
Abbattere le barriere alla scalabilità: come abbiamo ottimizzato l'utilizzo di Elasticsearch in Intercom
Pubblicato: 2022-09-22Elasticsearch è una parte indispensabile di Intercom.
Supporta le funzionalità Intercom di base come Posta in arrivo, Visualizzazioni Posta in arrivo, API, Articoli, l'elenco utenti, i rapporti, il Bot di risoluzione e i nostri sistemi di registrazione interni. I nostri cluster Elasticsearch contengono più di 350 TB di dati dei clienti, archiviano più di 300 miliardi di documenti e soddisfano più di 60 mila richieste al secondo al picco.
Con l'aumento dell'utilizzo di Elasticsearch di Intercom, dobbiamo garantire la scalabilità dei nostri sistemi per supportare la nostra continua crescita. Con il recente lancio della nostra Posta in arrivo di nuova generazione, l'affidabilità di Elasticsearch è più importante che mai.
Abbiamo deciso di affrontare un problema con la nostra configurazione Elasticsearch che poneva un rischio di disponibilità e minacciava futuri tempi di inattività: distribuzione non uniforme del traffico/lavoro tra i nodi nei nostri cluster Elasticsearch.
Primi segnali di inefficienza: squilibrio del carico
Elasticsearch ti consente di scalare orizzontalmente aumentando il numero di nodi che archiviano i dati (nodi di dati). Abbiamo iniziato a notare uno squilibrio di carico tra questi nodi di dati: alcuni di essi erano più sotto pressione (o "più caldi") di altri a causa di un maggiore utilizzo del disco o della CPU.
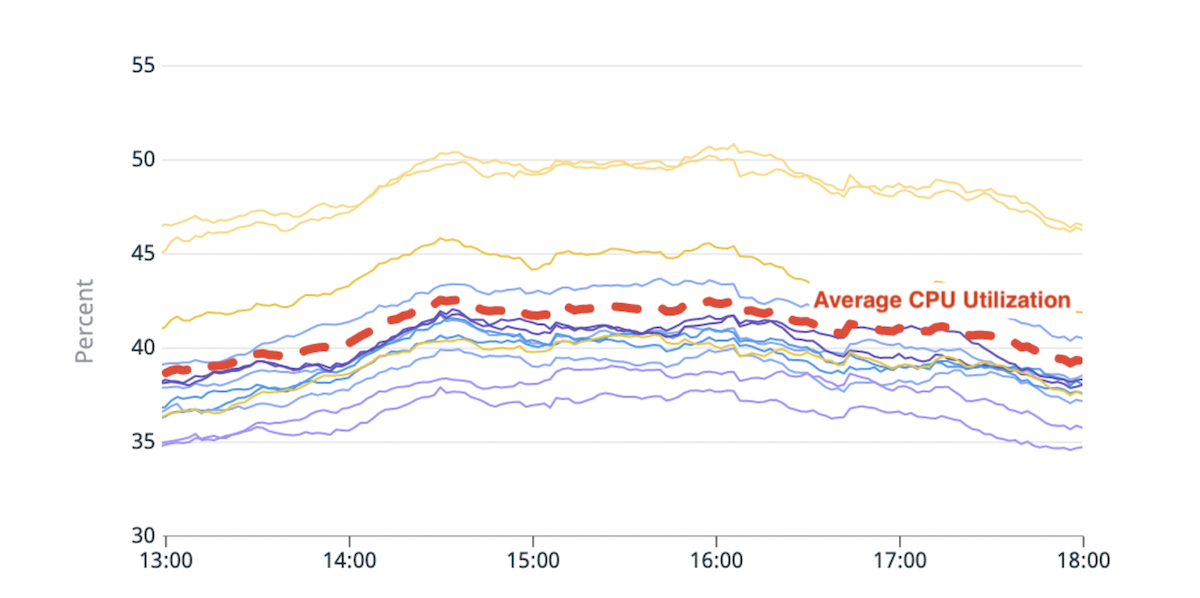
(Fig. 1) Squilibrio nell'utilizzo della CPU: due hot node con un utilizzo della CPU superiore del 20% rispetto alla media.
