
Rompiendo barreras para escalar: cómo hemos optimizado el uso de Elasticsearch en Intercom
Publicado: 2022-09-22Elasticsearch es una parte indispensable de Intercom.
Es la base de las funciones principales de Intercom, como la bandeja de entrada, las vistas de la bandeja de entrada, la API, los artículos, la lista de usuarios, los informes, el bot de resolución y nuestros sistemas de registro internos. Nuestros clústeres de Elasticsearch contienen más de 350 TB de datos de clientes, almacenan más de 300 000 millones de documentos y atienden más de 60 000 solicitudes por segundo en su punto máximo.
A medida que aumenta el uso de Elasticsearch de Intercom, debemos asegurarnos de que nuestros sistemas se escalen para respaldar nuestro crecimiento continuo. Con el reciente lanzamiento de nuestra bandeja de entrada de próxima generación, la confiabilidad de Elasticsearch es más crítica que nunca.
Decidimos abordar un problema con nuestra configuración de Elasticsearch que representaba un riesgo de disponibilidad y amenazaba con un tiempo de inactividad futuro: distribución desigual del tráfico/trabajo entre los nodos en nuestros clústeres de Elasticsearch.
Primeros signos de ineficiencia: Desequilibrio de carga
Elasticsearch le permite escalar horizontalmente al aumentar la cantidad de nodos que almacenan datos (nodos de datos). Empezamos a notar un desequilibrio de carga entre estos nodos de datos: algunos de ellos estaban bajo más presión (o "más calientes") que otros debido a un mayor uso del disco o de la CPU.
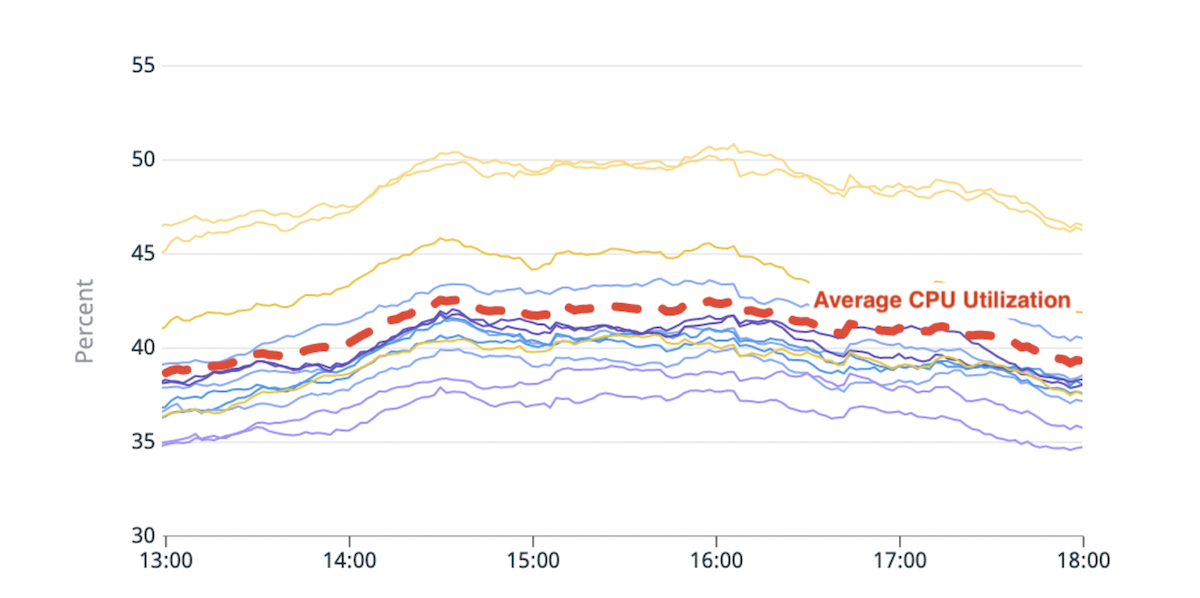
(Fig. 1) Desequilibrio en el uso de la CPU: dos nodos activos con una utilización de la CPU ~20 % más alta que el promedio.
La lógica de colocación de fragmentos integrada de Elasticsearch toma decisiones en función de un cálculo que estima aproximadamente el espacio en disco disponible en cada nodo y la cantidad de fragmentos de un índice por nodo. La utilización de recursos por fragmento no se tiene en cuenta en este cálculo. Como resultado, algunos nodos podrían recibir más fragmentos hambrientos de recursos y volverse "calientes". Cada solicitud de búsqueda es procesada por múltiples nodos de datos. Un nodo activo que supera sus límites durante el pico de tráfico puede provocar una degradación del rendimiento de todo el clúster.
