
การทำลายอุปสรรคในการปรับขนาด: เราปรับปรุงการใช้งาน Elasticsearch ที่ Intercom อย่างไร
เผยแพร่แล้ว: 2022-09-22Elasticsearch เป็นส่วนสำคัญของอินเตอร์คอม
รองรับฟีเจอร์หลักของอินเตอร์คอม เช่น Inbox, Inbox Views, API, Articles, รายชื่อผู้ใช้, การรายงาน, Resolution Bot และระบบการบันทึกภายในของเรา คลัสเตอร์ Elasticsearch ของเรามีข้อมูลลูกค้ามากกว่า 350TB จัดเก็บเอกสารมากกว่า 300 พันล้านเอกสาร และให้บริการคำขอมากกว่า 60,000 รายการต่อวินาทีที่จุดสูงสุด
เมื่อการใช้งาน Elasticsearch ของ Intercom เพิ่มขึ้น เราจำเป็นต้องตรวจสอบให้แน่ใจว่าระบบของเราปรับขนาดเพื่อรองรับการเติบโตอย่างต่อเนื่องของเรา ด้วยการเปิดตัว Inbox รุ่นต่อไป ความน่าเชื่อถือของ Elasticsearch มีความสำคัญมากกว่าที่เคย
เราตัดสินใจที่จะจัดการกับปัญหาด้วยการตั้งค่า Elasticsearch ของเราซึ่งก่อให้เกิดความเสี่ยงด้านความพร้อมใช้งานและคุกคามการหยุดทำงานในอนาคต: การกระจายการรับส่งข้อมูล/การทำงานที่ไม่สม่ำเสมอระหว่างโหนดในคลัสเตอร์ Elasticsearch ของเรา
สัญญาณเริ่มต้นของความไร้ประสิทธิภาพ: ความไม่สมดุลของโหลด
Elasticsearch ช่วยให้คุณปรับขนาดในแนวนอนโดยเพิ่มจำนวนโหนดที่เก็บข้อมูล (โหนดข้อมูล) เราเริ่มสังเกตเห็นความไม่สมดุลของโหลดระหว่างโหนดข้อมูลเหล่านี้: บางโหนดอยู่ภายใต้แรงกดดัน (หรือ "ร้อนกว่า") มากกว่าส่วนอื่นๆ เนื่องจากการใช้ดิสก์หรือ CPU ที่สูงขึ้น
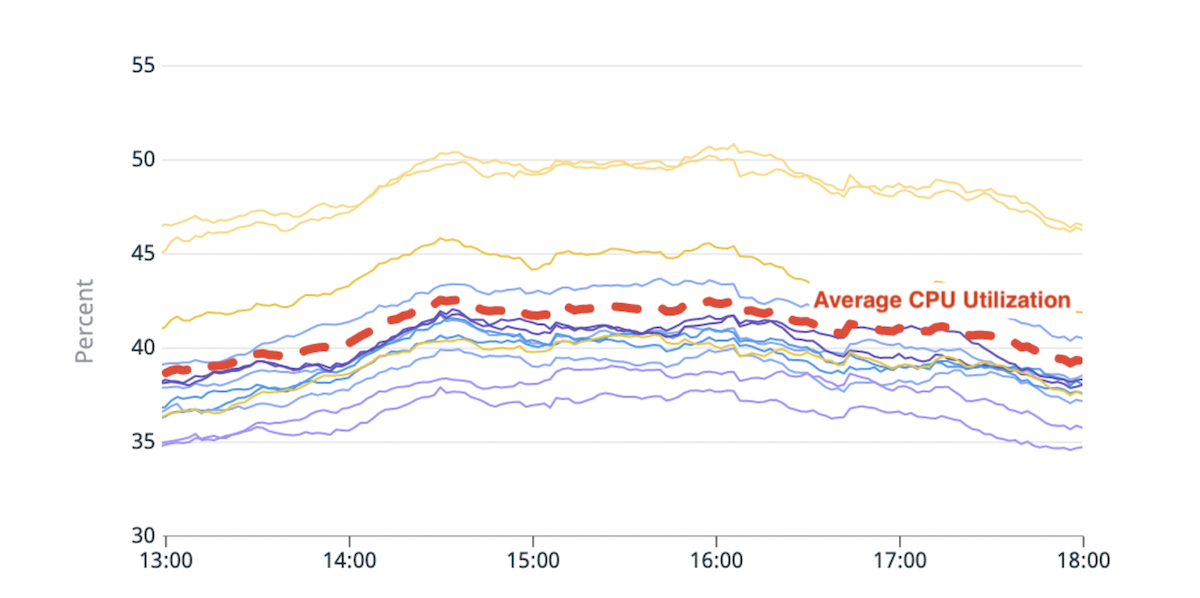
(รูปที่ 1) ความไม่สมดุลในการใช้งาน CPU: ฮอตโหนดสองโหนดที่มีการใช้งาน CPU สูงกว่าค่าเฉลี่ย ~20%