La logica di posizionamento degli shard integrata di Elasticsearch prende le decisioni in base a un calcolo che stima approssimativamente lo spazio su disco disponibile in ciascun nodo e il numero di shard di un indice per nodo. L'utilizzo delle risorse per shard non tiene conto di questo calcolo. Di conseguenza, alcuni nodi potrebbero ricevere frammenti più affamati di risorse e diventare "caldi". Ogni richiesta di ricerca viene elaborata da più nodi di dati. Un hot node che viene spinto oltre i suoi limiti durante il picco di traffico può causare un degrado delle prestazioni per l'intero cluster.
Un motivo comune per i nodi caldi è la logica di posizionamento degli shard che assegna shard di grandi dimensioni (in base all'utilizzo del disco) ai cluster, rendendo meno probabile un'allocazione bilanciata. In genere, a un nodo potrebbe essere assegnato uno shard più grande degli altri, rendendolo più caldo nell'utilizzo del disco. La presenza di frammenti di grandi dimensioni ostacola anche la nostra capacità di scalare in modo incrementale il cluster, poiché l'aggiunta di un nodo di dati non garantisce la riduzione del carico da tutti i nodi caldi (Fig. 2).
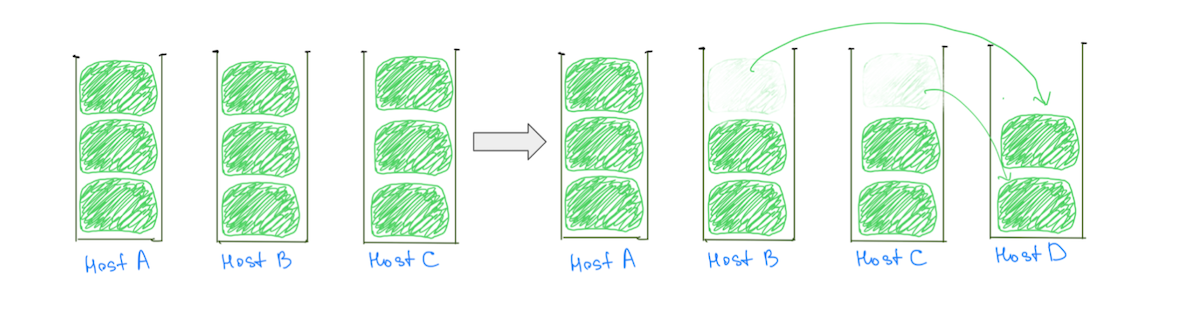
(Fig. 2) L'aggiunta di un nodo di dati non ha comportato una riduzione del carico sull'host A. L'aggiunta di un altro nodo ridurrebbe il carico sull'host A, ma il cluster avrà comunque una distribuzione del carico non uniforme.
Al contrario, avere shard più piccoli aiuta a ridurre il carico su tutti i nodi di dati man mano che il cluster si ridimensiona, compresi quelli "caldi" (Fig. 3).
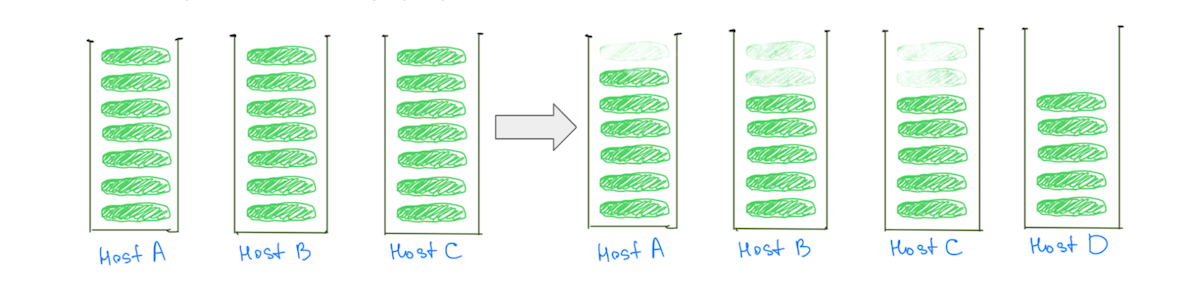
(Fig. 3) Avere molti shard più piccoli aiuta a ridurre il carico su tutti i nodi di dati.
