
Ölçeklendirmenin önündeki engelleri yıkmak: Intercom'da Elasticsearch kullanımını nasıl optimize ettik?
Yayınlanan: 2022-09-22Elasticsearch, Intercom'un vazgeçilmez bir parçasıdır.
Gelen Kutusu, Gelen Kutusu Görünümleri, API, Makaleler, kullanıcı listesi, raporlama, Çözünürlük Botu ve dahili kayıt sistemlerimiz gibi temel Intercom özelliklerini destekler. Elasticsearch kümelerimiz 350 TB'den fazla müşteri verisi içerir, 300 milyardan fazla belge depolar ve saniyede 60 binden fazla istek sunar.
Intercom'un Elasticsearch kullanımı arttıkça, sürekli büyümemizi desteklemek için sistemlerimizin ölçeklenmesini sağlamamız gerekiyor. Yeni nesil Gelen Kutumuzun yakın zamanda piyasaya sürülmesiyle, Elasticsearch'ün güvenilirliği her zamankinden daha kritik hale geldi.
Elasticsearch kurulumumuzla ilgili, kullanılabilirlik riski oluşturan ve gelecekteki kesinti süresini tehdit eden bir sorunu çözmeye karar verdik: Elasticsearch kümelerimizdeki düğümler arasında trafiğin/işin eşit olmayan dağılımı.
Verimsizliğin erken belirtileri: Yük dengesizliği
Elasticsearch, verileri depolayan düğümlerin (veri düğümleri) sayısını artırarak yatay olarak ölçeklendirmenize olanak tanır. Bu veri düğümleri arasında bir yük dengesizliği fark etmeye başladık: bazıları daha yüksek disk veya CPU kullanımı nedeniyle diğerlerinden daha fazla baskı (veya "daha sıcak") altındaydı.
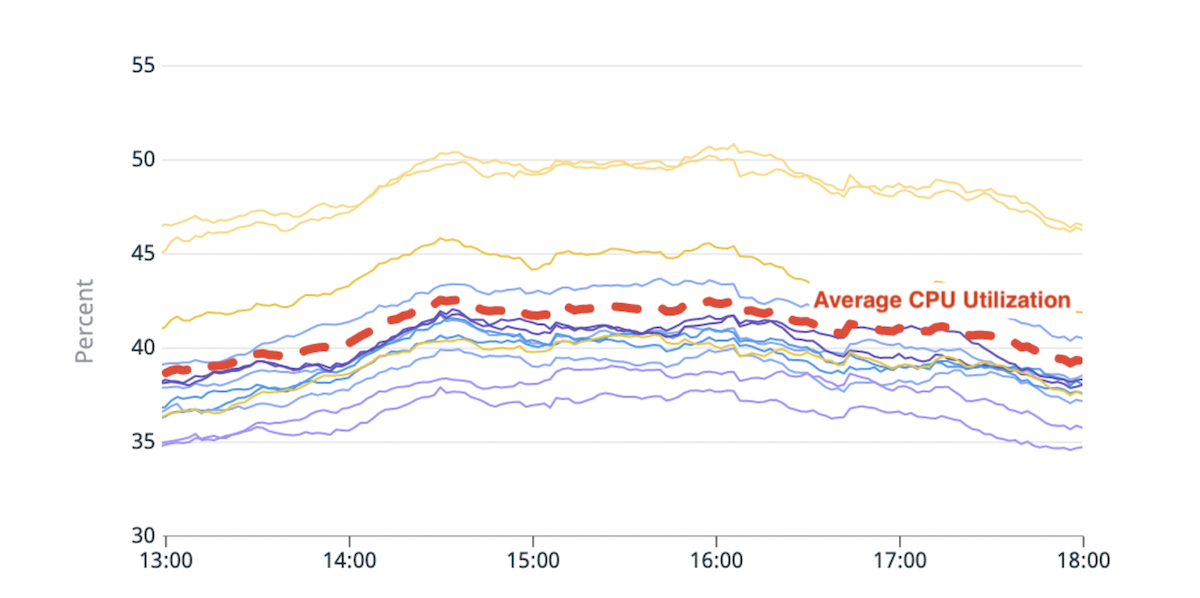
(Şekil 1) CPU kullanımında dengesizlik: Ortalamadan ~%20 daha yüksek CPU kullanımına sahip iki sıcak düğüm.
