
Înlăturarea barierelor la scară: cum am optimizat utilizarea Elasticsearch la Intercom
Publicat: 2022-09-22Elasticsearch este o parte indispensabilă a Intercomului.
Stă la baza funcțiilor de bază ale interfonului, cum ar fi Inbox, Inbox Views, API, Articole, lista de utilizatori, raportare, Resolution Bot și sistemele noastre interne de înregistrare. Clusterele noastre Elasticsearch conțin peste 350 TB de date despre clienți, stochează peste 300 de miliarde de documente și deservesc peste 60 de mii de solicitări pe secundă la vârf.
Pe măsură ce utilizarea Elasticsearch de la Intercom crește, trebuie să ne asigurăm că sistemele noastre se scalează pentru a ne susține creșterea continuă. Odată cu lansarea recentă a Inbox-ului de nouă generație, fiabilitatea Elasticsearch este mai critică ca niciodată.
Am decis să rezolvăm o problemă cu configurația noastră Elasticsearch, care a reprezentat un risc de disponibilitate și a amenințat viitoarele perioade de nefuncționare: distribuția neuniformă a traficului/lucrării între nodurile din clusterele noastre Elasticsearch.
Semne timpurii de ineficiență: dezechilibru de încărcare
Elasticsearch vă permite să scalați orizontal prin creșterea numărului de noduri care stochează date (noduri de date). Am început să observăm un dezechilibru de încărcare între aceste noduri de date: unele dintre ele erau supuse unei presiuni mai mari (sau „mai fierbinți”) decât altele din cauza utilizării mai mari a discului sau procesorului.
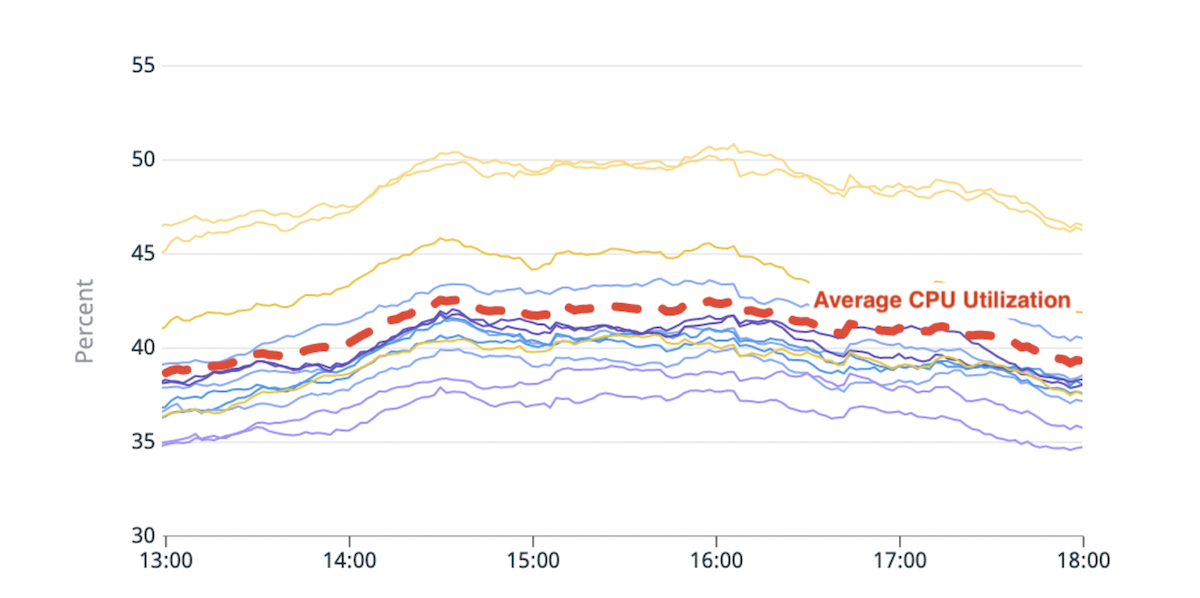
(Fig. 1) Dezechilibru în utilizarea CPU: Două noduri fierbinți cu ~20% mai mare utilizare CPU decât media.