Nota: il problema non è limitato ai cluster con shard di grandi dimensioni. Osserveremmo un comportamento simile se sostituiamo "dimensione" con "utilizzo della CPU" o "traffico di ricerca", ma il confronto delle dimensioni semplifica la visualizzazione.
Oltre a incidere sulla stabilità del cluster, lo squilibrio di carico influisce sulla nostra capacità di scalare in modo conveniente. Dovremo sempre aggiungere più capacità del necessario per mantenere i nodi più caldi al di sotto di livelli pericolosi. Risolvere questo problema significherebbe una migliore disponibilità e significativi risparmi sui costi derivanti dall'utilizzo della nostra infrastruttura in modo più efficiente.
La nostra profonda comprensione del problema ci ha aiutato a capire che il carico potrebbe essere distribuito in modo più uniforme se avessimo:
- Più shard rispetto al numero di nodi di dati. Ciò garantirebbe che la maggior parte dei nodi ricevesse un numero uguale di shard.
- Shard più piccoli rispetto alle dimensioni dei nodi di dati. Se ad alcuni nodi venissero assegnati alcuni shard extra, non comporterebbe alcun aumento significativo del carico per quei nodi.
Soluzione per cupcake: meno nodi più grandi
Questo rapporto tra il numero di shard e il numero di nodi di dati e la dimensione degli shard rispetto alla dimensione dei nodi di dati può essere ottimizzato disponendo di un numero maggiore di shard più piccoli. Ma può essere modificato più facilmente passando a nodi di dati meno numerosi ma più grandi.
Abbiamo deciso di iniziare con un cupcake per verificare questa ipotesi. Abbiamo migrato alcuni dei nostri cluster a istanze più grandi e potenti con meno nodi, preservando la stessa capacità totale. Ad esempio, abbiamo spostato un cluster da 40 istanze 4xlarge a 10 istanze 16xlarge, riducendo lo squilibrio del carico distribuendo gli shard in modo più uniforme.
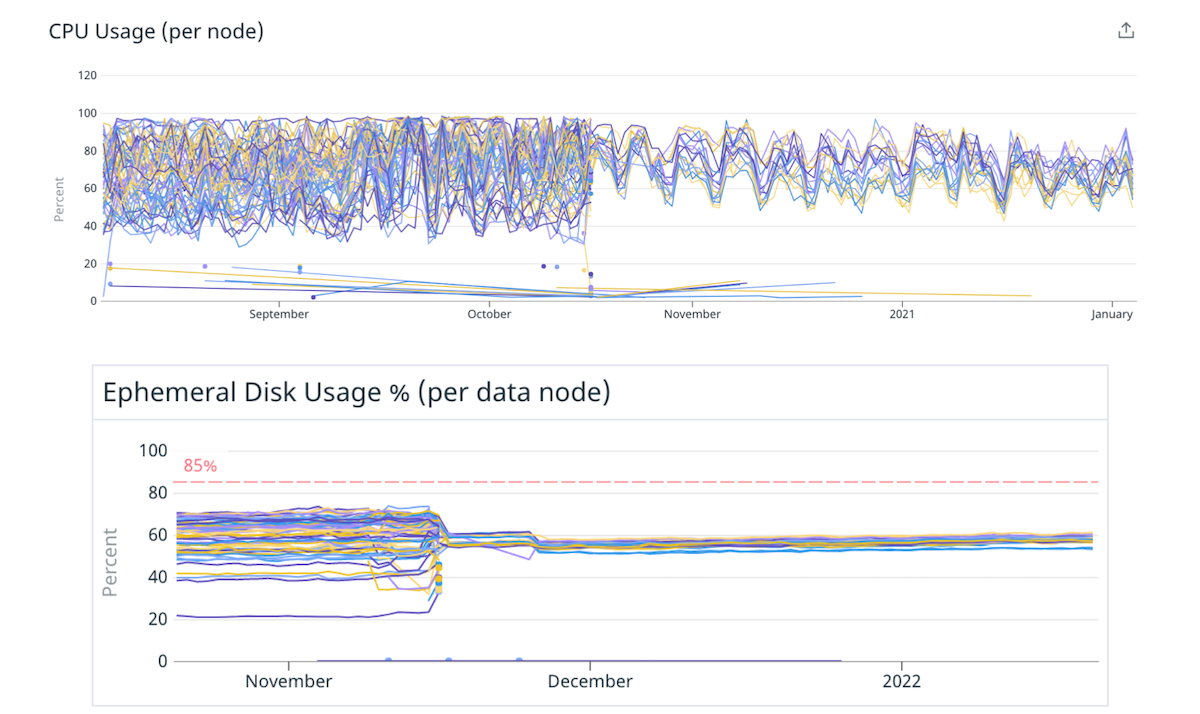
(Fig. 4) Migliore distribuzione del carico su disco e CPU passando a meno nodi più grandi.
