
預測分割:真正的數據驅動個性化入門
已發表: 2021-12-30正如 Avinash Kaushik 所說,“所有匯總的數據都是垃圾。” 細分和數據驅動的個性化是營銷人員和產品經理可以使用的一些最強大的工具。
您可以根據用戶獨特的行為、心理、人口統計和企業特徵來提供體驗,而不是以相同的方式對待每個訪問者或用戶。
在這一點上,我認為每個人都接受了分割的想法,以及它的邏輯擴展——個性化。
事實上,根據 Evergage 的一項研究,“92% 的營銷人員報告說他們在營銷中使用了個性化技術,但 55% 的營銷人員認為他們沒有足夠的客戶數據來實施有效的個性化。”
細分和個性化背後的理論往往比其執行的現實更樂觀。 實際上,您需要三個核心組件才能使個性化程序發揮作用。
本文將介紹這些核心要素,然後我將解釋傳統分割和預測分割(由機器學習驅動)之間的區別。
- 什麼是預測分割?
- 數據、內容和定位規則:個性化基礎
- 數據
- 內容
- 目標邏輯
- 預測細分與業務邏輯
- 業務邏輯分割
- 意見驅動的個性化
- 測試後分割
- 探索性數據分析和相關性
- 預測分割
- 聚類
- 分類
- 實驗+預測分割
- 如何開始使用數據驅動的個性化
- 第一階段:步行
- 第二階段:運行
- 第三階段:飛行
在本文結束時,您將對如何實現數據驅動的個性化和預測細分有一個很好的了解。
首先,什麼是“預測分割”?
細分,在高層次上,是將某物分成單獨的部分或部分的過程。
資料來源:CXL
當我們說“細分”時,我們通常指的是“市場細分”或“客戶細分”,或者可能是“行為細分”。 這種類型的細分是識別和定義將一個子組或客戶部分與另一個客戶區分開來的特徵的過程。
這通常通過業務邏輯完成。 例如,我們可以說移動設備用戶是與桌面用戶分開的部分。 或者更常見的是,我們可以按地理代表性對訪問者進行分組:NAM 與 EMEA 用戶。
預測分割是指您以編程方式或使用機器學習識別用戶集群。 閱讀更多 - 通過@webengage點擊鳴叫在這種方法中,您通常有一個要跟踪的目標或結果,並且您可以向後工作以確定子組與該目標共享的共同特徵。
例如,您可以在博客上跟踪“電子郵件列表註冊轉化”。 預測性細分可能會發現在訪問您的博客時存在行為一致的不同組。
一組移動訪問者往往在網站上花費的時間很少,並且跳出率很高。 另一組來自自然渠道的桌面訪問者花費的時間很少,並且以同樣高的速度跳出。
您可以使用數據分析自行發現這些細分,但預測細分工具會尋求識別和聚類這些用戶細分。 通常,像這樣的工具會嘗試預測這些細分將採取的行動,以便您可以觸發個性化規則。
數據、內容和定位規則:個性化基礎
要成功地向不同的用戶群提供個性化體驗,您需要三個組件:
- 數據
- 內容
- 目標邏輯
1. 數據
在細分和個性化方面,數據是一切的基礎。
如果您在需要時沒有所需的數據,則無法識別用戶細分,更不用說為他們觸發個性化體驗了。 此外,如果您的數據不准確和/或不完整,您的個性化可能無效。
因此,在您進行任何細分之前,請確認以下三件事:
- 你測量你需要的一切嗎? 您是否正確設置了目標、自定義維度等? 您的數據“完整”嗎?
- 你的數據可信嗎? 它不需要 100%“準確”,但它的日誌記錄是否一致和精確?
- 您的數據可以在需要時訪問嗎? 您需要做多少清理和準備工作才能從數據中獲得洞察力? 它是否聚合併連接到其他來源(社交、網絡、電子郵件、客戶數據)? 是否存放在可以立即使用和分析的地方?