ตรรกะการจัดตำแหน่งชาร์ดในตัวของ Elasticsearch ตัดสินใจโดยอิงจากการคำนวณที่ประมาณการพื้นที่ดิสก์ที่มีอยู่อย่างคร่าวๆ ในแต่ละโหนดและจำนวนชาร์ดของดัชนีต่อโหนด การใช้ทรัพยากรโดยชาร์ดจะไม่นับรวมในการคำนวณนี้ เป็นผลให้บางโหนดสามารถรับชิ้นส่วนที่หิวโหยทรัพยากรมากขึ้นและกลายเป็น "ร้อนแรง" คำขอค้นหาทุกรายการจะถูกประมวลผลโดยโหนดข้อมูลหลายโหนด ฮ็อตโหนดที่ถูกผลักเกินขีดจำกัดระหว่างการรับส่งข้อมูลสูงสุด อาจทำให้ประสิทธิภาพการทำงานลดลงสำหรับทั้งคลัสเตอร์
สาเหตุทั่วไปของฮ็อตโหนดคือตรรกะการจัดวางชาร์ดที่กำหนดชาร์ดขนาดใหญ่ (ตามการใช้งานดิสก์) ให้กับคลัสเตอร์ ทำให้การจัดสรรแบบสมดุลมีโอกาสน้อยลง โดยทั่วไป โหนดอาจถูกกำหนดให้กับชาร์ดขนาดใหญ่หนึ่งส่วนมากกว่าโหนดอื่น ทำให้ร้อนขึ้นในการใช้งานดิสก์ การมีอยู่ของชาร์ดขนาดใหญ่ยังเป็นอุปสรรคต่อความสามารถของเราในการเพิ่มขนาดคลัสเตอร์ เนื่องจากการเพิ่มโหนดข้อมูลไม่ได้รับประกันการลดโหลดจากฮ็อตโหนดทั้งหมด (รูปที่ 2)
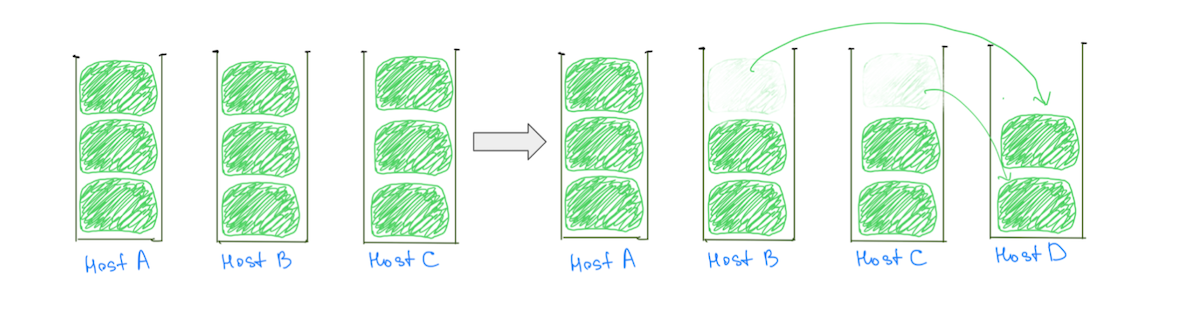
(รูปที่ 2) การเพิ่ม data node ไม่ได้ส่งผลให้โหลดบน Host A ลดลง การเพิ่มโหนดอื่นจะลดโหลดบน Host A แต่คลัสเตอร์จะยังคงมีการกระจายโหลดที่ไม่สม่ำเสมอ
ในทางตรงกันข้าม การมีชาร์ดที่เล็กกว่าช่วยลดภาระของโหนดข้อมูลทั้งหมดเมื่อคลัสเตอร์สเกล รวมถึงส่วนที่ "ร้อน" (รูปที่ 3)
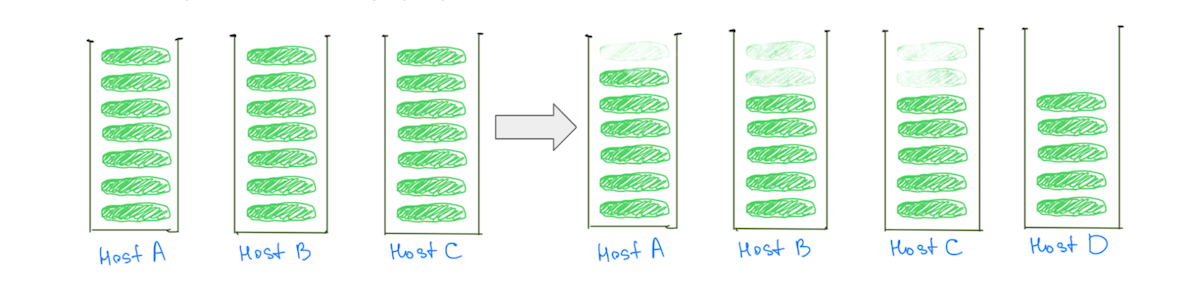
(รูปที่ 3) การมีชาร์ดที่เล็กกว่าจำนวนมากช่วยลดภาระบนโหนดข้อมูลทั้งหมด
หมายเหตุ: ปัญหาไม่ได้จำกัดเฉพาะคลัสเตอร์ที่มีชาร์ดขนาดใหญ่ เราจะสังเกตเห็นพฤติกรรมที่คล้ายกันนี้หากเราแทนที่ "ขนาด" ด้วย "การใช้ CPU" หรือ "ปริมาณการค้นหา" แต่การเปรียบเทียบขนาดทำให้มองเห็นได้ง่ายขึ้น