Elasticsearch'ün yerleşik parça yerleştirme mantığı, her düğümdeki kullanılabilir disk alanını ve düğüm başına bir dizinin parça sayısını kabaca tahmin eden bir hesaplamaya dayalı olarak kararlar verir. Parçaya göre kaynak kullanımı bu hesaplamayı etkilemez. Sonuç olarak, bazı düğümler daha fazla kaynağa aç parçalar alabilir ve "sıcak" hale gelebilir. Her arama isteği, birden çok veri düğümü tarafından işlenir. Yoğun trafik sırasında sınırlarının dışına itilen bir sıcak düğüm, tüm küme için performans düşüşüne neden olabilir.
Sıcak düğümlerin yaygın bir nedeni, kümelere büyük parçalar (disk kullanımına dayalı olarak) atayarak dengeli bir ayırma olasılığını azaltan parça yerleştirme mantığıdır. Tipik olarak, bir düğüme diğerlerinden daha fazla büyük bir parça atanabilir, bu da onu disk kullanımında daha sıcak hale getirir. Büyük parçaların varlığı, bir veri düğümü eklemek tüm etkin düğümlerden yükün azaltılmasını garanti etmediğinden, kümeyi aşamalı olarak ölçeklendirme yeteneğimizi de engeller (Şekil 2).
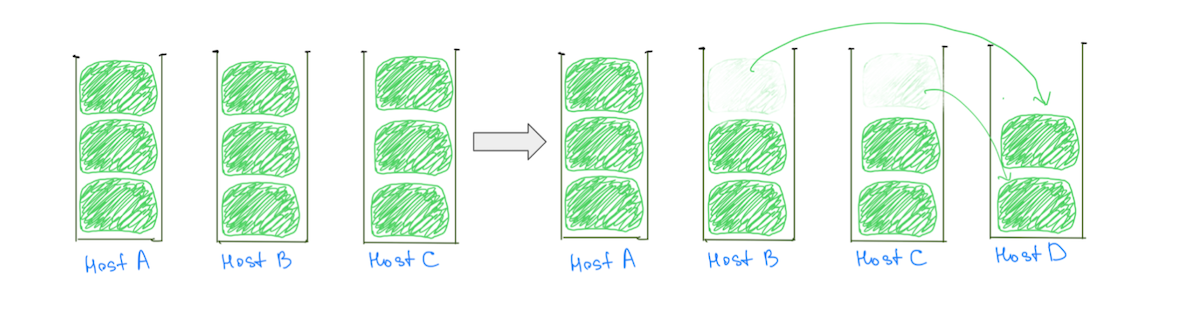
(Şek. 2) Bir veri düğümü eklemek, Ana Bilgisayar A'da yük azalmasına neden olmadı. Başka bir düğüm eklemek Ana Bilgisayar A üzerindeki yükü azaltır, ancak kümede yine de eşit olmayan yük dağılımı olacaktır.
Buna karşılık, daha küçük parçalara sahip olmak, küme ölçeklenirken tüm veri düğümleri üzerindeki yükün azaltılmasına yardımcı olur – “sıcak” olanlar da dahil (Şekil 3).
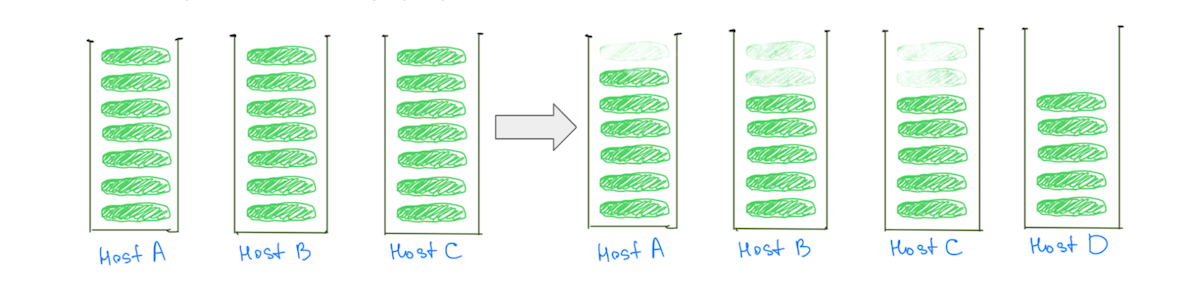
(Şek. 3) Çok sayıda küçük parçaya sahip olmak, tüm veri düğümlerindeki yükün azaltılmasına yardımcı olur.
