
预测分割:真正的数据驱动个性化入门
已发表: 2021-12-30正如 Avinash Kaushik 所说,“所有汇总的数据都是垃圾。” 细分和数据驱动的个性化是营销人员和产品经理可以使用的一些最强大的工具。
您可以根据用户独特的行为、心理、人口统计和企业特征来提供体验,而不是以相同的方式对待每个访问者或用户。
在这一点上,我认为每个人都接受了分割的想法,以及它的逻辑扩展——个性化。
事实上,根据 Evergage 的一项研究,“92% 的营销人员报告说他们在营销中使用了个性化技术,但 55% 的营销人员认为他们没有足够的客户数据来实施有效的个性化。”
细分和个性化背后的理论往往比其执行的现实更乐观。 实际上,您需要三个核心组件才能使个性化程序发挥作用。
本文将介绍这些核心要素,然后我将解释传统分割和预测分割(由机器学习驱动)之间的区别。
- 什么是预测分割?
- 数据、内容和定位规则:个性化基础
- 数据
- 内容
- 目标逻辑
- 预测细分与业务逻辑
- 业务逻辑分割
- 意见驱动的个性化
- 测试后分割
- 探索性数据分析和相关性
- 预测分割
- 聚类
- 分类
- 实验+预测分割
- 如何开始使用数据驱动的个性化
- 第一阶段:步行
- 第二阶段:运行
- 第三阶段:飞行
在本文结束时,您将对如何实现数据驱动的个性化和预测细分有一个很好的了解。
首先,什么是“预测分割”?
细分,在高层次上,是将某物分成单独的部分或部分的过程。
资料来源:CXL
当我们说“细分”时,我们通常指的是“市场细分”或“客户细分”,或者可能是“行为细分”。 这种类型的细分是识别和定义将一个子组或客户部分与另一个客户区分开来的特征的过程。
这通常通过业务逻辑完成。 例如,我们可以说移动设备用户是与桌面用户分开的部分。 或者更常见的是,我们可以按地理代表性对访问者进行分组:NAM 与 EMEA 用户。
预测分割是指您以编程方式或使用机器学习识别用户集群。 阅读更多 - 通过@webengage点击鸣叫在这种方法中,您通常有一个要跟踪的目标或结果,并且您可以向后工作以确定子组与该目标共享的共同特征。
例如,您可以在博客上跟踪“电子邮件列表注册转化”。 预测性细分可能会发现在访问您的博客时存在行为一致的不同组。
一组移动访问者往往在网站上花费的时间很少,并且跳出率很高。 另一组来自自然渠道的桌面访问者花费的时间很少,并且以同样高的速度跳出。
您可以使用数据分析自行发现这些细分,但预测细分工具会寻求识别和聚类这些用户细分。 通常,像这样的工具会尝试预测这些细分将采取的行动,以便您可以触发个性化规则。
数据、内容和定位规则:个性化基础
要成功地向不同的用户群提供个性化体验,您需要三个组件:
- 数据
- 内容
- 目标逻辑
1. 数据
在细分和个性化方面,数据是一切的基础。
如果您在需要时没有所需的数据,则无法识别用户细分,更不用说为他们触发个性化体验了。 此外,如果您的数据不准确和/或不完整,您的个性化可能无效。
因此,在您进行任何细分之前,请确认以下三件事:
- 你测量你需要的一切吗? 您是否正确设置了目标、自定义维度等? 您的数据“完整”吗?
- 你的数据可信吗? 它不需要 100%“准确”,但它的日志记录是否一致和精确?
- 您的数据可以在需要时访问吗? 您需要做多少清理和准备工作才能从数据中获得洞察力? 它是否聚合并连接到其他来源(社交、网络、电子邮件、客户数据)? 是否存放在可以立即使用和分析的地方?