Una razón común para los nodos calientes es la lógica de ubicación de fragmentos que asigna fragmentos grandes (según la utilización del disco) a los clústeres, lo que hace que sea menos probable una asignación equilibrada. Por lo general, a un nodo se le puede asignar un fragmento grande más que los demás, lo que hace que la utilización del disco sea más intensa. La presencia de fragmentos grandes también dificulta nuestra capacidad para escalar el clúster de manera incremental, ya que agregar un nodo de datos no garantiza la reducción de la carga de todos los nodos activos (Fig. 2).
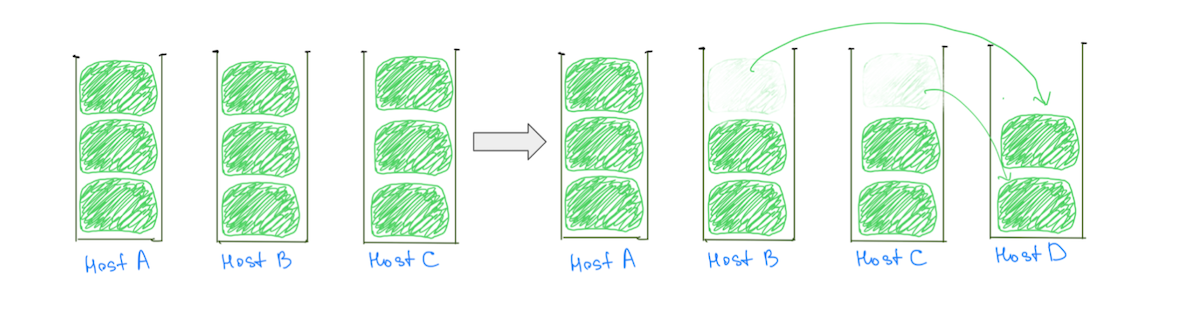
(Fig. 2) Agregar un nodo de datos no resultó en una reducción de carga en el Host A. Agregar otro nodo reduciría la carga en el Host A, pero el clúster aún tendrá una distribución de carga desigual.
Por el contrario, tener fragmentos más pequeños ayuda a reducir la carga en todos los nodos de datos a medida que se escala el clúster, incluidos los "calientes" (Fig. 3).
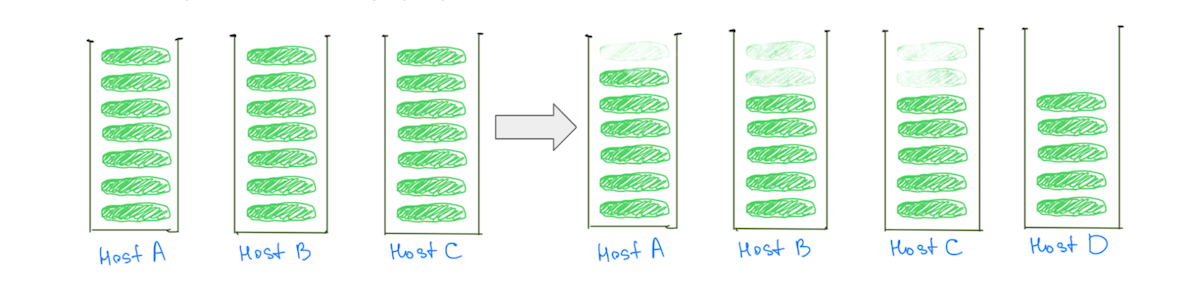
(Fig. 3) Tener muchos fragmentos más pequeños ayuda a reducir la carga en todos los nodos de datos.
Nota: el problema no se limita a los clústeres con fragmentos de gran tamaño. Observaríamos un comportamiento similar si reemplazamos "tamaño" con "utilización de CPU" o "tráfico de búsqueda", pero comparar tamaños hace que sea más fácil de visualizar.
Además de afectar la estabilidad del clúster, el desequilibrio de la carga afecta nuestra capacidad de escalar de manera rentable. Siempre tendremos que agregar más capacidad de la necesaria para mantener los nodos más calientes por debajo de niveles peligrosos. Solucionar este problema significaría una mejor disponibilidad y ahorros significativos en los costos al utilizar nuestra infraestructura de manera más eficiente.
