
Éliminer les obstacles à l'évolutivité : comment nous avons optimisé l'utilisation d'Elasticsearch chez Intercom
Publié: 2022-09-22Elasticsearch est un élément indispensable d'Intercom.
Il sous-tend les principales fonctionnalités d'Intercom telles que la boîte de réception, les vues de la boîte de réception, l'API, les articles, la liste des utilisateurs, les rapports, le bot de résolution et nos systèmes de journalisation internes. Nos clusters Elasticsearch contiennent plus de 350 To de données clients, stockent plus de 300 milliards de documents et traitent plus de 60 000 requêtes par seconde en période de pointe.
À mesure que l'utilisation d'Elasticsearch d'Intercom augmente, nous devons nous assurer que nos systèmes évoluent pour soutenir notre croissance continue. Avec le lancement récent de notre boîte de réception de nouvelle génération, la fiabilité d'Elasticsearch est plus critique que jamais.
Nous avons décidé de résoudre un problème avec notre configuration Elasticsearch qui posait un risque de disponibilité et menaçait de futurs temps d'arrêt : une répartition inégale du trafic/du travail entre les nœuds de nos clusters Elasticsearch.
Premiers signes d'inefficacité : déséquilibre de charge
Elasticsearch vous permet d'évoluer horizontalement en augmentant le nombre de nœuds qui stockent les données (nœuds de données). Nous avons commencé à remarquer un déséquilibre de charge entre ces nœuds de données : certains d'entre eux étaient sous plus de pression (ou "plus chauds") que d'autres en raison d'une utilisation plus élevée du disque ou du processeur.
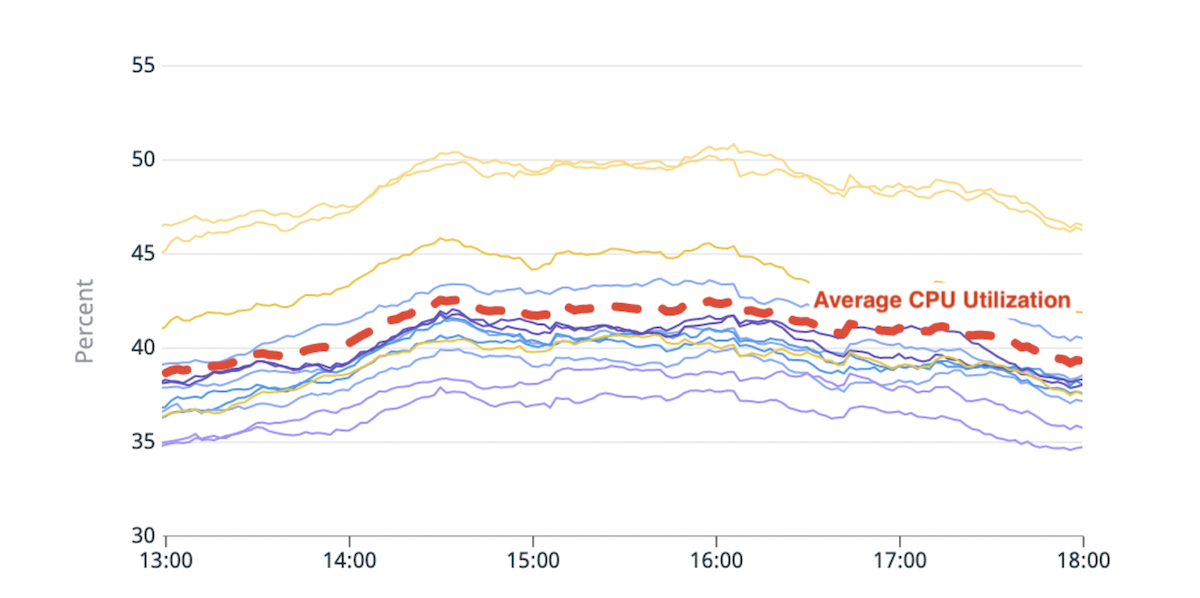
(Fig. 1) Déséquilibre dans l'utilisation du processeur : deux nœuds chauds avec une utilisation du processeur environ 20 % supérieure à la moyenne.
La logique de placement des partitions intégrée d'Elasticsearch prend des décisions basées sur un calcul qui estime approximativement l'espace disque disponible dans chaque nœud et le nombre de partitions d'un index par nœud. L'utilisation des ressources par partition n'entre pas en ligne de compte dans ce calcul. En conséquence, certains nœuds pourraient recevoir des fragments plus gourmands en ressources et devenir « chauds ». Chaque demande de recherche est traitée par plusieurs nœuds de données. Un nœud chaud qui est poussé au-delà de ses limites lors d'un pic de trafic peut entraîner une dégradation des performances pour l'ensemble du cluster.