此外,您需要将数据源连接到某个集中存储表。 如今,Hull.io 和 Segment 等客户数据平台 (CDP) 是游戏的名称,但您也可以使用 HubSpot 等 CRM 来集中、存储和操作您的营销和客户数据。
当您将购买前数据连接到购买后数据时,这些变得很重要。 这使您可以根据重要的业务指标(例如预测的生命周期价值或流失率)来识别细分市场。
2. 内容
内容部分更容易理解。
本质上,如果您想进行个性化,您首先使用您的数据源定义一个用户细分。 然后,您还需要创建一种新体验来交付给该细分市场。
创造新的内容或体验需要时间和金钱方面的资源。 此外,您交付和管理的内容和体验越多,您在组织中建立的复杂性就越高。
Conductrics 的首席执行官 Matt Gershoff 在 Digital Analytics Power Hour 播客中对此做了一个很好的类比。
他将个性化描述为本质上创造了一个多元宇宙。
为每个人运行一个版本的网站就像拥有一个宇宙,也许 A/B 测试可以让你运行反事实来看看平行宇宙(或“版本 B”)中的生活会是什么样子。
在 A/B 测试中,您想查看版本 B 是否对您的访问者来说是一个更好的“宇宙”,正如您的目标转换所定义的那样,如果您发现它确实是最优的,您关闭宇宙 A(原始)并再次重新进入一个奇异的宇宙。
但是,将多个内容变体交付给多个独特的细分市场就像保持开放的几个不同的宇宙,其中体验对于这些细分市场来说是独一无二的。
这样做的神奇之处在于,您可以通过增加每个细分市场的价值及其体验来增加您网站的价值,但您可以理解,在创建和管理所有这些方面,打开数以千计的“宇宙”将是多么昂贵。经验。
3. 目标逻辑
最后,如果您有有用的数据和资源来创建内容,您需要确定您如何准确地触发用户细分的定位或个性化逻辑。
这就是您将数据与体验联系起来的方式。
您可以使用业务逻辑(假设某些细分应该具有某些价值——您甚至可以对它们进行 A/B 测试),或者您可以引入机器学习和预测细分/RFM 将您的用户分类为不同的组——最有价值的用户,即将流失用户、休眠用户等。使用 RFM 细分,您还可以了解哪些用户细分对哪些内容体验的反应更加多变。
