
Segmentacja predykcyjna: pierwsze kroki w personalizacji opartej na danych
Opublikowany: 2021-12-30Jak mówi Avinash Kaushik: „Wszystkie dane zagregowane to bzdury”. Segmentacja i personalizacja oparta na danych to jedne z najpotężniejszych narzędzi, jakimi dysponują marketerzy i menedżerowie produktów.
Zamiast traktować każdego odwiedzającego lub użytkownika w ten sam sposób, możesz dostarczać doświadczenia oparte na unikalnych cechach behawioralnych, psychograficznych, demograficznych i firmograficznych użytkowników.
Myślę, że w tym momencie wszyscy są przyzwyczajeni do idei segmentacji, a także jej logicznego rozszerzenia – personalizacji.
W rzeczywistości, zgodnie z badaniem Evergage, „92% marketerów zgłosiło stosowanie technik personalizacji w swoich działaniach marketingowych, jednak 55% marketerów uważa, że nie dysponuje wystarczającymi danymi klientów, aby wdrożyć skuteczną personalizację”.
Teoria stojąca za segmentacją i personalizacją jest często bardziej różowa niż rzeczywistość jej wykonania. W rzeczywistości do działania programu personalizacji potrzebne są trzy podstawowe komponenty.
W tym artykule omówię te podstawowe elementy, a następnie wyjaśnię różnicę między segmentacją tradycyjną a segmentacją predykcyjną (napędzaną przez uczenie maszynowe).
- Co to jest segmentacja predykcyjna?
- Dane, treść i reguły kierowania: podstawy personalizacji
- Dane
- Zawartość
- Logika kierowania
- Segmentacja predykcyjna a logika biznesowa
- Segmentacja logiki biznesowej
- Personalizacja na podstawie opinii
- Segmentacja posttestowa
- Eksploracyjna analiza danych i korelacje
- Segmentacja predykcyjna
- Grupowanie
- Klasyfikacja
- Eksperymentowanie + segmentacja predykcyjna
- Jak zacząć korzystać z personalizacji opartej na danych
- Etap pierwszy: spacer
- Etap drugi: biegnij
- Etap trzeci: latać
Pod koniec tego artykułu dowiesz się, jak wdrożyć personalizację opartą na danych i segmentację predykcyjną.
Po pierwsze, co to jest „segmentacja predykcyjna”?
Segmentacja na wysokim poziomie to proces dzielenia czegoś na oddzielne części lub sekcje.
Źródło: CXL
Kiedy mówimy „segmentacja”, zwykle mamy na myśli „segmentację rynku” lub „segmentację klientów”, a może „segmentację behawioralną”. Ten rodzaj segmentacji to proces identyfikowania i definiowania cech, które oddzielają jedną podgrupę lub sekcję klientów od drugiej.
Odbywa się to zwykle za pomocą logiki biznesowej. Na przykład moglibyśmy powiedzieć, że użytkownicy urządzeń mobilnych stanowią odrębny segment od użytkowników komputerów stacjonarnych. Lub częściej możemy pogrupować odwiedzających według reprezentacji geograficznej: użytkownicy NAM vs EMEA.
Segmentacja predykcyjna ma miejsce, gdy identyfikujesz klastry użytkowników programistycznie lub przy użyciu uczenia maszynowego. Czytaj więcej - przez @webengage Kliknij, aby tweetowaćW tej metodzie zazwyczaj masz cel lub wynik, który śledzisz, i możesz pracować wstecz, aby zidentyfikować wspólne cechy wspólne dla podgrup w odniesieniu do tego celu.
Na przykład możesz śledzić „konwersje związane z rejestracją listy e-mailowej” na swoim blogu. Segmentacja przewidująca może odkryć, że istnieją odrębne grupy, które zachowują się konsekwentnie podczas odwiedzania Twojego bloga.
Jedna grupa użytkowników mobilnych spędza bardzo mało czasu w witrynie i szybko się odbija. Inna grupa użytkowników komputerów stacjonarnych z kanałów organicznych spędza bardzo mało czasu i odbija się w podobnym tempie.
Możesz odkryć te segmenty samodzielnie, korzystając z analizy danych, ale narzędzia do segmentacji predykcyjnej starają się zidentyfikować i pogrupować te segmenty użytkowników. Zazwyczaj takie narzędzia próbują przewidzieć działania, które te segmenty wykonają, aby można było uruchomić reguły personalizacji.
Dane, treść i reguły kierowania: podstawy personalizacji
Aby skutecznie dostarczać spersonalizowane doświadczenia różnym segmentom użytkowników, potrzebujesz trzech komponentów:
- Dane
- Zawartość
- Logika kierowania
1. Dane
Dane stanowią podstawę wszystkiego, jeśli chodzi o segmentację i personalizację.
