
拡張の障壁を打ち破る: Intercom で Elasticsearch の使用を最適化した方法
公開: 2022-09-22Elasticsearch は Intercom の不可欠な部分です。
これは、受信トレイ、受信トレイ ビュー、API、記事、ユーザー リスト、レポート、解決ボット、内部ログ システムなどの Intercom のコア機能を支えています。 当社の Elasticsearch クラスターには、350 TB を超える顧客データが含まれ、3,000 億を超えるドキュメントが保存され、ピーク時に 1 秒あたり 6 万を超えるリクエストを処理します。
Intercom の Elasticsearch の使用が増えるにつれて、継続的な成長をサポートするためにシステムを拡張する必要があります。 次世代の Inbox が最近リリースされたことで、Elasticsearch の信頼性はこれまで以上に重要になっています。
私たちは、Elasticsearch クラスター内のノード間でトラフィック/作業が不均一に分散されるという、可用性のリスクと将来のダウンタイムの恐れがある Elasticsearch セットアップの問題に取り組むことにしました。
非効率の初期兆候: 負荷の不均衡
Elasticsearch では、データを格納するノード (データ ノード) の数を増やすことで、水平方向にスケーリングできます。 これらのデータ ノード間で負荷の不均衡に気付き始めました。ディスクまたは CPU の使用率が高いため、一部のデータ ノードは他のノードよりも大きな負荷 (または「高温」) にさらされていました。
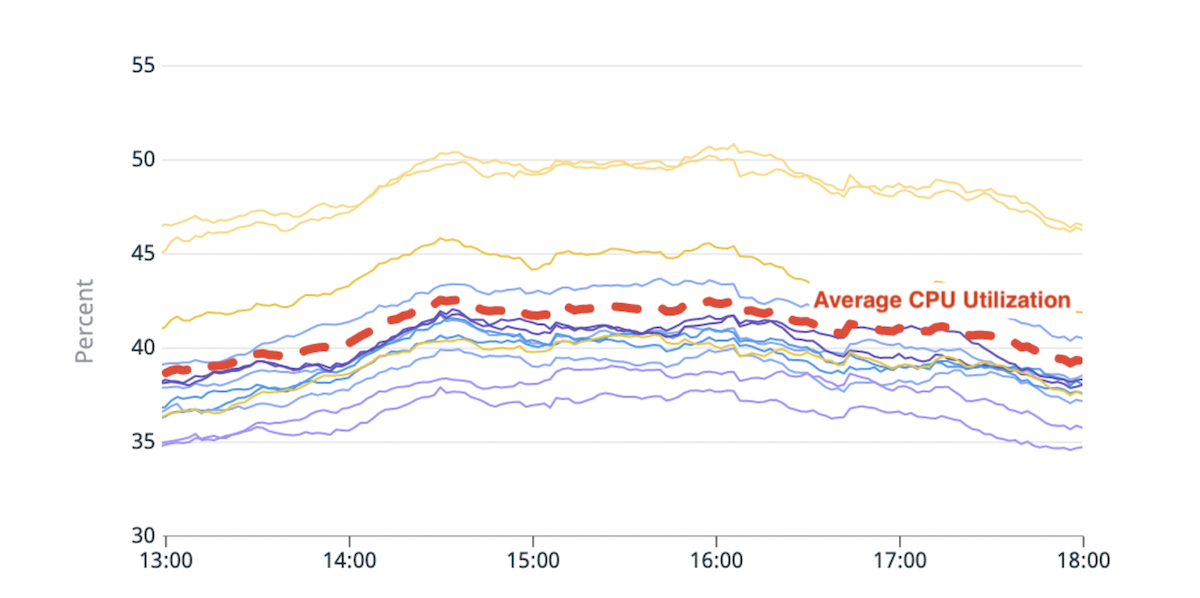
(図 1) CPU 使用率の不均衡: 平均よりも ~20% 高い CPU 使用率を持つ 2 つのホット ノード。
Elasticsearch の組み込みシャード配置ロジックは、各ノードで使用可能なディスク容量とノードごとのインデックスのシャード数を概算する計算に基づいて決定を下します。 シャードごとのリソース使用率は、この計算には考慮されません。 その結果、一部のノードはより多くのリソースを消費するシャードを受け取り、「ホット」になる可能性があります。 すべての検索リクエストは、複数のデータ ノードによって処理されます。 トラフィックのピーク時に制限を超えてプッシュされるホット ノードは、クラスター全体のパフォーマンス低下を引き起こす可能性があります。