此外,您需要將數據源連接到某個集中存儲表。 如今,Hull.io 和 Segment 等客戶數據平台 (CDP) 是遊戲的名稱,但您也可以使用 HubSpot 等 CRM 來集中、存儲和操作您的營銷和客戶數據。
當您將購買前數據連接到購買後數據時,這些變得很重要。 這使您可以根據重要的業務指標(例如預測的生命週期價值或流失率)來識別細分市場。
2. 內容
內容部分更容易理解。
本質上,如果您想進行個性化,您首先使用您的數據源定義一個用戶細分。 然後,您還需要創建一種新體驗來交付給該細分市場。
創造新的內容或體驗需要時間和金錢方面的資源。 此外,您交付和管理的內容和體驗越多,您在組織中建立的複雜性就越高。
Conductrics 的首席執行官 Matt Gershoff 在 Digital Analytics Power Hour 播客中對此做了一個很好的類比。
他將個性化描述為本質上創造了一個多元宇宙。
為每個人運行一個版本的網站就像擁有一個宇宙,也許 A/B 測試可以讓你運行反事實來看看平行宇宙(或“版本 B”)中的生活會是什麼樣子。
在 A/B 測試中,您想查看版本 B 是否對您的訪問者來說是一個更好的“宇宙”,正如您的目標轉換所定義的那樣,如果您發現它確實是最優的,您關閉宇宙 A(原始)並再次重新進入一個奇異的宇宙。
但是,將多個內容變體交付給多個獨特的細分市場就像保持開放的幾個不同的宇宙,其中體驗對於這些細分市場來說是獨一無二的。
這樣做的神奇之處在於,您可以通過增加每個細分市場及其體驗的價值來增加您網站的價值,但您可以理解,在創建和管理所有這些方面,打開數以千計的“宇宙”將是多麼昂貴。經驗。
3. 目標邏輯
最後,如果您有有用的數據和資源來創建內容,您需要確定您如何準確地觸髮用戶細分的定位或個性化邏輯。
這就是您將數據與體驗聯繫起來的方式。
您可以使用業務邏輯(假設某些細分應該具有某些價值——您甚至可以對它們進行 A/B 測試),或者您可以引入機器學習和預測細分/RFM 將您的用戶分類為不同的組——最有價值的用戶,即將流失用戶、休眠用戶等。使用 RFM 細分,您還可以了解哪些用戶細分對哪些內容體驗的反應更多樣化。
從技術上講,對於這一步,您需要一個內容交付系統,該系統要么連接到您的數據庫,要么可以集成並從您的數據庫中提取。 WebEngage 是一個全棧營銷自動化和保留操作系統,可以與您的 CRM 無縫連接,並幫助您通過電子郵件、SMS、WhatsApp、Facebook、移動和 Web 推送等渠道以 1:1 的方式吸引用戶。