Il minor numero di nodi di mitigazione più grandi ha convalidato le nostre ipotesi secondo cui la modifica del numero e delle dimensioni dei nodi di dati può migliorare la distribuzione del carico. Avremmo potuto fermarci qui, ma c'erano alcuni aspetti negativi dell'approccio:
- Sapevamo che lo squilibrio del carico si sarebbe ripresentato quando gli shard sarebbero aumentati nel tempo o se fossero stati aggiunti più nodi al cluster per tenere conto dell'aumento del traffico.
- I nodi più grandi rendono più costoso il ridimensionamento incrementale. L'aggiunta di un singolo nodo ora costerebbe di più, anche se avessimo bisogno solo di una piccola capacità extra.
Sfida: superare la soglia dei puntatori di oggetti ordinari compressi (OOP).
Il passaggio a meno nodi più grandi non è stato così semplice come modificare la dimensione dell'istanza. Un collo di bottiglia che abbiamo dovuto affrontare è stato quello di preservare la dimensione totale dell'heap disponibile (dimensione dell'heap su un nodo x numero totale di nodi) durante la migrazione.
Avevamo limitato la dimensione dell'heap nei nostri nodi di dati a circa 30,5 GB, come suggerito da Elastic, per assicurarci di rimanere al di sotto del limite in modo che la JVM potesse utilizzare OOP compressi. Se avessimo limitato la dimensione dell'heap a circa 30,5 GB dopo essere passati a un numero inferiore di nodi più grandi, ridurremmo la nostra capacità di heap in generale poiché lavoreremmo con meno nodi.
"Le istanze a cui stavamo migrando erano enormi e volevamo assegnare una grande porzione di RAM all'heap in modo da avere spazio per i puntatori, con abbastanza spazio per la cache del filesystem"
Non siamo riusciti a trovare molti consigli sull'impatto del superamento di questa soglia. Le istanze a cui stavamo migrando erano enormi e volevamo assegnare una grande parte della RAM all'heap in modo da avere spazio per i puntatori, con abbastanza spazio per la cache del filesystem. Abbiamo sperimentato alcune soglie replicando il nostro traffico di produzione per testare i cluster e abbiamo optato per un valore compreso tra il 33% e il 42% circa della RAM come dimensione dell'heap per le macchine con più di 200 GB di RAM.