Not: Sorun, büyük boyutlu parçalara sahip kümelerle sınırlı değildir. "Boyutu" "CPU kullanımı" veya "arama trafiği" ile değiştirirsek benzer bir davranış gözlemleyebiliriz, ancak boyutları karşılaştırmak görselleştirmeyi kolaylaştırır.
Küme istikrarını etkilemenin yanı sıra, yük dengesizliği maliyet etkin bir şekilde ölçeklendirme yeteneğimizi de etkiler. Daha sıcak düğümleri tehlikeli seviyelerin altında tutmak için her zaman gerekenden daha fazla kapasite eklememiz gerekecek. Bu sorunu düzeltmek, daha iyi kullanılabilirlik ve altyapımızı daha verimli kullanmaktan önemli ölçüde maliyet tasarrufu anlamına gelir.
Sorunu derinlemesine anlamamız, şu durumlarda yükün daha eşit dağılabileceğini anlamamıza yardımcı oldu:
- Veri düğümlerinin sayısına göre daha fazla parça . Bu, çoğu düğümün eşit sayıda parça almasını sağlayacaktır.
- Veri düğümlerinin boyutuna göre daha küçük parçalar . Bazı düğümlere fazladan birkaç parça verilirse, bu düğümler için yükte anlamlı bir artışa neden olmaz.
Cupcake çözümü: Daha az büyük düğüm
Parça sayısının veri düğümlerinin sayısına ve parçaların boyutunun veri düğümlerinin boyutuna oranı, daha fazla sayıda daha küçük parçaya sahip olarak ince ayar yapılabilir. Ancak daha az ancak daha büyük veri düğümlerine taşınarak daha kolay ince ayar yapılabilir.
Bu hipotezi doğrulamak için bir kekle başlamaya karar verdik. Aynı toplam kapasiteyi koruyarak, kümelerimizden birkaçını daha az düğüm içeren daha büyük, daha güçlü örneklere taşıdık. Örneğin, bir kümeyi 40 adet 4xlarge örnekten 10 adet 16xlarge örneğine taşıyarak, parçaları daha eşit bir şekilde dağıtarak yük dengesizliğini azalttık.
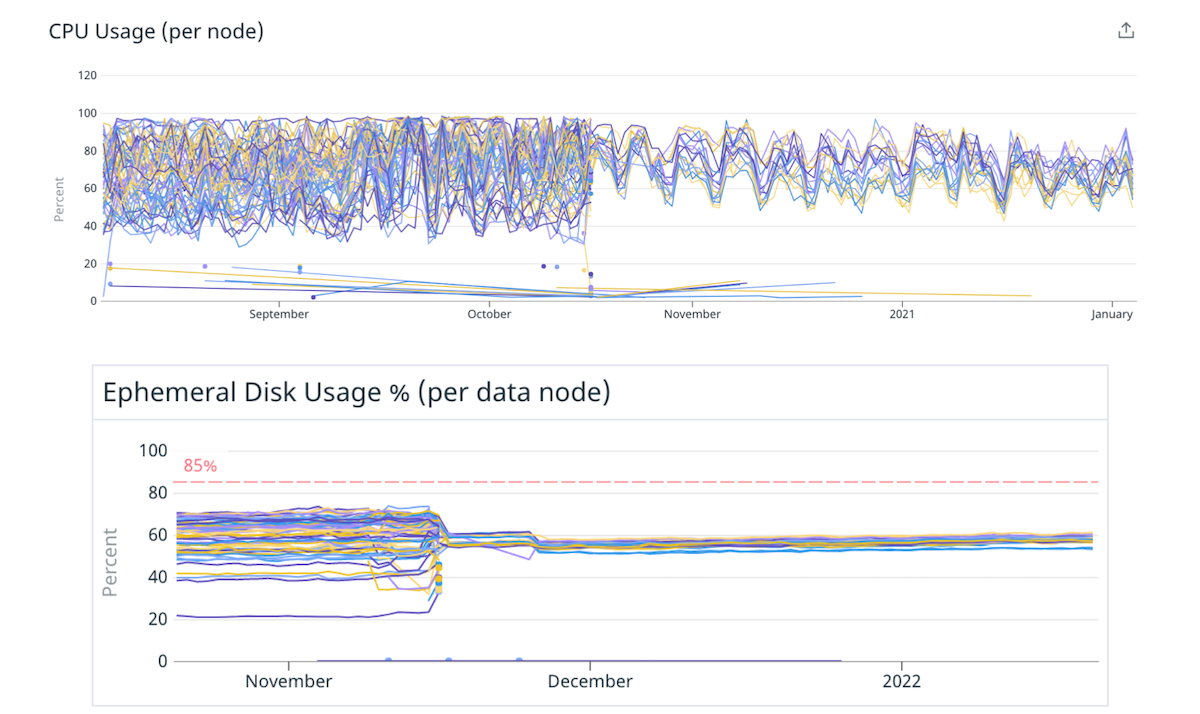
(Şek. 4) Daha az sayıda daha büyük düğüme geçerek disk ve CPU arasında daha iyi yük dağılımı.