Jeśli nie masz danych, których potrzebujesz, gdy ich potrzebujesz, nie możesz zidentyfikować segmentów użytkowników, nie mówiąc już o uruchamianiu dla nich spersonalizowanych doświadczeń. Dodatkowo, jeśli Twoje dane są nieprecyzyjne i/lub niekompletne, Twoja personalizacja może być nieskuteczna.
Dlatego zanim zrobisz jakąkolwiek segmentację, potwierdź te trzy rzeczy:
- Czy mierzysz wszystko, czego potrzebujesz? Czy masz odpowiednio ustawione cele, niestandardowe wymiary itp.? Czy Twoje dane są „kompletne”?
- Czy Twoje dane są godne zaufania? Nie musi być w 100% „dokładny”, ale czy jest spójny i precyzyjny w logowaniu?
- Czy Twoje dane są dostępne, kiedy ich potrzebujesz? Ile czyszczenia i przygotowań musisz zrobić, aby uzyskać wgląd w swoje dane? Czy są agregowane i połączone z innymi źródłami (społecznościowe, internetowe, e-mail, dane klientów)? Czy jest przechowywany w miejscu, które można natychmiast wykorzystać i przeanalizować?
Co więcej, będziesz chciał połączyć swoje źródła danych z jakąś scentralizowaną tabelą pamięci. W dzisiejszych czasach platformy danych klientów (CDP), takie jak Hull.io i Segment, to nazwa gry, ale możesz również używać CRM-ów, takich jak HubSpot, do centralizacji, przechowywania i operacjonalizacji danych marketingowych i danych klientów.
Stają się one ważne, gdy łączysz dane przed zakupem z danymi po zakupie. Dzięki temu możesz identyfikować segmenty na podstawie ważnych wskaźników biznesowych, takich jak ich przewidywana wartość od początku istnienia lub wskaźnik rezygnacji.
2. Treść
Część treści jest znacznie łatwiejsza do groka.
Zasadniczo, jeśli chcesz dokonać personalizacji, najpierw zdefiniuj segment użytkowników, korzystając ze swoich źródeł danych. Następnie musisz również stworzyć nowe środowisko, które będzie dostarczane do tego segmentu.
Tworzenie nowych treści lub doświadczeń wymaga zasobów, zarówno pod względem czasu, jak i pieniędzy. Co więcej, im więcej treści i doświadczeń dostarczasz i którymi zarządzasz, tym większą złożoność tworzysz w swojej organizacji.
Matt Gershoff, dyrektor generalny Conductrics, podał na ten temat świetną analogię w podcaście Digital Analytics Power Hour.
Opisał personalizację jako zasadniczo tworzenie wieloświata.
Prowadzenie jednej wersji witryny dla wszystkich jest jak posiadanie jednego wszechświata, a być może test A/B pozwala przeprowadzić analizę alternatywną, aby zobaczyć, jak wyglądałoby życie w równoległym wszechświecie (lub „wersji B”).
W teście A/B chcesz sprawdzić, czy wersja B jest lepszym „wszechświatem” dla użytkowników określonych przez konwersję celu, a jeśli okaże się, że jest rzeczywiście optymalna, zamykasz wszechświat A (pierwotny) i ponownie ponownie wejść do pojedynczego wszechświata.
Jednak wiele wariantów treści dostarczanych do wielu unikalnych segmentów jest jak utrzymywanie otwartych kilku odrębnych światów, w których doświadczenia są unikalne dla tych segmentów.
Magia polega na tym, że możesz zwiększyć wartość swojej witryny poprzez zwiększenie wartości każdego segmentu i ich doświadczenia, ale możesz zrozumieć, jak otwieranie tysięcy „wszechświatów” byłoby kosztowne zarówno pod względem tworzenia, jak i zarządzania nimi. doświadczenie.
3. Logika kierowania
Wreszcie, jeśli masz przydatne dane i zasoby do tworzenia treści, musisz określić, w jaki sposób uruchamiasz logikę kierowania lub personalizacji w segmentach użytkowników.
W ten sposób łączysz dane z doświadczeniami.
Możesz użyć logiki biznesowej (zakładając, że pewne segmenty powinny mieć określone wartości – możesz nawet przetestować je A/B) lub wprowadzić uczenie maszynowe i segmentację predykcyjną/RFM, aby podzielić użytkowników na różne grupy – najbardziej wartościowi użytkownicy, którzy wkrótce odejdą użytkownicy, użytkownicy nieaktywni itp. Korzystając z segmentacji RFM, możesz również dowiedzieć się, które segmenty użytkowników reagują w bardziej zróżnicowany sposób na różne treści.