不過,同樣,您觸發的目標規則越多,您構建的系統就越複雜。 因此,您可以通過定位給定的細分市場和引入系統的邊際複雜性來權衡投資回報率。 將名字合併到自定義電子郵件令牌很容易(現在大多數電子郵件工具都可以立即使用),但這並不能告訴您該定位規則的投資回報率。
資料來源:GMass
這就是為什麼,而不是僅僅因為你可以設置大量的個性化,你應該從戰略和方法上看待它,確定針對給定細分市場的投資回報率和效率。
預測細分與業務邏輯
我已經放棄了一些關於目標邏輯的行話——例如“業務邏輯”和“預測細分”。
業務邏輯本質上與“數據驅動的個性化”、“預測分割”或“基於機器學習的個性化”不同。 但這兩種方法都有相同的目標:確定需要個性化體驗的細分市場。
讓我們定義這兩個極點以及它們的不同之處。
業務邏輯分割
“業務邏輯”是人們選擇目標規則的常用方法。 在這種方法中,您基本上可以使用歷史數據和相關性或業務邏輯、策略或意見來確定哪些細分市場具有最大的影響機會。 您可以通過三種主要方式派生業務邏輯目標規則:
- 意見驅動的個性化
- 測試後分割
- 探索性數據分析
1.意見驅動的個性化
例如,出於純粹的主觀原因,您可能只是想避免在移動設備上觸發侵入性彈出窗口。 這不是一個好的用戶體驗,所以你避免它。 您甚至不需要數據來預測該細分市場的反應。
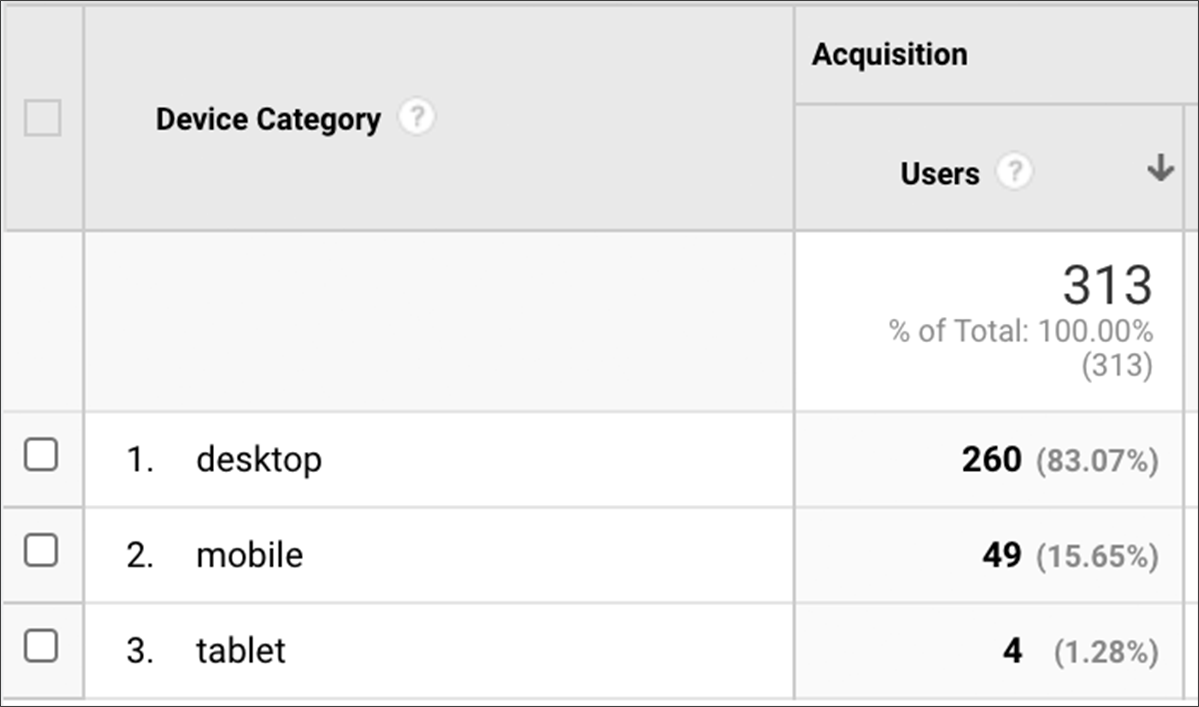
以不同方式對待移動用戶是個性化的常見用途
這是絕大多數公司在進行細分或數據驅動的個性化時使用的方法。 他們隨意猜測哪個細分市場會對哪種體驗做出積極響應,並根據他們的意見對其進行個性化設置。
2. 後測分割
然而,不太常見(但更有效)的是進行實驗,然後進行測試後分析,以確定某些變化是否對某些細分市場產生了更大的影響。
想像一下,您正在對電子商務結帳流程進行測試。
您決定測試多個變體——一個帶有一系列信任和安全符號的變體,一個帶有使用緊急消息的彈出窗口,一個沒有符號(原始版本)。
分析實驗後,您確定版本 B“獲勝”並且估計提升了 10%。 一場偉大的勝利。
但是,您深入研究數據並查看影響較大的細分市場,例如移動訪問者與桌面訪問者、回訪者與新訪問者、美國訪問者與非美國訪問者。
在這樣做的過程中,您發現 iPhone 用戶在變體 B 上的轉化率實際上提高了 35%。iPhone 用戶在您的受眾中佔很大比例,大約佔所有訪問者的 25%。 這意味著觸發該細分市場的個性化體驗可能是值得的並且投資回報率是積極的。
此外,Android 用戶在變體 B 上的轉化率實際上比對照組低 20%,在變體 C 上的轉化率比對照組高 15%。Android 用戶代表了 10% 的受眾,所以同樣是相當大的人口。