เช่นเดียวกับผลกระทบต่อความเสถียรของคลัสเตอร์ ความไม่สมดุลของโหลดส่งผลต่อความสามารถของเราในการปรับขนาดได้อย่างคุ้มค่า เราจะต้องเพิ่มความจุมากกว่าที่จำเป็นเสมอเพื่อให้โหนดที่ร้อนกว่านั้นต่ำกว่าระดับอันตราย การแก้ไขปัญหานี้จะหมายถึงความพร้อมใช้งานที่ดีขึ้นและประหยัดต้นทุนได้อย่างมากจากการใช้โครงสร้างพื้นฐานของเราอย่างมีประสิทธิภาพมากขึ้น
ความเข้าใจอย่างลึกซึ้งเกี่ยวกับปัญหาช่วยให้เราตระหนักว่าสามารถกระจายโหลดได้อย่างเท่าเทียมกันหากเรามี:
- ชาร์ด เพิ่มเติม สัมพันธ์กับจำนวนโหนดข้อมูล เพื่อให้แน่ใจว่าโหนดส่วนใหญ่ได้รับส่วนแบ่งข้อมูลเท่ากัน
- ชาร์ดที่ เล็กกว่า เมื่อเทียบกับขนาดของโหนดข้อมูล หากบางโหนดได้รับชาร์ดเพิ่มเติมสองสามส่วน จะไม่ส่งผลให้โหลดเพิ่มขึ้นอย่างมีนัยสำคัญสำหรับโหนดเหล่านั้น
โซลูชัน Cupcake: โหนดที่ใหญ่กว่าน้อยลง
อัตราส่วนของจำนวนชาร์ดต่อจำนวนโหนดข้อมูล และขนาดของชาร์ดต่อขนาดของโหนดข้อมูล สามารถปรับแต่งได้โดยการมีชาร์ดที่เล็กกว่าจำนวนมาก แต่สามารถปรับแต่งได้ง่ายขึ้นโดยการย้ายไปยังโหนดข้อมูลที่มีจำนวนน้อยลงแต่ใหญ่ขึ้น
เราตัดสินใจเริ่มต้นด้วยคัพเค้กเพื่อยืนยันสมมติฐานนี้ เราย้ายคลัสเตอร์ของเราบางส่วนไปยังอินสแตนซ์ที่ใหญ่และทรงพลังกว่าโดยมีโหนดน้อยลง โดยคงความจุรวมไว้เท่าเดิม ตัวอย่างเช่น เราย้ายคลัสเตอร์จากอินสแตนซ์ 4xlarge 40 รายการเป็นอินสแตนซ์ 16xlarge 10 รายการ ลดความไม่สมดุลของโหลดโดยกระจายชาร์ดอย่างเท่าเทียมกันมากขึ้น
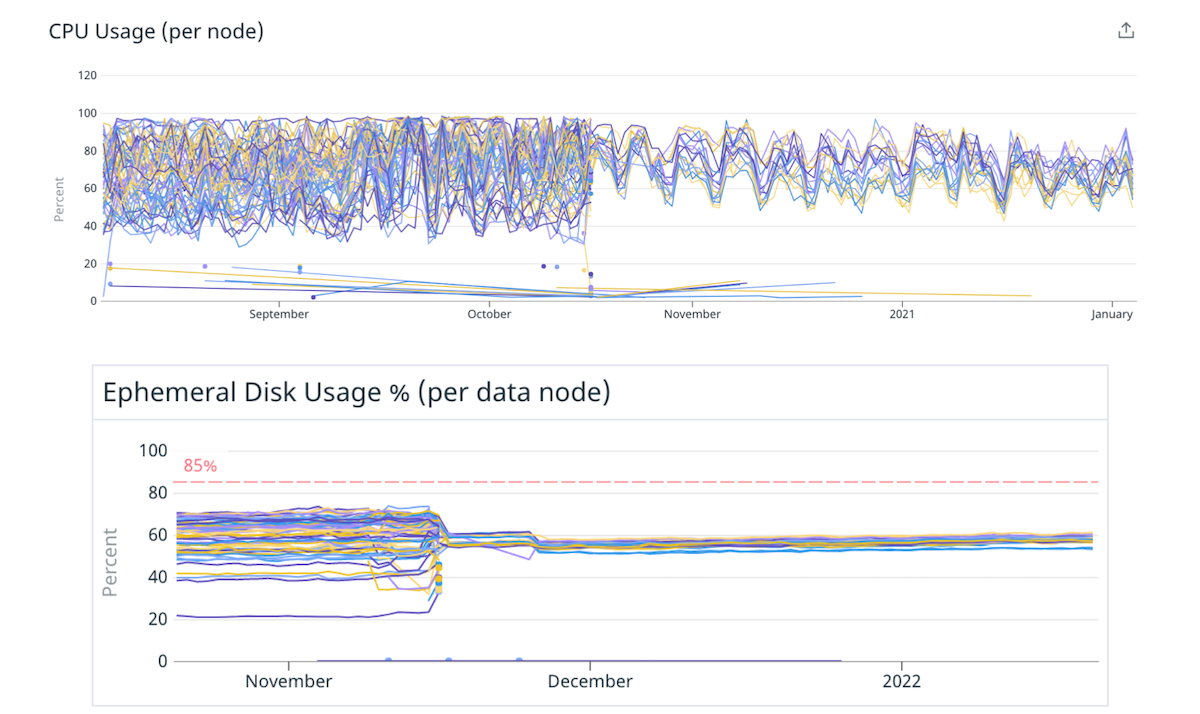
(รูปที่ 4) การกระจายโหลดที่ดีขึ้นในดิสก์และ CPU โดยการย้ายไปยังโหนดที่ใหญ่กว่าน้อยลง