Nuestro profundo conocimiento del problema nos ayudó a darnos cuenta de que la carga podría distribuirse de manera más uniforme si tuviéramos:
- Más fragmentos en relación con el número de nodos de datos. Esto garantizaría que la mayoría de los nodos recibieran la misma cantidad de fragmentos.
- Fragmentos más pequeños en relación con el tamaño de los nodos de datos. Si a algunos nodos se les dieran algunos fragmentos adicionales, no daría como resultado ningún aumento significativo en la carga para esos nodos.
Solución magdalena: Menos nodos más grandes
Esta relación entre el número de fragmentos y el número de nodos de datos, y el tamaño de los fragmentos y el tamaño de los nodos de datos, se puede ajustar si se tiene un mayor número de fragmentos más pequeños. Pero se puede modificar más fácilmente moviéndose a menos nodos de datos pero más grandes.
Decidimos comenzar con una magdalena para verificar esta hipótesis. Migramos algunos de nuestros clústeres a instancias más grandes y potentes con menos nodos, conservando la misma capacidad total. Por ejemplo, movimos un clúster de 40 instancias 4xlarge a 10 instancias 16xlarge, lo que redujo el desequilibrio de carga al distribuir los fragmentos de manera más uniforme.
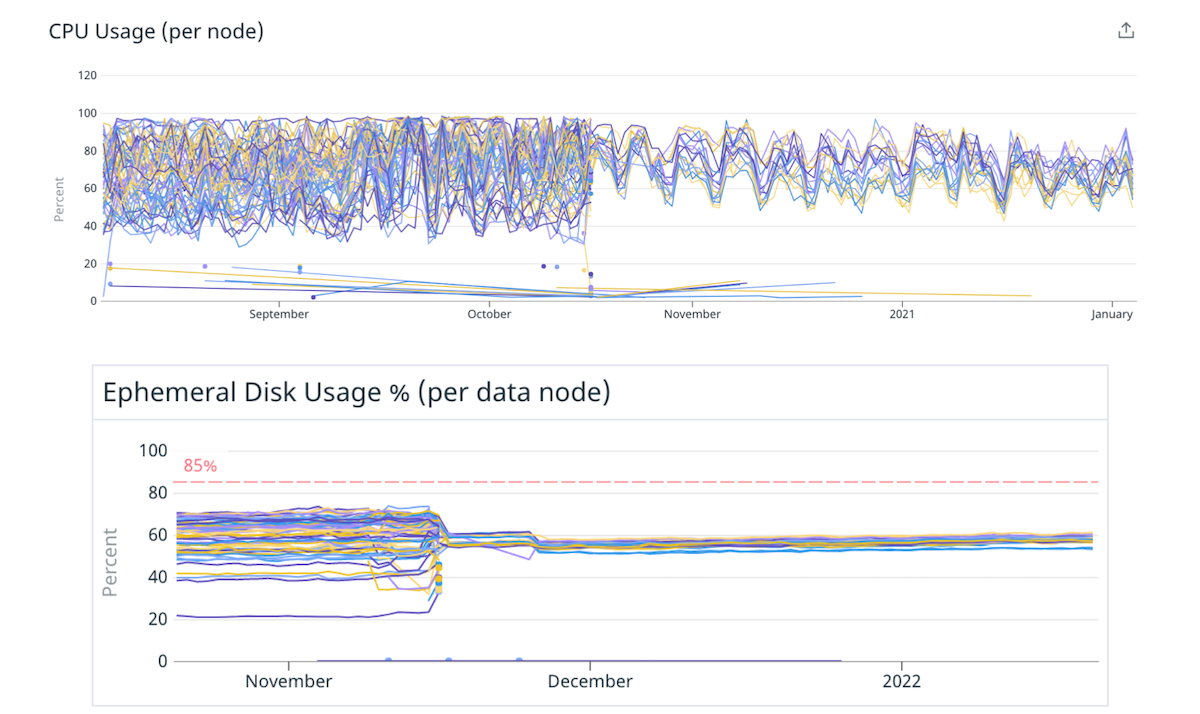
(Fig. 4) Mejor distribución de la carga en el disco y la CPU al pasar a menos nodos más grandes.