Daha az sayıda daha büyük düğüm azaltma, veri düğümlerinin sayısını ve boyutunu değiştirmenin yük dağılımını iyileştirebileceği varsayımlarımızı doğruladı. Orada durabilirdik, ancak yaklaşımın bazı olumsuz yönleri vardı:
- Zaman içinde parçalar büyüdükçe veya artan trafiği hesaba katmak için kümeye daha fazla düğüm eklendikçe yük dengesizliğinin yeniden ortaya çıkacağını biliyorduk.
- Daha büyük düğümler, artımlı ölçeklemeyi daha pahalı hale getirir. Sadece biraz ekstra kapasiteye ihtiyacımız olsa bile, tek bir düğüm eklemek artık daha pahalıya mal olacak.
Zorluk: Sıkıştırılmış Sıradan Nesne İşaretçileri (OOP'ler) eşiğini geçmek
Daha az sayıda daha büyük düğüme geçmek, yalnızca örnek boyutunu değiştirmek kadar basit değildi. Karşılaştığımız bir darboğaz, geçiş yaparken mevcut toplam yığın boyutunu (bir düğümdeki yığın boyutu x toplam düğüm sayısı) korumaktı.
JVM'nin sıkıştırılmış OOP'leri kullanabilmesi için sınırın altında kaldığımızdan emin olmak için, Elastic tarafından önerildiği gibi veri düğümlerimizdeki yığın boyutunu ~ 30,5 GB ile sınırlıyorduk. Daha az sayıda, daha büyük düğümlere geçtikten sonra yığın boyutunu ~30,5 GB ile sınırlasaydık, daha az düğümle çalışacağımız için genel olarak yığın kapasitemizi düşürürdük.
"Geçiş yaptığımız örnekler çok büyüktü ve yığına RAM'in büyük bir bölümünü atamak istedik, böylece işaretçiler için yerimiz oldu, dosya sistemi önbelleği için yeterli alan kaldı"
Bu eşiği geçmenin etkisi hakkında pek fazla tavsiye bulamadık. Geçiş yaptığımız örnekler çok büyüktü ve RAM'in büyük bir bölümünü yığına atamak istedik, böylece işaretçiler için yerimiz oldu, dosya sistemi önbelleği için yeterli alan kaldı. Kümeleri test etmek için üretim trafiğimizi çoğaltarak birkaç eşik ile denemeler yaptık ve 200 GB'den fazla RAM'e sahip makineler için yığın boyutu olarak RAM'in ~%33 ila ~%42'sine karar verdik.