การลดโหนดที่ใหญ่ขึ้นน้อยลงตรวจสอบสมมติฐานของเราว่าการปรับจำนวนและขนาดของโหนดข้อมูลสามารถปรับปรุงการกระจายโหลดได้ เราสามารถหยุดอยู่ที่นั่นได้ แต่มีข้อเสียบางประการสำหรับแนวทางนี้:
- เรารู้ว่าความไม่สมดุลของโหลดจะเพิ่มขึ้นอีกครั้งเมื่อชาร์ดมีขนาดใหญ่ขึ้นเมื่อเวลาผ่านไป หรือหากมีการเพิ่มโหนดในคลัสเตอร์มากขึ้นเพื่อรองรับการรับส่งข้อมูลที่เพิ่มขึ้น
- โหนดที่ใหญ่ขึ้นทำให้การปรับขนาดที่เพิ่มขึ้นมีราคาแพงกว่า การเพิ่มโหนดเดียวตอนนี้จะมีค่าใช้จ่ายมากขึ้น แม้ว่าเราต้องการความจุเพิ่มเติมเพียงเล็กน้อยก็ตาม
ความท้าทาย: ข้ามขีดจำกัดตัวชี้วัตถุธรรมดาที่บีบอัด (OOP)
การย้ายไปยังโหนดที่ใหญ่กว่าจำนวนน้อยลงนั้นไม่ง่ายเพียงแค่เปลี่ยนขนาดอินสแตนซ์ ปัญหาคอขวดที่เราเผชิญคือการรักษาขนาดฮีปทั้งหมดที่มี (ขนาดฮีปบนหนึ่งโหนด x จำนวนโหนดทั้งหมด) ขณะที่เราย้ายข้อมูล
เราได้จำกัดขนาดฮีปในโหนดข้อมูลของเราเป็น ~30.5 GB ตามที่ Elastic แนะนำ เพื่อให้แน่ใจว่าเราอยู่ต่ำกว่าจุดตัดเพื่อให้ JVM สามารถใช้ OOP ที่บีบอัดได้ หากเราจำกัดขนาดฮีปเป็น ~30.5 GB หลังจากย้ายไปยังโหนดที่ใหญ่ขึ้นและน้อยลง เราจะลดความจุของฮีปโดยรวมเนื่องจากเราจะทำงานกับโหนดน้อยลง
“อินสแตนซ์ที่เราย้ายไปมีขนาดใหญ่มาก และเราต้องการกำหนด RAM ส่วนใหญ่ให้กับฮีป เพื่อให้เรามีที่ว่างสำหรับพอยน์เตอร์ โดยเหลือเพียงพอสำหรับแคชของระบบไฟล์”
เราไม่พบคำแนะนำมากมายเกี่ยวกับผลกระทบของการข้ามเกณฑ์นี้ อินสแตนซ์ที่เราย้ายไปมีขนาดใหญ่มาก และเราต้องการกำหนด RAM ส่วนใหญ่ให้กับฮีป เพื่อให้เรามีที่ว่างสำหรับพอยน์เตอร์ โดยเหลือเพียงพอสำหรับแคชของระบบไฟล์ เราทดลองด้วยเกณฑ์สองสามอย่างโดยการจำลองปริมาณการใช้งานจริงเพื่อทดสอบคลัสเตอร์ และตัดสินบน RAM ประมาณ 33% ถึง 42% เป็นขนาดฮีปสำหรับเครื่องที่มี RAM มากกว่า 200 GB