Technicznie rzecz biorąc, na tym etapie potrzebny jest system dostarczania treści, który jest albo połączony z bazą danych, albo może być zintegrowany i pobierany z bazy danych. WebEngage to pełny system operacyjny do automatyzacji marketingu i retencji, który może bezproblemowo łączyć się z Twoim CRM i pomagać w angażowaniu użytkowników na zasadzie 1:1 w różnych kanałach, takich jak e-mail, SMS, WhatsApp, Facebook, Mobile i Web Push i nie tylko.
Ponownie jednak, im więcej reguł kierowania uruchomisz, tym bardziej złożony zostanie system. Istnieje więc kompromis w ROI, który możesz wykorzystać, kierując się do danego segmentu i marginalnej złożoności wprowadzonej do systemu. Łatwo jest scalić imiona z niestandardowymi tokenami e-mail (większość narzędzi pocztowych robi to teraz po wyjęciu z pudełka), ale to nie mówi o ROI tej reguły kierowania.
Źródło: GMass
Dlatego zamiast ustawiać mnóstwo personalizacji tylko dlatego, że możesz, powinieneś spojrzeć na to strategicznie i metodologicznie, określając ROI i skuteczność kierowania na dany segment.
Segmentacja predykcyjna a logika biznesowa
Porzuciłem już trochę żargonu w odniesieniu do logiki kierowania — na przykład „logika biznesowa” i „segmentacja predykcyjna”.
Logika biznesowa zasadniczo stoi po drugiej stronie spektrum od „personalizacji opartej na danych”, „segmentacji predykcyjnej” czy „personalizacji opartej na uczeniu maszynowym”. Ale obie te metody mają ten sam cel: identyfikacja segmentów, które należy traktować spersonalizowanymi doświadczeniami.
Zdefiniujmy te dwa bieguny i czym się różnią.
Segmentacja logiki biznesowej
„Logika biznesowa” to zwykła metoda, za pomocą której ludzie wybierają reguły kierowania. W tej metodzie zasadniczo decydujesz, które segmenty mają największe możliwości wpływu, korzystając z danych historycznych i korelacji lub logiki biznesowej, strategii lub opinii. Istnieją trzy główne sposoby tworzenia reguł kierowania w logice biznesowej:
- Personalizacja na podstawie opinii
- Segmentacja posttestowa
- Analiza danych rozpoznawczych
1. Personalizacja na podstawie opinii
Na przykład możesz po prostu chcieć uniknąć uruchamiania inwazyjnego wyskakującego okienka na telefonie komórkowym z czysto subiektywnych powodów. To nie jest dobre doświadczenie użytkownika, więc tego unikasz. Nie potrzebujesz nawet danych, aby przewidzieć reakcję tego segmentu.
Odmienne traktowanie użytkowników mobilnych to powszechne zastosowanie personalizacji
Jest to metoda, z której korzysta zdecydowana większość firm, deklarując, że przeprowadzają segmentację lub personalizację opartą na danych. Swobodnie odgadują, który segment pozytywnie zareaguje na jakie doświadczenie i personalizują je na podstawie swojej opinii.
2. Segmentacja posttestowa
Mniej powszechne (ale bardziej skuteczne) jest przeprowadzanie eksperymentu, a następnie przeprowadzanie analizy po teście, aby dowiedzieć się, czy pewne odmiany miały większy wpływ na niektóre segmenty.
Wyobraź sobie, że przeprowadzasz test w procesie realizacji transakcji w handlu elektronicznym.
Decydujesz się przetestować wiele wariantów – jeden wariant z serią symboli zaufania i bezpieczeństwa, jeden z wyskakującym okienkiem, które używa pilnych wiadomości, a drugi bez symboli (wersja oryginalna).
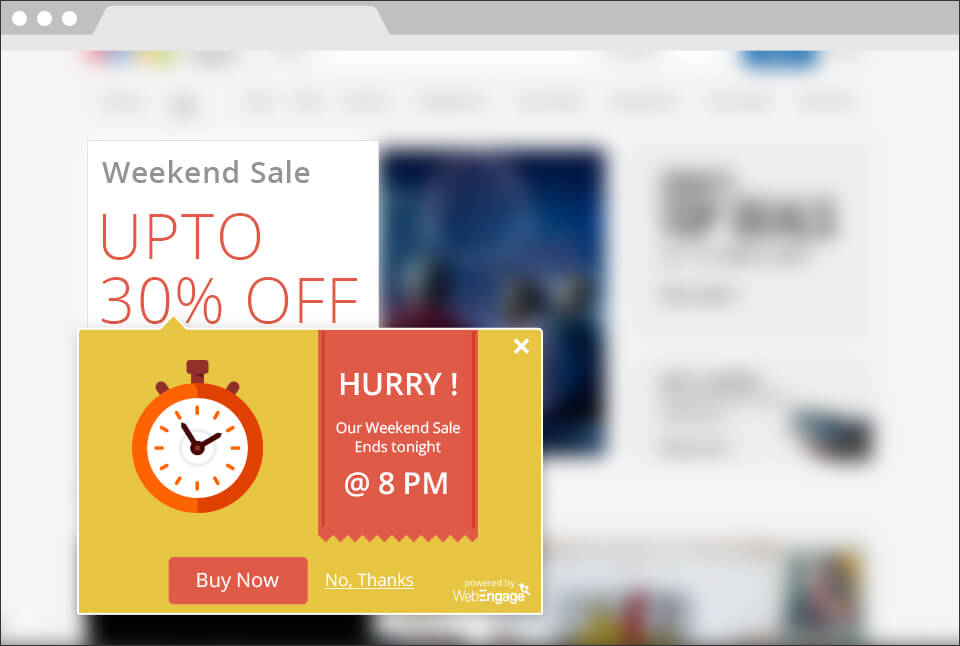
Po przeanalizowaniu eksperymentu ustaliłeś, że wersja B „wygrała” i ma szacunkowy wzrost na poziomie 10%. Wielka wygrana.