La modifica delle dimensioni dell'heap ha avuto un impatto diverso su vari cluster. Sebbene alcuni cluster non abbiano mostrato cambiamenti nelle metriche come "JVM % heap in use" o "Young GC Collection Time", la tendenza generale è stata un aumento. In ogni caso, nel complesso è stata un'esperienza positiva e i nostri cluster funzionano da più di 9 mesi con questa configurazione, senza alcun problema.

Correzione a lungo termine: molti frammenti più piccoli
Una soluzione a lungo termine sarebbe quella di passare ad avere un numero maggiore di frammenti più piccoli rispetto al numero e alle dimensioni dei nodi di dati. Possiamo arrivare a frammenti più piccoli in due modi:
- Migrazione dell'indice per avere più shard primari: questo distribuisce i dati nell'indice tra più shard.
- Suddivisione dell'indice in indici più piccoli (partizioni): distribuisce i dati nell'indice tra più indici.
È importante notare che non vogliamo creare un milione di minuscoli frammenti o avere centinaia di partizioni. Ogni indice e shard richiede memoria e risorse della CPU.
"Ci siamo concentrati sul rendere più facile sperimentare e correggere le configurazioni non ottimali all'interno del nostro sistema, piuttosto che fissarci sulla configurazione 'perfetta'"
Nella maggior parte dei casi, un piccolo insieme di frammenti di grandi dimensioni utilizza meno risorse rispetto a molti frammenti di piccole dimensioni. Ma ci sono altre opzioni: la sperimentazione dovrebbe aiutarti a raggiungere una configurazione più adatta al tuo caso d'uso.
Per rendere i nostri sistemi più resilienti, ci siamo concentrati sul rendere più facile sperimentare e correggere le configurazioni non ottimali all'interno del nostro sistema, piuttosto che fissarci sulla configurazione "perfetta".
Indici di partizionamento
L'aumento del numero di shard primari a volte può influire sulle prestazioni per le query che aggregano dati, cosa che abbiamo riscontrato durante la migrazione del cluster responsabile del prodotto Intercom Reporting. Al contrario, il partizionamento di un indice in più indici distribuisce il carico su più shard senza compromettere le prestazioni della query.
Intercom non richiede la co-localizzazione dei dati per più clienti, quindi abbiamo scelto di partizionare in base agli ID univoci dei clienti. Questo ci ha aiutato a fornire valore più velocemente, semplificando la logica di partizionamento e riducendo la configurazione richiesta.
"Per suddividere i dati in un modo che abbia un impatto minimo sulle abitudini e sui metodi esistenti dei nostri ingegneri, abbiamo inizialmente investito molto tempo per capire come i nostri ingegneri utilizzano Elasticsearch"
Per suddividere i dati in un modo che abbia un impatto minimo sulle abitudini e sui metodi esistenti dei nostri ingegneri, abbiamo inizialmente investito molto tempo per capire come i nostri ingegneri utilizzano Elasticsearch. Abbiamo integrato profondamente il nostro sistema di osservabilità nella libreria client di Elasticsearch e abbiamo spazzato via la nostra base di codice per conoscere tutti i diversi modi in cui il nostro team interagisce con le API di Elasticsearch.
La nostra modalità di ripristino in caso di errore consisteva nel riprovare le richieste, quindi abbiamo apportato le modifiche richieste quando stavamo facendo richieste non idempotenti. Abbiamo finito per aggiungere alcuni linter per scoraggiare l'uso di API come `update/delete_by_query`, poiché rendevano facile fare richieste non idempotenti.
Abbiamo creato due funzionalità che hanno lavorato insieme per fornire funzionalità complete:
- Un modo per instradare le richieste da un indice all'altro. Questo altro indice potrebbe essere una partizione o solo un indice non partizionato.