Une raison courante des nœuds chauds est la logique de placement des partitions qui attribue de grandes partitions (en fonction de l'utilisation du disque) aux clusters, ce qui rend moins probable une allocation équilibrée. En règle générale, un nœud peut se voir attribuer un grand fragment de plus que les autres, ce qui le rend plus chaud dans l'utilisation du disque. La présence de grands fragments entrave également notre capacité à faire évoluer le cluster de manière incrémentielle, car l'ajout d'un nœud de données ne garantit pas la réduction de la charge de tous les nœuds chauds (Fig. 2).
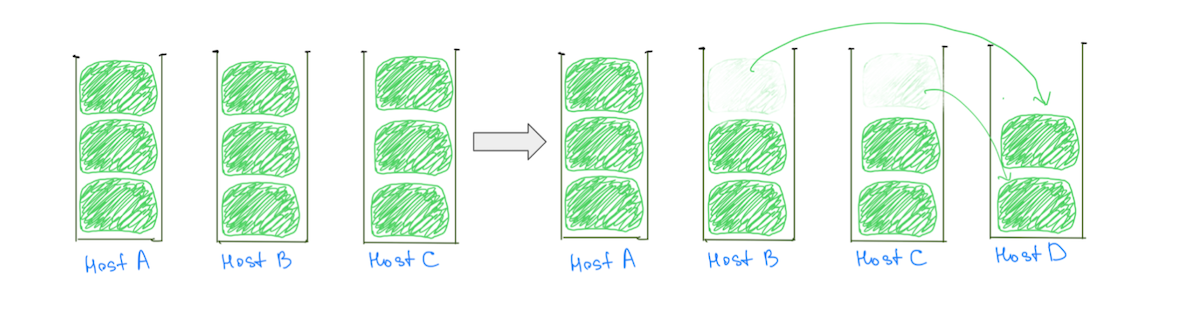
(Fig. 2) L'ajout d'un nœud de données n'a pas entraîné de réduction de charge sur l'hôte A. L'ajout d'un autre nœud réduirait la charge sur l'hôte A, mais le cluster aura toujours une répartition de charge inégale.
En revanche, le fait d'avoir des fragments plus petits permet de réduire la charge sur tous les nœuds de données à mesure que le cluster évolue, y compris les « chauds » (Fig. 3).
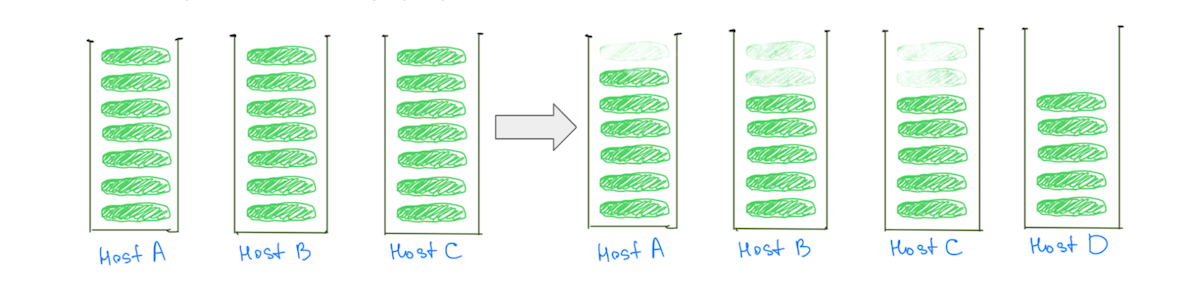
(Fig. 3) Le fait d'avoir de nombreux fragments plus petits permet de réduire la charge sur tous les nœuds de données.
Remarque : le problème ne se limite pas aux clusters avec des fragments de grande taille. Nous observerions un comportement similaire si nous remplacions « taille » par « utilisation du processeur » ou « trafic de recherche », mais la comparaison des tailles facilite la visualisation.
En plus d'avoir un impact sur la stabilité du cluster, le déséquilibre de charge affecte notre capacité à évoluer de manière rentable. Nous devrons toujours ajouter plus de capacité que nécessaire pour maintenir les nœuds les plus chauds en dessous de niveaux dangereux. Résoudre ce problème signifierait une meilleure disponibilité et des économies importantes grâce à une utilisation plus efficace de notre infrastructure.