Jednak zagłębiasz się w dane i patrzysz na segmenty o dużym wpływie, takie jak użytkownicy mobilni a użytkownicy komputerów stacjonarnych, powracający a nowi użytkownicy oraz odwiedzający ze Stanów Zjednoczonych a odwiedzający spoza USA.
W ten sposób odkryłeś, że użytkownicy iPhone'a w rzeczywistości dokonywali konwersji o 35% lepiej w wariancie B. Użytkownicy iPhone'a stanowią znaczny procent Twoich odbiorców, około 25% wszystkich odwiedzających. Oznacza to, że uruchomienie spersonalizowanego doświadczenia w tym segmencie może być opłacalne i mieć pozytywny zwrot z inwestycji.

Co więcej, użytkownicy Androida faktycznie przekonwertowali 20% mniej w wariancie B i 15% więcej niż w przypadku kontroli w wariancie C. Użytkownicy Androida stanowią 10% Twoich odbiorców, więc znowu jest to dość duża populacja.
Więc możesz po prostu uruchomić wariant B, ponieważ wygrał łącznie. Alternatywnie możesz skonfigurować reguły kierowania, aby użytkownicy iPhone'a otrzymali wariant B, a użytkownicy Androida – wariant C. Wszyscy pozostali otrzymają oryginał.
3. Eksploracyjna analiza danych i korelacje
Ostatnim sposobem wykorzystania „logiki biznesowej” do segmentacji jest po prostu eksploracja danych, do których masz dostęp, i szukanie korelacji między cechami segmentu a prawdopodobieństwem konwersji.
Może się na przykład okazać, że użytkownicy iPhone'a konwertują więcej. Lub osoby, które oglądają wideo na Twojej stronie głównej. Lub męskich użytkowników Androida z Kansas, którzy wypełnili połowę pól formularza i wrócili 3 razy w ciągu tygodnia.
Oto problem z tym podejściem: spójrz na wystarczającą liczbę segmentów, a znajdziesz korelację. To problem z sygnałem a szumem.
Źródło: Tyler Vigen
Większym problemem związanym z tym podejściem jest to, że korelacja nie implikuje związku przyczynowego.
To, że osoba powracająca z komputerów stacjonarnych z Kalifornii uzyskuje wyższą konwersję, nie oznacza, że jest to segment, na który warto kierować reklamy poprzez personalizację opartą na danych.
Najlepszym rozwiązaniem w świecie logiki biznesowej jest przeprowadzanie eksperymentów i odkrywanie segmentów o wysokiej wartości poprzez segmentację po testach. Następnie obliczasz ROI danej reguły kierowania i przeprowadzasz eksperyment kontrolny, którego celem jest tylko ten segment.
Następnie możesz wydobyć przyczynowość i prawdziwy zwrot z inwestycji w utrzymanie tej reguły kierowania. Aby uzyskać więcej informacji na temat tego podejścia, przeczytaj wspaniały przewodnik Andrew Andersona na ten temat.
Segmentacja predykcyjna
Segmentacja predykcyjna (lub pod inną nazwą, segmentacja „oparta na danych” lub „oparta na sztucznej inteligencji”) ma na celu usunięcie ludzkiej intuicji i ręcznej analizy danych z definicji segmentów i ustalania zasad kierowania.
Istnieje kilka sposobów definiowania segmentów za pomocą uczenia maszynowego. Zależy to tylko od Twoich celów i tego, co masz nadzieję osiągnąć dzięki tym segmentom. Tutaj omówimy trzy kluczowe metody:
- Grupowanie
- Klasyfikacja
- Eksperyment + łączenie predykcyjne
1. Klastrowanie
Po pierwsze, jeśli chcesz po prostu zidentyfikować i zrozumieć różne osoby lub segmenty użytkowników, algorytmy klastrowania (lub nienadzorowane uczenie maszynowe) to technika używana do grupowania segmentów na podstawie wspólnych cech.