Logica de plasare a fragmentelor încorporată a Elasticsearch ia decizii pe baza unui calcul care estimează aproximativ spațiul de disc disponibil în fiecare nod și numărul de fragmente ale unui index pe nod. Utilizarea resurselor de către shard nu ia în considerare acest calcul. Drept urmare, unele noduri ar putea primi mai multe cioburi amanate de resurse și ar putea deveni „fierbinte”. Fiecare cerere de căutare este procesată de mai multe noduri de date. Un nod fierbinte care este împins peste limitele sale în timpul traficului de vârf poate cauza degradarea performanței întregului cluster.
Un motiv obișnuit pentru nodurile fierbinți este logica de plasare a fragmentelor care atribuie fragmente mari (pe baza utilizării discului) clusterelor, făcând o alocare echilibrată mai puțin probabilă. În mod obișnuit, unui nod i se poate atribui un fragment mare mai mult decât celelalte, ceea ce îl face mai fierbinte în utilizarea discului. Prezența fragmentelor mari împiedică, de asemenea, capacitatea noastră de a scala în mod incremental clusterul, deoarece adăugarea unui nod de date nu garantează reducerea sarcinii de la toate nodurile fierbinți (Fig. 2).
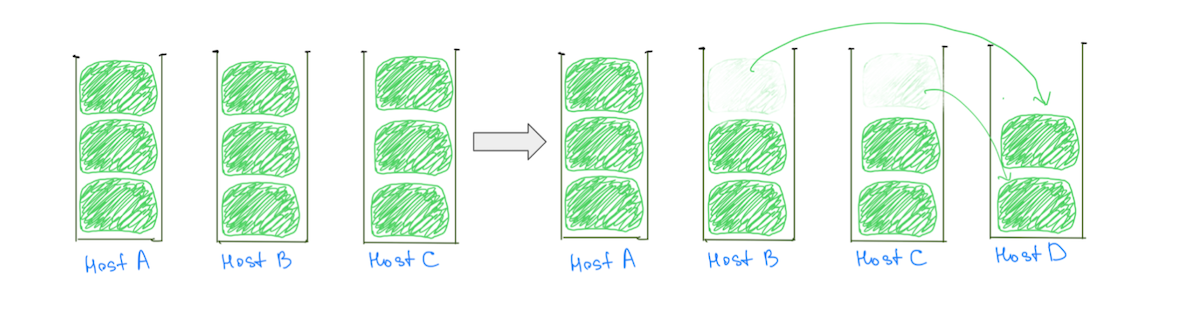
(Fig. 2) Adăugarea unui nod de date nu a dus la reducerea încărcării pe gazda A. Adăugarea unui alt nod ar reduce încărcarea pe gazda A, dar clusterul va avea în continuare o distribuție neuniformă a sarcinii.
În schimb, a avea fragmente mai mici ajută la reducerea încărcării tuturor nodurilor de date pe măsură ce clusterul se scalează – inclusiv pe cele „fierbinte” (Fig. 3).
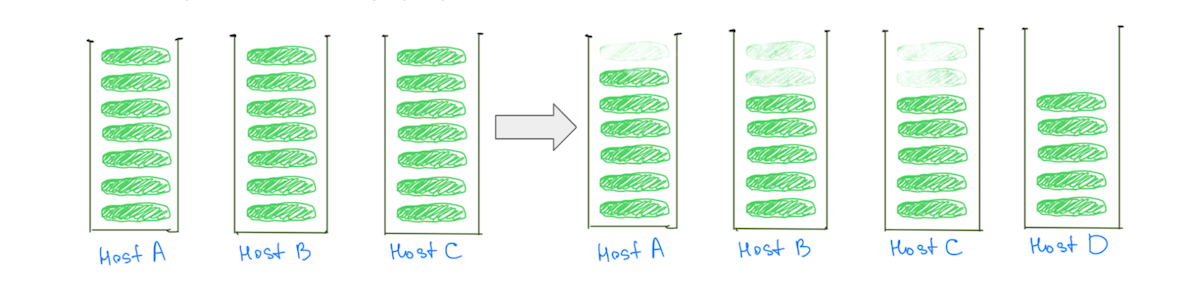
(Fig. 3) A avea multe fragmente mai mici ajută la reducerea încărcării tuturor nodurilor de date.