La mitigación de menos nodos más grandes validó nuestras suposiciones de que ajustar la cantidad y el tamaño de los nodos de datos puede mejorar la distribución de la carga. Podríamos habernos detenido allí, pero hubo algunas desventajas en el enfoque:
- Sabíamos que el desequilibrio de carga volvería a surgir a medida que los fragmentos crecen con el tiempo, o si se agregan más nodos al clúster para dar cuenta del aumento del tráfico.
- Los nodos más grandes hacen que el escalado incremental sea más costoso. Agregar un solo nodo ahora costaría más, incluso si solo necesitáramos un poco de capacidad adicional.
Desafío: cruzar el umbral de los punteros de objetos ordinarios comprimidos (OOP)
Pasar a menos nodos más grandes no fue tan simple como cambiar el tamaño de la instancia. Un cuello de botella al que nos enfrentamos fue conservar el tamaño total del almacenamiento dinámico disponible (tamaño del almacenamiento dinámico en un nodo x número total de nodos) a medida que migramos.
Habíamos estado limitando el tamaño del almacenamiento dinámico en nuestros nodos de datos a ~30,5 GB, como sugirió Elastic, para asegurarnos de mantenernos por debajo del límite para que la JVM pudiera usar OOP comprimidos. Si limitáramos el tamaño del almacenamiento dinámico a ~30,5 GB después de movernos a menos nodos más grandes, reduciríamos nuestra capacidad de almacenamiento dinámico en general, ya que estaríamos trabajando con menos nodos.
"Las instancias a las que estábamos migrando eran enormes y queríamos asignar una gran parte de la RAM al montón para tener espacio para los punteros, y suficiente para el caché del sistema de archivos".
No pudimos encontrar muchos consejos sobre el impacto de cruzar este umbral. Las instancias a las que estábamos migrando eran enormes y queríamos asignar una gran parte de la RAM al montón para tener espacio para los punteros, con suficiente espacio para el caché del sistema de archivos. Experimentamos con algunos umbrales mediante la replicación de nuestro tráfico de producción en clústeres de prueba, y nos decidimos por entre un 33 % y un 42 % de la RAM como tamaño de almacenamiento dinámico para máquinas con más de 200 GB de RAM.

El cambio en el tamaño del almacenamiento dinámico afectó a varios clústeres de manera diferente. Si bien algunos clústeres no mostraron cambios en métricas como "% de almacenamiento dinámico de JVM en uso" o "Tiempo de recopilación de GC joven", la tendencia general fue un aumento. Independientemente, en general fue una experiencia positiva y nuestros clústeres han estado funcionando durante más de 9 meses con esta configuración, sin ningún problema.
Solución a largo plazo: muchos fragmentos más pequeños
Una solución a más largo plazo sería pasar a tener una mayor cantidad de fragmentos más pequeños en relación con la cantidad y el tamaño de los nodos de datos. Podemos llegar a fragmentos más pequeños de dos maneras:
- Migrar el índice para tener más fragmentos primarios: esto distribuye los datos en el índice entre más fragmentos.
- Descomponer el índice en índices más pequeños (particiones): esto distribuye los datos en el índice entre más índices.
Es importante tener en cuenta que no queremos crear un millón de pequeños fragmentos ni tener cientos de particiones. Cada índice y fragmento requiere algunos recursos de memoria y CPU.
“Nos enfocamos en hacer que sea más fácil experimentar y corregir configuraciones subóptimas dentro de nuestro sistema, en lugar de obsesionarnos con la configuración 'perfecta'”
En la mayoría de los casos, un pequeño conjunto de fragmentos grandes utiliza menos recursos que muchos fragmentos pequeños. Pero hay otras opciones: la experimentación debería ayudarlo a alcanzar una configuración más adecuada para su caso de uso.
Para hacer que nuestros sistemas sean más resistentes, nos enfocamos en hacer que sea más fácil experimentar y corregir configuraciones subóptimas dentro de nuestro sistema, en lugar de obsesionarnos con la configuración "perfecta".
Índices de particionamiento
El aumento de la cantidad de fragmentos primarios a veces puede afectar el rendimiento de las consultas que agregan datos, lo que experimentamos al migrar el clúster responsable del producto de informes de Intercom. Por el contrario, la partición de un índice en varios índices distribuye la carga en más fragmentos sin degradar el rendimiento de las consultas.
Intercom no tiene ningún requisito para la ubicación conjunta de datos para varios clientes, por lo que elegimos particionar en función de las identificaciones únicas de los clientes. Esto nos ayudó a entregar valor más rápido al simplificar la lógica de partición y reducir la configuración requerida.