因此,您可以啟動變體 B,因為它總體上獲勝。 或者,您可以設置定位規則以觸發 iPhone 用戶接收變體 B 並觸發 Android 用戶接收變體 C。其他所有人都獲得原始版本。
3. 探索性數據分析和相關性
您可以使用“業務邏輯”進行細分的最後一種方法是簡單地探索您可以訪問的數據並尋找細分特徵和轉換概率之間的相關性。
例如,您可能會發現 iPhone 用戶的轉化率更高。 或者在您的主頁上觀看視頻的人。 或者來自堪薩斯州的男性 Android 用戶,他們填寫了一半的表單字段並在一周內返回 3 次。
這是這種方法的問題:查看足夠多的細分,您會發現相關性。 這是一個信號與噪聲的問題。
資料來源:泰勒維根
這種方法的更大問題是相關性並不意味著因果關係。
僅僅因為來自加利福尼亞的桌面回訪者轉化率更高並不意味著這是一個值得通過數據驅動的個性化定位的細分市場。
在業務邏輯領域,您最好的選擇是運行實驗並通過測試後細分發現高價值細分。 然後,您計算給定定位規則的投資回報率並運行僅針對該細分的後續實驗。
然後,您可以梳理出因果關係和維護該定位規則的真實投資回報率。 有關此方法的更多信息,請閱讀 Andrew Anderson 關於該主題的精彩演練。
預測分割
預測性細分(或另一個名稱,“數據驅動”或“基於人工智能”的細分)旨在從細分定義和設置目標規則中消除人類直覺和手動數據分析。
您可以通過多種方式使用機器學習來定義細分。 這僅取決於您的目標是什麼以及您希望通過這些細分市場實現什麼。 在這裡,我們將介紹三個關鍵方法:
- 聚類
- 分類
- 實驗+預測池
1. 聚類
首先,如果您只是想識別和理解不同的用戶角色或細分,聚類算法(或無監督機器學習)是一種用於根據共同特徵將細分分組在一起的技術。
這是我幾年前在 CXL 研究所從事的工作。
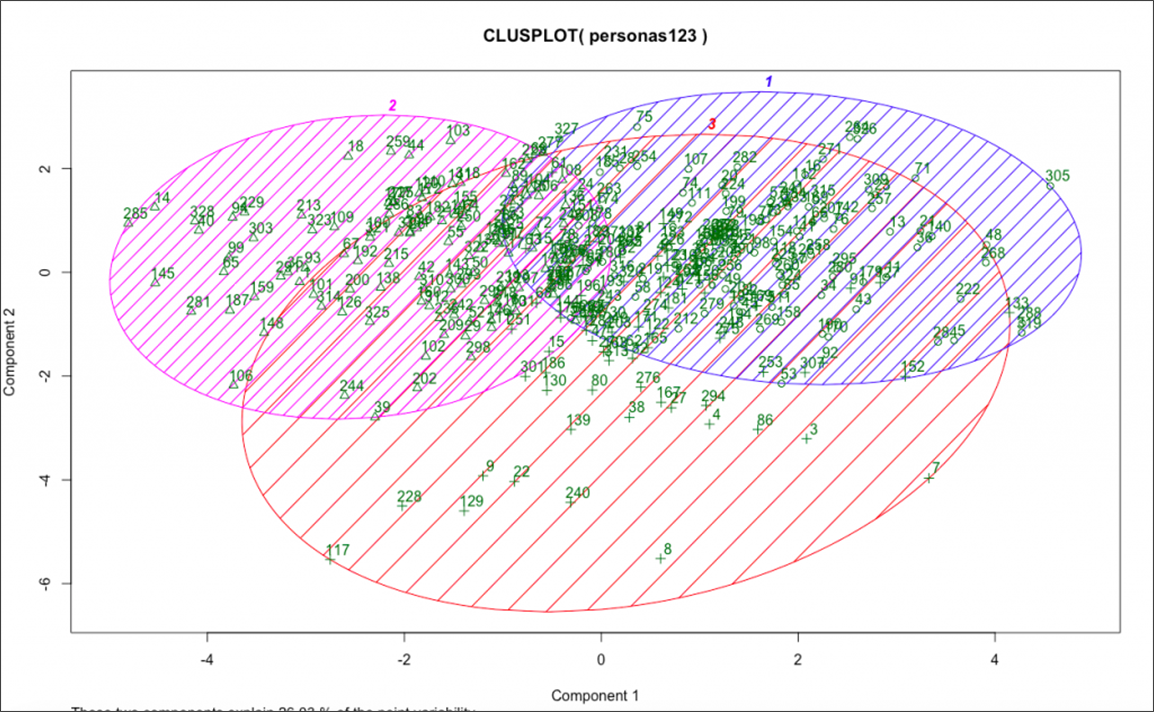
資料來源:CXL
我們向我們的客戶群發送了調查問卷,其中包含規模響應、分類變量和開放式問題。 然後,我將他們的反應編碼並對其運行 K 均值聚類算法。
這根據他們的反應大致確定了三個不同的部分。 然後,我對每個細分市場的定性見解進行分層,並採訪了每個細分市場高度代表的個人。 這使我們能夠深入了解我們現有的客戶群以及他們不同的願望、挑戰和行為。
如果您想進行聚類,請知道它主要是探索性的和知識構建。 它不會告訴您將個性化營銷傳播發送到這些細分市場之一的投資回報率,也不會告訴您哪些細分市場可能會響應哪些體驗。 例如,您可能會發現某部分電子郵件訂閱者打開的電子郵件更多,並且具有更高的生命週期價值,但您仍然需要進行構思新內容和體驗的創造性工作來進行測試。