การเปลี่ยนแปลงขนาดฮีปส่งผลกระทบต่อคลัสเตอร์ต่างๆ แตกต่างกัน แม้ว่าบางคลัสเตอร์จะไม่มีการเปลี่ยนแปลงในเมตริก เช่น "JVM % heap in use" หรือ "Young GC Collection Time" แนวโน้มทั่วไปก็เพิ่มขึ้น อย่างไรก็ตาม โดยรวมแล้วเป็นประสบการณ์ที่ดีและคลัสเตอร์ของเราทำงานมานานกว่า 9 เดือนด้วยการกำหนดค่านี้ – โดยไม่มีปัญหาใดๆ
การแก้ไขระยะยาว: เศษเล็กเศษน้อยจำนวนมาก
วิธีแก้ปัญหาระยะยาวคือการมุ่งไปสู่การมีส่วนแบ่งข้อมูลขนาดเล็กจำนวนมากขึ้นเมื่อเทียบกับจำนวนและขนาดของโหนดข้อมูล เราสามารถไปที่ชาร์ดที่เล็กกว่าได้สองวิธี:
- การย้ายดัชนีเพื่อให้มีชาร์ดหลักมากขึ้น ซึ่งจะกระจายข้อมูลในดัชนีไปยังชาร์ดอื่นๆ
- การแบ่งดัชนีออกเป็นดัชนีขนาดเล็ก (พาร์ติชั่น): สิ่งนี้จะกระจายข้อมูลในดัชนีไปยังดัชนีอื่นๆ
สิ่งสำคัญที่ควรทราบคือ เราไม่ต้องการสร้างชาร์ดเล็กๆ นับล้าน หรือมีพาร์ติชั่นเป็นร้อยๆ พาร์ติชั่น ทุกดัชนีและชาร์ดต้องใช้หน่วยความจำและทรัพยากร CPU บางส่วน
“เรามุ่งเน้นที่การทำให้การทดสอบและแก้ไขการกำหนดค่าที่ด้อยประสิทธิภาพภายในระบบของเราง่ายขึ้น แทนที่จะแก้ไขการกำหนดค่าที่ 'สมบูรณ์แบบ'”
ในกรณีส่วนใหญ่ ชาร์ดขนาดใหญ่ชุดเล็กใช้ทรัพยากรน้อยกว่าชาร์ดขนาดเล็กจำนวนมาก แต่ยังมีทางเลือกอื่นๆ อยู่ – การทดลองควรช่วยให้คุณได้รับการกำหนดค่าที่เหมาะสมกว่าสำหรับกรณีการใช้งานของคุณ
เพื่อให้ระบบของเรามีความยืดหยุ่นมากขึ้น เราจึงมุ่งเน้นที่การทำให้การทดสอบและแก้ไขการกำหนดค่าที่ไม่เหมาะสมภายในระบบของเราง่ายขึ้น แทนที่จะแก้ไขการกำหนดค่าที่ "สมบูรณ์แบบ"
ดัชนีการแบ่งพาร์ติชัน