从技术上讲,对于这一步,您需要一个内容交付系统,该系统要么连接到您的数据库,要么可以集成并从您的数据库中提取。 WebEngage 是一个全栈营销自动化和保留操作系统,可以与您的 CRM 无缝连接,并帮助您通过电子邮件、SMS、WhatsApp、Facebook、移动和 Web 推送等渠道以 1:1 的方式吸引用户。
不过,同样,您触发的目标规则越多,您构建的系统就越复杂。 因此,您可以通过定位给定的细分市场和引入系统的边际复杂性来权衡投资回报率。 将名字合并到自定义电子邮件令牌很容易(现在大多数电子邮件工具都可以立即使用),但这并不能告诉您该定位规则的投资回报率。
资料来源:GMass
这就是为什么,而不是仅仅因为你可以设置大量的个性化,你应该从战略和方法上看待它,确定针对给定细分市场的投资回报率和效率。
预测细分与业务逻辑
我已经放弃了一些关于目标逻辑的行话——例如“业务逻辑”和“预测细分”。
业务逻辑本质上与“数据驱动的个性化”、“预测分割”或“基于机器学习的个性化”不同。 但这两种方法都有相同的目标:确定需要个性化体验的细分市场。
让我们定义这两个极点以及它们的不同之处。
业务逻辑分割
“业务逻辑”是人们选择目标规则的常用方法。 在这种方法中,您基本上可以使用历史数据和相关性或业务逻辑、策略或意见来确定哪些细分市场具有最大的影响机会。 您可以通过三种主要方式派生业务逻辑目标规则:
- 意见驱动的个性化
- 测试后分割
- 探索性数据分析
1.意见驱动的个性化
例如,出于纯粹的主观原因,您可能只是想避免在移动设备上触发侵入性弹出窗口。 这不是一个好的用户体验,所以你避免它。 您甚至不需要数据来预测该细分市场的反应。
以不同方式对待移动用户是个性化的常见用途
这是绝大多数公司在进行细分或数据驱动的个性化时使用的方法。 他们随意猜测哪个细分市场会对哪种体验做出积极响应,并根据他们的意见对其进行个性化设置。
2. 后测分割
然而,不太常见(但更有效)的是进行实验,然后进行测试后分析,以确定某些变化是否对某些细分市场产生了更大的影响。
想象一下,您正在对电子商务结帐流程进行测试。
您决定测试多个变体——一个带有一系列信任和安全符号的变体,一个带有使用紧急消息的弹出窗口,一个没有符号(原始版本)。
