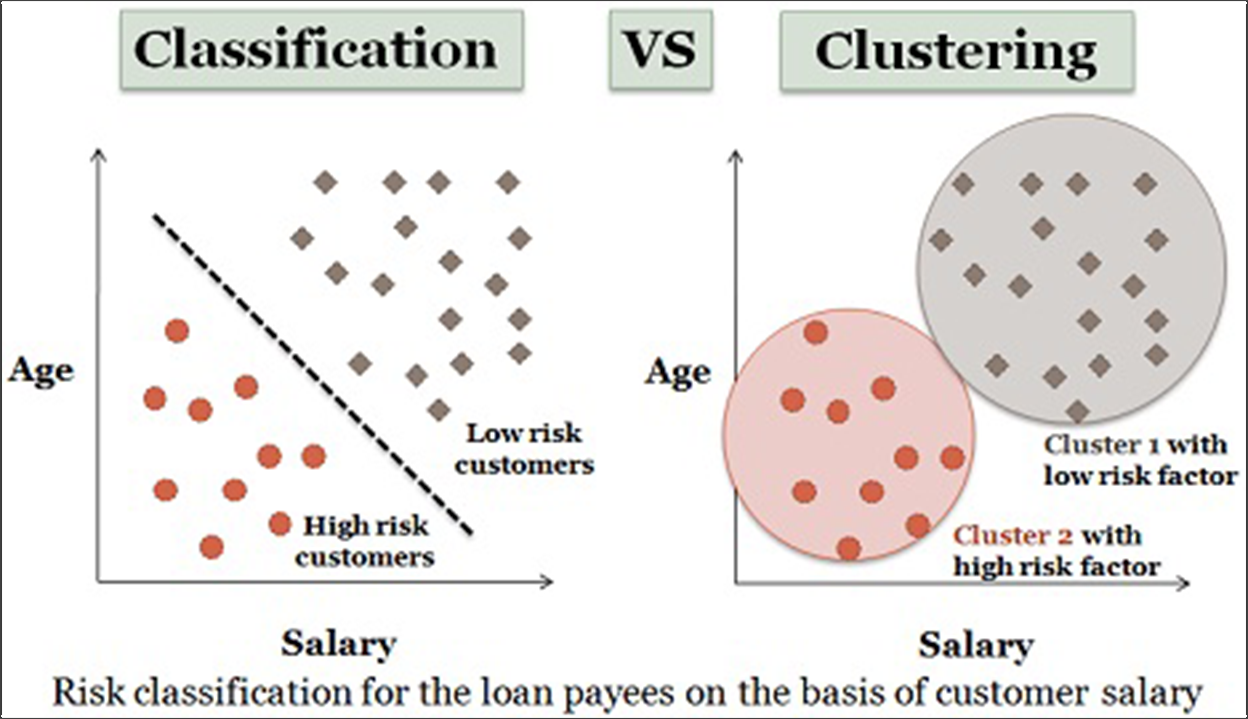
Sumber: Perbedaan teknologi
Ini berarti Anda memiliki kumpulan data yang mencakup berbagai "fitur" (dalam kasus kami, ini bisa berupa hal-hal seperti jenis perangkat, halaman yang dikunjungi, ukuran perusahaan, atau karakteristik apa pun yang dapat kami kumpulkan tentang pengunjung) dan kemudian Anda memiliki hasil yang Anda ingin memprediksi (dalam kasus kami, konversi atau pendapatan atau LTV).
Ada sejumlah besar metodologi dan algoritme yang mencoba memprediksi hasil berdasarkan fitur data, beberapa di antaranya termasuk regresi linier, regresi logistik, hutan acak, dan jaringan saraf.
Jika Anda ingin menggunakan metode ini, Anda memerlukan analis hebat yang dapat memasukkan model ke data Anda dengan benar (jika tidak, prediksi tidak berguna), atau membeli alat seperti Squark atau DataRobot. Alat-alat ini memungkinkan analis dan pebisnis untuk menyesuaikan model yang berbeda dengan data mereka dan memprediksi hasil tanpa mengkodekan algoritme itu sendiri.
3. Eksperimen + Segmentasi Prediktif
Seringkali cara terbaik untuk menemukan segmen pengguna yang menguntungkan adalah dengan melakukan eksperimen terkontrol normal Anda dan menggunakan alat (atau metode analisis) yang mendeteksi segmen yang menjanjikan.
Conductrics, misalnya, menunjukkan kepada Anda pohon keputusan yang sangat mudah ditafsirkan yang menghitung probabilitas keberhasilan konversi untuk masing-masing segmen yang sesuai dengan setiap varian yang Anda uji.
Poin bonus jika alat penargetan prediktif Anda memiliki visualisasi data yang menunjukkan kepada Anda, dalam ilustrasi sederhana, aturan penargetan apa yang telah Anda siapkan dan perkiraan ROI serta probabilitas keberhasilan aturan ini.

Sumber: Konduktor
Ini keren karena Anda tidak hanya mendapatkan probabilitas keberhasilan, tetapi Anda dapat memilih apakah akan menargetkan segmen itu atau tidak berdasarkan nilainya.
Android pria mengembalikan pengunjung dari pedesaan Kentucky? Mungkin tidak layak untuk menyiapkan aturan penargetan baru. Tapi mungkin ada baiknya menargetkan orang California jika mereka adalah populasi besar dan merespons dengan sangat baik terhadap pengalaman yang diberikan.
Cara Memulai Personalisasi Berdasarkan Data
Meskipun mungkin tergoda untuk mendalami personalisasi berbasis data, saya sarankan untuk memulai dengan perlahan.