To jest coś, nad czym pracowałem w CXL Institute kilka lat temu.
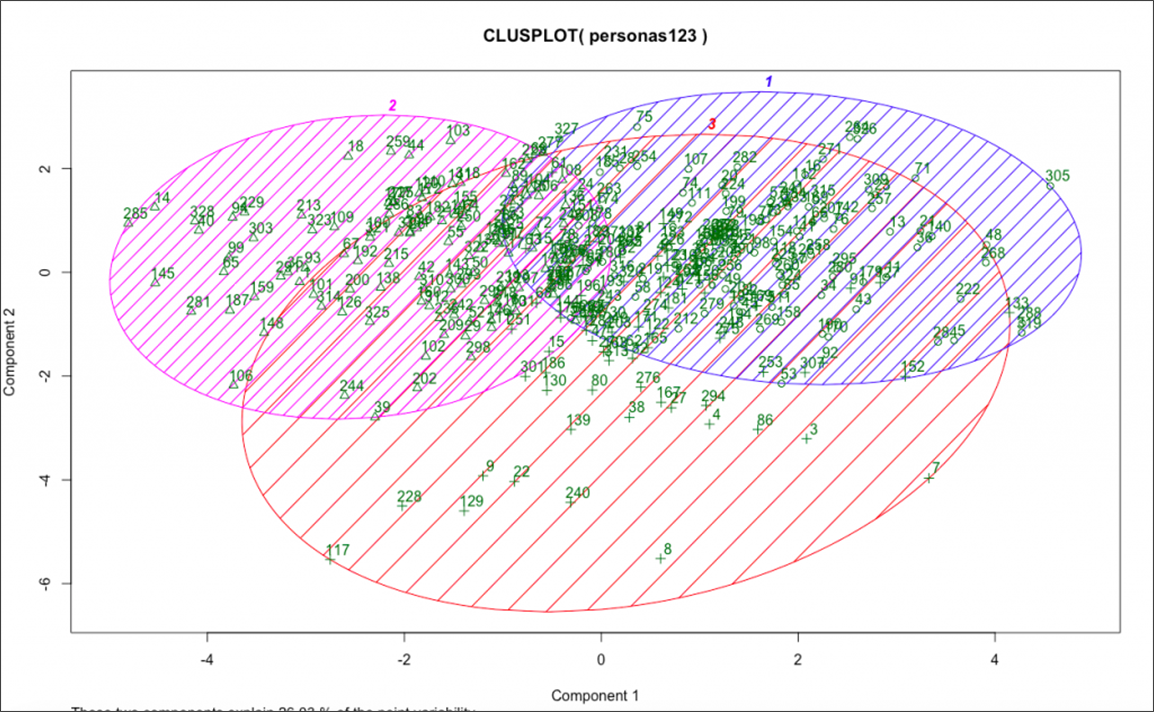
Źródło: CXL
Wysłaliśmy ankiety do naszej bazy klientów z mieszanką odpowiedzi skali, zmiennych kategorycznych i pytań otwartych. Następnie skodyfikowałem ich odpowiedzi i uruchomiłem na nich algorytm grupowania K Means.
Na podstawie ich odpowiedzi zidentyfikowano około trzech odrębnych segmentów. Następnie omówiłem jakościowe spostrzeżenia z każdego z tych segmentów i przeprowadziłem wywiady z osobami wysoce reprezentatywnymi dla każdego segmentu. To pozwoliło nam dogłębnie zrozumieć naszą obecną bazę klientów oraz ich różne pragnienia, wyzwania i zachowania.
Jeśli chcesz robić klastry, wiedz, że jest to głównie eksploracja i budowanie wiedzy. Nie powie Ci ROI z wysyłania spersonalizowanej komunikacji marketingowej do jednego z tych segmentów, ani nie powie, które segmenty prawdopodobnie zareagują na które doświadczenia. Na przykład może się okazać, że pewien segment subskrybentów wiadomości e-mail otwiera więcej e-maili i ma wyższą wartość w całym okresie życia, ale nadal musisz wykonać twórczą pracę polegającą na wymyślaniu nowych treści i doświadczeń do przetestowania.
Ale jest to dobra warstwa podstawowa, aby zacząć od personalizacji opartej na danych.
Będziesz także potrzebował porządnego analityka, który potrafi kodować w R lub Pythonie lub przynajmniej narzędzia takiego jak Squark, które nie pozwala na analizę predykcyjną kodu.
2. Klasyfikacja
Uczenie maszynowe dzieli się zwykle na uczenie nadzorowane i nienadzorowane. Tam, gdzie algorytmy klastrowania nie są nadzorowane, nadzorowane są algorytmy klasyfikacji.