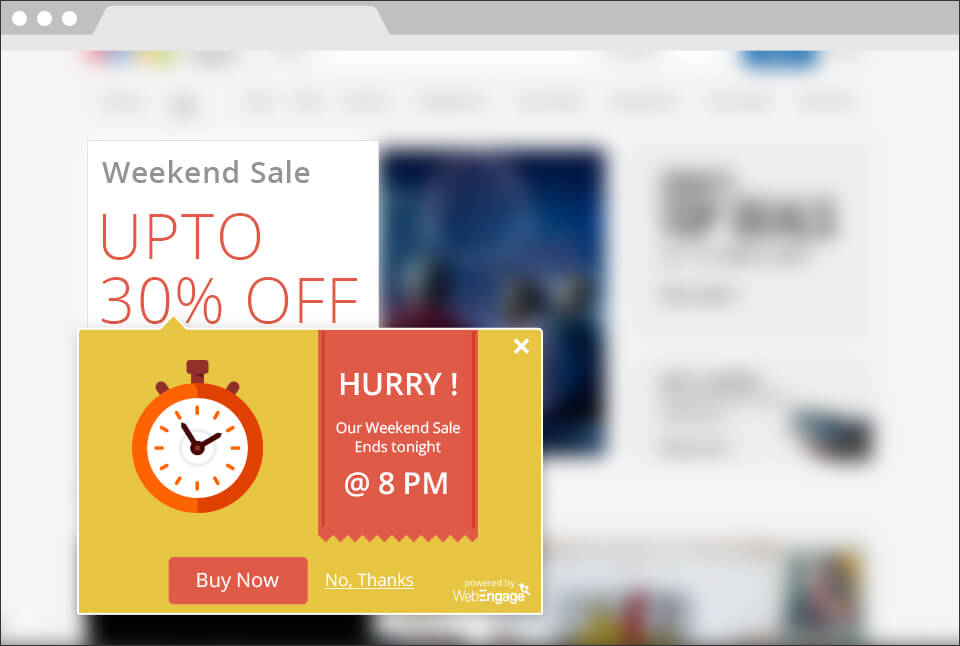
分析实验后,您确定版本 B“获胜”并且估计提升了 10%。 一场伟大的胜利。
但是,您深入研究数据并查看影响较大的细分市场,例如移动访问者与桌面访问者、回访者与新访问者、美国访问者与非美国访问者。
在这样做的过程中,您发现 iPhone 用户在变体 B 上的转化率实际上提高了 35%。iPhone 用户在您的受众中占很大比例,大约占所有访问者的 25%。 这意味着触发该细分市场的个性化体验可能是值得的并且投资回报率是积极的。
此外,Android 用户在变体 B 上的转化率实际上比对照组低 20%,在变体 C 上的转化率比对照组高 15%。Android 用户代表了 10% 的受众,所以同样是相当大的人口。

因此,您可以启动变体 B,因为它总体上获胜。 或者,您可以设置定位规则以触发 iPhone 用户接收变体 B 并触发 Android 用户接收变体 C。其他所有人都获得原始版本。
3. 探索性数据分析和相关性
您可以使用“业务逻辑”进行细分的最后一种方法是简单地探索您可以访问的数据并寻找细分特征和转换概率之间的相关性。
例如,您可能会发现 iPhone 用户的转化率更高。 或者在您的主页上观看视频的人。 或者来自堪萨斯州的男性 Android 用户,他们填写了一半的表单字段并在一周内返回 3 次。
这是这种方法的问题:查看足够多的细分,您会发现相关性。 这是一个信号与噪声的问题。
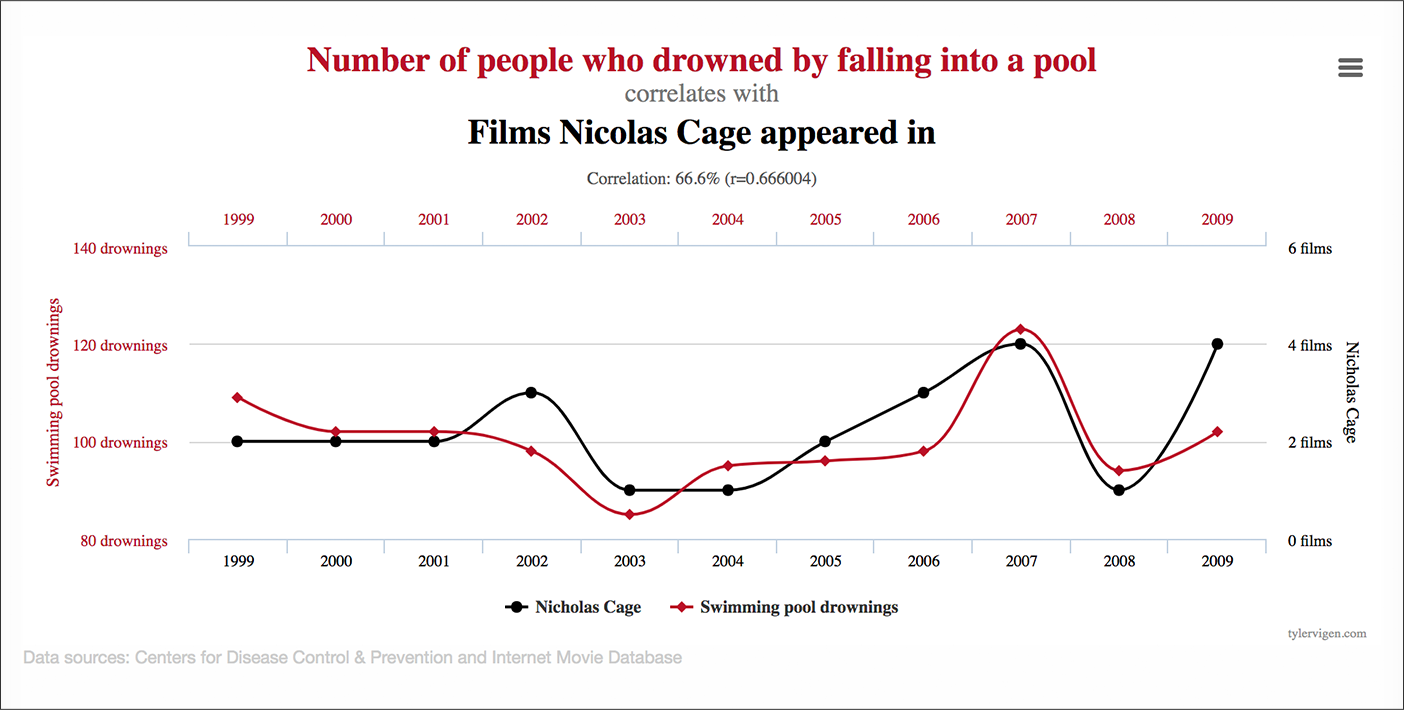
资料来源:泰勒维根
这种方法的更大问题是相关性并不意味着因果关系。
仅仅因为来自加利福尼亚的桌面回访者转化率更高并不意味着这是一个值得通过数据驱动的个性化定位的细分市场。
在业务逻辑领域,您最好的选择是运行实验并通过测试后细分发现高价值细分。 然后,您计算给定定位规则的投资回报率并运行仅针对该细分的后续实验。
然后,您可以梳理出因果关系和维护该定位规则的真实投资回报率。 有关此方法的更多信息,请阅读 Andrew Anderson 关于该主题的精彩演练。