ホット ノードの一般的な理由は、(ディスク使用率に基づいて) 大きなシャードをクラスターに割り当てるシャード配置ロジックであり、バランスの取れた割り当てが行われる可能性が低くなります。 通常、ノードには他のシャードよりも 1 つの大きなシャードが多く割り当てられるため、ディスク使用率が高くなります。 データノードを追加しても、すべてのホットノードからの負荷の削減が保証されないため、大きなシャードが存在すると、クラスターを段階的にスケーリングする能力が妨げられます (図 2)。
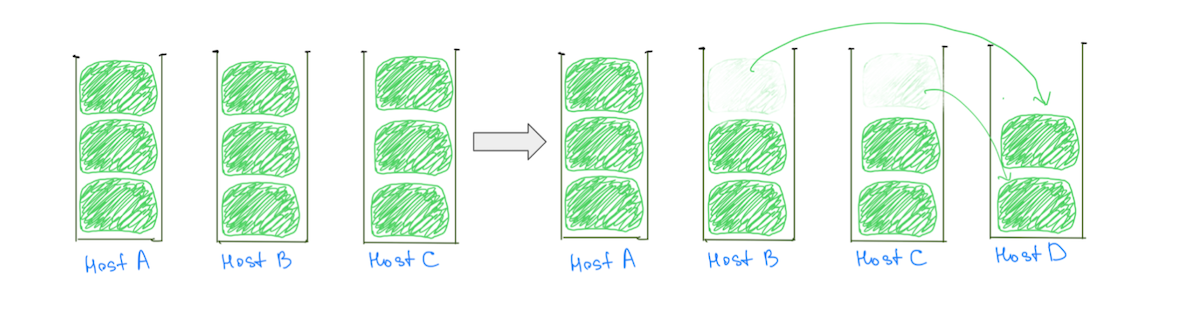
(図 2) データ ノードを追加してもホスト A の負荷は軽減されませんでした。別のノードを追加するとホスト A の負荷は軽減されますが、クラスターの負荷分散は依然として不均一です。
対照的に、シャードを小さくすると、「ホット」なノードを含め、クラスターがスケールするにつれてすべてのデータ ノードの負荷を軽減するのに役立ちます (図 3)。
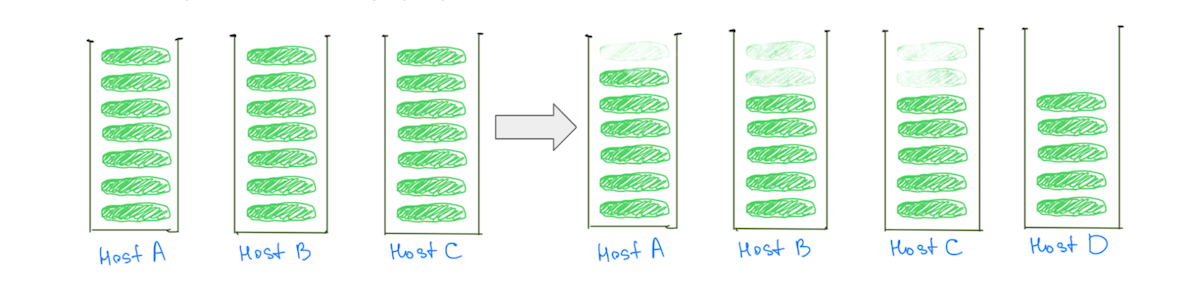
(図 3) 小さいシャードを多数持つことで、すべてのデータ ノードの負荷を軽減できます。
注:この問題は、大規模なシャードを持つクラスターに限定されません。 「サイズ」を「CPU 使用率」または「検索トラフィック」に置き換えると、同様の動作が見られますが、サイズを比較すると視覚化が容易になります。
負荷の不均衡は、クラスターの安定性に影響を与えるだけでなく、費用対効果の高いスケーリングに影響を与えます。 より高温のノードを危険なレベル以下に保つために、常に必要以上の容量を追加する必要があります。 この問題を解決することで、可用性が向上し、インフラストラクチャをより効率的に利用してコストを大幅に削減できます。
この問題を深く理解した結果、次のような条件があれば、負荷をより均等に分散できることがわかりました。
- データ ノードの数に比例してより多くのシャード。 これにより、ほとんどのノードが同じ数のシャードを受け取るようになります。
- データ ノードのサイズに比べて小さいシャード。 一部のノードにいくつかの余分なシャードが与えられた場合、それらのノードの負荷が有意に増加することはありません。
Cupcake ソリューション: より大きなノードを減らす
シャードの数とデータ ノードの数の比率、およびシャードのサイズとデータ ノードのサイズの比率は、小さなシャードの数を増やすことで調整できます。 しかし、より少ないがより大きなデータノードに移動することで、より簡単に微調整できます.