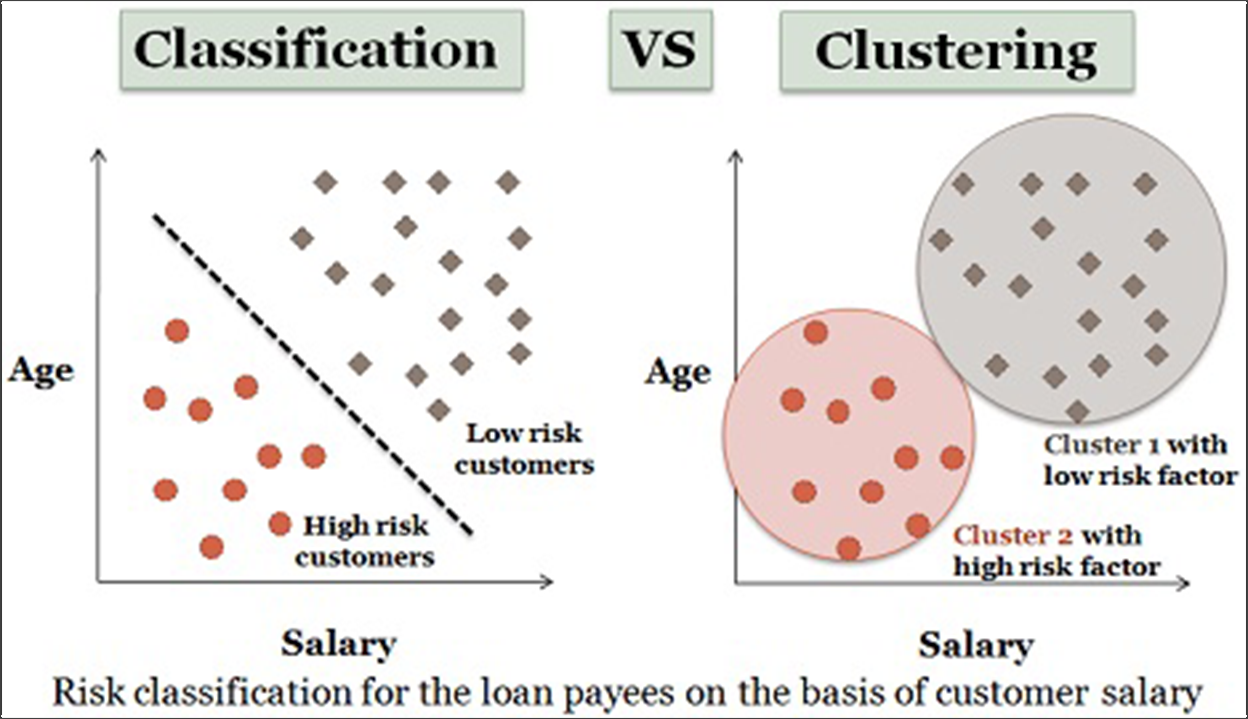
Źródło: różnice technologiczne
Oznacza to, że masz zbiór danych, który zawiera różne „funkcje” (w naszym przypadku mogą to być takie rzeczy, jak typ urządzenia, odwiedzane strony, wielkość firmy lub dowolna charakterystyka, którą możemy zebrać na temat odwiedzających), a następnie otrzymujesz wyniki, które chcesz przewidzieć (w naszym przypadku konwersje lub przychody lub LTV).
Istnieje ogromna ilość metodologii i algorytmów, które próbują przewidywać wyniki na podstawie cech danych, z których niektóre obejmują regresje liniowe, regresje logistyczne, losowe lasy i sieci neuronowe.
Jeśli chcesz skorzystać z tej metody, będziesz potrzebować świetnego analityka, który potrafi odpowiednio dopasować model do twoich danych (w przeciwnym razie prognozy są bezużyteczne) lub kupić narzędzie takie jak Squark lub DataRobot. Narzędzia te umożliwiają analitykom i ludziom biznesowym dopasowywanie różnych modeli do swoich danych i przewidywanie wyników bez kodowania samych algorytmów.
3. Eksperymentowanie + segmentacja predykcyjna
Często najlepszym sposobem na znalezienie lukratywnych segmentów użytkowników jest przejście do normalnego toku kontrolowanych eksperymentów i użycie narzędzia (lub metody analizy), która wykrywa obiecujące segmenty.
Na przykład Conductrics pokazuje wysoce interpretowalne drzewo decyzyjne, które oblicza prawdopodobieństwo sukcesu konwersji dla poszczególnych segmentów, które odpowiadają każdemu testowanemu wariantowi.
Dodatkowe punkty, jeśli narzędzie kierowania predykcyjnego zawiera wizualizację danych, która pokazuje na prostych ilustracjach, jakie reguły kierowania skonfigurowałeś, a także szacowany zwrot z inwestycji i prawdopodobieństwo sukcesu tych reguł.