预测分割
预测性细分(或另一个名称,“数据驱动”或“基于人工智能”的细分)旨在从细分定义和设置目标规则中消除人类直觉和手动数据分析。
您可以通过多种方式使用机器学习来定义细分。 这仅取决于您的目标是什么以及您希望通过这些细分市场实现什么。 在这里,我们将介绍三个关键方法:
- 聚类
- 分类
- 实验+预测池
1. 聚类
首先,如果您只是想识别和理解不同的用户角色或细分,聚类算法(或无监督机器学习)是一种用于根据共同特征将细分分组在一起的技术。
这是我几年前在 CXL 研究所从事的工作。
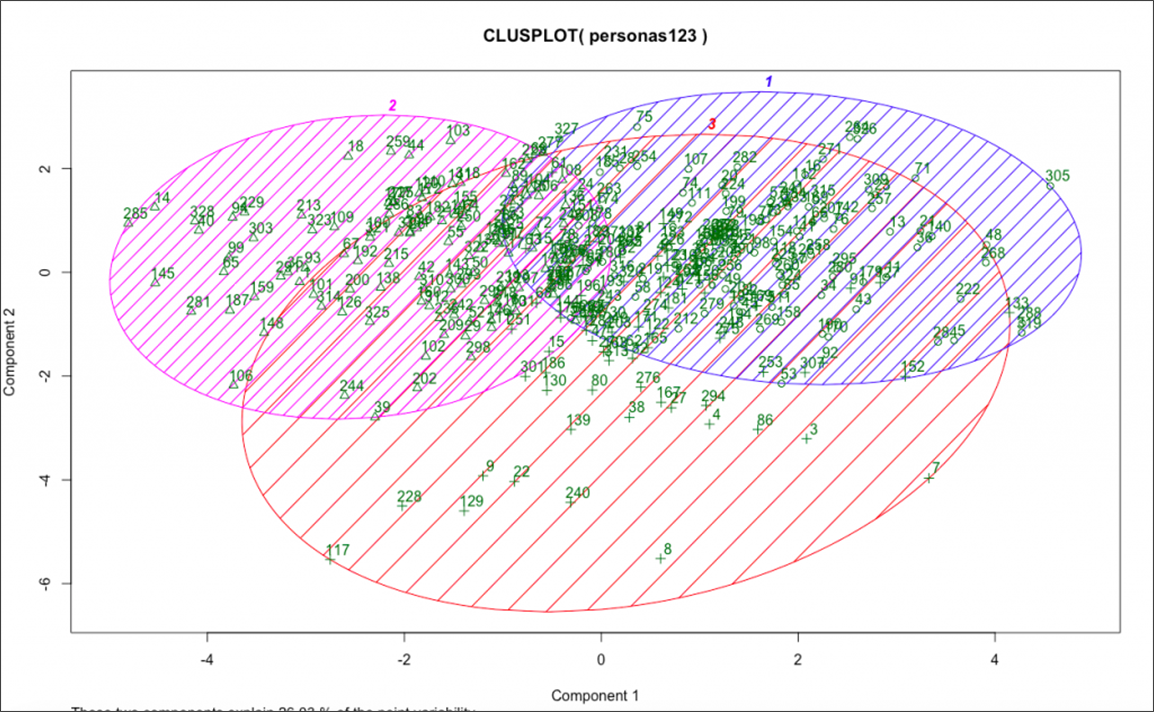
资料来源:CXL
我们向我们的客户群发送了调查问卷,其中包含规模响应、分类变量和开放式问题。 然后,我将他们的反应编码并对其运行 K 均值聚类算法。
这根据他们的反应大致确定了三个不同的部分。 然后,我对每个细分市场的定性见解进行分层,并采访了每个细分市场高度代表的个人。 这使我们能够深入了解我们现有的客户群以及他们不同的愿望、挑战和行为。
如果您想进行聚类,请知道它主要是探索性的和知识构建。 它不会告诉您将个性化营销传播发送到这些细分市场之一的投资回报率,也不会告诉您哪些细分市场可能会响应哪些体验。 例如,您可能会发现某部分电子邮件订阅者打开的电子邮件更多,并且具有更高的生命周期价值,但您仍然需要进行构思新内容和体验的创造性工作来进行测试。
但从数据驱动的个性化开始,这是一个很好的基础层。
您还需要一个可以编写 R 或 Python 代码的体面的分析师,或者至少需要一个像 Squark 这样的工具,它不允许进行代码预测分析。
2.分类
机器学习往往被划分为监督学习和无监督学习。 聚类算法是无监督的,分类算法是有监督的。
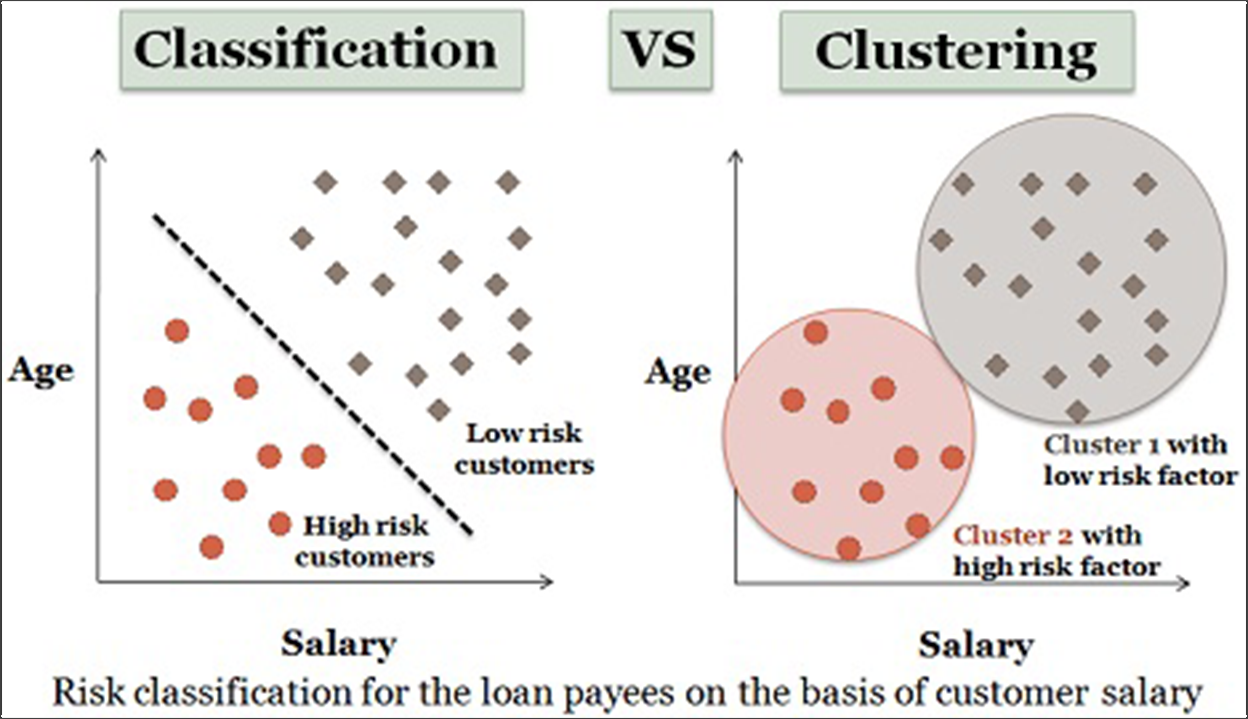
资料来源:技术差异
这意味着你有一个包含各种“特征”的数据集(在我们的例子中,这可能是设备类型、访问的页面、公司规模或我们可以收集的关于访问者的任何特征),然后你就会得到你想要的结果想要预测(在我们的例子中,是转化或收入或 LTV)。