この仮説を検証するために、カップケーキから始めることにしました。 いくつかのクラスターをより大きくより強力なインスタンスに移行し、ノード数を減らして、同じ総容量を維持しました。 たとえば、クラスターを 40 個の 4xlarge インスタンスから 10 個の 16xlarge インスタンスに移動し、シャードをより均等に分散することで負荷の不均衡を減らしました。
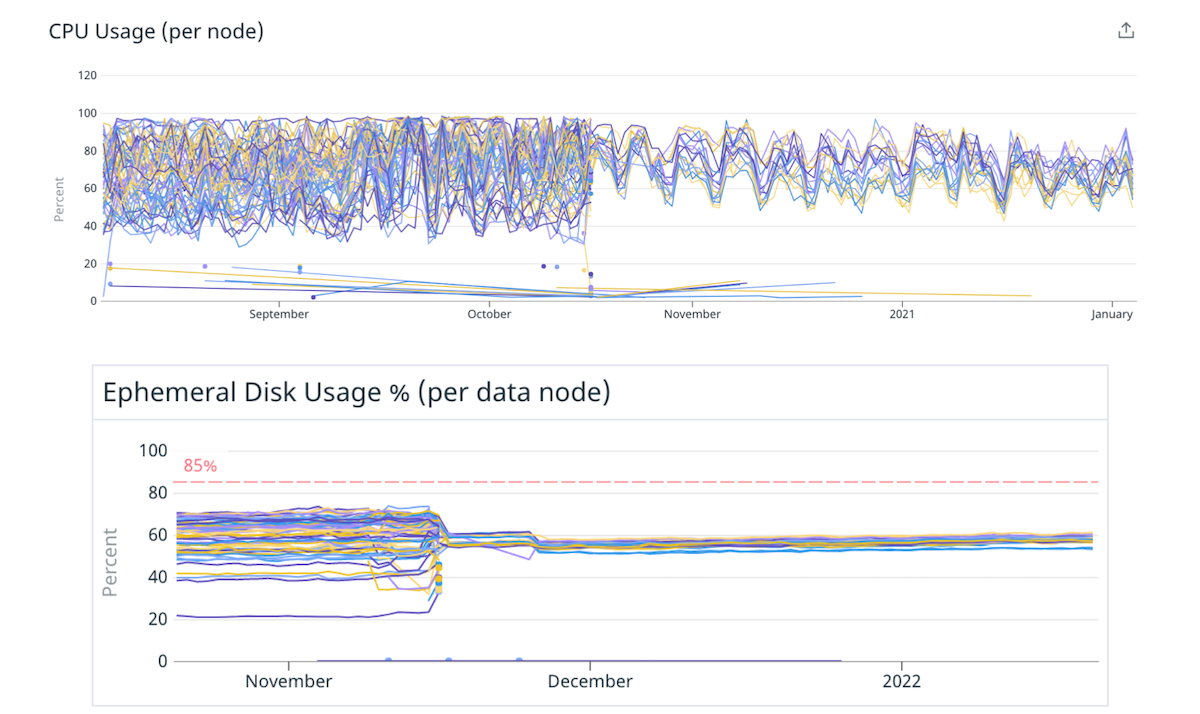
(図 4) 少数の大きなノードに移動することで、ディスクと CPU 間の負荷分散が改善されます。
少数の大きなノードの緩和により、データ ノードの数とサイズを微調整することで負荷分散を改善できるという私たちの仮定が検証されました。 ここでやめることもできましたが、このアプローチにはいくつかの欠点がありました。
- 時間の経過とともにシャードが大きくなったり、トラフィックの増加に対応するためにクラスターにノードが追加されたりすると、負荷の不均衡が再び発生することはわかっていました。
- ノードが大きいほど、増分スケーリングのコストが高くなります。 1 つのノードを追加すると、追加の容量が少しだけ必要な場合でも、より多くの費用がかかります。
課題: Compressed Ordinary Object Pointers (OOP) のしきい値を超える
少数の大きなノードに移動することは、インスタンス サイズを変更するだけでは簡単ではありませんでした。 私たちが直面したボトルネックは、移行時に使用可能な合計ヒープ サイズ (1 つのノードのヒープ サイズ x ノードの総数) を維持することでした。
JVM が圧縮された OOP を使用できるように、Elastic が提案したように、データ ノードのヒープ サイズを最大 30.5 GB に制限していました。 より少数のより大きなノードに移動した後にヒープ サイズを最大 30.5 GB に制限すると、より少ないノードで作業することになるため、ヒープ容量全体が減少します。
「移行先のインスタンスは巨大だったので、RAM の大部分をヒープに割り当てて、ポインター用のスペースを確保し、ファイルシステム キャッシュ用に十分なスペースを確保したかったのです」
このしきい値を超えた場合の影響については、多くのアドバイスを見つけることができませんでした. 移行先のインスタンスは巨大であり、RAM の大部分をヒープに割り当てて、ポインター用のスペースを確保し、ファイルシステム キャッシュ用に十分なスペースを確保したいと考えました。 実稼働トラフィックをテスト クラスターにレプリケートしていくつかのしきい値を試し、200 GB を超える RAM を搭載したマシンのヒープ サイズとして RAM の ~33% から ~42% に落ち着きました。