Źródło: Przewodniki
Jest to fajne, ponieważ nie tylko otrzymujesz prawdopodobieństwo sukcesu, ale możesz wybrać, czy kierować reklamy na ten segment, na podstawie jego wartości.
Czy mężczyźni wracają z Androida z wiejskiego Kentucky? Może nie warto konfigurować nowej reguły kierowania. Ale może warto zaatakować Kalifornijczyków, jeśli stanowią dużą populację i bardzo przychylnie reagują na dane doświadczenie.
Jak zacząć korzystać z personalizacji opartej na danych
Chociaż może być kuszące, aby zagłębić się w głęboką stronę personalizacji opartej na danych, polecam zacząć powoli.
Nie wiadomo, jaka jest prawdziwa wartość danej reguły personalizacji, a często krańcowe zwroty zwiększonej personalizacji są niższe od wprowadzonego krańcowego kosztu złożoności.
Dlatego przedstawię trzy podejścia do personalizacji zwiększającej się złożoności (i załóżmy, że etap „indeksowania” to po prostu uporządkowanie danych i zasobów/narzędzi wymaganych do dostarczania spersonalizowanych doświadczeń).
Etap pierwszy: spacer
Dlatego zanim zainwestujesz w narzędzie do predykcyjnego kierowania, możesz skorzystać z metodologii Andrew Andersona, która może być prostą kontynuacją normalnego programu eksperymentalnego (uwaga: nie masz ruchu na eksperymenty? Personalizacja nie jest dla Ciebie. marginalne zwroty nie będą tego warte na tym poziomie ruchu. Zamiast tego uderzaj w duże huśtawki).
Oto sedno metodologii:
- Twórz wiele egzekucji wiadomości lub doświadczenia
- Podaj wszystkie oferty wszystkim za pomocą kontrolowanego eksperymentu
- Spójrz na wyniki według segmentów i oblicz całkowity zysk, dając zróżnicowane doświadczenie. Upewnij się, że uwzględniłeś wielokrotne porównania podczas analizy wielu segmentów.
- Wykorzystaj na żywo największą znalezioną możliwość przynoszącą przychody (lub przeprowadź eksperyment kontrolny tylko na tym segmencie z doświadczeniami, które przetestowałeś na pełnej grupie odbiorców).
Możesz skorzystać z dedykowanych platform do testów A/B lub skorzystać ze zintegrowanej platformy do automatyzacji marketingu. Ta ostatnia pomoże Ci spersonalizować wiadomości w wielu kanałach, nie tylko w sieci lub w aplikacji, i możesz oferować spersonalizowane rekomendacje produktów, zwiększyć przychody i CLTV, poprawić odkrywanie treści/produktów i wiele więcej.
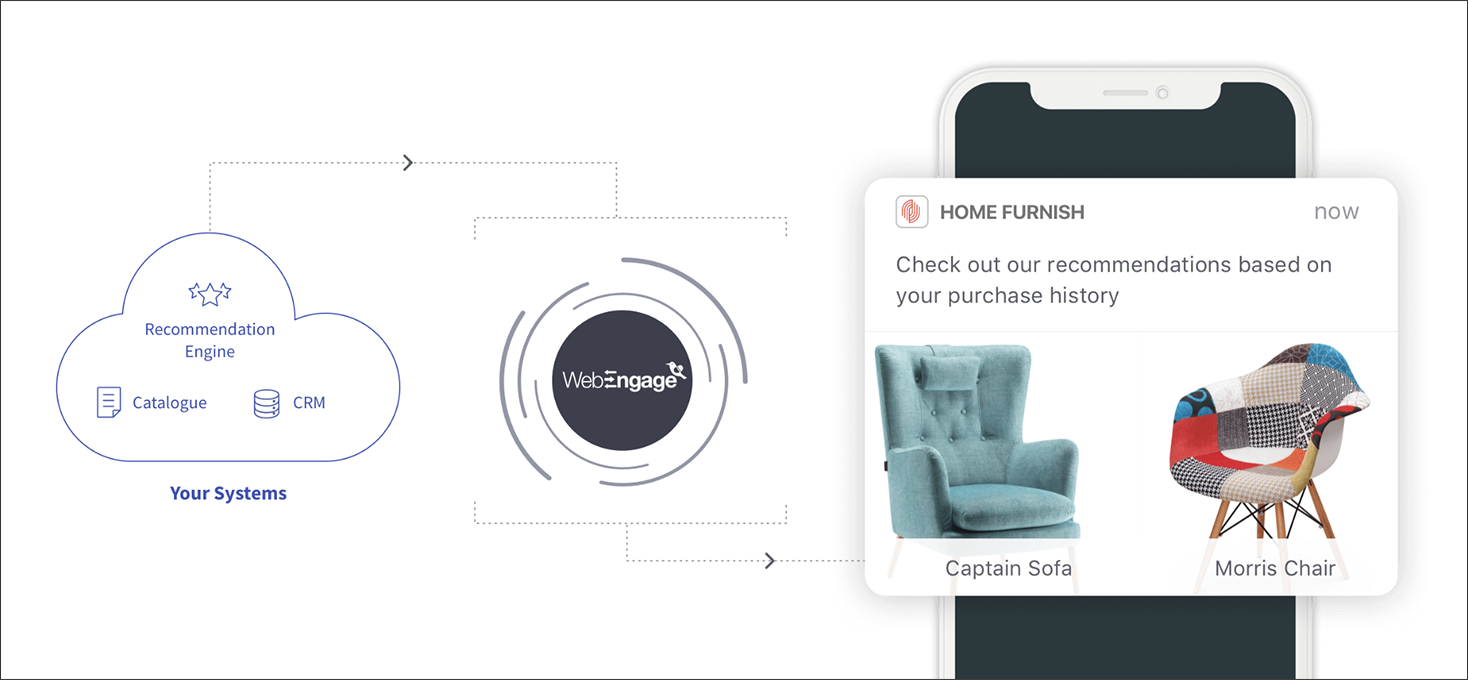
Etap drugi: biegnij
Po zdobyciu kilku wygranych możesz chcieć zainwestować w rozwiązanie do analizy predykcyjnej bez kodu, takie jak Squark (lub jeśli możesz zakodować algorytmy we własnym zakresie, za wszelką cenę). Podstawowy proces wygląda mniej więcej tak:
Określ swoje wskaźniki sukcesu
Zbieraj i oczyszczaj dane, dzieląc zestaw danych na dane treningowe i testowe.
Upewnij się, że masz w swoich danych mnóstwo wymiarów lub funkcji, których można użyć do przewidzenia wyniku.
Określ, które funkcje pozwalają przewidzieć Twoje wskaźniki sukcesu.
Oblicz ROI personalizacji doświadczeń dla tych segmentów. Ponownie, jeśli populacja jest zbyt mała, może nie być tego warta.
Teraz ważna część: po zdefiniowaniu funkcji lub wymiaru, który jest predyktorem sukcesu (powiedzmy, że są to powracający użytkownicy), nadal nie wiesz, które doświadczenia z większym prawdopodobieństwem zadziałają w tym segmencie.
Nadal pozostaje ciężka praca: czyli tworzenie nowych wspaniałych doświadczeń i przeprowadzanie eksperymentów w celu określenia skuteczności i ROI z nowych doświadczeń.
Nadal będziesz chciał zainwestować w rozwiązanie do dostarczania treści, takie jak WebEngage, aby kierować reklamy do określonych segmentów.
Etap trzeci: latać
Wreszcie, jeśli chcesz włączyć kierowanie predykcyjne do normalnego procesu eksperymentowania i optymalizacji, nie możesz pokonać takich narzędzi jak Conductrics lub Dynamic Yield. Narzędzia te pomogą Ci zidentyfikować segmenty i zapewnić spersonalizowane doświadczenia, zapewniając jednocześnie zrozumiałe reguły decyzyjne i raporty atrybucji ROI.
Wniosek
W świecie zdominowanym przez nagłówki i wykłady na konferencjach, w których sztuczna inteligencja jest srebrną kulą, możesz być zaskoczony, gdy dowiesz się, że proces „personalizacji opartej na danych” lub „segmentacji predykcyjnej” nie wykonuje całej pracy za Ciebie.
Pomoże Ci wykorzystać Twoje dane i zaoszczędzić dużo czasu (i błędów). Możesz łatwiej i dokładniej zidentyfikować dochodowe segmenty, o ile masz odpowiednie dane i są one dostępne, gdy ich potrzebujesz.
Nie może jednak podjąć za Ciebie decyzji, czy wykorzystać ten segment. Nadal będziesz musiał rozważyć zalety i wady, koszty i korzyści.
Na szczęście jednak proces identyfikowania i grupowania segmentów nigdy nie był łatwiejszy, ani też dostarczanie i zarządzanie wieloma różnymi doświadczeniami nigdy nie było łatwiejsze. Narzędzie do automatyzacji marketingu można podłączyć do źródła danych lub CRM. Możesz zarządzać i dostarczać nieograniczoną liczbę spersonalizowanych doświadczeń za pośrednictwem dowolnego kanału – płatnych reklam, społecznościowych, internetowych, push, e-mail itp.
To świetny czas na bycie marketerem opartym na danych.
 Źródło obrazu: WebEngage
Źródło obrazu: WebEngageWykorzystaj moc automatyzacji w swojej firmie
Z predykcyjnymi funkcjami segmentacji i wysokiej jakości obsługą klienta!