但從數據驅動的個性化開始,這是一個很好的基礎層。
您還需要一個可以編寫 R 或 Python 代碼的體面的分析師,或者至少需要一個像 Squark 這樣的工具,它不允許進行代碼預測分析。
2.分類
機器學習往往被劃分為監督學習和無監督學習。 聚類算法是無監督的,分類算法是有監督的。
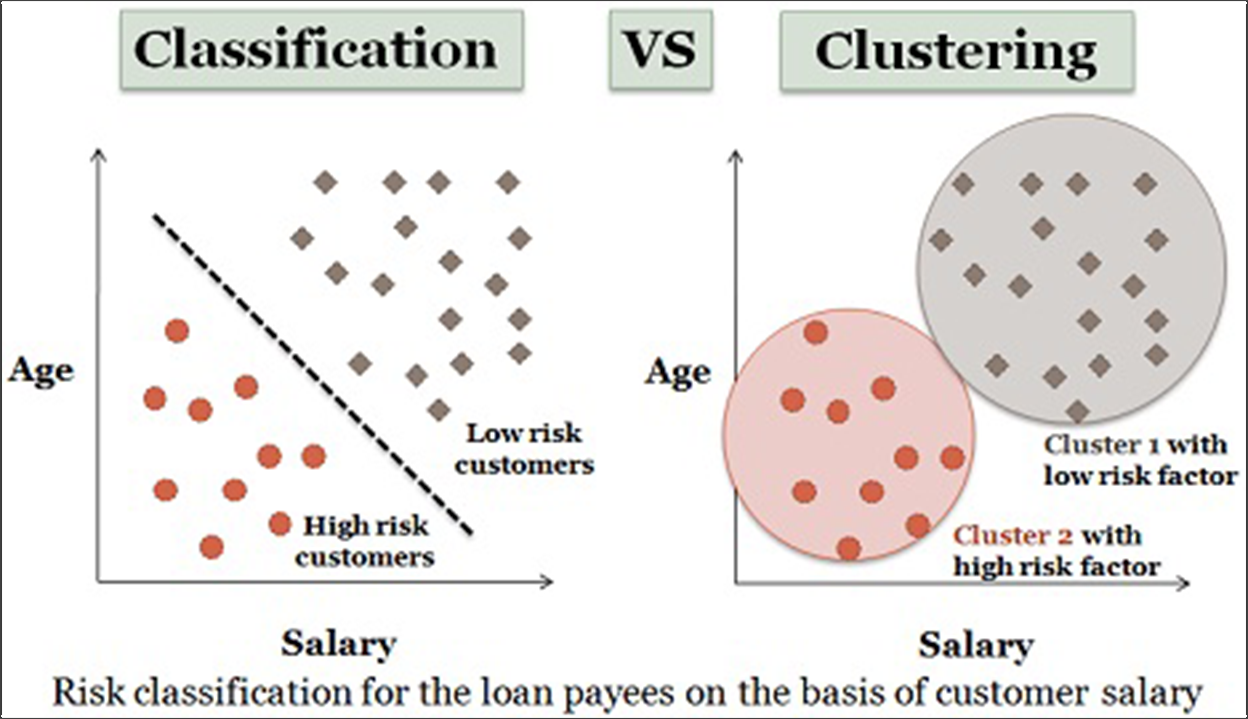
資料來源:技術差異
這意味著你有一個包含各種“特徵”的數據集(在我們的例子中,這可能是設備類型、訪問的頁面、公司規模或我們可以收集的關於訪問者的任何特徵),然後你就會得到你想要的結果想要預測(在我們的例子中,是轉化或收入或 LTV)。
有大量的方法和算法試圖根據數據特徵預測結果,其中一些包括線性回歸、邏輯回歸、隨機森林和神經網絡。
如果您想使用這種方法,您將需要一位出色的分析師,他可以將模型正確地擬合到您的數據中(否則預測將毫無用處),或者購買像 Squark 或 DataRobot 這樣的工具。 這些工具使分析師和業務人員能夠將不同的模型擬合到他們的數據中並預測結果,而無需自己編寫算法。
3. 實驗+預測分割
通常,尋找有利可圖的用戶細分的最佳方法是進行正常的受控實驗過程並使用檢測有前景的細分的工具(或分析方法)。
例如,Conductrics 向您展示了一個高度可解釋的決策樹,該樹計算與您測試的每個變體相對應的各個細分市場的轉化成功概率。
如果您的預測定位工具具有數據可視化功能,可以通過簡單的插圖向您顯示您設置了哪些定位規則,以及這些規則的估計投資回報率和成功概率,則可以獲得獎勵積分。

資料來源:導體
這很酷,因為您不僅可以獲得成功的概率,還可以根據其價值選擇是否定位該細分市場。
來自肯塔基州農村的男性機器人回訪者? 也許不值得設置新的定位規則。 但是,如果加利福尼亞人人口眾多並且對特定體驗的反應非常好,那麼也許值得針對加利福尼亞人。
如何開始使用數據驅動的個性化
雖然深入研究數據驅動的個性化可能很誘人,但我建議慢慢開始。
任何給定的個性化規則的真正價值是未知的,而且增加個性化的邊際回報往往低於引入的邊際複雜性成本。
因此,我將介紹三種提高複雜性的個性化方法(假設“抓取”階段只是整理您的數據以及提供個性化體驗所需的資源/工具)。
第一階段:步行
因此,在您投資預測定位工具之前,您可能希望使用 Andrew Anderson 的方法,它可以是您正常實驗計劃的簡單延續(旁注:沒有流量進行實驗?個性化不適合您。在那個流量水平上,邊際回報是不值得的。而是大幅波動)。