ヒープ サイズの変更は、さまざまなクラスターに異なる影響を与えました。 一部のクラスターでは、「JVM % heap in use」や「Young GC Collection Time」などの指標に変化が見られませんでしたが、一般的な傾向は増加していました。 いずれにせよ、全体的にはポジティブな経験であり、クラスターはこの構成で 9 か月以上問題なく稼働しています。

長期的な修正: 多くの小さな破片
長期的な解決策は、データ ノードの数とサイズに比べて、より小さなシャードをより多く持つことです。 より小さなシャードに到達するには、次の 2 つの方法があります。
- より多くのプライマリ シャードを持つようにインデックスを移行する: これにより、インデックス内のデータがより多くのシャードに分散されます。
- インデックスを小さなインデックス (パーティション) に分割する: これにより、インデックス内のデータが複数のインデックスに分散されます。
百万の小さなシャードを作成したり、何百ものパーティションを作成したりしたくないことに注意することが重要です。 すべてのインデックスとシャードには、メモリと CPU リソースが必要です。
「私たちは、『完璧な』構成に固執するのではなく、システム内の最適ではない構成を実験して修正しやすくすることに重点を置きました。」
ほとんどの場合、大きなシャードの小さなセットは、多くの小さなシャードよりも少ないリソースを使用します。 ただし、他にもオプションがあります。実験は、ユースケースにより適した構成に到達するのに役立ちます。
システムの回復力を高めるために、「完璧な」構成に固執するのではなく、システム内の次善の構成を実験して修正しやすくすることに重点を置きました。
パーティショニング インデックス
プライマリ シャードの数を増やすと、データを集計するクエリのパフォーマンスに影響を与えることがあります。これは、Intercom のレポート製品を担当するクラスターを移行する際に経験したことです。 対照的に、インデックスを複数のインデックスに分割すると、クエリのパフォーマンスを低下させることなく、より多くのシャードに負荷が分散されます。
Intercom には、複数の顧客のデータを同じ場所に配置する必要がないため、顧客の一意の ID に基づいて分割することを選択しました。 これにより、パーティショニング ロジックを簡素化し、必要なセットアップを減らすことで、より迅速に価値を提供することができました。