Notre compréhension approfondie du problème nous a aidés à réaliser que la charge pourrait être répartie plus uniformément si nous avions :
- Plus de fragments par rapport au nombre de nœuds de données. Cela garantirait que la plupart des nœuds reçoivent un nombre égal de fragments.
- Des fragments plus petits par rapport à la taille des nœuds de données. Si certains nœuds recevaient quelques fragments supplémentaires, cela n'entraînerait aucune augmentation significative de la charge pour ces nœuds.
Solution cupcake : moins de nœuds plus gros
Ce rapport entre le nombre de fragments et le nombre de nœuds de données, et la taille des fragments par rapport à la taille des nœuds de données, peut être modifié en ayant un plus grand nombre de fragments plus petits. Mais il peut être modifié plus facilement en déplaçant vers des nœuds de données moins nombreux mais plus gros.
Nous avons décidé de commencer par un cupcake pour vérifier cette hypothèse. Nous avons migré quelques-uns de nos clusters vers des instances plus grandes et plus puissantes avec moins de nœuds, en préservant la même capacité totale. Par exemple, nous avons déplacé un cluster de 40 instances 4xlarge vers 10 instances 16xlarge, réduisant ainsi le déséquilibre de charge en répartissant les fragments plus uniformément.
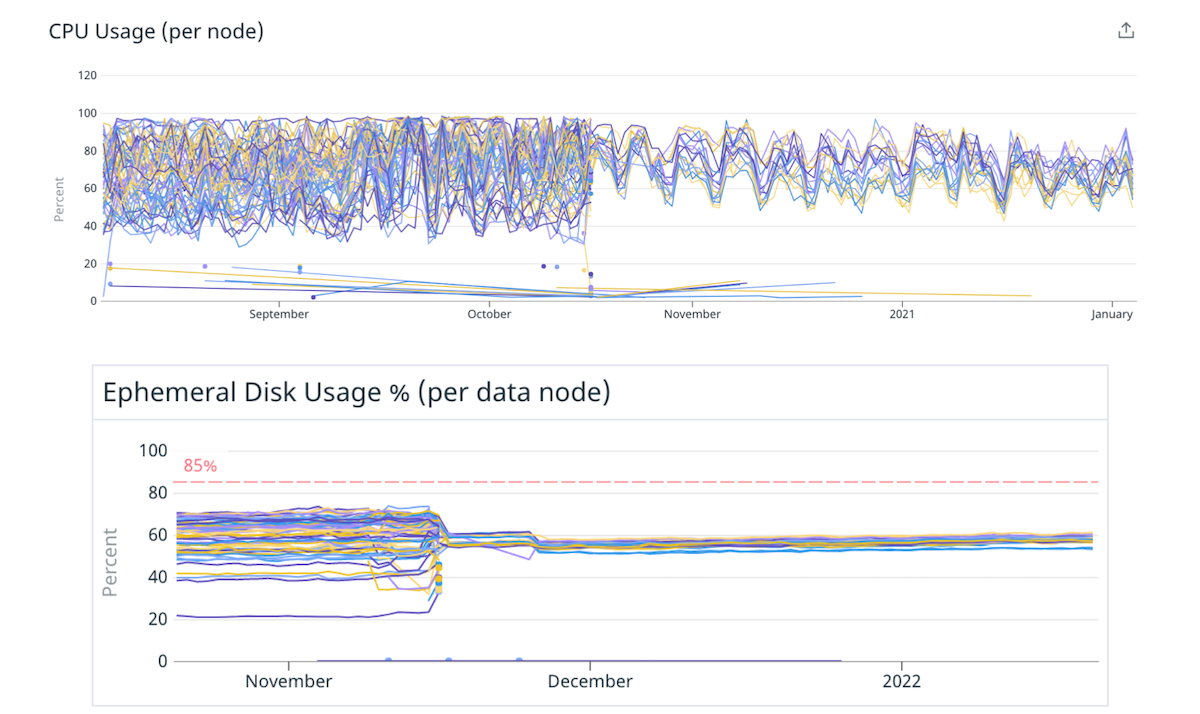
(Fig. 4) Meilleure répartition de la charge sur le disque et le processeur en passant à moins de nœuds plus gros.