การเพิ่มจำนวนชาร์ดหลักในบางครั้งอาจส่งผลต่อประสิทธิภาพการสืบค้นที่รวบรวมข้อมูล ซึ่งเราพบขณะย้ายคลัสเตอร์ที่รับผิดชอบผลิตภัณฑ์การรายงานของอินเตอร์คอม ในทางตรงกันข้าม การแบ่งพาร์ติชันดัชนีออกเป็นหลายดัชนีจะกระจายโหลดไปยังชาร์ดจำนวนมากขึ้นโดยไม่ลดประสิทธิภาพของคิวรี
อินเตอร์คอมไม่มีข้อกำหนดสำหรับการระบุตำแหน่งข้อมูลร่วมกันสำหรับลูกค้าหลายราย ดังนั้นเราจึงเลือกที่จะแบ่งพาร์ติชั่นตามรหัสเฉพาะของลูกค้า ซึ่งช่วยให้เราส่งมอบคุณค่าได้เร็วขึ้นโดยทำให้ตรรกะการแบ่งพาร์ติชันง่ายขึ้นและลดการตั้งค่าที่จำเป็น
“เพื่อแบ่งพาร์ติชั่นข้อมูลในลักษณะที่ส่งผลกระทบต่อนิสัยและวิธีการที่มีอยู่ของวิศวกรน้อยที่สุด ก่อนอื่นเราใช้เวลาอย่างมากในการทำความเข้าใจว่าวิศวกรของเราใช้ Elasticsearch อย่างไร”
ในการแบ่งพาร์ติชั่นข้อมูลในลักษณะที่ส่งผลกระทบต่อนิสัยและวิธีการที่มีอยู่ของวิศวกรน้อยที่สุด อันดับแรกเราใช้เวลาอย่างมากในการทำความเข้าใจว่าวิศวกรของเราใช้ Elasticsearch อย่างไร เราได้ผสานรวมระบบการสังเกตของเราเข้ากับไลบรารีไคลเอนต์ Elasticsearch และกวาดฐานโค้ดของเราเพื่อเรียนรู้เกี่ยวกับวิธีการต่างๆ ที่ทีมของเราโต้ตอบกับ Elasticsearch API
โหมดการกู้คืนความล้มเหลวของเราคือการลองส่งคำขออีกครั้ง ดังนั้นเราจึงทำการเปลี่ยนแปลงที่จำเป็นในที่ซึ่งเราส่งคำขอที่ไม่ใช่แบบถาวร เราลงเอยด้วยการเพิ่ม linters เพื่อกีดกันการใช้ API เช่น `update/delete_by_query` เนื่องจากมันทำให้ง่ายต่อการส่งคำขอที่ไม่ใช่ idempotent
เราสร้างสองความสามารถที่ทำงานร่วมกันเพื่อมอบฟังก์ชันการทำงานที่สมบูรณ์:
- วิธีกำหนดเส้นทางคำขอจากดัชนีหนึ่งไปยังอีกดัชนีหนึ่ง ดัชนีอื่นนี้อาจเป็นพาร์ติชั่น หรือเพียงแค่ดัชนีที่ไม่ได้แบ่งพาร์ติชั่น