- Un modo per eseguire la doppia scrittura dei dati su più indici. Questo ci ha permesso di mantenere le partizioni sincronizzate con l'indice in fase di migrazione.
“Abbiamo ottimizzato i nostri processi per ridurre al minimo il raggio di esplosione di eventuali incidenti, senza compromettere la velocità”
Complessivamente, il processo di migrazione di un indice alle partizioni è simile al seguente:
- Creiamo le nuove partizioni e attiviamo la doppia scrittura in modo che le nostre partizioni rimangano aggiornate con l'indice originale.
- Attiviamo un riempimento di tutti i dati. Queste richieste di riempimento verranno scritte in duplice copia nelle nuove partizioni.
- Al termine del riempimento, convalidiamo che gli indici vecchi e nuovi abbiano gli stessi dati. Se tutto sembra a posto, utilizziamo i flag delle funzionalità per iniziare a utilizzare le partizioni per alcuni clienti e monitorare i risultati.
- Una volta che siamo sicuri, spostiamo tutti i nostri clienti nelle partizioni, il tutto durante la doppia scrittura sia sul vecchio indice che sulle partizioni.
- Quando siamo sicuri che la migrazione sia andata a buon fine, interrompiamo la doppia scrittura ed eliminiamo il vecchio indice.
Questi passaggi apparentemente semplici racchiudono molta complessità. Abbiamo ottimizzato i nostri processi per ridurre al minimo il raggio di esplosione di eventuali incidenti, senza compromettere la velocità.
Raccogliendo i frutti
Questo lavoro ci ha aiutato a migliorare il bilanciamento del carico nei nostri cluster Elasticsearch. Ancora più importante, ora possiamo migliorare la distribuzione del carico ogni volta che diventa inaccettabile migrando gli indici in partizioni con meno shard primari, ottenendo il meglio da entrambi i mondi: shard sempre più piccoli per indice.
Applicando queste conoscenze, siamo stati in grado di sbloccare importanti guadagni e risparmi in termini di prestazioni.
- Abbiamo ridotto i costi di due dei nostri cluster rispettivamente del 40% e del 25% e abbiamo riscontrato notevoli risparmi sui costi anche su altri cluster.
- Abbiamo ridotto del 25% l'utilizzo medio della CPU per un determinato cluster e migliorato del 100% la latenza mediana delle richieste. Abbiamo raggiunto questo obiettivo migrando un indice di traffico elevato su partizioni con meno shard primari per partizione rispetto all'originale.
- La capacità generale di migrare gli indici ci consente anche di modificare lo schema di un indice, consentendo ai Product Engineer di creare esperienze migliori per i nostri clienti, o di reindicizzare i dati utilizzando una versione più recente di Lucene che sblocca la nostra capacità di eseguire l'aggiornamento a Elasticsearch 8.
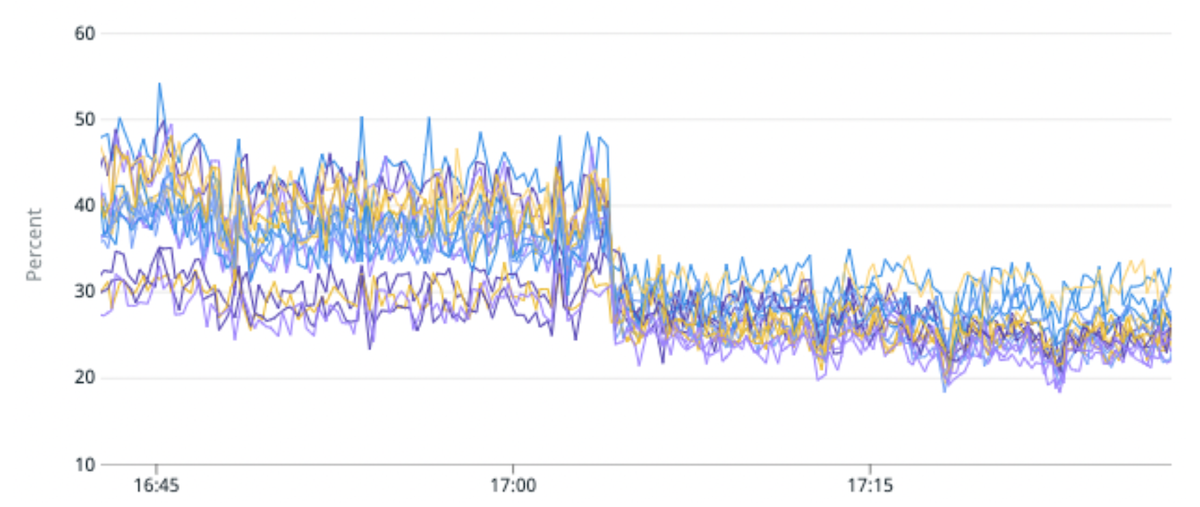
(Fig. 5) Miglioramento del 50% nello squilibrio del carico e del 25% nell'utilizzo della CPU migrando un indice di traffico elevato in partizioni con meno shard primari per partizione.