L'atténuation du nombre moins important de nœuds plus gros a validé nos hypothèses selon lesquelles l'ajustement du nombre et de la taille des nœuds de données peut améliorer la répartition de la charge. Nous aurions pu nous arrêter là, mais il y avait quelques inconvénients à l'approche :
- Nous savions que le déséquilibre de charge réapparaîtrait à mesure que les fragments grossiraient avec le temps, ou si davantage de nœuds étaient ajoutés au cluster pour tenir compte de l'augmentation du trafic.
- Les nœuds plus gros rendent la mise à l'échelle incrémentielle plus coûteuse. L'ajout d'un seul nœud coûterait désormais plus cher, même si nous n'avions besoin que d'un peu de capacité supplémentaire.
Défi : Franchir le seuil des pointeurs d'objets ordinaires compressés (OOP)
Passer à moins de nœuds plus gros n'était pas aussi simple que de simplement changer la taille de l'instance. Un goulot d'étranglement auquel nous étions confrontés était la préservation de la taille totale du tas disponible (taille du tas sur un nœud x nombre total de nœuds) lors de la migration.
Nous avions plafonné la taille du tas dans nos nœuds de données à environ 30,5 Go, comme suggéré par Elastic, pour nous assurer que nous restions en dessous du seuil afin que la JVM puisse utiliser des OOP compressés. Si nous plafonnions la taille du tas à ~ 30,5 Go après être passés à des nœuds moins nombreux et plus gros, nous réduirions globalement notre capacité de tas car nous travaillerions avec moins de nœuds.
"Les instances vers lesquelles nous migrions étaient énormes et nous voulions affecter une grande partie de la RAM au tas afin que nous ayons de l'espace pour les pointeurs, avec suffisamment de place pour le cache du système de fichiers"
Nous n'avons pas pu trouver beaucoup de conseils sur l'impact du franchissement de ce seuil. Les instances vers lesquelles nous migrions étaient énormes et nous voulions affecter une grande partie de la RAM au tas afin d'avoir de l'espace pour les pointeurs, avec suffisamment de place pour le cache du système de fichiers. Nous avons expérimenté quelques seuils en reproduisant notre trafic de production pour tester des clusters, et nous sommes installés sur ~33% à ~42% de la RAM comme taille de tas pour les machines avec plus de 200 Go de RAM.

La modification de la taille du tas a eu un impact différent sur les différents clusters. Alors que certains clusters n'ont montré aucun changement dans les métriques telles que "JVM % heap in use" ou "Young GC Collection Time", la tendance générale était à la hausse. Quoi qu'il en soit, dans l'ensemble, l'expérience a été positive et nos clusters fonctionnent depuis plus de 9 mois avec cette configuration, sans aucun problème.
Solution à long terme : de nombreux fragments plus petits
Une solution à plus long terme consisterait à adopter un plus grand nombre de fragments plus petits par rapport au nombre et à la taille des nœuds de données. Nous pouvons accéder à des fragments plus petits de deux manières :
- Migrer l'index pour avoir plus de partitions principales : cela répartit les données de l'index entre plusieurs partitions.
- Décomposer l'index en index plus petits (partitions) : cela répartit les données de l'index entre plusieurs index.
Il est important de noter que nous ne voulons pas créer un million de fragments minuscules ou avoir des centaines de partitions. Chaque index et fragment nécessite des ressources de mémoire et de processeur.
"Nous nous sommes concentrés sur la facilitation de l'expérimentation et de la correction des configurations sous-optimales au sein de notre système, plutôt que sur la configuration "parfaite""
Dans la plupart des cas, un petit ensemble de grandes partitions utilise moins de ressources que de nombreuses petites partitions. Mais il existe d'autres options - l'expérimentation devrait vous aider à atteindre une configuration plus adaptée à votre cas d'utilisation.
Pour rendre nos systèmes plus résilients, nous nous sommes efforcés de faciliter l'expérimentation et de corriger les configurations sous-optimales au sein de notre système, plutôt que de nous focaliser sur la configuration "parfaite".
Index de partitionnement
L'augmentation du nombre de partitions principales peut parfois avoir un impact sur les performances des requêtes qui agrègent les données, ce que nous avons rencontré lors de la migration du cluster responsable du produit de rapport d'Intercom. En revanche, le partitionnement d'un index en plusieurs index répartit la charge sur davantage de fragments sans dégrader les performances des requêtes.
Intercom n'a pas besoin de co-localiser les données pour plusieurs clients, nous avons donc choisi de partitionner en fonction des identifiants uniques des clients. Cela nous a aidés à générer de la valeur plus rapidement en simplifiant la logique de partitionnement et en réduisant la configuration requise.