Yığın boyutundaki değişiklik, çeşitli kümeleri farklı şekilde etkiledi. Bazı kümeler, "JVM % yığın kullanımda" veya "Genç GC Toplama Süresi" gibi metriklerde herhangi bir değişiklik göstermese de, genel eğilim bir artıştı. Ne olursa olsun, genel olarak olumlu bir deneyimdi ve kümelerimiz bu yapılandırmayla 9 aydan uzun süredir sorunsuz bir şekilde çalışıyor.
Uzun vadeli düzeltme: Birçok küçük parça
Daha uzun vadeli bir çözüm, veri düğümlerinin sayısı ve boyutuna göre daha fazla sayıda daha küçük parçaya sahip olmaya doğru hareket etmek olacaktır. Daha küçük parçalara iki şekilde ulaşabiliriz:
- Dizini daha fazla birincil parçaya sahip olacak şekilde geçirme: Bu, dizindeki verileri daha fazla parça arasında dağıtır.
- Dizini daha küçük dizinlere (bölümlere) bölme: bu, dizindeki verileri daha fazla dizin arasında dağıtır.
Milyonlarca küçük parça oluşturmak veya yüzlerce bölüme sahip olmak istemediğimizi belirtmek önemlidir. Her dizin ve parça, biraz bellek ve CPU kaynakları gerektirir.
“'Mükemmel' konfigürasyona takılıp kalmak yerine, sistemimizde optimal olmayan konfigürasyonları denemeyi ve düzeltmeyi kolaylaştırmaya odaklandık”
Çoğu durumda, küçük bir büyük parça kümesi, birçok küçük parçadan daha az kaynak kullanır. Ancak başka seçenekler de var - deneme, kullanım durumunuz için daha uygun bir yapılandırmaya ulaşmanıza yardımcı olacaktır.
Sistemlerimizi daha esnek hale getirmek için, "mükemmel" konfigürasyona takılıp kalmaktansa, sistemimizde optimal olmayan konfigürasyonları denemeyi ve düzeltmeyi kolaylaştırmaya odaklandık.
Bölümleme dizinleri
Birincil parçaların sayısını artırmak, bazen Intercom'un Raporlama ürününden sorumlu kümeyi taşırken karşılaştığımız verileri toplayan sorguların performansını etkileyebilir. Buna karşılık, bir dizini birden çok dizine bölmek, sorgu performansını düşürmeden yükü daha fazla parçaya dağıtır.
Intercom'un birden fazla müşteri için verileri bir arada bulma gereksinimi yoktur, bu nedenle müşterilerin benzersiz kimliklerine göre bölümlendirmeyi seçtik. Bu, bölümleme mantığını basitleştirerek ve gerekli kurulumu azaltarak değeri daha hızlı sunmamıza yardımcı oldu.
“Verileri, mühendislerimizin mevcut alışkanlıklarını ve yöntemlerini en az etkileyecek şekilde bölmek için önce mühendislerimizin Elasticsearch'ü nasıl kullandığını anlamak için çok zaman harcadık”
Verileri mühendislerimizin mevcut alışkanlıklarını ve yöntemlerini en az etkileyecek şekilde bölümlere ayırmak için önce mühendislerimizin Elasticsearch'ü nasıl kullandığını anlamak için çok zaman harcadık. Gözlemlenebilirlik sistemimizi Elasticsearch istemci kitaplığına derinlemesine entegre ettik ve ekibimizin Elasticsearch API'leriyle etkileşime girdiği tüm farklı yolları öğrenmek için kod tabanımızı taradık.
Başarısızlık kurtarma modumuz, istekleri yeniden denemekti, bu nedenle, yetersiz olmayan isteklerde bulunduğumuz yerde gerekli değişiklikleri yaptık. "update/delete_by_query" gibi API'lerin kullanımını caydırmak için bazı linterler ekledik, çünkü bunlar önemsiz isteklerde bulunmayı kolaylaştırdı.
Tam işlevsellik sağlamak için birlikte çalışan iki yetenek oluşturduk:
- İstekleri bir dizinden diğerine yönlendirmenin bir yolu. Bu diğer dizin, bir bölüm veya yalnızca bölümlenmemiş bir dizin olabilir.