Notă: problema nu se limitează la clustere cu fragmente mari. Am observa un comportament similar dacă înlocuim „dimensiunea” cu „utilizarea CPU” sau „traficul de căutare”, dar compararea dimensiunilor face mai ușor de vizualizat.
Pe lângă impactul asupra stabilității cluster-ului, dezechilibrul de încărcare afectează capacitatea noastră de a scala în mod eficient din punct de vedere al costurilor. Va trebui întotdeauna să adăugăm mai multă capacitate decât este necesar pentru a menține nodurile mai fierbinți sub niveluri periculoase. Remedierea acestei probleme ar însemna o disponibilitate mai bună și economii semnificative de costuri prin utilizarea mai eficientă a infrastructurii noastre.
Înțelegerea noastră profundă a problemei ne-a ajutat să realizăm că sarcina ar putea fi distribuită mai uniform dacă am avea:
- Mai multe fragmente în raport cu numărul de noduri de date. Acest lucru ar asigura că majoritatea nodurilor au primit un număr egal de fragmente.
- Cioburile mai mici în raport cu dimensiunea nodurilor de date. Dacă unor noduri li s-au oferit câteva fragmente suplimentare, nu ar avea ca rezultat o creștere semnificativă a încărcării pentru acele noduri.
Soluție pentru cupcake: Mai puține noduri mai mari
Acest raport dintre numărul de fragmente și numărul de noduri de date și dimensiunea fragmentelor la dimensiunea nodurilor de date poate fi ajustat prin existența unui număr mai mare de fragmente mai mici. Dar poate fi modificat mai ușor prin trecerea la noduri de date mai puține, dar mai mari.
Am decis să începem cu un cupcake pentru a verifica această ipoteză. Am migrat câteva dintre clusterele noastre către instanțe mai mari, mai puternice, cu mai puține noduri – păstrând aceeași capacitate totală. De exemplu, am mutat un cluster de la 40 de instanțe 4xlarge la 10 instanțe 16xlarge, reducând dezechilibrul de încărcare prin distribuirea mai uniformă a fragmentelor.
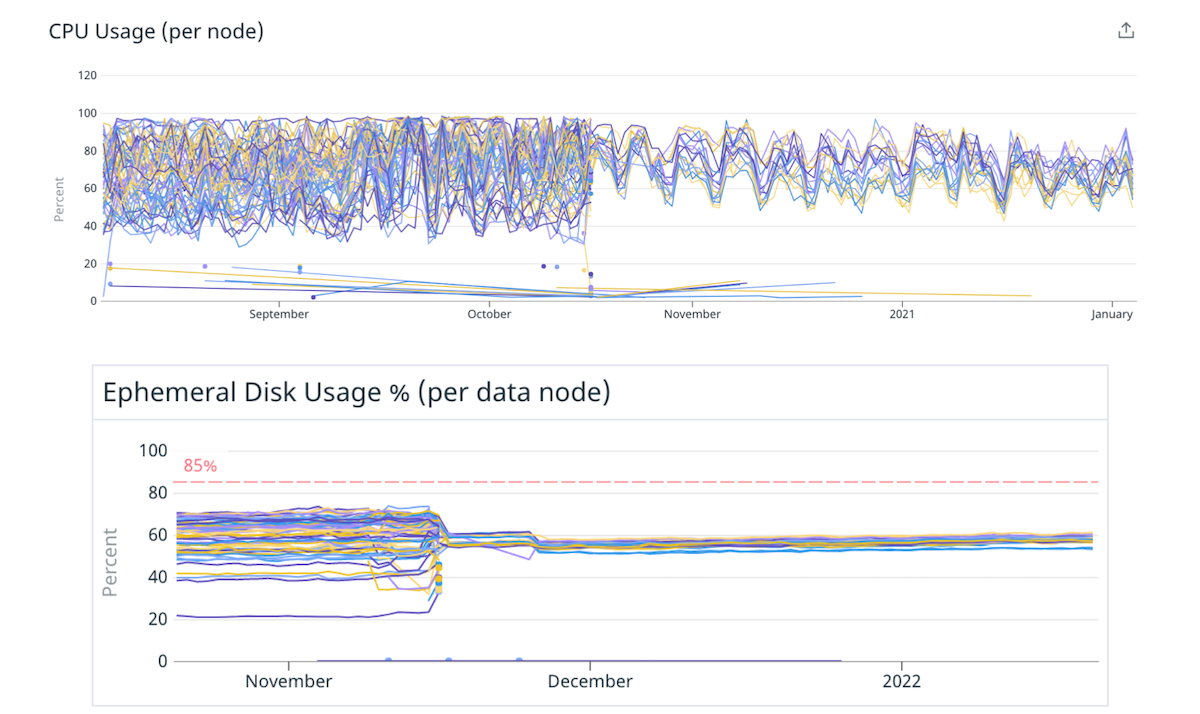
(Fig. 4) Distribuție mai bună a încărcării pe disc și CPU prin trecerea la mai puține noduri mai mari.