- วิธีในการเขียนข้อมูลแบบคู่ไปยังหลายดัชนี สิ่งนี้ทำให้เราสามารถรักษาพาร์ติชั่นให้ตรงกันกับดัชนีที่กำลังถูกย้าย
“เราปรับกระบวนการของเราให้เหมาะสมเพื่อลดรัศมีการระเบิดของเหตุการณ์ใดๆ โดยไม่ลดทอนความเร็ว”
โดยรวมแล้ว กระบวนการโอนย้ายดัชนีไปยังพาร์ติชั่นมีลักษณะดังนี้:
- เราสร้างพาร์ติชั่นใหม่และเปิดการเขียนแบบคู่ เพื่อให้พาร์ติชั่นของเราอัปเดตด้วยดัชนีเดิม
- เราทริกเกอร์การทดแทนข้อมูลทั้งหมด คำขอทดแทนเหล่านี้จะถูกเขียนแบบคู่ไปยังพาร์ติชั่นใหม่
- เมื่อโฆษณาทดแทนเสร็จสิ้น เราจะตรวจสอบว่าดัชนีทั้งเก่าและใหม่มีข้อมูลเหมือนกัน หากทุกอย่างดูดี เราใช้แฟล็กคุณลักษณะเพื่อเริ่มใช้พาร์ติชั่นสำหรับลูกค้าสองสามรายและตรวจสอบผลลัพธ์
- เมื่อเรามั่นใจแล้ว เราจะย้ายลูกค้าทั้งหมดของเราไปยังพาร์ติชั่น ทั้งหมดในขณะที่เขียนแบบคู่ไปยังทั้งดัชนีเก่าและพาร์ติชั่น
- เมื่อเราแน่ใจว่าการย้ายข้อมูลสำเร็จ เราจะหยุดการเขียนแบบคู่และลบดัชนีเก่า
ขั้นตอนง่ายๆ ที่ดูเหมือนซับซ้อนเหล่านี้ซับซ้อนมาก เราปรับกระบวนการของเราให้เหมาะสมเพื่อลดรัศมีการระเบิดของเหตุการณ์ใดๆ โดยไม่ลดทอนความเร็ว
เก็บเกี่ยวผลประโยชน์
งานนี้ช่วยเราปรับปรุงโหลดบาลานซ์ในคลัสเตอร์ Elasticsearch ของเรา ที่สำคัญกว่านั้น ตอนนี้ เราสามารถปรับปรุงการกระจายโหลดได้ทุกครั้งที่ไม่สามารถยอมรับได้โดยการย้ายดัชนีไปยังพาร์ติชั่นที่มีชาร์ดหลักน้อยลง เพื่อให้ได้สิ่งที่ดีที่สุดของทั้งสองโลก: ชาร์ดต่อดัชนีน้อยลงและน้อยลง
การใช้การเรียนรู้เหล่านี้ทำให้เราสามารถปลดล็อกประสิทธิภาพที่เพิ่มขึ้นและการประหยัดได้