- Verileri birden çok dizine çift yazmanın bir yolu. Bu, bölümleri taşınmakta olan dizinle senkronize tutmamıza izin verdi.
“Hızdan ödün vermeden herhangi bir olayın patlama yarıçapını en aza indirmek için süreçlerimizi optimize ettik”
Toplamda, bir dizini bölümlere geçirme süreci şöyle görünür:
- Yeni bölümleri oluşturuyoruz ve ikili yazmayı açıyoruz, böylece bölümlerimiz orijinal dizinle güncel kalıyor.
- Tüm verilerin bir dolgusunu tetikliyoruz. Bu dolgu istekleri, yeni bölümlere ikili olarak yazılacaktır.
- Doldurma tamamlandığında, hem eski hem de yeni dizinlerin aynı verilere sahip olduğunu doğrularız. Her şey yolunda görünüyorsa, bölümleri birkaç müşteri için kullanmaya başlamak ve sonuçları izlemek için özellik bayraklarını kullanırız.
- Kendimize güvendikten sonra, hem eski dizine hem de bölümlere çift yazarken tüm müşterilerimizi bölümlere taşıyoruz.
- Geçişin başarılı olduğundan emin olduğumuzda, ikili yazmayı durdurur ve eski dizini sileriz.
Bu görünüşte basit adımlar çok fazla karmaşıklık içerir. Hızdan ödün vermeden herhangi bir olayın patlama yarıçapını en aza indirmek için süreçlerimizi optimize ettik.
Faydaları toplamak
Bu çalışma, Elasticsearch kümelerimizdeki yük dengesini iyileştirmemize yardımcı oldu. Daha da önemlisi, artık kabul edilemez hale geldiği her seferinde dizinleri daha az birincil parçaya sahip bölümlere geçirerek yük dağılımını iyileştirebilir ve her iki dünyanın da en iyisini elde edebiliriz: dizin başına daha az ve daha küçük parça.
Bu öğrenmeleri uygulayarak önemli performans kazanımlarının ve tasarrufların kilidini açmayı başardık.
- İki kümemizin maliyetlerini sırasıyla %40 ve %25 oranında düşürdük ve diğer kümelerde de önemli ölçüde maliyet tasarrufu sağladık.
- Belirli bir küme için ortalama CPU kullanımını %25 oranında azalttık ve medyan istek gecikmesini %100 oranında iyileştirdik. Bunu, yüksek trafik indeksini, orijinaline kıyasla bölüm başına daha az birincil parçaya sahip bölümlere geçirerek başardık.
- Genel dizinleri taşıma yeteneği aynı zamanda bir dizinin şemasını değiştirmemize, Ürün Mühendislerinin müşterilerimiz için daha iyi deneyimler oluşturmasına veya Elasticsearch 8'e yükseltme yeteneğimizin kilidini açan daha yeni bir Lucene sürümünü kullanarak verileri yeniden dizine eklememize olanak tanır.