"Pour partitionner les données d'une manière qui ait le moins d'impact sur les habitudes et les méthodes existantes de nos ingénieurs, nous avons d'abord investi beaucoup de temps pour comprendre comment nos ingénieurs utilisent Elasticsearch"
Pour partitionner les données d'une manière qui ait le moins d'impact sur les habitudes et les méthodes existantes de nos ingénieurs, nous avons d'abord investi beaucoup de temps pour comprendre comment nos ingénieurs utilisent Elasticsearch. Nous avons profondément intégré notre système d'observabilité dans la bibliothèque client Elasticsearch et balayé notre base de code pour en savoir plus sur toutes les différentes façons dont notre équipe interagit avec les API Elasticsearch.
Notre mode de récupération après échec consistait à réessayer les requêtes, nous avons donc apporté les modifications requises là où nous faisions des requêtes non idempotentes. Nous avons fini par ajouter quelques linters pour décourager l'utilisation d'API comme `update/delete_by_query`, car ils facilitaient la création de requêtes non idempotentes.
Nous avons construit deux capacités qui ont fonctionné ensemble pour offrir une fonctionnalité complète :
- Un moyen d'acheminer les requêtes d'un index à un autre. Cet autre index peut être une partition ou simplement un index non partitionné.
- Un moyen d'écrire des données en double sur plusieurs index. Cela nous a permis de garder les partitions synchronisées avec l'index en cours de migration.
"Nous avons optimisé nos processus pour minimiser le rayon de souffle de tout incident, sans compromettre la vitesse"
Au total, le processus de migration d'un index vers des partitions ressemble à ceci :
- Nous créons les nouvelles partitions et activons la double écriture afin que nos partitions restent à jour avec l'index d'origine.
- Nous déclenchons un remblai de toutes les données. Ces demandes de remplissage seront écrites en double sur les nouvelles partitions.
- Une fois le remplissage terminé, nous validons que les anciens et les nouveaux index contiennent les mêmes données. Si tout semble correct, nous utilisons des indicateurs de fonctionnalité pour commencer à utiliser les partitions pour quelques clients et surveiller les résultats.
- Une fois que nous sommes confiants, nous déplaçons tous nos clients vers les partitions, tout en écrivant à la fois sur l'ancien index et sur les partitions.
- Lorsque nous sommes sûrs que la migration a réussi, nous arrêtons la double écriture et supprimons l'ancien index.
Ces étapes apparemment simples sont très complexes. Nous avons optimisé nos processus pour minimiser le rayon de souffle de tout incident, sans compromettre la vitesse.
Récolter les bénéfices
Ce travail nous a permis d'améliorer l'équilibrage de charge dans nos clusters Elasticsearch. Plus important encore, nous pouvons désormais améliorer la répartition de la charge chaque fois qu'elle devient inacceptable en migrant les index vers des partitions avec moins de fragments primaires, obtenant ainsi le meilleur des deux mondes : des fragments moins nombreux et plus petits par index.
En appliquant ces apprentissages, nous avons pu débloquer d'importants gains de performance et des économies.
- Nous avons réduit les coûts de deux de nos clusters de 40 % et 25 % respectivement, et avons également réalisé des économies importantes sur d'autres clusters.
- Nous avons réduit de 25 % l'utilisation moyenne du processeur pour un certain cluster et amélioré la latence médiane des requêtes de 100 %. Nous y sommes parvenus en migrant un indice de trafic élevé vers des partitions avec moins de fragments primaires par partition par rapport à l'original.
- La possibilité générale de migrer les index nous permet également de modifier le schéma d'un index, permettant aux ingénieurs produit de créer de meilleures expériences pour nos clients, ou de réindexer les données à l'aide d'une version plus récente de Lucene qui débloque notre capacité de mise à niveau vers Elasticsearch 8.