Atenuarea mai puține noduri mai mari a validat ipotezele noastre că ajustarea numărului și dimensiunii nodurilor de date poate îmbunătăți distribuția sarcinii. Ne-am fi putut opri acolo, dar au existat câteva dezavantaje ale abordării:
- Știam că dezechilibrul de încărcare va apărea din nou pe măsură ce fragmentele cresc în timp sau dacă mai multe noduri ar fi adăugate în cluster pentru a ține seama de creșterea traficului.
- Nodurile mai mari fac scalarea incrementală mai costisitoare. Adăugarea unui singur nod ar costa acum mai mult, chiar dacă am avea nevoie doar de puțină capacitate suplimentară.
Provocare: Depășirea pragului de indicatori ai obiectelor obișnuite comprimate (OOP).
Mutarea la mai puține noduri mai mari nu a fost la fel de simplă ca doar schimbarea dimensiunii instanței. Un blocaj cu care ne-am confruntat a fost păstrarea dimensiunii totale a heap-ului disponibil (dimensiunea heap-ului pe un nod x numărul total de noduri) pe măsură ce am migrat.
Limitam dimensiunea heap-ului din nodurile noastre de date la ~ 30,5 GB, așa cum a sugerat Elastic, pentru a ne asigura că am rămas sub limită, astfel încât JVM-ul să poată folosi OOP-uri comprimate. Dacă am limita dimensiunea heap-ului la ~30,5 GB după ce ne-am mutat la mai puține noduri mai mari, ne-am reduce capacitatea heap-ului în general, deoarece am lucra cu mai puține noduri.
„Instanțele către care migram au fost uriașe și am vrut să alocam o mare parte a memoriei RAM la heap, astfel încât să avem spațiu pentru pointeri, cu suficient pentru cache-ul sistemului de fișiere”
Nu am putut găsi multe sfaturi despre impactul depășirii acestui prag. Instanțele spre care migram au fost uriașe și am vrut să atribuim o mare parte a memoriei RAM la heap, astfel încât să avem spațiu pentru pointeri, cu suficient pentru cache-ul sistemului de fișiere. Am experimentat cu câteva praguri prin replicarea traficului nostru de producție pentru a testa clustere și am stabilit pe aproximativ 33% până la ~42% din RAM ca dimensiune a heap-ului pentru mașinile cu mai mult de 200 GB de RAM.