有大量的方法和算法试图根据数据特征预测结果,其中一些包括线性回归、逻辑回归、随机森林和神经网络。
如果您想使用这种方法,您将需要一位出色的分析师,他可以将模型正确地拟合到您的数据中(否则预测将毫无用处),或者购买像 Squark 或 DataRobot 这样的工具。 这些工具使分析师和业务人员能够将不同的模型拟合到他们的数据中并预测结果,而无需自己编写算法。
3. 实验+预测分割
通常,寻找有利可图的用户细分的最佳方法是进行正常的受控实验过程并使用检测有前景的细分的工具(或分析方法)。
例如,Conductrics 向您展示了一个高度可解释的决策树,该树计算与您测试的每个变体相对应的各个细分市场的转化成功概率。
如果您的预测定位工具具有数据可视化功能,可以通过简单的插图向您显示您设置了哪些定位规则,以及这些规则的估计投资回报率和成功概率,则可以获得奖励积分。

资料来源:导体
这很酷,因为您不仅可以获得成功的概率,还可以根据其价值选择是否定位该细分市场。
来自肯塔基州农村的男性机器人回访者? 也许不值得设置新的定位规则。 但是,如果加利福尼亚人人口众多并且对特定体验的反应非常好,那么也许值得针对加利福尼亚人。
如何开始使用数据驱动的个性化
虽然深入研究数据驱动的个性化可能很诱人,但我建议慢慢开始。
任何给定的个性化规则的真正价值是未知的,而且增加个性化的边际回报往往低于引入的边际复杂性成本。
因此,我将介绍三种提高复杂性的个性化方法(假设“抓取”阶段只是整理您的数据以及提供个性化体验所需的资源/工具)。
第一阶段:步行
因此,在您投资预测性定位工具之前,您可能需要使用 Andrew Anderson 的方法,它可以是您正常实验计划的简单延续(旁注:没有流量进行实验?个性化不适合您。在那个流量水平上,边际回报是不值得的。而是大幅波动)。
以下是该方法的要点:
- 创建消息或体验的多次执行
- 通过受控实验为每个人提供所有优惠
- 按细分查看结果,并通过提供差异化体验来计算总收益。 确保在分析多个细分时纠正多重比较。
- 实时推送发现的最高创收机会(或仅针对该细分市场进行后续实验,并使用您在全部受众中测试的体验)。