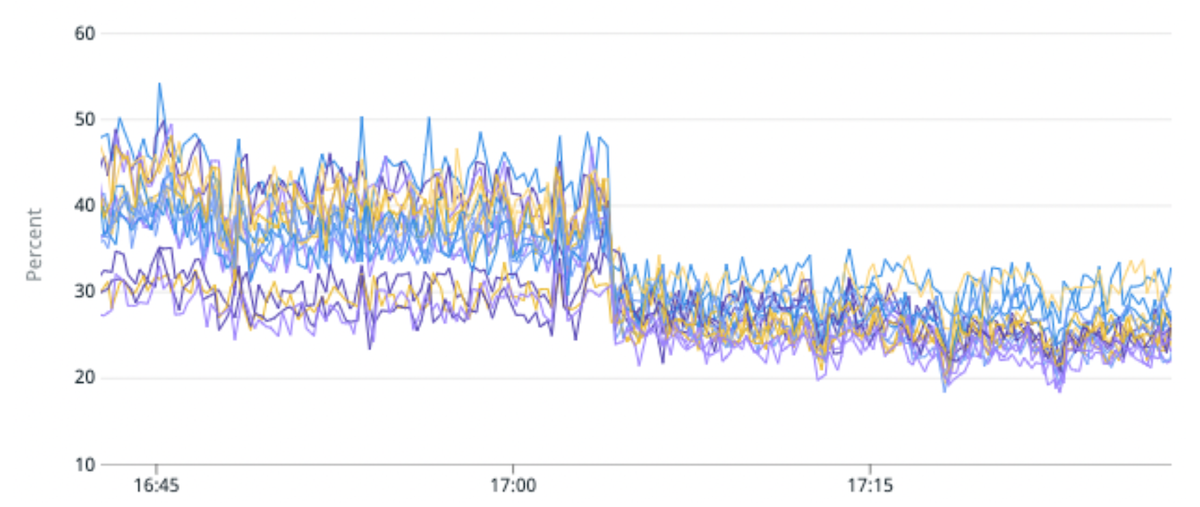
(Şekil 5) Yüksek trafik indeksini bölüm başına daha az birincil parçaya sahip bölümlere geçirerek yük dengesizliğinde %50 ve CPU kullanımında %25 iyileşme.
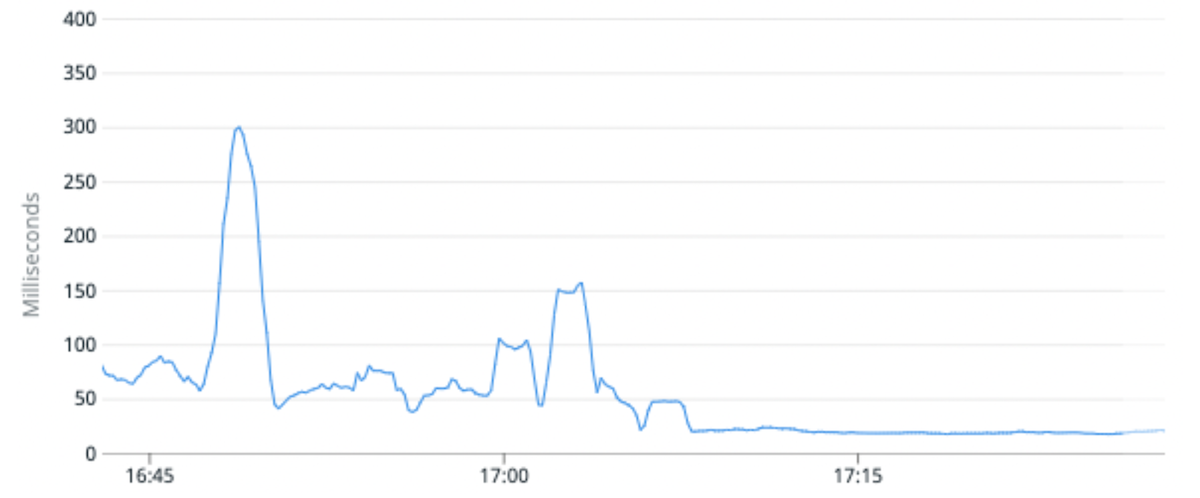
(Şek. 6) Medyan İstek gecikmesi, yüksek trafik indeksini bölüm başına daha az birincil parçaya sahip bölümlere geçirerek ortalama %100 iyileştirildi.
Sıradaki ne?
Yeni ürünlere ve özelliklere güç sağlamak için Elasticsearch'ün tanıtımı basit olmalıdır. Vizyonumuz, modern web çerçevelerinin ilişkisel veritabanlarıyla etkileşime girmesini sağladığı gibi, mühendislerimizin Elasticsearch ile etkileşim kurmasını kolaylaştırmaktır. Ekiplerin bir dizin oluşturması, dizinden okuması veya yazması, şemasında değişiklik yapması ve daha fazlasını - isteklerin nasıl sunulacağı konusunda endişelenmenize gerek kalmadan kolay olmalıdır.
Intercom'da Mühendislik ekibimizin çalışma şekliyle ilgileniyor musunuz? Daha fazla bilgi edinin ve burada açık rollerimize göz atın.