Modificarea dimensiunii heap-ului a afectat diferite clustere în mod diferit. În timp ce unele clustere nu au arătat nicio schimbare în valori precum „% heap JVM în uz” sau „Young GC Collection Time”, tendința generală a fost o creștere. Indiferent, în general a fost o experiență pozitivă, iar clusterele noastre funcționează de mai bine de 9 luni cu această configurație – fără probleme.
Remediere pe termen lung: multe cioburi mai mici
O soluție pe termen mai lung ar fi să se îndrepte spre a avea un număr mai mare de fragmente mai mici în raport cu numărul și dimensiunea nodurilor de date. Putem ajunge la cioburi mai mici în două moduri:
- Migrarea indexului pentru a avea mai multe fragmente primare: aceasta distribuie datele din index între mai multe fragmente.
- Împărțirea indexului în indici mai mici (partiții): aceasta distribuie datele din index între mai mulți indici.
Este important să rețineți că nu vrem să creăm un milion de fragmente minuscule sau să avem sute de partiții. Fiecare index și fragment necesită anumite resurse de memorie și CPU.
„Ne-am concentrat să facem mai ușor experimentarea și remedierea configurațiilor suboptime în cadrul sistemului nostru, mai degrabă decât să ne fixăm pe configurația „perfectă””
În cele mai multe cazuri, un set mic de cioburi mari utilizează mai puține resurse decât multe cioburi mici. Dar există și alte opțiuni - experimentarea ar trebui să vă ajute să ajungeți la o configurație mai potrivită pentru cazul dvs. de utilizare.
Pentru a face sistemele noastre mai rezistente, ne-am concentrat să facem mai ușor experimentarea și remedierea configurațiilor suboptime în cadrul sistemului nostru, mai degrabă decât să ne fixăm pe configurația „perfectă”.
Indici de partiţionare
Creșterea numărului de fragmente primare poate afecta uneori performanța pentru interogările care agregă date, ceea ce am experimentat în timpul migrării clusterului responsabil pentru produsul de raportare al Intercom. În schimb, partiționarea unui index în mai mulți indecși distribuie încărcarea pe mai multe fragmente fără a degrada performanța interogării.
Interfonul nu are cerință pentru colocarea datelor pentru mai mulți clienți, așa că am ales să partiționăm pe baza ID-urilor unice ale clienților. Acest lucru ne-a ajutat să oferim valoare mai rapid prin simplificarea logicii de partiționare și reducerea setărilor necesare.
„Pentru a împărți datele într-un mod care a afectat cel mai puțin obiceiurile și metodele existente ale inginerilor noștri, am investit mai întâi mult timp în înțelegerea modului în care inginerii noștri folosesc Elasticsearch”
Pentru a împărți datele într-un mod care a afectat cel mai puțin obiceiurile și metodele existente ale inginerilor noștri, mai întâi am investit mult timp în înțelegerea modului în care inginerii noștri folosesc Elasticsearch. Am integrat profund sistemul nostru de observabilitate în biblioteca client Elasticsearch și ne-am măturat baza de cod pentru a afla despre toate modurile diferite în care echipa noastră interacționează cu API-urile Elasticsearch.
Modul nostru de recuperare a erorilor a fost să reîncercăm solicitările, așa că am făcut modificările necesare în cazul în care făceam solicitări non-idempotente. Am ajuns să adăugăm câteva linters pentru a descuraja utilizarea API-urilor precum `update/delete_by_query`, deoarece au făcut mai ușor să faceți cereri non-idempotente.
Am construit două capabilități care au lucrat împreună pentru a oferi funcționalitate completă:
- O modalitate de a direcționa cererile de la un index la altul. Acest alt index ar putea fi o partiție sau doar un index nepartiționat.