您可以使用专用的 A/B 测试平台,也可以使用集成营销自动化平台。 后者将帮助您在多个渠道上个性化消息,而不仅仅是网络或应用程序,您可以提供个性化的产品推荐、增加收入和 CLTV、改进内容/产品发现等等。
第二阶段:运行
在这里取得一些胜利后,您可能希望投资于像 Squark 这样的无代码预测分析解决方案(或者如果您可以在内部编写算法,无论如何)。 基本过程如下所示:
确定您的成功指标
收集和清理您的数据,将您的数据集拆分为训练和测试数据。
确保数据中有无数维度或特征可用于预测结果。
确定哪些功能可以预测您的成功指标。
计算这些细分市场的个性化体验的投资回报率。 同样,如果人口太少,可能不值得。
现在是重要的部分:一旦您定义了可预测成功的特征或维度(例如回访者),您仍然没有弄清楚哪些体验更有可能在该细分市场上发挥作用。
艰苦的工作仍然存在:即创造新的伟大体验并进行实验以确定新体验的有效性和投资回报率。
您仍然需要在 WebEngage 等内容交付解决方案上进行投资,以针对特定细分市场。
第三阶段:飞行
最后,如果您想将预测性定位纳入您的正常实验和优化工作流程,您无法击败像 Conductrics 或 Dynamic Yield 这样的工具。 这些工具将帮助您识别细分市场并提供个性化体验,同时为您提供可解释的决策规则和 ROI 归因报告。
结论
在一个充斥着头条新闻和关于人工智能是灵丹妙药的会议讨论的世界中,您可能会惊讶地发现“数据驱动的个性化”或“预测细分”过程并不能为您完成所有工作。
它可以帮助您利用数据并节省大量时间(和错误)。 您可以更轻松、更准确地识别利润丰厚的细分市场,只要您拥有适当的数据并且在您需要时可以访问这些数据。
但是,它无法为您决定是否利用该细分市场。 您仍然需要权衡利弊、成本和收益。
然而幸运的是,识别和分组细分的过程从未如此简单,交付和管理多种不同的体验也从未如此简单。 营销自动化工具可以插入您的数据源或 CRM。 您可以通过任何您想要的渠道(付费广告、社交、网络、推送、电子邮件等)管理和提供无限的个性化体验。
现在是成为数据驱动营销人员的好时机。
 i图片来源:WebEngage
i图片来源:WebEngage为您的业务利用自动化的力量
具有预测细分功能和优质的客户支持!