“Para particionar los datos de una manera que impactara lo menos posible en los hábitos y métodos existentes de nuestros ingenieros, primero invertimos mucho tiempo en comprender cómo nuestros ingenieros usan Elasticsearch”
Para particionar los datos de una manera que impactara lo menos posible en los hábitos y métodos existentes de nuestros ingenieros, primero invertimos mucho tiempo en comprender cómo nuestros ingenieros usan Elasticsearch. Integramos profundamente nuestro sistema de observabilidad en la biblioteca del cliente de Elasticsearch y revisamos nuestra base de código para aprender sobre las diferentes formas en que nuestro equipo interactúa con las API de Elasticsearch.
Nuestro modo de recuperación de fallas era volver a intentar las solicitudes, por lo que hicimos los cambios necesarios cuando realizábamos solicitudes no idempotentes. Terminamos agregando algunos linters para desalentar el uso de API como `update/delete_by_query`, ya que facilitaban la realización de solicitudes no idempotentes.
Construimos dos capacidades que trabajaron juntas para ofrecer una funcionalidad completa:
- Una forma de enrutar solicitudes de un índice a otro. Este otro índice podría ser una partición o simplemente un índice no particionado.
- Una forma de escritura dual de datos en múltiples índices. Esto nos permitió mantener las particiones sincronizadas con el índice que se está migrando.
“Optimizamos nuestros procesos para minimizar el radio de explosión de cualquier incidente, sin comprometer la velocidad”
En total, el proceso de migrar un índice a particiones se ve así:
- Creamos las nuevas particiones y activamos la escritura dual para que nuestras particiones se mantengan actualizadas con el índice original.
- Activamos una reposición de todos los datos. Estas solicitudes de reposición se escribirán de forma dual en las nuevas particiones.
- Cuando se completa el reabastecimiento, validamos que tanto el índice antiguo como el nuevo tengan los mismos datos. Si todo se ve bien, usamos indicadores de características para comenzar a usar las particiones para algunos clientes y monitorear los resultados.
- Una vez que estamos seguros, movemos a todos nuestros clientes a las particiones, todo mientras realizamos una doble escritura tanto en el índice antiguo como en las particiones.
- Cuando estamos seguros de que la migración se ha realizado correctamente, detenemos la escritura dual y eliminamos el índice antiguo.
Estos pasos aparentemente simples tienen mucha complejidad. Optimizamos nuestros procesos para minimizar el radio de explosión de cualquier incidente, sin comprometer la velocidad.
Cosechando los beneficios
Este trabajo nos ayudó a mejorar el equilibrio de carga en nuestros clústeres de Elasticsearch. Más importante aún, ahora podemos mejorar la distribución de la carga cada vez que se vuelve inaceptable al migrar índices a particiones con menos fragmentos primarios, logrando lo mejor de ambos mundos: menos fragmentos y más pequeños por índice.
Al aplicar estos aprendizajes, pudimos desbloquear importantes ganancias de rendimiento y ahorros.
- Redujimos los costos de dos de nuestros clústeres en un 40 % y un 25 %, respectivamente, y también obtuvimos importantes ahorros de costos en otros clústeres.
- Redujimos la utilización promedio de CPU para un determinado clúster en un 25 % y mejoramos la latencia de solicitud promedio en un 100 %. Logramos esto al migrar un alto índice de tráfico a particiones con menos fragmentos primarios por partición en comparación con el original.
- La capacidad general de migrar índices también nos permite cambiar el esquema de un índice, lo que permite a los ingenieros de productos crear mejores experiencias para nuestros clientes o volver a indexar los datos con una versión más nueva de Lucene que desbloquea nuestra capacidad de actualizar a Elasticsearch 8.