- เราลดต้นทุนของสองคลัสเตอร์ของเราลง 40% และ 25% ตามลำดับ และเห็นการประหยัดต้นทุนอย่างมากสำหรับคลัสเตอร์อื่นๆ เช่นกัน
- เราลดการใช้งาน CPU โดยเฉลี่ยสำหรับคลัสเตอร์หนึ่งๆ ลง 25% และปรับปรุงเวลาแฝงของคำขอมัธยฐานขึ้น 100% เราทำได้โดยการย้ายดัชนีการรับส่งข้อมูลสูงไปยังพาร์ติชั่นที่มีชาร์ดหลักต่อพาร์ติชั่นน้อยกว่าเมื่อเทียบกับพาร์ติชั่นดั้งเดิม
- ความสามารถทั่วไปในการย้ายดัชนียังช่วยให้เราเปลี่ยนสคีมาของดัชนี ช่วยให้วิศวกรผลิตภัณฑ์สร้างประสบการณ์ที่ดีขึ้นสำหรับลูกค้าของเรา หรือจัดทำดัชนีข้อมูลใหม่โดยใช้ Lucene เวอร์ชันใหม่กว่าที่ปลดล็อกความสามารถของเราในการอัปเกรดเป็น Elasticsearch 8
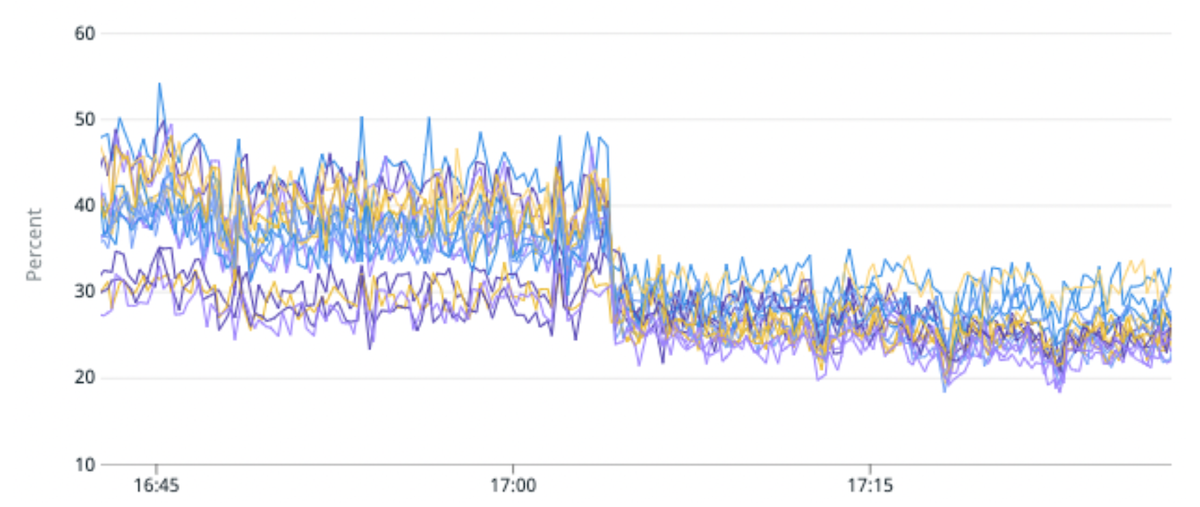
(รูปที่ 5) การปรับปรุงความไม่สมดุลของโหลด 50% และการปรับปรุงการใช้งาน CPU 25% โดยการย้ายดัชนีการรับส่งข้อมูลสูงไปยังพาร์ติชั่นที่มีชาร์ดหลักน้อยลงต่อพาร์ติชั่น
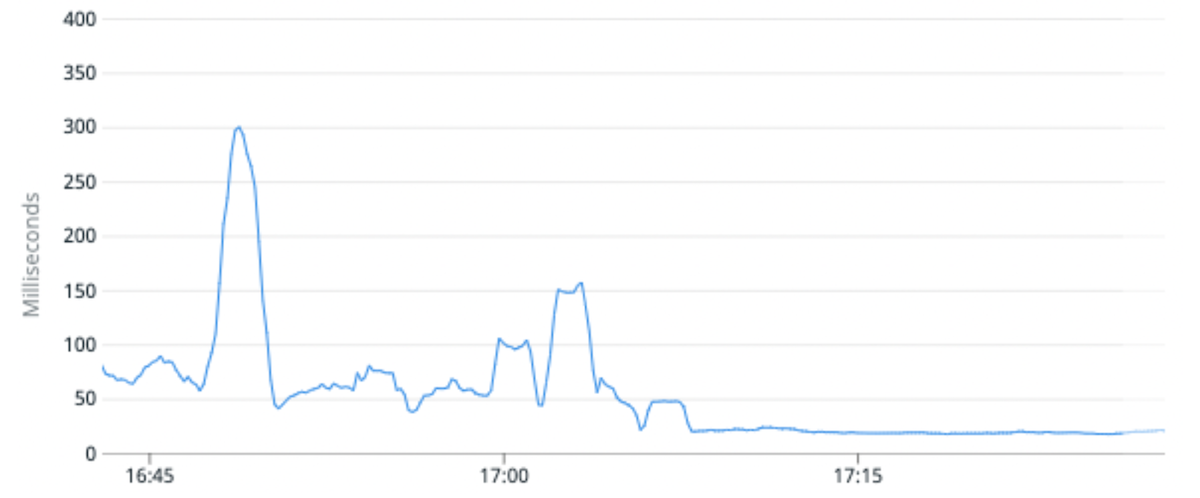
(รูปที่ 6) เวลาแฝงของคำขอเฉลี่ยดีขึ้นโดยเฉลี่ย 100% โดยการย้ายดัชนีการรับส่งข้อมูลสูงไปยังพาร์ติชั่นที่มีชาร์ดหลักต่อพาร์ติชั่นน้อยกว่า
อะไรต่อไป?
การแนะนำ Elasticsearch เพื่อขับเคลื่อนผลิตภัณฑ์และคุณสมบัติใหม่ควรตรงไปตรงมา วิสัยทัศน์ของเราคือการทำให้วิศวกรของเราโต้ตอบกับ Elasticsearch ได้ง่ายเช่นเดียวกับเฟรมเวิร์กเว็บสมัยใหม่ทำให้สามารถโต้ตอบกับฐานข้อมูลเชิงสัมพันธ์ได้ ทีมควรสร้างดัชนี อ่านหรือเขียนจากดัชนี ทำการเปลี่ยนแปลงสคีมา และอื่นๆ ได้โดยง่าย โดยไม่ต้องกังวลว่าคำขอจะได้รับบริการอย่างไร
คุณสนใจวิธีการทำงานของทีมวิศวกรของเราที่อินเตอร์คอมหรือไม่? เรียนรู้เพิ่มเติมและตรวจสอบบทบาทที่เปิดกว้างของเราที่นี่