- O modalitate de a scrie dublă date în mai mulți indecși. Acest lucru ne-a permis să menținem partițiile sincronizate cu indexul migrat.
„Ne-am optimizat procesele pentru a minimiza raza exploziei a oricăror incidente, fără a compromite viteza”
În total, procesul de migrare a unui index către partiții arată astfel:
- Creăm noile partiții și activăm scrierea duală, astfel încât partițiile noastre să rămână la zi cu indexul original.
- Declanșăm o completare a tuturor datelor. Aceste solicitări de completare vor fi scrise dual pe noile partiții.
- Când se finalizează completarea, validăm că atât indecșii vechi, cât și cei noi au aceleași date. Dacă totul arată bine, folosim steaguri de caracteristici pentru a începe să folosim partițiile pentru câțiva clienți și pentru a monitoriza rezultatele.
- Odată ce suntem încrezători, mutăm toți clienții noștri la partiții, totul în timp ce scriem dual atât în vechiul index, cât și în partiții.
- Când suntem siguri că migrarea a avut succes, oprim scrierea duală și ștergem vechiul index.
Acești pași aparent simpli au o mulțime de complexitate. Ne-am optimizat procesele pentru a minimiza raza de explozie a oricăror incidente, fără a compromite viteza.
Culegând beneficiile
Această activitate ne-a ajutat să îmbunătățim echilibrul de încărcare în clusterele noastre Elasticsearch. Mai important, acum putem îmbunătăți distribuția încărcării de fiecare dată când aceasta devine inacceptabilă, migrând indexuri către partiții cu mai puține fragmente primare, obținând tot ce este mai bun din ambele lumi: fragmente mai puține și mai mici pe index.
Aplicând aceste învățăminte, am reușit să obținem câștiguri importante de performanță și economii.
- Am redus costurile a două dintre clusterele noastre cu 40% și, respectiv, 25% și am observat economii semnificative de costuri și pentru alte clustere.
- Am redus utilizarea medie a procesorului pentru un anumit cluster cu 25% și am îmbunătățit latența medie a cererii cu 100%. Am reușit acest lucru prin migrarea unui indice de trafic ridicat către partiții cu mai puține fragmente primare pe partiție în comparație cu originalul.
- Abilitatea generală de a migra indexurile ne permite, de asemenea, să schimbăm schema unui index, permițând inginerilor de produs să construiască experiențe mai bune pentru clienții noștri sau să reindexeze datele folosind o versiune Lucene mai nouă, care ne deblochează capacitatea de a face upgrade la Elasticsearch 8.
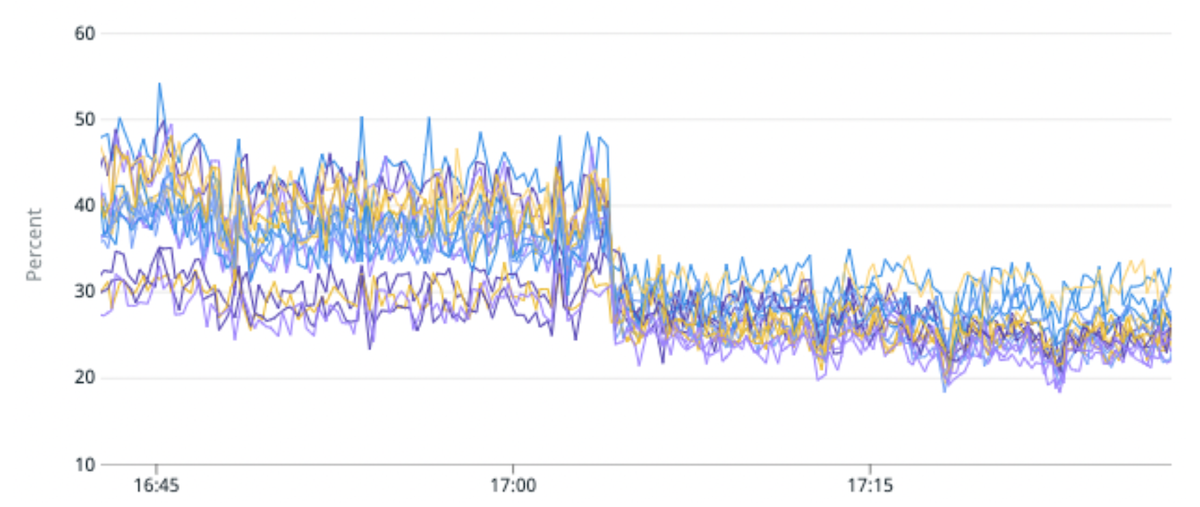
(Fig. 5) Îmbunătățire cu 50% a dezechilibrului de încărcare și îmbunătățire cu 25% a utilizării CPU prin migrarea unui indice de trafic ridicat către partiții cu mai puține fragmente primare pe partiție.