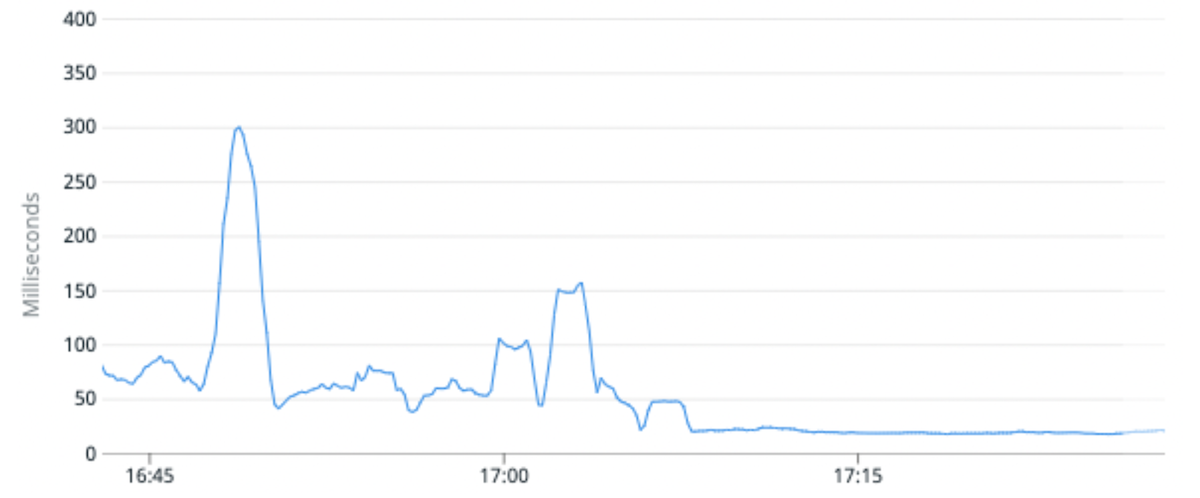
(Fig. 6) La latenza mediana della richiesta è migliorata in media del 100% migrando un indice di traffico elevato su partizioni con meno shard primari per partizione.
Qual è il prossimo?
L'introduzione di Elasticsearch per potenziare nuovi prodotti e funzionalità dovrebbe essere semplice. La nostra visione è rendere l'interazione con Elasticsearch per i nostri ingegneri tanto semplice quanto i moderni framework web rendono semplice l'interazione con i database relazionali. Dovrebbe essere facile per i team creare un indice, leggere o scrivere dall'indice, apportare modifiche allo schema e altro ancora, senza doversi preoccupare di come vengono servite le richieste.
Sei interessato al modo in cui il nostro team di ingegneri lavora a Intercom? Scopri di più e dai un'occhiata ai nostri ruoli aperti qui.