以下是該方法的要點:
- 創建消息或體驗的多次執行
- 通過受控實驗為每個人提供所有優惠
- 按細分查看結果,並通過提供差異化體驗來計算總收益。 確保在分析多個細分時糾正多重比較。
- 實時推送發現的最高創收機會(或僅針對該細分市場進行後續實驗,並使用您在全部受眾中測試的體驗)。
您可以使用專用的 A/B 測試平台,也可以使用集成營銷自動化平台。 後者將幫助您在多個渠道上個性化消息,而不僅僅是網絡或應用程序,您可以提供個性化的產品推薦、增加收入和 CLTV、改進內容/產品發現等等。
第二階段:運行
在這裡取得一些勝利後,您可能希望投資於像 Squark 這樣的無代碼預測分析解決方案(或者如果您可以在內部編寫算法,無論如何)。 基本過程如下所示:
確定您的成功指標
收集和清理您的數據,將您的數據集拆分為訓練和測試數據。
確保數據中有無數維度或特徵可用於預測結果。
確定哪些功能可以預測您的成功指標。
計算這些細分市場的個性化體驗的投資回報率。 同樣,如果人口太少,可能不值得。
現在是重要的部分:一旦您定義了可預測成功的特徵或維度(例如回訪者),您仍然沒有弄清楚哪些體驗更有可能在該細分市場上發揮作用。
艱苦的工作仍然存在:即創造新的偉大體驗並進行實驗以確定新體驗的有效性和投資回報率。
您仍然需要在 WebEngage 等內容交付解決方案上進行投資,以針對特定細分市場。
第三階段:飛行
最後,如果您想將預測性定位納入您的正常實驗和優化工作流程,您無法擊敗像 Conductrics 或 Dynamic Yield 這樣的工具。 這些工具將幫助您識別細分市場並提供個性化體驗,同時為您提供可解釋的決策規則和 ROI 歸因報告。
結論
在一個充斥著頭條新聞和關於人工智能是靈丹妙藥的會議討論的世界中,您可能會驚訝地發現“數據驅動的個性化”或“預測細分”過程並不能為您完成所有工作。
它可以幫助您利用數據並節省大量時間(和錯誤)。 您可以更輕鬆、更準確地識別利潤豐厚的細分市場,只要您擁有適當的數據並且在您需要時可以訪問這些數據。
但是,它無法為您決定是否利用該細分市場。 您仍然需要權衡利弊、成本和收益。
然而幸運的是,識別和分組細分的過程從未如此簡單,交付和管理多種不同的體驗也從未如此簡單。 營銷自動化工具可以插入您的數據源或 CRM。 您可以通過任何您想要的渠道(付費廣告、社交、網絡、推送、電子郵件等)管理和提供無限的個性化體驗。
現在是成為數據驅動營銷人員的好時機。
 i圖片來源:WebEngage
i圖片來源:WebEngage為您的業務利用自動化的力量
具有預測細分功能和優質的客戶支持!