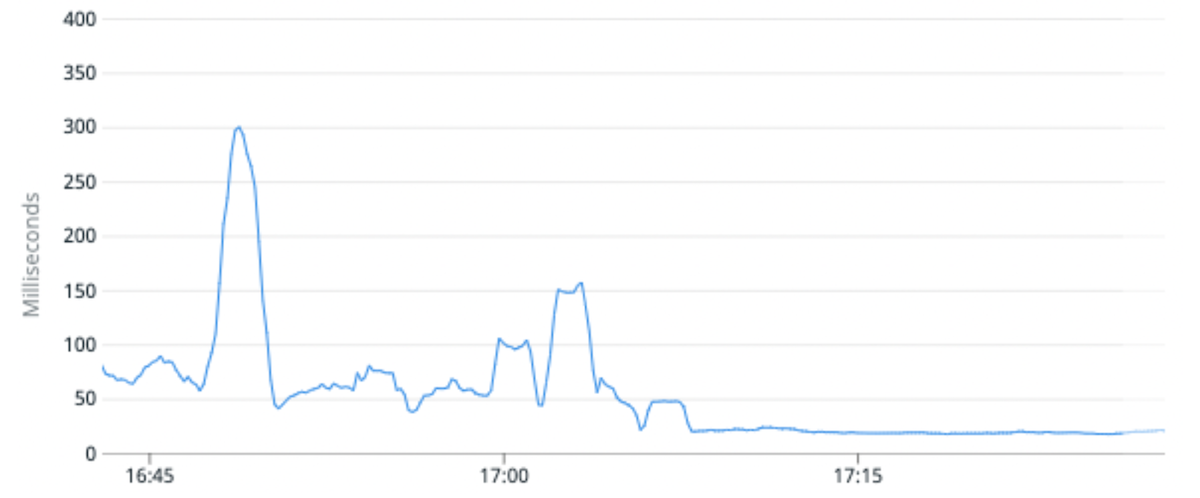
(Fig. 6) Latența medie a cererii s-a îmbunătățit cu 100% în medie prin migrarea unui indice de trafic ridicat către partiții cu mai puține fragmente primare pe partiție.
Ce urmeaza?
Introducerea Elasticsearch pentru a alimenta noi produse și funcții ar trebui să fie simplă. Viziunea noastră este de a face ca inginerii noștri să interacționeze cu Elasticsearch la fel de simplu, așa cum cadrele web moderne îl fac să interacționeze cu bazele de date relaționale. Ar trebui să fie ușor pentru echipe să creeze un index, să citească sau să scrie din index, să facă modificări schemei acestuia și multe altele – fără a fi nevoiți să vă faceți griji cu privire la modul în care sunt servite solicitările.
Ești interesat de modul în care echipa noastră de inginerie lucrează la Intercom? Aflați mai multe și consultați rolurile noastre deschise aici.