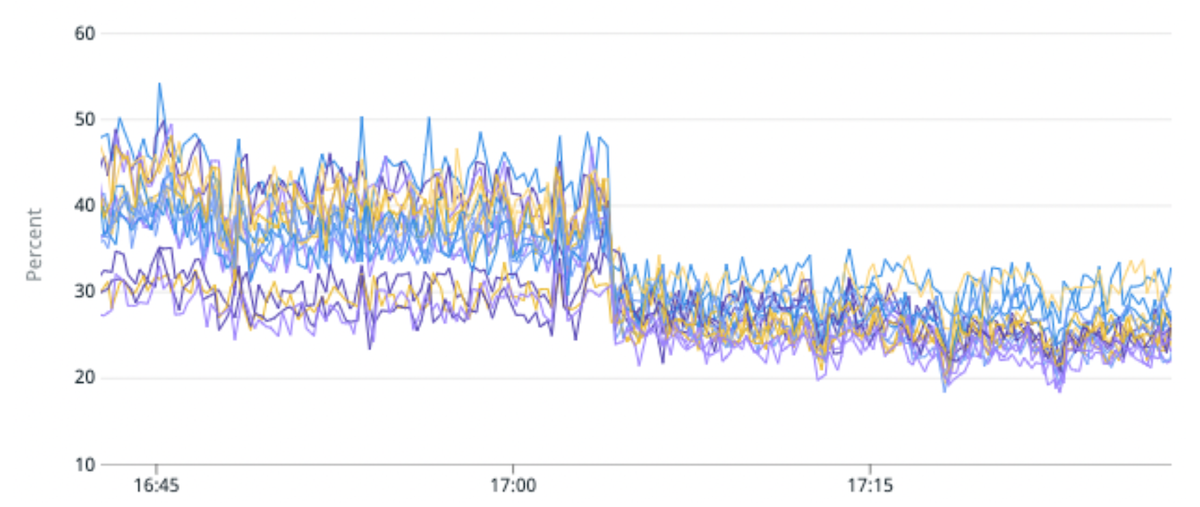
(Fig. 5) 50 % de mejora en el desequilibrio de carga y 25 % de mejora en la utilización de la CPU al migrar un índice de tráfico alto a particiones con menos fragmentos primarios por partición.
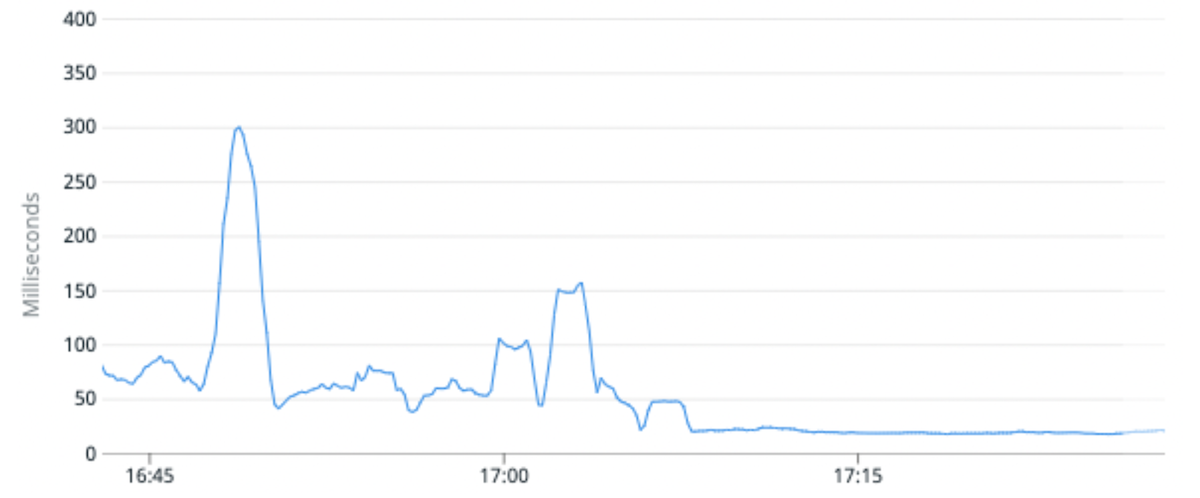
(Fig. 6) La latencia media de solicitudes mejoró en un 100 % en promedio al migrar un índice de tráfico alto a particiones con menos fragmentos primarios por partición.
¿Que sigue?
La introducción de Elasticsearch para potenciar nuevos productos y funciones debería ser sencilla. Nuestra visión es hacer que sea tan simple para nuestros ingenieros interactuar con Elasticsearch como lo hacen los marcos web modernos para interactuar con bases de datos relacionales. Debería ser fácil para los equipos crear un índice, leer o escribir desde el índice, realizar cambios en su esquema y más, sin tener que preocuparse por cómo se atienden las solicitudes.
¿Está interesado en la forma en que trabaja nuestro equipo de Ingeniería en Intercom? Obtenga más información y consulte nuestros puestos vacantes aquí.