Tidak diketahui apa nilai sebenarnya dari setiap aturan personalisasi yang diberikan, dan sering kali keuntungan marginal dari peningkatan personalisasi kurang dari biaya kompleksitas marginal yang diperkenalkan.
Oleh karena itu, saya akan memperkenalkan tiga pendekatan personalisasi untuk meningkatkan kompleksitas (dan mari kita asumsikan tahap 'perayapan' hanya mengatur data Anda dan sumber daya/alat yang diperlukan untuk memberikan pengalaman yang dipersonalisasi).
Tahap Satu: Berjalan
Oleh karena itu, sebelum Anda berinvestasi dalam alat penargetan prediktif, Anda mungkin ingin menggunakan metodologi Andrew Anderson, yang dapat menjadi kelanjutan sederhana dari program eksperimen normal Anda (catatan tambahan: tidak memiliki lalu lintas untuk eksperimen? Personalisasi bukan untuk Anda. pengembalian marjinal tidak akan sepadan dengan tingkat lalu lintas itu. Sebagai gantinya, lakukan perubahan besar).
Inilah inti dari metodologi:
- Buat beberapa eksekusi pesan atau pengalaman
- Sajikan semua penawaran kepada semua orang melalui eksperimen terkontrol
- Lihat hasil berdasarkan segmen dan hitung total keuntungan dengan memberikan pengalaman yang berbeda. Pastikan Anda mengoreksi beberapa perbandingan saat menganalisis banyak segmen.
- Dorong langsung peluang penghasil pendapatan tertinggi yang ditemukan (atau jalankan eksperimen tindak lanjut hanya pada segmen tersebut dengan pengalaman yang Anda uji pada audiens penuh).
Anda dapat menggunakan platform pengujian A/B khusus atau Anda dapat menggunakan platform otomatisasi pemasaran terintegrasi. Yang terakhir akan membantu Anda mempersonalisasi pesan di beberapa saluran, bukan hanya web atau aplikasi, dan Anda dapat menawarkan rekomendasi produk yang dipersonalisasi, meningkatkan pendapatan dan CLTV Anda, meningkatkan penemuan konten/produk, dan banyak lagi.
Tahap Dua: Lari
Setelah mendapatkan beberapa kemenangan di sini, Anda mungkin ingin berinvestasi dalam solusi analitik prediktif tanpa kode seperti Squark (atau jika Anda dapat membuat kode algoritme sendiri, tentu saja). Proses dasarnya terlihat seperti ini:
Tentukan metrik kesuksesan Anda
Kumpulkan dan bersihkan data Anda, pisahkan kumpulan data Anda menjadi data pelatihan dan pengujian.
Pastikan Anda memiliki segudang dimensi atau fitur dalam data Anda yang dapat digunakan untuk memprediksi hasilnya.
Tentukan fitur mana yang memprediksi metrik kesuksesan Anda.
Hitung ROI dari pengalaman yang dipersonalisasi untuk segmen tersebut. Sekali lagi, jika populasinya terlalu kecil, mungkin tidak sepadan.
Sekarang bagian yang penting: setelah Anda menentukan fitur atau dimensi yang memprediksi keberhasilan (misalnya pengunjung yang kembali), Anda masih belum mengetahui pengalaman mana yang lebih mungkin berhasil di segmen tersebut.
Kerja keras masih tersisa: yaitu, menciptakan pengalaman baru yang hebat dan menjalankan eksperimen untuk menentukan keefektifan dan ROI dari pengalaman baru Anda.
Anda tetap ingin berinvestasi dalam solusi pengiriman konten di sini seperti WebEngage untuk menargetkan segmen tertentu.
Tahap Tiga: Terbang
Terakhir, jika Anda ingin memasukkan penargetan prediktif ke dalam eksperimen normal dan alur kerja pengoptimalan, Anda tidak dapat mengalahkan alat seperti Conductrics atau Dynamic Yield. Alat ini akan membantu Anda mengidentifikasi segmen dan memberikan pengalaman yang dipersonalisasi sambil memberi Anda aturan keputusan yang dapat ditafsirkan dan laporan atribusi ROI.
Kesimpulan
Di dunia yang didominasi oleh berita utama dan pembicaraan konferensi tentang kecerdasan buatan menjadi peluru perak, Anda mungkin terkejut mengetahui bahwa proses "personalisasi berbasis data" atau "segmentasi prediktif" tidak melakukan semua pekerjaan untuk Anda.
Ini dapat membantu Anda memanfaatkan data Anda dan menghemat banyak waktu (dan kesalahan). Anda dapat lebih mudah dan akurat mengidentifikasi segmen yang menguntungkan, selama Anda memiliki data yang tepat dan dapat diakses saat Anda membutuhkannya.
Namun, itu tidak dapat membuat keputusan untuk Anda apakah akan memanfaatkan segmen itu atau tidak. Anda masih harus mempertimbangkan pro dan kontra, biaya, dan manfaatnya.
Namun, untungnya, proses mengidentifikasi dan mengelompokkan segmen tidak pernah semudah ini, juga tidak pernah semudah ini untuk menyampaikan dan mengelola berbagai pengalaman berbeda. Alat otomatisasi pemasaran dapat dicolokkan ke sumber data atau CRM Anda. Anda dapat mengelola dan memberikan pengalaman pribadi tanpa batas melalui saluran apa pun yang Anda inginkan – iklan berbayar, sosial, web, push, email, dll.
Ini adalah waktu yang tepat untuk menjadi pemasar berbasis data.
 i Sumber gambar: WebEngage
i Sumber gambar: WebEngageManfaatkan Kekuatan Otomatisasi Untuk Bisnis Anda
Dengan fitur segmentasi prediktif dan dukungan pelanggan berkualitas!