「エンジニアの既存の習慣や手法への影響を最小限に抑える方法でデータを分割するために、まず、エンジニアが Elasticsearch をどのように使用しているかを理解することに多くの時間を費やしました。」
エンジニアの既存の習慣や手法への影響を最小限に抑える方法でデータを分割するために、まず、エンジニアが Elasticsearch をどのように使用しているかを理解することに多くの時間を費やしました。 オブザーバビリティ システムを Elasticsearch クライアント ライブラリに深く統合し、コードベースを一掃して、チームが Elasticsearch API を操作するさまざまな方法について学びました。
私たちの失敗回復モードはリクエストを再試行することだったので、べき等でないリクエストを行っていたところに必要な変更を加えました。 最終的に、`update/delete_by_query` などの API の使用を思いとどまらせるためにいくつかのリンターを追加しました。
完全な機能を提供するために連携する 2 つの機能を構築しました。
- あるインデックスから別のインデックスにリクエストをルーティングする方法。 この他のインデックスは、パーティションの場合もあれば、パーティション化されていないインデックスの場合もあります。
- 複数のインデックスにデータを二重書き込みする方法。 これにより、パーティションを移行中のインデックスと同期させることができました。
「スピードを犠牲にすることなく、インシデントの爆発範囲を最小限に抑えるためにプロセスを最適化しました」
全体として、インデックスをパーティションに移行するプロセスは次のようになります。
- 新しいパーティションを作成し、二重書き込みを有効にして、パーティションが元のインデックスで最新の状態に保たれるようにします。
- すべてのデータのバックフィルをトリガーします。 これらのバックフィル リクエストは、新しいパーティションに二重に書き込まれます。
- バックフィルが完了すると、古いインデックスと新しいインデックスの両方に同じデータがあることが検証されます。 すべてが問題ないように見える場合は、機能フラグを使用して、いくつかの顧客に対してパーティションの使用を開始し、結果を監視します。
- 確信が持てたら、古いインデックスとパーティションの両方に二重書き込みを行いながら、すべての顧客をパーティションに移動します。
- 移行が成功したことを確認したら、二重書き込みを停止し、古いインデックスを削除します。
これらの一見単純な手順には、多くの複雑さが含まれています。 プロセスを最適化して、速度を犠牲にすることなく、インシデントの爆発範囲を最小限に抑えました。