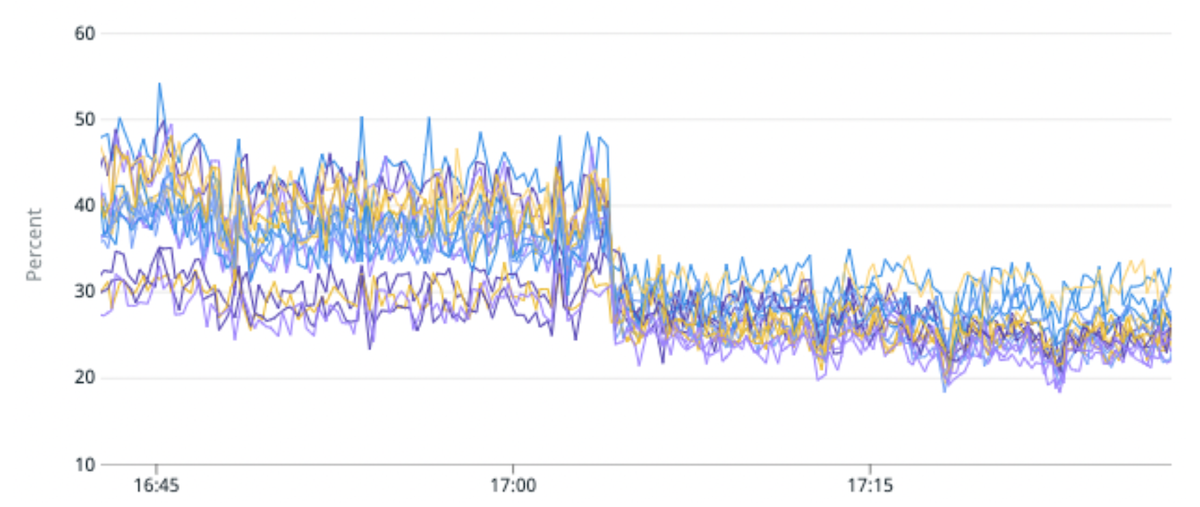
(Fig. 5) Amélioration de 50 % du déséquilibre de charge et de 25 % de l'utilisation du CPU en migrant un indice de trafic élevé vers des partitions avec moins de fragments primaires par partition.
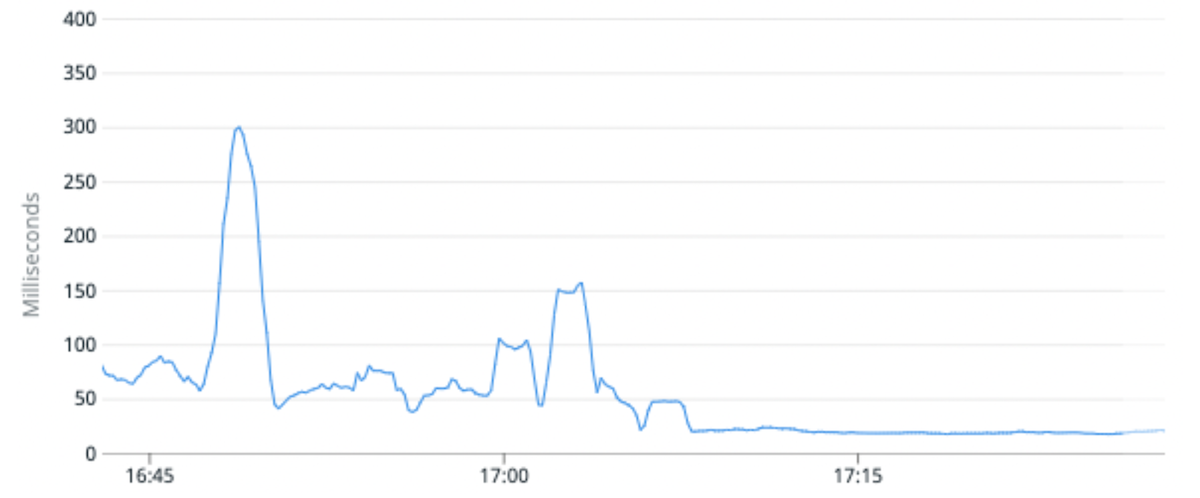
(Fig. 6) La latence médiane des requêtes s'est améliorée de 100 % en moyenne en migrant un indice de trafic élevé vers des partitions avec moins de fragments primaires par partition.
Et après?
L'introduction d'Elasticsearch pour alimenter de nouveaux produits et fonctionnalités devrait être simple. Notre vision est de rendre l'interaction avec Elasticsearch aussi simple pour nos ingénieurs que les frameworks Web modernes le font pour interagir avec des bases de données relationnelles. Il devrait être facile pour les équipes de créer un index, de lire ou d'écrire à partir de l'index, d'apporter des modifications à son schéma, etc., sans avoir à se soucier de la manière dont les requêtes sont servies.
Êtes-vous intéressé par la façon dont notre équipe d'ingénierie travaille chez Intercom? Apprenez-en plus et consultez nos rôles ouverts ici.