メリットを享受する
この作業により、Elasticsearch クラスターの負荷分散が改善されました。 さらに重要なことは、プライマリ シャードの数が少ないパーティションにインデックスを移行することで、受け入れられなくなるたびに負荷分散を改善できるようになり、インデックスあたりのシャードが少なくて小さいという両方の長所を実現できるようになったことです。
これらの学習を適用することで、重要なパフォーマンスの向上と節約を実現することができました。
- 2 つのクラスターのコストをそれぞれ 40% と 25% 削減し、他のクラスターでも大幅なコスト削減が見られました。
- 特定のクラスターの平均 CPU 使用率を 25% 削減し、リクエスト レイテンシの中央値を 100% 改善しました。 これは、高いトラフィック インデックスを、元のパーティションに比べてパーティションあたりのプライマリ シャードが少ないパーティションに移行することで実現しました。
- インデックスを移行する一般的な機能により、インデックスのスキーマを変更して、製品エンジニアがお客様により良いエクスペリエンスを構築したり、新しい Lucene バージョンを使用してデータのインデックスを再作成したりして、Elasticsearch 8 にアップグレードできるようにすることもできます。
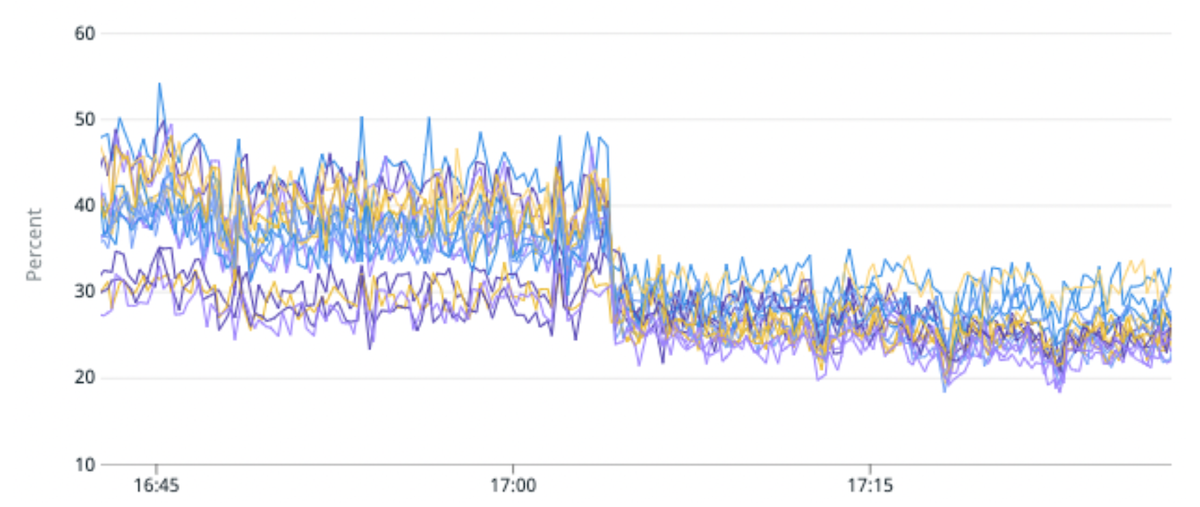
(図 5) パーティションあたりのプライマリ シャードが少ないパーティションに高いトラフィック インデックスを移行することで、負荷の不均衡が 50% 改善され、CPU 使用率が 25% 改善されました。
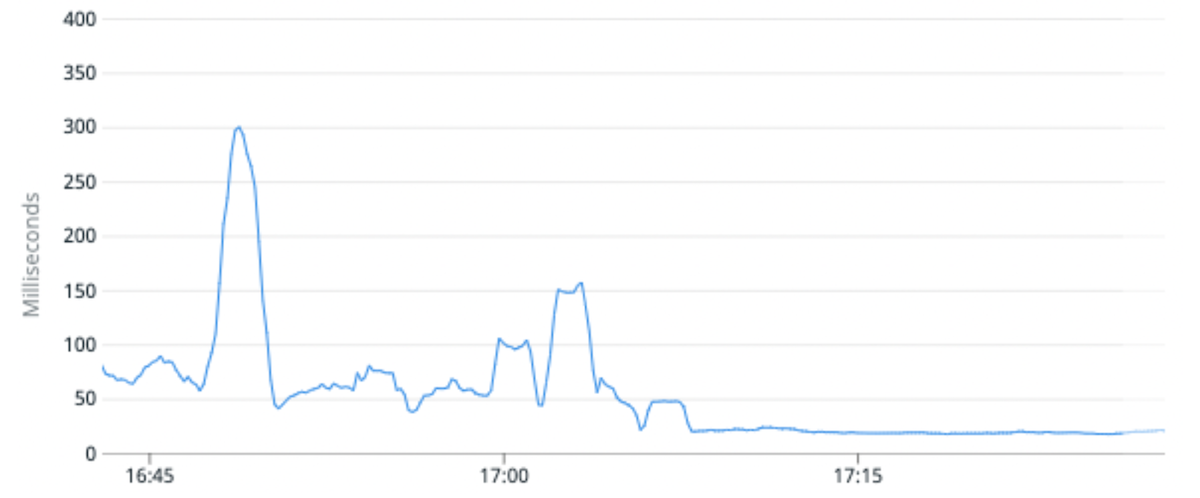
(図 6) パーティションあたりのプライマリ シャードの数が少ないパーティションに高いトラフィック インデックスを移行することで、リクエストのレイテンシの中央値が平均で 100% 改善されました。
次は何ですか?
新しい製品や機能を強化するために Elasticsearch を導入することは簡単です。 私たちのビジョンは、最新の Web フレームワークがリレーショナル データベースとやり取りするように、エンジニアが Elasticsearch とやり取りできるようにすることです。 チームは、リクエストがどのように処理されるかを心配することなく、インデックスの作成、インデックスからの読み取りまたは書き込み、スキーマの変更などを簡単に行える必要があります。
Intercom でのエンジニアリング チームの働き方に興味がありますか? 詳細については、こちらで募集中の職種をご覧ください。
